Хэ Кайминг присоединился к Массачусетскому технологическому институту и возглавил команду, которая впервые предложила диффузионные потери, опираясь на идею диффузионной модели, чтобы заставить авторегрессионную модель отказаться от векторного квантования!

Принято считать, что модели авторегрессии для генерации изображений обычно сопровождаются обозначениями векторного квантования. Авторы заметили, что, хотя пространство дискретных значений может облегчить представление категориальных распределений, это не является обязательным требованием для авторегрессионного моделирования. В этой работе авторы предлагают использовать процесс диффузии для моделирования распределения вероятностей каждого маркера, что позволяет авторам применять модели авторегрессии в непрерывном пространстве значений. Вместо использования категориальной кросс-энтропийной потери авторы определяют функцию диффузионных потерь для моделирования вероятности каждого токена. Этот подход устраняет необходимость в маркерах дискретных значений. Авторы оценивают его эффективность в широком диапазоне ситуаций, включая стандартные модели авторегрессии и варианты генерализованной авторегрессии по маске (MAR). Устранив векторное квантование, авторский генератор изображений достигает мощных результатов, сохраняя при этом преимущество в скорости моделирования последовательностей. Авторы надеются, что эта работа простимулирует интерес к использованию авторегрессионной генерации в других областях и приложениях с непрерывными значениями.
1 Introduction
Модели авторегрессии в настоящее время являются де-факто решением для генеративных моделей обработки естественного языка. Эти модели прогнозируют следующее слово или токен в последовательности на основе предыдущего слова в качестве входных данных. Из-за дискретной природы языка входные и выходные данные этих моделей находятся в категориальном дискретнозначном пространстве. Этот общий подход привел к широко распространенному мнению, что модели авторегрессии по своей сути привязаны к дискретным представлениям.
Поэтому исследования по обобщению моделей авторегрессии на области с непрерывными значениями (особенно генерация изображений) были сосредоточены на дискретизации данных [6; 40; Общепринятой стратегией является обучение токенизатора с дискретными значениями для изображений, который включает в себя ограниченный словарный запас, полученный посредством векторного квантования (VQ) [51; 41].
Затем модели авторегрессии работают с пространствами токенов с дискретными значениями, как и их лингвистические аналоги.
В данной работе авторы стремятся ответить на следующий вопрос: «Нужно ли сочетать авторегрессионные модели с векторно-квантованными представлениями?» Авторы отмечают, что свойство авторегрессии, то есть «предсказание следующего токена на основе предыдущего токена» , не связано со значением. Неважно, дискретное оно или непрерывное. Что необходимо, так это смоделировать распределение вероятностей каждого тега, которое можно измерить с помощью функции потерь, и извлечь из него образцы. Представления дискретных значений можно удобно моделировать с помощью категориальных распределений, но концептуально это не является необходимым. Если предложены другие модели распределения вероятностей для каждого маркера, модели авторегрессии можно использовать без векторного квантования.
Основываясь на этом наблюдении, авторы предлагают моделировать распределение вероятностей каждого маркера с помощью процесса диффузии, действующего в области непрерывных значений. Методика авторов использует принципы диффузионных моделей [45; 33] для представления произвольных распределений вероятностей. В частности, метод авторов авторегрессионно прогнозирует вектор для каждой метки, который обусловлен сетью шумоподавления (например, небольшой MLP). Процесс диффузии шумоподавления позволил авторам представить основное распределение выходных данных (рис. 1). Эта небольшая сеть шумоподавления обучается с помощью авторегрессионной модели, принимая маркеры с непрерывными значениями в качестве входных и целевых значений. Концептуально этот небольшой прогноз, применяемый к каждому токену, похож на функцию потерь, используемую для измерения качества. Авторы называют эту функцию потерь «диффузионными потерями».

Подход авторов устраняет необходимость в токенизаторах с дискретными значениями. Сегментаторы векторно-квантованных слов трудно обучать, и они чувствительны к стратегиям градиентной аппроксимации. Качество их реконструкции обычно хуже, чем у их аналогов с непрерывными значениями [42]. Подход авторов позволяет авторегрессионным моделям воспользоваться преимуществами высококачественных неквантованных токенизаторов.
Чтобы расширить сферу применения, авторы дополнительно объединили стандартную модель авторегрессии (AR) [13] и модель генерации маски [4] в обобщенную авторегрессионную структуру (рис. 3); Концептуально, модель генерации маски прогнозирует несколько выходных токенов одновременно в случайном порядке, сохраняя при этом авторегрессионный характер прогнозирования следующего токена на основе известных токенов. В результате получается модель «Авторегрессия по маске» (MAR), которую можно легко использовать с диффузионными потерями.
Авторы экспериментально демонстрируют эффективность диффузионных потерь в различных случаях, включая модели AR и MAR. Это устраняет необходимость в токенизаторах векторного квантования и последовательно улучшает качество генерации. Авторскую функцию потерь можно гибко применять к разным типам токенизаторов. Кроме того, метод авторов обладает преимуществом высокой скорости моделей последовательностей. Авторская модель MAR с диффузионными потерями генерирует менее 0,3 секунды на изображение в ImageNet 256256, достигая при этом сильного FID менее 2,0. Лучшая модель автора может достигать 1,55 FID.
