Flink выполняет анализ исходного кода написания Hudi
1.Предисловие
Flink является лидером в области потоковых вычислений, а Hudi всегда был очень популярен в области озер данных. Комбинация этих двух решений также является выбором многих компаний. Если вы хотите получить более глубокое представление о применении или настройке производительности технологии Flink + Hudi, то понимание принципов исходного кода окажет нам большую помощь. Эта статья в основном посвящена анализу процесса написания Flink + Hudi. Hudi, чтобы понять различные основные концепции Hudi, такие как копирование при записи (COW), слияние при чтении (MOR), файл Макеты (разметка файлов), Timeline (Временная шкала) и т. д. В этой статье предполагается, что каждый имеет некоторое представление об этих понятиях. Эти понятия будут задействованы в анализе кода в статье и не будут подробно объясняться.
2. Демонстрация чтения исходного кода
Самое важное в чтении исходного кода — это то, что вы можете следить за чтением с помощью точек останова. Как правило, самый простой демонстрационный код может улучшить эффект чтения исходного кода. Вы можете наблюдать полный процесс записи Flink в Hudi с помощью следующего демонстрационного кода.
Map<String, String> options = new HashMap<>();
options.put(FlinkOptions.PATH.key(), basePath);
options.put(FlinkOptions.TABLE_TYPE.key(), HoodieTableType.MERGE_ON_READ.name());
options.put(FlinkOptions.PRECOMBINE_FIELD.key(), "ts");
// Чтобы облегчить наблюдение за процессом исходного кода, размер кэша Bucket установлен равным 0,5 КБ.
options.put(FlinkOptions.WRITE_BATCH_SIZE.key(), "0.0005");
// Чтобы облегчить наблюдение за процессом исходного кода, параллелизм каждой задачи во всем процессе установлен равным 1.
options.put(FlinkOptions.INDEX_BOOTSTRAP_TASKS.key(), "1");
options.put(FlinkOptions.BUCKET_ASSIGN_TASKS.key(), "1");
options.put(FlinkOptions.WRITE_TASKS.key(), "1");
options.put(FlinkOptions.COMPACTION_TASKS.key(), "1");
// Чтобы облегчить наблюдение за процессом исходного кода, механизм компактного запуска устанавливается на delta_commit каждые 2 раза.
options.put(FlinkOptions.COMPACTION_TRIGGER_STRATEGY.key(), FlinkOptions.NUM_COMMITS);
options.put(FlinkOptions.COMPACTION_DELTA_COMMITS.key(), "2");
HoodiePipeline.Builder builder = HoodiePipeline.builder(targetTable)
.column("uuid VARCHAR(20)")
.column("name VARCHAR(10)")
.column("age INT")
.column("ts INT")
.column("`partition` VARCHAR(20)")
.pk("uuid")
.partition("partition")
.options(options);
builder.sink(dataStream, false);
env.execute("HudiWriteDemoWithFlink");3. Полное введение в процесс написания Flink.
Интерфейсом Flink для записи во внешнее хранилище является DynamicTableSink. Hudi реализует интерфейс записи Flink через HoodieTableSink. Основная логика записи находится в getSinkRuntimeProvider. Из-за нехватки места в этой статье для объяснения будет выбрана только одна ссылка в каждой ссылке.
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
return (DataStreamSinkProviderAdapter) dataStream -> {
long ckpTimeout = dataStream.getExecutionEnvironment()
.getCheckpointConfig().getCheckpointTimeout();
// Настройте момент Hudi Тайм-аут фиксации — это тайм-аут контрольной точки Flink, поскольку Flink выполняет мгновенный процесс фиксации после завершения контрольной точки.
conf.setLong(FlinkOptions.WRITE_COMMIT_ACK_TIMEOUT, ckpTimeout);
OptionsInference.setupSinkTasks(conf, dataStream.getExecutionConfig().getParallelism());
RowType rowType = (RowType) schema.toSinkRowDataType().notNull().getLogicalType();
// Эта ветвь будет достигнута, когда тип операции записи будет Bulk_insert. В этой статье в основном представлен процесс записи потока Flink. Тип операции записи, который мы используем, upsert.
final String writeOperation = this.conf.get(FlinkOptions.OPERATION);
if (WriteOperationType.fromValue(writeOperation) == WriteOperationType.BULK_INSERT) {
return Pipelines.bulkInsert(conf, rowType, dataStream);
}
// Когда тип операции — вставка, для таблиц типа mor данные записываются в методе добавления. Для таблиц типа коровы метод добавления можно использовать только при использовании write.insert.cluster=flase. При записи. =true, небольшие файлы будут объединены при записи данных. Путь к этой ветке не описан в этот раз.
