ICASSP 2024 | FreeTalker: управляемая речь и генерация текстовых жестов на основе модели диффузии
введение
Движения говорящего имеют решающее значение в различных приложениях, таких как виртуальные агенты, анимация и взаимодействие человека с компьютером. Эти движения можно в основном разделить на две части: соречевые жесты, тесно связанные с содержанием речи, и неспонтанные движения, проявляющиеся во время речи.
Однако существующие работы в основном сосредоточены на глобальном стиле управления жестами совместной речи и не способствуют свободному перемещению говорящих, например, хождению по сцене, указанию или взгляду в определенных направлениях или взаимодействию с аудиторией. В презентациях и выступлениях эти аспекты имеют решающее значение. Насколько нам известно, не было предпринято усилий, направленных на интеграцию этих двух категорий действий. Проблемы возникают из-за различных представлений движения и сложности мультимодального обучения.
в этой статье,Предлагаем новую рамку,Используется для создания спонтанных и неспонтанных действий говорящего. Конкретно,Сначала мы разработали модель, основанную на диффузии.,для генерации действий динамика,Использованы разнородные данные из различных видов спорта. Набор данных. Затем,в процессе рассуждения,Мы использовали начальную загрузку без классификаторов.,для достижения легко управляемого стиля в полученных клипах. также,Мы используем DoubleTake,Используется для создания плавных переходов между клипами и обеспечения плавного смешивания движений. Основной вклад нашей работы включает в себя:
- FreeTalker предложил,Насколько нам известно,Это первый метод, обученный на нескольких наборах данных.,рамка для генерации действий говорящего, которые могут быть как спонтанными, так и не спонтанными.
- Загрузка без классификаторов и DoubleTake представлены в нашей модели на основе диффузии для повышения гибкости и контроля над генерацией жестов.
- Доказано множеством экспериментов.,Наш метод имеет более высокую естественность с точки зрения генерируемых движений динамика.,По качеству действия он превосходит существующие методы.
метод
Обработка данных
Нас ждут разные виды спорта Характеристики данных сохраняются корректно. и Ude и Unifiedgesture В отличие от этого, Удэ использует дискретное кодирование для представления движений человеческого тела, тогда как Unifiedgesture Перенаправление движений человека в гомоморфный граф, состоящий из пяти конечных суставов (голова, руки и ноги), рискует потерять такие важные детали, как плечи и пальцы. Наш метод решает эту проблему и сохраняет детали движения. Сначала мы преобразуем матрицу вращения данных захвата движения (формат BVH) в SMPL-X. Угол оси выражен. Для данных о 3D-позиции мы используем VPoser соответствовать этому SMPL-X выражать. Затем 3D-трансляция корневого сустава соответствующим образом масштабируется, а первоначальная ориентация корректируется. быть согласованными между данными, например Unifiedgesture Такой же. проходить SMPL-X Для прямого расчета модели мы можем получить SMPL-X представляет трехмерное положение. Используем высоту корня、Основная линейная и скорость вращения、вращение суставов、совместная позиция、Скорости суставов и удары стоп представлены как характеристики движения.
Метод диффузии для генерации движения
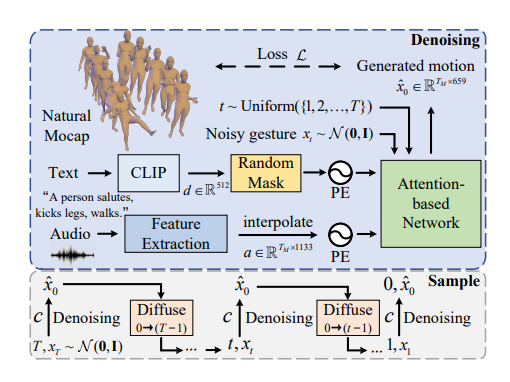
Мы извлекаем Mel-спектр, высоту тона, энергию, WavLM, информацию о началах из исходного аудио и кодируем текст в пространство CLIP. Мы выбираем слой самообслуживания в качестве сети шумоподавления и используем HuberLoss во время обучения:
Генерация длительного действия
В задачах, которые генерируют вневременные последовательности восприятия (например, преобразование текста в движение),Традиционный метод использования положения семени неэффективен.,Поэтому мы позаимствовали метод DoubleTake для генерации движения на большие расстояния.
