Генерация текста, интерпретация технологии Сора - модели генерации видео как симуляторы мира Модели генерации видео как симуляторы мира
OpenAI недавно запустила новую модель видео для генерации текста: Sora. Пока вы вводите несколько подсказок, описывающих видеоэкран, он может генерировать 60-секундное видео. Качество и точность этих видеороликов поражают, создавая одновременно реалистичные и творческие сцены, которые называются «видеогенеративные модели как симуляторы мира».
Что такое Сора? Насколько классен Сора? Какой технический принцип стоит за этим? Какова ценность приложения? В этой статье будут представлены эффекты, технологии, развитие и понимание Соры на основе технического отчета при его интерпретации.
Адрес предварительного просмотра Sora: https://openai.com/sora Адрес технического отчета: https://openai.com/research/video-generation-models-as-world-simulators
1. Аннотация
Мы исследуем масштабное обучение генеративных моделей на видеоданных. В частности, мы совместно обучаем модель условного распространения текста на видео и изображениях с переменной длительностью, разрешением и соотношением сторон. Мы используем архитектуру Transformer, которая работает с пространственно-временными фрагментами скрытых кодов видео и изображений. Sora способна создавать высококачественные одноминутные видеоролики. Наши результаты показывают, что масштабирование моделей генерации видео (Sora) является многообещающим направлением для создания универсальных симуляторов физического мира.
2. Интерпретация технологии генерации текста Sora для видео генерации текста
2.1. Краткий обзор созданных моделей.
Во многих предыдущих работах изучалось генеративное моделирование видеоданных с использованием различных методов, включая рекуррентную нейронную сеть (RNN), генеративно-состязательную сеть (GAN), авторегрессионный преобразователь (модель авторегрессии) и модель диффузии (модель диффузии), работы которых обычно сосредоточены на небольшом категория визуальных данных, более короткие видеоролики или видеоролики фиксированного размера.
1️⃣, Диффузная модель (Диффузия Model) Диффузионная модель — это тип генеративной модели, которая преобразует гауссовский шум в образцы известного распределения данных посредством итеративного процесса шумоподавления. Сгенерированные изображения обладают хорошим разнообразием и реалистичностью.
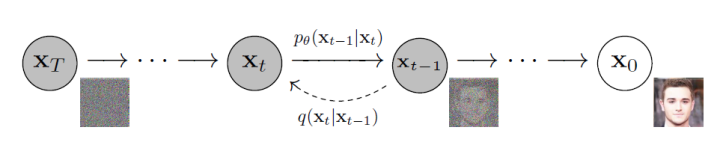
Процесс диффузии постепенно добавляет гауссов шум к исходному изображению.,представляет собой фиксированный процесс цепи Маркова,Окончательное изображение также постепенно преобразуется в гауссов шум.。иОбратный процесс шаг за шагом восстанавливает исходное изображение путем шумоподавления.,Это позволяет создавать изображения или видео.
2️⃣, Авторегрессионная модель (Авторегрессивная Model) Модель авторегрессии стала парадигмой для моделирования корреляции последовательностей за счет использования мощного механизма внимания. Вдохновленный успехом модели GPT в моделировании естественного языка, Image GPT (iGPT) использует Transformer, выполняющий авторегрессионную генерацию изображений. Правдоподобность сгенерированных изображений демонстрирует способность модели Transformer моделировать пространственные отношения между пикселями и атрибутами высокого уровня (текстурой, семантикой и масштабом). Трансформатор в целом разделен на две части: кодер и декодер, который использует многоголовочный механизм самообслуживания для кодирования и декодирования.