Эффективность подхода авторов проливает свет на малоизученную область генерации изображений: моделирование «взаимозависимости» маркеров посредством авторегрессии с одновременным моделированием распределения каждого маркера посредством диффузии. Это контрастирует с типичными моделями скрытой диффузии [42; 37], в которых процесс диффузии моделирует совместное распределение всех маркеров. Учитывая эффективность, скорость и гибкость нашего подхода, мы надеемся, что диффузионные потери будут способствовать созданию авторегрессионных изображений и распространиться на другие области будущих исследований.
2 Related Work
Модель последовательности для генерации изображений. Новаторская работа по авторегрессионным моделям изображений была проведена на последовательностях пикселей. Авторегрессия может быть реализована с помощью RNN [50], CNN [49; 7], а наиболее популярными в последнее время являются трансформаторы [36; 6]. Вдохновленное языковыми моделями, другое направление работы [51; 13; 40] моделирует изображения как токены с дискретными значениями. Авторегрессионные [13; 40] и генеративные модели по маскам [4; 29] могут работать с пространствами меток с дискретными значениями. Но дискретные маркеры трудно обучать, что в последнее время привлекает особое внимание [27; 32;
Что касается работы авторов, недавняя работа по GIFT [48] также фокусируется на маркерах непрерывных значений в моделях последовательностей. Работа как ГИВТ, так и авторов раскрывает важность и потенциал этого направления. В GIVT распределение меток представлено моделью гауссовой смеси. Он использует заранее определенное количество смесей, что может ограничивать типы распределений, которые он может представлять. Напротив, подход авторов использует эффективность диффузионных процессов при моделировании произвольных распределений.
Представляет собой диффузный процесс обучения. Процесс диффузии шумоподавления был исследован как критерий визуального обучения с самоконтролем. Например, Дифф МАЭ [53] Заменен оригинал на диффузионный декодер с шумоподавлением. MAE [21] в L2 ДАРЛ; [30] Обучение авторегрессионной модели с использованием декодера диффузионных блоков с шумоподавлением. Эти усилия в основном сосредоточены на обучении представлению, а не на создании изображений. В своих сценариях генерируют диверсификация изображения не являются целью; эти методы еще не продемонстрировали способность генерировать новые изображения с нуля. Распространение стратегического обучения. Авторские работы и стратегии распространения в области робототехники [8] концептуально связаны. В таких случаях _примите меры_ Распределение формулируется как процесс шумоподавления, наблюдаемый роботом, и может быть пиксельным или скрытым представлением. [8; 34]. При создании изображений авторы могут рассматривать создание разметки как «действие». Несмотря на эту концептуальную связь, разнообразие образцов, созданных в области робототехники, не так разнообразно, как основные соображения по созданию изображений.
ПРИМЕЧАНИЕ. Раздел формулы остается в соответствии с вашим запросом, исходным выводом, непереведенным.
3 Method
Таким образом, подход авторов к генерации изображений представляет собой модель последовательности, работающую на токенизированном скрытом пространстве [6; 40]. Но в отличие от предыдущих подходов, основанных на тэгерах с векторным квантованием (например, варианты VQ-VAE [51; 13]), авторы стремятся использовать тэгеры с непрерывными значениями (например, [42]). Авторы предлагают диффузионные потери, которые делают модели последовательностей совместимыми с непрерывно оцениваемыми маркерами.
Rethinking Discrete-Valued Tokens
Авторы сначала рассматривают роль маркеров дискретных значений в авторегрессионных генеративных моделях. Используйте для указания следующей позиции, которую нужно спрогнозировать. GT отметка. С помощью дискретного токенизатора его можно выразить в виде целого числа: $0\leq. x<k$,в Размер словарного запасадля$k$。авторегрессионный Модельпроизводит непрерывное значение$d$размерный вектор$z\in\mathbb{r}^{d}$,а затем передать$k$Матрица классификатора дорог$w\in\mathbb{r}^{k\times></k$,в Размер словарного запасадля$k$。авторегрессионный Модельпроизводит непрерывное значение$d$размерный вектор$z\in\mathbb{r}^{d}$,а затем передать$k$Матрица классификатора дорог$w\in\mathbb{r}^{k\times>
В контексте генеративного моделирования это распределение вероятностей должно проявлять два фундаментальных свойства. Во-первых, функция потерь может измерять разницу между предполагаемым распределением и истинным распределением. В случае категориальных распределений это можно сделать просто за счет потери перекрестной энтропии. Во-вторых, сэмплер может извлекать выборки из распределения во время вывода. В случае категориального распределения это обычно реализуется путем отбора из него выборок, где – температурный параметр, управляющий разнообразием выборок. Выборка из категориальных распределений может быть достигнута с помощью метода максимума Гамбеля [18] или выборки с обратным преобразованием.
