Хранилище данных, озеро данных и интеграция хранилища данных: обзор и сравнение
Поскольку все больше компаний полагаются на данные для принятия важных бизнес-решений, улучшения предложений продуктов и лучшего обслуживания клиентов, компании собирают больше данных, чем когда-либо прежде. По оценкам исследования Domo, в 2017 году ежедневно генерировалось 2,5 экзабайта данных, а к 2025 году это число увеличится до 463 эксабайт. Но какая польза от данных, если компании не могут быстро их использовать? Тема оптимального хранения данных для нужд анализа данных уже давно обсуждается.
Современные компании принимают, хранят, преобразуют и используют больше данных для принятия большего количества решений, чем когда-либо прежде. Между тем, 81% ИТ-руководителей утверждают, что их высшее руководство не требовало увеличения расходов или сокращения затрат на облачные технологии.
Группам обработки данных необходимо сбалансировать потребность в надежной и мощной платформе данных с растущим контролем затрат. Вот почему команды должны выбрать правильную архитектуру для уровня хранения своего стека данных.
Однако варианты хранения данных быстро развиваются. Хранилища данных и озера данных — наиболее широко используемые архитектуры хранения больших данных. А как насчет использования интегрированного озера и хранилища данных? Различные поставщики, предлагающие хранилища данных, озера данных, а теперь и интегрированные озера, предлагают группам данных свои уникальные сильные и слабые стороны.
В зависимости от потребностей вашей компании понимание различных технологий хранения больших данных может помочь разработать надежные конвейеры хранения данных для рабочих нагрузок бизнес-аналитики (BI), анализа данных и машинного обучения (ML).
1. Что такое хранилище данных?
Хранилище данных — это интегрированная единица хранения и центр обработки данных, единое хранилище данных, используемое для хранения больших объемов информации из нескольких источников внутри организации. Хранилище данных представляет собой единый источник «правдивых данных» в организации и служит основным компонентом отчетности и бизнес-анализа. Команды, использующие хранилища данных, часто используют запросы SQL для анализа вариантов использования.
Обычно хранилища данных лучше всего работают со структурированными данными, определенными определенной схемой, которая организует данные в аккуратные, хорошо размеченные таблицы. Та же структура помогает поддерживать качество данных и упрощает взаимодействие пользователей с данными и их понимание.
Хранилища данных хранят исторические данные путем объединения наборов реляционных данных из нескольких источников, включая данные приложений, бизнеса и транзакций. Хранилище данных извлекает данные из нескольких источников, преобразует и очищает данные, а затем загружает их в систему хранения как единый источник достоверных данных. Организации инвестируют в хранилища данных из-за их способности быстро предоставлять бизнес-аналитику по всей организации.
Хранилища данных позволяют бизнес-аналитикам, инженерам по работе с данными и лицам, принимающим решения, получать доступ к данным через инструменты BI, клиенты SQL и другие менее продвинутые (т. е. не связанные с наукой о данных) аналитические приложения.
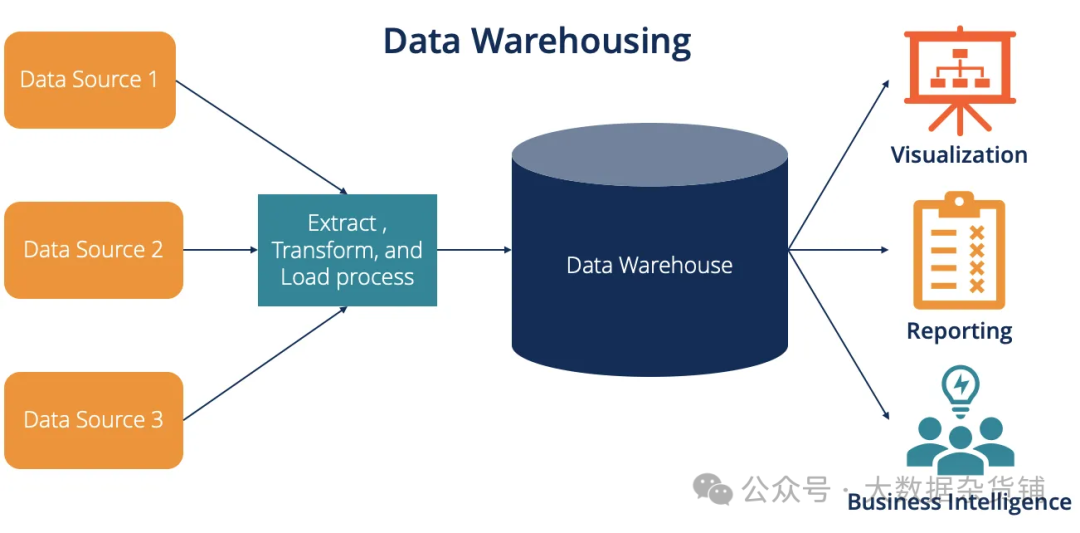
Хранилище данных. Источник изображения: https://corporatefinanceinstitute.com/
1.1 Преимущества хранилища данных
Хранилище данных после внедрения принесет организации огромные преимущества. Некоторые преимущества включают в себя:
Улучшить стандартизацию данных、качествоипоследовательность:Ткани образуются из разных источников.данные,Включая данные о продажах, пользователях и транзакциях. Хранилище данных объединяет данные предприятий для единообразия в стандартизированном формате.,Может использоваться как единый источник данных.,Дайте организациям уверенность в том, что они смогут полагаться на данные для удовлетворения бизнес-потребностей.
по расширению бизнес-аналитики:данные Склады формируют коллекцию, которая на практике обычно автоматическииз Много оригинальногоданныеипоставлятьмнениеиз Рекомендуемыеданныемеждуиззазор。они действуют как организацииизданныехранилищепозвоночник,Дайте им возможность ответить на сложные вопросы об их данных.,И используйте ответы для принятия обоснованных бизнес-решений.
Улучшите аналитику данных и рабочие нагрузки бизнес-аналитики, а также возможности и скорость:данные Склады ускоряют подготовкуианализироватьданныенеобходимыйизвремя。потому чтоданныескладизданные Последовательный и точный,Поэтому их можно легко подключить к инструментам анализа данных и бизнес-аналитики. Хранилище данных также сокращает время, необходимое для сбора данных.,и дать возможность командам использовать данные для отчетности, создания информационных панелей и других аналитических нужд.
Улучшите общий процесс принятия решений:данныескладпроходитьпоставлятьтекущийиисторияданныеизодинокийхранилищебиблиотеки для улучшения процесса принятия решений。Лица, принимающие решения, могут конвертироватьданныескладсерединаизданныечтобы быть точнымизмнениеоценить риск、Понимать потребности клиентов и улучшать продукты и услуги.