3️⃣, Модель генеративно-состязательной сети (Генеративная Adversarial Networks)
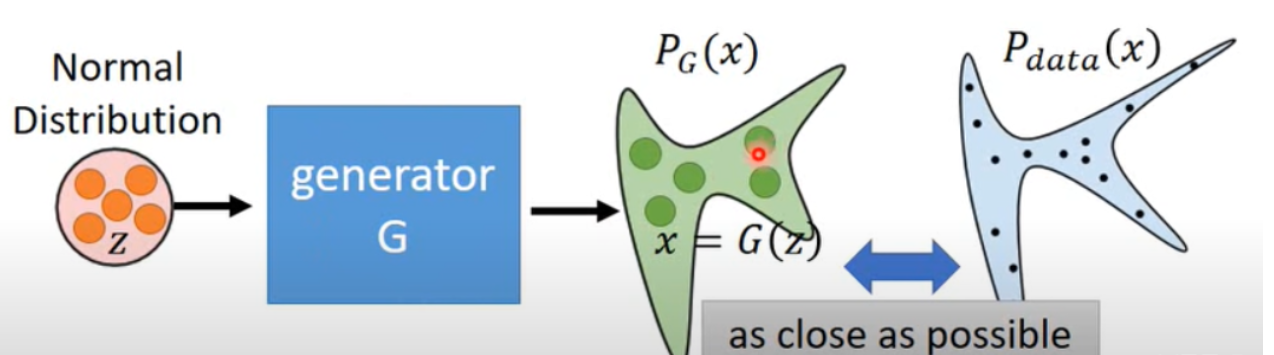
Генеративно-состязательные сети содержат генеративную и дискриминативную модели. Среди них генеративная модель отвечает за распределение выборочных данных, тогда как дискриминативная модель обычно представляет собой двоичный классификатор, который определяет, являются ли входные данные реальными данными или сгенерированными выборками. Весь тренировочный процесс — это постоянная игра и оптимизация между ними. Распределение сгенерированных генератором изображений постоянно близко к реальному распределению изображений для достижения цели обмана дискриминатора и улучшения дискриминантной способности дискриминатора. Дискриминатор различает реальные изображения и сгенерированные изображения, чтобы улучшить возможности генерации генератора.
Sora — это общая модель визуальных данных, которая может генерировать видео и изображения различной продолжительности, соотношений сторон и разрешений, вплоть до одной минуты видео высокой четкости.
2.2. Предварительная обработка видеоданных.
Сора использует подход к обработке видеоданных,Сначала он сжимает видео в скрытое пространство меньшей размерности, а затем разлагает это сжатое представление на серию пространственно-временных скрытых фрагментов. Эти фрагменты можно рассматривать как небольшие фрагменты видео, и каждый фрагмент захватывает небольшой пространственный период времени. структуру для лучшего понимания и обработки видеоданных, что делает ее пригодной для последующего обучения и генерации модели.
2.2.1 Превращение визуальных данных в патчи: Превращение визуальных данных в патчи.
Большие языковые модели приобретают общие возможности путем обучения на данных масштаба Интернета, отчасти благодаря используемым ими токенам, которые элегантно объединяют разрозненные формы текста, включая код, математику и различные естественные языки. В этой работе исследователи рассмотрели, как эту общую возможность можно применить к моделям, генерирующим визуальные данные.
В отличие от больших языковых моделей, использующих текстовые токены, модель Sora использует визуальные патчи для обработки визуальных данных. Подобно текстовым токенам, визуальные патчи также хорошо масштабируются и эффективны, что делает их особенно подходящими для обучения моделей, генерирующих множество типов видео и изображений.

2.2.2. Сеть сжатия видео: Сеть сжатия видео.
Сора обучает сеть уменьшению размерности визуальных данных. Сеть принимает исходное видео в качестве входных данных и выводит скрытое представление, сжатое в пространстве и времени. Сора обучается работе с этим сжатым скрытым пространством и генерирует в нем видео. Соответствующая модель декодера также обучается отображать сгенерированное скрытое представление обратно в пространство пикселей.
Проще говоря, Sora сжимает содержимое видео в более компактную и эффективную форму (т. е. уменьшает размерность). Таким образом, Сора может более эффективно обрабатывать видео, сохраняя при этом достаточно информации для восстановления исходного видео.
2.2.3. Скрытые патчи пространства-времени: Скрытые патчи пространства-времени.
Учитывая сжатое входное видео, Сора извлекает последовательность пространственно-временных фрагментов, которые служат токенами преобразователя. Эта схема работает и для изображений, поскольку изображения — это просто видеоролики с одним кадром. Представление на основе патчей позволяет Sora обучаться на видео и изображениях различного разрешения, продолжительности и соотношения сторон. Во время вывода размером сгенерированного видео можно управлять, располагая случайно инициализированные фрагменты в сетке соответствующего размера.
