ICCV 2023 | Pix2Video: Монтаж видео на основе модели диффузии
источник:ICCV 2023 тема:Pix2Video: Video Editing using Image Diffusion Адрес проекта:https://github.com/duyguceylan/pix2video Бумажный адрес:https://arxiv.org/abs/2303.12688 автор:Duygu Ceylan, Chun-Hao P. Хуанг и др. Организация контента:Ван Хан В этой статье исследуется, как использовать предварительно обученную модель распространения изображений для редактирования видео с текстовым управлением. Предлагается метод, не требующий обучения, который может быть распространен на широкий круг редакторов. Мы демонстрируем эффективность нашего подхода посредством обширных экспериментов и сравниваем его с четырьмя различными предыдущими и параллельными работами (по ArXiv). В этой статье показано, что реалистичное редактирование видео с текстовым сопровождением возможно без необходимости какой-либо трудоемкой предварительной обработки или тонкой настройки персонализации видео.
Введение
Модель диффузии изображений, обученная на большой коллекции изображений, стала наиболее универсальной моделью генератора изображений с точки зрения качества и разнообразия. Они поддерживают инверсию реальных условий, подобных изображению (например,,text), что делает его очень популярным среди высококачественных приложений для редактирования изображений. В этой статье рассказывается, как использовать предварительно обученные изображения, такие как Модель, для редактирования видео с текстовым управлением. Ключевой задачей является достижение целевых изменений при сохранении содержания источника. Наш метод состоит из двух простых шагов: во-первых, с использованием предварительно обученного руководства по структуре (например, глубина)картинаподобная диффузная модель затем выполняет редактирование текста в поле привязки;,в ключевых шагах,Постепенное распространение изменений на будущие кадры с помощью Внедрения функции самообслуживания.,Адаптировать основной этап шумоподавления диффузии. Модель. Затем,Объедините эти изменения, отрегулировав базовую кодировку кадра.,Затем продолжайте процесс.
Детали алгоритма
Дана последовательность кадров видеоклипа
, надеясь создать новый набор изображений
, связь между ними определяется целевым текстом
Представляемый редактор. Например, имея видео автомобиля, пользователь может захотеть создать отредактированное видео, в котором редактируются атрибуты автомобиля (например, цвет). Цель этой статьи — использовать возможности предварительно обученных и фиксированных крупномасштабных моделей диффузии изображений для выполнения этих операций как можно более согласованно, не требуя какой-либо тонкой настройки или обширного обучения для конкретного примера. Эта статья достигает этой цели путем манипулирования внутренними характеристиками модели диффузии, а также дополнительными ограничениями начальной загрузки. Учитывая фиксированную модель генерации изображений для обучения, поскольку имеется только одно изображение, невозможно рассуждать о динамике и геометрических изменениях, происходящих во входном видео. В сочетании с недавними достижениями в различных моделях генерации изображений, обусловленных структурными сигналами, этот дополнительный структурный канал оказался эффективным при захвате динамики движения. Поэтому в данной статье наш метод построен на модели устойчивой диффузии, обусловленной глубиной. Учитывая I, выполняется покадровое предсказание глубины и используется в качестве дополнительных входных данных для модели.
