Хранилище данных реального времени: эволюция хранилища данных реального времени 3.0
Хранилище данных реального времени 1.0
Традиционно мы обычно делим обработку данных на автономную обработку данных и обработку данных в реальном времени. Для сценариев обработки в реальном времени мы обычно можем разделить их на две категории. Одна категория, такая как мониторинг сигналов тревоги и сценарии отображения на большом экране, обычно требует секунд или даже миллисекунд. не имеет очень высоких требований к своевременности, обычно допустимый уровень минут, например 10 минут или даже 30 минут.
Для первого типа сценариев данных в реальном времени обычный в отрасли подход является относительно простым и грубым и, как правило, не требует очень тщательной стратификации данных. Данные вычисляются напрямую с помощью Flink или агрегируются, а результаты записываются в MySQL/ES/. HBASE/Druid/Kudu и т. д. напрямую обеспечивают запросы приложений или многомерный анализ. Как показано ниже:
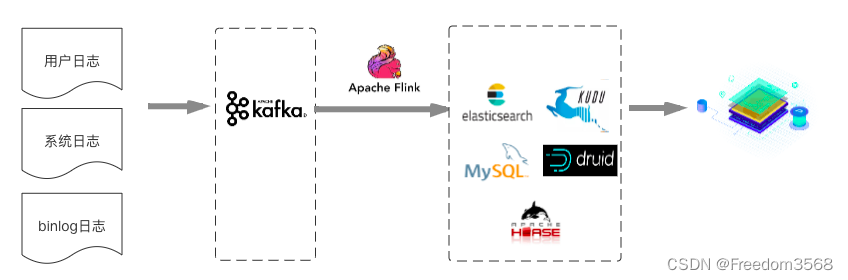
В последнем случае обычным подходом является проектирование в соответствии со структурой хранилища данных. Последний сценарий приложения мы называем «Хранилище». данных в режиме реального время будет в центре внимания этой статьи. Судя по ситуации в отрасли, нынешнее мейнстрим Хранилище данных в режиме реального Архитектура времени в основном основана на Архитектуре Кафки+Флинка (для удобства написания она называется Хранилище). данных реального времени 1.0). Изображение ниже основано на информации «Хранилище», которой поделились крупнейшие компании отрасли. данных в режиме реального Архитектура времени Абстрактная схема:
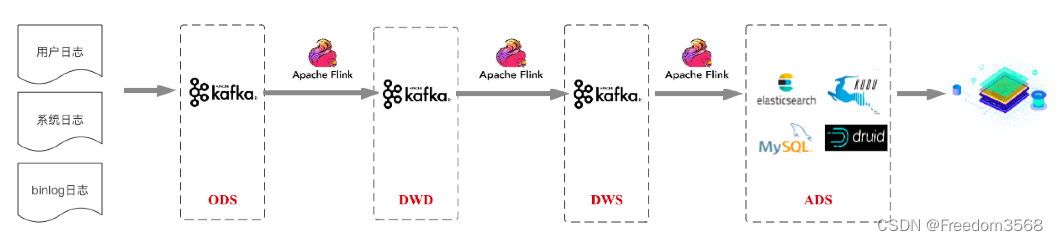
Эта архитектура, как правило, по-прежнему соответствует стандартной иерархической структуре хранилища данных, и различные данные сначала собираются на уровне доступа к данным ODS. Затем посредством очистки, фильтрации и других операций с этими исходными подробными данными завершается объединение аналогичных подробных данных из нескольких источников для формирования уровня детализации данных DWD, ориентированного на бизнес-темы. На этой основе выполняется операция сводки освещения для формирования слоя сводки освещения DWS, который в определенной степени удобен для запроса (Примечание: слой измерения DIM здесь не отображается, и общий выбор — Redis/HBase. Он также не изображен на схеме архитектуры ниже, уровень измерения DIM, описанный здесь). Наконец, с учетом потребностей бизнеса данные дополнительно организуются на уровне приложений данных ADS на основе уровня DWS. Бизнес поддерживает портреты пользователей, отчеты пользователей и другие бизнес-сценарии на основе уровня приложений данных.