Проще говоря, Сора разбивает видео на небольшие фрагменты. Эти небольшие фрагменты содержат небольшую часть пространственной и временной информации в видео, которая представляет собой подробный «список» видеоконтента, помогая Соре нацелить его на объект. последующие шаги творчески обработайте каждую часть видео.
2.3. Генерация видео
2.3.1. Расширение Transformer для генерации видео: диффузионные трансформаторы. Масштабирующие преобразователи для генерации видео.
Sora — это генеративная модель, основанная на модели диффузии. Она работает, получая входные зашумленные участки (например, локальные области изображения) и некоторую информацию о состоянии (например, текстовые сигналы), а затем прогнозирует исходный «чистый» патч посредством обучения. , то есть патч с убранным шумом. Цель этой модели — сделать сгенерированные изображения более четкими и реалистичными.
Стоит отметить, что,Сора использует специальную архитектуру трансформатора — диффузионный трансформатор (DiT).,Структура ее модели следующая:
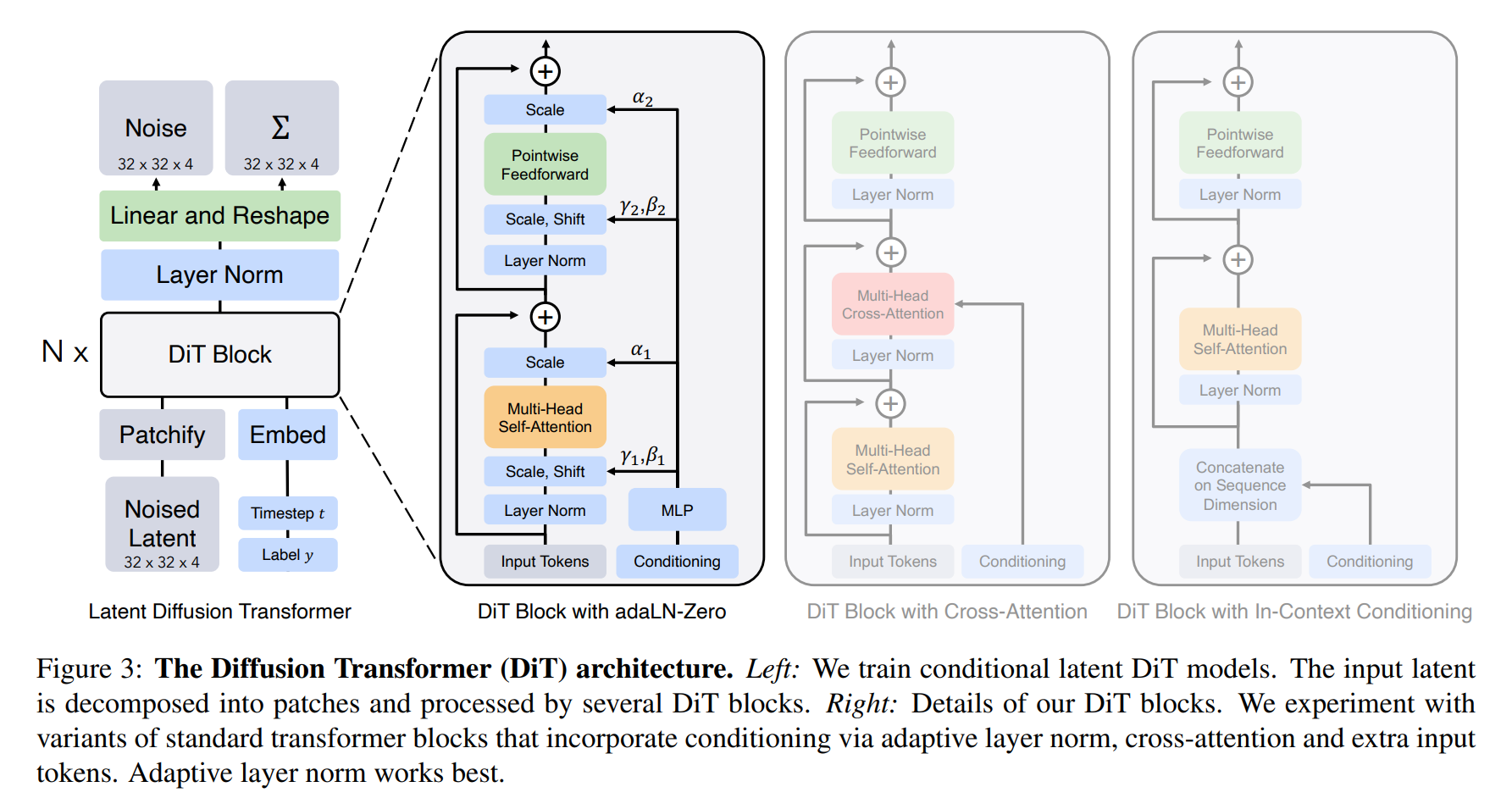
Диффузионные трансформаторы (DiTs) — это диффузионная модель, основанная на трансформаторах. Они следуют передовому опыту Vision Transformers (ViT) и предназначены для управления процессом распространения изображений.