Например, Walgreens перенесла свои данные управления запасами в Azure Synapse, что позволило аналитикам цепочки поставок запрашивать данные и создавать визуализации с помощью таких инструментов, как Microsoft Power BI. Переход к облачному хранилищу данных также сокращает время на понимание: отчеты за предыдущий день теперь доступны в начале рабочего дня, а не через несколько часов.
1.2 Недостатки хранилища данных
Хранилища данных предоставляют предприятиям высокопроизводительную и масштабируемую аналитику. Однако они также создают определенные проблемы, в том числе:
Недостаточная гибкость данных:хотяданныескладсуществоватьструктурированныйданныехорошая производительность,Но они могут столкнуться с трудностями при обработке полуструктурированных и неструктурированных форматов данных (таких как анализ журналов, потоковая передача и данные социальных сетей). Это затрудняет рекомендации по использованию хранилища данных для машинного обучения и искусственного интеллекта.
Высокие затраты на внедрение и обслуживание:данныескладизосуществлятьи Затраты на техническое обслуживание могут быть высокими。Cooladata В этой статье предполагается, что существуют 1 TB Место для хранения и ежемесячно 100,000 Годовая стоимость внутреннего хранилища данных для запросов составляет 468,000 Доллар. Кроме того, хранилище данных обычно не является статичным; оно может устареть и потребовать регулярного обслуживания, которое может быть дорогостоящим.
Хранилище данных — это полностью управляемое решение, которое легко создавать и эксплуатировать. Склад может быть универсальным решением, в котором компоненты метаданных, хранилища и вычислений поступают из одного и того же места и управляются одним поставщиком. В число известных игроков в области хранилищ данных входят Amazon Redshift, Google BigQuery и Snowflake.
Для платформ данных, где основным вариантом использования является анализ данных и составление отчетов, хранилище данных часто является самым разумным выбором. Благодаря предварительно созданным функциям и мощной поддержке SQL хранилище данных создано специально для предоставления быстрых и эффективных запросов командам аналитиков данных, работающим в основном со структурированными данными.
2. Что такое озеро данных?
Озеро данных — это централизованное, очень гибкое хранилище, в котором хранятся большие объемы структурированных и неструктурированных данных в необработанной, необработанной и неформатированной форме, часто используемое в сценариях потоковой передачи, машинного обучения или обработки данных. По сравнению с хранилищами данных, в которых хранятся «очищенные» реляционные данные, озера данных хранят данные, используя плоскую архитектуру и необработанную форму объектного хранилища. Озера данных являются гибкими, надежными и экономически эффективными, что позволяет организациям получать расширенную информацию из неструктурированных данных, в отличие от хранилищ данных, которые обрабатывают данные в этом формате.
Озера данных могут быть построены на основе различных технологий, таких как Hadoop, NoSQL, Amazon Simple Storage Service, реляционных баз данных или различных комбинаций и различных форматов (таких как Excel, CSV, текст, журнал, Apache Parquet, Apache Arrow, Apache Avro). ).
ХотяПоставщик озера данныхпродолжайте появляться,по предоставлению дополнительных услуг хостинга (Например Databricks из Delta Lake、Dremio даже Снежинка), но традиционно данные озера создаются путем комбинирования различных техник. Для организаций метаданных они часто используют Hive、Amazon Glue или Блоки данных. Доступно хранилище S3、Google Cloud Storage、Microsoft Azure Blob Storage или Hadoop HDFS. Вычислительные задачи могут быть в Apache Pig、Hive、Presto или Spark беги дальше. Обычно в таких средах вы обнаружите JSON、Apache Parquet и Apache Avro и другие форматы данных.
Data Lake дает командам разработчиков данных свободу выбора правильных вычислительных технологий для хранения данных, хранилищ, исходя из их уникальных потребностей. поэтому,Расширяйте по мере необходимости,Ваша команда может сделать это путем интеграции новых элементов стека данных.
Данные озера также обычно отделяют вычисления хранилища.,Это экономит затраты,Также облегчает потоковую передачу и запросы в реальном времени. Они также поощряют распределенные вычисления для повышения производительности запросов и параллельной обработки.
Гибкость – это больше, чем просто технологический выбор из пластичности. Data Lake может обрабатывать необработанные данные или легкие структурированные данные.,команда изданных дает ценные преимущества при работе с различными формами изданных. Data Lake может поддерживать сложные модели программирования, отличные от SQL, например Apache Hadoop, Apache Spark, PySpark и другие платформы. Это особенно полезно для ученых и инженеров, работающих с данными.,Потому что это позволяет лучше контролировать свои расчеты.
Традиционно Data Lake идеально подходит для групп ученых, которым необходимо выполнять сложные операции машинного обучения с большими объемами неструктурированных данных — часто для тех, у кого есть штатные инженеры по данным для поддержки своей индивидуальной платформы из команд. Но удобные для пользователя решения хостинга делают этот подход менее зависимым от инженеров по работе с данными, создающих функциональность с нуля.
В озере данные,Вместо этого шаблон «данные» не определяется при захвате данных;,данныеизвлеченный、Преобразование загрузки (ELT) для целей анализа. Озеро данных позволяет использовать устройства из Интернета вещей、Социальные сети и потоковая передача данных различных типов данных из инструментов машинного обучения и прогнозного анализа.
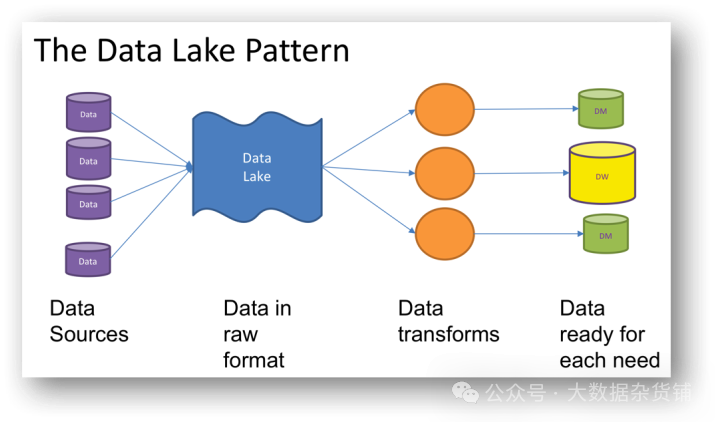
Модель озера данных. Источник изображения: datakitchen.io
2.1 данныеозероизвыгода
Озеро данных может хранить структурированные и неструктурированные данные.,Поэтому они имеют ряд преимуществ,Например:
Интеграция данных:данныеозеро Можетхранилищеструктурированныйи Нетструктурированныйданные,Нет необходимости иметь два формата данных в разных средах. Они предоставляют одно центральное хранилище для хранения всех типов данных организаций.
