[Глубокое обучение] Введение в Transformer
В последние годы модель Transformer распространилась по области обработки естественного языка (NLP). Модели, представленные BERT и GPT, неоднократно возглавляли список и теперь стали стандартной моделью в этой области. В то же время в таких областях, как компьютерное зрение, модели Трансформеров постепенно привлекли внимание, и все больше и больше исследовательских усилий начали внедрять такие модели в алгоритмы. Эта статья основана на статье, опубликованной Google в 2017 году, и знакомит с принципами модели Transformer.
1. Зачем представлять Трансформер?
Самая ранняя предложенная модель Transformer [1] предназначена для задач перевода на естественный язык. В задачах перевода на естественный язык необходимо понимать значение каждого слова и использовать последовательную связь слов. Обычно используемые модели естественного языка — это рекуррентная нейронная сеть (RNN) и сверточная нейронная сеть (CNN).
Среди них модель рекуррентной нейронной сети считывает одно слово за раз и обновляет скрытое состояние узла на основе текущего скрытого состояния узла и входного слова. Судя по описанному выше процессу, когда рекуррентная нейронная сеть обрабатывает предложение, она может обрабатывать только одно слово по порядку. Предыдущие слова должны быть обработаны до того, как будут обработаны последующие слова. Следовательно, вычисления рекуррентной нейронной сети. все сериализованы, обучение модели и вывод модели займут больше времени.
С другой стороны, сверточная нейронная сеть рассматривает все предложение как 1*D-мерный вектор (где D — размерность признаков каждого слова) и обрабатывает предложение посредством одномерной свертки. В сверточных нейронных сетях за счет наложения сверточных слоев размер рецептивного поля каждого сверточного слоя постепенно увеличивается, тем самым используя контекст. Поскольку сверточная нейронная сеть не различает каждый блок в предложении, она может обрабатывать каждый блок в предложении параллельно. Таким образом, во время расчета процесс расчета каждого слоя можно легко распараллелить, а эффективность вычислений выше, чем у. круговые нейронные сети. Однако в модели сверточной нейронной сети для установления связи между двумя словами необходимая глубина сети положительно связана с расстоянием до слова в предложении. Поэтому трудно изучить ассоциацию на большом расстоянии в предложении. предложение через модель сверточной нейронной сети. Очень большое.
Модель Трансформера была предложена для решения двух вышеупомянутых проблем: (1) она может эффективно вычисляться; (2) она может точно запоминать ассоциации в предложениях на расстоянии.
2. Введение в модель трансформатора.
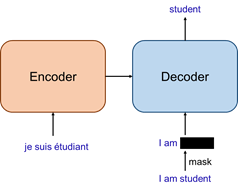
Как показано на рисунке ниже, модель Transformer использует классическую структуру кодера-декодера. Среди них предложение, подлежащее переводу, используется в качестве входных данных кодера. После кодирования кодировщиком оно затем вводится в декодер. Помимо получения выходных данных кодера, декодеру также нужны выходные слова. были получены до текущего шага. Конечным результатом всей модели является переведенное предложение. Вероятность следующего слова.
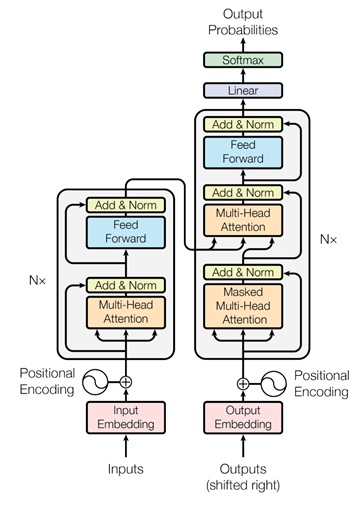
В существующих методах кодер и декодер обычно реализуются посредством многослойных рекуррентных нейронных сетей или сверток, тогда как Transformer предлагает новый, полностью основанный на внимании сетевой уровень для замены существующих модулей, как показано ниже. Как показано на рисунке. Кодер и декодер на рисунке имеют схожую структуру. Оба они состоят из модулей, сложенных N раз. Однако существуют определенные различия в модулях, используемых в кодере и декодере. В частности, базовый модуль кодера включает в себя две части: операцию многоголового внимания (Multi-Head Attention) и многоуровневый персептрон (Feed Forward). Базовый модуль декодера включает в себя две различные операции многоголового внимания (Masked Multi); - Head Attention и Multi-Head Attention), многослойный перцептрон (Feed Forward) три части.
