Глубина что угодно | Дань уважения SAM,Гонконг&Байт предлагает большую оценку глубины для произвольных изображенийМодель,ужеОткрытый исходный код!

https://arxiv.org/abs/2401.10891 https://github.com/LiheYoung/Depth-Anything https://depth-anything.github.io/
В данной статье предлагается метод монокулярной оценки глубины (Монокулярный Depth Estimation, MDE)очень практичное решениеDepth Anything「платить даньSegment Anything», целью которого является создание простой и мощной базовой глубокой модели, способной обрабатывать любое изображение в среде задачи. С этой целью автор исследовал три аспекта:
- Размеры набора данных,дизайн разработал движок данных для сбора данных и автоматического аннотирования.,Построено около 62 млн крупномасштабных немаркированных данных.,Это значительно улучшает охват данных и уменьшает ошибки обобщения;
- используяданные Создан инструмент для аугментацииБолее сложная цель оптимизации,Посоветуйте модели активно изучать дополнительные визуальные знания.,тем самым улучшая надежность функций;
- дизайн ПонятноСвоего рода вспомогательная информация о надзорезаставить Модельот предварительной тренировкиEncoderНаследовать богатую семантическую предварительную информацию。
Автор оценил возможности модели с нулевым снимком на шести общедоступных наборах данных и случайно снятых изображениях; новый SOTA был достигнут путем точной настройки измеренной информации о глубине, а затем была создана более совершенная модель глубины, которая затем привела к созданию более эффективной сети ControlNet с контролем глубины; Для получения дополнительных демонстрационных примеров рекомендуется перейти на домашнюю страницу проекта: https://eepsearch-anything.github.io.

План этой статьи
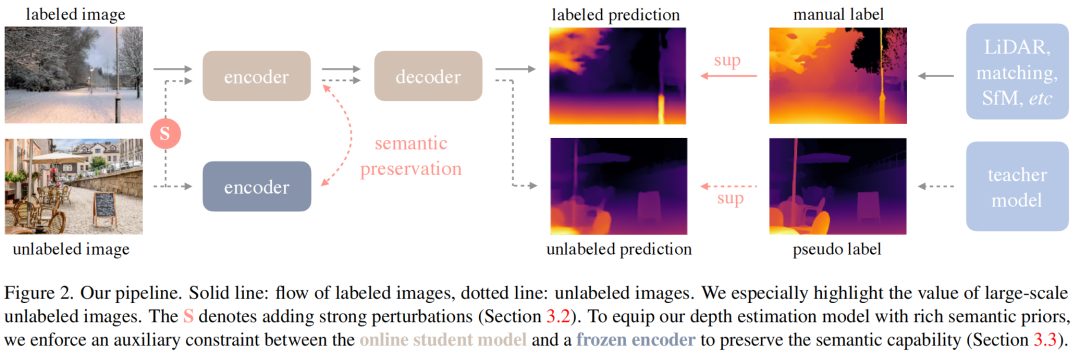
На рисунке выше показана архитектурная схема предлагаемого решения. В этой статье используются помеченные и немаркированные изображения для обучения лучшей монокулярной оценке глубины. гипотеза
Представляйте помеченные и немаркированные наборы данных соответственно.
- Во-первых, на основе набора данных
Изучите модель учителя Т;
- Затем используйте T как набор данных
Дайте псевдоярлыки;
- Наконец, студент МодельS обучается на основе двух данных.
Крупномасштабные наборы данных
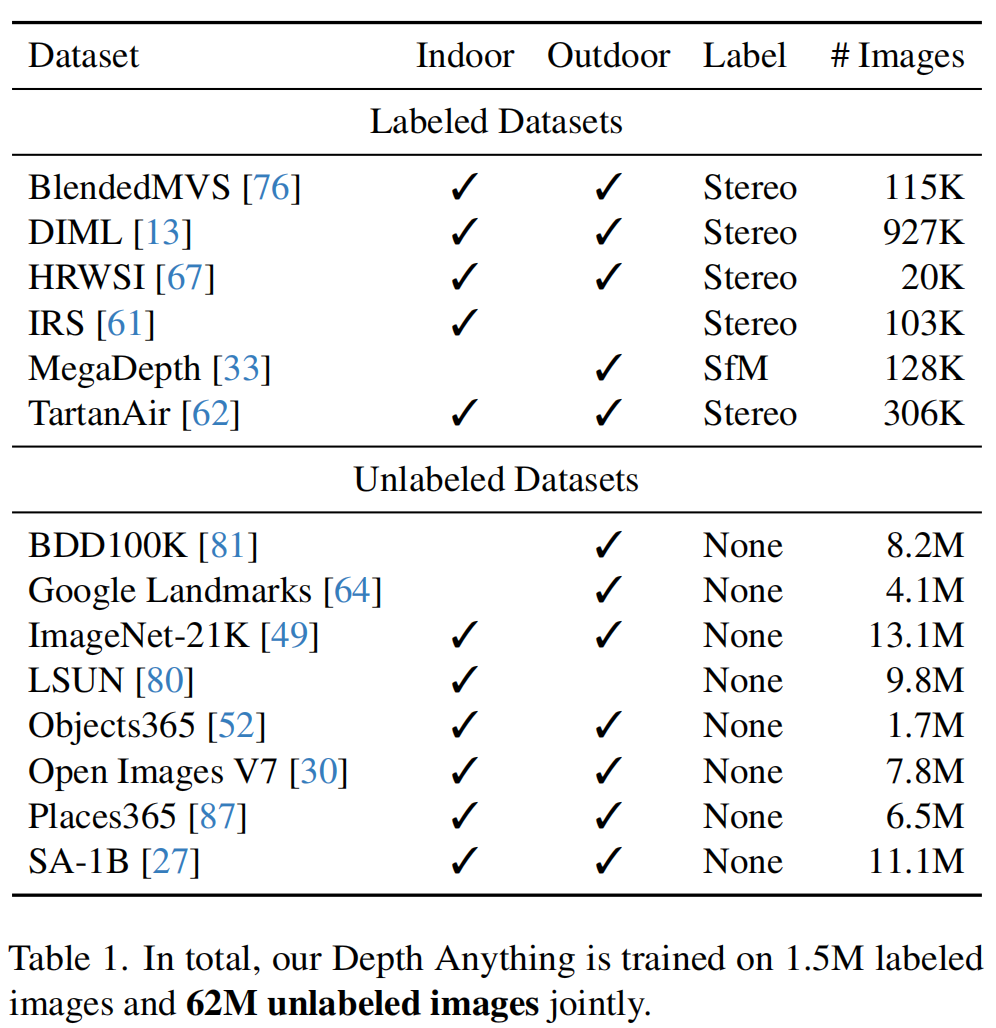
В приведенной выше таблице показаны помеченные и неразмеченные наборы данных, созданные в этой статье. По сравнению с MiDaS v3.1 эта схема использует меньшее количество помеченных наборов данных (6 против 12).
- NYUv2 и KITTI не используются для обеспечения нулевой оценки;
- Фильмы и WSVD больше недоступны;
- Некоторые данные низкого качества.,Такие как RedWeb;
Хотя менее практично, есть теги данных.,Но болееЛегкодоступных и разнообразных немаркированных данных достаточно, чтобы компенсировать охват данных и значительно улучшить способность к обобщению и надежность модели.。также,Для дальнейшего повышения квалификации учителя Модель,Автор использует предварительно обученные веса DINOv2 для инициализации.。
Раскройте потенциал немаркированных данных
