Генерация тестовых примеров на основе Langchain для приложений с большими моделями
01 、Практический эффект от генерации прецедентов
В ходе формирования команды по гибкому подходу в этом году я внедрил автоматическое модульное тестирование в один клик с помощью Suite executor. Кроме экзекьютора Suite, какие еще экзекьюторы есть у Juint? Здесь начинается мое путешествие по исследованию Раннера!
В повседневной работе ключевыми задачами всегда являются постоянная оптимизация технологии тестирования и повышение эффективности тестирования. Мы изучаем практику использования больших моделей для создания тестовых примеров, надеясь использовать мощные возможности обработки естественного языка для автоматического создания более полных и высококачественных тестовых примеров.
В настоящее время компании широко используют JoyCoder. Мы можем скопировать соответствующие требования и информацию о проектной документации в JoyCoder и позволить ему генерировать тестовые примеры. Однако во время использования возникают следующие болевые точки:
1) По-прежнему требуются многоэтапные ручные операции: такие как копирование и вставка документов, написание слов-подсказок, копирование результатов, сохранение вариантов использования и т. д.
2) Длительное время отклика и нестабильные результаты: если содержание требований или проектного документа велико, слово подсказки слишком длинное или превышает лимит токена.
Поэтому я исследовал способы автоматического, быстрого и стабильного создания тест-кейсов на основе Langchain и существующей платформы компании. Эффект следующий:
Использование Джой Кодера | Самостоятельная разработка на основе Langchain | |
|---|---|---|
Время создания (для проектов — с большим содержанием документа) | ·Около 10–20 минут, требующих выполнения нескольких ручных операций (сначала будет подсказка: на основе предоставленного вами документа с требованиями ниже приведен пример тестового примера в формате Markdown. Поскольку содержимое документа относительно велико, я предоставлю общий тест. Шаблон варианта использования, вы можете дополнительно уточнить каждый шаг в соответствии с фактическими потребностями. Когда контента слишком много, появляется сообщение об ошибке: Достигнут максимальный предел токенов по умолчанию, НЕИЗВЕСТНАЯ ОШИБКА: время ожидания запроса истекло. Это может быть связано с. сервер является перегружено, вам нужно вручную попытаться ввести, сколько контента подходит | ·Автоматически генерируется примерно за 5 минут (после того, как все контрольные точки сгенерированы с помощью сводки, варианты использования, которые необходимо уточнить, генерируются с помощью векторного поиска) ·Если контента слишком много, его можно обрезать в соответствии с текстом токена, а затем предоставить к большой модели |
Время генерации (для обычных мелких нужд) | Разница невелика, 1-5 минут. | |
Точность | Нет большой разницы в зависимости от содержания слов-подсказок, но удобнее закреплять оптимизированные слова-подсказки при самостоятельном исследовании. | |
- Что такое Лангчейн? Это платформа с открытым исходным кодом для создания крупномасштабных приложений на основе языковых моделей (LLM). Магистр права — это крупномасштабная модель глубокого обучения, предварительно обученная на больших объемах данных, которая может генерировать ответы на запросы пользователей, такие как ответы на вопросы или создание изображений на основе текстовых подсказок. Лангчейн Предоставляет различные инструменты и абстракции для повышения настройки, точности и актуальности информации, генерируемой Моделью. Например, разработчики могут использовать LangChain Компонент для создания новых цепочек подсказок или настройки существующих шаблонов. Лангчейн Также включает компоненты, которые позволяют LLM Доступ к новым наборам данных можно получить без повторного обучения.
02 、Подробности
Прежде всего, MCube определит, нужно ли ему получать последний шаблон из сети, на основе состояния кэша шаблонов. Когда шаблон будет получен, он будет загружен. На этапе загрузки продукт будет преобразован в структуру. дерева представления. После завершения преобразования выражение будет проанализировано с помощью механизма анализа и получит правильное значение, проанализирует определяемое пользователем событие с помощью механизма анализа событий и завершит привязку события. и привязка событий, представление будет отображено.