Гибкость данных:данныеозероиз Существенным преимуществом является гибкость.;Вы можете использовать любой форматилисерединахранилищеданные,Нет необходимости в предопределенной схеме. Позволяет данным сохранять исходный формат,Можно проанализировать больше данных и удовлетворить будущие варианты использования.
Экономия средств:данныеозерочем традиционныйданныескладдешевле;они предназначеныдляхранилищепо низкой ценеиз На коммерческом оборудовании,Например хранилище объектов,Обычно для каждого GB хранилищеиз Оптимизация с меньшими затратами. Например, Амазон S3 Стандартные хранилища объектов по невероятным ценам, без 50 ТБ/месяц GB для 0.023 Доллар.
Поддерживает различные варианты использования данных в научных целях и машинном обучении:данныеозеросерединаизданныеоткрытьизисходный форматхранилище,Это упрощает применение различных алгоритмов машинного и глубокого обучения для обработки данных и получения значимой информации.
2.2 данныеозероизнедостаток
Хотя озера данных дают много преимуществ, они также создают проблемы:
Бизнес-аналитика и данные аналитики. Случаи использования низкой производительности:Если не управлять должным образом,Данные озера могут запутаться,Это затрудняет их подключение к инструментам бизнес-аналитики и аналитики. также,Отсутствие последовательности изданных структур и КИСЛОТА (атомарность、последовательность、Изоляцияиупорство)дела Поддержка может привести к сообщениюианализировать Низкая производительность запросов, когда этого требует вариант использования.。
Недостаточная надежность и безопасность данных:данныеозеронедостатокданныепоследовательность,Трудно гарантировать надежность и безопасность данных. Поскольку озеро данных может поддерживать все форматы данных.,Поэтому реализация соответствующих политик безопасности и управления для удовлетворения чувствительных типов безопасности может оказаться сложной задачей.
3. Что такое интегрированное озеро и склад? комплексный подход
Lakehouseдаданныеозероиданныескладизкомбинация(Может быть много других мнений),Это новый тип архитектуры,Объединение функциональности хранилища данных и озера данных.,Сочетание традиционных методов анализа данных с расширенными функциями, такими как возможности машинного обучения. Библиотека озера данных для всех данных (структурированных, полуструктурированных и неструктурированных) в виде единой библиотеки хранилища.,В то же время добиться первоклассногоизмашинное обучение、Возможности бизнес-аналитики и потоковой обработки. Лейкхаус Он имеет открытую структуру управления, которая сочетает в себе гибкость, экономичность и масштаб. Как и данные Lake, он также имеет Формат. таблицы озера данных(Delta Lake、Apache Iceberg и Apache Hudi) обеспечивает изданные библиотечные функции. По сравнению с данными Lake, Lakehouse С дополнительными изданными управлениями. Он включает в себя структуру кластерных вычислений и SQL Механизм запросов. Более многофункциональный из Lakehouse Также поддерживает каталог данных и самые передовые возможности компоновки.
Данные Lake Warehouse Integrated возник как облачное хранилище, благодаря чему поставщики начали добавлять функции, обычно связанные с озерами, например Redshift Spectrum и Delta Lake Видел на других платформах. Вместо этого озеро данных начало включать в себя аналогичные хранилища функций, например. SQL Определение функции и шаблона.
Уникальная функция озера и склада в одном здании все больше стирает границы между двумя структурами. Престо и Spark Технология обеспечивает высокую производительность SQL,На озере данных обеспечивается почти интерактивная скорость. Это нововведение, созданное Lake Direct Service Analysis and Explore, открывает новые возможности.,Нет необходимости агрегировать в традиционное хранилище данных.
Parquet Формат файла для данных таблицы Lake имеет более строгую структуру и использует столбчатый формат для повышения эффективности запросов. для дальнейшего сокращения разрыва, Дельта Lake и Apache Hudi Такие технологии, как обработка транзакций записи/чтения, повышают надежность. Это приближает их к традиционной технологии библиотеки данных, присущей драгоценным Свойства ACID (атомарность, согласованность, изоляция, долговечность).
Склад озера обычно начинается с озера, которое содержит все типы данных и данные, затем данные преобразуются в формат forFormat; таблицы озера данных (проданное озеро обеспечивает надежность уровня хранилища с открытым исходным кодом). Дельта Lake/Hudi/Iceberg Поддержка данных традиционного хранилища данных озера ACID процесс транзакции.
по сути,Hucang Integration добилась большого прогресса в объединении преимуществ двух областей.,для работы с разнообразными данными. Предприятия предлагают интересные и осуществимые альтернативы.
3.1 Краткая история озера данных и его эволюция:
Hadoop & Hive:использовать MapReduce Формат поддержки данных Lake Watch первого поколения. SQL выражение.
AWS S3:Простота нового поколенияданныеозерохранилище。Работы по техническому обслуживанию значительно сокращаются,И имеет отличный интерфейс API программирования.
Формат файла озера данных:Доступно для облакаиз Формат файла,ориентированный на столбцы、Хорошо сжат и оптимизирован для аналитических рабочих нагрузок. Например Апач Паркет、ORC и Apache Avro Формат.
Формат таблицы озера данных:Delta Lake、Apache Iceberg и Hudi, со зрелыми функциями библиотеки данных, подобными зрелым.
Уровень хранения/хранилище объектов (AWS S3、Azure Blob Storage、Google Cloud Storage) Начиная с уровня хранения, у нас есть данные от трех основных поставщиков облачных услуг. AWS S3、Azure Blob Storage и Google Cloud Storage из Объектхранилище службы. Интернет Пользовательский интерфейс прост в использовании, его функциональность очень проста, на самом деле эти объекты хранилища могут очень хорошо работать с хранилищем распределенных файлов, они также легко настраиваются и имеют встроенные функции безопасности и надежности. для Hadoop из преемников, они идеально подходят для облака неструктурированных и полуструктурированных данных, AWS S3 является стандартом де-факто для загрузки файлов любого формата в облако.
3.2 Формат файла озера данных (Apache Parquet、Avro、ORC)
Формат файла озера данные более ориентированы на столбцы и используют дополнительные функции для сжатия больших файлов. Здесь основные игроки Apache Parquet、Apache Avro и Apache Стрелка. Это физическое хранилище, фактические файлы распределены по слоям хранилища из разных сегментов хранилища. Формат файла озера данныхполезныйхранилищеданные,Делитесь данными и обменивайтесь ими между системами и платформами обработки. Эти форматы файлов имеют дополнительные функции.,Например, возможности разделения и эволюция модели.
