Фотография и звук создают суперреалистичное видео за считанные секунды! НТУ и другие предложили новую систему для точного восстановления движений губ.

Монтажер: Беги так сонно
【Шин Джиген Введение】недавно,Исследователи НТУ и других учреждений разработали универсальную рамку,Просто используйте абзац Аудио, чтобы аватар на фотографии говорил на нескольких языках. И движения головы, и форма рта очень естественны.,Видел много хорошего
Фрагмент аудио + фотография, и человек на фотографии может начать говорить в одно мгновение.
Сгенерированная речевая анимация не только плавно выравнивает форму рта и звук, но также делает мимику и положение головы очень естественными и выразительными.
Поддерживаемые стили изображений также очень разнообразны. Помимо обычных фотографий, мультипликационных изображений, фотографий на документы и т. д., создаваемые эффекты очень естественны.
В сочетании с многоязычной поддержкой персонажи на фото мгновенно оживают и могут говорить на иностранных языках, открывая рот.
Это общая структура, предложенная исследователями из Нанкинского университета и других учреждений — VividTalk, которая требует только голоса и изображения для создания высококачественных разговорных видеороликов.

Адрес статьи: https://arxiv.org/abs/2312.01841.
Этот кадр представляет собой двухэтапный кадр, состоящий из аудио для генерации сеток и создания сеток для видео.
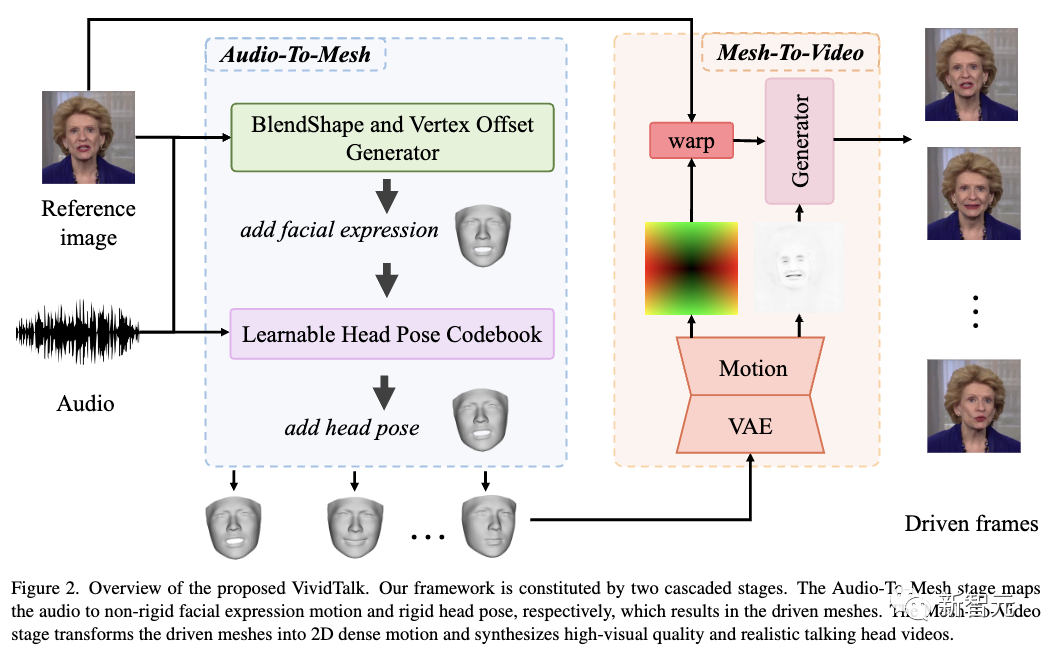
На первом этапе рассматривается сопоставление «один ко многим» между движением лица и распределением blendshape, используя blendshape и трехмерные вершины в качестве промежуточных представлений, где blendshape обеспечивает грубое движение, а смещения вершин описывают мелкозернистое движение губ.
Кроме того, также используется многоветвевая сеть Transformer, чтобы полностью использовать аудиоконтекст для моделирования отношений с промежуточными представлениями.
Чтобы более разумно изучить жесткие движения головы по звуку, исследователи преобразовали эту задачу в задачу запроса кода в дискретном конечном пространстве и создали обучаемую кодовую книгу позы головы с механизмами реконструкции и картирования.
После этого оба изученных движения применяются к опорному ориентиру, в результате чего создается движущаяся сетка.
На втором этапе проецируемые текстуры внутренних и внешних поверхностей (например, туловища) визуализируются на основе управляющей сетки и эталонных изображений для полной модели движения.
Затем разрабатывается новая модель движения с двумя ветвями для имитации плотного движения, которая отправляется в качестве входных данных в генератор для покадрового синтеза конечного видео.
