Глубокое понимание MapReduce: использование Java для написания программ MapReduce [Шанцзинь Сяокай Чжу]
📬📬Я маленький новичок, специализирующийся на разработке программного обеспечения в Шэньянском технологическом университете. Мне нравится программировать и продолжать выдавать полезную информацию.
MapReduce — это модель параллельного программирования для обработки крупномасштабных наборов данных. Благодаря своей эффективности и масштабируемости MapReduce стала предпочтительным решением для многих крупных интернет-компаний для обработки больших данных. В этой статье мы подробно рассмотрим MapReduce и напишем простую программу MapReduce с использованием Java.
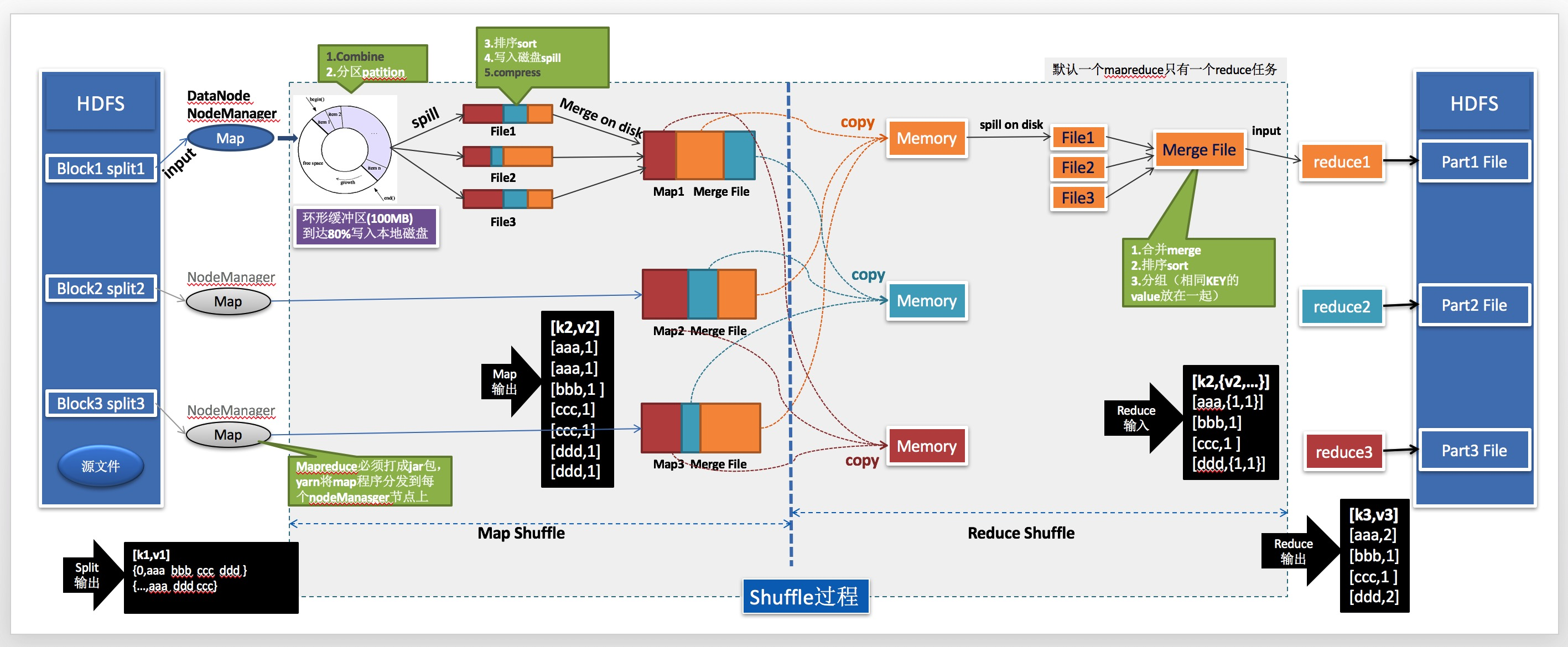
Принцип MapReduce
MapReduce состоит из двух основных этапов: Map и Reduce. В Этап В картах набор данных разделен на несколько небольших блоков, и каждый небольшой блок обрабатывается Mapfunction и выводит серию пар ключ-значение. В Уменьшить На этапе пары ключ-значение объединяются в меньший набор результатов. Ниже мы подробно объясним принципы каждого этапа.
Этап карты
Этап Входными данными для карты является исходный набор данных. Он делит входные данные на несколько небольших частей, и каждая маленькая часть обрабатывается Mapфункцией. Входные данные функции Mapfunction представляют собой пару ключ-значение, а выходные данные также являются парой ключ-значение. В Mapfunction каждая входная пара ключ-значение обрабатывается для создания набора промежуточных пар ключ-значение, которые будут использоваться как Уменьшить. фазовый ввод.
Уменьшить фазу
Уменьшить Входные данные для фазы: Этап. карты Выходной набор промежуточных пар ключ-значение。Reduceфункция Выполните операцию агрегирования для каждого ключа,и выведите результаты в окончательный набор результатов. Результатом функции уменьшения обычно является одна пара ключ-значение.,Но это также может быть несколько пар ключ-значение.
Этап перемешивания
Этап перемешиваниясуществоватьMapи Уменьшить Выполняется между фазами. В Этап В картах каждая задача Map генерирует набор промежуточных пар ключ-значение. В Этап перемешиваниясередина,Эти промежуточные пары ключ-значение будут отсортированы и сгруппированы по ключу.,Чтобы задачи сокращения могли параллельно обрабатывать промежуточные результаты с одинаковыми ключами.
Реализация программы MapReduce
Ниже мы напишем простую программу MapReduce, используя Java. Эта программа будет подсчитывать вхождения каждого слова во входном тексте.
Сначала нам нужно написать функцию Map. Функция Map сопоставляет каждое слово во входном тексте с парой ключ-значение, где ключом является само слово, а значение равно 1. Ниже приведен код функции Map:
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}Далее мы пишем функцию уменьшения. Функция уменьшения добавляет значения с одним и тем же ключом и выводит результат в виде пары ключ-значение. Ниже приведен код функции уменьшения:
javaCopy codepublic static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));Наконец, мы объединяем функцию Map и функцию уменьшения и передаем их в кластер Hadoop как часть программы MapReduce. Ниже приведена полная программа MapReduce:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}В приведенном выше коде мы сначала определяем класс Map и класс Редукция, затем объединяем их в основной функции и используем класс Job для отправки программы в кластер Hadoop для обработки. Мы указываем пути ввода и вывода с помощью FileInputFormat и FileOutputFormat.
Подвести итог
В этой статье представлен принцип MapReduceииспользоватьJavaписатьMapReduceпрограммаметод。MapReduceЭто мощная модель параллельного программирования.,Может использоваться для обработки крупномасштабных наборов данных. Если вы имеете дело с большими наборами данных,Тогда MapReduce может быть вашим первым выбором.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