if (OptionsResolver.isAppendMode(conf)) {
DataStream<Object> pipeline = Pipelines.append(conf, rowType, dataStream, context.isBounded());
if (OptionsResolver.needsAsyncClustering(conf)) {
return Pipelines.cluster(conf, rowType, pipeline);
} else {
return Pipelines.dummySink(pipeline);
}
}
DataStream<Object> pipeline;
// Здесь начинается основная отправная точка для анализа этой статьи. Вот источник данных для создания HoodieRecord. Процесс DataStream по умолчанию загружает индекс ключа и идентификатора файла. Flink не загружает индекс файла во время процесса записи. По умолчанию пара ключа и идентификатора файла в файле считывается и отправляется в нисходящий поток с помощью. Механизм состояния Флинка для сохранения
final DataStream<HoodieRecord> hoodieRecordDataStream =
Pipelines.bootstrap(conf, rowType, dataStream, context.isBounded(), overwrite);
// Flink сгенерирует HoodieRecord Сохранение DataStream в процессе сохранения включает в себя процесс мгновенной фиксации. Когда весь параллелизм задачи записи завершает операцию сохранения, результаты записи будут сообщены Оператору-координатору. Наконец, когда контрольная точка будет завершена, он уведомит об этом. Оператор-координатор для выполнения текущего процесса фиксации и запуска запрошенного процесса следующего текущего этапа.
pipeline = Pipelines.hoodieStreamWrite(conf, hoodieRecordDataStream);
// Если тип таблицы — mor и установлено асинхронное сжатие, в группу обеспечения доступности баз данных Flink будет добавлена задача для управления процессом сжатия.
if (OptionsResolver.needsAsyncCompaction(conf)) {
// use synchronous compaction for bounded source.
if (context.isBounded()) {
conf.setBoolean(FlinkOptions.COMPACTION_ASYNC_ENABLED, false);
}
return Pipelines.compact(conf, pipeline);
} else {
return Pipelines.clean(conf, pipeline);
}
};Полный основной процесс можно представить на рисунке ниже, а конкретные шаги по каждой ссылке будут объяснены в следующих ссылках.
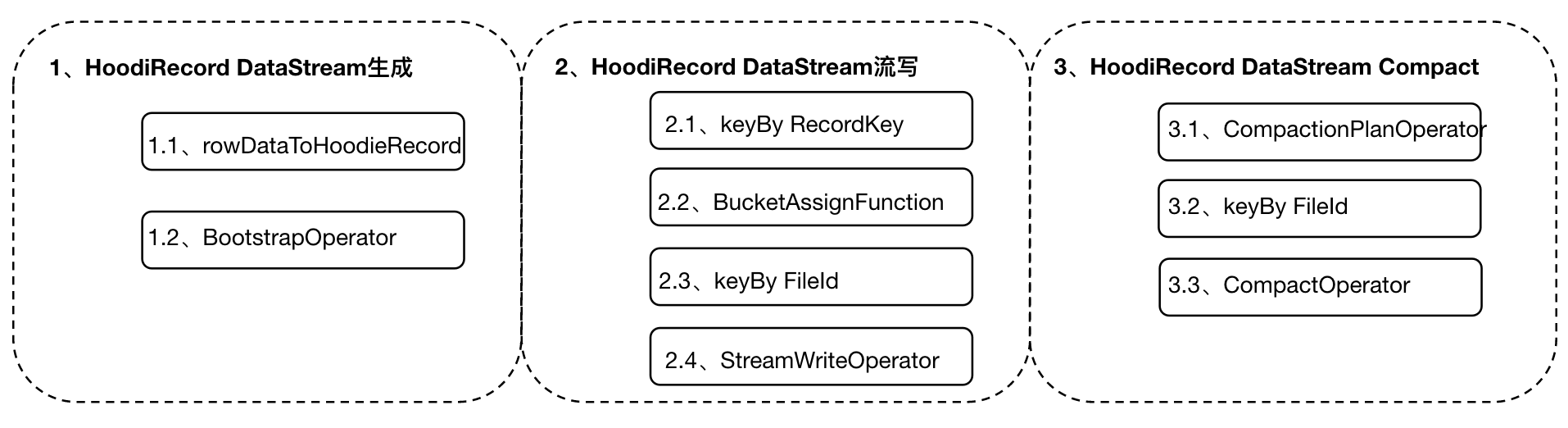
4. Подробное объяснение процесса создания потока данных HoodieRecord.