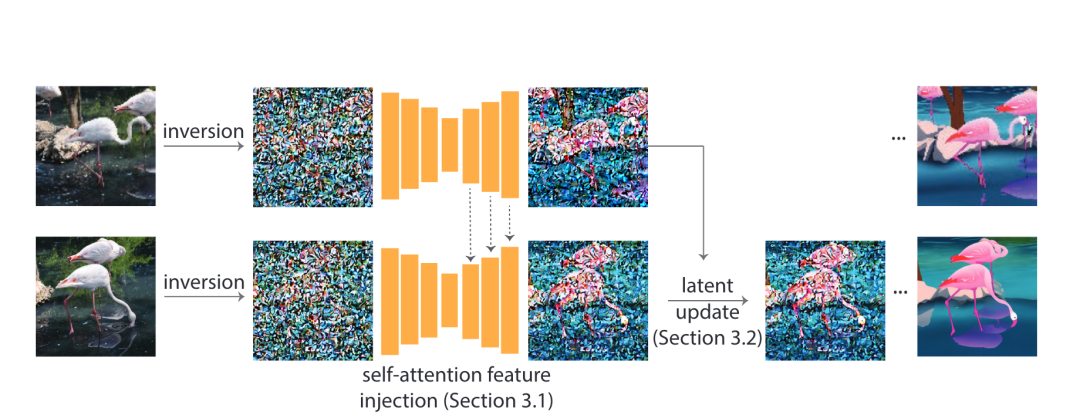
Рисунок 1
Внедрение функции самообслуживания
В контексте статических изображений диффузионные модели для крупномасштабной генерации изображений обычно состоят из архитектуры U-Net, состоящей из блоков остаточного, внутреннего и перекрестного внимания. Блоки перекрестного внимания помогают добиться точности текстовых сигналов, а слои внутреннего внимания помогают определить общую структуру и внешний вид изображения. На каждом этапе диффузии t входные характеристики
Модулю самообслуживания слоя l передать матрицу соответственно
,
и
проект, получить
,
и
, а затем рассчитайте выходные данные блока внимания как:
в
поверхность представляет собой размер QиK,То есть,Для текущего пространственного объекта изображение
каждое место в,Рассчитайте вес других пространственных объектов для сбора глобальной информации. Распространено на контекст видео,Наш метод фиксирует взаимодействие между последовательностями входных изображений, манипулируя входными характеристиками в модулях самообслуживания. Конкретно,Мы вводим функции, полученные из предыдущего кадра. Простой подход заключается в создании признаков для кадра i.
При этом обратите внимание на характеристики предыдущего кадра j
Благодаря такому внедрению функций текущий кадр может использовать контекст предыдущего кадра, тем самым сохраняя изменения внешнего вида. Естественный вопрос заключается в том, можно ли использовать явный, скрытый модуль цикла для объединения состояний функций предыдущего кадра без необходимости явного сосредоточения внимания. на конкретном кадре. Однако разработка и обучение такого модуля не являются тривиальными. Вместо этого мы полагаемся на предварительно обученную генеративную модель, подобную изображению, для неявного выполнения этого слияния. Для каждого кадра i мы добавляем признаки, полученные из кадра i-1. Поскольку редактирование выполняется покадрово, характеристики кадра i-1 необходимо рассчитывать через i-2. Поэтому в этой статье предлагается неявный способ агрегирования состояний объектов. Моя мама доказала, что хотя сосредоточиться Предыдущий кадр помогает сохранить внешний вид, но в более длинных эпизодах он показывает ограничения сокращенного редактирования. Добавление дополнительного поля привязки позволяет избежать этого забывчивого поведения, предоставляя глобальные ограничения на внешний вид. Поэтому в каждом блоке внимания к себе эта статья будет кадром и i. - Характеристики 1 кадра объединяются для расчета пар ключ-значение. В экспериментах этой статьи мы установили = 1, это первый кадр.
Выполните описанное выше внедрение функции на уровне декодера UNet.,Было обнаружено, что он эффективен для поддержания постоянства внешнего вида. Более глубокие уровни декодера собирают информацию высокого разрешения и информацию, связанную с внешним видом.,и произвели рамы с похожим внешним видом, но с минимальными структурными изменениями. Введение признаков в ранние уровни декодера позволяет нам избежать таких высокочастотных структурных изменений. При внедрении функций в кодировщик UNet,Никаких дополнительных существенных преимуществ не наблюдалось.,В некоторых примерах наблюдались небольшие артефакты.
Руководство по возможным обновлениям
Хотя Внедрение функции самообслуживание эффективно создает кадры с целостным внешним видом, но по-прежнему страдает от временного мерцания. Чтобы улучшить временную стабильность алгоритма, мы используем дополнительные указания вдоль линии наведения классификатора для обновления скрытых переменных на каждом этапе распространения. Чтобы выполнить такое обновление, сначала устанавливается энергетическая функция для повышения согласованности. Стабильная диффузия и многие другие крупномасштабные изображения, такие как модель диффузии, представляют собой неявную модель шумоподавления диффузии ( DDIM ),¡На каждом этапе диффузии,Учитывая шумный образец
, указывая вдоль
Вычислите свободные от шума выборки в направлении (
) прогноз. формальный,
Окончательный прогноз определяется по формуле на рисунке 2.

Рисунок 2
в
и
параметр планировщика,
— это шум, предсказанный UNet при текущем размере шага t. ориентировочная стоимость (
) как
Функция рассчитывается и представляет окончательно сгенерированное изображение. Поскольку наша цель — в конечном итоге генерировать похожие последовательные кадры, мы определяем функцию потерь L2.