Благодаря развитию Интернета мы можем легко создать разнообразный и крупномасштабный набор неразмеченных данных, а также использовать предварительно обученные модели MDE для создания плотных карт глубины для этих неразмеченных изображений. Это более удобно и эффективно, чем стереосогласование и реконструкция SfM.
Учитывая предварительно обученную модель учителя MDE T, мы можем преобразовать немаркированный набор данных
Преобразование в набор данных с псевдомаркировкой
:
На основе объединенных данных
,Мы можем обучать студентов Модели ~ но,к сожалению:При приведенной выше схеме самообучения нам сложно добиться повышения производительности.。
Предположение автора:Когда имеется достаточное количество размеченных данных, дополнительные знания, полученные от неразмеченных данных, весьма ограничены.。для этого,Авторы формулируют более сложные задачи оптимизации для модели студента, чтобы получить дополнительные визуальные знания из дополнительных немаркированных данных.。
во время тренировки,авторВнесение сильных возмущений в неразмеченные данные,Этот вид леченияПомогает моделям учащихся активно изучать дополнительные визуальные знания и изучать на их основе инвариантные представления.。Что касается конкретной реализации,В основном существуют два типа нарушений:
- Сильное искажение цвета, включая размытие цвета и размытие по Гауссу;
- Сильные пространственные искажения, такие как CutMix.
Хотя описанная выше операция относительно проста,но ониПомогает крупномасштабным немаркированным данным значительно улучшить базовый уровень маркированных изображений.。
семантическое восприятие
Хотя были проведены некоторые исследования по улучшению оценки глубины с помощью задач семантической сегментации, Модельпроизводительность,Но, к сожалению: после попытки,Комбинированное решение RAM+GroundDINO+HQ-SAM не может еще больше повысить производительность исходной модели MDE.。
автор Спекулировать:Декодирование изображений в дискретные пространства категорий приведет к потере слишком большого количества семантической информации. Ограниченная информация, содержащаяся в этих семантических масках, затрудняет дальнейшее повышение производительности глубоких моделей.(Особенно Модельуже Очень конкурентоспособный)。
поэтому,Автор исследует более надежную семантическую информацию из схемы DINOv2, чтобы помочь в решении задачи оценки глубины.,Прямо сейчасПеренесите сильные семантические возможности DINOv2 в предлагаемую глубокую модель за счет потери выравнивания вспомогательных функций.。Функция потерь определяется следующим образом:
Ключом к выравниванию функций является то, что семантический кодировщик DINOv2 имеет тенденцию генерировать схожие функции для разных частей одного и того же объекта. но,углубленная оценка,Разные части могут иметь разную глубину. поэтому,Нет необходимости требовать, чтобы глубокая модель генерировала точно те же функции, что и замороженный кодировщик.。
Чтобы решить эту проблему, автор устанавливает параметр избыточности для выравнивания признаков.