Это архитектурное решение на основе Kafka+Flink вполне может удовлетворить бизнес-требования к своевременности хранения данных в режиме реального времени. Обычно задержка может составлять секунды или даже меньше. На основе решения по архитектуре хранилища данных реального времени, показанного на рисунке выше, автор составил общее решение по архитектуре хранилища данных, которое является относительно распространенным в отрасли:
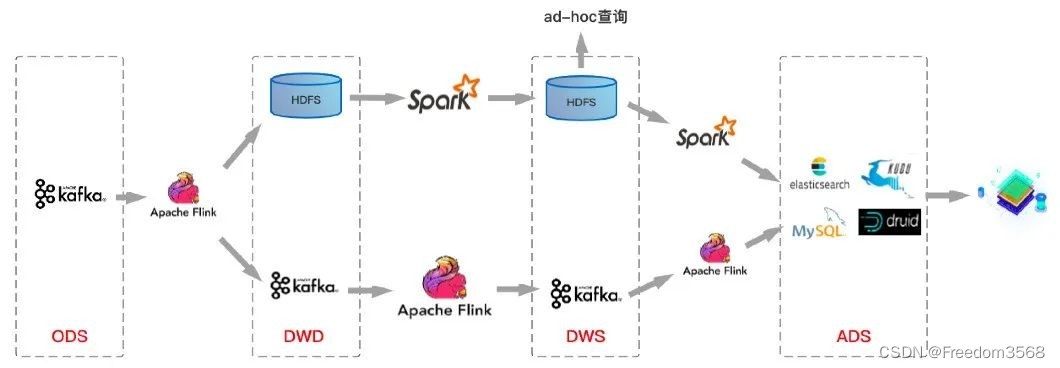
На приведенном выше рисунке верхняя ссылка — это ссылка для потока данных в автономном хранилище данных, а нижняя ссылка — это ссылка для потока данных в хранилище данных в реальном времени. Конечно, реальная ситуация может заключаться в том, что многие компании не строго следуют хранилищу данных. иерархическая структура при построении хранилищ данных реального времени Многоуровневая, немного отличающаяся от рисунка выше.
Однако решение для хранилища данных реального времени на базе Kafka+Flink имеет несколько очевидных недостатков: **(1)Kafka не поддерживает хранение больших объемов данных. **Для бизнес-направлений с огромными объемами данных Kafka обычно может хранить данные только в течение очень короткого периода времени, например, за последнюю неделю или даже за последний день;
**(2)Kafka не может поддерживать эффективные запросы OLAP. **Большинство компаний надеются поддерживать специальные запросы на уровне DWD\DWS, но Kafka не может поддерживать такие потребности очень дружелюбно;
(3) Невозможно повторно использовать уже очень зрелую линию передачи данных, основанную на автономных хранилищах данных.、система управления качеством данных. Необходимо повторно реализовать набор родословных данных.、система управления качеством данных;
(4) Стоимость обслуживания ламбадной архитектуры очень высока.。очевидно,Этот вид Архитектура Внизданные Есть две копии、Схема не унифицирована、 Логика обработки данных не унифицирована, а стоимость обслуживания всей системы хранилища данных очень высока;
(5) Kafka не поддерживает обновление/обновление.。в настоящий моментKafkaПоддерживает толькоappend。В реальных сценарияхDWSСлой агрегации света часто необходимо обновлять.,От уровня детализации DWD до уровня легкой агрегации DWS обычно выполняется определенная агрегация на основе временной детализации и размеров.,Используется для уменьшения объема данных.,Улучшите производительность запросов. Если исходные данные являются данными второго уровня,Окно агрегации — 1 минута.,Возможно, что некоторые отложенные данные необходимо будет обновить после агрегации временных окон, прежде чем потребуется обновить данные. Эту часть требований к обновлению невозможно выполнить с помощью Kafka.
Таким образом, хранилище данных в реальном времени превратилось в текущую архитектуру, которая в определенной степени решила проблему своевременности предоставления данных. Однако я считаю, что с развитием технологий в этой архитектуре все еще существует много проблем. Архитектура хранилища данных в реальном времени на основе Kafka+Flink еще больше улучшит работу Move Forward. Куда это пойдет?