Подробный код процесса генерации потока данных HoodieRecord приведен ниже.
public static DataStream<HoodieRecord> bootstrap(
Configuration conf,
RowType rowType,
DataStream<RowData> dataStream,
boolean bounded,
boolean overwrite) {
// Обновлять ли индекс старого пути раздела
final boolean globalIndex = conf.getBoolean(FlinkOptions.INDEX_GLOBAL_ENABLED);
if (overwrite || OptionsResolver.isBucketIndexType(conf)) {
// Если перезапись или тип индекса — сегмент, этот шаг представляет собой просто операцию преобразования потока данных.
return rowDataToHoodieRecord(conf, rowType, dataStream);
} else if (bounded && !globalIndex && OptionsResolver.isPartitionedTable(conf)) {
// Когда пакетные задачи выполнены и нескольким разделам разрешено иметь один и тот же ключ и таблицу разделов,
return boundedBootstrap(conf, rowType, dataStream);
} else {
// Для других типов flink использует функцию состояния flink для загрузки индексной информации старого раздела. Эта часть является основным анализом этой статьи. Подробный анализ см. в части 4.2.
return streamBootstrap(conf, rowType, dataStream, bounded);
}
}4.1 rowDataToHoodieRecord
Основная задача, реализованная в операторе RowDataToHoodieFunction, заключается в преобразовании RowData в HoodieAvroRecord. Основные члены HoodieAvroRecord следующие:
//В основном включает в себя ключ записи данных и информацию о разделе раздела, которая извлекается из исходных данных на основе информации о создании таблицы.
HoodieKey key;
//Исходные данные, включая все поля ввода
T data;
//Тип операции с данными в Hudi описан в журнале изменений
HoodieOperation operation;
//Данные соответствуют файлу в Hudi. Значение на этом шаге равно нулю и будет заполнено после шага 2.2.
HoodieRecordLocation currentLocation; 4.2 BootstrapOperator
Основной код выглядит следующим образом:
private static DataStream<HoodieRecord> streamBootstrap(
Configuration conf,
RowType rowType,
DataStream<RowData> dataStream,
boolean bounded) {
// Преобразование DataStream в класс инкапсуляции HoodieRecord
DataStream<HoodieRecord> dataStream1 = rowDataToHoodieRecord(conf, rowType, dataStream);
if (conf.getBoolean(FlinkOptions.INDEX_BOOTSTRAP_ENABLED) || bounded) {
// При установке статуса начальной загрузки или обработке пакетных задач индексная информация исторических данных будет загружена в статус нижестоящих операторов флинка.
dataStream1 = dataStream1
.transform(
"index_bootstrap",
TypeInformation.of(HoodieRecord.class),
new BootstrapOperator<>(conf))
.setParallelism(conf.getOptional(FlinkOptions.INDEX_BOOTSTRAP_TASKS).orElse(dataStream1.getParallelism()))
.uid(opUID("index_bootstrap", conf));
}
return dataStream1;
}Функция BootstrapOperator заключается в загрузке сохраненного HoodieKey и соответствующей файловой информации FileSlice в таблице Hudi в состояние нисходящего оператора (BucketAssignFunction) для использования новым сегментом поиска данных. Основная логика реализации заключается в методе InitializeState. Сначала извлекаются все пути разделов в каталоге таблицы Hudi, а затем выполняется обычное сопоставление на основе путей разделов. Если они совпадают, загружаются все HoodieKeys в разделе. файл не используется при загрузке, но, прочитав ключ и PartitionPath всех файлов в разделе, конкретная реализация может следовать методу loadRecords.
Flink естественным образом поддерживает состояние, поэтому пары отношений HoodieKey и FileSlice Hudi можно сохранять в состоянии для поиска новых данных вместо поиска путем загрузки индекса таблицы, как это делает Spark. Таким образом, механизм управления состоянием Flink и контрольная точка. Механизм избавляет пользователей от необходимости выполнять сложные операции, такие как загрузка индекса и результирующее управление памятью. В то же время индекс, используемый Hudi, может иметь ложные срабатывания, а с помощью метода состояния можно гарантировать состояние нижестоящего оператора. Все точно.
5. Подробное объяснение процесса записи потока HoodieRecord DataStream.
