Глубокое погружение в прогнозирование временных рядов с помощью нейронных сетей LSTM
RNN (Recurrent Neural Network) — искусственная нейронная сеть, в которой узлы направленно соединены в кольцо. В отличие от нейронных сетей с прямой связью, RNN может использовать внутреннюю память для обработки входных последовательностей в любое время, то есть она не только изучает информацию в текущий момент, но также полагается на информацию о предыдущей последовательности, поэтому она имеет большой потенциал в распознавании речи. языковой перевод и т.п. преимущества.
RNN Сейчас существует множество вариаций, наиболее часто используемых, таких как LSTM, Seq2SeqLSTM и другие варианты, такие как Attention Механический Transformer Модели и т. д.。Принципы и структуры этих вариантов кажутся очень сложными.,Но на самом деле, если у вас есть определенные математические и компьютерные навыки,Изучая, внимательно разбирайтесь,Все позади легко решается。
Эта статья будет LSTM Внутренние знания делаютОчень сжатое введение (включая прямой вывод и цепное правило),Затем установите время. Модели оптимизации Модель,Наконец оцените Модель и сравните с ARIMA или ARIMA-GARCH Сравнение моделей.
1 Введение в базовую логику нейронной сети RNN
(Примечание: все приведенные ниже поясняющие схемы моделей взяты из изображений Baidu)
1.1 Входной слой, скрытый слой и выходной слой
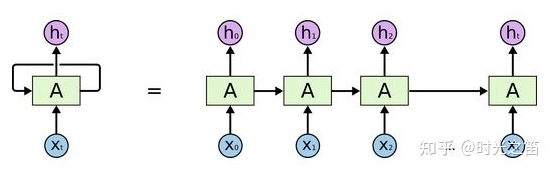
▲ Рисунок 1
На рисунке 1 выше, если предположить, что это пакетный ввод в последовательности (здесь количество выборок, размер выборочного объекта), соответствующее состояние скрытого слоя равно ( — длина скрытого слоя) и окончательный результат ( — размерность выходного вектора, то есть выходной вектор. Сколько элементов он содержит? Тогда при расчете времени действует формула:
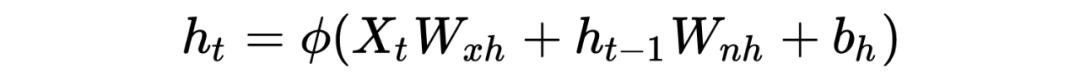
Вот это особая функция активации, вес, который нужно выучить,значение отклонения, которое необходимо изучить,Так Та же причинаРезультат: Параметры описаны выше!
1.2 Определение функции потерь
По характеру функции ошибки,Для проблем регрессии,Большинство из них основаны на расстоянии от среднеквадратической ошибки или функции абсолютной ошибки.,Если это проблема классификации,Мы в Все выберет перекрестную энтропию, такую как Функция!
Есть ошибка во времени ,Вот это реальная стоимость, это прогнозируемое значение. Тогда весь промежуток времени , у нас есть , наша цель — обновить все параметры и делать Минимум.
1.3 Градиентный спуск и вывод цепного правила
Вывод Вот более сложен.,Для того, чтобы каждый мог понять всю идею Модели, а не просто академические исследования.,Будут представлены только ключевые моменты! И функция активации упрощена!
Для обновления параметров используется классический формат градиентного спуска: , основываясь на знаниях в области исчисления, мы знаем, что формула правила цепочки: если , то может быть выражена как процесс цепного вывода!
