ICCV 2023 | Глубокое сжатие видео на основе моделей
Введение
Как традиционные платформы гибридного видеокодирования, так и существующие методы сжатия видео на основе глубокого обучения (DLVC) следуют одному и тому же подходу к сжатию видео, разрабатывая различные модули для уменьшения пространственной и временной избыточности. Они используют соседние пиксели в одном и том же кадре или соседних кадрах в качестве эталонов для получения значений внутреннего или внешнего предсказания. Поскольку видеопоследовательности захватываются с высокой частотой кадров (например, 30 кадров в секунду или 60 кадров в секунду), одна и та же сцена может появляться в сотнях кадров, которые сильно коррелированы во временной области. Однако существующие стратегии сжатия не могут полностью устранить избыточность сцены при прогнозировании на уровне блоков или кадров.
Чтобы преодолеть узкое место в производительности при сжатии видео, в этой статье предлагается инновационная парадигма кодирования видео, целью которой является поиск компактного подпространства для видеопоследовательностей одной и той же сцены вместо уменьшения пространственно-временной избыточности с помощью методов прогнозирования на уровне блоков или кадров. Эта парадигма заменяет сокращение избыточности посредством локального прогнозирования неявным моделированием компактного подпространства всей сцены. Поэтому поиск подходящего инструмента моделирования для представления сценария имеет решающее значение для этой парадигмы, а неявные нейронные представления (INR) популярны благодаря своей мощной способности моделировать различные сигналы через глубокие сети. Некоторые исследователи применили INR к задачам сжатия изображений и добились многообещающих результатов, что позволяет применять INR к задачам MVC.
В MVC,Моделирование последовательности – очень важный фактор,Это основная проблема, с которой сталкивается сжатие видео. Однако,Возможности представления исходного метода видеоINR ограничены.,Чтобы получить видео, необходимо пройти каждый пиксель каждого кадра изображения. И отказаться от попиксельного обхода,Производительность метода INR, который принимает в качестве объекта индекс видеокадра, очень ограничена.,Например, предыдущий NeRV не был даже так хорош, как H.265. Это скорее иллюстрирует потенциал дальнейшего развития применения видеоINR для задач сжатия видео. поэтому,в этой статье,Автор еще больше улучшает видеоINR в улучшении пространственного контекстаи Регистрация временной Возможности моделирования последовательностей в сравнении.
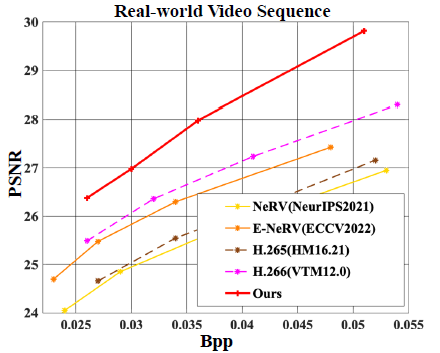
Рисунок 1. Сравнение производительности различных методов видео INR и традиционных методов сжатия видео.
Для захвата пространственного контекста в этой статье предлагается метод контекстно-зависимого внедрения пространственного положения (CRSPE). Также представлен модуль контроля частотной области (FDS), который может захватывать высокочастотные детали и улучшать качество реконструкции без необходимости дополнительной скорости передачи данных. Временная корреляция является ключевым фактором для метода INR, позволяющим повысить эффективность представления различных кадров. Существующие методы INR для видео в основном полагаются на различные кодировки временных позиций для различения кадров и ожидают, что сеть неявно выучит временные корреляции. Но для длинных видеопоследовательностей им трудно исследовать сложные долгосрочные временные корреляции. Чтобы решить эту проблему, в этой статье представлен механизм ограничения оптического потока сцены (SFCM) для краткосрочной временной корреляции и потеря временного контраста (TCL) для долгосрочной временной корреляции. Эти механизмы не увеличивают параметры сети и хорошо подходят для задач MVC. Эта новая структура MVC уже значительно превосходит H.266, демонстрируя потенциал подхода MVC.
Подводя итог, можно выделить следующие основные моменты этой статьи:
- Предложил MVC,Цель: выявить более компактные подпространства для видеопоследовательностей. В отличие от существующих методов, которые полагаются на явное уменьшение пространственно-временной избыточности посредством прогнозирования на уровне блоков или кадров.,MVC использует корреляцию между всеми кадрами сцены одновременно.
- Устранить ограничения существующих методов видеоINR при применении к сжатию видео.,Автор внедрил CRSPEиFDS в улучшение внутреннего контекста.,Они могут обрабатывать пространственные изменения от кадра к кадру и захватывать высокочастотные детали. Автор доработал SFCMиTCL для моделирования временной корреляции.