Код всего написанного процесса выглядит следующим образом:
public static DataStream<Object> hoodieStreamWrite(Configuration conf, DataStream<HoodieRecord> dataStream) {
if (OptionsResolver.isBucketIndexType(conf)) {
// Когда тип индекса Hudi использует сегмент, задача Flink кэширует отношение сопоставления раздела/сегмента/идентификатора файла, а затем находит соответствующий файл с помощью отношения сопоставления в памяти на основе данных.
WriteOperatorFactory<HoodieRecord> operatorFactory = BucketStreamWriteOperator.getFactory(conf);
int bucketNum = conf.getInteger(FlinkOptions.BUCKET_INDEX_NUM_BUCKETS);
String indexKeyFields = conf.getString(FlinkOptions.INDEX_KEY_FIELD);
BucketIndexPartitioner<HoodieKey> partitioner = new BucketIndexPartitioner<>(bucketNum, indexKeyFields);
return dataStream.partitionCustom(partitioner, HoodieRecord::getKey)
.transform(opName("bucket_write", conf), TypeInformation.of(Object.class), operatorFactory)
.uid(opUID("bucket_write", conf))
.setParallelism(conf.getInteger(FlinkOptions.WRITE_TASKS));
} else {
// Другие типы сделают это
WriteOperatorFactory<HoodieRecord> operatorFactory = StreamWriteOperator.getFactory(conf);
return dataStream
// Группируйте по ключу, чтобы избежать одновременной записи нескольких задач в корзину.
.keyBy(HoodieRecord::getRecordKey)
// Затем выполните операцию выделения сегмента для данных. Здесь будут использоваться статус, загружаемый при запуске (если установлена загрузка при запуске), и информация о состоянии инкрементных обновлений данных.
.transform(
"bucket_assigner",
TypeInformation.of(HoodieRecord.class),
new KeyedProcessOperator<>(new BucketAssignFunction<>(conf)))
.uid(opUID("bucket_assigner", conf))
.setParallelism(conf.getInteger(FlinkOptions.BUCKET_ASSIGN_TASKS))
// Группируйте по идентификатору файла, чтобы гарантировать, что один и тот же файл будет записан в одной задаче.
.keyBy(record -> record.getCurrentLocation().getFileId())
// Выполните операцию записи данных в файл. Этот шаг будет в центре внимания последующего анализа ядра.
.transform(opName("stream_write", conf), TypeInformation.of(Object.class), operatorFactory)
.uid(opUID("stream_write", conf))
.setParallelism(conf.getInteger(FlinkOptions.WRITE_TASKS));
}
}5.1 Распределение данных по сегментам
Базовый класс — BucketAssignFunction, а основной код обработки выглядит следующим образом:
private void processRecord(HoodieRecord<?> record, Collector<O> out) throws Exception {
...
// Получить индекс в состоянии оператора
HoodieRecordGlobalLocation oldLoc = indexState.value();
if (isChangingRecords && oldLoc != null) {
// Если тип операции — UPSERT/UPSERT_PREPPED/DELETE и статус определен, поиск местоположения (fileId) будет осуществляться по статусу и моменту. Отметка времени — «U», что указывает на операцию обновления корзины.
if (!Objects.equals(oldLoc.getPartitionPath(), partitionPath)) {
// Если он отличается от старого раздела, это означает, что ключ охватывает разделы, и последующие операции будут выполняться в соответствии с конфигурацией.
if (globalIndex) {
// Если в конфигурации необходимо обновить индекс старого раздела, в старый раздел необходимо добавить удаленную запись.
HoodieRecord<?> deleteRecord = new HoodieAvroRecord<>(new HoodieKey(recordKey, oldLoc.getPartitionPath()),
payloadCreation.createDeletePayload((BaseAvroPayload) record.getData()));
deleteRecord.unseal();
deleteRecord.setCurrentLocation(oldLoc.toLocal("U"));
deleteRecord.seal();
out.collect((O) deleteRecord);
}
// Вставьте новую запись в новый раздел
location = getNewRecordLocation(partitionPath);
} else {
// Если перекрестного раздела нет, индекс в статусе будет возвращен напрямую.
location = oldLoc.toLocal("U");
this.bucketAssigner.addUpdate(partitionPath, location.getFileId());
}
} else {
// Добавить новую информацию об индексе
location = getNewRecordLocation(partitionPath);
}
if (isChangingRecords) {
// Обновить индекс в статусе
updateIndexState(partitionPath, location);
}
record.unseal();
record.setCurrentLocation(location);
record.seal();
out.collect((O) record);
}Для межраздельного поведения одного и того же ключа Hudi удалит данные в старом разделе при настройке индекса, который необходимо обновить в старом разделе, и сохранит последние данные в новом разделе для достижения глобальной уникальности.