Теперь выведем результаты цепного вывода каждой функции для любой. вывод времени , это легко узнать из определения функции потерь: , то для обновлено всего несколько шагов, чтобы добраться ,проситьидоступный:
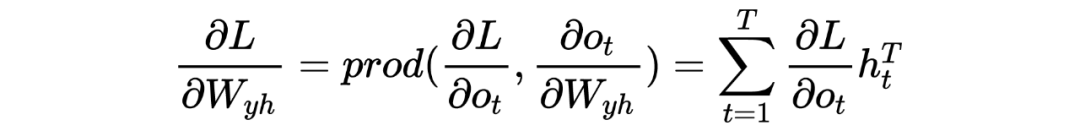
Для конечного момента мы легко имеем:
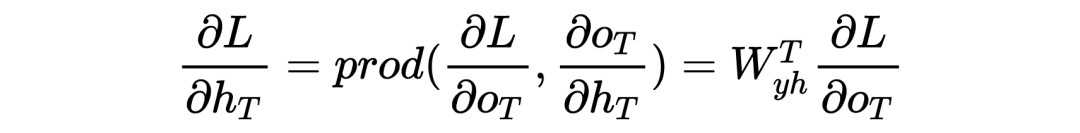
Но для < time получение скрытого слоя сложнее, поскольку существует временной контекст, поэтому мы имеем:
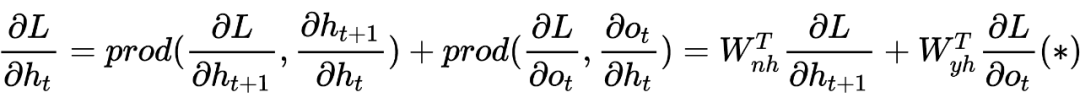
Таким же образом нам легко решить:
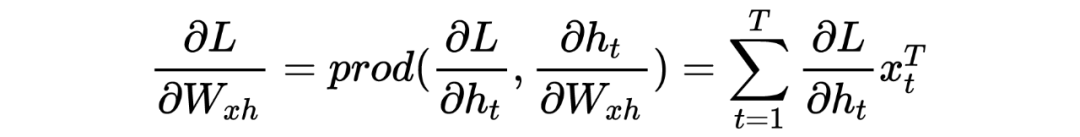
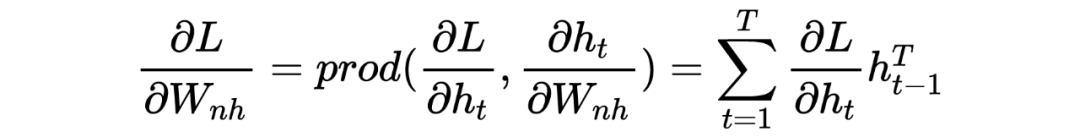
2 Объяснение принципа градиентной диссипации (взрыва)
Как правило, модели RNN имеют проблемы диссипации градиента (взрыва) в правиле цепочки, поэтому нам необходимо разработать новые варианты решения этой проблемы. Так где же эта проблема градиента? Внимательно обнаружите, что в процессе вывода уравнения (*) в предыдущем разделе для вывода скрытого слоя мы можем продолжить переписывать уравнение (*), чтобы получить:
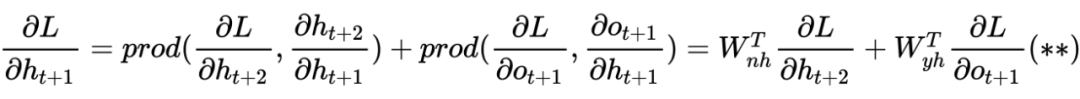
Мы отодвигаемся еще на один шаг назад, а затем по очереди приближаемся к этому моменту, и, наконец, с помощью математической индукции легко получить:
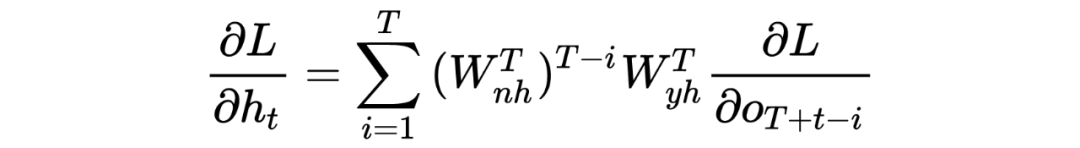
Из этой формулы мы знаем, что когда 、 Он становится больше и меньше. Для расчетов мощности результатом будет внезапное изменение. Большой будет иметь тенденцию стабилизироваться и исчезнуть! Из этого целом RNN Теория представлена здесь. Если вы хотите узнать о ней больше, вы можете проверить соответствующие статьи.
3 Введение в основную теорию LSTM
Чтобы лучше фиксировать зависимости с большими временными интервалами, была создана сеть длинной и короткой памяти (LSTM), основанная на управлении воротами!