- Провёл обширный эксперимент на разных базах данных.,И провел детальный анализ модуля дизайна. Результаты эксперимента показывают,предлагаемый метод может быть лучше, чем H.266 (VTM12.0). Это демонстрирует превосходство предложенного алгоритма.,И может вдохновить исследователей на изучение сжатия видео с новых точек зрения.
предлагаемый метод
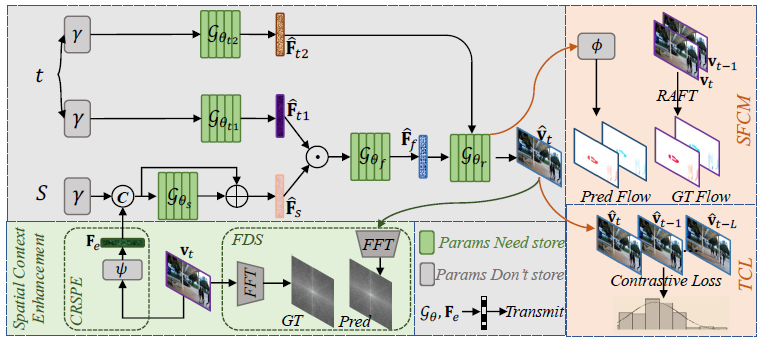
Рисунок 2. Структура предлагаемого MVC
предыдущая работа
Рисунок Диаграмма серого прямоугольника в 1 соответствует использованию предыдущей работа,Используется метод видеоINR, использующий временное и пространственное разделение информации. Конкретно,сеть требует индекс кадра текущего момента
и пространственная система координат
,
Размер
, представляет пространственные объекты с низким разрешением. индекс кадра
и пространственная система координат
Сначала выполните операцию нормализации, а затем введите кодировку положения.
Выполнение расширения размеров и кодирования позиции
Это может быть выражено как:
в
. Кодирование положения может эффективно расширить размеры входного сигнала. Предыдущие исследования показали, что способность INR плохо подгоняться, когда пространственные координаты или временные индексы вводятся напрямую, в то время как многомерное расширение может улучшить способность представления INR. Следующим шагом является извлечение пространственных и временных характеристик текущего кадра. Временные характеристики получаются с помощью MLP, а пространственные характеристики — с помощью внедрения преобразователя. Эти сети используют параметры.
и
выразить. В частности, извлеченные функции можно записать как:
После этого необходимо соединить извлеченные временные и пространственные особенности приезжать.
это
размерный вектор и
, поэтому умножьте непосредственно на канал и передайте параметр как
Сеть генерирует слитые пространственно-временные характеристики, и это
сеть Усыновленныйи
Та же конструкция трансформатора. Этот процесс можно конкретно выразить так:
Благодаря объединению пространственно-временных функций вы можете рассмотреть возможность создания индекса текущего кадра.
момент видеокадра. сеть
Карта объектов подвергается повышению дискретизации с использованием операций свертки и перемешивания пикселей, что является постепенным процессом. сеть
Он содержит пять идентичных структур повышающей дискретизации, и каждая структура разработана с разным коэффициентом повышающей дискретизации. В процессе повышения дискретизации для дальнейшей интеграции временного контекста будет создан дополнительный временной признак, который будет управлять смещением распределения промежуточной карты признаков. Этот процесс может эффективно повысить производительность. Таким образом, процесс генерации видеокадра можно резюмировать следующим образом:
улучшение пространственного контекста
Контекстно-ориентированное пространственно-позиционное встраивание
Вышеупомянутое работает через фиксированные координаты сетки.
Неявно представляет пространственный контекст,Это встраивание контекстно-свободного пространственного местоположения. Однако пространственный контент будет меняться между разными видеокадрами.,Это приведет к увеличению параметров сети Модель и увеличению времени обучения.,Только так мы сможем получить относительно хороший результат. Чтобы решить эту проблему,Авторы предложили CRSPE. Смотреть приезжать с рисунка 2,перед тренировкой,пройдет сеть
Извлеките пространственный объект для каждого видеокадра
, а затем пространственные особенности
Пространственные координаты после расширения измерения
Выполните каскадирование. Для видео 720P, сеть
это
Сверточный слой и для видео 1080P сеть
это
Сверточный слой. Несмотря на передачу
Требуются дополнительные биты, но это позволяет модели добиться лучшего качества реконструкции, что повысит производительность RD. Результаты теста показывают, что за видео 720P требуется дополнительная плата.
За счет Бпп, примерно
Улучшение PSNR в д Б.