Этот анализ показывает, что маркеры дискретных значений не нужны для авторегрессионных моделей. Скорее, моделирование распределения необходимо по своей сути. Пространство меток с дискретными значениями подразумевает категориальное распределение, функция потерь и выборка которого легко определяются. Что на самом деле нужно авторам, так это функция потерь для моделирования распределения и соответствующий ей сэмплер.
Diffusion Loss
Модель диффузии с шумоподавлением [24] обеспечивает эффективную основу для моделирования произвольных распределений. Но в отличие от обычного использования модели диффузии для представления совместного распределения всех пикселей или всех токенов, в случае автора модель диффузии используется для представления распределения каждого токена.
Рассмотрим вектор непрерывных значений, который представляет токен GT, который будет предсказан в следующей позиции. Модель авторегрессии создает вектор в этом месте. Авторы стремятся смоделировать условные распределения вероятностей с точки зрения , т.е. Функция потерь и сэмплер могут быть заданы в соответствии с определением диффузионной модели [24; 33 10], которое описано ниже;
функция потерь. Согласно [24; 33; 10], функция потерь основного распределения вероятностей может быть выражена как критерий шумоподавления:
здесь, из Вектор шума, извлеченный из . Векторы, загрязненные шумом для ,в Определите план борьбы с шумом [24; 33]。 – временной шаг графика шума. оценщик шума , по параметрам Control – небольшая сеть MLP (см. раздел 4). символ Указывает, что эта сеть Введите для и условие включения и . в соответствии с [46; 47], уравнение (1) Концептуально похоже на форму дробного сопоставления: оно связано с связано с функцией потерь дробной функции, то есть . Диффузионные потери — это параметризованная функция потерь, которая аналогична состязательным потерям. [15] или воспринимаемая потеря [56] похожий.
Стоит отметить, что вектор состояния генерируется авторегрессионной сетью: автор обсудит это позже. Градиент из уравнения (1) в функции потерь распространяется. Концептуально уравнение (1) Определяет сеть для обучения сети функция потерь.
Автор отмечает, что уравнение (1) в Ожидания речь идет о , для любого заданного . Поскольку авторская сеть шумоподавления меньше, автор может для любого заданного множественная выборка . Это помогает улучшить использование функции потерь без необходимости ее повторного расчета. . Во время обучения автор пробует каждое изображение 4 раза.
пробоотборник. Во время вывода необходимо извлечь образцы из распределения. Отбор проб осуществляется методом обратной диффузии [24]: . Здесь, полученный из распределения Гаусса, показан уровень шума на временном шаге. Начиная с , этот процесс создает образец такой, что [24].
При использовании категориальных распределений (раздел 3.1) авторегрессионные модели могут воспользоваться преимуществом контроля температуры разнообразия выборки. Действительно, существующая литература показывает, что температура играет ключевую роль в авторегрессионной генерации, как в языке, так и в изображениях. Авторы надеются, что диффузионный пробоотборник станет температурным аналогом. Авторы приняли температурную дискретизацию, предложенную в [10]. Концептуально, при использовании температуры можно было бы захотеть сделать выборку из (перенормированных) вероятностей, чья оценочная функция равна . На практике [10] рекомендует делить на или масштабировать шум на . Автор выбрал последний вариант: я нажал Zoom в сэмплере. Интуитивно понятно, что разнообразие выборки контролируется путем регулировки дисперсии шума.
Diffusion Loss for Autoregressive Models
Далее авторы описывают авторегрессионную модель с диффузионными потерями для генерации изображений. Дана последовательность токенов ,в надстрочный индекс Указан порядок, авторегрессионная модель [17; 50; 49; 36; 7; 6] Сгенерирует формулировку задачи для «предсказания следующего токена»:
Используйте сеть для представления условных вероятностей . В случае автора, Может непрерывно оцениваться. Автор может переписать эту формулу на две части. Сначала автор проходит сеть (например, Трансформер [52]) оперирует предыдущей меткой для создания вектора состояния :. Затем автор проходит Вероятность следующего токена в модели. уравнение (1) в Диффузионные потери могут быть применены . Градиент передается обратно в обновить параметры.
Unifying Autoregressive and Masked Generative Models
Автор показывает такие примеры, как MaskGIT [4]иMAGE [29] и тому подобное Mask Генеративные модели можно обобщить в рамках широкой концепции авторегрессии, то есть прогнозирования следующего токена.
Двунаправленное внимание может выполнять авторегрессию. Концепция авторегрессии ортогональна сетевой архитектуре: авторегрессия может быть достигнута с помощью RNN. [50]、CNNs [49; 7]иTransformers [38; 36; 6] для завершения. Хотя авторегрессионные модели обычно реализуются посредством каузального внимания, авторы показывают, что при использовании Трансформеров их можно реализовать и с помощью двунаправленного внимания. См. рисунок 2. Важно отметить, что цель авторегрессии состоит в том, чтобы предсказать следующий токен на основе предыдущего токена; она не ограничивает способ взаимодействия предыдущего токена со следующим.