1. Решение для генерации тестовых примеров на основе Langchain
преимущество | недостаток | Применимые сценарии | |
|---|---|---|---|
Вариант 1. Перенесите все требования к продукту и проектную документацию по НИОКР в большую модель и автоматически создайте сценарии использования. | Содержание вариантов использования относительно точное | Очень большие документы не поддерживаются и могут легко превысить лимит токенов (https://www.51cto.com/article/763949.html). | Требования и конструкция обычного масштаба |
Вариант 2. После обобщения всех требований к продукту и проектной документации по НИОКР предоставьте сводную информацию в большую модель и автоматически создайте варианты использования. | Не нужно беспокоиться о проблемах с токенами после подведения итогов | Содержание вариантов использования неточно, большинство из них представляют собой лишь общие моменты. | Чрезвычайно масштабные требования и конструкции |
Вариант 3: хранить все требования к продукту и проектную документацию НИОКР в векторной базе данных и автоматически генерировать определенную часть тестовых примеров путем поиска похожего контента. | Контент варианта использования более целенаправленный Не нужно беспокоиться о проблемах с токенами | Не всеобъемлющий вариант использования | Создавайте варианты использования только для определенной части требований и дизайна. |
Поскольку сценарии использования трех решений различны,Отличное качество также может дополнять друг друга.,Итак, теперь я реализовал все 3 метода,Доступен каждому, звоните по запросу.
2. Детали реализации
2.1 Общий процесс
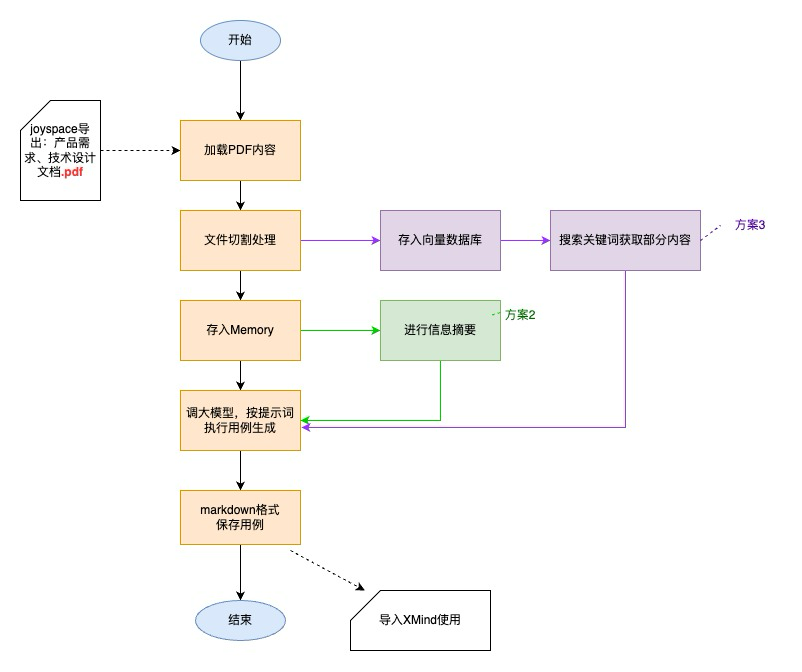
2.2 Технические детали
- Анализ содержимого PDF-файлов::LangchainПоддерживает анализ нескольких форматов файлов.(https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/),Такие как csv, json, html, pdf и т. д.,Есть много разных библиотек для pdf (https://zhuanlan.zhihu.com/p/352722932), которые можно использовать,На этот раз я выбрал PyMuPDF.,Он обладает преимуществами комплексных функций и высокой скорости обработки.
- Обработка резки файла:Чтобы предотвратить передачу слишком большого количества контента за один раз,Легко вызвать длительное время отклика или превысить лимит токена.,Использование разделителя текста Langchain (https://python.langchain.com/v0.1/docs/modules/data_connection/document_transformers/split_by_token/),Разделите файл на список небольших фрагментов текста.