Контроль частотной области
В предыдущих исследованиях INR в целом было обнаружено, что сети трудно усваивать высокочастотную информацию. Некоторые работы используют в своих сетях частотно-зависимые операции, которые могут захватывать высокочастотные детали изображений. Однако эти операции сложно напрямую применить к задачам сжатия видео, поскольку они требуют дополнительных сложных модулей и вводят больше битов кодирования. Чтобы сохранить высокочастотные детали в видеокадрах, предлагается использовать функцию потери восприятия с учетом частоты без добавления сетевых параметров. В частности, для преобразования используется быстрое преобразование Фурье (БПФ).
и
Преобразуйте в частотную область и затем вычислите
потеря:
Регистрация временной корреляции
Предыдущий метод INR использовал только индекс кадра текущего момента.
Чтобы различать разные кадры, модель столкнется с ухудшением производительности в условиях сложных временных изменений, особенно в случае долгосрочных временных корреляций. Поэтому авторы предложили SFCM для фиксации краткосрочной временной корреляции. В дополнение к этому, TCL также предназначен для улучшения моделирования долгосрочных временных корреляций.
Механизм ограничения потока сцены
SFCM повысит дискретизацию сети с
Извлеките последнюю карту объектов перед созданием изображения видеокадра.
,использовать
для создания оптического потока. Для ограничений используются два оптических потока: прямой оптический поток.
Представлять из
приезжать
Схема оптического потока и обратный оптический поток
Представлять из
приезжать
Оптическая схема. Генерация карт оптических потоков опирается на предварительно обученные сети.
, и поскольку карта оптического потока GT генерируется алгоритмом оценки оптического потока RAFT, видеокадр
Соответствующая оптическая схема
. Наконец, пройдите
Оптимизация потерь:
Поскольку карта оптического потока GT оценивается алгоритмом RAFT приезжать,По разным причинам, таким как точность алгоритма и т. д.,В карте оптического потока будет определенное количество шума.,Карта оптического потока, содержащая шум, ухудшает качество изображения. Чтобы решить проблему шума,Введены операции регуляризации. Конкретно,Автор использует
Свертка плюс пара слоев softmax
После обработки получается регуляризованная весовая матрица двух каналов.
. затем выберите
Второй канал регуляризует карту оптического потока, и регуляризованные ограничения оптического потока становятся:
Автор здесь намеренно помещает весовую матрицу
Разработан с двумя каналами, одной из целей которого является облегчение
Оптимизация становится формой горячего вектора в измерении канала. Кроме того, одноканальный
Подобно карте внимания, ее можно контролировать только косвенно за счет потери реконструкции MVC, и существует риск того, что она не сможет эффективно учиться. Следовательно, это будет
Он спроектирован как двухканальный и использует функцию потерь для оптимизации.
, эта функция определяется как:
На рисунке 3 показаны результаты регуляризации оптического потока.,Вы можете видеть, что фоновый шум, которого не должно быть, исчез.,Выделен оптический поток людей как движущихся объектов.

Рис. 3. Сравнение оптического потока до и после регуляризации
Временная контрастная потеря
Хотя SFCM может фиксировать кратковременную временную корреляцию двух соседних кадров.,Но долгосрочные временные корреляции также важны. поэтому,Авторы рассматривают моделирование долгосрочной временной корреляции между текущим кадром и ранее восстановленным кадром.,В основном это достигается посредством сравнительного обучения. учитывать текущий момент
реконструированный кадр
èЗа мгновение до
приезжать
Коллекция реконструированных кадров
. Использование предварительно обученного извлечения признаков в сети глобального пула восстанавливает кадр
Встраивание вектора признаков прибытия
Поднимитесь. Поскольку кадры, находящиеся рядом во времени, имеют более высокую корреляцию, чем кадры, находящиеся на расстоянии, предполагается, что
и
Сходство между ними должно следовать априорному гауссовскому распределению временного расстояния, а сходство векторов признаков рассчитывается по косинусному сходству. Наконец, на основе приведенных выше предположений, используется расхождение KL для оптимизации сходства признаков и априорного распределения Гаусса. Блок-схема выглядит следующим образом: Рисунок. Как показано на рисунке 4, этот процесс может быть выражено как:
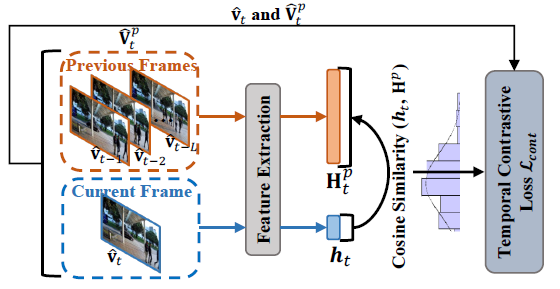
Рисунок 4. Процесс расчета TCL
В частности, соответствующие значения параметров в формуле:
. На основе всех приведенных выше расчетов функция общих потерь после полного учета всей пространственно-временной информации рассчитывается как:
Процесс сжатия видео и сжатие модели
Процесс сжатия видео, используемый в этой статье, показан на рисунке 5. На этапе обучения (кодирования) предлагаемая сеть сначала обучается на всем видео. Затем установите параметры сети
Пространственные особенности
Квантуется в битовый поток для хранения и передачи. Параметры сети представляют собой числа одинарной точности с плавающей запятой, и для представления каждого веса требуется 32 бита. Чтобы уменьшить требования к памяти,ИспользоватьAIMET (набор инструментов для повышения эффективности моделей искусственного интеллекта) определяет количественную оценку модели. Поскольку диапазон значений каждого весового тензора различен, для достижения равномерного квантования для каждого весового тензора необходимо использовать разные стратегии квантования. Опыт показывает, что 7- или 8-битное квантование гарантирует наилучшую производительность искажений. наконец,использоватьколичественносетьпараметр Пространственные Особенности декодирования. Помимо количественной оценки,Существует также множество методов сжатия моделей, которые могут еще больше улучшить характеристики искажения скорости.,Автор не дискутирует дальше, чтобы обеспечить справедливость. Сравнить существующие методы сжатия,Автор определяет Bpp MVC:
. Проще говоря, это общее количество битов функции «Модели», разделенное на общее количество пикселей видео.
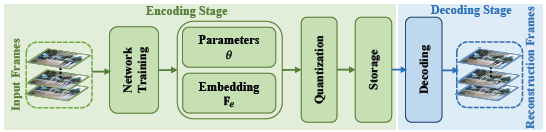
Рисунок 5. Блок-схема сжатия видео методом MVC.
эксперимент
эксперимент Конфигурация
В этой статье PSNRиBpp используется как мера производительности сжатия.,Характеристики MVCсеть определяют, что на данном этапе его можно использовать только для задач сжатия не в реальном времени. В использовании используется три набора данных: HEVC ClassE Three 720Pvideo.,Три монитора 1080P стандарта IEEE1857 видео,и два монитора 1080P, использованные в других документах. Авторы сравнивают метод MVC с традиционными кодеками, методами на основе INR и методами DLVC. Объектами сравнения традиционными методами являются H.265 (HM16.21) и H.266 (VTM12.0), а методом на основе INR — E-NeRV.,Методы DLVC включают HSTE (или DCVC-HEM) и CANFVC.
экспериментрезультат
В таблице 1 показаны результаты BDBR различными методами.,Базовым методом сравнения является H.266. Под наблюдением видео,MVC может добиться улучшения PSNR примерно на 1 д Б по сравнению с H.266 при аналогичном Bpp.,Это значительное преимущество. MVC добился наилучшей производительности на всех наборах тестовых данных.

Таблица 1 Сравнительная производительность BDBR разных МодельиH.266 при разных последовательностях видео
В таблице 2 показаны различные эксперименты по абляции, выполненные автором. Вы можете посмотреть приезжать,Все предложенные модули повышаютпроизводительность сети. Серия экспериментов проверит эффективность модуля, предложенного в этой статье. в SFCM,Отдельно обсуждается также эффективность предложенного метода регуляризации и двухканальной весовой матрицы. Вы можете посмотреть приезжать,без регуляризации,Производительность модели даже несколько ухудшилась. И для ТСЛ,Эффективность гауссовского априора и влияние длины эталонной последовательности обсуждаются соответственно.

Таблица 2 удалятьэкспериментрезультат
Подвести итог
В этой статье предлагается новая платформа MVC для задач сжатия. Эта структура использует INR в качестве магистральной сети.,Обсуждаются ограничения существующих методов видеоINR применительно к задачам кодирования видео. Чтобы обойти эти ограничения,Автор предлагает контекстно-зависимое встраивание пространственного местоположения и контроль частотной области.,Расширить возможности существующих методов INR по извлечению пространственного контекста. также,Также улучшается механизм ограничения оптического потока сцены и потеря временной контрастности.,улучшить возможности моделирования времени. в эксперименте,Предложенный в этой статье метод MVC превосходит H.266 во всех тестовых последовательностях.,Это мотивирует нас изучить задачу сжатия видео с новой точки зрения.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
