Головная боль! Что такое сверточная нейронная сеть? Полное объяснение структуры, обучения и оптимизации CNN в одной статье.
В этой статье всесторонне обсуждается сверточная нейронная сеть CNN, углубленный анализ фона и важности, введение определения и уровня, обучение и оптимизация, подробный анализ ее слоя свертки, функции активации, уровня пула, уровня нормализации и, наконец, списки. Он включает в себя множество ключевых технологий для обучения и оптимизации: подготовка и улучшение обучающего набора, функция потерь, оптимизатор, регулировка скорости обучения, методы регуляризации, а также оценка и настройка модели. Автор TechLead имеет более чем 10-летний опыт работы в области архитектуры интернет-сервисов, опыт разработки продуктов искусственного интеллекта и опыт управления командой. Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud. профессионал в области управления проектами и менеджер по исследованиям и разработкам продуктов с доходом в сотни миллионов долларов.
1. Введение
Сложность и гибкость сверточных нейронных сетей (CNN) делают их одной из основных тем исследований в области глубокого обучения. В этом вводном разделе мы углубимся в историческую подоплеку, основы, важность и влияние CNN в науке и промышленности.
1.1 Предыстория и важность
Сверточные нейронные сети созданы на основе зрительной системы человека, в частности структуры нейронов зрительной коры. Со времени новаторской работы Хьюбела и Визеля в 1962 году эта идея положила начало серии исследований и разработок.
- раннее развитие: Ю Янн LeNet-5, разработанный Ле Куном и др. в конце 1980-х - начале 1990-х годов, считается первой успешной сверточной системой. нейронная сеть. LeNet-5 достигает впечатляющих результатов в распознавании рукописных цифр.
- Возвышение современности: Благодаря быстрому развитию аппаратного обеспечения и большомуданныепоявление,CNN начал свое возрождение в начале 2000-х годов.,И добился прорывного прогресса в различных областях.
Важность CNN отражается не только в ее точности и эффективности, но и в ее теоретических открытиях. Например, сверточные слои уменьшают количество параметров за счет совместного использования весов, что помогает более эффективно обучать модель, а также улучшает понимание модели трансляционной инвариантности.
1.2 Обзор сверточных нейронных сетей
Сверточная нейронная сеть — это нейронная сеть прямого распространения, искусственные нейроны которой могут реагировать на локальные области окружающих единиц, тем самым имея возможность идентифицировать некоторые структурные особенности визуального пространства. Ниже приведены ключевые компоненты сверточной нейронной сети:
- слой свертки: проходитьоперация свертки выявляет локальные особенности изображения.
- функция активации: Внесите нелинейность и повысьте выразительность Модели.
- Слой объединения: Уменьшите размерность объекта и увеличьте надежность модели.
- Полностью связный слой: После обработки пространственных объектов Полностью связный слой используется для классификации или регрессии.
Эти компоненты сверточной нейронной сети работают вместе, чтобы позволить CNN автоматически изучать значимые иерархии функций на основе необработанных пикселей. По мере увеличения глубины эти функции постепенно абстрагируются от базовых форм и текстур к сложным представлениям объектов и сцен.
Уникальным преимуществом сверточных нейронных сетей является их способность автоматизировать многие части проектирования функций, которые требуют ручного вмешательства в традиционном машинном обучении. Это не только позволяет ему достигать превосходных результатов во многих задачах, но также стимулирует широкий академический и промышленный интерес.
2. Введение в слои сверточной нейронной сети.
Сверточные нейронные сети состоят из нескольких слоев, каждый из которых имеет определенную цель и функцию. В этой части будут рассмотрены основные концепции операций свертки, функций активации, слоев пула и слоев нормализации.
2.1 Операция свертки
Операция свертки является ядром сверточной нейронной сети и включает в себя множество сложных концепций и деталей. Мы представим их один за другим.