5.2 Выполнение операции записи Hudi
Функция записи Flink для Hudi — это StreamWriteFunction. Поскольку мы уже знаем, в какой идентификатор файла необходимо записать данные на этом этапе, нам нужно только выполнить на этом этапе обычные операции сохранения и кэширования в локальной памяти. -> очистить диск, основной код выглядит следующим образом
protected void bufferRecord(HoodieRecord<?> value) {
final String bucketID = getBucketID(value);
// Найдите соответствующий сегмент в кеше и создайте новый сегмент, если его нет в кеше.
DataBucket bucket = this.buckets.computeIfAbsent(bucketID,
k -> new DataBucket(this.config.getDouble(FlinkOptions.WRITE_BATCH_SIZE), value));
final DataItem item = DataItem.fromHoodieRecord(value);
bucket.records.add(item);
// Определить, достигает ли текущий сегмент минимального размера для записи.
boolean flushBucket = bucket.detector.detect(item);
// Определить, достигает ли объем данных всех сегментов в текущем операторе записанного размера.
boolean flushBuffer = this.tracer.trace(bucket.detector.lastRecordSize);
if (flushBucket) {
// очистить текущий сегмент
if (flushBucket(bucket)) {
this.tracer.countDown(bucket.detector.totalSize);
bucket.reset();
}
} else if (flushBuffer) {
// Найдите самое большое ведро в операторе и промойте его.
DataBucket bucketToFlush = this.buckets.values().stream()
.max(Comparator.comparingLong(b -> b.detector.totalSize))
.orElseThrow(NoSuchElementException::new);
if (flushBucket(bucketToFlush)) {
this.tracer.countDown(bucketToFlush.detector.totalSize);
bucketToFlush.reset();
} else {
LOG.warn("The buffer size hits the threshold {}, but still flush the max size data bucket failed!", this.tracer.maxBufferSize);
}
}
}При оценке размера корзины здесь используется выборка в размере 1 %. При интенсивном трафике или нестабильном размере данных коэффициент выборки можно отрегулировать.
Основной код процесса выполнения прошивки диска
private boolean flushBucket(DataBucket bucket) {
String instant = instantToWrite(true);
if (instant == null) {
LOG.info("No inflight instant when flushing data, skip.");
return false;
}
List<HoodieRecord> records = bucket.writeBuffer();
ValidationUtils.checkState(records.size() > 0, "Data bucket to flush has no buffering records");
if (config.getBoolean(FlinkOptions.PRE_COMBINE)) {
// Выполните операцию дедупликации перед вставкой/обновлением
records = (List<HoodieRecord>) FlinkWriteHelper.newInstance()
.deduplicateRecords(records, null, -1, this.writeClient.getConfig().getSchema(), this.writeClient.getConfig().getProps(), recordMerger);
}
bucket.preWrite(records);
// Выполните операцию очистки диска в ведре. Эта часть относится к процессу записи Худи. Новый раздел будет открыт для анализа позже.
final List<WriteStatus> writeStatus = new ArrayList<>(writeFunction.apply(records, instant));
records.clear();
// Запишите результат флэш-диска сегмента
final WriteMetadataEvent event = WriteMetadataEvent.builder()
.taskID(taskID)
.instantTime(instant) // the write instant may shift but the event still use the currentInstant.
.writeStatus(writeStatus)
.lastBatch(false)
.endInput(false)
.build();
// Синхронизировать результат промывки ведра на диск координатору оператора
this.eventGateway.sendEventToCoordinator(event);
writeStatuses.addAll(writeStatus);
return true;
}На этом этапе запись Flink в Hudi была проанализирована, и данные были сброшены на диск. Так где же отражаются нисходящая видимость данных и транзакционный характер записи Hudi?