, используемый для сравнения предсказанного чистого изображения изображения на каждом этапе диффузии t между кадрами i-1иi. Мы обновляем в направлении, которое минимизирует g
, то есть текущая выборка шума кадра i на этапе диффузии t:
в
— скаляр, определяющий размер шага обновления. Экспериментально было замечено, что выполнения одного обновления градиента на каждом этапе диффузии достаточно, и мы установили
. Мы выполняем этот процесс обновления на ранних этапах шумоподавления, то есть на первых 25 шагах из 50 шагов, поскольку общая структура сгенерированного изображения уже определена на ранних этапах диффузии. Выполнение возможных обновлений на оставшихся этапах часто приводит к снижению качества изображений.

Рисунок 3
Наконец, первоначальный шум, используемый для редактирования каждого кадра, также может существенно повлиять на временную согласованность сгенерированных результатов. Мы используем один механизм инверсии — инверсию DDIM, но можно использовать и другие методы инверсии, предназначенные для сохранения редактируемости изображений. Чтобы получить исходные сигналы для инверсии, мы используем модель субтитров для создания субтитров для первого кадра видео. Общие этапы этого метода приведены в алгоритме выше.
Подробности эксперимента
- Набор данных: Pix2Video оценивалась на основе видео, полученного из набора данных DAVIS. Для видео, использованных в предыдущей работе или в тот же период.,Мы используем советы по редактированию, предоставленные такими сайтами. Для других видео,Мы генерируем редакционные советы, консультируясь с небольшим количеством пользователей. Длина таких видео варьируется от 50 до 82 кадров.
- Базовый уровень: Pix2Video сравнивается с современными методами редактирования изображений и видео. ( i Метод Джамриски и др. передает стиль заданного набора кадров во входной сегмент. Мы используем отредактированное поле привязки в качестве ключевого кадра. ( ii ) Мы сравнили недавний метод редактирования видео с текстовым управлением Text2Live. . Отметим, что для этого метода сначала необходимо вычислить нейронный спектр слоя переднего плана и фонового слоя видео, каждое видео занимает около 7 ~ 8 часов. Учитывая спектр нейронного изображения, метод дополнительно настраивает изображение текстовой карты для создания Модели, тратя еще 30 min。( iii ) Мы также сравнили с SDEdit, где мы добавляли шум к каждому входному кадру и условно удаляли шум в командной строке редактирования. Были проведены эксперименты по добавлению шума различной интенсивности и использованию стабильной диффузии, обусловленной глубиной, в качестве модели основной диффузии. ( iv ) Наконец, мы также рассмотрели параллельный подход Tune-a-Video, который выполняет точную настройку для видео предварительно обученного изображения, такого как Модель. Поскольку этот метод генерирует только ограниченное количество кадров, мы выбираем каждый второй кадр на входе, чтобы сгенерировать 24 кадра на основе настроек, предоставленных автором. Примечательно, что этот метод не ограничен какими-либо структурными признаками, такими как глубина. Результаты обобщены на поверхности1. эксперимента。

Таблица 1
- Метрики: Мы ожидаем, что успешный видеоредактор будет точно отражать редактируемую тему и быть последовательным во времени. Для обеспечения точности выбирается показатель CLIP, который представляет собой косинусное сходство между внедрением CLIP подсказки по редактированию и внедрением каждого кадра в отредактированное видео. Мы называем эту меру « CLIP-Text ". Чтобы измерить временную согласованность, мы измерили редактирование видео(' CLIPImage')последовательных кадровкартина Как среднее между вложениямиCLIPсходство。мы наблюдалиCLIPкартина Подобные встраивания кодируют более глобальный внешний вид, чем локальные детали.。поэтому,Мы также вычисляем оптический поток между последовательными кадрами.,И используйте этот оптический поток для редактирования каждого кадра видео, чтобы деформировать следующий кадр. Мы вычисляем среднюю квадратичную ошибку пикселя между каждым деформированным кадром и соответствующим ему целевым кадром как «Pixel-MSE». Отметим, что эта метрика полезна для методов Text2Live и Jamriska et al.,Они явно используют информацию об оптическом потоке. Поскольку наш метод также использует грубое руководство по глубокой структуре,Поэтому мы включили его в нашу оценку.