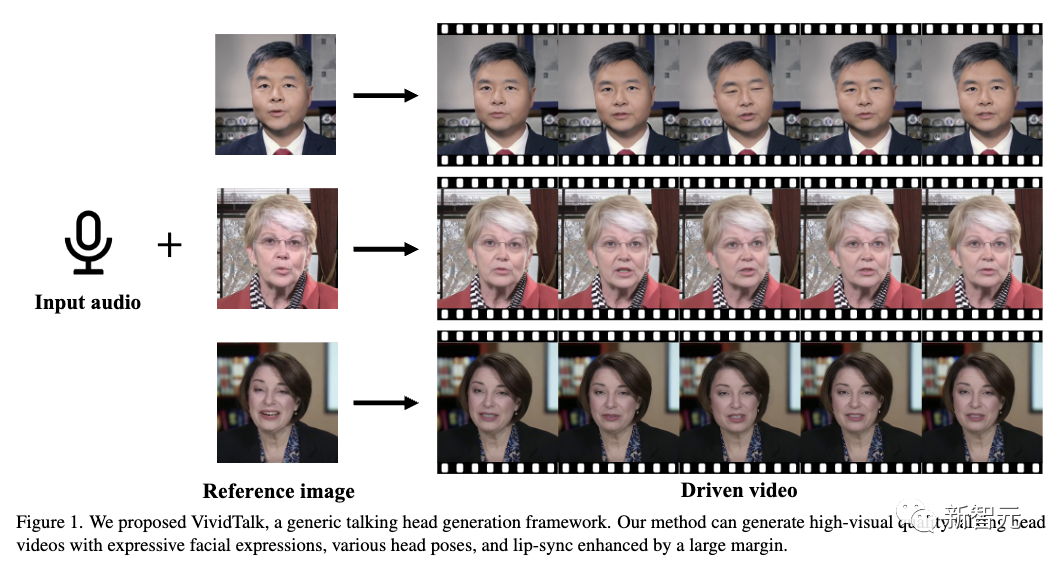
VividTalk может создавать синхронизированные по губам видео, говорящие головой, с выразительным выражением лица и естественными позами головы.
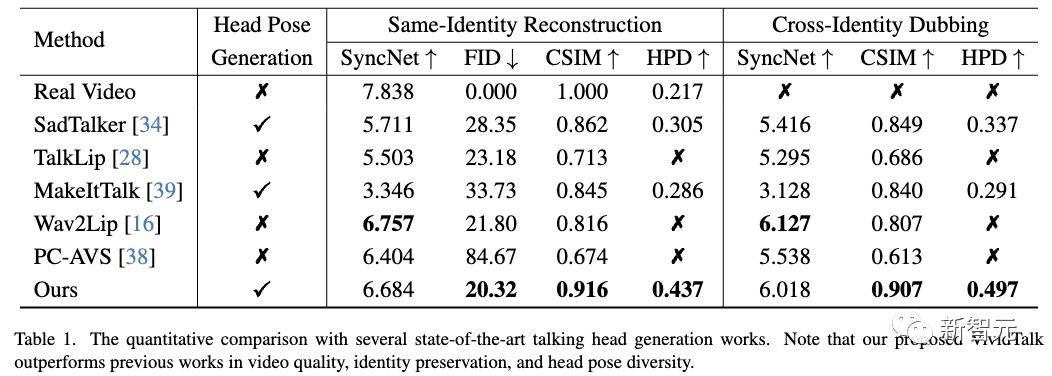
Как показано в таблице ниже, как визуальные результаты, так и количественный анализ демонстрируют превосходство нового метода с точки зрения качества генерации и обобщения модели.
Метод реализации фреймворка
Учитывая аудиопоследовательность и эталонное изображение лица в качестве входных данных, новый метод может генерировать видео «говорящей головы» с различными выражениями лица и естественными позами головы.
VividTalkрамка состоит из двух этапов: «Аудио для генерации сеток» и «Создание сеток для видео».
аудио для генерации сетки
Целью этого этапа является создание трехмерной сетки на основе входной аудиопоследовательности и эталонного изображения лица.
В частности, FaceVerse сначала используется для восстановления эталонного изображения лица.
Затем из звука изучаются нежесткие движения выражения лица и жесткие движения головы для управления реконструированной сеткой.
С этой целью исследователи предложили многоветвевой BlendShape и генератор смещения вершин, а также обучаемую кодовую книгу позы головы.
BlendShape и генератор смещения вершин
Изучение общей модели для создания точных движений рта и выразительной мимики в индивидуальном стиле представляет собой сложную задачу по двум причинам:
1) Первой проблемой является проблема корреляции звукового движения. Поскольку звуковые сигналы наиболее важны для движений рта, сложно смоделировать движения, не связанные с ртом, на основе звука.
