ICCV 2023 | Экскурсия по 10 статьям, посвященным управляемой генерации диффузионной модели диффузии
1、Adding Conditional Control to Text-to-Image Diffusion Models

Классический обзор снова! ICCV 2023 Best Paper ControlNet за добавление пространственно обусловленного управления к большим предварительно обученным моделям диффузии текста в изображение. ControlNet фиксирует готовые крупномасштабные диффузионные модели и повторно использует их глубокие и надежные уровни кодирования, предварительно обученные на миллиардах изображений, в качестве мощной поддержки для изучения разнообразного условного управления. Нейронная архитектура связана с «нулевыми свертками» (сверточными слоями, инициализируемыми с нуля), начиная с нуля и постепенно увеличивая параметры, гарантируя, что никакой вредный шум не сможет повлиять на процесс тонкой настройки.
Использовать стабильную версию DiffusionТестирование различных средств контроля состояния,Такие как край, глубина, сегментация, поза человека и т. д.,Используйте одно или несколько условий,С подсказкой или без。выставкаControlNetобучение в небольших масштабах(<50k)и масштабный(>1m)данные Все стабильно。Обширные результаты показывают,ControlNet может способствовать более широкому внедрению,контролировать распространение изображения Модель。уже Открытый исходный Код: https://github.com/llyasviel/ControlNet
2、MagicFusion: Boosting Text-to-Image Generation Performance by Fusing Diffusion Models
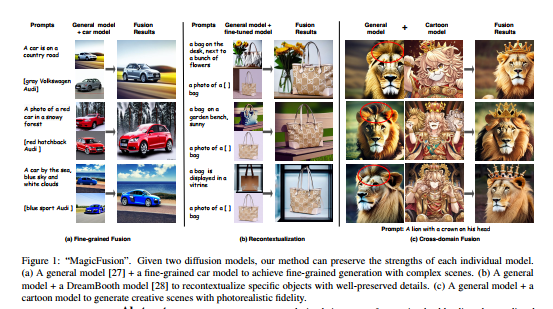
Многие мощные модели распространения с текстовым управлением обучаются на различных наборах данных. Однако было мало исследований по объединению этих моделей для использования их преимуществ. В этом исследовании предлагается простой и эффективный метод, называемый слиянием шумов восприятия (SNB), который может обеспечить более контролируемое создание объединенных диффузионных моделей, управляемых текстом.
В частности, экспериментально показано, что реакция без указания классификатора тесно связана с значимостью сгенерированного изображения. Таким образом, шум прогнозирования двух диффузионных моделей смешивается ориентированным на восприятие способом, чтобы доверять различным моделям в их областях знаний. SNB не требует обучения и может быть выполнен в процессе выборки DDIM. Более того, он может автоматически выравнивать семантику в двух зашумленных пространствах, не требуя дополнительных аннотаций, таких как маски. Большое количество экспериментов доказало замечательную эффективность SNB в различных приложениях. Исходный код уже открыт по адресу: https://github.com/MagicFusion/MagicFusion.github.io.
3、Erasing Concepts from Diffusion Models

Крупномасштабные диффузионные модели могут генерировать нежелательные результаты (например, контент сексуального характера или художественные стили, защищенные авторским правом), и мы исследуем проблему удаления определенных концепций из весов диффузионной модели.
Предлагается метод тонкой настройки, позволяющий стереть определенную визуальную концепцию из предварительно обученной диффузионной модели, просто указав название стиля и используя негативное руководство в качестве учителя. Этот метод сравнивается с предыдущими методами удаления контента сексуального характера, и показано, что его эффективность сопоставима с безопасным скрытым распространением и обучением с цензурой.
Для оценки эффективности удаления художественных стилей были проведены эксперименты, в ходе которых из сети были удалены пять современных художников, а также проведены пользовательские исследования для оценки влияния удаленных стилей на человеческое восприятие. В отличие от предыдущих методов, этот метод навсегда удаляет концепции из модели распространения, а не изменяет выходные данные во время вывода, поэтому даже если у пользователя есть доступ к весам модели, обойти их невозможно. Исходный код уже открыт по адресу: https://github.com/rohitgandikota/erasing.
4、Ablating Concepts in Text-to-Image Diffusion Models

