Google | предлагает глубокий гибридный преобразователь для динамического распределения вычислительных ресурсов на 66 % быстрее оптимального базового уровня.
введение
Это исследование демонстрирует новыйTransformerязык Модель:Mixture-of-Depths Transformer,Должен МодельможетДинамическое распределение вычислительных ресурсовв определенную позицию во входной последовательности,Вместо равномерного распределения вычислительных ресурсов, как в традиционной модели. Распределение посредством динамического расчета,Может значительно увеличить скорость модели, сохраняя при этом производительность.,На 66 % быстрее, чем оптимальная базовая модель isoFLOP.!

https://arxiv.org/pdf/2404.02258.pdf
Предыстория
в жизни,Не все проблемы требуют одного и того же времени для решения. Также на языке Модель,Не все токены и последовательности требуют одинаковой вычислительной мощности для прогнозирования. Однако,Модель трансформатора тратит одинаковое количество вычислений для каждого токена при прямом распространении.,Для этой проблемы,Можем ли мы позволить Transformer сохранить эти ненужные вычисления?
Условные вычисления — это метод, который уменьшает общий объем вычислений, выполняя вычисления только при необходимости. Уже существует множество решений того, когда и в каком объеме необходим расчет. Однако эти алгоритмы не обязательно применимы к существующему оборудованию, поскольку они имеют тенденцию вводить динамические графы вычислений, в то время как существующее оборудование предпочитает использовать статические графы вычислений.
Чтобы преодолеть эту проблему,Автор этой статьи рассматривает моделирование языка в условиях статического вычислительного бюджета.,И этот статический бюджет может быть меньше, чем вычислительный бюджет, необходимый обычному Трансформатору.。в,Принятие решений по токену для каждого уровня,Нейронные сети должны научиться динамически распределять вычислительные ресурсы. В процессе реализации,Общие вычислительные усилия определяются пользователем.,И он неизменен до тренировки,а не функция сетевого динамического принятия решений. поэтому,Улучшение использования оборудования можно предсказать заранее на основе сокращения использования памяти и уменьшения количества FLOP на прямое распространение.
В этом документе используется подход, аналогичный преобразователю Mix of Experts (MoE), где решения по динамической маршрутизации на уровне токена принимаются по всей глубине сети. В отличие от MoE, в этой статье выбран вариант применения вычислений к токену (аналогично стандартному преобразователю) или прямое распространение через остаточные соединения. Кроме того, в этой статье этот метод маршрутизации также применяется для одновременной пересылки многоуровневых перцептронов (MLP) и механизмов внимания с несколькими головками. Следовательно, это также влияет на обработку ключей и запросов. Маршрутизация не только определяет, какие токены обновляются, но также определяет, какие токены используются для механизма внимания. В этой статье эта стратегия называется «Смешение глубин» (MoD).
реализация МО
Метод MoD Transformers устанавливает статический бюджет вычислений. Эта предустановленная сумма вычислений меньше, чем в традиционной модели Transformer.。Этот вычислительный бюджет может участвовать в самоинъекции, ограничивая его внутри заданного слоя.TokenВнимание и многослойные перцептроны(MLP)рассчитанныйTokenколичество для достижения。Этот подход использует послойныймаршрутизацияустройство, чтобы решить, какойToken应Должен参与计算,Какие из них следует обойти для вычислений через остаточные соединения,Это экономит вычислительные ресурсы.
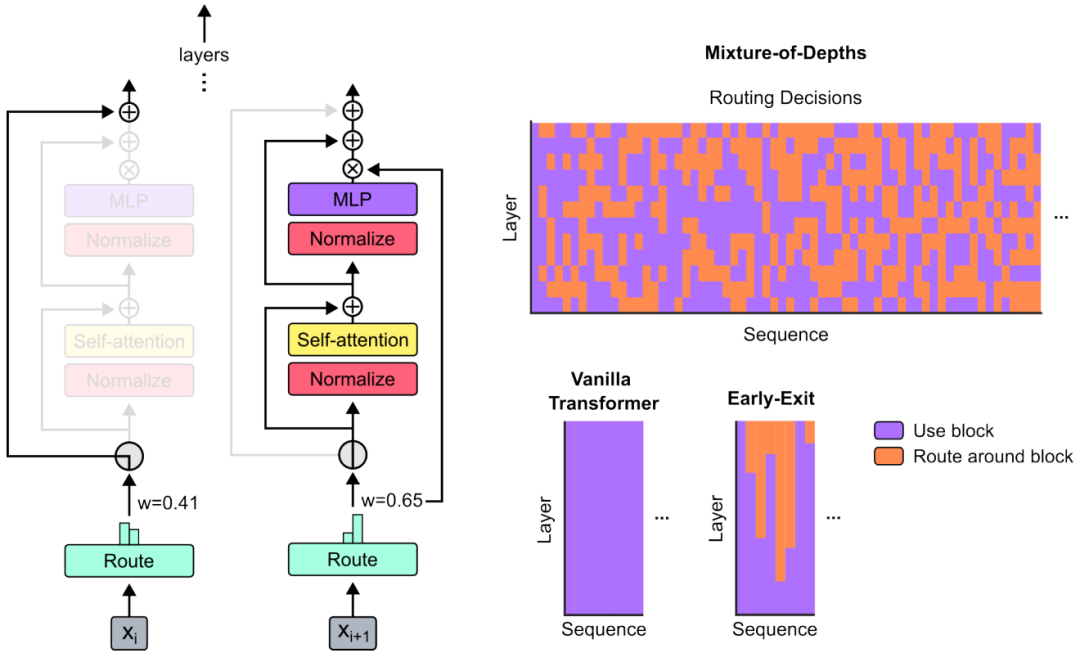
Конкретные методы реализации:
«1. Определить бюджет расчета» То есть общий вычислительный бюджет обеспечивается за счет ограничения количества токенов в последовательности, которые могут участвовать в расчете. Чтобы эффективно управлять вычислительными ресурсами в модели Трансформера, автор использует концепцию «мощности» для ограничения количества входных Токенов для каждого расчета. Самообслуживание Традиционного Трансформатора и MLP используют все токены, в то время как MoE Transformer выделяет каждому эксперту меньше токенов, чтобы сбалансировать вычислительную нагрузку.