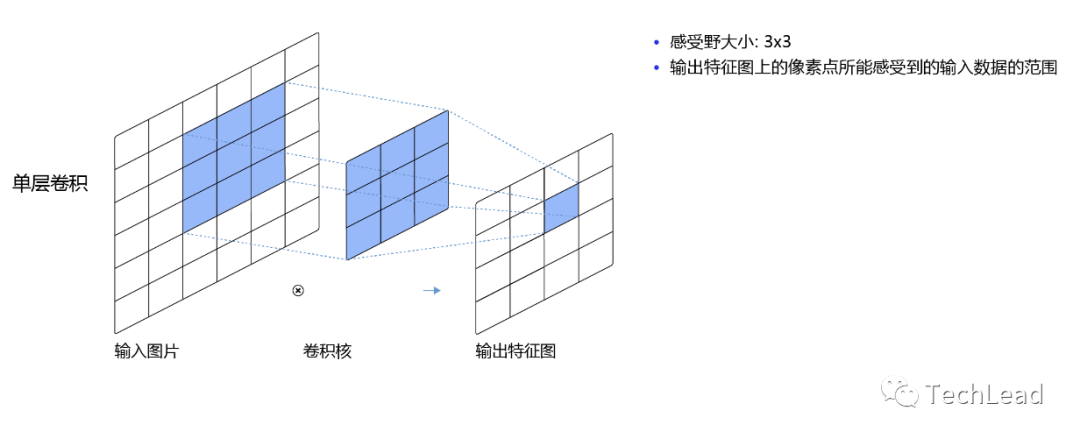
Ядро свертки и карта функций
Ядро свертки представляет собой небольшую матрицу, которая генерирует карты объектов путем скольжения по входным данным. Каждое ядро свертки может захватывать различные функции, такие как края, углы и т. д.
Размер ядра свертки
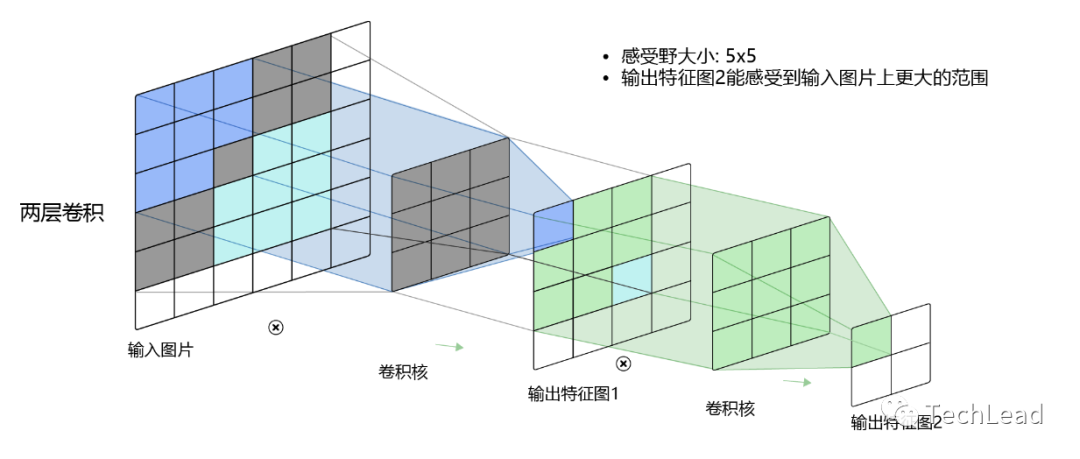
Размер ядра свертки влияет на масштаб функций, которые оно может захватывать. Меньшие ядра свертки могут захватывать более подробные функции, тогда как более крупные ядра свертки могут захватывать более широкие функции.
# Используйте ядро свертки 3x3
conv_layer_small = nn.Conv2d(3, 64, 3)
# Используйте ядро свертки 5x5
conv_layer_large = nn.Conv2d(3, 64, 5)
многоканальная свертка
Свертка выполняется для многоканального ввода, каждый входной канал свертывается с помощью ядра свертки, а затем все результаты складываются. Это позволяет модели захватывать различные функции из разных каналов.
Размер шага и отступы
длина контроль работы шаги и наполнения Геометрические свойства свертки.
длина шага
длина шаг определяет скорость, с которой ядро свертки движется на входе. большая длина шаг может уменьшить размер вывода, а меньшая длина шаг сохраняет размер неизменным.