Крупномасштабные модели диффузии текста в изображение генерируют высококачественные изображения с мощными комбинаторными возможностями. Однако эти модели обычно обучаются на больших объемах интернет-данных, часто содержащих материалы, защищенные авторским правом, лицензионные изображения и личные фотографии. Кроме того, было обнаружено, что они копируют стили различных реальных художников или запоминают точные тренировочные образцы. Как удалить эти концепции или изображения, защищенные авторским правом, без переобучения модели?
Для достижения этой цели предлагается эффективный метод исключения концепций в предварительно обученных моделях, то есть предотвращения генерации целевых концепций. Алгоритм учится сопоставлять распределение изображений, созданных целевым стилем, экземпляром или текстовыми репликами, с распределением, соответствующим концепции привязки. Таким образом, модель не может генерировать целевые понятия на основе текстовых условий. Эксперименты показывают, что этот метод может успешно предотвратить появление исключенных концепций, сохраняя при этом тесно связанные концепции в модели.
5、Editing Implicit Assumptions in Text-to-Image Diffusion Models

Модели диффузии текста в изображение часто делают некоторые неявные предположения при создании изображений. Хотя некоторые предположения полезны (например, небо голубое), они могут быть устаревшими, неверными или отражать систематические ошибки, присутствующие в обучающих данных. Следовательно, необходимо контролировать эти предположения, не требуя явного ввода данных пользователем или дорогостоящего переобучения.
Цель этой работы — отредактировать неявное предположение в предварительно обученной диффузионной модели. Предлагаемый метод (редактирование модели «текст-изображение», TIME) получает пару входных данных: расплывчатый намек «источника», для которого модель делает неявное предположение (например, «букет роз»), и «пункт назначения». приглашение, описывающее ту же сцену, но содержащее указанный желаемый атрибут (например, «букет синих роз»). Затем TIME обновляет слои перекрестного внимания модели, поскольку эти слои придают визуальное значение текстовым токенам. Приблизьте исходный сигнал к целевому, отредактировав матрицу проекции в этих слоях. Метод очень эффективен: он изменяет только 2,2% параметров модели менее чем за одну секунду.
Для оценки методов редактирования модели введен TIMED (набор данных TIME), содержащий 147 пар исходных и целевых подсказок из разных доменов. Эксперименты (с использованием стабильной диффузии) показывают, что TIME успешно редактирует модели, хорошо обобщает важные сигналы, невидимые во время редактирования, и оказывает минимальное влияние на нерелевантную генерацию. Исходный код уже открыт по адресу: https://github.com/bahjat-kawar/time-diffusion.
6、Localizing Object-level Shape Variations with Text-to-Image Diffusion Models
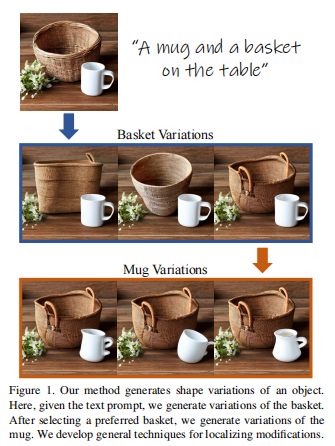
Модели преобразования текста в изображение часто требуют анализа большого количества сгенерированных изображений. Глобальный характер процесса преобразования текста в изображение не позволяет пользователям ограничивать исследование конкретными объектами на изображении.
В этой статье предлагается метод создания коллекции различных изображений объекта конкретной формы, позволяющий осуществлять процесс исследования формы на уровне объекта. Создание правдоподобных вариаций является сложной задачей, поскольку требует контроля над формой создаваемого объекта при сохранении его семантики. При создании вариантов объекта особой проблемой является точное позиционирование операций, применяемых к форме объекта. Введена техника гибридного сигнала, позволяющая получить несколько вариантов формы путем переключения между различными сигналами во время шумоподавления.
Для локализации операций в пространстве изображений предлагаются два метода локализации с использованием слоев самообслуживания и слоев перекрестного внимания. Также показано, что данные методы локализации универсальны и эффективны за пределами диапазона вариаций генерируемых объектов. Обширные результаты и сравнения демонстрируют эффективность метода в создании вариаций объектов, а также конкурентоспособность технологии локализации. Исходный код уже открыт по адресу: https://github.com/orpatashnik/local-prompt-mixing.
7、Harnessing the Spatial-Temporal Attention of Diffusion Models for High-Fidelity Text-to-Image Synthesis

Ключевым ограничением моделей диффузии является низкая точность между сгенерированными изображениями и текстовыми описаниями, такими как отсутствующие объекты, несовпадения атрибутов и неправильное расположение объектов. Ключевой причиной этих несоответствий является неточная обработка текста в измерениях внимания в пространстве и времени. Пространственное измерение определяет, в какой области пикселей должен появиться объект, а временное измерение определяет, как различные уровни детализации добавляются на этапе шумоподавления.
В этой статье предлагается новый алгоритм преобразования текста в изображение, который добавляет явный контроль пространственно-временного перекрестного внимания к диффузионным моделям. Во-первых, предиктор макета используется для прогнозирования пиксельных областей объектов, упомянутых в тексте. Затем реализуется пространственное управление вниманием путем объединения внимания между всем текстовым описанием и локальным описанием этого конкретного объекта в соответствующей области пикселей. Управление временным вниманием дополнительно усиливается за счет изменения комбинированных весов на каждом этапе шумоподавления, а также за счет оптимизации комбинированных весов для обеспечения высокой точности между изображениями и текстом.
Эксперименты показывают, что этот метод имеет более высокую точность создания изображений по сравнению с методами базовой линии, основанными на диффузионной модели. Исходный код уже открыт по адресу: https://github.com/UCSB-NLP-Chang/Diffusion-SpaceTime-Attn.
8、BoxDiff: Text-to-Image Synthesis with Training-Free Box-Constrained Diffusion

