Говоря о СЛАЙДАХ CUTLASS GTC2020
Предисловие
Начнем с куриного супа:
Этот блог основан на слайдах Cutlass GTC2020, адрес: https://www.nvidia.com/en-us/on-demand/session/gtcsj20-s21745/
what are tensorcores
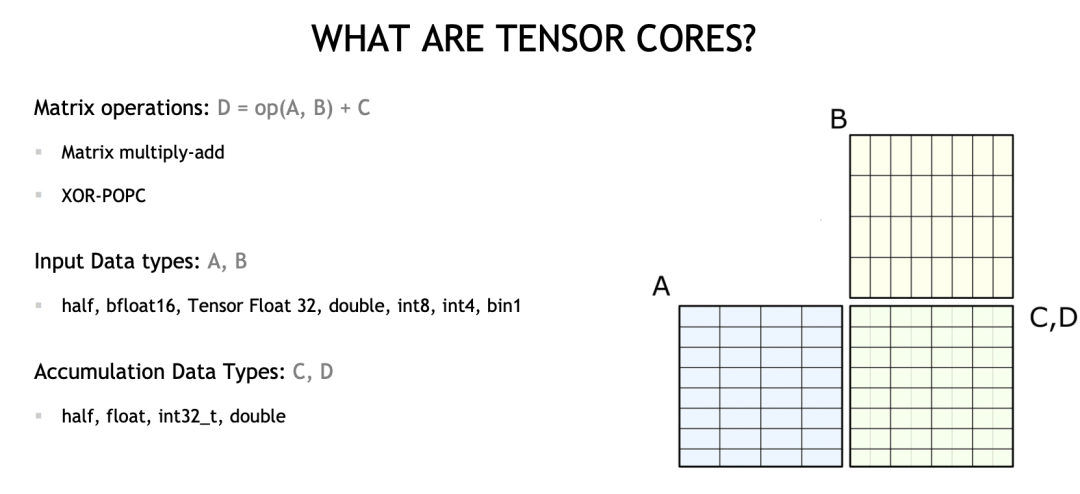
TensorCore — это аппаратная концепция, в основном используемая для ускорения операций умножения матриц (мы также называем ее MMA, Matrix Multiply Add). Она выполняет:
D = A * B + C
Он также поддерживает несколько типов ввода и типы числового накопления.
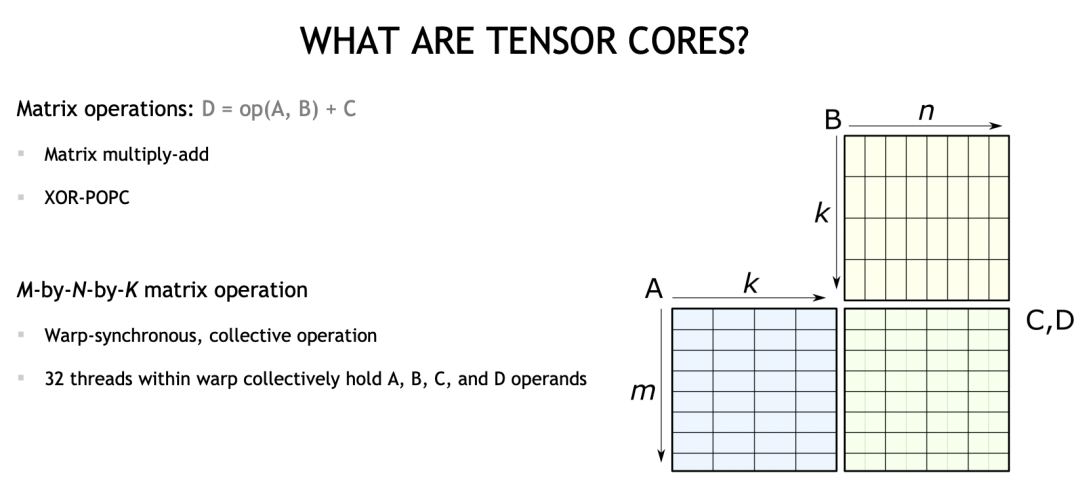
На уровне программирования TensorCore находится на уровне Warp (32 последовательных потока). WARP хранит данные четырех операндов A, B, C и D.
