Хорошие новости для обнаружения целей | Если вы используете объединение функций, вы все еще используете FPN/PAFPN? Слияние YOLOX+GFPN сразу же взлетело и поднялось еще на 2 пункта.

Пирамида визуальных функций демонстрирует свою эффективность и результативность в задачах обнаружения объектов. Однако современные методы склонны переоценивать межуровневое взаимодействие функций и игнорировать ключевой аспект внутриуровневой настройки функций. Опыт подчеркивает важные преимущества внутриуровневого взаимодействия функций при улучшении задач обнаружения объектов. Хотя некоторые методы пытаются изучить сжатые представления объектов внутри слоя с помощью механизмов внимания или визуальных преобразователей, они игнорируют интеграцию глобальных информационных взаимодействий. Такое пренебрежение приводит к увеличению количества ложных обнаружений и пропущенных целей. Чтобы решить эту ключевую проблему, в этом документе представлена Глобальная пирамидальная сеть функций (GFPNet), расширенная версия PAFPN, которая объединяет глобальную информацию для улучшения обнаружения целей. В частности, авторы используют облегченный MLP для сбора информации о глобальных функциях, используют кодировщик VNC для обработки этих функций и применяют параллельный обучаемый механизм для извлечения внутриуровневых функций из входного изображения. Исходя из этого, автор сохраняет метод PAFPN, чтобы обеспечить взаимодействие объектов между слоями и извлекать подробную информацию о функциях на нескольких уровнях. По сравнению с традиционной пирамидой функций, GFPN не только эффективно фокусируется на межуровневой информации о функциях, но также фиксирует глобальные детали функций, способствует взаимодействию функций внутри уровней и генерирует более полное и влиятельное представление функций. GFPN неизменно превосходит базовый уровень обнаружения объектов.
1 Introduction
Задача обнаружения объектов — одна из самых фундаментальных, но сложных исследовательских задач в области компьютерного зрения. Цель этой задачи — спрогнозировать уникальную ограничивающую рамку для каждого объекта во входном изображении, которая содержит не только информацию о местоположении объекта, но также информацию о категории объекта внутри рамки. В последние годы эта задача получила широкое развитие и применение, например, в таких областях, как автономное вождение и компьютерная медицинская диагностика. Современные методы обнаружения целей можно условно разделить на две категории. Один тип основан на сверточной нейронной сети (CNN) как методе магистральной сети, а другой тип основан на трансформере как методе магистральной сети. Методы использования CNN в качестве магистральной сети включают двухэтапные (например, Faster R-CNN) и одноэтапные (например, SSD и YOLO) методы. Из-за неопределенности размера объекта информация в масштабе одного объекта не может соответствовать требованиям к высокоточному распознаванию.
Поэтому предлагаются методы, основанные на пирамидах функций интрасети (таких как SSD и FFP), которые эффективно достигают удовлетворительных результатов. Ключевая идея этих методов состоит в том, чтобы ввести восходящий и нисходящий поток информации в верхней части CNN для создания многомасштабной пирамиды признаков, которая помогает улучшить производительность обнаружения модели для объектов разных размеров. В целом суть этих методов заключается в объединении карт признаков разных уровней для обработки разномасштабной информации в единой сети. Взаимодействие между различными функциями уровня очень важно. Вашишт и др. (2020) предложили эффективный метод взаимодействия функций, позволяющий сделать функции изображения более полными и богатыми, позволяя модели обнаружения целей обучаться более полно и значимо. Корреляционный метод хорошо это иллюстрирует. Например, FPN предлагает нисходящий механизм взаимодействия объектов между слоями, позволяющий мелким объектам получать глобальную контекстную информацию и семантическое представление глубоких объектов. NAS-FPN пытается найти стратегии и получить масштабируемое представление функций с помощью сетевой архитектуры.
2 Related Work
Object Detection
Обнаружение объектов играет жизненно важную роль в области компьютерного зрения. Исследования Shen et al. (2023) и Liu et al (2019) показывают, что обнаружение объектов играет фундаментальную роль в компьютерном зрении, идентифицируя объекты на изображениях и предоставляя им информацию об их местоположении и категории. С развитием сверточных нейронных сетей (CNN) в этой области был достигнут значительный прогресс. Например, платформы на основе привязки, такие как Fast R-CNN, представляют метод сквозного обнаружения для достижения целевого обнаружения за счет совместного использования сверточных функций и интеграции пула рентабельности инвестиций.
На основе Faster R-CNN представлена сеть предложений регионов (RPN) для улучшения локализации и обнаружения целей. Точечные системы без привязки привлекли внимание, поскольку они могут напрямую прогнозировать ограничивающие рамки и вероятности классов, тем самым обеспечивая более быстрые и эффективные детекторы, такие как семейство YOLO и методы SSD. YOLOX — это мощный и простой метод, который повышает точность и скорость вывода за счет разделения головок обнаружения и адаптивных стратегий. Целью данной статьи является достижение более значимых результатов обнаружения за счет повышения производительности базовой модели с использованием взаимодействий внутренних слоев пирамиды признаков.