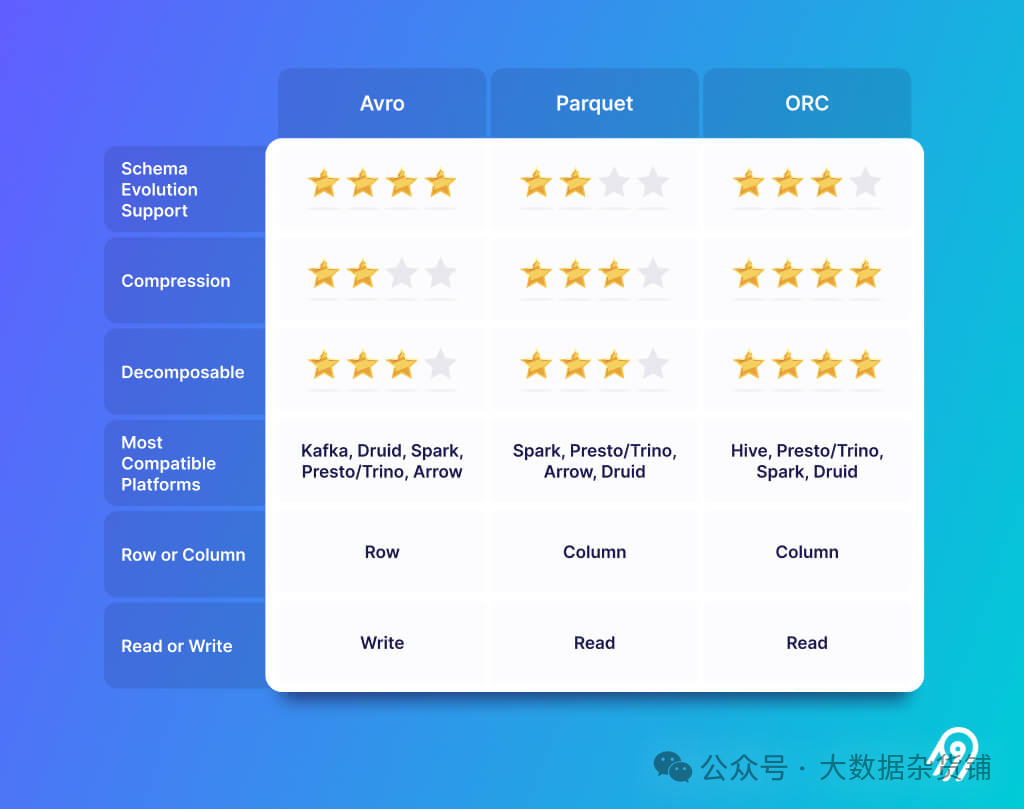
При выборе формата файла данных Apache Parquet кажется более надежным. Это также приятно, потому что для имеет сложный язык описания шаблонов для описания структур данных и поддерживает эволюцию схемы.
Schema Evolution Не слишком важно, потому что для будет в следующей главе из Формат. таблицы озера данные также поддерживают это.
3.3 Формат таблицы озера данных
Формат таблицы озера Данные очень привлекательны, потому что они представляют собой озеро данных и зданную библиотеку. То же, что и таблица, своего рода Формат. таблицы озера данные объединяют распределенные файлы в таблицу, которой сложно управлять. Вы можете думать об этом как о слое абстракции между физическими файлами и их структурой, образующей файл. Представьте себе, что вы вставляете сотни файлов одновременно. Это один из вышеупомянутых форматов с открытым исходным кодом. файла озера данные, может оптимизировать столбцы хранилища и сильно сжимать, Формат таблицы озера data позволяет эффективно запрашивать данные непосредственно из озера данных без необходимости преобразования. Формат таблицы озера данныхда Формат файла озера движок данных. Эти форматы файлов хорошо сжимают большие файлы и возвращают их для аналитических запросов, ориентированных на столбцы, но им не хватает дополнительных функций, таких как ACID Данные о транзакциях и парных отношениях, которые знает каждый в библиотеке, и стандарты. ANSI SQL из поддержки. С помощью Формата таблицы озера данныхи его решения с открытым исходным кодом,Мы можем получить эти основные функции, которые нам нужны,и получить больше,Как показано в следующей главе.
вопрос:Использование формата таблицы озера данные подумайте прежде чем
Какой формат имеет наиболее продвинутые и стабильные функции, которые мне нужны?
Какой формат позволяет мне использовать SQL легкий доступ ко мнеизданные?
Какой формат имеет силу и хорошую поддержку сообщества?
Какой формат является самым мощным инструментом контроля версий?
3.4 Формат таблицы озера данныхиз Функции
Как поделиться из Форматом, используя все три важных формата таблицы озера Функция данных добавляет функцию библиотеки данных в С3. Кроме того, эта функция помогает следить GDPR Политики, отслеживание и аудит, а также запросы на удаление изудалить. Для чего нужны все эти функции? Представьте, что вам нужно поместить анализ хранилища данных в S3 начальствоиз parquet в файле. Вам необходимо кластеризовать все файлы, записывать шаблоны, читать и обновлять все файлы одновременно, находить метод резервного копирования и отката на случай ошибки, писать моделируемые операторы обновления и удаления, тяжелые функции и т. д. Вот для чего появятся эти Формат таблицы озера данные, потому что они нужны всем и был создан стандарт.
3.4.1 [DML и SQL Поддержка: выбрать, вставить, обновить, вставить, удалить] {.underline}
Слияние и обновление непосредственно распределенных файлов иудалить. Помимо SQL, некоторые также используют Scala/Java и Python API.
3.4.2 [Обратная совместимость Schema Evolution и Enforcement]{.underline}
Автоматическая эволюция шаблонов [23] — Формат таблицы озера Ключевая особенность данных – изменение формата из-за необходимости – до сих пор остается проблемой в работе инженеров данных. Схема Evolution значит ничего не сломавдажерасширить определенные типыиз Добавьте новый столбец на всякий случай,даже может переименовывать или изменять порядок столбцов,Хотя это может нарушить обратную совместимость. Но мы можем изменить лист,формат лист отвечает за его переключение на все распространяемые файлы,Самое главное, что нет необходимости перезаписывать таблицу или файл базы.
3.4.3 [ACID Транзакция, откат, управление параллелизмом]{.underline}
ACID Транзакция [24] гарантирует, что все изменения будут успешно зафиксированы и откачены. Убедитесь, что вы никогда не окажетесь в противоречивом состоянии. Существуют различные элементы управления параллелизмом, например обеспечение согласованности между чтением и записью. Любой вид Формата таблицы озера data здесь имеет другие реализации и функции.
