Google выпускает модель генерации видео VideoPoet, AI также берет на себя работу редакторов

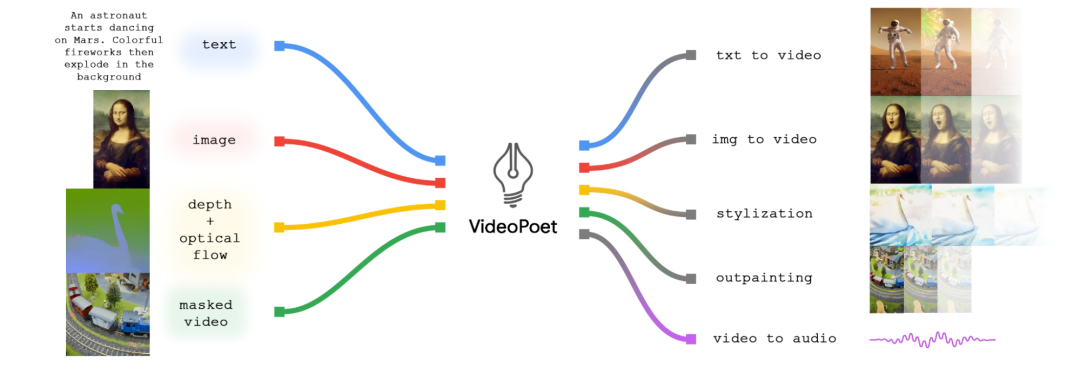
VideoPoet может реализовать множество задач по созданию видео с помощью одной большой модели.
Автор | Хуан Нань
Редактор | Чэнь Цайсянь
В прошлом году генеративный контент, начиная от рисования, написания стихов, кодирования и заканчивая речью, пережил взрывной рост. Среди них генерация видео (текст в видео), которая считается одним из основных направлений AIGC, подвержена влиянию данных. и вычислительной мощности, технический порог выше, и необходимо решить множество проблем, таких как качество видеоизображения, непрерывность изображения, текстовое и видеоконтент.
Недавно VideoPoet, новая модель генерации видео с использованием искусственного интеллекта, запущенная Google, представляет собой модель генерации видео с нулевым кадром (нулевой выборкой), которая может сэкономить много данных и вычислительных ресурсов, а производительность модели также демонстрирует удивительные эффекты изображения.
Например, в большинстве случаев даже ведущие генеративные модели неизбежно будут иметь очевидные проблемы с артефактами при работе с большими или маленькими движущимися видеоизображениями. А вот в VideoPoet вышеуказанные проблемы в некоторой степени исправлены.
Кроме того, преимущество VideoPoet заключается в том, что он может интегрировать несколько функций генерации, таких как преобразование стилей, генерация аудио и видео, длинные видеоролики и т. д., в одну и ту же большую языковую модель для выполнения нескольких задач вместо интеграции компонентов обучения для одной задачи.
1
VideoPoet: модель создания видео с нулевым кадром
По словам представителей Google, VideoPoet — это большая языковая модель, которая может выполнять многозадачность на различных видео-ориентированных входах и выходах, выбирая текст в качестве входных данных, включая преобразование текста в видео, изображение в видео, видео в аудио, передачу стилей, рисование и т. д.
Среди них входное изображение может создавать движение, а обрезанное или закрытое видео также можно изменить или исправить с помощью VideoPoet.
Например, в видео генерации текста:
Введите текст «Танцующий енот на Таймс-сквер» и вы получите короткое видео танцующего енота.