- Использование памяти:большинство LLM Модель имеет диалоговый интерфейс.,Когда мы используем интерфейс для вызова больших возможностей Модели,Каждый звонок — это новый сеанс. Если мы хотим провести несколько раундов диалога с большой Моделью,вместо того, чтобы каждый раз повторять предыдущий контекст,Нам нужна Память, чтобы помнить содержание наших предыдущих разговоров. Память – это такой модуль,Чтобы помочь разработчикам быстро создать собственную «память» приложений. На этот раз я использовал ConversationBufferMemory и ConversationSummaryBufferMemory от Langchain (https://python.langchain.com/v0.1/docs/modules/memory/types/) для реализации,Непосредственно сохраняйте содержимое документа с требованиями и документа дизайна в памяти.,Можно сократить количество вопросов и ответов с помощью Da Model (уменьшить количество обращений к шлюзу Da Model),Улучшена общая скорость создания файлов сценариев использования. ConversationSummaryBufferMemory в основном используется для извлечения «сводной» информации.,Он может суммировать содержание документа с требованиями и проектного документа.,Затем передайте его большой модели.
- векторная база данных:Используйте то, что уже есть у компаниивекторная база данныетест Environment Vearch, сохраните файл. Что нужно знать при создании таблицы данных векторная база данных Поиск Модельи соответствующие ему параметры,В настоящее время поддерживаются шесть типов,IVFPQ,HNSW,GPU,IVFFLAT,BINARYIVF,ПЛОСКИЙ (Для получения подробных различий и параметров нажмите эту ссылку https://github.com/vearch/vearch/wiki/Vearch%E7%B4%A2%E5%BC%95%E4%BB%8B%E7%BB% 8D% E5%92%8C%E5%8F%82%E6%95%B0%E9%80%89%E6%8B%A9),В настоящее время я выбрал более простой индекс, основанный на количественном определении IVFFLAT.,Оптимизируйте позже, если объем данных слишком велик или данные графика необходимо обработать. Кроме того, Langchain также имеет очень удобный метод хранения векторов и запросов, который можно использовать (https://python.langchain.com/v0.2/docs/integrations/vectorstores/vearch/).
2.3 Структура кода и частичное отображение кода
Структура кода:
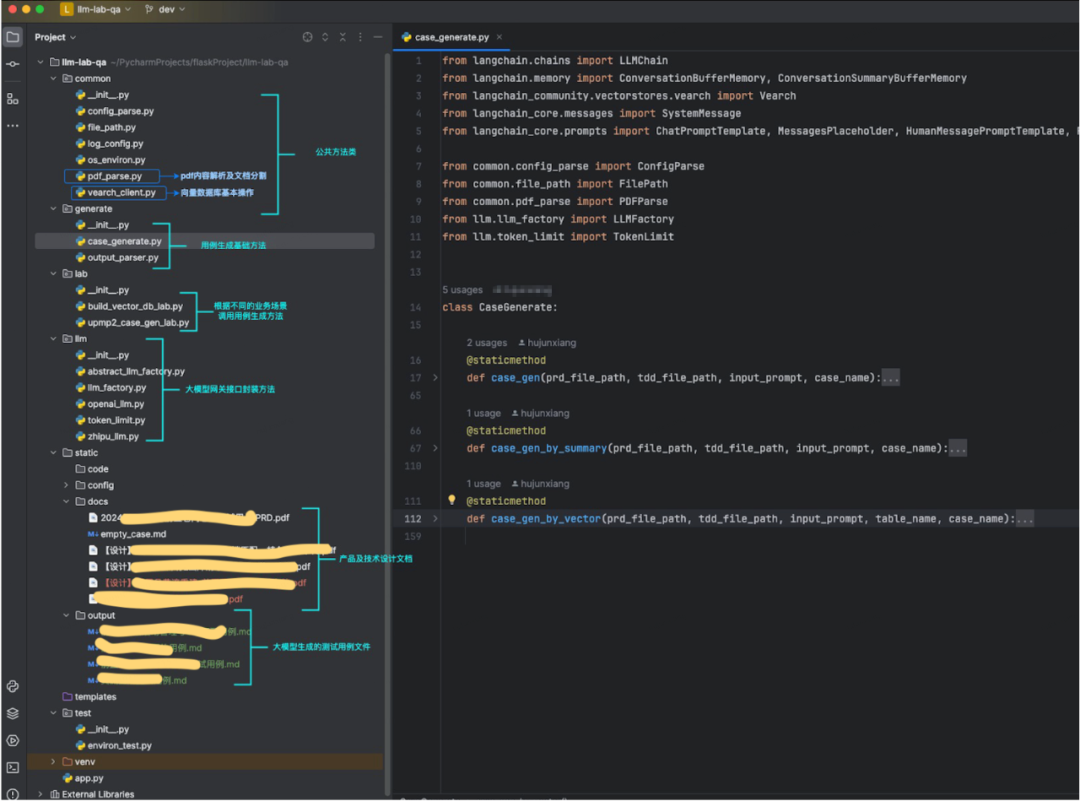
Пример кода:
def case_gen(prd_file_path, tdd_file_path, input_prompt, case_name):
"""
Как генерировать варианты использования
параметр:
prd_file_path - путь к документу PRD
tdd_file_path - Путь к документу технического проекта
case_name - Имя создаваемого тестового варианта использования.