Авторы могут использовать такие методы, как Masked Autoencoder (MAE) Реализация двунаправленного внимания показана в [21]. См. рисунок 2(б). В частности, авторы сначала применяют кодер 1 в стиле MAE (с позиционными вложениями [52]) к известным токенам. Затем автор сравнивает закодированную последовательность с Mask Токены (опять же плюс позиционные вложения) объединяются, и эта последовательность отображается с помощью декодера в стиле MAE. Mask Встраивание позиций в маркеры позволяет декодеру знать, какие позиции необходимо предсказать.。В отличие от причинного внимания,Потери здесь рассчитываются только по неизвестным маркерам [21]. Используйте советы по стилю MAE,Автор разрешает _все_ известным тегам видеть друг друга,Также позволяет всем неизвестным маркерам видеть все известные маркеры. Такое «полное внимание» обеспечивает лучший эффект при общении между токенами, чем причинное внимание. в рассуждениях,Авторы могут использовать эту двустороннюю формулу для генерации токенов (один или несколько за шаг).,Это форма авторегрессии. пойти на компромисс,Авторы не смогли использовать кэш «ключ-значение» (kv) каузального внимания [44] для ускорения вывода. Но так же, как автор может генерировать несколько тегов одновременно,Авторы могут сократить этапы генерации, чтобы ускорить вывод. Полное внимание между маркерами может значительно улучшить качество,и обеспечивает лучший компромисс между скоростью и точностью.
Авторегрессионная модель в случайном порядке. для с Mask Генеративная модель[4, 29]связанный,Авторы рассмотрели вариант авторегрессии в рандомизированном порядке. Модель получает случайно расположенную последовательность. Это случайное расположение различно для каждого образца. См. рисунок 3(б). в этом случае,Местоположение следующего прогнозируемого маркера должно быть доступно Модели. Авторы применяют стратегию, аналогичную MAE [21]: авторы добавляют встраивание позиций на уровень декодирования (соответствующее неперетасованным позициям).,Это сообщает Модели, какие позиции прогнозировать. Эта стратегия работает в причинно-следственной и двунаправленной версии.
Как показано на рисунке 3(b)(c), ряд стохастической последовательной авторегрессии похож на специальную маску.
** Mask Авторегрессионная модель**. существовать Mask Генеративное моделирование [4,29], Модель прогнозирует случайное подмножество токенов на основе известных/прогнозированных токенов. Это можно сформулировать как: — упорядочивает последовательность токенов в случайном порядке, а затем прогнозирует несколько токенов на основе предыдущих токенов. См. рисунок 3(c). Концептуально это авторегрессионный процесс, который можно записать как оценку условного распределения:,в Несколько тегов для прогнозирования (). Автор может записать эту авторегрессионную модель как:
(
здесь, Это в первом На этом этапе необходимо спрогнозировать набор маркеров, и существует . В этом смысле это, по сути, «предсказание следующей группы тегов» и, следовательно, общая форма авторегрессии. Автор называет этот вариант Mask Авторегрессия (в маске) Авторегрессионная модель (сокращенно MAR). МАР представляет собой рандомизированную последовательную авторегрессионную модель, которая может прогнозировать несколько маркеров одновременно. МАР Концептуально с MAGE [29] Связанный. Однако МАР Путем применения температуры к распределению вероятностей каждого маркера для выборки маркеров (это что-то вроде GPT Традиционная практика таких генеративных языковых моделей). Напротив, MAGE (вслед за MaskGIT [4]) для прогнозирует местоположение маркера путем выборки температуры приложения: это не полностью случайный порядок, что приводит к различию между строками для во время обучения и времени вывода. выполнить
В этом разделе описана авторская реализация. Авторы отмечают, что концепции, представленные в данной статье, носят общий характер и не ограничиваются конкретной реализацией. Более подробная информация представлена в Приложении Б.
Diffusion Loss 2024-06-23-03-52-26
процесс диффузии. Процесс диффузии авторов следует [33]. Авторский график шума имеет косинусоидальную форму.,Во время обучения выполняется 1000 шагов;,Повторная выборка за меньшее количество шагов(по умолчаниюдля100шаги)[33]。Авторское шумоподавлениесеть Вектор шума прогнозирования [двадцать четыре]. Функция потерь может дополнительно содержать вариационную нижнюю границу. [33]. Потери на диффузию естественным образом поддерживают руководство без классификаторов (CFG) [23] (подробности см. в Приложении B).
Шумоподавление MLP. Для шумоподавления авторы используют небольшой MLP, состоящий из нескольких остаточных блоков [20]. Нормализация уровня (LN) применяется последовательно для каждого блока [1].,линейный слой,SiLU[12],и еще линейный слой,и объединены посредством остаточных связей. По умолчанию,Автор использует ширину в 3 блока и 1024 канала. Шумоподавление MLP основано на векторах, сгенерированных AR/MARModel (см. рисунок 1). Векторы добавляются к временному внедрению временного шага планирования шума.,Это делается AdaLN [37] как условие дляMLP на уровне LN.