Vision Attention
Сверточные нейронные сети (CNN) известны своей ориентацией на локальные особенности, но по мере развития компьютерного зрения этот локальный фокус может не адекватно отражать глобальный контекст и долгосрочные зависимости, необходимые современным системам распознавания. Для решения этой проблемы предлагаются механизмы обучения внимания, определяющие место на изображении для распределения внимания, тем самым достигая более полного внимания к особенностям изображения. Нелокальные операции, например, использование нелокальных нейронных сетей для непосредственного захвата долгосрочных зависимостей, подчеркивают важность нелокального моделирования при обнаружении объектов. Однако CNN по-прежнему сталкиваются с проблемой захвата внутренних локальных представлений, что ограничивает их способность захватывать широкую контекстную информацию. Трансформатор использует механизм самообслуживания с несколькими головками и завоевал значительное внимание и успех в области компьютерного зрения, особенно в классификации изображений. Типичным методом является визуальный преобразователь (ViT), который делит изображения на представления последовательностей и использует позиционное кодирование. Эти представления затем обрабатываются последовательным блоком Transformer для извлечения параметризованных векторов изображений в качестве визуальных представлений. Хотя модели на основе трансформаторов демонстрируют отличную производительность при решении различных задач компьютерного зрения, в настоящее время они по-прежнему сталкиваются с ограничениями в вычислительной интенсивности и сложности обнаружения объектов. Однако постоянные улучшения привели к появлению моделей с хорошей производительностью при решении различных задач компьютерного зрения.
Feature Pyramid Network
Функциональная пирамида — это базовая сеть Нека в модели обнаружения целей, которую можно эффективно и результативно использовать для обнаружения объектов разных размеров. SSD — один из первых методов обнаружения объектов, использующих пирамидальную классификацию объектов. Он собирает информацию о многомасштабных объектах через сети с разными пространственными размерами, тем самым повышая точность распознавания модели. FPN в основном полагается на функции иерархических пирамид для построения пирамид функций более высокого уровня путем установления контекстных путей и боковых связей из многомасштабных семантических карт объектов высокого уровня. EMRN предлагает модуль унификации размеров объектов с несколькими разрешениями для фиксации пространственных объектов на изображениях с разным разрешением.
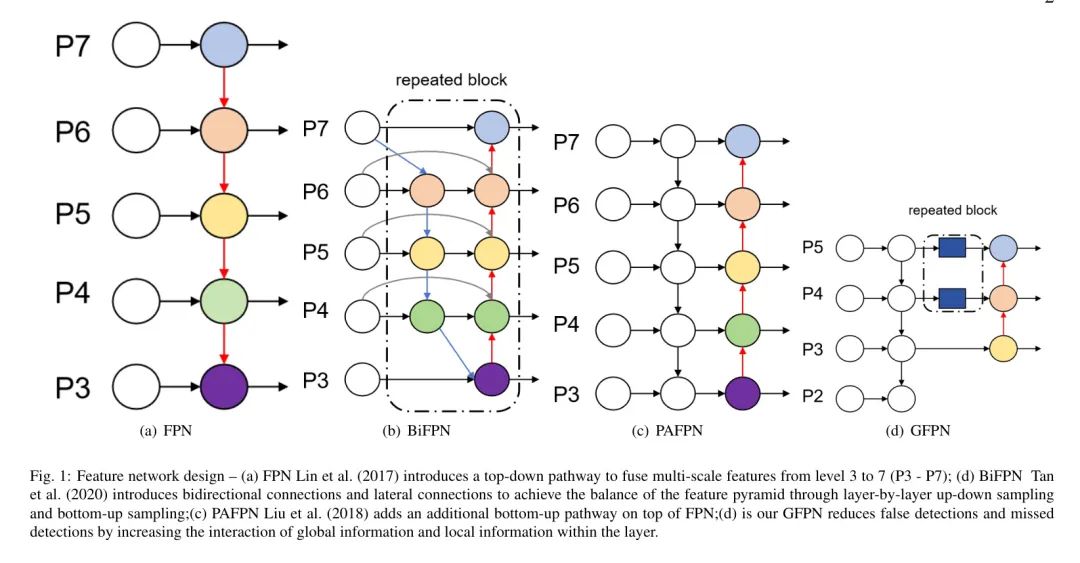
На этой основе PANet предлагает базовый путь на основе FPN для обмена информацией об объектах между уровнями, чтобы объекты высокого уровня могли получать достаточную информацию о объектах низкого уровня. Посредством поиска нейронной архитектуры NAS-FPN использует стратегию пространственного поиска для соединения различных слоев через пирамиды объектов для получения масштабируемой информации о функциях. HSGM предлагает модуль иерархического графа сходства для смягчения конфликтов в магистральных сетях и выявления дискриминационных функций. PAFPN обеспечивает более мощное многомасштабное представление объектов за счет улучшения соединений и каскадов путей в сети пирамиды объектов, что позволяет сети лучше захватывать сложную семантическую информацию. Таким образом, пирамида признаков может решать проблемы многомасштабных вариаций при распознавании целей без увеличения вычислительных затрат. Извлеченные признаки могут генерировать многомасштабные представления объектов, включая некоторые признаки с высоким разрешением. В этой работе автор выполняет лучшую настройку функций внутреннего слоя с точки зрения межуровневого взаимодействия функций и настройки внутреннего уровня функций пирамиды и объединяет ее с механизмом внимания канала для повышения производительности модели.