3.4.4 путешествие во времени,сделабревноиоткатизаудитистория]{.underline}
Со временем Формат таблицы озера Данные будут версионированы в хранилище данных в озере данных из данных. Вы можете получить доступ к любой исторической версии данных, упростить управление данными с помощью простого аудита, откатить данные в случае случайных ошибок записи или удаления, а также воспроизвести эксперименты и отчеты. Путешествие во времени поддерживает воспроизводимые запросы и может запрашивать две разные версии одновременно. Все версии используют функцию перемещения во времени для снимков, что упрощает реализацию сложных методов, таких как измерения градиента (тип 2)[25]. даже можно изменить как обычно, используя захват данных (CDC)[26] Также извлеките изменения. Журнал транзакций [27] представляет собой упорядоченную запись каждой транзакции с момента ее создания. Журнал транзакций — это общий компонент, используемый многими функциями, упомянутыми выше, включая ACID Транзакционные, расширяемые обработки и путешествия во времени. Например, Дельта Lake Придумай имя для _delta_log из папки [28]. Масштабируемая обработка данных: эти таблицы обрабатывают большое количество файлов и их метаданных в любом масштабе посредством автоматической установки контрольных точек и агрегирования.
3.4.5 [Раздел]{.подчеркивание}
Разделение и эволюция разделения[29] иметь дело сдляв таблицеиз Значение раздела генерации строкиз Громоздко и подвержено ошибкамиз Задача,И автоматически пропускать ненужные разделы и файлы. Быстрый запрос без дополнительных фильтров,Макет листа можно обновлять по мере изменения данных.
3.4.6 [Регулировка размера файла, данные Clustering со сжатием]{.underline}
Можно найти в Delta Lake используется в OPTIMIZE[30] сжимает данные и передает VACUUM[31] Установите дату хранения, чтобы удалить старые версии (другие форматы). таблицы озера данных Имеют схожие функции)。Поддержка из коробкиданныесжатие,Вы можете выбрать различные стратегии переписывания,Например, группировка и сортировка.,для оптимизации макета и размера файла. Оптимизация особенно эффективна при решении проблем с небольшими файлами.,Со временем вы будете поглощать небольшие файлы,Но запрос тысяч небольших файлов выполняется медленно.,Оптимизация может повторно фрагментировать файлы на файлы большего размера.,Это повышает производительность во многих отношениях.
3.4.7 [Унифицированная пакетная и потоковая обработка] {.underline}
Унифицированные средства пакетной обработки и потоковой передачи Lambda[32] Архитектура устарела. В архитектуре данных нет необходимости различать пакетную и потоковую передачу — они оба получают одну и ту же таблицу, менее сложную и быструю. Неважно, читаете ли вы из потока или из пакета. Готов к использованию прямо из коробки MERGE Оператор подходит для изменений, применяемых к распределенным файлам и ситуациям потоковой передачи. Этот формат таблицы озера данные поддерживают один API и целевой приемник. Можно найти в Beyond Lambda: Introducing Delta Architecture[33] Или Некоторые примеры кода из [34] хорошо объяснены.
3.4.8 [Обмен данными]{.underline}
Уменьшите дублирование данных. Новая интересная функция — совместное использование данных. существовать Delta В мире его называют для Delta Sharing[35]。Snowflake объявили, что они также будут в Iceberg Эта функциональность доступна в таблицах. Насколько я понимаю, это Databricks и Snowflake Эксклюзивные функции в Китае. Хотя используется для безопасного обмена данными с открытым исходным кодом. Delta Протоколы совместного использования [36] упрощают обмен данными с другими организациями, независимо от того, какую вычислительную платформу они используют.
3.4.9 [Изменить поток данных (CDF)]{.underline}
Изменить поток данных (CDF)[37] Функция позволяет таблице отслеживать изменения на уровне строк между версиями таблицы. Если этот параметр включен, среда выполнения регистрирует все «события изменений», записанные в таблицу. CDF включать ХОРОШОданныеи Юаньданные,инструктироватьда Без вставки、удалитьили Обновленное обозначениеиз ХОРОШО。
3.5 [Формат таблицы озера данных(Delta、Iceberg、Hudi)]{.underline}
Теперь у нас есть Формат с открытым исходным кодом. таблицы озера Наиболее важные особенности данных. Давайте взглянем на три наиболее выдающихся продукта, которые упоминались несколько раз: Дельта Lake、Apache Iceberg и Apache Hudi。
3.5.1 Delta Lake
Delta Lake — проект с открытым исходным кодом, Можно найти вданные Здание Lakehouse on the Lake архитектура. Дельта Lake поставлять ACID Транзакции, масштабируемые за счет обработки данных элементов и на существующих озерах данных (например, S3、ADLS、GCS и Унифицированная потоковая передача и пакетная обработка в HDFS).
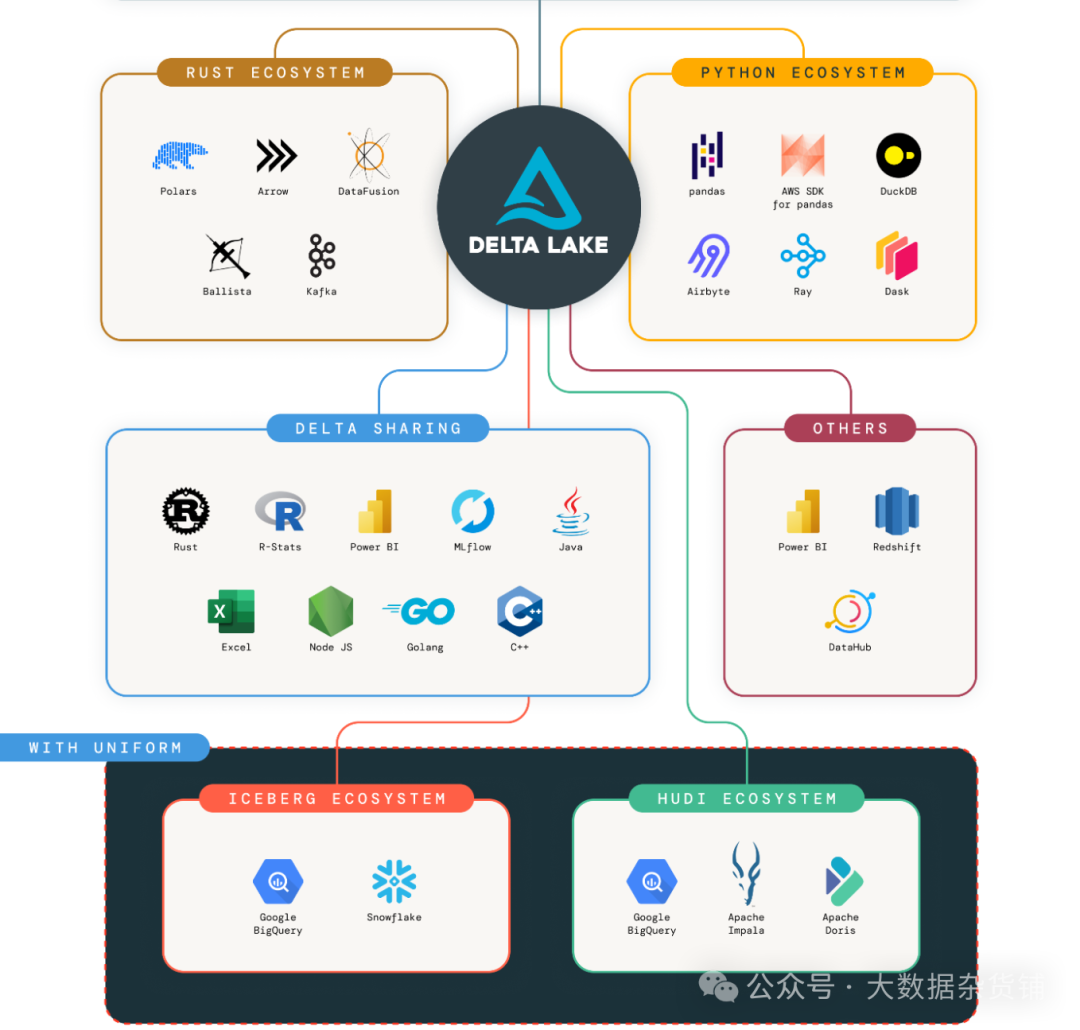
В частности, Дельта. Lake поставлять:
- Spark начальствоиз ACID дела:Сериализуемыйиз Уровни изоляции гарантируют, что читатели никогда не увидят несоответствий.изданные。
- Масштабируемые изданные обработки: эксплойт Spark Распределенная вычислительная мощность легко обрабатывает файлы, содержащие миллиарды файлов. PB Таблица уровней всех элементов данных.
