GPT-4V может занять только второе место! Университет Хуаке и другие выпустили новый эталон для мультимодальных больших моделей: комплексная оценка 14 моделей для пяти основных задач.
Новый отчет мудрости
Монтажер: LRS Так хочется спать
【Шин Джиген Введение】Хуачжунский университет науки и технологий и Южно-Китайский технологический университет、Исследователи из Университета науки и технологий Пекина и других учреждений14основной мультимодальный транспорт Модель Провел комплексную проверку,Охватывает 5 задач,27индивидуальныйданныенабор。
Недавно большие мультимодальные модели (LMM) продемонстрировали впечатляющие возможности в задачах визуального языка. Однако из-за открытости ответов на мультимодальные большие модели то, как точно оценить производительность всех аспектов мультимодальных больших моделей, стало актуальной проблемой, которую необходимо решить.
В настоящее время некоторые методы используют GPT для оценки ответов, но существуют проблемы с неточностью и субъективностью. Другие методы используют вопросы «верно-неверно» и с несколькими вариантами ответов для оценки возможностей мультимодальных больших моделей.
Однако вопросы «верно-неверно» и с множественным выбором выбирают только лучший ответ из серии эталонных ответов и не могут точно отражать способность мультимодальных больших моделей полностью распознавать текст на изображениях. В настоящее время оптическое распознавание символов отсутствует ( OCR) для мультимодальных больших моделей. Специализированные тесты оценки способностей.
Недавно команда Бай Сяна из Хуачжунского университета науки и технологий и исследователи из Южно-Китайского технологического университета, Пекинского университета науки и технологий, Китайской академии наук и Microsoft Research провели углубленное исследование возможностей оптического распознавания мультимодальных больших модели.
Пять задач: распознавание текста, VQA текста сцены, VQA документа, извлечение ключевой информации и распознавание рукописных математических выражений были выполнены на 27 общедоступных наборах данных и 2 сгенерированных наборах семантических и контрастных семантических данных.

Ссылка на статью: https://arxiv.org/abs/2305.07895.
Адрес кода: https://github.com/Yuliang-Liu/MultimodalOCR
Чтобы удобно и точно оценить возможности оптического распознавания мультимодальных больших моделей, в этой статье дополнительно создается OCRBench, наиболее полный тест оценки в текстовом поле для проверки способности мультимодальных больших моделей к обобщению с нулевой выборкой, а также оценивается Google Gemini, OpenAI GPT4V. Помимо множества мультимодальных больших моделей, подобных GPT4V, которые в настоящее время имеют открытый исходный код, он раскрывает ограничения прямого применения мультимодальных больших моделей в области оптического распознавания символов.
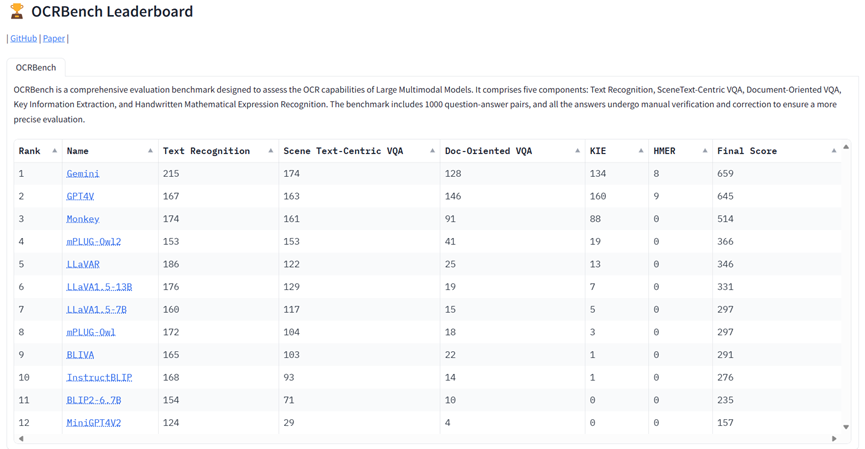
Обзор модели оценки
В этой статье оцениваются 14 мультимодальных больших моделей, включая Google Gemini и OpenAI GPT4V.