Autoregressive and Masked Autoregressive Image Generation
Токенизатор. Автор использовал ЛДМ Публичный токенизатор, предоставленный [42]. В экспериментах автора будут задействованы их варианты VQ-16иKL-16 [42]. VQ-16 — это VQ-GAN [13], то есть VQ-VAE [51] с потерей GAN [15] и перцептивной потерей [56] — его соответствующая версия по Кульбаку-Лейблеру (KL). Дивергенция — это регуляризованный без вектора Количественная оценка. 16 представляет размер шага токенизатора.
Трансформатор. Архитектура автора соответствует реализации ViT[11]вTransformer[52]. Учитывая последовательность токенов из токенизатора,Авторы добавляют позиционные вложения [52] и теги категорий [cls] в начале последовательности, затем последовательность обрабатывается через преобразователь; По умолчанию,Авторский Трансформер имеет ширину 32 блока и 1024.,Автор называет его для больших (-L) (около 400M параметров).
**Авторегрессия Baseline **. Причинное внимание следует общепринятой практике GPT [38] (рис. 2(а)). Входная последовательность сдвигается на маркер (здесь для[cls]). треугольник Mask [52] была применена к матрице внимания. Во время вывода применяется выборка температуры (τ). Авторы используют kv-кэш [44] для эффективного вывода.
** Mask Авторегрессионная модель**. Используя двунаправленное внимание (рис. 2(б)), мы можем предсказать любое количество неизвестных тегов на основе любого количества известных тегов. Во время обучения автор находится в [0.7, Случайная выборка в диапазоне 1,0] Mask Соотношение[21, 4, 29]: Например, 0,7 означает, что 70% маркеров неизвестны. Поскольку выборочные последовательности могут быть очень короткими, мы всегда добавляем 64 токена [cls] в начало последовательности кодера, что повышает стабильность и производительность нашего кодирования. Как показано на рисунке 2, введенный в декодер Mask отметка[м],и добавьте встраивание местоположения. для простоты,Отличие от [21],Авторы сделали кодер и декодер одного размера: в каждом по половине всех блоков (например,,В MAR-L для16).
Во время вывода MAR выполняет «следующий набор прогнозов токенов». Он постепенно снижает коэффициент Маски от 1,0 до 0 по косинусному графику [4, 29]. По умолчанию автор использует в этой программе 64 шага. Примените отбор проб температуры (τ). В отличие от [4, 29], MAR всегда использует полностью случайный порядок.
5 Experiments
Автор есть на ImageNet [9] Эксперименты проводились на наборе данных с разрешением 256×256. Авторы оценили FID [22] иIS [43] и обеспечивать точность и отзыв в виде форссылки на основе общепринятой практики [10]. Авторы следовали набору оценок, представленному в [10].
Properties of Diffusion Loss
Сравнение диффузионных потерь и кросс-энтропийных потерь. Авторы сначала сравнили непрерывную маркировку с использованием диффузионных потерь со стандартной дискретной маркировкой с использованием перекрестной энтропийной потери (таблица 1). Для честного сравнения два токенизатора («VQ-16» и «CL-16») были загружены из кодовой базы LDM [42]. (например, [13, 42, 37]).
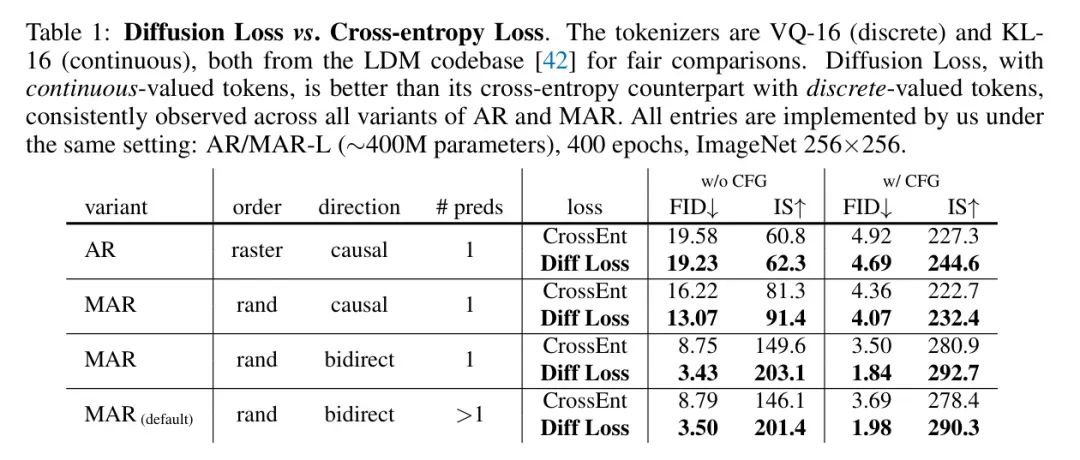
Сравнение проводилось среди четырех вариантов AR/MAR. Как показано в Таблице 1,во всех случаях,Диффузионные потери всегда лучше, чем потери перекрестной энтропии. в частности,В MAR (напр.,настройка по умолчанию),Использование диффузионных потерь может относительно снизить FID примерно на 50–60%. Это связано с тем, что KL-16 при непрерывных значениях имеет меньшие потери на сжатие, чем VQ-16 (обсуждается в Таблице 2 ниже).,А еще потому, что процесс диффузии моделирует распределение более эффективно, чем процесс классификации.