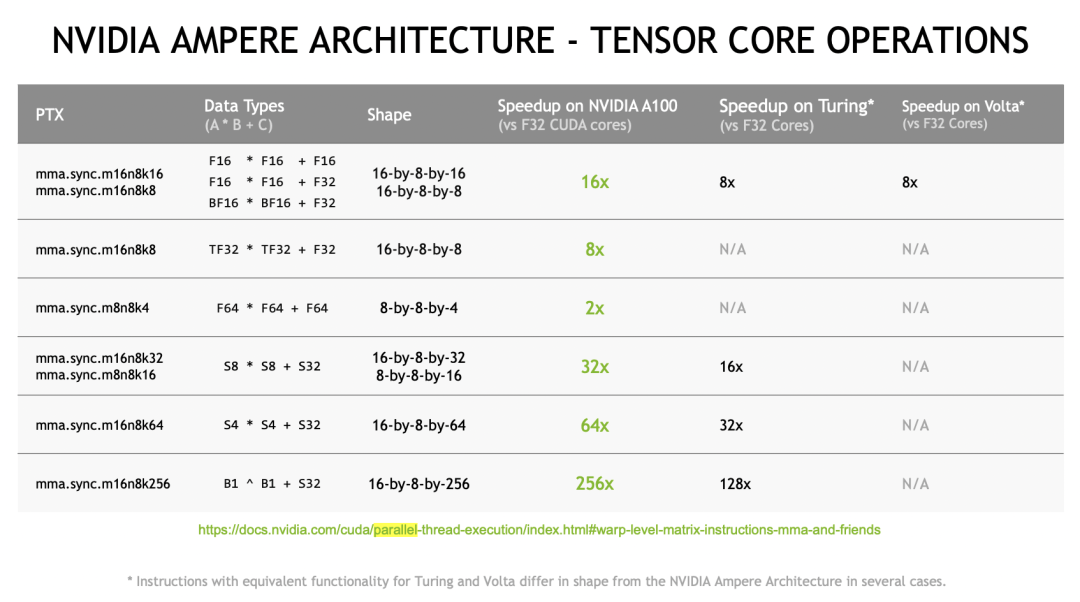
На рисунке выше показана инструкция MMA, поддерживаемая архитектурой Ampere, которая поддерживает несколько размеров и типов данных.
На следующих слайдах представлены MMA различных размеров. Мы можем запустить его с помощью кода.
S8 * S8 + S32 Code
При использовании TensorCore,К оформлению данных предъявляются особые требования. Инструкции MMA выполняются в рамках WARP.,Следовательно, каждый поток также имеет особые отношения сопоставления, соответствующие месту выборки данных.。
Сначала давайте выполним простую операцию int8 x int8 = int32 (8x16 matmul 16x8 = 8x8). Макет в слайдах выглядит следующим образом:
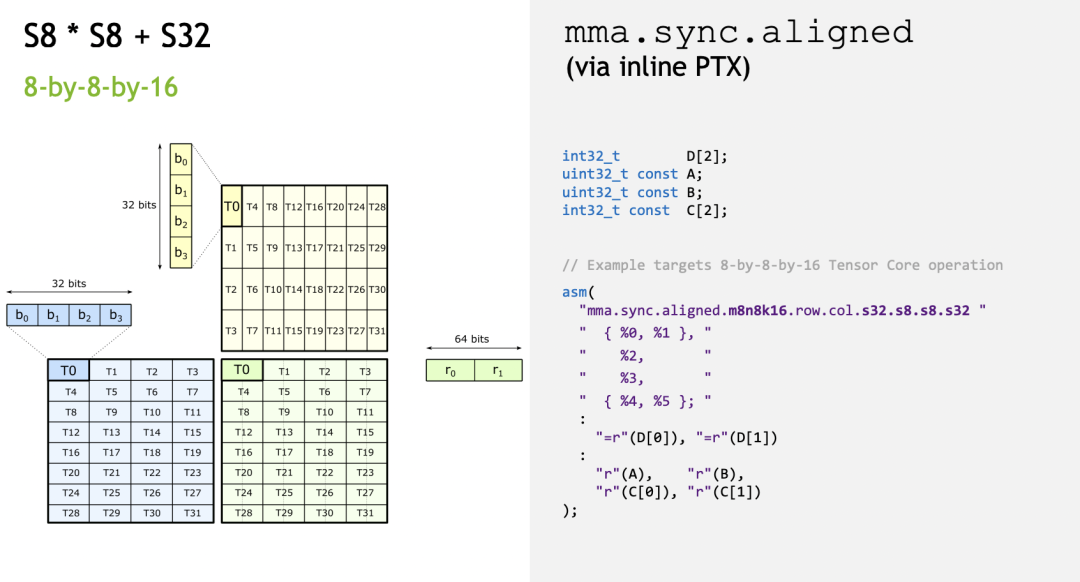
Каждый поток содержит 4x8-битные = 32-битные данные A, 4x8-битные = 32-битные данные B и 2x32-битные = 64-битные данные C/D.