Среди них BLIP2 представил Q-Former для соединения визуальных и языковых моделей; Flamingo и OpenFlamingo представили новые закрытые слои перекрестного внимания, позволяющие большим языковым моделям понимать визуальный ввод; LLaVA впервые применила GPT-4 для создания мультимодальных инструкций; data и его продолжение, LLaVA1.5, еще больше повышают производительность LLaVA за счет улучшения уровня выравнивания и дизайна подсказок.
Кроме того, mPLUG-Owl и mPLUG-Owl2 подчеркивают модальное взаимодействие изображений и текста; LLaVAR собирает насыщенные текстом обучающие данные и использует CLIP с более высоким разрешением в качестве визуального кодировщика для расширения возможностей OCR LLaVA.
BLIVA сочетает в себе функции распознавания инструкций и глобальные визуальные функции для сбора более подробной информации об изображениях; MiniGPT4V2 использует уникальные идентификаторы для различных задач при обучении модели, чтобы легко различать инструкции для каждой задачи; UniDoc работает с крупномасштабным набором данных отслеживания инструкций. Выполнение унифицированных мультимодальных инструкций; тонкая настройка и использование выгодных взаимодействий между задачами для повышения производительности отдельных задач.
Docpedia обрабатывает визуальный ввод непосредственно в частотной области, а не в пространстве пикселей. Monkey повышает детализацию LMM при небольших затратах, генерируя данные подробного описания и архитектуру модели с высоким разрешением.
Показатели оценки и наборы данных оценки
Ответы, генерируемые LMM, часто содержат множество пояснительных высказываний, поэтому полное точное соответствие или среднее нормализованное сходство Левенштейна (ANLS) не подходят при оценке производительности LMM в сценариях Zero-Shot.
В этой статье определяется единый и простой критерий оценки для всех наборов данных, то есть для определения того, содержит ли вывод LMM GT, чтобы уменьшить количество ложных срабатываний, в этой статье дополнительно отфильтровываются все пары вопросов и ответов с ответами менее 4 символов; .
Распознавание текста
В этой статье LMM оценивается с использованием широко распространенного набора данных для распознавания текста OCR. Эти наборы данных включают в себя:
(1) Обычное распознавание текста: IIIT5K, SVT, IC13;
(2) Распознавание нестандартного текста: IC15, SVTP, CT80, COCOText (COCO), SCUT-CTW1500 (CTW), Total-Text (TT);
(3) Распознавание текста в сценах окклюзии, WOST и HOST;
(4) Распознавание художественного слова: WordArt;
(5) Распознавание рукописного текста: IAM;
(6) Китайское признание: ReCTS;
(7) Распознавание рукописных цифр: ORAND-CAR-2014 (CAR-A);
(8) Свободный от семантики текст (NST) и семантический текст (ST): набор данных ST содержит 3000 изображений слов из словаря IIIT5K. Разница между набором данных NST и набором данных ST заключается в порядке символов в словаре. Слова нарушены. Смысловой смысл отсутствует.
Для распознавания английских слов в этой статье используется единая подсказка: «что написано на изображении?». Для текста на китайском языке в наборе данных ReCTS используйте в качестве подсказки «Какие китайские иероглифы изображены на изображении?». Для рукописных строк цифр используйте подсказку: «Какое число на изображении?».
Текст-ориентированный VQA сцены
В этой статье проводятся эксперименты с STVQA, TextVQA, OCRVQA и ESTVQA. Набор данных ESTVQA разделен на ESTVQA(CN) и ESTVQA(EN), которые содержат пары вопросов и ответов на китайском и английском языках соответственно.