2) Сопоставление звука с действиями выражения лица, естественно, имеет свойство «один ко многим», что означает, что один и тот же аудиовход может иметь более одного правильного шаблона действия, в результате чего изображение лица не имеет личных характеристик.
Чтобы решить проблему корреляции звукового движения, исследователи использовали blendshape и смещения вершин в качестве промежуточных представлений, где blendshape обеспечивает глобальное грубое движение выражения лица, а смещения вершин, связанные с губами, обеспечивают локальное мелкозернистое движение губ.
Для решения проблемы отсутствия черт лица исследователи предлагают многоветвевой генератор на основе трансформатора, который моделирует движение каждой части индивидуально и привносит индивидуальный стиль для сохранения личных характеристик.
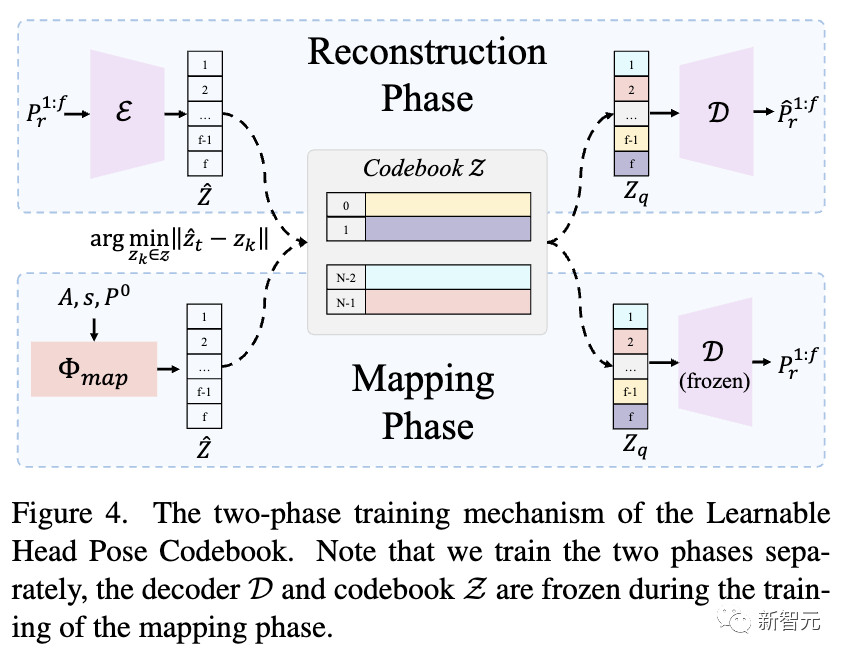
Обучаемая кодовая книга позы головы
Положение головы — еще один важный фактор, влияющий на реалистичность видео с говорящей головой. Однако изучить его непосредственно по аудио непросто, поскольку связь между ними слабая, что приводит к необоснованным и прерывистым результатам.
Вдохновленное предыдущими исследованиями, использование дискретной кодовой книги в качестве априорной обеспечивает высокоточную генерацию даже при ухудшении качества входных данных.
Исследователи предложили преобразовать эту проблему в задачу запроса кода в дискретном и ограниченном пространстве позы головы и тщательно разработали двухэтапный механизм обучения. На первом этапе создается богатая кодовая книга позы головы, а на втором этапе сопоставляется входной звук. Кодовая книга генерирует окончательный результат, как показано на рисунке ниже.
Создание сетки для видео
Как показано на рисунке ниже, исследователи предложили двойную ветвь движения для моделирования плотного 2D-движения, которая будет использоваться в качестве входных данных для генератора для синтеза конечного видео.