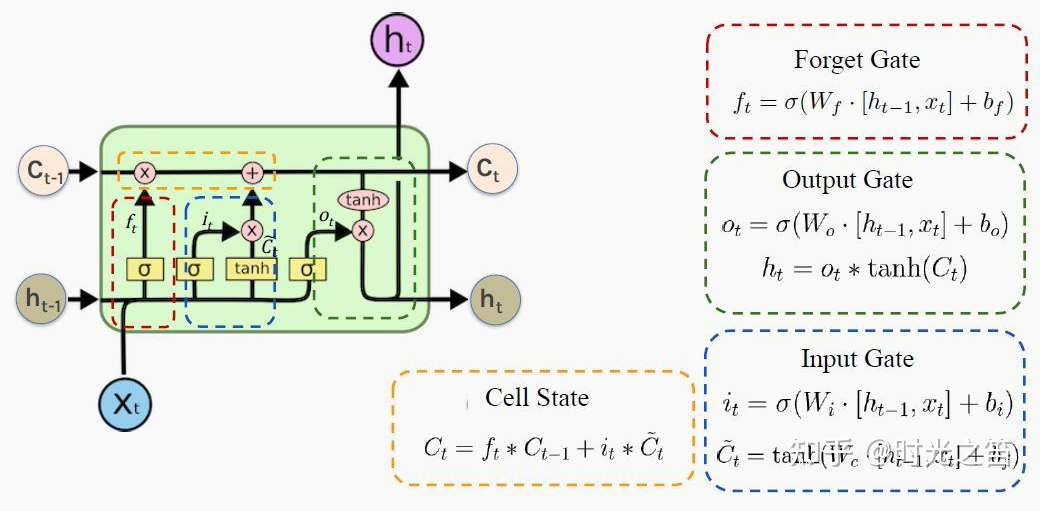
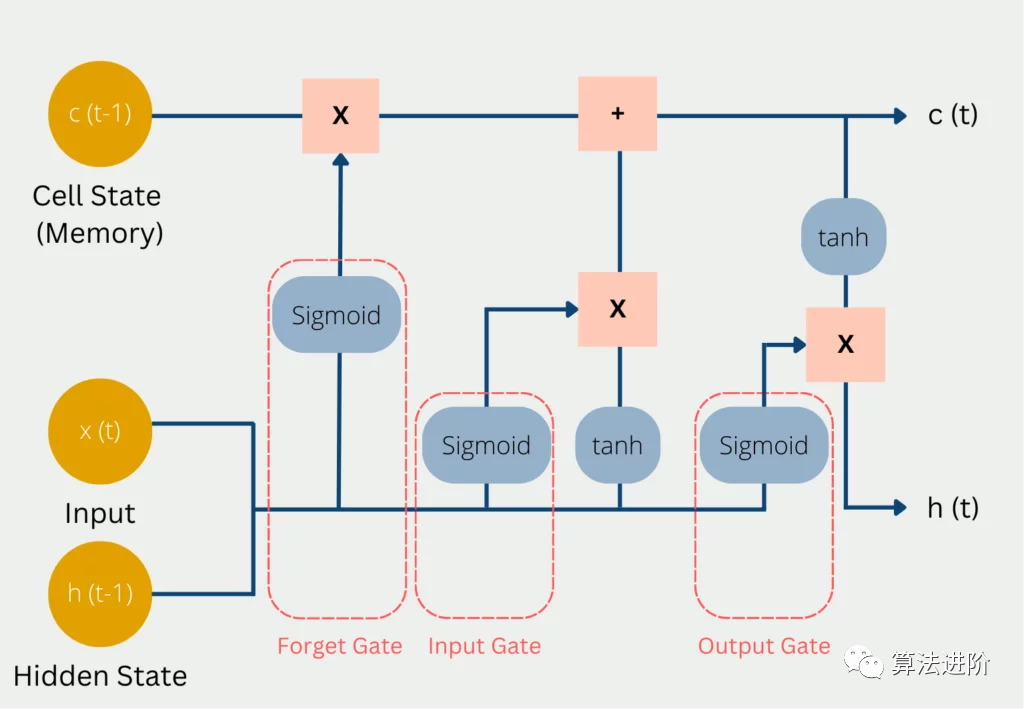
▲ Рисунок 2
так называемый“Дверь”Структура используется для удаленияиливозможность добавлять информацию о состоянии ячейки。Вот Состояние сотовой связи — это ядро,Это особый скрытый слой,похож на конвейерную ленту,Пробежаться по всей цепочке,На нем будет легко поддерживать поток информации!