Диффузионные трансформаторы применяют трансформаторы к диффузионным моделям для достижения более эффективной генерации изображений. В традиционных моделях диффузии для обработки входных данных с зашумленными изображениями обычно требуется дополнительная информация о состоянии. В частности, разработка DiT включает в себя следующие аспекты:
- Состояние верхнего и нижнего предложения:DiTsВоляtиcвекторные вложения как два дополнительных токена во входной последовательности,и обращаться с ним так же, как с тегами изображений. При этом сохраняются масштабирующие свойства стандартного Трансформера без изменения его архитектуры.
- смешанный базовый подход:DiTsИспользуйте готовые сверточные вариационные автоэнкодеры.(VAE)ина основе преобразователяDDPMдля генерации непространственных данных,Например, встраивание изображений CLIP.
- Вариант дизайна:DiTsЧетыре разныхTransformerВарианты,Они по-разному обрабатывают условный ввод,Небольшие, но существенные изменения в конструкции стандартного блока ВИТ.
Если вас интересуют подробности о диффузионных трансформаторах, вы можете оставить сообщение в комментариях. Если желающих много, вы можете опубликовать подробное объяснение архитектуры диффузионных трансформаторов в следующем выпуске.
При этом в ходе исследовательской работы Соры исследователи обнаружили, что диффузионные трансформаторы не только превосходны в генерации изображений, но и очень эффективны при видеомоделировании. Сравнивая образцы видео, созданные по мере увеличения объема обучающих вычислений, они обнаружили, что качество образцов значительно улучшалось по мере продвижения обучения. Это означает, что диффузионные трансформаторы могут эффективно обучаться и генерировать видеоконтент более высокого качества при обработке видеоданных, что имеет большое значение для области генерации видео.
2.4. Оптимизация эффектов.
OpenAI также использует некоторые методы оптимизации, чтобы модель имела переменную продолжительность, разрешение, соотношение сторон и другие характеристики, в том числе: гибкие методы выборки, улучшенную композицию и композицию изображения и т. д. Из-за отсутствия соответствующей информации она недоступна здесь для Развернуть, если вам интересно, вы также можете оставить сообщение в комментариях.

2.5. Понимание естественного языка: Понимание языка.
Что касается понимания естественного языка, OpenAI применяет технологию повторного субтитров, представленную в DALL·E 3. Методы повторного субтитров генерируют текстовые субтитры для всех видео в обучающем наборе путем обучения модели создания высокоописательных субтитров. Преимущество этого заключается в том, что обучение с использованием информативных заголовков видео может повысить точность текста, позволяя модели лучше понимать и генерировать видеоконтент, тем самым улучшая качество и точность создаваемых видео.
Как и в DALL·E 3, автор также использует GPT для преобразования краткой подсказки пользователя в более подробный заголовок, который затем отправляется в видеомодель. Это позволяет Sora создавать высококачественные видеоролики, точно соответствующие подсказкам пользователя.
Эти два метода обогащают подсказки для обучения преобразованию текста в видео, упрощая обучение.
3. Текущие ограничения Соры
В техническом отчете автор также упомянул, что у Sora все еще есть много ограничений. Например, он не может точно моделировать физические явления многих основных взаимодействий, таких как разбитие стекла. Другие взаимодействия, такие как употребление пищи, не всегда корректно меняют состояние объекта. На нашей домашней странице мы перечисляем другие распространенные режимы сбоя моделей, такие как некогерентность при длительных выборках или внезапное появление объектов.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