Документоориентированный VQA
В этом документе оцениваются наборы данных DocVQA, InfographicVQA и ChartQA, включая отсканированные документы, сложные плакаты и диаграммы.
Извлечение ключевой информации (KIE)
В этой статье проводятся эксперименты с наборами данных SROIE, FUNSD и POIE, которые включают квитанции, формы и этикетки с пищевой ценностью продуктов. KIE требует извлечения пар ключ-значение из изображений.
Чтобы LMM мог точно извлечь правильное значение заданного ключа в наборе данных KIE, в этой статье разработаны разные подсказки для разных наборов данных.
Для набора данных SROIE в этой статье используются следующие подсказки, которые помогут LMM сгенерировать соответствующие значения для «компании», «даты», «адреса» и «итого»: «как называется компания, выдавшая эту квитанцию?» «, «когда была выдана эта квитанция?», «где была выдана эта квитанция?» и «какова общая сумма этой квитанции?».
Кроме того, чтобы получить значение, соответствующее данному ключу в FUNSD и POIE, в этой статье используется подсказка: «Каково значение для '{key}'?».
Распознавание рукописных математических формул (HMER)
Набор данных HME100K был оценен. В процессе оценки в этой статье в качестве подсказки используется фраза «Запишите выражение формулы на изображении, используя формат LaTeX».
Результаты оценки
LMM достигает производительности, сравнимой с Supervised-SOTA, при идентификации обычного текста, нерегулярного текста, текста в сценах окклюзии и WordArt.
Производительность InstructBLIP2 и BLIVA даже превосходит Supervised-SOTA в наборе данных WordArt, но LMM по-прежнему имеет серьезные ограничения.
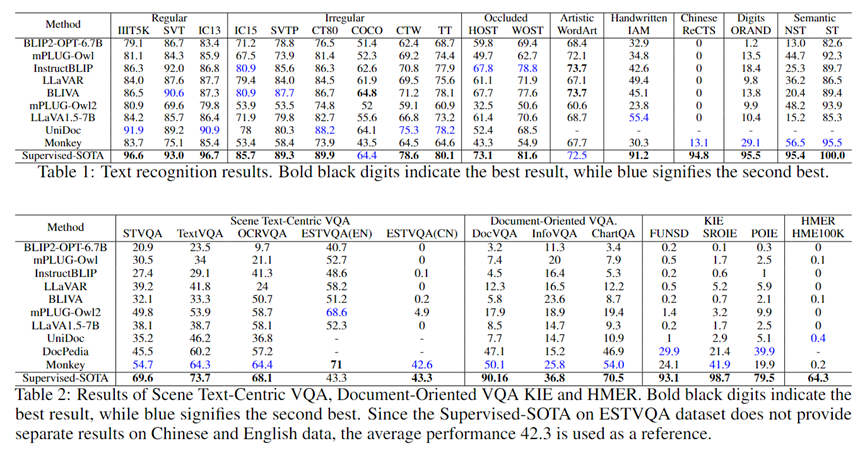
Семантические зависимости
LMM демонстрируют плохую производительность распознавания при определении комбинаций символов, которым не хватает семантики.
В частности, точность LMM в наборе данных NST упала в среднем на 57,0% по сравнению с набором данных ST, тогда как точность Supervised-SOTA снизилась всего примерно на 4,6%.
Это связано с тем, что Supervised-SOTA для распознавания текста сцены напрямую распознает каждый символ, а семантическая информация используется только для облегчения процесса распознавания, в то время как LMM в основном полагаются на семантическое понимание для распознавания слов.