На рисунке 2 выше наглядно изображена «трехворотная структура», лежащая в основе LSTM. Красный кружок — это так называемые ворота забывания, тогда во времени выражается следующая формула (если мы действительно поймем логику RNN, LSTM станет легче понять):
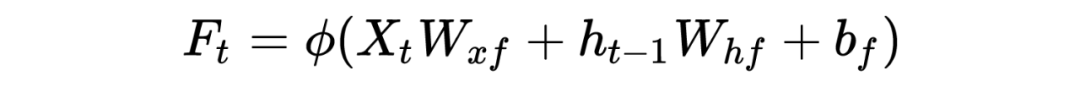
Входные ворота синего круга имеют
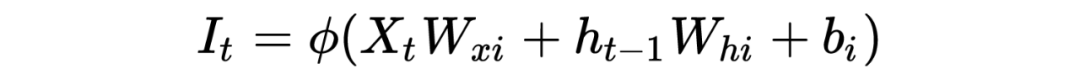
Выходной вентиль зеленого круга имеет

Аналогично, параметры, задействованные выше и Для параметров, которые необходимо обновить через правило цепочки! Тогда окончательная формула расчета информации о ячейке желтого круга будет следующей:
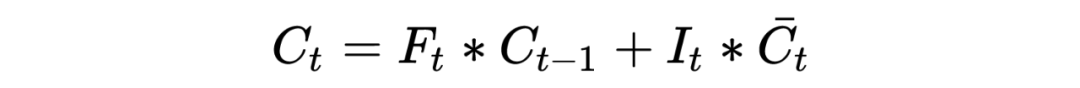
в
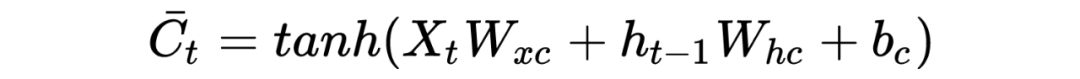
Здесь задействована функция гиперболического тангенса. в Цело фиксировано,Так что это такое большое дело,Какова цель участия в таком большом количестве процессов контроля информации? когда, конечно, с целью обновления клеток. скрытого слоя:
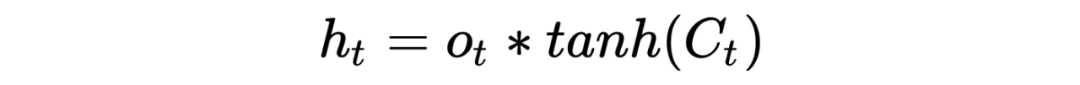
3.1 Значение функции активации сигмовидной кишки
когда Выбор функции активации sigmoid принадлежать 0~1 изфункциячас,Для ворот забывания оно примерно равно 1. Входной вентиль примерно равен 0, вообще-то Он не обновляется, поэтому информация о прошлых ячейках сохраняется до сих пор, что решает проблему рассеивания градиента.
Точно так же выходной вентиль может быть примерно равен 1, что также может быть приблизительно равно 0,Так приблизительно равно 1 Когда информация о ячейке будет передана на скрытый слой, примерно равна; 0 В это время информация о ячейке сохраняется только сама по себе. В этот момент все параметры обновляются и продолжают снижаться. . .
PS: Для новичков может быть головной болью видеть такое количество символов, но логика идет от простого к сложному. Глубокое понимание RNN поможет разобраться в более глубокой модели позже. Я также опустил здесь многие детали. Общая структура модели такова, что достаточно, чтобы понять, как она работает. Что касается того, как он это придумал и более подробного процесса вывода, из-за ограниченного уровня автора вы можете обратиться к соответствующим статьям RNN, а также обменяться информацией и узнать больше!
4 Что делать, если в прогнозе моделирования есть «правое смещение»?
Для проведения сравнительных экспериментов мы также выберем фактические данные о продажах, соответствующие предыдущим статьям временного ряда! Мы построим собственную сеть LSTM на основе модуля keras для прогнозирования временных рядов.

▲ Рисунок 3. Фактические данные о продажах.