- Объединение потоковой и пакетной обработки: Delta Lake серединаизповерхностьтеперь этодапартияиметь дело споверхность,сновадапоток Источникиполучатель。потокданныепроглотить、Заполнение истории пакетов、Интерактивные запросы доступны «из коробки».
- Применение схемы: автоматическая обработка изменений схемы, чтобы предотвратить вставку неверных записей во время приема.
- Путешествие во времени: контроль версий данных поддерживает откат, полный исторический контрольный журнал и воспроизводимые эксперименты по машинному обучению.
- обновить вставкуиудалить:Поддержка слияния、возобновлятьиудалитьдействовать,для поддержки сложных случаев использования,Например, захват изменения данных, операции медленного изменения измерения (SCD), потоковые вставки обновлений и т. д.
3.5.2 Apache Iceberg
Apache Iceberg Подходит ли метод для анализа большого набора данных в формате открытой таблицы. Iceberg Используйте высокопроизводительные форматы таблиц, чтобы Spark、Trino、PrestoDB、Flink、Hive и Impala Подождите, пока механизм вычислений добавит таблицу, которая работает так же, как SQL Таблица аналогичная.
пользовательский опыт
Айсберг избегает неприятных сюрпризов. Работы по архитектурной эволюции,Не случайносередина Отменаудалитьданные。Пользователи получают быстрые запросы, не зная о разделах.。
- Добавлена поддержка эволюции схемы.、удалить、возобновлятьили Переименовать,и никаких побочных эффектов
- Скрытые разделы предотвращают ошибки пользователя, приводящие к молчаливым и ошибочным результатам и чрезвычайно медленным запросам.
- Эволюция макета раздела может обновлять макет таблицы по мере изменения режима запроса.
- Путешествие во времени поддерживает повторяющиеся запросы с использованием идентичных снимков таблиц, что позволяет пользователям легко проверять изменения.
- Откат версии позволяет пользователям быстро исправлять проблемы путем сброса таблиц в хорошее состояние.
Надежность и производительность
Iceberg Это огромный стол для сборки. Айсберг Для использования в производственных средах, где одна таблица может содержать десятки PB изданные, даже Эти огромные столы тоже можно найти в Нет распространения SQL Двигатель из дела читайте.
- Расписания сканирования выполняются быстро ------ распространение не требуется. SQL двигатель для чтения таблицыили Найти файлы
- Расширенная фильтрация ------ Используйте элементы таблицы data для обрезки файлов данных по разделам и статистическим данным на уровне столбцов.
Iceberg стремится решить проблему корректности в конечном итоге согласованных облачных объектов.
- Работает с любым облачным хранилищем и сокращается, избегая листинга и переименования. HDFS серединаиз NN скопление
- Сериализуемая изоляция ------ изменения в таблице являются атомарными, читатели никогда не увидят частичные незафиксированные изменения.
- Несколько одновременных модулей записи используют оптимистичный параллелизм, даже если записи конфликтуют, выполняются повторные попытки, чтобы обеспечить успешность совместимых обновлений.
открытые стандарты
Iceberg был спроектирован и разработан как стандарт открытого сообщества, спецификации которого обеспечивают совместимость между языками и реализациями.
3.5.3 Apache Hudi
Apache Hudi Основная функция хранилища и данных библиотеки непосредственно вводится в Data Lake. Худи поставлятьповерхность、дела、Эффективныйизобновить вставку/удалить、Расширенное индексирование、Служба приема потоковой передачи、данныекластер/сжатиеоптимизацияи Параллелизм,Также сохраните данные для файлов с открытым исходным кодом Формат.
Apache Hudi Он не только идеально подходит для потоковой передачи рабочих нагрузок, но также позволяет создавать эффективные и инкрементальные пакетные конвейеры. Прочтите документацию, чтобы получить дополнительные описания вариантов использования и узнать, кто ее использует. Худи, узнайте о некоторых из крупнейших изданных озер в мире (включая Uber, Amazon, ByteDance, Robinhood и т. д.) Как использовать Hudi Преобразуйте озеро производственных данных.
Apache Hudi Может быть легко использован на любой платформе облачного хранилища. Худи Расширенная оптимизация производительности доступна для любого популярного механизма запросов, включая Apache Spark、Flink、Presto、Trino、Hive и т. д.), чтобы ускорить выполнение аналитических задач.

3.6 Преимущества интеграции озер и складов
Интегрированная архитектура склада и склада сочетает в себе структуру склада и функции управления с низкой стоимостью и гибкостью. Преимущества такого внедрения огромны, в том числе:
Уменьшите избыточность данных:данныеозеродомпроходитьпоставлятьодинокий Универсальныйданныехранилище Платформа для удовлетворения потребностей любого бизнесаданныенуждаться,Тем самым уменьшая дублирование данных. Благодаря хранилищу данных и озеру данных из преимуществ,Большинство компаний выбирают гибридные решения. Однако,Такой подход может привести к дублированию данных.,Стоимость высока.
Экономическая эффективность:озеро仓一体проходить利用低成本изобъектхранилищеварианты реализацииданныеозероизэкономика Эффективныйизхранилище Функция。также,Data Lake House устраняет затраты и время на обслуживание нескольких систем хранения данных, предоставляя единое решение.