3 Proposed Method
Overview
В области глубокого обучения Feature Pyramid Network (FPN) широко используется в задачах обнаружения объектов для решения задач обнаружения объектов разных масштабов. Распространенным методом построения пирамиды объектов изображения является объединение объектов между различными слоями, при котором объединение объектов снизу вверх постепенно переносит информацию с карт объектов с низким разрешением на карты объектов с высоким разрешением, в то время как объединение объектов сверху вниз постепенно передает информацию из слоев с низким разрешением. Сопоставление объектов с высоким разрешением в картах объектов с высоким разрешением. Объединение объектов переносит контекстную информацию с карты объектов с высоким разрешением на карту объектов с низким разрешением. На этой основе Cascade FPN (CAFPN) обеспечивает более разнообразное и полное представление путем объединения нескольких FPN для построения многоуровневой пирамиды функций в разных масштабах.
NAS-FPN полностью использует многомасштабную информацию посредством методов поиска нейронной архитектуры. BiFPN обеспечивает агрегирование информации карты объектов различного уровня путем добавления двунаправленных соединений. Однако эти методы игнорируют взаимодействие между объектами внутри одного слоя. Внутриуровневое взаимодействие объектов означает обогащение представления объектов внутри одного слоя за счет взаимодействия между каналами, что также оказывает существенное влияние на задачу обнаружения целей. Поскольку признаки разных каналов обычно соответствуют разной семантической информации, введение внутриуровневого взаимодействия признаков может улучшить восприятие объектов сетью.
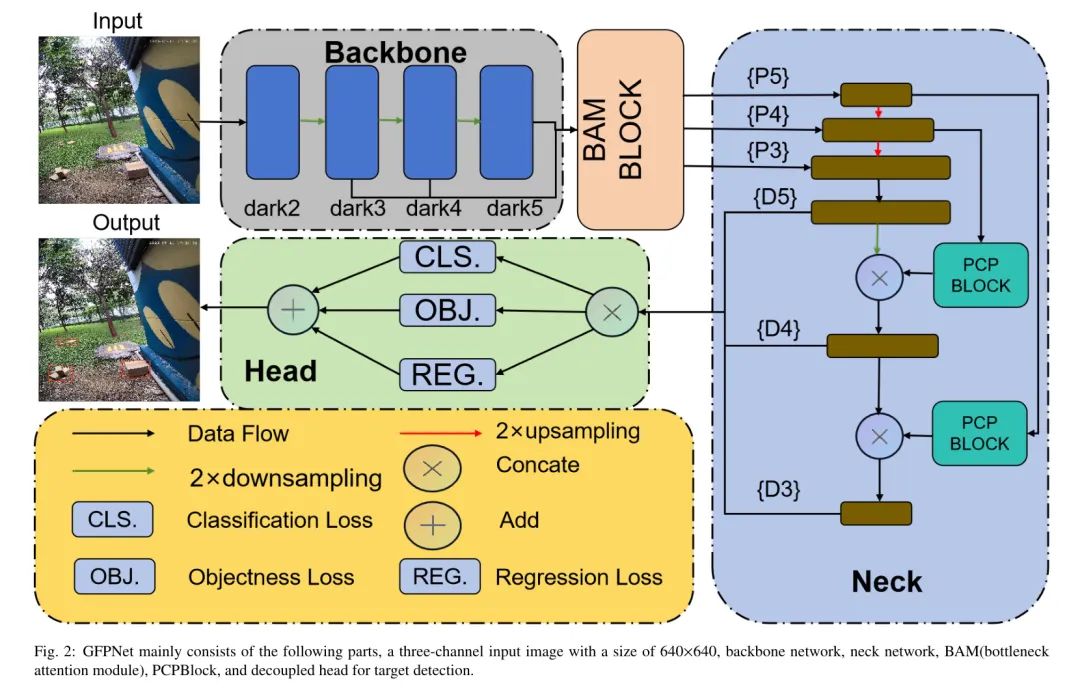
Поэтому в этой работе автор предлагает вариант модели, основанной на параллельной пирамидальной сети функций (PAFPN), которая реализует внутриуровневое взаимодействие функций и глобальный сбор информации на основе PAFPN. В частности, авторы вводят модуль внимания для каждого функционального слоя, который изучает адаптивные веса каналов для взаимодействия с семантической информацией между каналами.
Кроме того, автор добавляет слой глобального пула на вершину пирамиды признаков для дальнейшего извлечения глобальной семантической информации и помощи сети лучше понять семантическую структуру всего изображения. Объединив внутриуровневое взаимодействие функций и глобальную информацию, модель авторов может всесторонне и точно захватывать объекты в разных масштабах, тем самым достигая значительного повышения производительности в задачах обнаружения объектов.