Результаты эксперимента

Рисунок 4
Количественный эксперимент
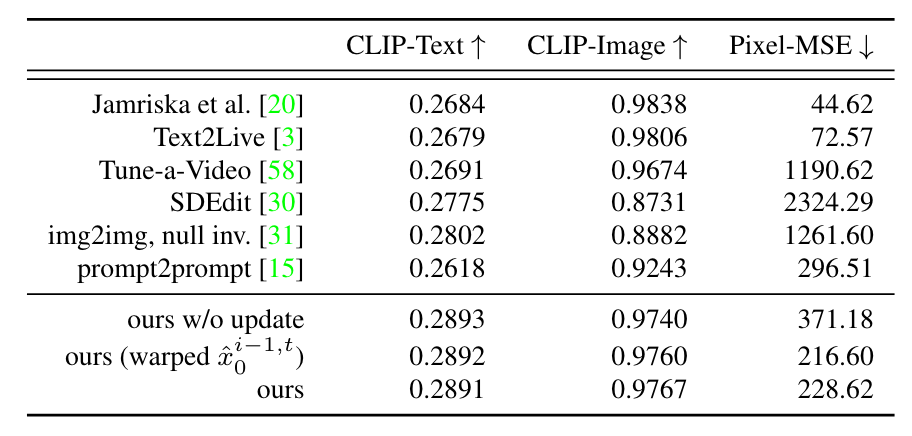
Таблица 2
пользовательский эксперимент
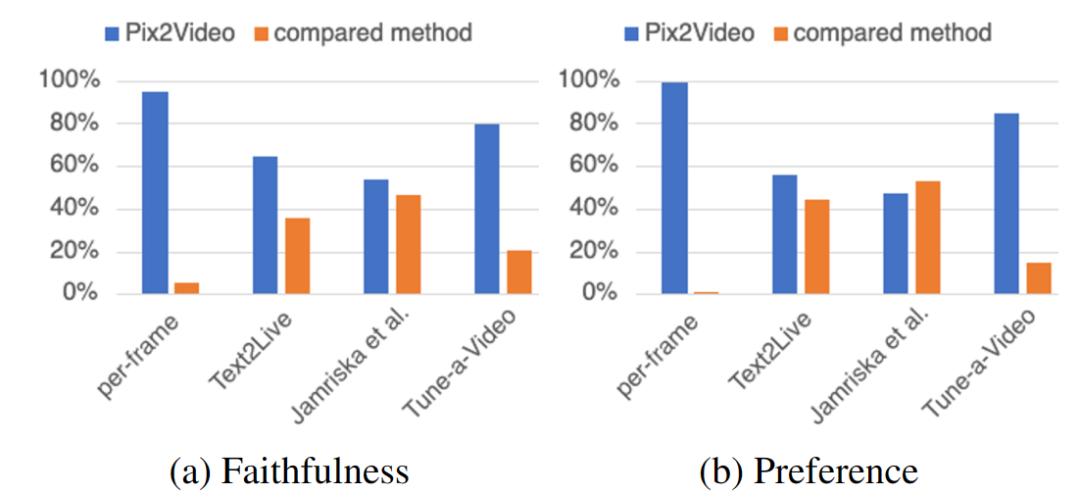
Таблица 3
эксперимент по абляции
Сначала мы оцениваем различные варианты внедрения признаков самообслуживания из предыдущего кадра. На рисунке ниже мы сравниваем, как мы всегда фокусируемся на ( i ) фиксированный опорный кадр (первый кадр в наших экспериментах), ( ii )Только предыдущий кадр,( iii ) поле привязки и случайно выбранный предыдущий кадр, и ( iv ) якорь и сцена предыдущего кадра.

Рисунок 5
Без использования информации о предыдущем кадре или выбора случайного предыдущего кадра мы наблюдали артефакты, особенно в последовательностях, содержащих больше вращательного движения, например, структура автомобиля не сохраняется при вращении автомобиля. Это подтверждает нашу интуицию о том, что внимание к предыдущему кадру неявно отражает статус редактора по кругу. Без блоков привязки мы наблюдали большее временное мерцание и редактирование, которое уменьшалось по мере продвижения видео. Объединив предыдущий кадр с опорным кадром, мы достигаем хорошего баланса.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