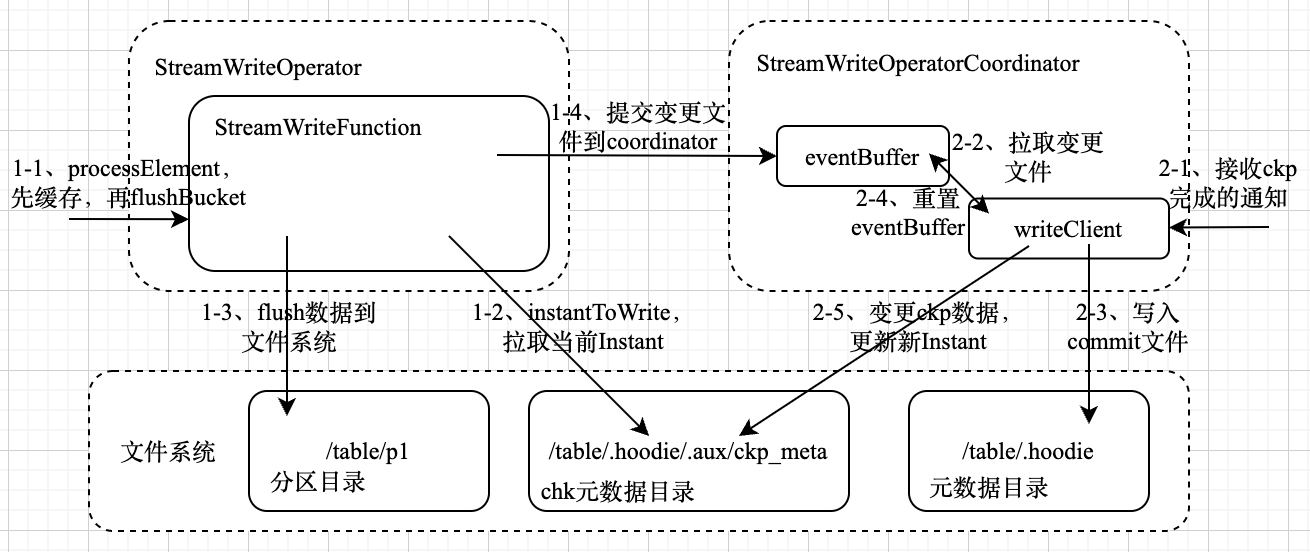
первый,Результаты очистки диска Flink Hudi будут синхронизированы с координатором оператора.,Последующие операции фиксации будут выполняться через координатора.,Этот шаг похож на двухфазную фиксацию Кафки.,Данные сначала будут сброшены на диск хранения.,Затем отправьте операцию фиксации равномерно,Основной код выглядит следующим образом:
private void handleWriteMetaEvent(WriteMetadataEvent event) {
// Есть задача, которая сбрасывает данные в кэш после завершения ckp, поэтому момент в это время будет меньше текущего момента.
ValidationUtils.checkState(
HoodieTimeline.compareTimestamps(this.instant, HoodieTimeline.GREATER_THAN_OR_EQUALS, event.getInstantTime()),
String.format("Receive an unexpected event for instant %s from task %d",
event.getInstantTime(), event.getTaskID()));
addEventToBuffer(event);
}
private void addEventToBuffer(WriteMetadataEvent event) {
// Результаты сброса каждой задачи оператора будут кэшироваться в eventBuffer координатора.
if (this.eventBuffer[event.getTaskID()] != null) {
this.eventBuffer[event.getTaskID()].mergeWith(event);
} else {
this.eventBuffer[event.getTaskID()] = event;
}
}Вышеупомянутые шаги отправят результаты очистки, отправленные каждой задачей в процессе ckp, координатору, а координатор кэширует результаты локально.
Когда все задачи выполнены ckp,Координатор получит уведомление о завершении ckp.,Затем будет выполнена операция фиксации после сброса.,Основной код выглядит следующим образом:
public void notifyCheckpointComplete(long checkpointId) {
executor.execute(
() -> {
Thread.currentThread().setContextClassLoader(getClass().getClassLoader());
// Запустить операцию фиксации
final boolean committed = commitInstant(this.instant, checkpointId);
if (tableState.scheduleCompaction) {
// Если установлена асинхронная операция уплотнения, здесь будет выполнен план.
CompactionUtil.scheduleCompaction(metaClient, writeClient, tableState.isDeltaTimeCompaction, committed);
}
if (tableState.scheduleClustering) {
// Если установлена асинхронная операция кластера, она будет запланирована здесь.
ClusteringUtil.scheduleClustering(conf, writeClient, committed);
}
if (committed) {
// Начните новый раунд мгновенного
startInstant();
// Синхронизировать метаданные куста
syncHiveAsync();
}
}, "commits the instant %s", this.instant
);
}Подробная логика отправки находится в методе commitInstant. Основная логика заключается в записи измененных файлов в текущий момент в соответствующий файл фиксации и сбросе eventBuffer. На этом этапе данные отправлены, и данные видны нижестоящему потоку. .