Таким образом, эта работа представляет внутриуровневое взаимодействие функций и глобальный сбор информации на основе PAFPN, обеспечивая эффективное взаимодействие между межуровневыми и внутриуровневыми функциями, извлекая более полные и разнообразные представления функций и, таким образом, улучшая производительность задач обнаружения целей. добиться превосходной производительности.
PCPBlock
Автор предложил PCPBlock, который состоит из облегченного MLP и кодера VNC. Легкий MLP в основном используется для сбора глобальной информации. Благодаря небольшому размеру параметров и вычислительным затратам он может эффективно извлекать семантическую информацию высокого уровня, сохраняя при этом низкие вычислительные затраты. Являясь обучаемым модулем, кодер VNC собирает локальную информацию и взаимодействует с ней, а также использует глобальную информацию, полученную с помощью облегченного MLP. Это позволяет эффективно кодировать сложную информацию и эффективно взаимодействовать с ней.
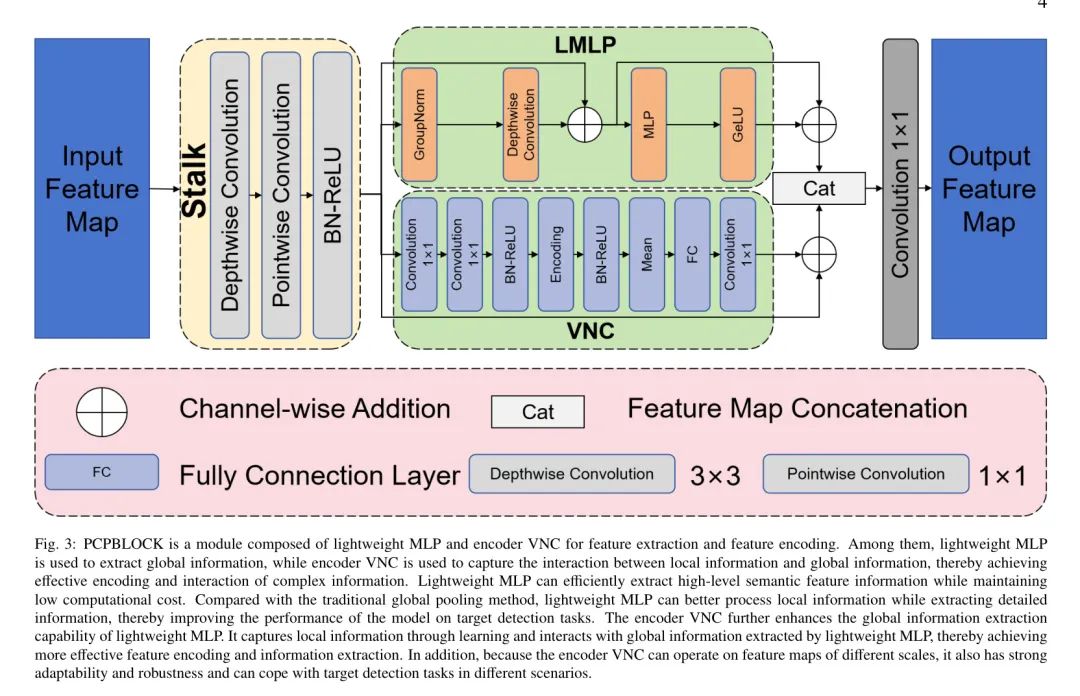
В PCPBlock выходные карты функций облегченного MLP и кодера VNC объединяются в измерении канала как конечный результат PCPBlock. Такая конструкция позволяет PCPBlock одновременно объединять глобальную и локальную информацию и обеспечивать более полное и богатое представление функций. Путем интеграции нескольких блоков PCPBlocks можно создать более мощную сетевую структуру для улучшения представления функций и возможностей обучения.
Для дальнейшего повышения эффективности взаимодействия функций реализация включает дополнительный модуль, называемый модулем преследования, который расположен между картой объектов каждого слоя и PCPBlock. По сравнению с реализацией непосредственно на исходной карте объектов эта стратегия является более гибкой, поскольку модуль отслеживания может сглаживать объекты для повышения качества, тем самым облегчая последующее взаимодействие функций.
Модуль стебля включает в себя отделимые свертки, в том числе поточечную свертку 3x3 и поточечную свертку 1x1. Такая конструкция обеспечивает согласованность количества входных и выходных каналов, а эффективное использование разделяемых сверток эффективно снижает параметры сети, увеличивает вычислительную мощность и дополнительно улучшает представление функций за счет пакетной нормализации и слоев активации. Конкретный процесс можно выразить так:
где X — результат PCPBlock,
Представляет объединение карт объектов в измерении канала.
и
соответственно представляют собой выходные данные облегченного обучаемого кодера MLPи, а
— это выход модуля подрулевого переключателя, как показано ниже:
здесь,
это результат PCPBlock,
Представляет объединение карт объектов в измерении канала.
и
соответственно представляют собой выходные данные облегченного обучаемого кодера MLPи, а
Это выход модуля подрулевого переключателя.