Мы предполагаем, что используемая матрица:
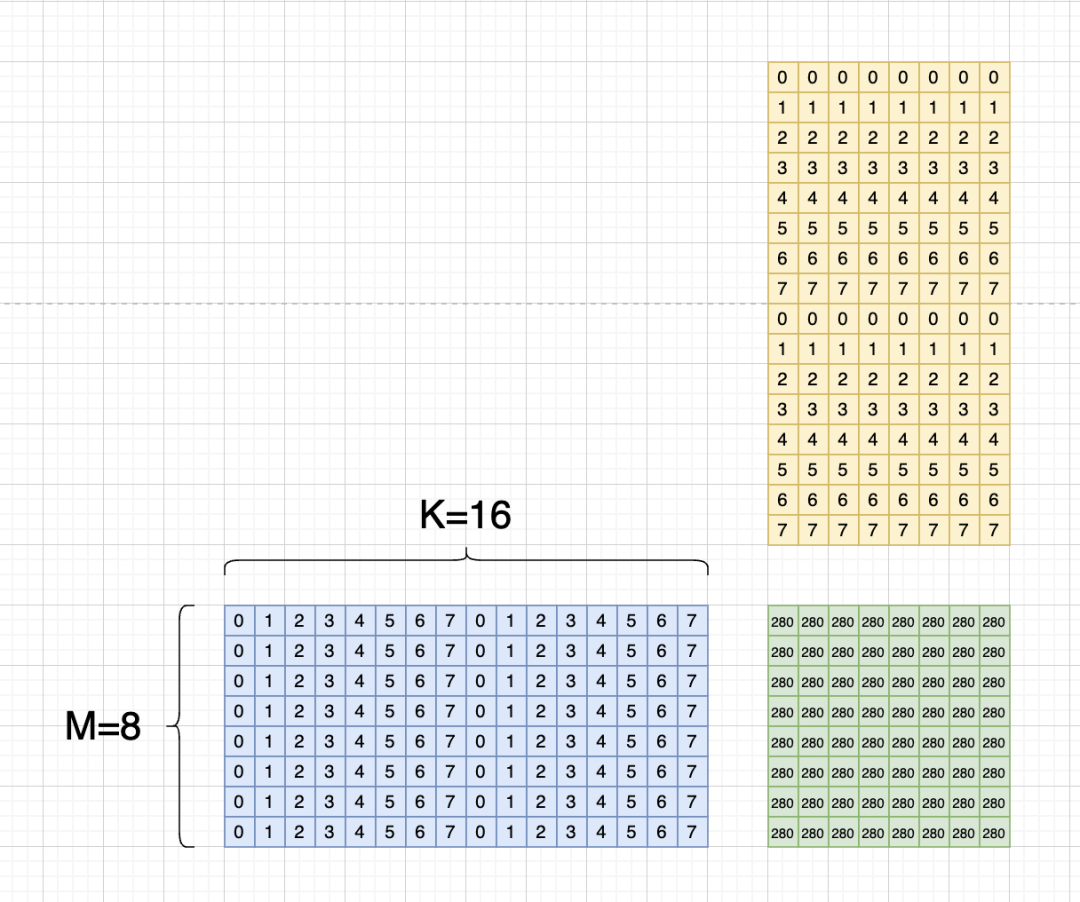
Мы пишем отображение потоков и элементы вместе:
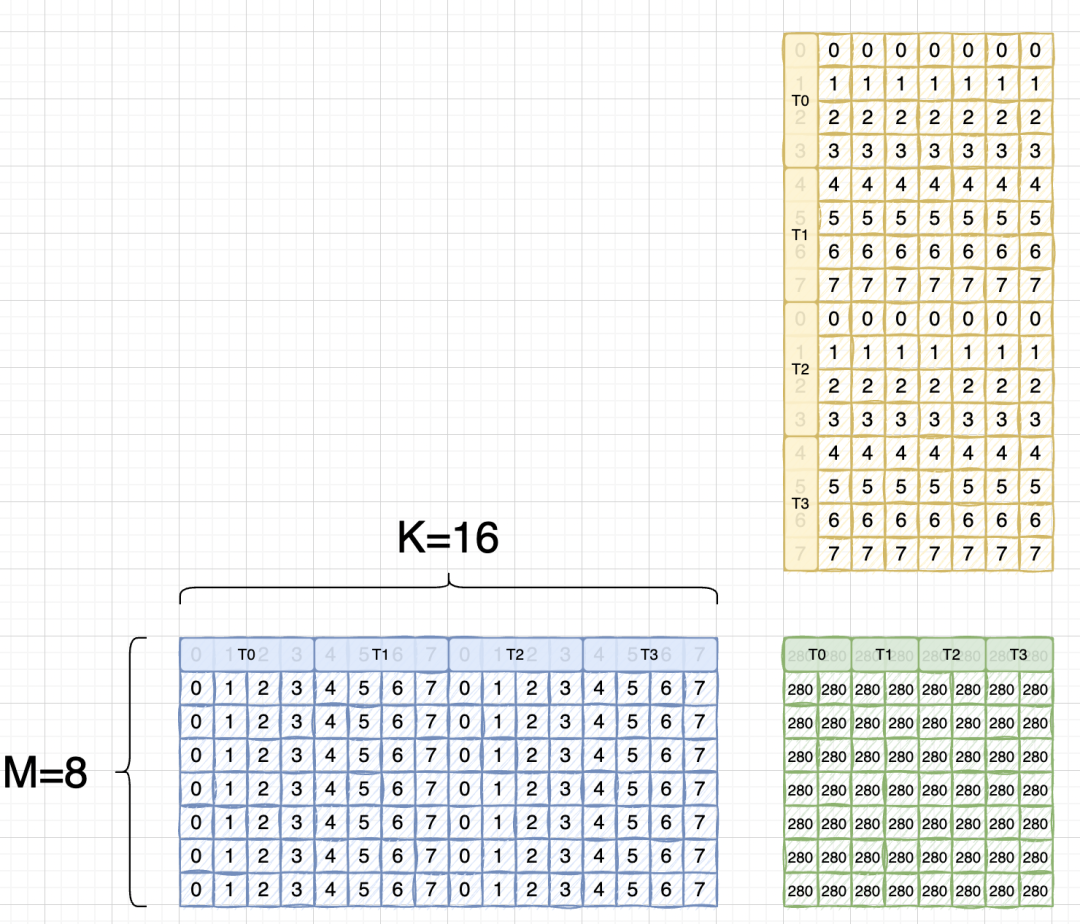
И потому что инструкция тензорного ядра имеет макет TN.