# использоватьдлина шага2
conv_layer_stride2 = nn.Conv2d(3, 64, 3, stride=2)наполнение
наполнение Управляйте размером вывода, добавляя нули к краям ввода. Это помогает контролировать потерю информации при операции свертки.
# Используйте наполнение1, чтобы выходные размеры были такими же, как входные (при условии, что длина шагадля1)
conv_layer_padding1 = nn.Conv2d(3, 64, 3, padding=1)
Расширенная свертка
Атрусная свертка — это метод расширения рецептивного поля ядра свертки путем вставки пробелов между элементами ядра свертки. Это позволяет сети захватывать более широкий спектр информации без увеличения размера ядра или вычислительных затрат.
# Используйте ядро свертки с частотой дырок 2.
conv_layer_dilated = nn.Conv2d(3, 64, 3, dilation=2)
Групповая свертка
Групповая свертка расширяет операцию свертки, группируя входные каналы и используя разные ядра свертки для каждой группы. Это увеличивает емкость модели и позволяет ей изучать более сложные представления.
# Используйте 2 группы
conv_layer_grouped = nn.Conv2d(3, 64, 3, groups=2)
2.2 Функция активации
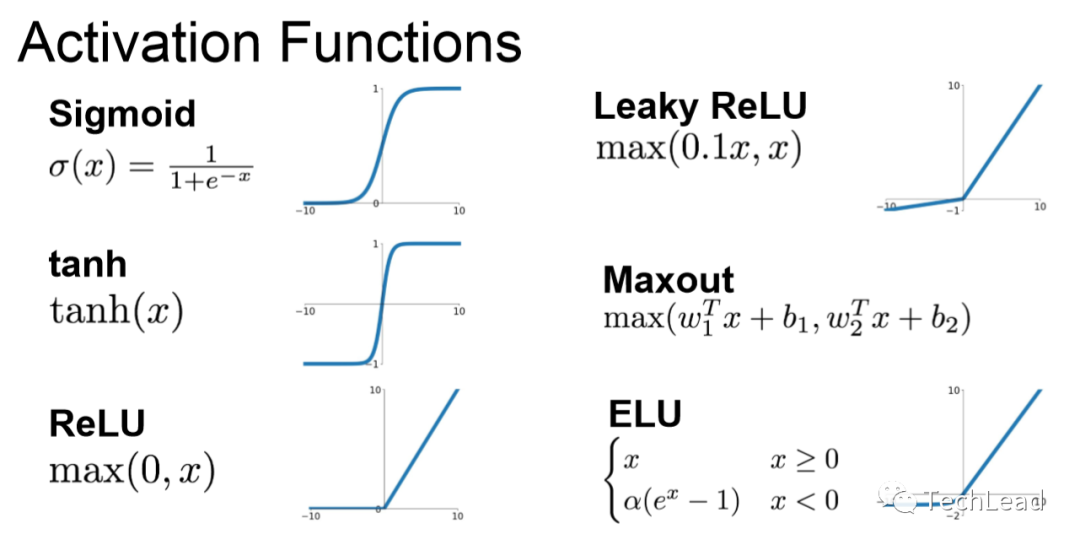
Функция активации играет решающую роль в нейронных сетях. Они увеличивают нелинейность модели, позволяя ей обучаться и аппроксимировать сложные функции.
Функция активации ReLU
ReLU (выпрямленная линейная единица) — одна из самых популярных функций активации в современном глубоком обучении. Он нелинейный, но очень эффективный в вычислительном отношении.
Преимущества и недостатки
Основными преимуществами ReLU являются его высокая вычислительная эффективность и поддержка редких активаций. Однако это может привести к феномену «мертвого ReLU», когда определенные нейроны никогда не активируются.
# Определите функцию с помощью PyTorch активации ReLU
relu = nn.ReLU()
Leaky ReLU
Leaky ReLU — это вариант ReLU, который допускает небольшие положительные наклоны для отрицательных входных значений. Это помогает смягчить проблему «мертвого ReLU».