Обратите внимание, что код здесь, возможно, придется изменить в зависимости от вашей конкретной реализации.
Среди них SepConv представляет собой отделимую свертку, состоящую из 3
3DWConvи1
Состоящий из PWConv, равный 1, BN представляет собой пакетную нормализацию, а RELU — функцию активации.
BAM
BAMпредложил простойи Модуль эффективного внимания,Этот модуль широко используется в глубоком обучении.,Улучшить способность модели к обучению на изображениях или картах объектов. Внедряя механизм внимания,Модуль BAM может взвешивать функции в канальных и пространственных измерениях.,Это позволяет сети более точно сфокусироваться и извлечь более репрезентативные представления объектов. В модуле БАМ,Вход проходит через 1
1После операции свертки,Он разделен на две непересекающиеся ветви: ветвь канала внимания и ветвь пространственного внимания. Ветка внимания канала в основном используется для моделирования корреляции между различными каналами. Через глобальную операцию объединения средних показателей,Сжимайте карту объектов в вектор канала в измерении канала.
Далее векторы каналов обрабатываются через два полносвязных слоя (включая функцию активации ReLU) для получения веса каждого канала. Эти веса отражают важность каждого канала в конкретном контексте, тем самым обеспечивая отображение карт признаков в пространственном измерении. Используя 3
3 ядра свертки извлекают объекты из входных данных для получения карт пространственных объектов. Затем карта пространственных объектов обрабатывается через два полностью связанных слоя для получения веса каждого пространственного местоположения. Эти веса отражают важность различных мест в конкретном контексте, тем самым позволяя составить карту пространственных отношений.
наконец,Умножьте веса ветвей канала внимания и пространственного внимания.,чтобы получить окончательную карту внимания,Затем карта внимания умножается на исходные данные.,для достижения взвешивания функций. так,Модуль BAM позволяет сети уточнять важные области изображения или карты объектов.,и извлекать более различительные представления объектов.
Loss Function
В эксперименте, по сравнению с использованием BCE Loss, в качестве функции потерь ветви классификации предлагается использовать Focal Loss. Фокальная потеря — это функция потерь, используемая для решения проблем дисбаланса классов. По сравнению с BCE Loss, он более эффективно обрабатывает трудноклассифицируемые выборки и повышает точность прогнозирования модели по нескольким категориям. Дисбаланс классов относится к ситуации, когда существует значительная разница в количестве образцов каждого класса в наборе данных.
В этом случае сеть имеет тенденцию учиться прогнозировать категорию большинства и игнорировать категорию меньшинства, что приводит к снижению прогнозирующей способности модели в отношении категории меньшинства. Вводя коэффициент балансировки, Focal Loss может эффективно подавлять вес образцов, которые легко классифицировать, одновременно увеличивая вес образцов, которые трудно классифицировать, тем самым уделяя больше внимания нескольким категориям и компенсируя потерю производительности, вызванную дисбалансом категорий. .
В частности, Фокальный Loss представляет регулируемую гамму гиперпараметров для регулировки веса легко классифицируемых и трудно классифицируемых образцов. Для образцов, которые легко классифицировать и которые имеют большие градиенты, использование параметра гамма может уменьшить их вес, чтобы они меньше вносили вклад в потери. Для образцов, которые трудно классифицировать и которые имеют небольшие градиенты, параметр гамма можно использовать для увеличения их веса, чтобы они вносили больший вклад в потери. Таким образом, Фокальный Loss может лучше обрабатывать несбалансированные по классам выборки и повышать точность прогнозирования модели по нескольким категориям.
Например, Фокал Потери — лучший выбор в качестве функции потерь ветви классификации. В задачах обнаружения целей обычно возникает очевидная проблема дисбаланса классов Focal. Потеря может лучше решить эту проблему и улучшить производительность модели по нескольким категориям. Поэтому, используя Focal Loss,Эксперименты по решению проблемы классового дисбалансаиулучшать Модель Лучшие результаты были достигнуты с точки зрения точности классификации.。
4 Experiment and Analysis
Чтобы убедиться в преимуществах предложенного метода GFPN, авторы сравнили его с несколькими современными алгоритмами, включая PCP, на крупномасштабных наборах данных.
Datasets and Evaluation Metrics
в этой работе,Набор данных PCP использовался для проверки преимуществ предложенного метода GFPN. PCP содержит 5 типов целей сцены.,Обучающий набор и тестовый набор содержат 46 тыс. и 2 тыс. изображений соответственно.
В экспериментах для честного сравнения все обучающие изображения масштабируются до фиксированного размера 640.
640. Об улучшении данных,Были использованы Mosaic и MixUp, первоначально использованные YOLOX в эксперименте. в то же время,В эксперименте использовался метод точной настройки.,Выберите точную настройку с использованием обученных гирь YOLOX-S на COCO.,и внаконец5индивидуальныйepochСредне близкоданные Стратегия улучшения。
Показатели оценки. в эксперименте,В основном соответствует обычно используемому индексу средней точности оценки обнаружения цели (AP).,Включает AP50,AP75,АП (маленький),AP (средний) и AP (большой).