Учитывая вышеизложенные вопросы, давайте поговорим о другой концепции, которая в последние год или два была так же популярна, как хранилище данных в реальном времени: пакетная и потоковая интеграция. Что касается понимания интеграции пакетной и потоковой обработки, автор обнаружил, что существует множество интерпретаций. Например, некоторые руководители отрасли считают, что пакетная и потоковая обработка объединены в один и тот же SQL на уровне разработки, а некоторые руководители считают, что пакетная и потоковая обработка интегрированы. на уровне вычислительного механизма. Может быть интегрирован в один и тот же вычислительный механизм для интеграции пакетных и потоковых операций, например Spark/Spark Structured. Потоковая передача — это вычислительная среда, реализующая пакетную и потоковую интеграцию на уровне вычислительного механизма. В то же время другой вычислительный механизм, Flink, проделал большую работу в области потоковой обработки и получил общее признание в отрасли, но с точки зрения Пакетная обработка Еще есть над чем работать.
Хранилище данных реального времени 2.0
Автор считает, что как унификация использования бизнес-SQL, так и унификация вычислительных механизмов являются аспектами пакетно-потоковой интеграции. Кроме того, существует еще один ключевой аспект интеграции пакетных потоков — унификация на уровне хранилища. В отрасли также есть несколько передовых технологий в этом отношении, например, ставшие популярными в последнее время «Три мушкетера озера данных» — дельта/худи/айсберг, направляющийся в этом направлении. Как только хранилище будет унифицировано, вышеупомянутая Архитектура хранилища данных будет выглядеть следующим образом (с Icebergo нулевым данных как пример единой хранилища), называемой Хранилище. данных реального времени 2.0:
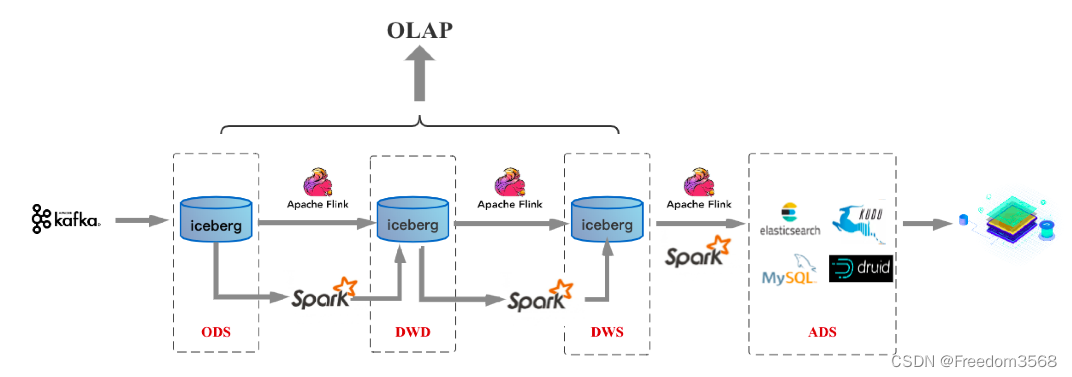
В этой архитектуре, будь то потоковая или пакетная обработка, хранение данных унифицировано в озере данных Iceberg. Так каковы же преимущества объединения хранилища с такой архитектурой? Очевидно, что первые четыре проблемы хранилища данных реального времени архитектуры Kafka+Flink могут быть решены: (1) Это может решить проблему небольшого объема данных, хранящихся в Kafka.。в настоящий моментвсеозеро Основная идея данных — это система управления файлами на базе HDFS, поэтому данные могут быть очень большими.
(2) Данные уровня DW по-прежнему могут поддерживать запросы OLAP.。такой жеозеро Данные реализованы в HDFS и требуют лишь некоторых адаптаций текущего механизма запросов OLAP для выполнения запросов OLAP.
(3) Пакетное и потоковое хранилище основано на хранилище Iceberg/HDFS.,Вполне возможно повторно использовать одну и ту же систему управления качеством крови и данных.
(4) Архитектура Каппа по сравнению с архитектурой Ламбад.,унификация схемы,данные обрабатывают логическое объединение,Пользователям больше не нужно хранить две копии данных.
Некоторые студенты сказали: «Нет, вы сразу решили первые четыре вопроса, а как насчет пятого вопроса?» Да, вопрос 5 будет рассмотрен ниже.