4.1 Строить целомLSTMМодель,Когда мы выбираем размер шага равный 1,Сначала дайте результаты следующим образом
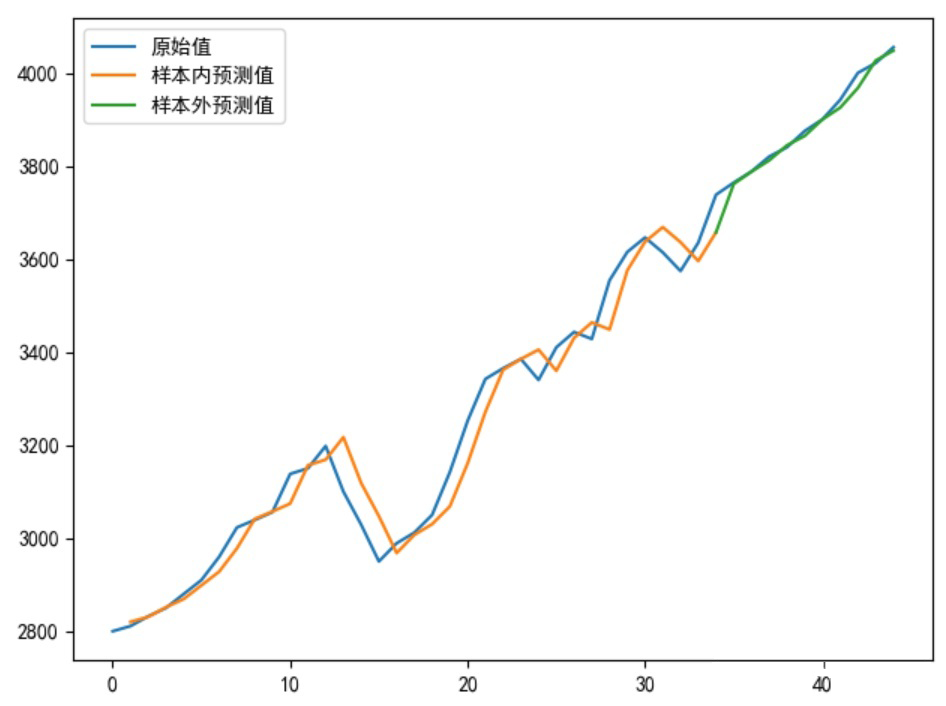
▲ Рисунок 4
Нормальное заведение LSTM Модель Прогнозируется, что вышеперечисленное появитсяПрогнозы смещены вправо,хотя r2 или ВОЗ MSE Очень хорошо, но установленная модель на самом деле является недействительной моделью!
4.2 Причины и улучшения
когда Модель имеет тенденцию использовать истинное значение предыдущего времени в качестве прогнозируемого значения следующего времени.,что приводит к гистерезису на двух кривых,То есть кривая истинной стоимости отстает от кривой прогнозируемой стоимости.,Как показано на картинке 4 Таким образом。Причина, почему это так,Это потому, что последовательность имеет автокорреляцию,Например, автокорреляция первого порядка относится к корреляции между значением предыдущего времени и его значением предыдущего времени. поэтому,Если последовательность имеет автокорреляцию первого порядка,Модель изучает корреляцию первого порядка. Способ устранения автокорреляции – выполнение дифференциальных операций.,То есть мы можем использовать разницу между предыдущим временем и предыдущим временем в качестве цели регрессии.
Более того, тест белого шума, проведенный в предыдущей статье, также показал, что последовательность действительно имеет сильную автокорреляцию! Как показано на рисунке 5 ниже.