Здесь мы по-прежнему используем библиотеку расчета blas. В библиотеке blas мы будем использовать ее. a x b = c -> b_T x a_T = c_T, T здесь означает, что матрица B транспонирована, то есть матрица A является RowMajor, Матрица B — ColMajor.
Так что на самом деле должно быть:
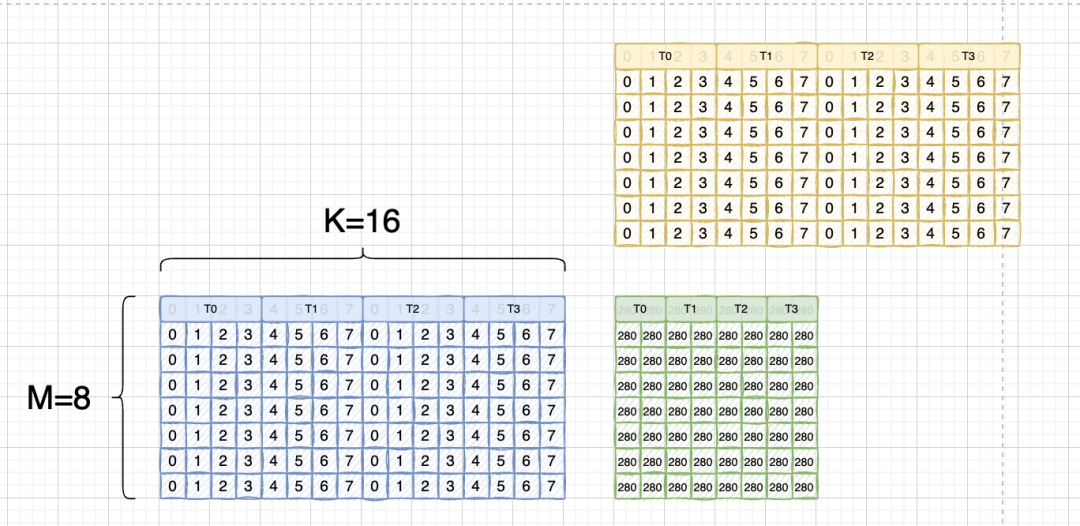
Вы можете видеть, что она точно такая же, как матрица A. При последующем извлечении элементов индекс, используемый двумя регистрами матрицы, будет одинаковым.
Код, используемый здесь, представляет собой пример на слайдах.

Сначала просто напишите инициализированное ядро:
#include "stdio.h"
#include "stdint.h"
__global__ void set_value(int8_t* x, int32_t elem_cnt){
for(int i = 0; i < elem_cnt; i++){
x[i] = static_cast<int8_t>(i % 8);
}
}
Далее идет ядро операции TensorCore. Следует отметить, что здесь используется тип int32, и мы выполняем расчет s8 x s8 = s32. При вызове его необходимо переинтерпретировать.
// Do AxB + C = D.
__global__ void tensor_core_example_8x8x16(int32_t *D,
uint32_t const *A,
uint32_t const *B,
int32_t const *C) {
// Compute the coordinates of accesses to A and B matrices
int outer = threadIdx.x / 4; // m or n dimension
int inner = threadIdx.x % 4; // k dimension
// Compute the coordinates for the accumulator matrices
int c_row = threadIdx.x / 4;
int c_col = 2 * (threadIdx.x % 4);
// Compute linear offsets into each matrix
int ab_idx = outer * 4 + inner;
int cd_idx = c_row * 8 + c_col;
// Issue Tensor Core operation
asm volatile("mma.sync.aligned.m8n8k16.row.col.s32.s8.s8.s32 {%0,%1}, {%2}, {%3}, {%4,%5};\n"
: "=r"(D[cd_idx]), "=r"(D[cd_idx+1])
: "r"(A[ab_idx]), "r"(B[ab_idx]), "r"(C[cd_idx]), "r"(C[cd_idx+1]));
}
Наконец, напечатайте результат вывода:
__global__ void printMatrix(int32_t* result, const int m, const int n){
for(int row = 0; row < m; row++){
for(int col = 0; col < n; col++){
printf("Row id: %d, Col id: %d, result is: %d \n", row, col, result[row * n + col]);
}
}
}
int main(){
int8_t* a;
int8_t* b;
int32_t* c;
int32_t* d;
const int32_t m = 8;
const int32_t k = 16;
const int32_t n = 8;
cudaMalloc(&a, m * k * sizeof(int8_t));
cudaMalloc(&b, k * n * sizeof(int8_t));
cudaMalloc(&c, m * n * sizeof(int32_t));
cudaMalloc(&d, m * n * sizeof(int32_t));
set_value<<<1, 1>>>(a, m * k);
set_value<<<1, 1>>>(b, k * n);
cudaMemset(c, 0, sizeof(int32_t) * m * n);
cudaMemset(d, 0, sizeof(int32_t) * m * n);
tensor_core_example_8x8x16<<<1, 32>>>(reinterpret_cast<int32_t*>(d),
reinterpret_cast<uint32_t*>(a),
reinterpret_cast<uint32_t*>(b),
reinterpret_cast<int32_t*>(c));
printMatrix<<<1, 1>>>(d, m, n);
cudaDeviceSynchronize();
cudaFree(a);
cudaFree(b);
cudaFree(c);
cudaFree(d);
}
учиться по аналогии
Ниже мы также можемучиться по аналогии,записать f16*f16+fp32 tensorcore, соответствующая инструкция 16 x 8 x 8. Однако данные, хранящиеся в потоке, несколько отличаются от данных в предыдущем примере, и их необходимо изменить.