"""
# Анализировать требования и документы, связанные с проектированием, Результатом является список документов.
prd_file = PDFParse(prd_file_path).load_pymupdf_split()
tdd_file = PDFParse(tdd_file_path).load_pymupdf_split()
empty_case = FilePath.read_file(FilePath.empty_case)
# Установите требования и документы, связанные с дизайном, в память в качестве информации о памяти llm.
prompt = ChatPromptTemplate.from_messages(
[
SystemMessage(
content="You are a chatbot having a conversation with a human."
), # The persistent system prompt
MessagesPlaceholder(
variable_name="chat_history"
), # Where the memory will be stored.
HumanMessagePromptTemplate.from_template(
"{human_input}"
), # Where the human input will injected
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
for prd in prd_file:
memory.save_context({"input": prd.page_content}, {"output": «Это документ с требованиями, который необходим для последующих вариантов использования выходного теста»})
for tdd in tdd_file:
memory.save_context({"input": tdd.page_content}, {"output": «Это документ технического дизайна, который необходим для последующих вариантов использования при выводе теста»})
# Включите «Модель», чтобы создать тестовый вариант использования.
llm = LLMFactory.get_openai_factory().get_chat_llm()
human_input = «Как эксперт по разработке программного обеспечения, пожалуйста, ознакомьтесь с приведенными выше требованиями к продукту и информацией о техническом дизайне». + input_prompt + ",Вывести тестовый вариант использования в формате уценки, шаблон варианта использования" + empty_case
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory,
)
output_raw = chain.invoke({'human_input': human_input})
# Сохраните содержимое выходного варианта использования в формате уценки.
file_path = FilePath.out_file + case_name + ".md"
with open(file_path, 'w') as file:
file.write(output_raw.get('text')) def case_gen_by_vector(prd_file_path, tdd_file_path, input_prompt, table_name, case_name):
"""
!!!Когда текст очень большой, не допускайте, чтобы токена было недостаточно, с помощью векторной база данных, найдите определенную часть контента и создайте частичные тестовые варианты использования с более точными деталями!!!
параметр:
prd_file_path - путь к документу PRD
tdd_file_path - Путь к документу технического проекта
table_name - векторная база Имя таблицы данных хранится по бизнесу. Обычно используется аббревиатура английского уникального идентификатора бизнеса.
case_name - Имя создаваемого тестового варианта использования.
"""
# Анализировать требования и документы, связанные с проектированием, Результатом является список документов.
prd_file = PDFParse(prd_file_path).load_pymupdf_split()
tdd_file = PDFParse(tdd_file_path).load_pymupdf_split()
empty_case = FilePath.read_file(FilePath.empty_case)
# Сохранить документ в векторную база данных
docs = prd_file + tdd_file
embedding_model = LLMFactory.get_openai_factory().get_embedding()
router_url = ConfigParse(FilePath.config_file_path).get_vearch_router_server()
vearch_cluster = Vearch.from_documents(
docs,
embedding_model,
path_or_url=router_url,
db_name="y_test_qa",
table_name=table_name,
flag=1,
)
# отвекторная база данные Поиск соответствующего контента
docs = vearch_cluster.similarity_search(query=input_prompt, k=1)