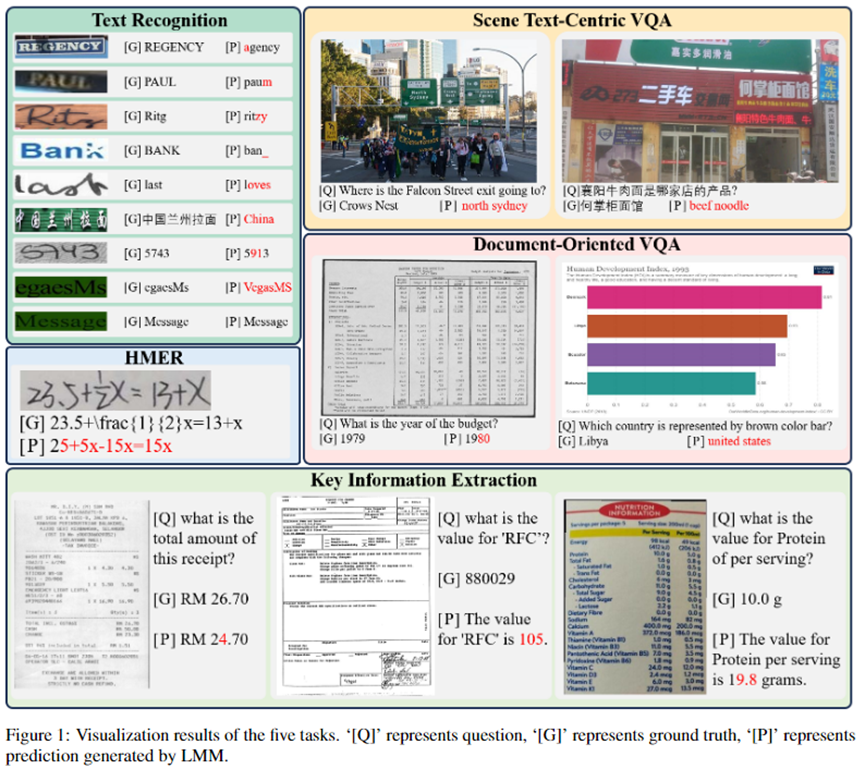
Например, на рисунке 1 LMM успешно распознал слово «Сообщение», но неправильно распознал «egaesMs», что представляет собой просто изменение порядка слова «Сообщение».
- рукописный текст
У LMM есть проблемы с точным распознаванием рукописного текста. Рукописный текст часто выглядит неполным или размытым из-за таких факторов, как быстрое письмо, неровный почерк или некачественная бумага. В среднем LMM справляются с этой задачей на 51,9% хуже, чем Supervised-SOTA.
- Многоязычный текст
Значительный разрыв в производительности, наблюдаемый в ReCTS, ESTVQA(En) и ESTVQA(Ch), демонстрирует недостатки LMM в распознавании китайского текста и ответах на вопросы. Это может быть связано с отсутствием данных по обучению на китайском языке. Языковая модель и визуальный кодер Monkey были обучены на большом объеме данных на китайском языке, поэтому они работают лучше, чем другие мультимодальные большие модели, на китайских сценах.
- Тонкое восприятие.
В настоящее время разрешение входного изображения большинства LMM ограничено 224 x 224, что соответствует входному размеру визуального кодировщика, используемого в их архитектуре. Однако входные изображения с высоким разрешением могут захватывать больше деталей изображения и, таким образом, предоставлять более детальную информацию. Из-за ограниченного входного разрешения LMM, таких как BLIP2, их способность извлекать детальную информацию в таких задачах, как ответы на вопросы по тексту сцены, ответы на вопросы о документах и извлечение ключевой информации, является слабой. Напротив, мультимодальные большие модели с более высоким разрешением ввода, такие как Monkey и DocPedia, имеют лучшую производительность в этих задачах.
- HMER
LMM создают большие проблемы с распознаванием рукописных математических выражений. В основном это вызвано неряшливыми рукописными символами, сложной пространственной структурой, непрямым представлением LaTeX и отсутствием обучающих данных.
OCRBench
Полная оценка всех наборов данных может занять много времени, а неточные аннотации в некоторых наборах данных делают оценки, основанные на точности, менее точными.