Некоторые студенты скажут, что описанная выше архитектура действительно решает многие проблемы архитектуры Lambad, но эта архитектура выглядит как канал автономной обработки. Как она обеспечивает вывод отчетов в реальном времени? Действительно, приведенная выше схема архитектуры в основном заменяет HDFS в канале автономной обработки с озером данных Iceberg, которое утверждает, что может создать хранилище данных в реальном времени, что звучит запутанно. Ключевым моментом здесь является озеро данных Айсберг. Какая в нем магия?
Чтобы ответить на этот вопрос, автор даст краткое введение в описанную выше архитектуру и саму технологию озера данных (затем будет специальная тема на основе Iceberg, где будет более подробно рассмотрена технология озера данных). На приведенной выше схеме архитектуры есть два канала обработки данных: один — канал передачи данных в реальном времени на основе Flink, а другой — автономный канал передачи данных на основе Spark. Обычно данные обрабатываются непосредственно через ссылку в реальном времени, тогда как автономные ссылки больше используются в нетрадиционных сценариях, таких как коррекция данных. Чтобы такая архитектура стала решением хранилища данных в реальном времени, которое можно реализовать, озеро данных Iceberg должно отвечать следующим требованиям:
(1) Поддержка потоковой записи и добавочного извлечения。Потоковая запись реализована на основеFlinkможет быть достигнуто,Это не что иное, как сокращение интервала между контрольными точками.,Например, 1 минута,Это означает, что файлы, генерируемые каждую минуту, можно записывать в HDFS.,Это потоковое письмо. Это верно,Но здесь есть две проблемы,Первая проблема заключается в том, что существует много маленьких файлов.,Но это не самое главное,Вторая проблема – самая фатальная.,То есть восходящий поток передает в HDFS множество файлов каждую минуту.,Flink для дальнейшего использования не знает, какие файлы отправлены последними.,Таким образом, нижестоящий Flink не знает, какие файлы следует использовать и обрабатывать. Эта проблема является одной из наиболее важных причин, почему автономные хранилища данных не могут работать в режиме реального времени.,Способ использования автономного хранилища данных заключается в том, что восходящий поток завершил импорт всех данных.,Сообщите нижестоящим, что вся эта волна данных была направлена,Вы можете потреблять и обрабатывать его.,В этом случае обработка в реальном времени невозможна.
Озера данных решают эту проблему. Во время обработки канала передачи данных в реальном времени, после поступления файлов, записанных восходящим Flink, файлы данных нисходящего потока могут быть прочитаны последовательно. Акцент здесь делается на последовательном чтении, что означает, что вы не можете прочитать на один файл больше или прочитать на один файл меньше. Сколько файлов было записано восходящим потоком за этот период, будет прочитано нисходящим. Мы называем такое чтение инкрементным извлечением.
(2) Решите проблему слишком большого количества маленьких файлов.。озеро данных реализует интерфейс, связанный с объединением небольших файлов. Верхний движок Spark/Flink может периодически вызывать интерфейс для объединения небольших файлов.
(3) Поддерживает пакетные и потоковые функции Upsert (Delete).。партияUpsert/DeleteФункция в основном используется в автономном режимеданныеисправление。потоковая передачаupsertСценарий был представлен выше.,В основном в сценарии обработки потока, если есть задержка в прибытии после агрегирования времени окна данных, возникнет требование обновления. Такие требования требуют наличия системы хранения, способной поддерживать обновления.,Если автономное хранилище данных обновляется, его необходимо полностью охватить.,Это также одна из ключевых причин, почему автономные хранилища данных не могут работать в режиме реального времени.,озеро данные должны решить эту проблему.
(4) Поддержка относительно полной экосистемы OLAP.。Например, поддержкаHive/Spark/Presto/ImpalaждатьOLAPмеханизм запросов,Обеспечьте эффективную производительность многомерных агрегирующих запросов.
Здесь следует отметить, что некоторые функции Iceberg все еще находятся в стадии разработки. Пожалуйста, продолжайте обращать внимание на то, как Iceberg решает вышеуказанные проблемы на конкретном техническом уровне. В следующей статье это будет описано подробно.