content = docs[0].page_content
# Создайте варианты использования для большой модели, используя информацию, связанную с векторным запросом.
prompt_template = «Как эксперт по разработке тестов программного обеспечения, пожалуйста, выведите вариант использования в формате уценки в соответствии с соответствующей информацией {input_prompt} в дизайне технологии требований к продукту: {content}. Шаблон варианта использования: {empty_case}»
prompt = PromptTemplate(
input_variables=["input_prompt", "content", "empty_case"],
template=prompt_template
)
llm = LLMFactory.get_openai_factory().get_chat_llm()
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True
)
output_raw = chain.invoke(
{'input_prompt': input_prompt, 'content': content, 'empty_case': empty_case})
# Сохраните содержимое выходного варианта использования в формате уценки.
file_path = FilePath.out_file + case_name + ".md"
with open(file_path, 'w') as file:
file.write(output_raw.get('text'))03 、Отображение эффектов
Прежде всего, MCube определит, нужно ли ему получать последний шаблон из сети, на основе состояния кэша шаблонов. Когда шаблон будет получен, он будет загружен. На этапе загрузки продукт будет преобразован в структуру. дерева представления. После завершения преобразования выражение будет проанализировано с помощью механизма анализа и получит правильное значение, проанализирует определяемое пользователем событие с помощью механизма анализа событий и завершит привязку события. и привязка событий, представление будет отображено.
Влияние фактического применения на требования/проекты
Вопрос о том, может ли генерация вариантов использования действительно помочь нам сэкономить время при разработке вариантов использования, поэтому я случайным образом провел эксперимент с небольшим требованием. Общее количество слов в документе PRD для этого требования составляет 2363, а общее количество. слов в проектном документе составляет 158 (из-за большого размера) Часть его представляет собой блок-схему), а эффективность реального процесса проектирования варианта использования может достигать 50%.
На этот раз преимущество использования большой Модели для автоматического создания вариантов использования:
Преимущества:
- Комплексное и быстрое логическое разделение сценариев использования.,Помогите тестировщику проанализировать и понять потребности и дизайн.
- Сократите время написания тестовых сценариев использования, ручная работа требует только подтверждения содержания и корректировки деталей.
- Содержание вариантов использования является более полным и насыщенным. Во время проверки варианта использования нужно добавлять меньше пунктов, и это может эффективно предотвратить пропущенные тесты.
- Например, тестировщик, отвечающий только за часть функций тестировщика.,Также возможен поиск по векторной базе данных.,Сосредоточьтесь на генерации некоторых функций
Недостатки:
- Неспособность хорошо понимать сложные блок-схемы. Когда текстовых описаний мало, создаваемый контент является предвзятым.
- Для опытного тестировщика,Идея автоматического создания вариантов использования может не соответствовать той идее, к которой вы привыкли.,Необходимость корректировки или адаптации самостоятельно
04 、Проблемы, которые необходимо решить, и планы дальнейших действий.
Прежде всего, MCube определит, нужно ли ему получать последний шаблон из сети, на основе состояния кэша шаблонов. Когда шаблон будет получен, он будет загружен. На этапе загрузки продукт будет преобразован в структуру. дерева представления. После завершения преобразования выражение будет проанализировано с помощью механизма анализа и получит правильное значение, проанализирует определяемое пользователем событие с помощью механизма анализа событий и завершит привязку события. и привязка событий, представление будет отображено.
1. Для блок-схем (форма изображения) в формате PDF реализовано извлечение и распознавание текста (методы, связанные с langchain pdf, поддерживают распознавание OCR). В будущем нам необходимо найти более подходящий способ решения проблемы анализа и извлечения содержимого изображения.
2. Создание вариантов использования — это лишь малая часть повышения эффективности тестирования. В будущем вам нужно попытаться применить большие модели к ежедневному процессу тестирования. Текущие идеи включают анализ кодов различий и журналов сервера для автоматического обнаружения дефектов и реализацию модели. -управляемое тестирование в сочетании с графами знаний. Автоматизированное тестирование и другие направления.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