# Определение Leaky с помощью PyTorch Функция активации ReLU
leaky_relu = nn.LeakyReLU(0.01)
Функция активации сигмовидной кишки
Функция активации сигмовидной кишки может сжимать любое значение от 0 до 1.
Преимущества и недостатки
Сигмоид может представлять вероятность при использовании в выходном слое, но может вызывать проблемы с исчезновением градиента в скрытом слое.
# Определите функцию с помощью PyTorch активации сигмовидной кишки
sigmoid = nn.Sigmoid()
Функция активации Тана
Tanh — еще одна функция активации, похожая на Sigmoid, но она сжимает выходные данные в диапазоне от -1 до 1.
Преимущества и недостатки
Tanh, как правило, лучше, чем Sigmoid, поскольку его выходной диапазон шире, но все равно может вызывать исчезновение градиентов.
# Определите функцию с помощью PyTorch активации Тана
tanh = nn.Tanh()
Функция активации Swish
Swish — это адаптивная функция активации, которая может автоматически корректировать свою форму в соответствии с конкретной проблемой.
# Определите функцию с помощью PyTorch активации Swish
class Swish(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
Другие функции активации
Есть еще много других функции активации,Такие как Softmax, Mish, ELU и т. д.,Каждый из них имеет свои преимущества и применимые сценарии.
Выбор функции активации
Выбор функции Эффективность зависит от многих факторов, таких как архитектура модели, тип данных и потребности конкретной задачи. Путем экспериментирования и настройки можно найти лучшую функцию для конкретной проблемы. активации。
2.3 Уровень объединения
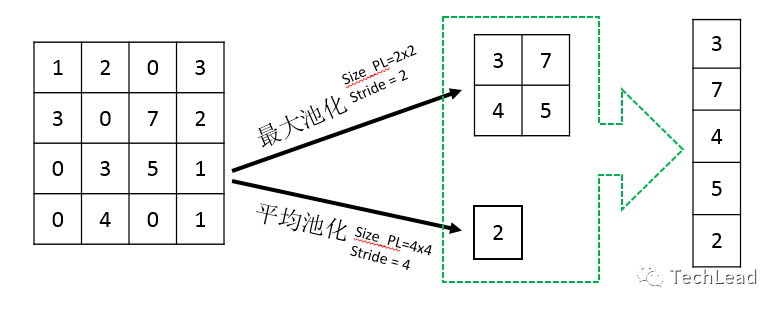
Уровень пула играет важную роль в сверточных нейронных сетях и обычно используется для уменьшения размерности карт признаков, тем самым снижая вычислительные требования и увеличивая восприимчивое поле детектора признаков.
Макс Пуллинг
Максимальное объединение — один из наиболее часто используемых методов объединения. Он уменьшает размер карты объектов, выбирая максимальное значение в окне.
# Определите максимальный размер Слоя 2x2 с помощью PyTorch. объединения
max_pooling = nn.MaxPool2d(2)
Преимущества и недостатки
Основное преимущество максимального пула заключается в том, что при нем сохраняются наиболее важные функции окна. Однако при этом теряются некоторые детали.
Средний пул
В отличие от максимального пула, средний пул использует среднее значение всех значений в окне.
# Определите 2x2 означает Слой, используя PyTorch объединения
average_pooling = nn.AvgPool2d(2)
Преимущества и недостатки
Среднее объединение может облегчить проблему, связанную с тем, что максимальное объединение может привести к чрезмерному подчеркиванию определенных функций, но может преуменьшить некоторые важные функции.
Глобальное среднее объединение
Объединение глобальных средних значений — это более сложная стратегия объединения, которая вычисляет среднее значение для всей карты объектов. Это часто используется на последнем уровне сети, непосредственно для классификации.
# Определение глобального среднего значения с помощью PyTorch объединения
global_average_pooling = nn.AdaptiveAvgPool2d(1)
Размер окна пула и шаг
Размер и длина окна пула шага напрямую повлияет на размер вывода. Большие окна и длина шага уменьшит размер более существенно.
Альтернативы объединению
Слой Уже существуют некоторые современные альтернативы объединению, такие как использование слоев. сверткииздлина шаг больше 1 или используйте расширенную свертку. Эти методы могут обеспечить лучшее сохранение функций.