#include "stdio.h"
#include "stdint.h"
#include "cuda_fp16.h"
template<typename T>
__global__ void set_value(T* x, int32_t elem_cnt){
for(int i = 0; i < elem_cnt; i++){
x[i] = static_cast<T>(i % 8);
}
}
__global__ void tensor_core_example_16x8x8(float *D,
uint32_t const *A,
uint32_t const *B,
float const *C) {
// Compute the coordinates of accesses to A and B matrices
int outer = threadIdx.x / 4; // m or n dimension
int inner = threadIdx.x % 4; // k dimension
// Compute the coordinates for the accumulator matrices
int c_row = threadIdx.x / 4;
int c_col = 2 * (threadIdx.x % 4);
// Compute linear offsets into each matrix
int ab_idx = outer * 4 + inner;
int cd_idx = c_row * 8 + c_col;
// Issue Tensor Core operation
asm volatile("mma.sync.aligned.m16n8k8.row.col.f32.f16.f16.f32 {%0,%1,%2,%3}, {%4,%5}, {%6}, {%7,%8,%9,%10};\n"
: "=f"(D[cd_idx]), "=f"(D[cd_idx+1]), "=f"(D[cd_idx+64]), "=f"(D[cd_idx+1+64])
:
"r"(A[ab_idx]), "r"(A[ab_idx+32]),
"r"(B[ab_idx]),
"f"(C[cd_idx]), "f"(C[cd_idx+1]), "f"(C[cd_idx+64]), "f"(C[cd_idx+1+64])
);
}
__global__ void printMatrix(float* result, const int m, const int n){
for(int row = 0; row < m; row++){
printf("Row id: %d, result is: ", row);
for(int col = 0; col < n; col++){
printf("%f ", static_cast<float>(result[row * n + col]));
}
printf("\n");
}
}
int main(){
half* a;
half* b;
float* c;
float* d;
const int32_t m = 16;
const int32_t k = 8;
const int32_t n = 8;
cudaMalloc(&a, m * k * sizeof(half));
cudaMalloc(&b, k * n * sizeof(half));
cudaMalloc(&c, m * n * sizeof(float));
cudaMalloc(&d, m * n * sizeof(float));
set_value<half><<<1, 1>>>(a, m * k);
set_value<half><<<1, 1>>>(b, k * n);
cudaMemset(c, 0, sizeof(float) * m * n);
cudaMemset(d, 0, sizeof(float) * m * n);
tensor_core_example_16x8x8<<<1, 32>>>(reinterpret_cast<float*>(d),
reinterpret_cast<uint32_t*>(a),
reinterpret_cast<uint32_t*>(b),
reinterpret_cast<float*>(c));
printMatrix<<<1, 1>>>(d, m, n);
cudaDeviceSynchronize();
cudaFree(a);
cudaFree(b);
cudaFree(c);
cudaFree(d);
}
Видно, что разные инструкции MMA соответствуют разным размерам матриц и разным типам данных. В CUTLASS вышеуказанные MMA объединены в шаблон:

Для фактического использования вам нужно только соответствующим образом создать экземпляр шаблона MMA:

DATA Movement
На следующих слайдах рассказывается о части обработки данных при умножении матриц и инструкции LDMatrix, представленной в новой архитектуре.

На этом слайде в качестве примера по-прежнему используется MMA S8 x S8 + S32. Ранее мы также пришли к выводу, что WARP завершает 8x16 matmul 16x8, поэтому для загрузки матрицы A и B требуется в общей сложности (8x16 + 16x8) = 256B. Расчет FLOPS выглядит следующим образом:
C Всего матриц 8 * 8 = 64 элементы
Каждый элемент требует 16 умножений и сложений.,
FLOPS = 64 * 16 * 2 = 2048
Разделив эти два значения, вычисленный коэффициент доступа к памяти составит 8 флопс/байт.
Затем давайте взглянем на проектные характеристики, указанные в официальном документе по архитектуре Ampere. Вычислительная мощность тензорного ядра Int8 A100 составляет 624 терафлопс (312 — это FP16, а скорость int8 у A100 с памятью 80 ГБ — 1,6 ТБ/с). , поэтому это идеальный доступ к вычислительным ресурсам. Коэффициент хранения составляет 400 флопсов на байт.
Сравнивая соотношение доступа к памяти между ними, мы видим, что после использования TensorCore доступ к памяти стал узким местом. Вот почему обработка данных является очень важной частью оптимизации GEMM.
Я думаю, что это оценка идеальной ситуации. Реальная ситуация может быть более сложной, и вам нужно учитывать скорость попадания в кэш и т. д. (см. статью Чжиху Ли Шаося).