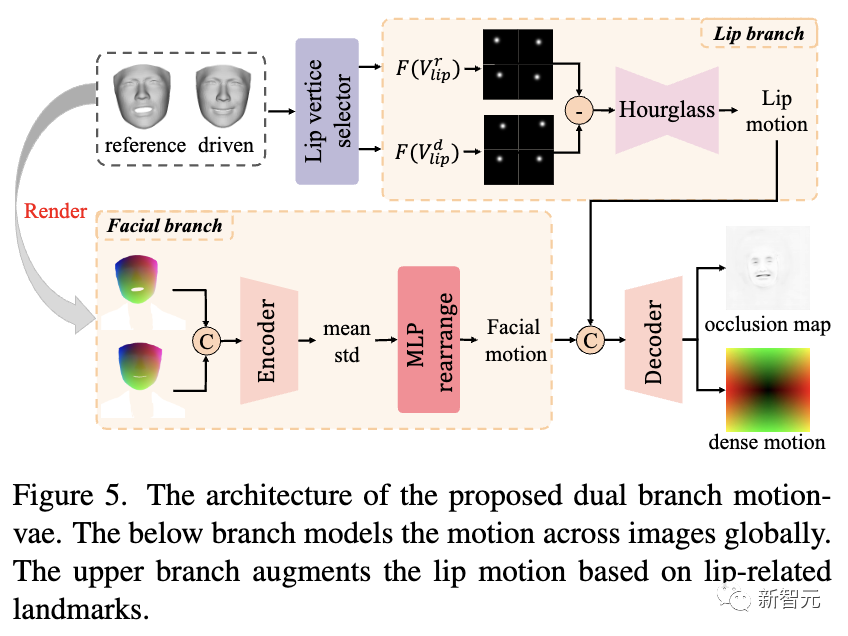
Непосредственное преобразование движения трехмерной области в движение двухмерной области сложно и неэффективно, поскольку для лучшего моделирования сети необходимо найти соответствие между двумя движениями области.
Чтобы улучшить производительность сети и повысить ее производительность, исследователи выполнили это преобразование в 2D-области с помощью проецируемых текстурных представлений.
Как показано на рисунке выше, в ветви лица опорная текстура проекции PT и управляемая текстура проекции P Tare соединяются и подаются в кодер, а затем вводятся в MLP для вывода двухмерной карты движения лица.
Чтобы еще больше улучшить движение губ и более точно смоделировать его, исследователи также выбрали ориентиры, связанные с губами, и преобразовали их в карты Гаусса, более компактное и эффективное представление.
Затем сеть песочных часов принимает вычтенную карту Гаусса в качестве входных данных и выводит двумерное движение губ, которое объединяется с движением лица и декодируется в плотные карты движения и окклюзии.
Наконец, исследователи деформировали эталонное изображение на основе ранее предсказанной карты плотного движения, чтобы получить деформированное изображение, которое будет использоваться в качестве входных данных для генератора вместе с картой окклюзии для покадрового синтеза конечного видео.
Результаты эксперимента
Набор данных
HDTF — аудиовизуальный набор высокого разрешения. данных, более 16 часов видео, содержащих 346 тем. VoxCeleb — еще один более крупный набор данных, включающих более 100 000 видео и 1000 личностей.
Исследователи сначала отфильтровали два набора данных, чтобы удалить недействительные данные, такие как данные аудио и видео, не синхронизированные.
Затем область лица на видео обрезается и изменяется ее размер до 256×256.
Наконец, обработанные видео делятся на 80%, 10% и 10%, которые будут использоваться для обучения, проверки и тестирования.
Детали реализации
В экспериментах исследователи использовали FaceVerse, современный метод реконструкции одного изображения, для восстановления видео и получения достоверных смешанных форм и сеток для наблюдения.
В процессе обучения этапы Audio-To-Mesh и Mesh-To-Video обучаются отдельно.
В частности, BlendShape от Аудио до стадии сетки и обучаемая кодовая книга позы головы также обучаются отдельно.
Во время вывода модель исследователей может работать сквозным образом, каскадируя два этапа, описанных выше.
Для оптимизации используется оптимизатор Адама со скоростью обучения 1×10 и 1×10 для двух этапов соответственно. Общее время обучения на 8 графических процессорах NVIDIA V100 составляет 2 дня.
Сравнение с СОТА

Как видно, предложенный исследователями метод позволяет создавать высококачественные видеоролики с точной синхронизацией губ и выразительными движениями лица.
Для сравнения:
- SadTalker не может генерировать точные и детальные движения губ.,И видео более низкого качества.
- TalkLip дает размытые результаты и меняет стиль тона кожи на слегка более желтый, в определенной степени теряя идентификационную информацию.
- MakeItTalk не может создавать точные формы рта, особенно в настройках перекрестного дубляжа.
- Wav2Lip имеет тенденцию синтезировать размытые области рта и выводить изображения со статической позой головы и движениями глаз при вводе одного эталонного изображения.
- PC-AVS требует наличия драйвера видео в качестве входных данных,и пытается сохранить идентичность.
Количественное сравнение
Как показано в таблице ниже, новый метод работает лучше с точки зрения качества изображения и сохранения идентичности, о чем свидетельствуют более низкие показатели FID и более высокие показатели CSIM.
Благодаря новому механизму обучаемой кодовой книги позы головы, создаваемые новым методом, также становятся более разнообразными и естественными.
Хотя новый метод имеет более низкую оценку SyncNet, чем Wav2Lip, его можно реализовать за счет использования эталонного изображения одного аудио вместо видео и создания кадров более высокого качества.
Ссылки:
https://humanaigc.github.io/vivid-talk/



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