Распределение вычислительных ресурсов зависит от мощности токена даже в условных расчетах. Уменьшая вычислительную мощность, можно уменьшить вычислительные требования для каждого прямого прохода, но если не обработать их должным образом, это может повлиять на производительность модели. Автор считает, что не все токены требуют одинакового уровня обработки, поэтому модель может научиться определять, какие токены более важны. Таким образом, сеть может более эффективно использовать вычислительные ресурсы, сохраняя при этом производительность.
«2. Трассировка вокруг блока Трансформатора» Механизм маршрутизации позволяет модели решать, какие данные требуют интенсивных вычислений, а какие можно пропустить. Это достигается путем присвоения веса каждому элементу данных в последовательности. Элементы данных с высокими весами участвуют в полном процессе расчета, тогда как элементы с низкими весами проходят простой этап пропуска для экономии вычислительных ресурсов. Этот метод динамического выбора позволяет модели работать более эффективно, сохраняя при этом качество обработки. Настраивая этот механизм, модели могут найти наилучший баланс между скоростью и производительностью.
「3.План маршрутизации」 Стратегия, используемая для принятия решения о том, какие элементы данных участвуют в сложных вычислениях, а какие можно упростить для обработки. Существует два основных решения: 1) Маршрутизация на основе токенов: каждый элемент данных выбирает путь для участия в расчете на основе предпочтений, но это может привести к неравномерной обработке. 2) Маршрутизация на основе экспертов: каждый путь расчета выбирает определенное количество элементов данных для обеспечения сбалансированной обработки, но может привести к чрезмерной или недостаточной обработке некоторых элементов данных.
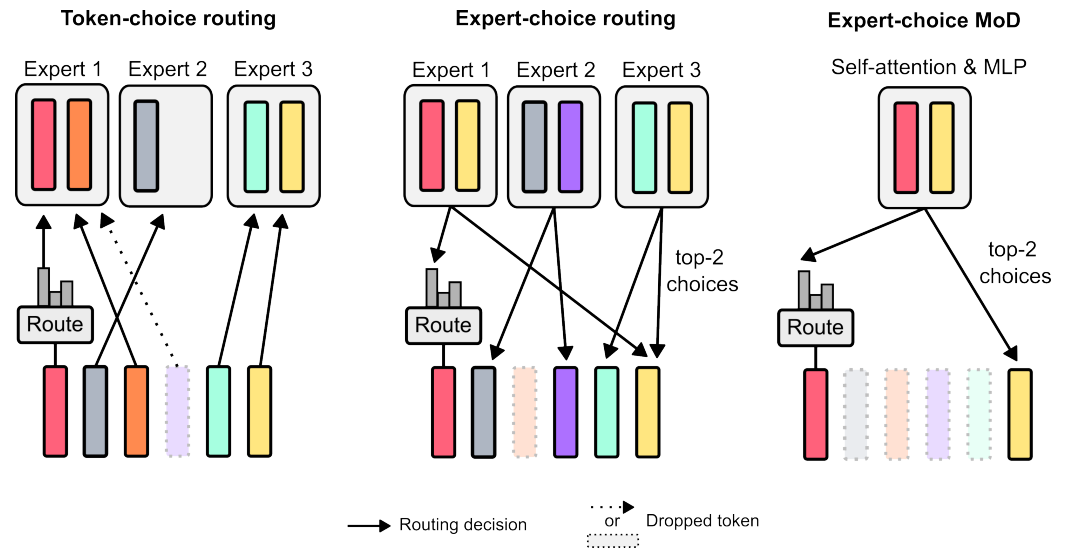
В этой статье в конечном итоге была выбрана схема маршрутизации на основе экспертов, поскольку она более эффективно балансирует вычислительные ресурсы и упрощает процесс реализации, как показано на рисунке выше. Благодаря этому методу модель может сократить объем вычислений и повысить эффективность работы при сохранении производительности.