Выбор слоя пула
Выбор конкретного типа слоя пула зависит от требований задачи и конкретных характеристик данных. Глубокое понимание того, как работают различные методы объединения, может дать представление о том, как они влияют на производительность модели.
2.4 Уровень нормализации
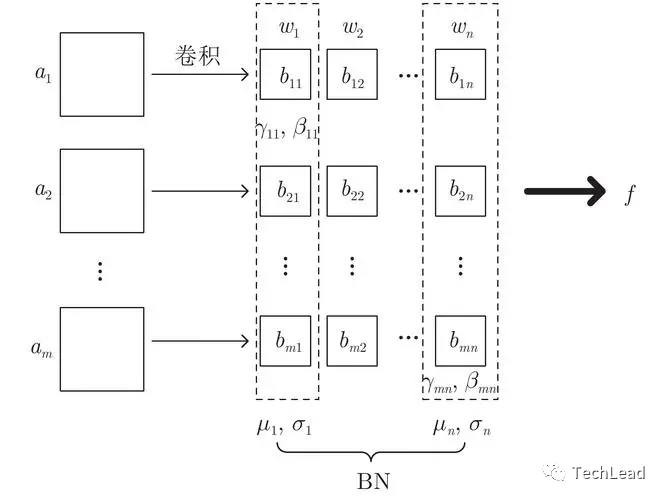
Слой нормализации играет ключевую роль в обучении глубоких нейронных сетей и в основном используется для повышения стабильности и скорости обучения. Слои нормализации помогают решить проблемы исчезновения и взрыва градиента во время обучения путем масштабирования входных данных до подходящего диапазона.
Пакетная нормализация
Пакетная нормализация масштабирует входные данные до нулевого среднего значения и единичной дисперсии путем нормализации входных данных для каждого канала признаков.
# Определение пакетов с помощью PyTorch нормализации
batch_norm = nn.BatchNorm2d(num_features=64)
Преимущества и недостатки
- Преимущества:это позволяет вышеизскорость обучения,Обеспечивает некоторые эффекты регуляризации,Обычно приводит к более быстрому обучению.
- Недостатки:существовать На небольших партияхиз Статистические оценки могут вызывать различия между обучением и выводом.изнепоследовательный。
Нормализация слоев
Нормализация слоев — это вариант нормализации всех функций в одном образце. Он особенно популярен в обработке предложений и рекуррентных нейронных сетях.
# Определение нормализации слоев с помощью PyTorch
layer_norm = nn.LayerNorm(normalized_shape=64)
Нормализация экземпляра
Нормализация экземпляра в основном используется для задач передачи стиля, где нормализация выполняется независимо для каждого канала каждого сэмпла.
# Определение нормализации экземпляра с помощью PyTorch
instance_norm = nn.InstanceNorm2d(num_features=64)
Групповая нормализация
Групповая нормализация представляет собой компромисс между пакетной нормализацией и нормализацией слоев, разделяя каналы на разные группы и нормализуя внутри каждой группы.
# Определите нормализацию группы с помощью PyTorch
group_norm = nn.GroupNorm(num_groups=32, num_channels=64)
Выбор слоя нормализации
Выбор уровня нормализации должен основываться на конкретных задачах и архитектуре модели. Например,в визуальных задачах,Пакетная нормализация может быть предпочтительнее.,И в задачах НЛП,Нормализация слоев может быть более полезной.