Baseline
В эксперименте YOLOX выбран в качестве эталонной модели. YOLOX — это передовая модель в области обнаружения целей, в которой используется ряд передовых технологий для повышения эффективности обнаружения целей. В состав YOLOX входит CSPDarkNet как Backbone сеть, PAFPN в качестве шейной сети и сеть головки развязки в качестве головки обнаружения цели. Тем временем YOLOXв соответствии с шириной и глубиной сети генерирует сеть в трех разных масштабах: YOLOX-S,YOLOX-MиYOLOX-L。
CSPDarkNet от YOLOX Backbone который использует модуль подключения CSP (Cross Phase Part) для достижения лучшего представления объектов и градиента путем разделения входной карты объектов на две ветви и реорганизации объектов между ветвями. PAFPN — это «шея» YOLOX, которая представляет структуру пирамиды функций и объединяет информацию о функциях разных масштабов посредством агрегации путей. PAFPN из Backbone разница в сети Level Извлечение многомасштабных карт объектов,И создавайте карты объектов с обширной семантической информацией посредством повышения дискретизации и объединения функций. Это объединение нескольких масштабных функций может улучшить возможности обнаружения модели для разных целевых масштабов.,И повышает производительность Модели в задачах обнаружения целей.
Сеть развязывающей головки является головкой обнаружения цели YOLOX.,Он включает в себя классификацию, регрессию и obj-ветви. Ветка классификации используется для прогнозирования распределения вероятностей целевой категории.,Ветвь регрессии используется для прогнозирования местоположения и размера цели.,Ветка obj используется для прогнозирования оценки присутствия цели. Разделенный дизайн позволяет YOLOX сбалансировать классификацию целевых категорий и задачи локальной регрессии.,и эффективно выполнять обнаружение целей. Создавая сеть трех разных масштабов (YOLOX-S,YOLOX-MиYOLOX-L),YOLOXМожетв соответствии Ширина и глубина ссети адаптируются к различным сценариям обнаружения целей.
Меньший масштаб сети подходит для облегченного обнаружения целей с более высокой скоростью вывода, тогда как более крупный масштаб сети подходит для более сложных задач обнаружения целей с более высокой точностью обнаружения. Короче говоря, YOLOX — это CSPDarkNet. Backbone сеть、PAFPNшеясетьи Развязывающий заголовоксеть Мощное обнаружение целей Модель。Создавая различные масштабысеть,YOLOX может адаптироваться к различным потребностям обнаружения целей,И добиться превосходной производительности обнаружения в различных сценариях.
Implementation Details
В ходе эксперимента изображение было масштабировано до 640.
640. Это означает, что входное изображение в модель масштабируется в соответствии с входными размерами модели. Масштабирование изображения до соответствующего размера гарантирует, что модель более точно и эффективно усвоит визуальные особенности изображения. Во время обучения в качестве оптимизатора используется стохастический градиентный спуск (SGD). SGD — один из часто используемых алгоритмов оптимизации в глубоком обучении. Он корректирует параметры модели, чтобы минимизировать потери путем расчета функции потерь. SGD случайным образом выбирает небольшое количество выборок (то есть стохастических градиентов) в каждом обучающем пакете и использует эти выборки для расчета градиентов и обновления параметров модели. Постоянно повторяя процесс обучения, SGD может постепенно оптимизировать производительность модели.
Кроме того, установлен диапазон ставок обучения. Скорость обучения контролирует размер шага обновления параметров на каждой итерации. Более низкая скорость обучения может сделать обучение более стабильным и уменьшить величину обновления параметров, но может привести к более медленному обучению. Более высокая скорость обучения может ускорить сходимость, но может привести к нестабильности или невозможности сходимости процесса обучения. Установив скорость обучения в диапазоне от 0,0005 до 0,001, ее можно настроить в соответствии с реальной ситуацией, чтобы найти оптимальное значение скорости обучения для достижения наилучшего эффекта обучения.
Comparison with State-of-the-art Methods
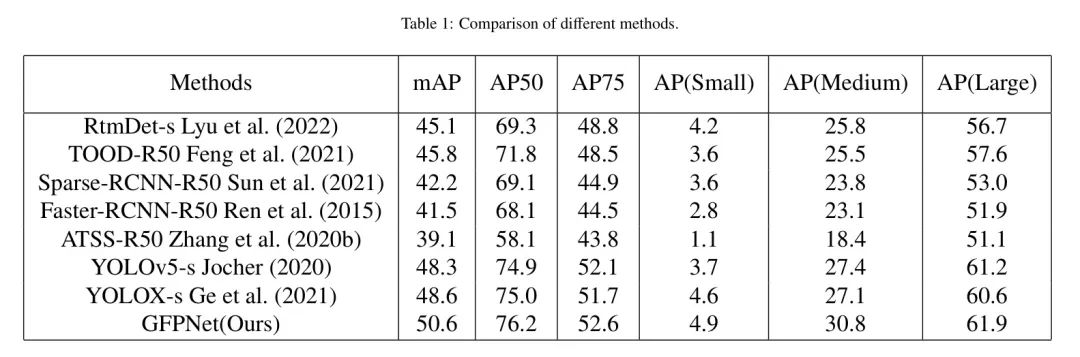
в соответствии споверхность1вданныеанализировать,Авторы сравнивают GFPN с несколькими современными одноступенчатыми и многоступенчатыми детекторами. По данным сравнительного эксперимента,Автор может сделать вывод, что GFPN добилась лучших результатов по различным показателям производительности. Его производительность превосходит другие одноступенчатые и многоступенчатые детекторы.,Включая, помимо прочего, mAP,AP50иAP75. в то же время,GFPN значительно улучшился по сравнению с AP (Medium). Это показывает, что GFPN имеет значительные преимущества в задачах обнаружения целей.,Его производительность опережает другие современные детекторы.