В следующих исследованиях абляции авторы следовали настройкам MAR «по умолчанию», указанным в Таблице 1, если не указано иное.
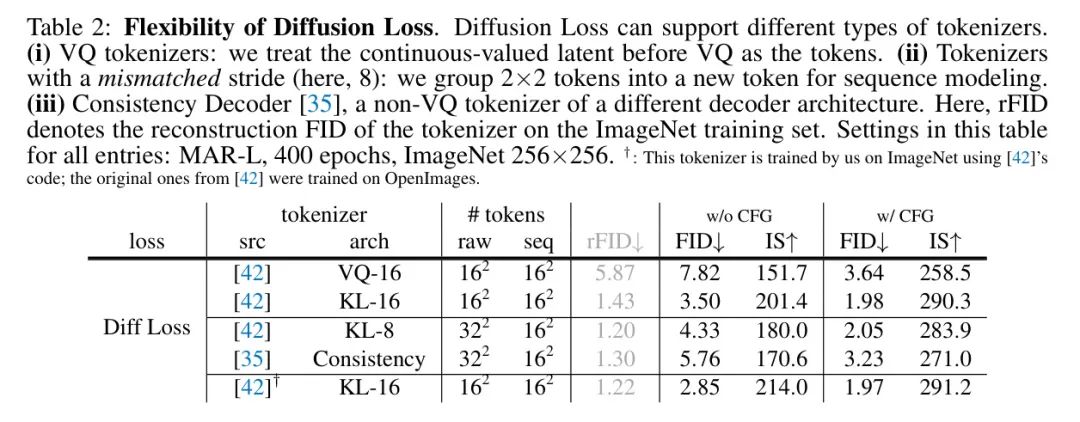
Диффузия теряет гибкость. Существенным преимуществом диффузионных потерь является то, что они работают с различными токенизаторами. Авторы сравнивают несколько общедоступных токенизаторов в таблице 2.
Даже при наличии токенизатора VQ можно легко использовать диффузионные потери. Авторы просто рассматривают потенциальные теги с непрерывным значением перед слоем VQ как теги для. Этот вариант дал автору 7,82 FID (безCFG), 8,79 с потерей перекрестной энтропии с использованием того же токенизатора VQ Po сравнение с FID (таблица 1) производительность хорошая. моделирует распределение.
Этот вариант также позволяет авторам сравнивать токенизаторы VQ-16 и KL-16 с одинаковыми потерями. Как показано в Таблице 2,У VQ-16 реконструированный ПИД (rFID) гораздо хуже, чем у KL-16.,Это также приводит к образованию FID (например,,поверхность2в7.82 vs 3.50) гораздо хуже.
интересная вещь,Диффузионные потери также позволяют авторам использовать токенизаторы с несовпадающими размерами шагов. В таблице 2,Автор изучил размер шага для8,Токенизатор KL-8 с длиной выходной последовательности 32×32. без увеличения длины порождающей последовательности,Автор объединяет маркеры 2×2 в новый маркер. Хотя размер шага не соответствует,Автор все еще может получить хорошие результаты,Например,КЛ-8 принес автору 2,05 FID, а КЛ-16 – 1,98 FID. также,Эта функция позволяет автору изучать другие токенизаторы.,Напримерпоследовательный декодер[35],Это токенизатор, отличный от VQ, с другой архитектурой/размером шага.,Специально разработан для разных целей.
для полноты,Автор также обучил токенизатор KL-16 на ImageNet, используя код [42],Обратите внимание [42], что исходный KL-16 был обучен на OpenImages [28]. Сравнение находится в последней строке таблицы 2. Автор будет использовать этот токенизатор в следующих исследованиях.
Диффузионные потерившумоподавлениеMLP。作者在поверхность3середина研究了шумоподавлениеMLP。даже очень маленькийMLP(Например,2M) также может обеспечить конкурентоспособные результаты. как и ожидалось,Увеличение ширины MLP помогает улучшить качество генерации. Авторы также исследовали увеличение глубины и наблюдали аналогичную ситуацию; пожалуйста, обрати внимание,Размер MLP автора по умолчанию (ширина 1024,21M) Только дляMAR-LМодель добавляет около 5% дополнительных параметров. во время рассуждений,Общие затраты на эксплуатацию диффузионного пробоотборника умеренные.,Около 10%. В авторской реализации,Увеличение ширины MLP практически не требует дополнительных затрат (таблица 3).,Частично причина в том, чтодля Основные расходы неречь идет о Вычисления, но обмен данными с памятью.
Процедура отбора проб для диффузионных потерь. Наш процесс диффузии следует общепринятой практике DDPM [24, 10]: мы используем шумовой график из 1000 шагов для обучения, но используем меньшее количество шагов для вывода. На рисунке 4 показано, что использования 100 шагов диффузии во время вывода достаточно для достижения высокого генеративного качества.