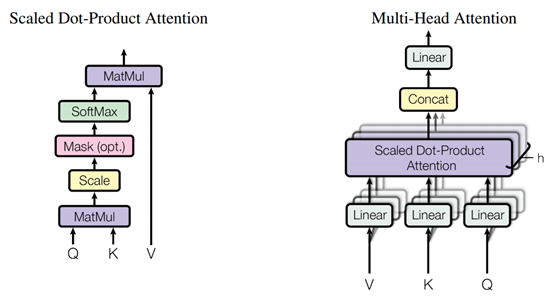
Среди вышеперечисленных операций основной частью являются три различные операции Multi-Head Attention. Процесс этой операции показан на рисунке ниже. Его можно просто понять как преобразование входного признака через взаимосвязь между признаками (вниманием). ), усиливать или ослаблять интенсивность различных размеров объекта. В модели используются следующие три модуля внимания:
- Многоголовое внимание в кодировщике: входные данные многоголового внимания в кодировщике содержат только выходные данные предыдущего базового модуля в кодере, используют выходные данные предыдущего базового модуля для расчета внимания и корректируют выходные данные предыдущего базового модуля. модуль, поэтому это механизм «самообслуживания»;
- Замаскировано в декодере Multi-Head Внимание: Трансформатор,Входными данными для декодера является полное целевое предложение.,Во избежание использования Моделью слов, которые еще не обработаны.,Поэтому в базовом модуле декодера,Добавлена маска в механизм «самовнимания».,Тем самым блокируя информацию, которая не должна использоваться Моделью;
- Мультиголовка в декодере Внимание: В декодере помимо самообслуживания должна использоваться выходная информация кодера для корректной обработки текста. Поэтому декодер использует на одну мультиголовку больше, чем кодировщик. внимание, чтобы объединить информацию входного предложения и предложений, которые были сгенерированы. Эта мультиголовка Внимание использует выходные данные предыдущего уровня «самовнимания» в декодере и выходные данные кодера для расчета внимания, а затем преобразует выходные данные кодировщика, используя преобразованный выходной сигнал кодера в качестве выходного результата, что эквивалентно на основе текущего результата перевода и оригинала. На предложении для определения последующих действий следует сосредоточиться на слово.
В дополнение к основной операции Multi-Head Attention автор также использует кодирование позиции, остаточное соединение, нормализацию слоев, выпадение и другие операции для соединения ввода, внимания и многослойного персептрона для формирования полной модели Трансформера. Изменяя такие параметры, как количество базовых модулей, установленных в кодере и декодере, количество узлов многоуровневого перцептрона и количество головок в многоголовом внимании, можно получить различные структуры модели, такие как BERT и GPT-3. .
3. Результаты экспериментов
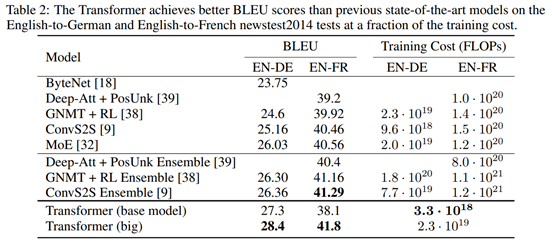
В ходе эксперимента автор обучил модель на newstest2013 и newstest2014 и проверил точность перевода модели между англо-немецким и англо-французским языками. Результаты экспериментов показывают, что модель Трансформера обеспечивает высочайшую точность, а затраты на ее обучение на один-два порядка ниже, чем у существующих методов, что демонстрирует превосходство этого метода.
Сравнительные эксперименты с существующими методами показывают более высокие оценки BLEU и меньшие вычислительные затраты:
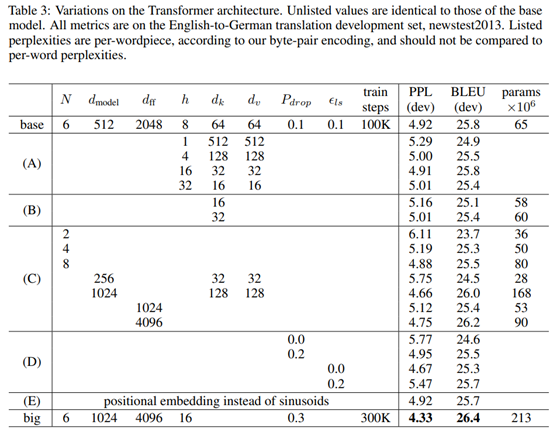
Проверка достоверности модуля. Такие параметры, как размерность каждого отдельного момента в модели, количество голов в режиме многоголового внимания и количество стеков базовых модулей, оказывают существенное влияние на точность модели:
Ссылки
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin. Attention Is All You Need. NIPS 2017.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