Учитывая эти ограничения, в этой статье дополнительно создается OCRBench для удобной и точной оценки возможностей оптического распознавания символов LMM.

OCRBench содержит 1000 пар вопросов-ответов для пяти задач: распознавание текста, ответы на вопросы по тексту сцены, ответы на вопросы по документам, извлечение ключевой информации и распознавание рукописных математических выражений.
Для задачи KIE в эту статью дополнительно добавлено «Ответьте на этот вопрос, используя текст на изображении напрямую», чтобы ограничить формат ответа модели.
Чтобы обеспечить более точную оценку, в этой статье вручную проверили 1000 пар вопросов и ответов в OCRBench, исправили неверные варианты и предоставили другим кандидатам правильный ответ.
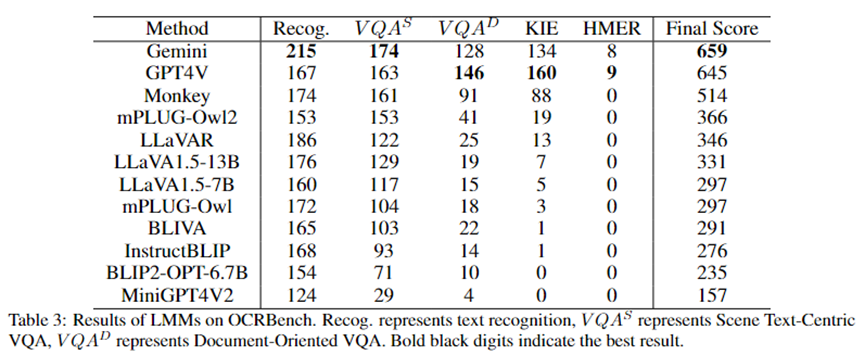
Результаты показаны в Таблице 3. Gemini получил наивысший балл, а GPT4V занял второе место. Следует отметить, что из-за строгой проверки безопасности, проведенной OpenAI, GPT4V отказался предоставить результаты по 84 изображениям в OCRBench.
Обезьяна продемонстрировала возможности оптического распознавания символов, уступая только GPT4V и Gemini. По результатам испытаний мы можем наблюдать, что даже самые продвинутые мультимодальные большие модели, такие как GPT4V и Gemini, сталкиваются с трудностями при выполнении задачи HMER.
Кроме того, у них также возникают проблемы с обработкой размытых изображений, рукописным текстом, текстом без семантики и выполнением инструкций по выполнению задач.
Как показано на рисунке 2(g), Gemini по-прежнему интерпретирует «02.02.2018» как «2 февраля 2018 года», даже несмотря на то, что ему явно предлагается ответить, используя текст на изображении.
Подвести итог
В этой статье проводится обширное исследование производительности LMM в задачах оптического распознавания символов, включая распознавание текста, ответы на вопросы по тексту сцены, ответы на вопросы по документам, KIE и HMER.
Количественная оценка в этой статье показывает, что LMM может достичь многообещающих результатов, особенно в распознавании текста, даже достигая SOTA в некоторых наборах данных.
Тем не менее, сохраняется значительный разрыв по сравнению с контролируемыми подходами, специфичными для конкретной предметной области, что позволяет предположить, что специализированные методы, адаптированные к каждой задаче, по-прежнему важны, поскольку последние используют гораздо меньше вычислительных ресурсов и данных.
OCRBench, предложенный в этой статье, обеспечивает эталон для оценки возможностей оптического распознавания мультимодальных больших моделей и выявляет ограничения прямого применения мультимодальных больших моделей в области оптического распознавания символов.
В этой статье также создается онлайн-рейтинг-лист для OCRBench для отображения и сравнения возможностей оптического распознавания различных мультимодальных больших моделей (о том, как присоединиться к рейтинговому списку, можно узнать на Github).
Ссылки:
https://github.com/Yuliang-Liu/MultimodalOCR



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