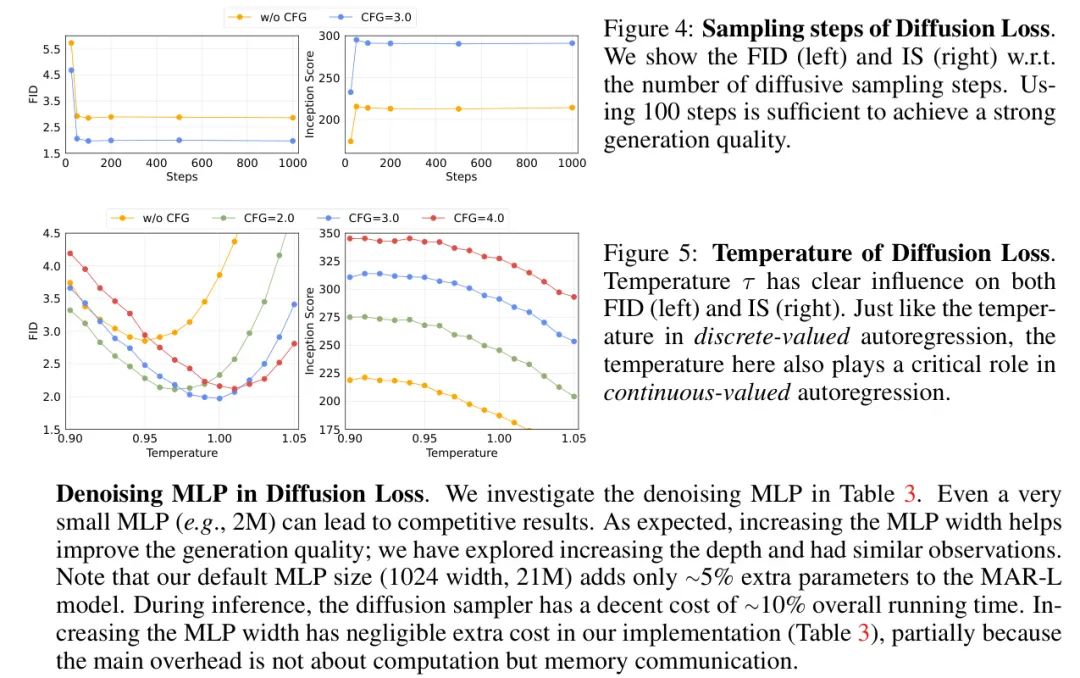
Температура диффузионных потерь. В случае потери перекрестной энтропии,Температура имеет решающее значение. Диффузионные потери также являются температурным аналогом, который контролирует разнообразие и точность воспроизведения. На рисунке 5 показано влияние температуры τ в диффузионном пробоотборнике во время вывода (см. раздел 3.2). Температура τ играет важную роль в авторской Модели.,Аналогичные наблюдения сделаны для аналогов, основанных на кросс-энтропии (обратите внимание на таблицу 1, где результаты кросс-энтропии приведены при оптимальной температуре).
Properties of Generalized Autoregressive Models
От АР до МАР. Таблица 1 также представляет собой сравнение вариантов AR/MAR.,Об этом автор говорит далее. первый,Замена порядка растра ARв на для_random_order может принести значительную выгоду.,Например,FID уменьшен с 19.23 до 13.07 без CFG. Следующий,Замена причинного внимания двунаправленным вниманием приводит к еще одному огромному выигрышу.,Например,FID уменьшен с 13.07 до 3,43 без CFG.
Двусторонняя AR со случайной последовательностью по сути является формой MAR.,一次预测一个отметка。Прогнозируйте на каждом этапе_Несколько_отметка('>1')可以有效地减少авторегрессионный步骤的数量。在поверхность1середина,Авторы показывают, что вариант MAR из 64 шагов немного жертвует качеством генерации. Далее обсуждается более полное сравнение компромиссов.
Компромисс скорости/точности. Следуя MaskGIT [4], авторский MAR обладает гибкостью прогнозирования нескольких тегов одновременно. Это контролируется количеством шагов авторегрессии в выводе. На рис. 6 показан компромисс между скоростью и точностью. У MAR лучшие компромиссы, чем у AR с эффективным kv-кешем.