Таким образом, Cutlass абстрагирует набор эффективных процессов передачи данных. Многие статьи по оптимизации GEMM уже рассказывали о них, поэтому я не буду вдаваться в подробности:
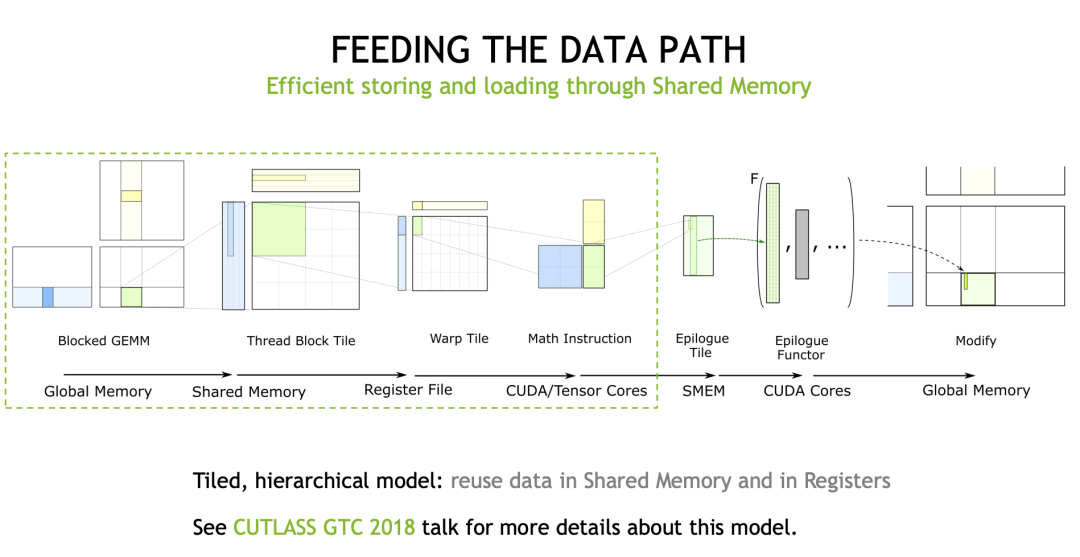
Среди них в архитектуре Ampere впервые введен механизм AsyncCopy, то есть в Global Memory приезжать SharedMemory эта ссылка. Раньше нам приходилось начинать с глобального Память считывает регистр прибытия, а затем сохраняет из реестра приезжатьSharedMemory, но с помощью этой инструкции мы можем прибыть за один шаг из GlobalMemory. -> SharedMemory в определенной степени снижает нагрузку на регистры. (Если вы часто профилируете GEMM должен уметь понимать)
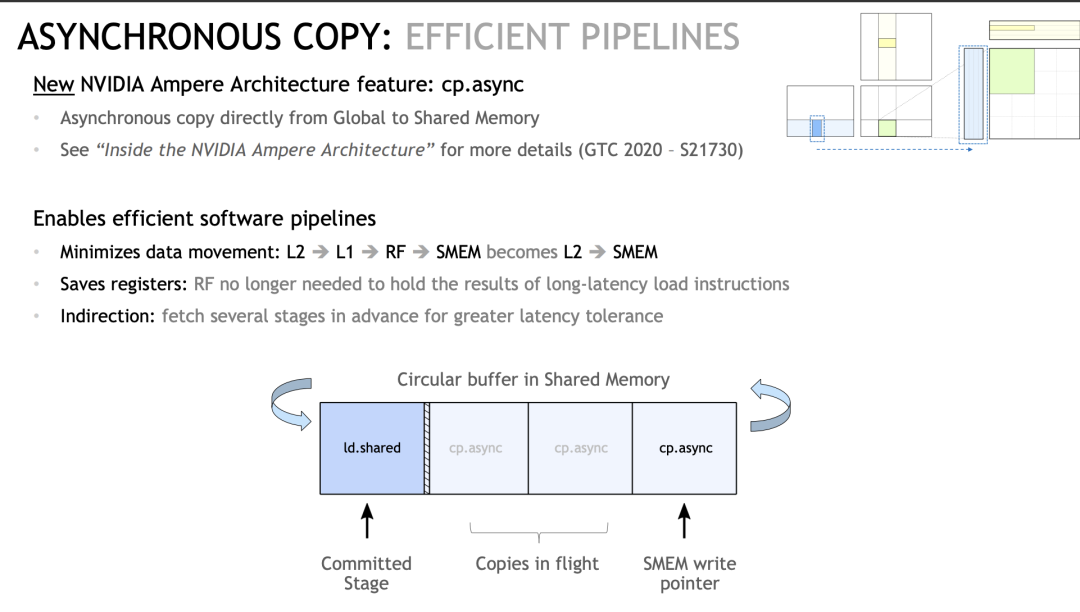
И это асинхронная операция, а это означает, что мы можем заранее выполнить несколько раундов инструкций предварительной выборки данных (часто называемых этапом в абордажной сабле), чтобы добиться сокрытия задержки (я перемещаю свою, вы считаете свою).
Еще одна специальная инструкция — LDMatrix, которая используется в процессе прибытия SharedMemoryRegister.