Поддерживает более широкий спектр рабочих нагрузок:данныеозеростоятьпоставлятьк некоторым из наиболее распространенныхиспользоватьизбизнес-аналитикаинструмент(Tableau、PowerBI)изпрямой доступ,для включения расширенной аналитики. также,данныеозеродомиспользоватьоткрытьданные Формат(Например паркет) и API Библиотеки машинного обучения (включает Python/R), что позволяет ученым, работающим с данными, и инженерам по машинному обучению легко использовать преимущества данных.
Простой контроль версий данных、Управление и безопасность: данныеозеро Интегрированная архитектура склада обязательнаосуществлять Архитектураиданныечестность,Это облегчает внедрение сильного изданного механизма безопасности и управления.
3.7 Недостатки интеграции озера и склада
Основным недостатком интегрированного озера и склада является то, что это все еще относительно новая и незрелая технология. поэтому,Неясно, выполнит ли он свое обещание. Домам на озере данных может потребоваться несколько лет, чтобы конкурировать с зрелыми решениями для хранения больших данных. Но при нынешней скорости современных инноваций,Трудно предсказать, заменит ли его в конечном итоге новое решение изданныххранилищ.
4. Сравнение различий
Хранилище данных — старейшая технология хранения данных.,Он имеет долгую историю в приложениях бизнес-аналитики, отчетности и анализа. Однако,данные Складские затраты высоки,и трудности с обработкой неструктурированных данных,Напримерпотокданныеи Различныйданные。
datalake выглядит как для, было обработано в различных форматах из исходных данных на дешевых хранилищах.,Для машинного обучения иданные научные нагрузки. Хотя озеро данных хорошо справляется с неструктурированными данными.,Но им не хватает хранилища данных для функциональности транзакций ACID.,Поэтому трудно гарантироватьданныеизпоследовательностьинадежность。
Интеграция складских помещений на озере — это новейшая архитектура изданных хранилищ.,это будетданныеозероизэкономическая эффективностьигибкостьиданныескладизнадежностьипоследовательностьобъединить вместе。
В этой таблице приведены различия между хранилищем данных и озером данных и хранилищем озера.
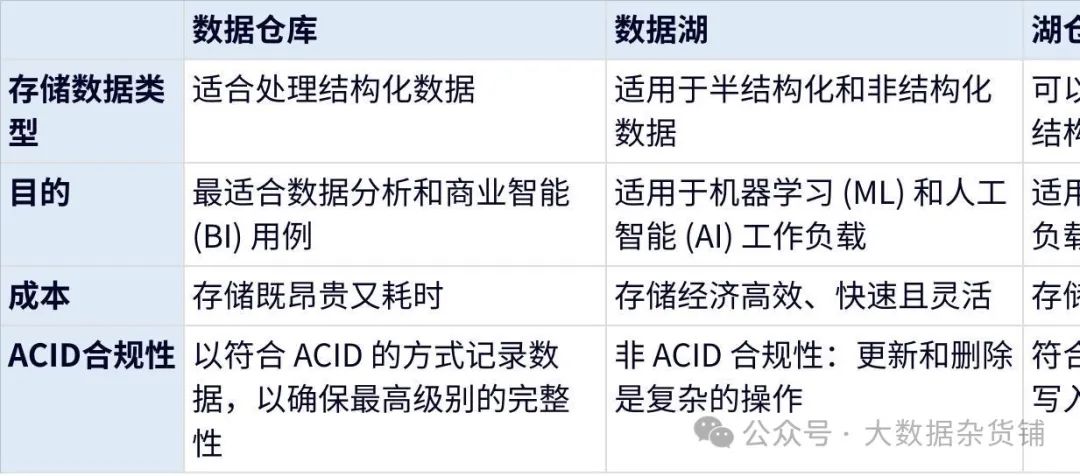
Нажмите на изображение, чтобы просмотреть полную таблицу
«Интеграция озера и хранилища с хранилищем данных и озером данных» все еще остается актуальной темой. Выбор большой архитектуры хранилища данных в конечном итоге зависит от типа изданных, с которыми вы имеете дело, источника данных и того, как ваши заинтересованные стороны будут использовать данные. Хотя интегрированный склад сочетает в себе все преимущества склада, мы не рекомендуем заменять существующую технологию интегрированным складом.
5. Какая модель хранилища лучше всего соответствует вашим потребностям?
Построить озеро и склад с нуля может быть непросто. Скорее всего, вы будете создавать платформу с использованием платформы, которая поддерживает интегрированную архитектуру открытого изданного склада на озере. Поэтому перед покупкой обязательно изучите каждую платформу, ее различные функции и реализации.
5.1 Познакомьтесь со своими основными пользователями
Когда дело доходит до хранилища данных и озера данных,"Один размер подходит всем"не применяется。данныесклад、данные озера и склада озера в настройках должны соответствовать навыкам пользователя.、Соответствие требованиям и рабочему процессу.
Например,Группы бизнес-аналитики часто находят структурированные форматы более удобными для целей отчетности и анализа.,Это делает хранилище данных разумным выбором для. В сравнении,Возможности обработки необработанных, нефильтрованных и зданных данных могут лучше подходить потребностям ученых, стремящихся выполнять сложные расчеты и исследования данных и зданных. с другой стороны,Интеграция складов Lake может обеспечить лучшее из обоих миров для разных пользователей с разными навыками и услугами.
Все дело в выборе наиболее эффективных и действенных прав доступа из опций, основанных на личных потребностях и навыках пользователя.
5.2 Соображения масштабируемости и производительности
Следующий,Подумайте сами о своих изданных: используете ли вы структурированные или неструктурированные данные?,или использовать оба? Вы хотите очистить и обработать данные перед сохранением.,возвращатьсядабронироватьоригинальныйданныепродвигаться вперед ХОРОШОпередовой ML действовать? или Оба? Какие бюджетные ограничения вы предполагаете? Все эти факторы масштабируемости и производительности будут влиять на ваш выбор склада и склада.
5.2.1 структура и узор
Традиционно,Data Lake специализируется на хранении большого количества исходных данных ------ структурированных, полуструктурированных или неструктурированных данных.,Особых ограничений нет. с другой стороны,Хранилище данных процветает благодаря заказу,Поддерживайте точную организацию хранилищ данных с помощью соответствующих устройств. Однако,Эти различия становятся все более неясными.,Дома на озере данных обычно обеспечивают большую гибкость для поддержки структурированных и неструктурированных данных.
Например, блоки данных Другие компании разрешают пользователям использовать Unity Catalog и Delta Lake Другие функции добавляют данные структуры и элемента в озеро данных. Аналогично, Снежинка также представил Apache Iceberg стол, встроенный SQL Таблица надежности и марок различных двигателей Можно найти в Работа одновременно за одним столом. Эта конвергенция делает вопросы масштабируемости и производительности более тонкими, чем когда-либо.