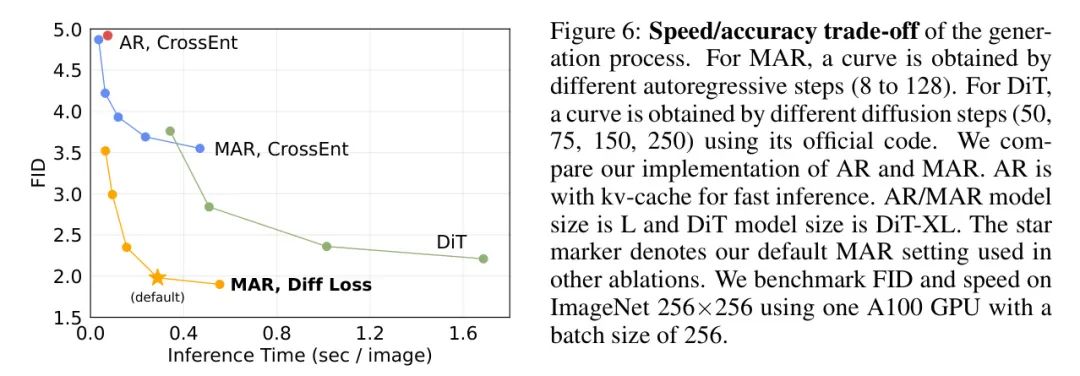
При диффузионных потерях с использованием недавно популярной технологии Diffusion Transformer (DiT) [37]по сравнению с,MAR также демонстрирует выгодные компромиссы. что касается потенциальной диффузии Модель,DiT моделирует взаимозависимость между всеми маркерами посредством процесса диффузии. Соотношение скорости и точности DiT в первую очередь определяется шагом его распространения. Отличается от авторского процесса распространения небольших MLP.,Процесс распространения DiT включает в себя всю архитектуру Transformer. Авторский метод более точный и быстрый. Стоит отметить, что,Авторский метод можно усилитьFID(<2.0)Каждое изображение ниже меньше, чем0.3Генерация за секунды。
Benchmarking with Previous Systems
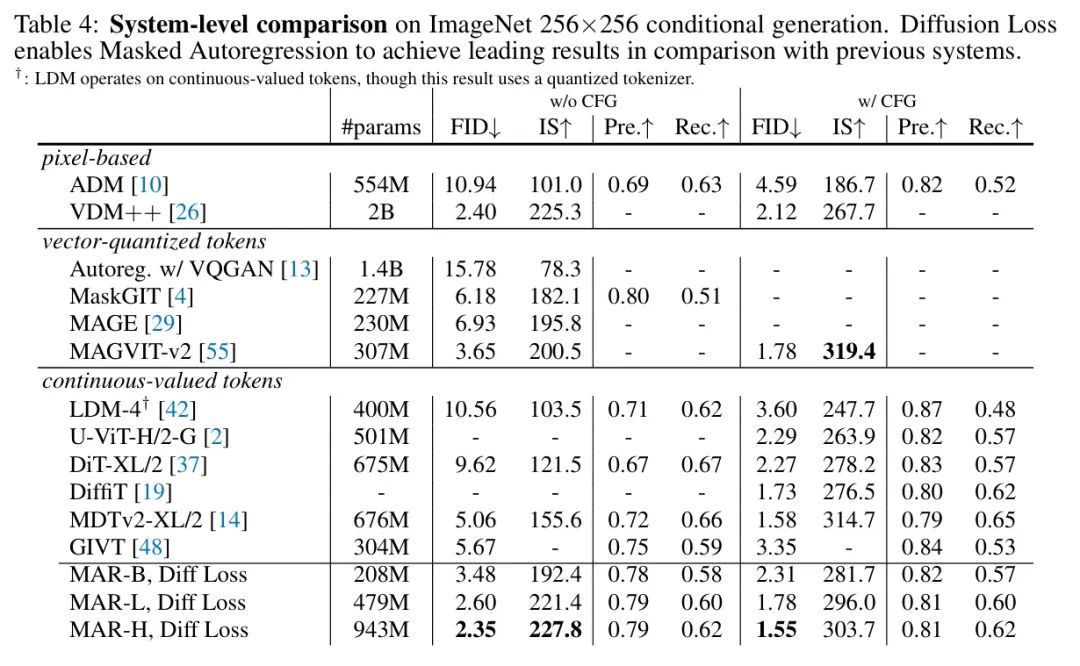
Авторы сравнивают с современными системами в Таблице 4. Автор исследовал различные размеры моделей (см. Приложение Б).,и обучался 800 эпох. Аналогично авторегрессионному языку Модель[3],Автор заметил вдохновляющую строку Увеличить для. Дальнейшие исследования увеличения могут оказаться многообещающими. По показателям,Авторы сообщают о FID 2,35 без CFG.,Значительно превосходит другие методы на основе маркеров. Лучший результат автора — FID 1,55.,и работает хорошо по сравнению с современными системами. На рисунке 7 показаны качественные результаты.

6 Discussion and Conclusion
Эффективность диффузионных потерь в различных моделях авторегрессии открывает новые возможности: моделирование взаимозависимости между маркерами посредством авторегрессии и одновременное моделирование распределения каждого маркера посредством диффузии. Это отличается от общепринятой практики моделирования совместного распределения всех маркеров посредством диффузии.
Мощные результаты авторов по созданию изображений демонстрируют, что модели авторегрессии или их расширения являются мощными инструментами, выходящими за рамки языкового моделирования.
Эти модели не обязательно ограничиваются представлением векторного квантования.
Авторы надеются, что их работа вдохновит исследовательское сообщество на изучение моделей последовательностей с непрерывными представлениями в других областях.
ссылка
[1].Autoregressive Image Generation without Vector Quantization.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