Полная логика написания и отправки показана на рисунке ниже:
Этот процесс написания очень долгий. Для Flink обычно требуется семантика «точно один раз». Итак, может ли описанный выше процесс достичь семантики «точно один раз»? Что касается Худи, какие соображения следует учитывать в CAP?
6. Подробное объяснение процесса сжатия файлов Hudi.
6.1 Генерация компактного плана
Компактный процесс Hudi разделен на синхронный и асинхронный. Синхронизация оказывает большое влияние на производительность. В этом разделе основное внимание уделяется анализу асинхронного компактного процесса Hudi. В предыдущей главе, когда асинхронный компактный процесс настроен, Flink генерирует план Compact, основная логика кода. следующее
public static void scheduleCompaction(
HoodieTableMetaClient metaClient,
HoodieFlinkWriteClient<?> writeClient,
boolean deltaTimeCompaction,
boolean committed) {
if (committed) {
// После завершения подачи будет создан компактный план.
writeClient.scheduleCompaction(Option.empty());
} else if (deltaTimeCompaction) {
// Если настроено планирование компактности на основе временного интервала, Генерация все равно будет выполняться независимо от того, завершена фиксация или нет. плана
metaClient.reloadActiveTimeline();
Option<String> compactionInstantTime = CompactionUtil.getCompactionInstantTime(metaClient);
if (compactionInstantTime.isPresent()) {
writeClient.scheduleCompactionAtInstant(compactionInstantTime.get(), Option.empty());
}
}
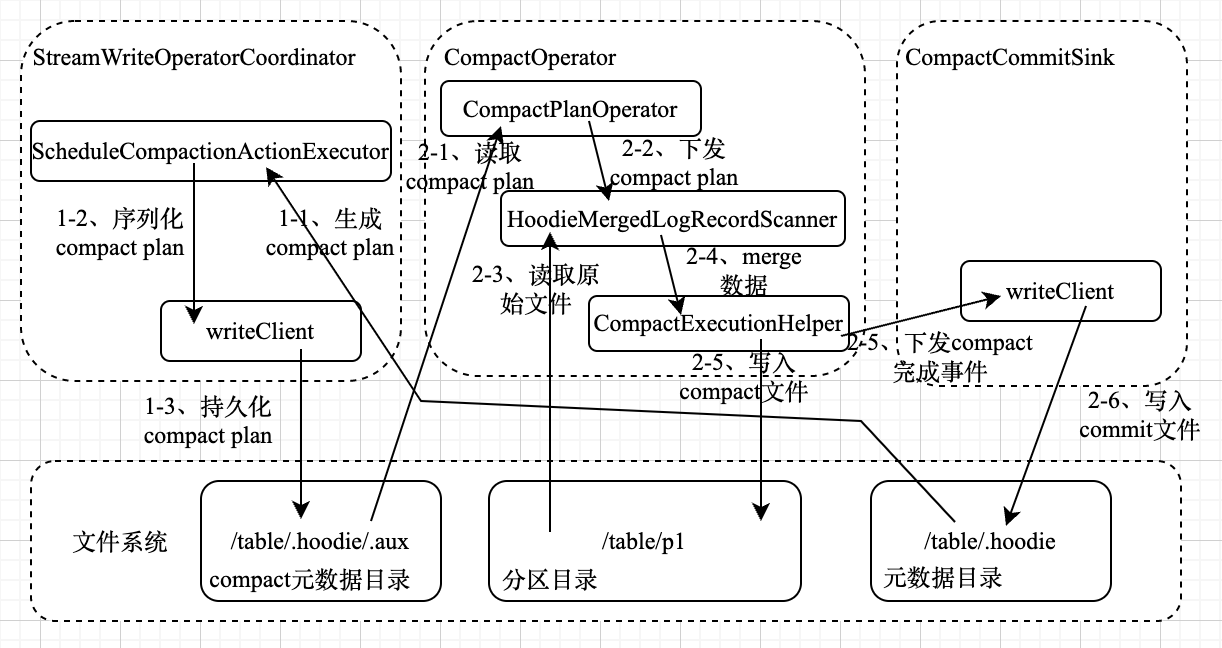
}Наше ядро следует методу ScheduleCompaction и в конечном итоге войдет в метод ScheduleCompaction таблицы. Здесь мы выбираем HoodieFlinkMergeOnReadTable. Сначала будет создан исполнитель ScheduleCompactionActionExecutor, который создает план. Этот исполнитель инициализирует Compact. Генератор плана, которым является BaseHoodieCompactionPlanGenerator, окончательно определяет, необходимо ли уплотнение в соответствии с исполнителем в соответствии со стратегией компактности, а затем вызывает генератор плана для создания плана выполнения Compact. Основной код выглядит следующим образом.
public Option<HoodieCompactionPlan> execute() {
...