Ablation Studies and Analysis
Результаты сравнения, представленные в таблице, показывают, что,Предложенный метод GFPN превосходит многие современные однокаскадные и многокаскадные детекторы. Ниже всесторонне анализируются характеристики предлагаемого метода обнаружения целей с нескольких аспектов.,и исследует логику своего превосходства.

- Влияние PCPBlock в соответствии Используя данные в Таблице 2, автор может заметить, что использование PCPBlock для реализации взаимодействия между глобальной информацией и локальной информацией значительно повышает производительность Модели. В частности, индекс Модели на индикаторе mAP увеличился на 1,5%, а это означает, что после использования PCPBlock Модель может более точно определять местонахождение и классифицировать цели в задаче обнаружения целей. Кроме того, показатель APM Модели также увеличился на 2,9%, что еще раз доказывает эффективность PCPBlock. Преимущество PCPBlock заключается в том, что он может одновременно захватывать глобальную и локальную информацию и реализовывать взаимодействие между ними. Благодаря легкому MLP PCPBlock может лучше собирать глобальную информацию о функциях, что очень важно для понимания всей сцены и точного обнаружения целей. в то же время,Encoder VNC также может сохранять локальную информацию и осуществлять информационное взаимодействие.,Сделайте его более богатым и гибким в представлении функций. Взаимодействие глобальной и локальной информации позволяет повысить эффективность задач обнаружения целей.,И заставить Модель лучше адаптироваться к различным сценариям и целям. в общем,Использование PCPBlock значительно улучшает производительность Модели. Он может собирать обширную глобальную информацию и взаимодействовать с локальной информацией.,Тем самым повышая точность и точность обнаружения целей. Эти результаты показывают, что PCPBlock является действительным модулем.,Его можно интегрировать в систему обнаружения целей, чтобы улучшить ее производительность и решить проблему ложного обнаружения и пропущенного обнаружения.
- Влияние модулей БАМ в соответствии Учитывая данные таблицы 2, можно сделать вывод, что использование модуля BAM может привести к определенному повышению производительности. В частности, после добавления модуля БАМ индекс Модели по показателю mAP увеличился на 0,3%, а это означает, что Модель показала лучшие результаты по точности обнаружения целей. В то же время показатель APM Модели также увеличился на 0,7%, что означает, что модуль BAM улучшил способность Модели изучать функции, позволяя Модели лучше понимать и интерпретировать входные функции. Преимущество модуля BAM заключается в том, что он расширяет возможности Модели выражать функции и предоставляет более полную информацию при взаимодействии функций. Используя глобальную контекстную информациюи Взаимозависимость между функциональными каналами,Модуль BAM реализует улучшения и улучшения функций. также,Модуль BAM может адаптивно регулировать вес значения ответа для адаптации к различным сценариям и целям.,отиулучшать Модельадаптивностьиспособность к обобщению。
- Абляционное исследование модуля PCPBlock в соответствии Анализируя данные в таблице 3, можно сделать вывод, что каждый модуль в модуле PCPBlock играет разную роль в улучшении моделипроизводительности. В частности, с точки зрения одного модуля, Индекс модуля стебля по метрике mAP увеличился на 0,9%, что показывает, что модуль стебля играет важную роль в сборе глобальной информации и обучении функций.