Другой пример — использование текста для преобразования изображений в видео:
левый:рисованиесерединаизображает корабль,Он путешествует по бурному морю, грозам и молниям середина
середина:Множество мерцающих туманностей плывут
верно:в ветреные дни,Бездомный с тростью стоит на скале,Он посмотрел вниз на клубящийся туман внизу.
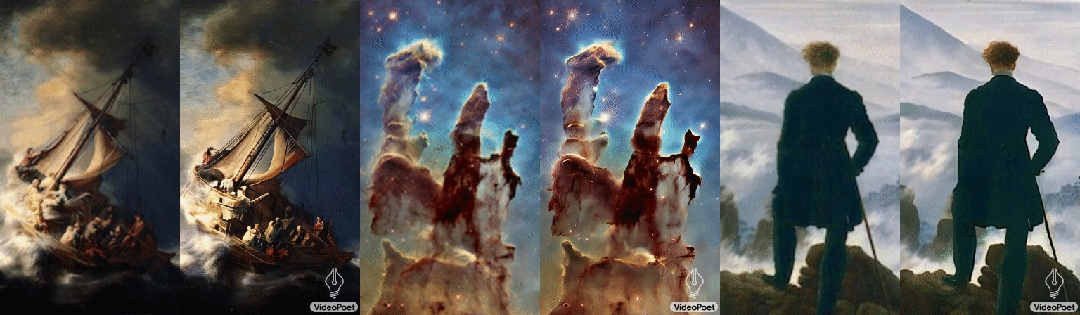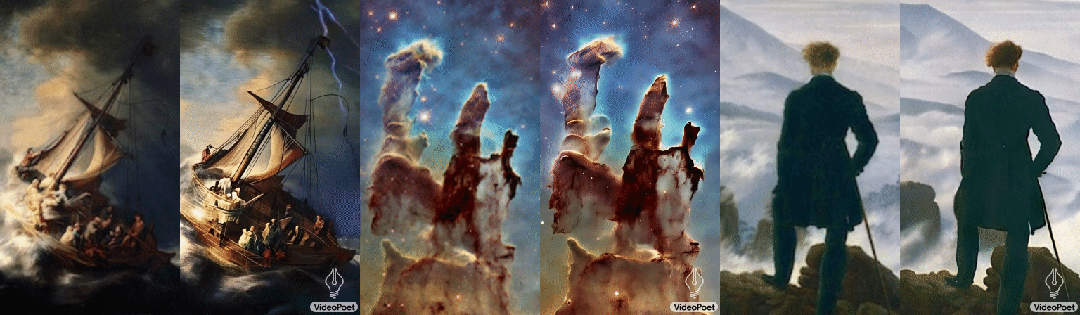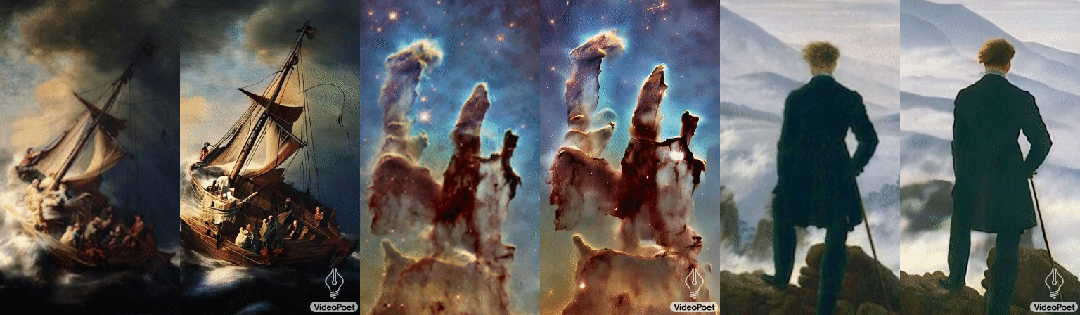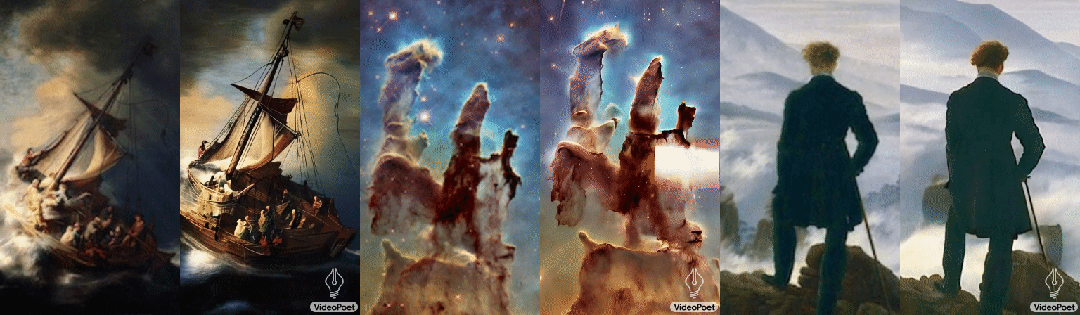
Согласно разным описаниям картин, одна и та же картина также может быть преобразована в разные видеоклипы, например:
левый:Женщина поворачивается и смотрит в камеру
верно:Женщина зевает