Что касается моделей диффузии текста в изображение, исследователи в основном изучали методы генерации изображений с использованием только текстовых сигналов. Хотя в некоторых попытках в качестве условий используются другие модальности, они требуют большого количества парных данных, таких как пары ограничивающего прямоугольника/изображения-маски, и требуют точной настройки обучения. Поскольку получение парных данных требует времени и усилий и ограничивается закрытыми коллекциями, это может стать узким местом для приложений в открытом мире.
Ориентируясь на простейшую форму условий, предоставляемых пользователем, таких как ограничивающие рамки или рисунки, в этой статье предлагается не требующий обучения метод управления объектами и фоном в синтезированных изображениях для соответствия заданным пространственным условиям. В частности, в этой статье разрабатываются три пространственных ограничения, а именно ограничения внутреннего блока, внешнего блока и угловой точки, и легко интегрируются их в этап шумоподавления модели диффузии, не требуя дополнительного обучения и больших объемов аннотированных данных макета. Экспериментальные результаты показывают, что предложенные ограничения могут контролировать, что и где представлять на изображении, сохраняя при этом способность диффузной модели синтезировать высокую точность и разнообразный охват концепций. Исходный код уже открыт по адресу: https://github.com/showlab/BoxDiff.
9、Versatile Diffusion: Text, Images and Variations All in One Diffusion Model

В последние годы прогресс диффузионных моделей достиг впечатляющих результатов во многих задачах генерации, благодаря таким громким работам, как DALL-E2, Imagen и Stable Diffusion. Хотя эта область быстро меняется, последние новые подходы сосредоточены в основном на масштабировании и производительности, а не на емкости, что требует отдельного моделирования для различных задач.
В этой статье существующий однопоточный конвейер диффузии расширяется до многозадачной мультимодальной сети под названием Versatile Diffusion (VD), которая используется для обработки нескольких потоков, таких как преобразование текста в изображение, изображения в текст и т. д., а также для обработки нескольких потоков. потоки в единой модели меняются. Конструкция конвейера VD реализует единую многопоточную диффузионную структуру, содержащую разделяемые и заменяемые модули слоев, что обеспечивает межмодальную универсальность, выходящую за рамки изображений и текста.
Обширные эксперименты показывают, что VD успешно достигает следующего: а) VD превосходит базовые методы и способен решать все основные задачи с конкурентоспособным качеством; б) VD реализует некоторые новые расширения, такие как диссоциация стиля и семантики, слияние двойного и множественного контекста; и т. д.; в) Успех многопотоковой мультимодальной структуры изображений и текста, описанной в этой статье, может вдохновить на дополнительные размышления в общих исследованиях ИИ, основанных на диффузии. Исходный код уже открыт по адресу: https://github.com/SHI-Labs/Versatile-Diffusion.
10、FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model

Модели условной диффузии получили широкое внимание во многих приложениях благодаря своим превосходным генеративным возможностям. Однако многие существующие методы требуют обучения. Это увеличивает стоимость построения модели условной диффузии и делает неудобным перенос при разных условиях. Некоторые существующие методы пытаются преодолеть это ограничение, предлагая решения, не требующие обучения, но большинство из них можно применять только к конкретным классам задач, а не к более общим условиям.
В этой статье предлагается модель условной диффузии без обучения (FreeDoM) для различных условий. В частности, готовые предварительно обученные сети, такие как модели распознавания лиц, используются для создания независимых от времени энергетических функций, которые управляют процессом генерации без обучения. Кроме того, поскольку построение энергетической функции очень гибко и адаптируется к различным условиям, предлагаемый FreeDoM имеет более широкий спектр применения, чем существующие методы, не требующие обучения.
FreeDoM имеет преимущества простоты, эффективности и низкой стоимости. Эксперименты доказали, что FreeDoM эффективен для различных условий и подходит для моделей диффузии в различных областях данных, включая изображения и скрытые коды. Исходный код уже открыт по адресу: https://github.com/vvictoryuki/FreeDoM.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