Чтобы максимизировать пропускную способность,существоватьGlobalMemory->SharedMemoryПо этой ссылке,Каждый файл хранится с 128-битной степенью детализации доступа. Как упоминалось ранее, приезжатьTensorCore имеет разные индексы для каждого уровня данных.,Это также приводит к тому, что элементы, необходимые каждому потоку, становятся прерывистыми в SharedMemory.。

На примере Slides давайте посмотрим на поток T0, который требует, чтобы T0, T8, T16 и T24 соответствовали первому элементу SharedMemory. До того, как LDMatrix не существовало, он должен был соответствовать четырем операциям LDS32. Если мы вызовем LDMatrix, мы сможем выполнить вышеуказанные операции в одной инструкции:

Кратко упомянем крестообразное расположение Cutlass (не очень в этом разбираюсь). Вообще говоря, чтобы избежать BankConflict, мы обычно добавляем еще один элемент в Padding, чтобы распределить доступ к потокам внутри Warp, но это определенно приведет к пустой трате SharedMemory. Cutlass предлагает новый макет, который вычисляет индекс посредством серии очень сложных операций XOR. В конечном итоге это выглядит примерно так:
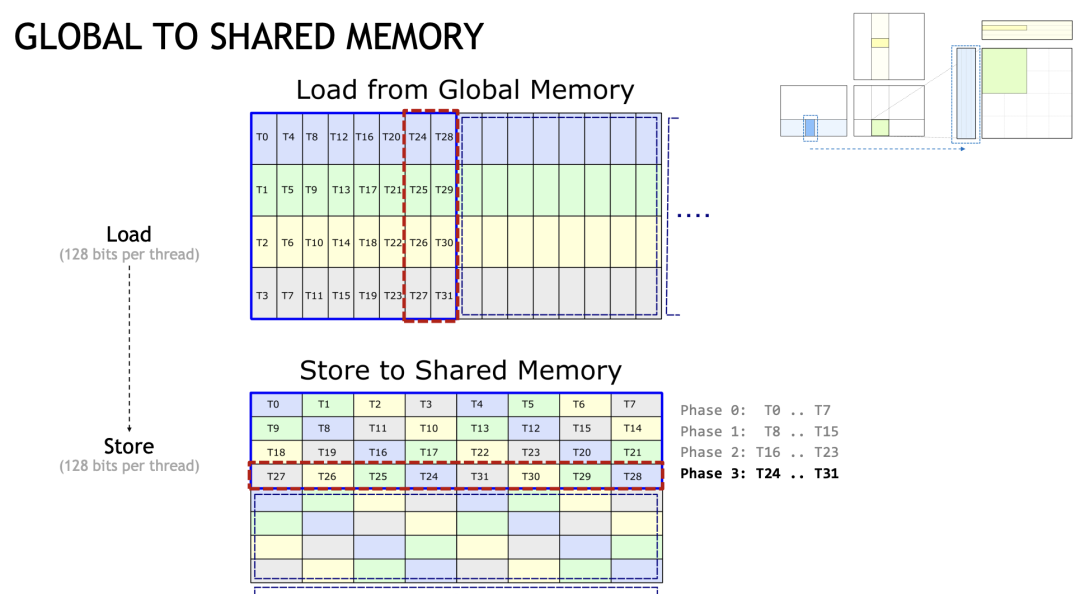
Здесь каждый нит имеет 128 сохраненных бит.,То есть он занимает 4 банка. Давайте в качестве примера возьмем данные, которые нам нужны для нить0.,Вы можете посмотреть приезжатьT0 T8 T16 Т24 располагается в шахматном порядке и хранится в разных банках (то же самое касается и других нит)
Ниже приведен пример LDMatrix.
PS: Не знаю, верно ли то, что я написал. По крайней мере, результаты выглядят разумными. Поправьте меня, если я ошибаюсь.
LDMatrix example
#include "stdio.h"
#include "stdint.h"
#include "cuda_fp16.h"
#define LDMATRIX_X4(R0, R1, R2, R3, addr) \
asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n" \
: "=r"(R0), "=r"(R1), "=r"(R2), "=r"(R3) \
: "r"(addr))
template<typename T>
__global__ void set_value(T* x, int32_t elem_cnt){
for(int i = 0; i < elem_cnt; i++){
x[i] = static_cast<T>(i % 8);
}
}
// Скопировано из CUTLASS
__device__ uint32_t cast_smem_ptr_to_uint(void const* const ptr) {
// We prefer to use the new CVTA intrinsics if they are available, otherwise we will fall back to
// the previous internal intrinsics if they are available.
#if CUTE_CVTA_GENERIC_TO_SHARED_ACTIVATED
//
// This NVVM intrinsic converts an address in shared memory to a plain
// unsigned integer. This is necessary to pass to shared memory instructions
// in inline PTX.
//
// In CUDA 11 and beyond, this replaces __nvvm_get_smem_pointer() [only available in 10.2].