В зависимости от различных стилей видео, продолжительности, редактирования экрана и других потребностей VideoPoet также может предоставлять соответствующие услуги.
Например, использование текста в видео для создания нового стиля видео:
Слева: Вомбат в солнечных очках держит пляжный мяч на солнечном пляже.
В центре: плюшевый мишка катается на коньках по чистому замерзшему озеру.
Справа: «Металлический лев рычит под огнями кузницы.

Например, в случае требований к длинному видео при нормальных обстоятельствах VideoPoet по умолчанию выводит контент короткого формата, но если последняя секунда видео настроена и содержимое следующей секунды прогнозируется, VideoPoet может выводить более длинный видеоконтент:
Астронавт начинает танцевать на Марсе, а на заднем плане взрывается красочный фейерверк

FPV (вид от первого лица, вид от первого лица), в джунглях очень резкий эльфийский каменный город, ярко-синие реки, водопады и большие и крутые скалы.

Кроме того, VideoPoet также может принимать ввод видеоконтента и редактировать видео с помощью текстовых указаний.
Первое видео слева — это входное видео, и даны соответствующие подсказки:
Крупный план симпатичного, ржавого, поврежденного робота в стиле стимпанк, покрытого влажным мхом и прорастающей растительностью и окруженного высокой травой.
Затем добавьте динамические экранные подсказки:
Включите питание с дымом на заднем плане

Другой пример: учитывая необходимый снимок камеры, текст может точно контролировать траекторию съемки камеры:
На рисунке ниже показаны следующие кадры: уменьшение масштаба, перемещение масштаба, панорамирование влево, съемка по дуге, съемка с помощью подвеса, съемка с дрона с FPV.