Хранилище данных реального времени 3.0
Согласно обсуждению выше интеграции пакетного и потокового,Если вычислительная машина достигнет унификации пакетной и потоковой,Вы можете добиться унификации SQL, унификации вычислений и унификации хранилища.,А сейчас зайдите в Хранилище. данных реального времени 3.0 эпоха. Для компаний, в которых Spark является основным стеком технологий, Хранилище данных реального времени Появление версии 2.0 означает появление версии 3.0, поскольку Spark уже интегрировал пакетную и потоковую обработку на уровне вычислительного механизма. На базе Спарка/озеро Архитектура данных версии 3.0 показана ниже:
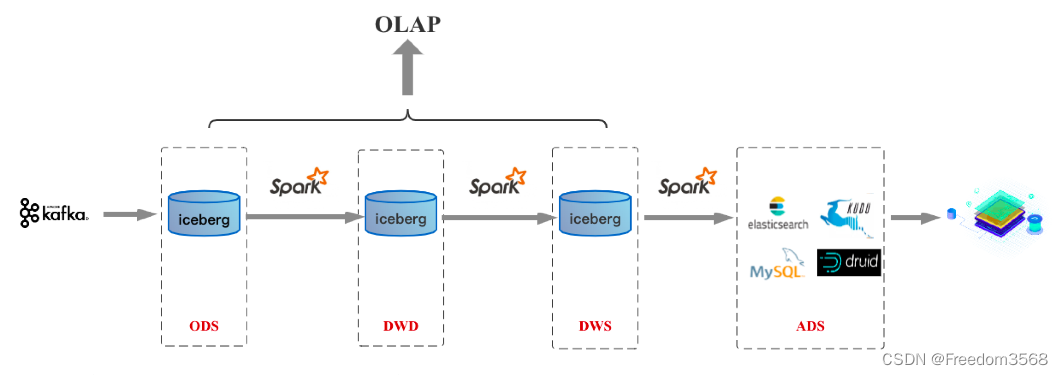
Если в будущем Flink достигнет определенной зрелости в области пакетной обработки, архитектура 3.0, основанная на Flink/озере данных, будет такой, как показано ниже:
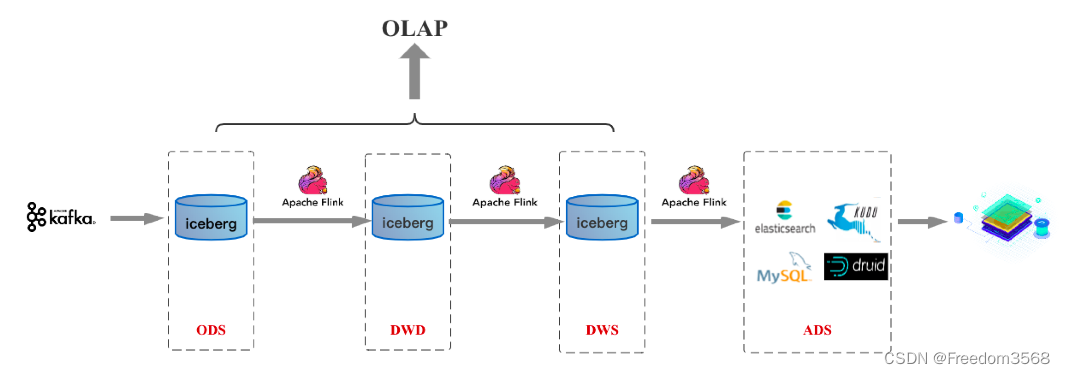
Подвести итог
То, что представлено выше, — это, по мнению автора, возможный путь развития хранилищ данных в ближайшие несколько лет. Для отрасли в настоящее время Хранилище данных в режиме реального Прогноз развития времени, лично я считаю, что большинство компаний отрасли по-прежнему собираются в Хранилище. данных реального времени Архитектура 1.0 находится на подъеме и в ближайшие 1-2 года, как и озеро; Зрелость технологии данных, Хранилище данных реального времени Архитектура 2.0 станет выбором все большего числа компаний. Фактически, после эпохи 2.0 спрос в режиме реального времени на отчеты, которые больше всего беспокоят студентов-бизнесменов, и хранилища данных, которые больше всего беспокоят студентов с большой платформы данных. решается по мере развития вычислительной машины, Хранилище; данных реального времени 3.0возможно и Хранилище данных реального времени 2.0 набирает обороты или немного отстает от некоторых по популярности.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