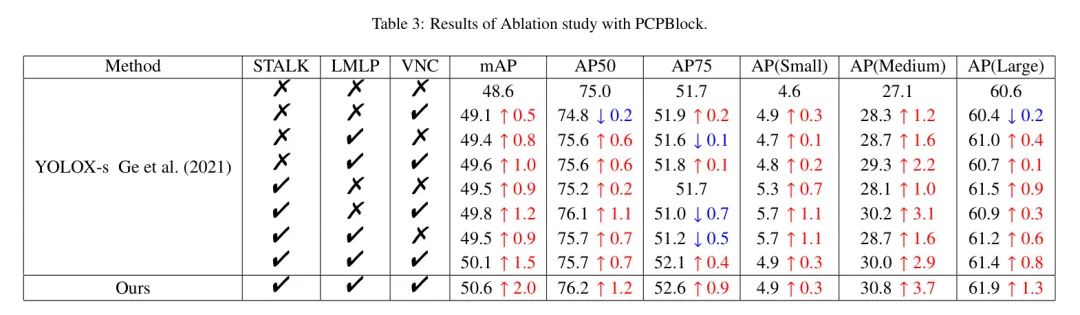
Улучшение модуля LMLP в индикаторе AP (Medium) более заметно.,увеличился на 1,6%,Это показывает, что модуль LMLP имеет преимущества при обработке локальной информации и детальных функциях. в то же время,Модуль vnc действует как мост,Органично объедините глобальную информацию модуля стебля и локальную информацию модуля LMLP.,оти进一步улучшать Модельизпроизводительность。
- Абляционное исследование модуля БАМ в соответствии Анализируя данные таблицы 4, автор может сделать вывод, что при сравнении модуля BAM и модуля CBAM модуль BAM работает лучше по индикатору mAP и индикатору AP (Medium). В частности, по сравнению с модулем CBAM модуль BAM улучшил показатель mAP на 0,2% и показатель AP (Medium) на 0,1%. Это доказывает, что модуль BAM имеет преимущества при объединении локальной и глобальной информации. в соответствии Сданные в Таблице 4, обнаружено, что если сверточная часть модуля BAM использует глубинно отделимые свертки (DWConv), его производительность будет улучшена. Глубоко отделимая свертка — это метод, который разлагает стандартные свертки на глубинные свертки и точечные свертки, что может уменьшить количество параметров и ускорить вычисления, одновременно улучшая производительность Моделипроизводительности в определенной степени.

Следовательно, используя свертки, разделяемые по глубине, в качестве сверточной части модуля BAM, можно эффективно повысить производительность модуля. Используя механизм адаптивного внимания, модуль BAM может эффективно объединять глобальную и локальную информацию, улучшать возможности представления функций и повышать производительность в компьютерных системах. зрение Задача(Например, обнаружение цели)中具有很好из应用价值。CBAMмодуль вBAM模块中添加了一индивидуальный卷积操作。Рани,По результатам эксперимента,Производительность модуля CBAM не так хороша, как у модуля BAM. Это может быть связано с влиянием модуля CBAM на размерность объекта при использовании операций свертки.
Visualization

в соответствии с Baseline и Сравнивая авторский метод и блок аннотаций, показанный на рисунке 4, автор может сделать следующие наблюдения:
Во-первых, как показано в первом ряду рисунка 4, в базовой линии имеются очевидные случаи ложного обнаружения, в то время как в авторском методе щенки успешно обнаруживаются с высокой достоверностью, что полностью иллюстрирует авторскую модель снижения ложных обнаружений. Были достигнуты значительные улучшения. сделал. Поскольку ложные обнаружения обычно являются одной из наиболее серьезных проблем в задачах обнаружения объектов, улучшения, достигнутые авторской моделью в этом отношении, имеют большое значение для практических приложений.
Во-вторых, вторая строка рисунка 4 показывает: Baseline Не все обнаруживаются полностью, но метод авторов не только обнаруживает всех, но и Baseline 检测到из人具有更高из置信度,Это показывает, что Модель авторов также достигла значительных улучшений в снижении уровня ложноположительных результатов. Ложноположительный показатель – еще одна важная проблема,Это вызывает ненужные вычисления и накладные расходы на обработку.,И может повлиять на эффективность и точность системы.
Наконец, третья строка рисунка 4 показывает: Baseline Скучаю по людям и собакам,Но метод автора успешно обнаружил людей и собак.,с высокой уверенностью,Это указывает на то, что некоторые категории не были обнаружены авторской Моделью. Эти недостатки показывают надежность и применимость авторской Модели. Суммируя,Эти визуализации наглядно демонстрируют и объясняют продуктивность автора.,И это дает автору полезное вдохновение для дальнейших исследований и разработки модели обнаружения целей.
5 Conclusion
В этом исследовании,GFPN,Усовершенствованный метод обнаружения целей,Проблема ложного обнаружения и пропущенных целей решается за счет оптимизации архитектуры PAFPN. Включает модуль PCPBlockиBAM.,Охватывайте глобальные функции и улучшайте механизмы обучения. GFPN стабильно превосходит контрольные показатели,Извлечение многомасштабных функций имеет решающее значение для точного обнаружения. PCPBlock GFPN эффективно фиксирует глобальные функции,Модуль BAM усиливает эффект обучения вниманию для получения лучшего контраста целей. экспериментально,GFPN всегда превосходит существующие методы,Обеспечивает надежное решение,Используется для борьбы с ложными обнаружениями и пропущенными целями в задачах обнаружения целей.
Будущая работа: Автор продолжит оптимизацию конструкции модулей PCPBlock и BAM, чтобы улучшить возможности глобального захвата функций и эффект взаимодействия функций. Кроме того, GFPN можно рассматривать и для других целей. зрение Задача,Например, сегментация экземпляров и отслеживание видеообъектов.,Проверить его гибкость и масштабируемость в различных сценариях.
ссылка
[1].Global Feature Pyramid Network



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