Видно, что VideoPoet в настоящее время демонстрирует сильные возможности понимания и генерации. Благодаря повторяющимся ссылкам модель может не только хорошо расширять видеоконтент, но также, даже если добавлено несколько инструкций, модель также может хорошо работать в итерациях. сгенерированного объекта.
Раньше из-за влияния дискретных токенов больших языковых моделей качество генерации видео легко ухудшалось. Преимущество VideoPoet заключается в том, что он использует несколько тегов для изучения видео, изображений, аудио и текста. Видео и аудиоклипы кодируются в отдельные последовательности тегов. Как только модель генерирует теги, обусловленные некоторым контекстом, их можно передать через декодер тегов. , преобразует эти токены обратно в просматриваемое представление.
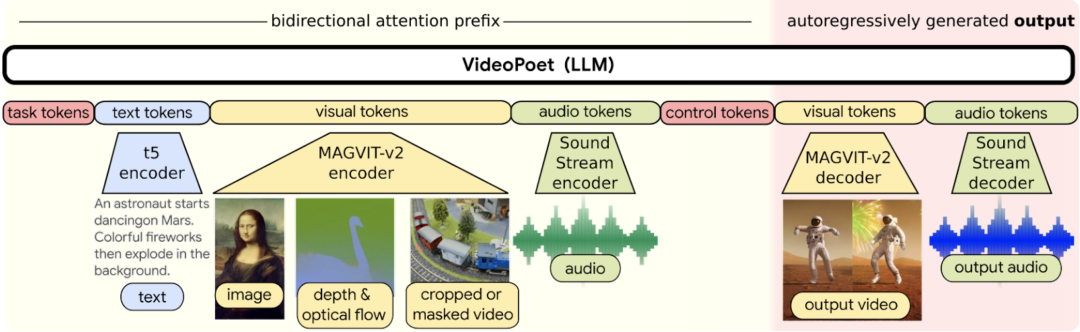
Кроме того, VideoPoet — это модель генерации видео с нулевым кадром, которая может сэкономить много данных и вычислительных ресурсов. В то же время, по сравнению с аналогичными моделями генерации видео, которые в основном используют обучение одной задаче, а затем интегрируют каждую функцию в компоненты, VideoPoet может выполнять несколько задач генерации видео с помощью одной и той же большой языковой модели.
2
Оценка: Производительность обычно превосходит другие модели.
Чтобы в дальнейшем наблюдать за производительностью VideoPoet, команда Google протестировала все остальные модели генерации видео под разными подсказками и предоставила их пользователям для оценки их предпочтений.
Прежде всего, с точки зрения точности текста, то есть процента предпочтительных видео с точки зрения точного следования подсказкам, в целом пользователи считают, что с точки зрения производительности следующих подсказок 24–35 % случаев VideoPoet показали лучшие результаты. а доля аналогичных конкурирующих моделей составляет 8-11%.
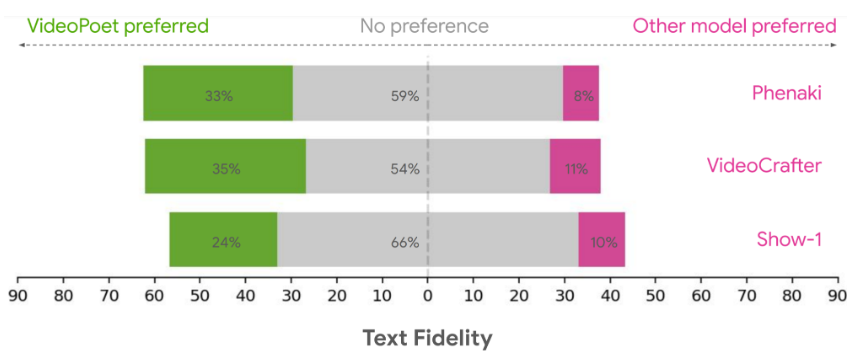
Что касается увлекательности действия, 41–54% пользователей, оценивших его, предпочли примеры VideoPoet из-за их более яркой графики и более интересного действия по сравнению с 11–21% для других моделей.
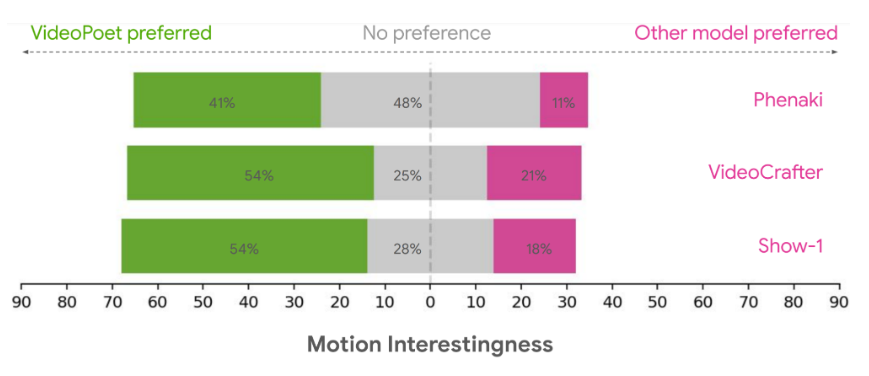
Видно, что VideoPoet на данный момент имеет весьма конкурентоспособное качество генерации видео по сравнению с аналогичными моделями в различных задачах, особенно при создании интересных и качественных действий в видеороликах.
Однако в настоящее время VideoPoet выпустила только демонстрации моделей, а соответствующие документы, коды и т. д. не были опубликованы. В связи с этим некоторые пользователи сети сказали: «Как обычно, Google выпустил впечатляющую демонстрацию искусственного интеллекта, но нет возможности опробовать ее, нет ни исходного кода, ни API, и это не коммерческий продукт… Итак , никто на самом деле не будет его использовать».

По сравнению с полями текста и изображений, генерации видео еще предстоит пройти долгий путь, прежде чем она сможет добиться прорыва. Инсайдеры отрасли ранее отмечали, что одной из основных проблем при создании видео является продолжительность. С длительностью напрямую связан смысл действий. Чтобы продлить продолжительность производства видео, первая задача — решить проблему понимания и рассуждения модели. действий и, в конце концов, изучить, как можно выполнять сложные действия.
Во-вторых, хотя четкость и плавность видео были улучшены, до этапа применения еще предстоит пройти долгий путь.
Возможно, в ближайшем будущем мы также сможем стать свидетелями применения моделей генерации видео к генерации «любой к любому», например, к преобразованию текста в аудио, аудио в видео и видеосубтитрам.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