«4. Отбор проб» В МО На этапе авторегрессионной выборки модели Transformer возникает проблема принятия эффективных решений о маршрутизации, не полагаясь на будущую информацию о токенах. Для решения этой проблемы в документе предлагаются две стратегии. Первый — ввести вспомогательные потери и настроить выходные данные маршрутизатора с помощью функции двоичной перекрестной энтропии потерь, чтобы модель могла принимать решения о причинной маршрутизации на основе текущей и прошлой информации о токене.
Вторая стратегия заключается в использовании вспомогательного предсказателя, который действует как небольшая вспомогательная сеть для прогнозирования того, должен ли каждый токен участвовать в вычислении, тем самым предоставляя необходимую информацию о маршрутизации во время процесса выборки. Оба метода позволяют избежать зависимости от будущих токенов и обеспечивают высокую производительность и эффективность модели при генерации последовательности.
«5. Модельное обучение»все Модель Все используют одну и ту же базовую конфигурацию гиперпараметров.(Например,128batch、2048 длина последовательности).
Результаты экспериментов
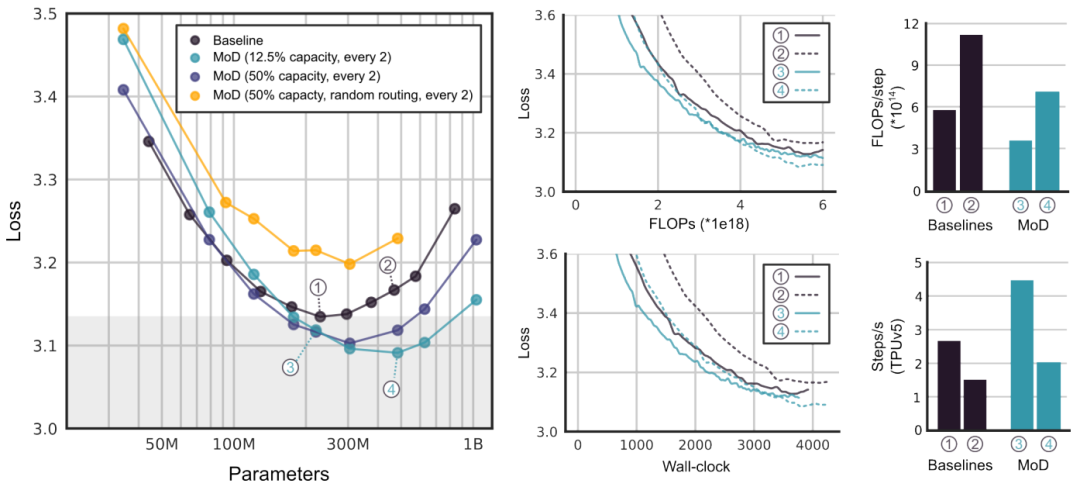
«Увеличение скорости» На рисунке ниже показаноMoDРезультаты тонкой настройки гиперпараметра,Включает сравнение производительности различных вариантов модели.,и кривая обучения,Описание модели при сохранении той же производительности,На 66 % быстрее, чем оптимальная базовая модель isoFLOP.。
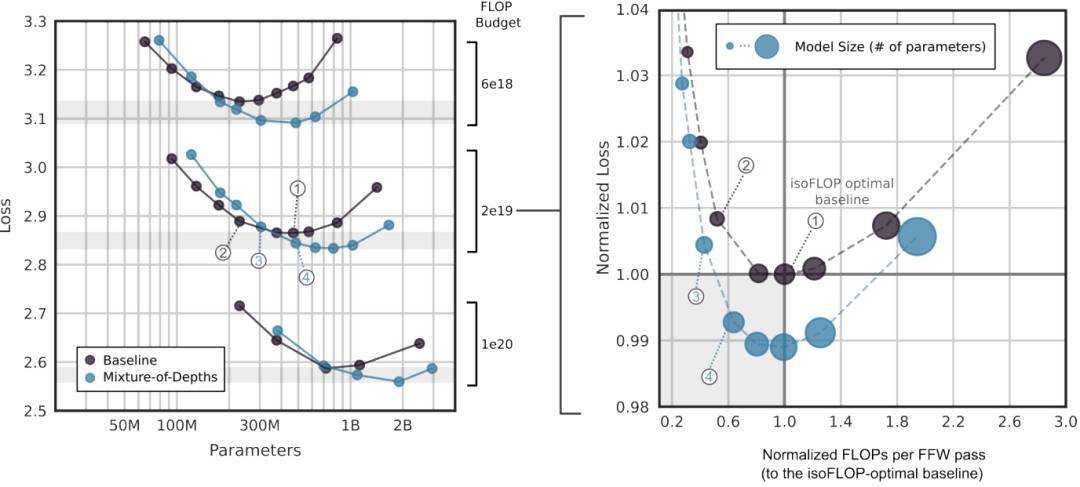
«изофлоп-анализ» Как показано на рисунке ниже, существуют некоторые варианты MoD, которые имеют более высокую скорость шага, чем оптимальная базовая модель isoFLOP, при этом обеспечивая меньшие потери при обучении. Эти результаты демонстрируют, что модель MoD способна достичь более высокой вычислительной эффективности при сохранении производительности.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