3. Обучение и оптимизация
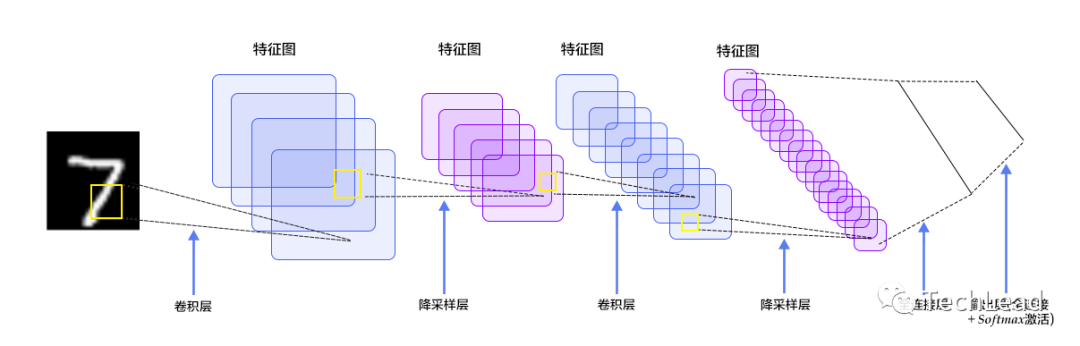
Обучение и оптимизация сверточных нейронных сетей включает в себя множество ключевых компонентов и методов, которые вместе определяют производительность и удобство использования модели. Эти аспекты подробно описаны ниже.
3.1 Подготовка и усовершенствование обучающего набора
Эффективные данные обучения являются основой успеха глубокого обучения. Для эффективного обучения сверточных нейронных сетей решающее значение имеет выбор и улучшение обучающих наборов.
Предварительная обработка данных
Предварительная обработка является ключевым этапом подготовки обучающего набора, включающим:
- стандартизация:Масштабируйте ввод до0-1объем。
- Централизация:Вычтите среднее значение,Сделайте данные центрированными в 0.
- Очистка данных:消除непоследовательный和错误изданные。
увеличение данных
Увеличение данных — это метод, который увеличивает объем данных путем применения случайных преобразований, тем самым увеличивая способность Модели к обобщению.
Общие методы улучшения
- Поворот изображения, масштабирование и обрезка
- Сглаживание цвета
- добавление случайного шума
# Различные улучшения изображений с помощью PyTorch
from torchvision import transforms
transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomResizedCrop(224),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1)
])
Разделение обучающего набора
Данные обычно делятся на обучающие, проверочные и тестовые наборы, чтобы гарантировать, что модель не переобучится.
3.2 Функция потерь
Функция потерь измеряет разрыв между предсказаниями модели и истинной целью. Выбор подходящей функции потерь является важным шагом в оптимизации производительности модели.
возвращение миссии
Для непрерывного прогнозирования значений обычно используйте:
- Среднеквадратическая ошибка (MSE):Измерьте разницу между прогнозируемым значением и истинным значениемизквадратичная разница。
# Определение потерь MSE с использованием PyTorch
mse_loss = nn.MSELoss()
- Плавная потеря L1:Уменьшите выбросыиз Влияние。
Классификационные задачи
Для прогнозирования категорий общие функции потерь включают в себя:
- перекрестная потеря энтропии:Измерьте разницу между прогнозируемым распределением вероятностей и истинным распределением.изразница。
# использоватьPyTorchопределениеперекрестная потеря энтропии
cross_entropy_loss = nn.CrossEntropyLoss()- Двоичныйперекрестная потеря энтропии:Специально для двоих Классификационные задачи。
- потеря нескольких меток:Подходит для классификации по нескольким меткам。
Оптимизировать функцию потерь
Выбор подходящей функции потерь зависит не только от типа задачи, но и от архитектуры модели, распределения данных и конкретных бизнес-показателей. Иногда может потребоваться специальная функция потерь, чтобы уловить основные проблемы конкретной проблемы.
3.3 Оптимизатор
Оптимизатор используется для обновления весов нейронной сети, чтобы минимизировать функцию потерь. Каждый оптимизатор имеет свои специфические математические принципы и сценарии применения.
Стохастический градиентный спуск (SGD)
SGD — это самый простой алгоритм оптимизации.
- БазовыйSGD: Обновите веса в направлении отрицательных градиентов.
- SGD с импульсом: Введен термин импульса для накопления предыдущих градиентов для более плавной сходимости.
# Определение SGD с помощью PyTorch с импульсомоптимизатор
optimizer_sgd_momentum = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
адаптивный оптимизатор
адаптивный оптимизатор может автоматически регулировать скорость обучения.
- Adam: Сочетает в себе преимущества Momentum и RMSProp.