//
//__device__ size_t __cvta_generic_to_shared(void* ptr);
/// CUTE helper to get SMEM pointer
return static_cast<uint32_t>(__cvta_generic_to_shared(ptr));
#elif CUTE_NVVM_GET_SMEM_POINTER_ACTIVATED
return __nvvm_get_smem_pointer(ptr);
#elif defined(__CUDA_ARCH__)
uint32_t smem_ptr;
asm(
"{ .reg .u64 smem_ptr; cvta.to.shared.u64 smem_ptr, %1; cvt.u32.u64 %0, smem_ptr; }\n"
: "=r"(smem_ptr) : "l"(ptr));
return smem_ptr;
#else
(void) ptr;
printf("ERROR: cast_smem_ptr_to_uint not supported but used.\n");
return 0;
#endif
}
__global__ void ldmatrix_example(uint32_t* x,
uint32_t* y) {
const int32_t row_tid = threadIdx.x / 8;
const int32_t col_tid = threadIdx.x % 8;
uint32_t RegisterLoad[4];
uint32_t RegisterTensorcore[4];
__shared__ half smem[4][64];
*reinterpret_cast<float4*>(RegisterLoad) = *reinterpret_cast<float4*>((x + threadIdx.x * 4));
half* half_register_load_ptr = reinterpret_cast<half*>(RegisterLoad);
if(threadIdx.x == 0){
printf("ThreadIdx: %d, Value is: %f, %f, %f, %f, %f, %f, %f, %f. \n", threadIdx.x,
static_cast<float>(half_register_load_ptr[0]), static_cast<float>(half_register_load_ptr[1]),
static_cast<float>(half_register_load_ptr[2]), static_cast<float>(half_register_load_ptr[3]),
static_cast<float>(half_register_load_ptr[4]), static_cast<float>(half_register_load_ptr[5]),
static_cast<float>(half_register_load_ptr[6]), static_cast<float>(half_register_load_ptr[7]));
}
int32_t xor_idx = threadIdx.x;
if(row_tid == 1){
xor_idx ^= 1;
}
if(row_tid == 2){
xor_idx ^= 2;
}
if(row_tid == 3){
xor_idx ^= 3;
}
const int32_t store_smem_row_tid = xor_idx / 8;
const int32_t store_smem_col_tid = xor_idx % 8;
// if(threadIdx.x == 0){
printf("ThreadIdx: %d, XorIdx is: %d, store_smem_row_tid is :%d, store_smem_col_tid is: %d. \n", threadIdx.x, xor_idx, store_smem_row_tid, store_smem_col_tid * 8);
// }
half* smem_ptr = &(smem[store_smem_row_tid][store_smem_col_tid * 8]); // smem[store_smem_row_tid][store_smem_col_tid * 4];
*reinterpret_cast<float4*>(smem_ptr) = *reinterpret_cast<float4*>(RegisterLoad);
__syncthreads();
if(threadIdx.x == 0 || threadIdx.x == 8 || threadIdx.x == 16 || threadIdx.x == 24){
printf("ThreadIdx: %d, SMEM Value is: %f, %f, %f, %f, %f, %f, %f, %f. \n", threadIdx.x,
static_cast<float>(smem[0][0]), static_cast<float>(smem[0][1]),
static_cast<float>(smem[0][2]), static_cast<float>(smem[0][3]),
static_cast<float>(smem[0][4]), static_cast<float>(smem[0][5]),
static_cast<float>(smem[0][6]), static_cast<float>(smem[0][7]));
}
uint32_t addr = cast_smem_ptr_to_uint(smem_ptr);
LDMATRIX_X4(RegisterTensorcore[0], RegisterTensorcore[1], RegisterTensorcore[2], RegisterTensorcore[3], addr);
half* half_register_tensorcore_ptr = reinterpret_cast<half*>(RegisterTensorcore);
if(threadIdx.x == 0){
printf("After LDMATRIX, ThreadIdx: %d, Value is: %f, %f, %f, %f, %f, %f, %f, %f. \n",
threadIdx.x,
static_cast<float>(half_register_tensorcore_ptr[0]), static_cast<float>(half_register_tensorcore_ptr[1]),
static_cast<float>(half_register_tensorcore_ptr[2]), static_cast<float>(half_register_tensorcore_ptr[3]),
static_cast<float>(half_register_tensorcore_ptr[4]), static_cast<float>(half_register_tensorcore_ptr[5]),
static_cast<float>(half_register_tensorcore_ptr[6]), static_cast<float>(half_register_tensorcore_ptr[7]));
}
}
__global__ void printMatrix(half* result, const int m, const int n){
for(int row = 0; row < m; row++){
printf("Row id: %d, result is: ", row);
for(int col = 0; col < n; col++){
printf("%f ", static_cast<float>(result[row * n + col]));
}
printf("\n");
}
}
int main(){
half* x;
half* y;
const int32_t m = 16;
const int32_t k = 16;
const int32_t n = 8;
cudaMalloc(&x, m * k * sizeof(half));
cudaMalloc(&y, m * k * sizeof(half));
set_value<half><<<1, 1>>>(x, m * k);
cudaMemset(y, 0, sizeof(half) * m * k);
ldmatrix_example<<<1, 32>>>(reinterpret_cast<uint32_t*>(x),
reinterpret_cast<uint32_t*>(y));
// printMatrix<<<1, 1>>>(y, m, k);
cudaDeviceSynchronize();
cudaFree(x);
cudaFree(y);
}
Мне не совсем понятно, что такое функция cast_smem_ptr_to_uint. Я взял абзац из блога Юань Жун Цисина по транспозиции матриц:
Следует отметить, что адрес общей памяти не является адресом глобальной синхронизации (Generic Адрес), поэтому перед использованием адреса общей памяти для чтения или записи данных вам необходимо выполнить встроенную функцию __cvta_generic_to_shared. Конечно, вы также можете написать PTX вручную.
пример индекса преобразования xor
for i in range(8, 16):
print(i, i ^ 1)
for i in range(16, 24):
print(i, i ^ 2)
for i in range(24, 32):
print(i, i ^ 3)



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