:когда
Когда сходство между,Этот пиксель не включен в вышеуказанную потерю。Это делаетЭто решение имеет как представление семантического восприятия DINOv2, так и возможность представления распознавания компонентов для глубокого контроля.。
План этой статьи
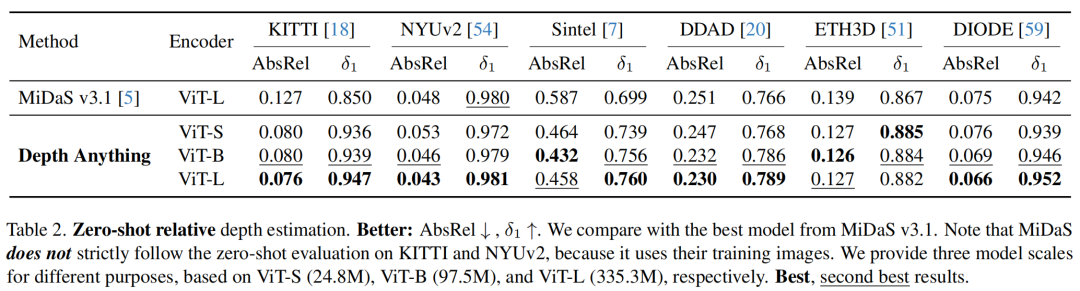
В приведенной выше таблице сравнивается производительность текущего решения SOTA MiDaS v3.1 для оценки относительной глубины и предлагаемого решения на различных наборах данных. Вы можете увидеть:
- По двум показателям,Предложенные решения лучше самых сильных MiDaSМодель;
- На съемках DDADданные,Индикатор AbsRel улучшен с 0,251 до 0,230.,
Показатель увеличился с 0,766 до 0,789;
- Модель ViT-B даже была значительно лучше, чем модель MiDaS, а меньшая по размеру ViT-S может даже превзойти MiDaS в нескольких невидимых эпизодах данных.

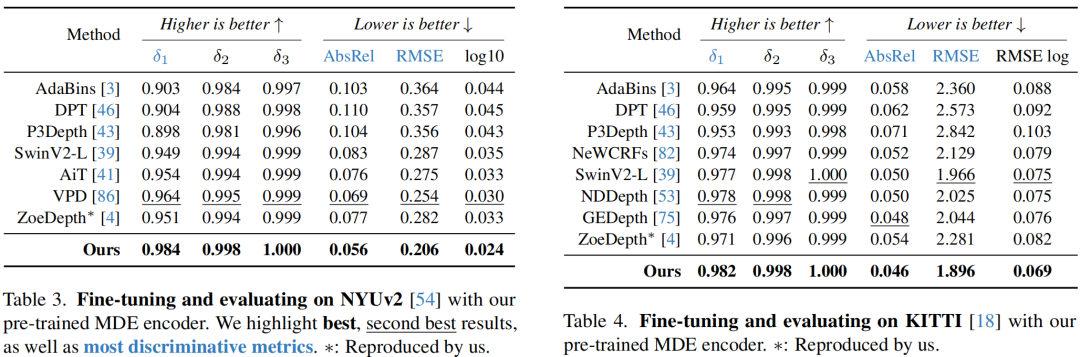
В двух приведенных выше таблицах сравниваются углы оценки глубины измерения внутри области и вне области. Очевидно, что предложенная схема обеспечивает очень хорошие характеристики точной настройки.
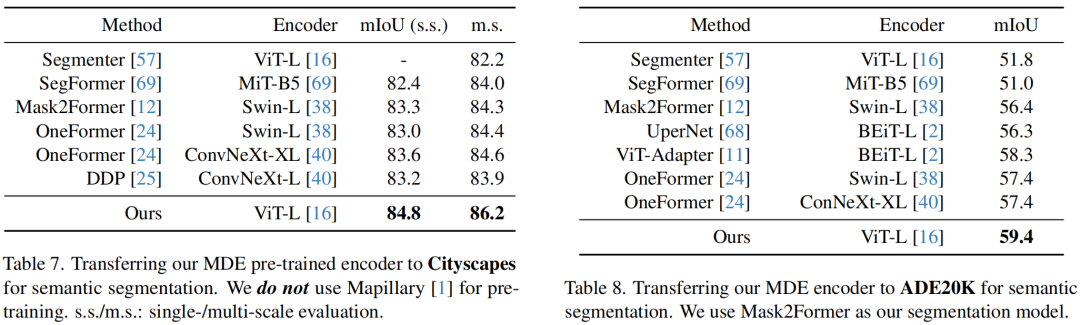
Наконец, автор также проверил способность предлагаемого кодировщика MDE выполнять задачу семантической сегментации, как показано в таблице выше.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