# Определите оптимизатор Адама с помощью PyTorch
optimizer_adam = torch.optim.Adam(model.parameters(), lr=0.001)
- Адаград, RMSprop и т. д.: Для разных параметров существуют разные скорости обучения.
Рекомендации по выбору оптимизатора
- актуальность задачи: Разные оптимизаторы могут по-разному влиять на разные задачи и данные.
- Настройка гиперпараметров: Например, может потребоваться корректировка скорости обучения, импульса и т. д.
3.4 Регулировка скорости обучения
Скорость обучения является ключевым гиперпараметром оптимизатора, и ее настройка оказывает глубокое влияние на обучение модели.
фиксированная скорость обучения
Самый простой способ — использовать фиксированную скорость обучения. Но он может оказаться недостаточно гибким.
Планирование скорости обучения
Более сложный подход заключается в динамической корректировке скорости обучения во время обучения.
плановые корректировки
- уходит вниз: Уменьшите скорость обучения с фиксированным шагом.
- косинусный отжиг: Периодически корректируйте скорость обучения.
# Определите косинусный с помощью PyTorch планировщик отжига
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_adam, T_max=50)
адаптивная регулировка
- ReduceLROnPlateau: Уменьшите скорость обучения на основе потери при проверке.
Разминка скорости обучения
Постепенно увеличивайте скорость обучения на ранних этапах обучения.
- Линейный предварительный нагрев: Скорость обучения на начальном этапе увеличивается линейно.
3.5 Методы регуляризации
Регуляризация — это ключевая технология, позволяющая предотвратить переоснащение и улучшить способность модели к обобщению.
Регуляризация L1 и L2
- Регуляризация L1:Имеет тенденцию производить редкие веса,Помогает в выборе функций.
- Регуляризация L2:Уменьшить вес,Делает модель более плавной.
# Удалить диапазон PyTorch из L1 и L2
l1_лямбда = 0,0005
l2_лямбда = 0,0001
потеря = потеря + l1_lambda *torch.norm(веса, 1) + l2_lambda *torch.norm(веса, 2);Dropout
Случайным образом отключите некоторые нейроны, чтобы сделать модель более надежной.
- Нормальное отсев:Случайно отбрасывать нейроны。
- Spatial Dropout:существоватьслой Вся карта объектов случайным образом отбрасывается в свертки.
Batch Normalization
Ускорьте обучение и уменьшите чувствительность инициализации за счет нормализации входных данных слоев.
увеличение данных
Как упоминалось ранее, увеличение данных является важным методом регуляризации.
3.6 Оценка и настройка модели
Оценка модели — это процесс измерения производительности модели, а настройка — это процесс улучшения производительности.
перекрестная проверка
Используйте перекрестную проверку, чтобы оценить способность Модели к обобщению.
- k-складыватьперекрестная проверка:Воляданныеточкадляkчасти,Используйте один из них по очереди в качестве набора проверки.
Навыки настройки параметров
- поиск по сетке:Попробуйте разные комбинации гиперпараметров。
- случайный поиск:Случайный выбор гиперпараметров,Более эффективный.
Техники ранней остановки
Если потери при проверке больше не уменьшаются, обучение прекращается, чтобы предотвратить переобучение.
Интеграция модели
Улучшите производительность за счет объединения нескольких моделей.
- Bagging:тренировать несколько Модельи прогнозируем в среднем。
- Boosting:существоватьранее Модельиз Обучайте новых на ошибках Модель。
- Stacking:использоватьновый Модель Объединяйтесь с другими Модельизпредсказывать。
4. Резюме
В этой статье всесторонне обсуждается сверточная нейронная сеть CNN, углубленный анализ фона и важности, введение определения и уровня, обучение и оптимизация, подробный анализ ее слоя свертки, функции активации, уровня пула, уровня нормализации и, наконец, списки. Он включает в себя множество ключевых технологий для обучения и оптимизации: подготовка и улучшение обучающего набора, функция потерь, оптимизатор, регулировка скорости обучения, методы регуляризации, а также оценка и настройка модели. Его цель — предоставить исследователям искусственного интеллекта комплексное руководство по использованию сверточных нейронных сетей (CNN).



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