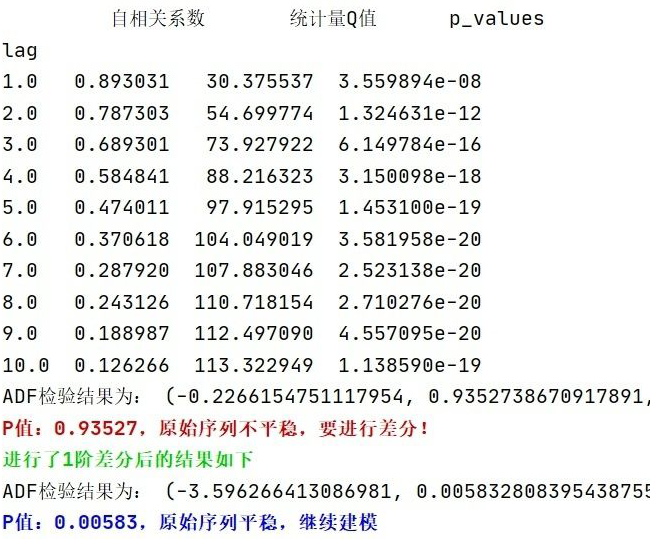
▲ Рисунок 5
5 Улучшение вывода модели
Давайте посмотрим на конечный результат модели:


▲ Рисунок 6: Результаты LSTM
5.1 Оптимальные результаты вывода при классической модели синхронизации
Принцип упорядочивания и модельный анализ модели ARIMA:
https://zhuanlan.zhihu.com/p/417232759

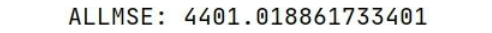
▲ Рисунок 7: Результаты ARIMA
Глобальный взгляд на этот результат MSE=4401.02 больше, чем LSTM сеть MSE=2521.30, видно, что оптимизируем LSTM После моделирования в определенной степени моделирование временных рядов лучше,чем ARIMA или ВОЗ ARIMA-GARCH Будьте превосходны!
LSTM теория прогнозирования и ARIMA Есть и разница, LSTM В основном он основан на скольжении окон с использованием обучения данным для прогнозирования задержки данных. cell Механизм позволит снизить некоторые параметры за счет распределения веса ARIMA; Модель основана на теории авторегрессии для построения модели, связанной с собственным прошлым. Общим для них является то, что они могут эффективно использовать данные о последовательностях и прогнозировать бесконечно посредством непрерывной итерации. Однако модель прогнозирования, основанная на краткосрочных прогнозах, по-прежнему эффективна. Долгосрочные прогнозы неизбежно приведут к большим отклонениям. и прогнозируемые значения могут стать неизменными.
6 окончательный код
from keras.callbacks import LearningRateScheduler
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
import matplotlib.pyplot as plt
from keras.layers import Dense
from keras.layers import LSTM
from keras import optimizers
import keras.backend as K
import tensorflow as tf
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']##Проблема с искажением китайского языка!
plt.rcParams['axes.unicode_minus']=False#Отрицательный знак абсцисс указывает на проблему!
###Параметры инициализации
my_seed = 369# Просто дайте случайное начальное число
tf.random.set_seed(my_seed)##Запуск tf действительно может исправить случайное начальное число
sell_data = np.array([2800,2811,2832,2850,2880,2910,2960,3023,3039,3056,3138,3150,3198,3100,3029,2950,2989,3012,3050,3142,3252,3342,3365,3385,3340,3410,3443,3428,3554,3615,3646,3614,3574,3635,3738,3764,3788,3820,3840,3875,3900,3942,4000,4021,4055])
num_steps = 3##Получить размер шага последовательности
test_len = 10##Количество и длина тестового набора
S_sell_data = pd.Series(sell_data).diff(1).dropna()##Разница
revisedata = S_sell_data.max()
sell_datanormalization = S_sell_data / revisedata##данные Стандартизировать
##данные Преобразование формы очень важно! !
def data_format(data, num_steps=3, test_len=5):
# Группировать по test_len
X = np.array([data[i: i + num_steps]
for i in range(len(data) - num_steps)])
y = np.array([data[i + num_steps]
for i in range(len(data) - num_steps)])
train_size = test_len
train_X, test_X = X[:-train_size], X[-train_size:]
train_y, test_y = y[:-train_size], y[-train_size:]
return train_X, train_y, test_X, test_y
transformer_selldata = np.reshape(pd.Series(sell_datanormalization).values,(-1,1))
train_X, train_y, test_X, test_y = data_format(transformer_selldata, num_steps, test_len)
print('\033[1;38m Исходная информация об измерении последовательности: %s; преобразованный обучающий набор Информация об Xданных измерениях: %s, Информация об измерениях Y: %s; тестовый набор Информация об измерениях Xd: %s, Информация об измерениях Y: %s \ 033[0m'%(transformer_selldata.shape, train_X.shape, train_y.shape, test_X.shape, test_y.shape))
def buildmylstm(initactivation='relu',ininlr=0.001):
nb_lstm_outputs1 = 128#Количество нейронов
nb_lstm_outputs2 = 128#Количество нейронов
nb_time_steps = train_X.shape[1]#Длина временного ряда
nb_input_vector = train_X.shape[2]#Входная последовательность
model = Sequential()
model.add(LSTM(units=nb_lstm_outputs1, input_shape=(nb_time_steps, nb_input_vector),return_sequences=True))
model.add(LSTM(units=nb_lstm_outputs2, input_shape=(nb_time_steps, nb_input_vector)))
model.add(Dense(64, activation=initactivation))
model.add(Dense(32, activation='relu'))
model.add(Dense(test_y.shape[1], activation='tanh'))
lr = ininlr
adam = optimizers.adam_v2.Adam(learning_rate=lr)
