Flume собирает скрытые данные о поведении на стороне приложения в HDFS
Собрать фон
Эта статья взята из хранилища данных электронной коммерции Shang Silicon Valley 6.0.
Когда мы собираем данные журнала сервера журналов, мы сначала передаем данные в Kafka через Flumel (чтобы облегчить последующую обработку в реальном времени), а затем собираем данные в HDFS через Flume. Затем соберите данные из Kafka в HDFS. В это время возникнет проблема дрейфа нулевой точки. (Когда данные около 24:00 в первый день поступают из Kafka и собираются Flume, временная метка времени в заголовке [текущее записанное время не является рабочим временем] станет временем следующего дня из-за задержки) и мы находятся в HDFSSink. Путь времени — это временная метка из заголовка, поэтому мы создаем перехватчик для обработки этой ситуации. Таким образом, данные точно собираются в каталог дат в HDFS.
Коллектор лотка 1
file_to_kafka.conf
Этот сборщик собирает скрытые данные о поведении сервера журналов в Kafka.
Поскольку KafkaChannel может собирать данные непосредственно в Kafka, мы больше не используем приемник для обработки.
vim file_to_kafka.conf
#Определить компонент
a1.sources = r1
a1.channels = c1
#Настроить источник
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
#Настроить канал
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#собрать
a1.sources.r1.channels = c1Скрипт запуска коллектора 1
# Создать скрипт
vim f1.sh
#!/bin/bash
echo " --------запускать hadoop102 Собрать лоток -------"
nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &
# Добавить разрешения
chmod 777 ./f1.shКоллектор лотка 2
kafka_to_hdfs_log.conf
Этот сборщик собирает данные Kafka в HDFS. Мы добавляем перехватчик, чтобы обеспечить точность данных.
#Определить компонент
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#Настроить источник1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
# Перехватчик
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.example.TimestampInterceptor$Builder
#Настроить канал
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
#Настроить раковину
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#Управление типом выходного файла
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#собрать
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1Скрипт запуска Collector 2
# Создать скрипт
vim f2.sh
#!/bin/bash
echo " --------запускать hadoop102 Поток данных журнала -------"
nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &
# Добавить разрешения
chmod 777 ./f2.shПерехватчик лотка
Формат данных журнала следующий:
{
"common": {
"ar": "12",
"ba": "realme",
"ch": "wandoujia",
"is_new": "1",
"md": "realme Neo2",
"mid": "mid_411",
"os": "Android 13.0",
"sid": "4f34596c-ca8f-434c-a8d5-356b944eb0d6",
"vc": "v2.1.134"
},
"start": {
"entry": "icon",
"loading_time": 12974,
"open_ad_id": 16,
"open_ad_ms": 5415,
"open_ad_skip_ms": 0
},
"ts": 1654620592548
}pom-файл
Если maven не может быть загружен, вы можете принудительно обновить зависимости в кеше в корневом каталоге проекта: mvn clean install -U
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.10.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>TimestampInterceptor
Принцип коллектора:
Из-за проблемы дрейфа нулевой точки мы настроили перехватчик для перехвата каждого события. На данный момент инкапсулированные данные поступают из Kafka, а данные Kafka поступают с сервера журналов. Нам нужны данные ts тела. , который используется для настройки пути коллектора Flume. (/%Y-%m-%d) Итак, нам нужно получить эти данные, обработать их, а затем загрузить в заголовок.
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class TimestampInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1. Получаем данные заголовка и тела.
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
try {
//2. Преобразуем тип данных body в тип jsonObject (удобно получать данные)
JSONObject jsonObject = JSONObject.parseObject(log);
//3. Заменить поле времени временной метки в заголовке на временную метку, сгенерированную журналом (решаем проблему дрейфа данных)
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()) {
Event event = iterator.next();
if (intercept(event) == null) {
iterator.remove();
}
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}Запустить канал сбора
# Запуск коллектора лотка
f1.sh
f2.sh
# Запустить сервер журналов
java -jar /opt/module/applog/gmall-remake-mock-2023-05-15-3.jarПроверить результаты
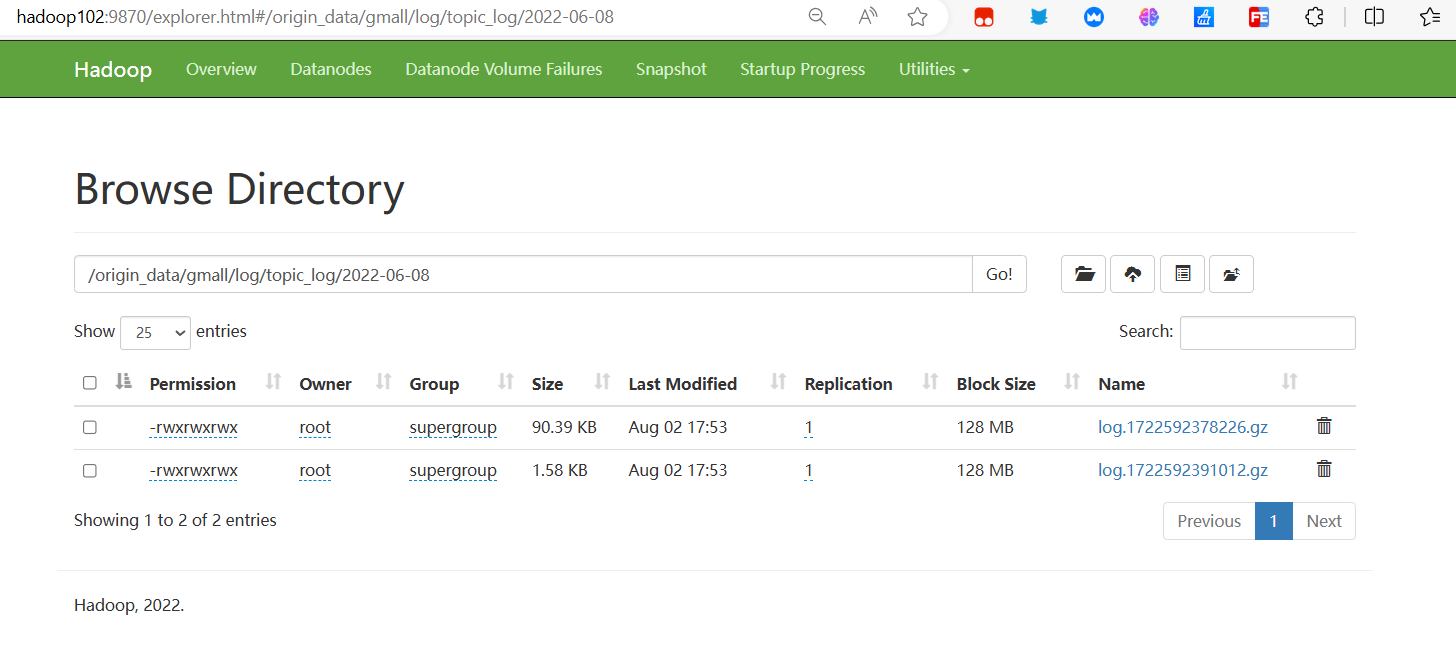



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