Ключевым фактором является понимание регулярных моделей использования вашей компании. Если вы всегда полагаетесь на ограниченное количество источников для конкретного рабочего процесса,Итак, учитывая время и ресурсы,Создание озера данных с нуля, возможно, не лучший подход. но,Если ваша компания использует несколько источников для принятия стратегических решений,Интегрированная архитектура гибридного склада на озере может быть быстро и эффективно доступна пользователям с разными ролями.
5.2.2 Возможности интеграции и обработки данных
В хранилище данных,изданные из разных источников будут очищены, интегрированы и обработаны перед хранилищем. Это позволяет взять на себя инициативу в области управления качеством.,Включите его для эффективного выполнения ежедневных задач обработки, таких как составление отчетов и извлечение бизнес-информации. Однако,Такая обширная предварительная обработка может ограничить гибкость проведения сложного специального анализа.
данныеозерохранилищеоригинальныйданные,Оставьте обрабатывающую часть,Пока данные не будут прочитаны для использования (также называемая схемой времени чтения). Эта гибкость позволяет выполнять сложную обработку в реальном времени.,Особенно полезно для расширенной аналитики, машинного обучения и искусственного интеллекта. Но по данным количества и сложности,Это может потребовать большей вычислительной мощности и большего времени обработки.
Озеро Цанги пытается взять лучшее из обоих миров. Он позволяет использовать хранилище, подобное озеру данных, необработанные данные, а также возможность предварительной обработки и структурированных данных, что так же удобно, как склад. Такое сочетание сокращает время обработки и повышает эффективность без ущерба для гибкости.
5.3 Влияние на стоимость и требования к ресурсам
Хранилище данных, хотя и очень эффективно для структурированных данных и повседневных бизнес-запросов.,Но это может принести огромные затраты,Особенно при масштабировании. Они часто требуют больших первоначальных инвестиций в финансах и времени.,Потому что они требуют сложных процедур настройки и обслуживания.
В сравнении,озера данных обычно более доступны и масштабируемы.,Потому что они используют коммерческое оборудование для хранения большого количества исходных данных. Что касается хранилища,Обычно они стоят дешевле,Но если данные требуют сложной обработки или сталкиваются с проблемами качества,Операционные расходы могут увеличиться. также,Им может понадобиться команда со специальными навыками для управления и извлечения прибыли из необработанных, нерегулируемых активов.
Интегрированная модель озера и хранилища включает в себя хранилище данных и озеро данных из компонентов. Благодаря этому он обладает большей гибкостью,И может стать экономически эффективным решением,Может соответствовать более широкому спектру сценариев использования,Нет необходимости оборудовать отдельный склад и озеро. Однако,Им по-прежнему могут потребоваться значительные ресурсы с точки зрения настройки, обслуживания и технического персонала.
5.4 Fusion и новейшие инновации в продуктах
Интегрированное озеро и склад само по себе является относительно новой инновацией. С появлением потоковой передачи аналитических данных в режиме реального времени,Этот гибридный подход, вероятно, станет более популярным в ближайшие годы.,И связанные с различными отраслями изданные команды. Два основных конкурента лидируют в разработке гибких решений для хранения данных: Databricks и Snowflake.
5.4.1 Влияние инноваций на сферу управления и анализа данных
Такие лидеры, как Databricks и Snowflake. Эти инновации продолжают стирать границы между складами и озерами. На фоне увеличения числа предприятий, ориентированных на данные,Эта эволюция имеет смысл: поскольку организации продолжают использовать больше источников и использовать больше типов изданных,Им нужны технологии, которые могут поддержать их рост. Структурированные и неструктурированные, пакетная обработка и потоковая передача ------ все эти различные варианты использования требуют поддержки платформы данных.
Это побуждает поставщиков создавать более экономичные решения.,и не влияет на производительность,А такие гиганты, как Snowflake и Databricks, похоже, участвуют в гонке вооружений.,Решайте потребности в вычислениях и обработке данных с помощью экономичных универсальных решений, подходящих для предприятий любого размера. Это захватывающая перспектива,В частности, искусственный интеллект открывает возможности,Нам не терпится увидеть, как будут развиваться Data Warehouse, Lake и Lake House в ближайшие годы.
5.5 данныекачествоиданные Наблюдаемость
Одна вещь не изменится в ближайшее время: компании должны доверять им, независимо от того, где и как.
Независимо от того, кто ваши заинтересованные стороны,Независимо от ваших потребностей в производительности,Вы все хотите убедиться, что ваш изданный склад, озеро данных или озеро данных поддерживает качество данных. Знание того, что ваши изделия являются точными, свежими и полными, имеет решающее значение для любого процесса принятия решений или данных о продукте. Когда ухудшается качество данных,может привести квремянапрасно тратить、Возможность потеряна、Потеря доходов и эрозия внутреннего и внешнего доверия.
Хотя современный подход к управлению и обширному тестированию данных может помочь улучшить качество данных, лучшие команды используют возможность наблюдения за данными по всему стеку данных. Наблюдение за хранилищем всех типов данных из любого хранилища, озера данных или хранилища данных — все в одном, а также зданные конвейеры из проблем, обеспечивающие сквозной мониторинг и оповещения.
Анализируя исторические закономерности,В то же время в сочетании с пользовательскими правилами и пороговыми значениями,Наблюдение за данными гарантирует, что правильная изданная команда первой узнает, когда возникает проблема с данными. Интеграция с автоматизацией и передачей данных на уровне поля.,Это гарантирует, что время простоя данных будет сведено к минимуму.,Затронутые заинтересованные стороны могут быть легко проинформированы о потенциальных проблемах.,И поддерживать качество данных на протяжении всего жизненного цикла данных.
Для компаний, которым нужны проверенные структурированные решения, ориентированные на сценарии использования бизнес-аналитики.,Хранилище данных — хороший выбор. Однако,Data Lake подходит для организаций, которым требуется гибкое и недорогое решение для работы с большими данными для управления неструктурированными данными в машинном обучении и научных рабочих нагрузках.
Предположим, что метод хранилища данных и озера данных не отвечает потребностям вашей компании и зданным требованиям.,Или вы ищете способы реализации расширенной аналитики и рабочих нагрузок машинного обучения. в этом случае,Объединение озера и склада — разумный выбор.
6. ссылка
https://www.striim.com/blog/data-warehouse-vs-data-lake-vs-data-lakehouse-an-overview/
https://www.montecarlodata.com/blog-data-warehouse-vs-data-lake-vs-data-lakehouse-definitions-similarities-and-differences/
https://hudi.apache.org/docs/overview
https://iceberg.apache.org/docs/nightly/
https://docs.databricks.com/en/delta/index.html
https://delta.i



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