def Scheduler(epoch):##Запись изменений скорости обученияфункция
# Каждую эпоху скорость обучения снижается до 1/10 от исходной.
if epoch % 100 == 0 and epoch != 0:
lr = K.get_value(model.optimizer.lr)
K.set_value(model.optimizer.lr, lr * 0.1)
print('lr changed to {}'.format(lr * 0.1))
return K.get_value(model.optimizer.lr)
model.compile(loss='mse', optimizer=adam, metrics=['mse'])##В зависимости от характера потерьфункция регрессионного моделированияв В целом выберите «ошибку расстояния» в качестве функции потерь, классификации. В целом выберите функцию потери «Перекрестная энтропия».
reduce_lr = LearningRateScheduler(scheduler)
###данные Несколько серий, полный формат участия, эпохив целое пропорционально пакетному размеру
##callbacks: функция обратного вызова, вызов уменьшения_lr
##verbose=0: Неизбыточная печать, т. е. процесс обучения не печатается.
batchsize = int(len(sell_data) / 5)
epochs = max(128,batchsize * 4)##Минимальное количество циклов 128
model.fit(train_X, train_y, batch_size=batchsize, epochs=epochs, verbose=0, callbacks=[reduce_lr])
return model
def prediction(lstmmodel):
predsinner = lstmmodel.predict(train_X)
predsinner_true = predsinner * revisedata
init_value1 = sell_data[num_steps - 1]##Из-за соотношения длины шага отправной точкой здесь является num_steps
predsinner_true = predsinner_true.cumsum() ##Дифференциальное восстановление
predsinner_true = init_value1 + predsinner_true
predsouter = lstmmodel.predict(test_X)
predsouter_true = predsouter * revisedata
init_value2 = predsinner_true[-1]
predsouter_true = predsouter_true.cumsum() ##Дифференциальное восстановление
predsouter_true = init_value2 + predsouter_true
# Рисунок
plt.plot(sell_data, label='исходное значение')
Xinner = [i for i in range(num_steps + 1, len(sell_data) - test_len)]
plt.plot(Xinner, list(predsinner_true), label='прогнозируемое значение в выборке')
Xouter = [i for i in range(len(sell_data) - test_len - 1, len(sell_data))]
plt.plot(Xouter, [init_value2] + list(predsouter_true), label='Значение прогноза вне выборки')
allpredata = list(predsinner_true) + list(predsouter_true)
plt.legend()
plt.show()
return allpredata
mymlstmmodel = buildmylstm()
presult = prediction(mymlstmmodel)
def evaluate_model(allpredata):
allmse = mean_squared_error(sell_data[num_steps + 1:], allpredata)
print('ALLMSE:',allmse)
evaluate_model(presult)
Приведенный выше код можно использовать напрямую. Я прокомментировал ключевые моменты, если что-то неясно, вы можете поделиться со мной. Возможно, в этом коде есть некоторая оптимизация, поэтому поделитесь со мной. для LSTM Моделирование и преобразование измерений данных — необходимые этапы, и каждый должен внимательно их понимать!
7 Подвести итог
Никто не всемогущ, главное – уметь находить и решать проблемы.
Моделирование малых данных зачастую сложнее, чем больших данных, и требует больше размышлений.
Для глубокого обучения Модель,Я по-прежнему настоятельно рекомендую вам иметь общее представление о значении и принципах модели.,Если у вас есть условия, вы можете даже вывести их самостоятельно или просто реализовать алгоритм градиентного спуска, построение функции потерь и т. д.,В противном случае будет сложно решить реальную проблему.
автор | Фэн Тайтао единица | Шанхайский университет науки и технологий Направление исследований | Теория вероятностей и математическая статистика
Рекомендуем к прочтению
👉Расширенное руководство по пандам



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