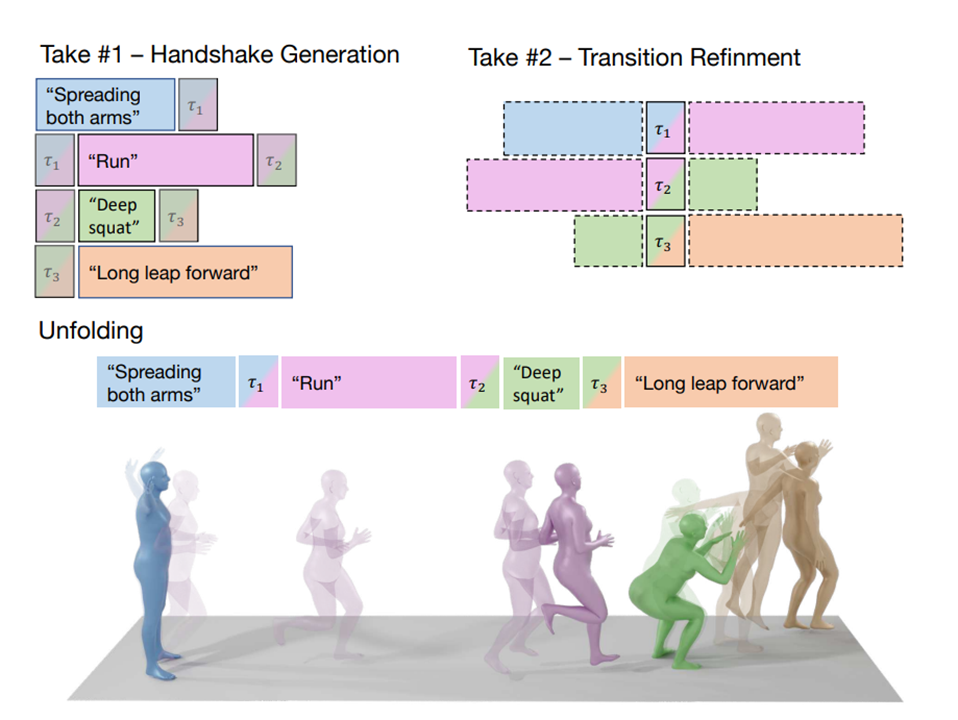
Очень интуитивная идея: генерация длинной последовательности действий может быть разделена на несколько коротких действий, а затем объединена. Поэтому для создания переходов между несколькими сегментами движения она делится на два этапа: первый. Суффикс и Префиксы взвешиваются и усредняются кадр за кадром для первоначального создания прототипа перехода.
но,Создание переходов таким способом явно слишком тонкое.,Артефакты присутствуют,Следовательно, линейно-взвешенный шум необходимо добавить на основе прототипа, а затем удалить шум. Используем маску и для последовательности Mиτ. Маскирование обеспечивает постепенный переход между значениями маски.,Позволяет линейную маскировку длины кадра b между è. Этот процесс работает путем уточнения первоначально сгенерированного движения во время второго кадра каждого шага шумоподавления, чтобы оно соответствовало преобразованию:
здесь,представляет собой уточненный переход последовательности,Будьте оригинальны. наконец,Создавайте длинные движения, разворачивая изысканные последовательности и переходы.,Это приводит к плавному движению.
эксперимент
Набор данных
HumanML3D: для создания текстового движения.
BEAT: для генерации жестов на основе речи.
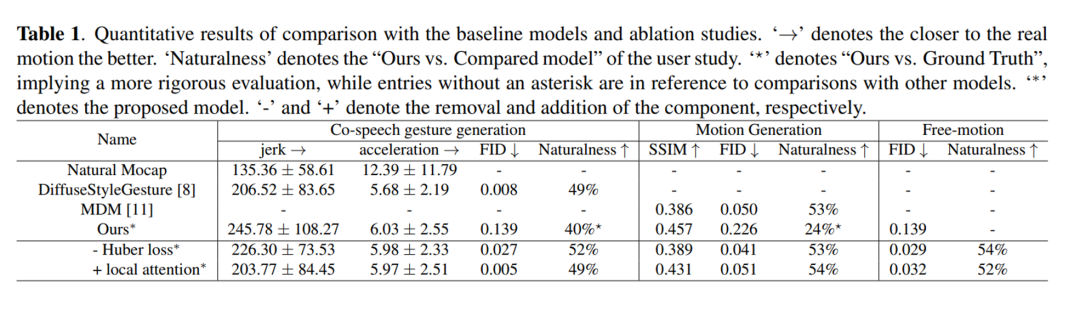
экспериментрезультат

в заключение
в этой статье,Мы предложили FreeTalker,Это простая, но эффектная рамка.,Используется для создания спонтанных и неспонтанных действий говорящего. Использование модели на основе диффузии,Наш метод в Наборах из разных видов спорта Обучение проводится на разнородных данных. Наведение без классификатора и DoubleTake вводятся на этапе вывода для обеспечения естественного, легко контролируемого и дальнего действия. Кроме того, наш метод готовит к будущим масштабным движениям. данные заложили основу для Работы над более сложной Моделью, открыв путь для дальнейших разработок в области генерации движений динамиков и повышения естественности голосовых аватаров в различных приложениях.
Мы намерены и дальше углубляться в расширение нашей Работы на поколение полностью цифровых людей.,Включая движения, мимику и движения губ. Мы также планируем изучить более унифицированный метод цифрового поколения людей.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