//
HoodieCompactionPlan plan = scheduleCompaction();
Option<HoodieCompactionPlan> option = Option.empty();
if (plan != null && nonEmpty(plan.getOperations())) {
...
try {
if (operationType.equals(WriteOperationType.COMPACT)) {
// Компактный для сохранения файлов данных Hudi. plan
HoodieInstant compactionInstant = new HoodieInstant(HoodieInstant.State.REQUESTED,
HoodieTimeline.COMPACTION_ACTION, instantTime);
// Сериализуйте и сохраните сгенерированный план в каталоге таблицы Hudi.
table.getActiveTimeline().saveToCompactionRequested(compactionInstant,
TimelineMetadataUtils.serializeCompactionPlan(plan));
} else {
// Компактный для сохранения файлов журналов Hudi. plan
HoodieInstant logCompactionInstant = new HoodieInstant(HoodieInstant.State.REQUESTED,
HoodieTimeline.LOG_COMPACTION_ACTION, instantTime);
table.getActiveTimeline().saveToLogCompactionRequested(logCompactionInstant,
TimelineMetadataUtils.serializeCompactionPlan(plan));
}
} catch (IOException ioe) {
...
}
option = Option.of(plan);
}
return option;
}Если вы продолжите анализ метода ScheduleCompaction, вы обнаружите, что сначала извлекается самая последняя информация DeltaCommit, а затем сравнивается в соответствии со стратегией компактного выполнения, чтобы определить, требуется ли операция Compact. Если операция требуется, BaseHoodieCompactionPlanGenerator. используется для группировки информации DeltaCommit для создания HoodieCompactionPlan, а затем HoodieCompactionPlan. Выполните кодирование Avro и затем сериализуйте в файловую систему.
private HoodieCompactionPlan scheduleCompaction() {
// Определите, нужна ли компактность, на основе последней информации об инкрементальных фиксации и стратегии компактности.
boolean compactable = needCompact(config.getInlineCompactTriggerStrategy());
if (compactable) {
try {
context.setJobStatus(this.getClass().getSimpleName(), "Compaction: generating compaction plan");
// Создать компактный план, может быть закодирован в формате avro, может быть сериализован
return planGenerator.generateCompactionPlan();
} catch (IOException e) {
... }
}
return new HoodieCompactionPlan();
}6.2 Заключение и подача Договора
Основной код процесса компактного выполнения и отправки выглядит следующим образом:
public static DataStreamSink<CompactionCommitEvent> compact(Configuration conf, DataStream<Object> dataStream) {
return dataStream.transform("compact_plan_generate",
TypeInformation.of(CompactionPlanEvent.class),
// Сам оператор не выполняется. Когда контрольная точка будет завершена, будет загружен постоянный компакт предыдущего оператора. спланируйте и выполните его. Для этого оператора должна быть установлена одна степень параллелизма.
new CompactionPlanOperator(conf))
.setParallelism(1)
// Разделение по идентификатору файла
.keyBy(plan -> plan.getOperation().getFileGroupId().getFileId())
.transform("compact_task",
TypeInformation.of(CompactionCommitEvent.class),
// Согласно полученному компакту plan выполняет операцию слияния для создания новых файлов и сохранения их в файловой системе. Из-за ограничений по объему этот шаг не будет подробно анализироваться. Чтобы продолжить чтение, вы можете обратиться к исходному коду.
new CompactOperator(conf))
.setParallelism(conf.getInteger(FlinkOptions.COMPACTION_TASKS))
// Получите результаты, отправленные восходящим потоком после завершения сжатия, и выполните операцию фиксации.
.addSink(new CompactionCommitSink(conf))
.name("compact_commit")
.setParallelism(1);
}Полный процесс компактирования показан на рисунке ниже.
7. Наконец
В этой статье анализируется основной процесс написания Flink для Hudi путем чтения исходного кода. Я считаю, что только полностью поняв процесс написания, мы сможем полностью понять различные характеристики Flink и Hudi и полностью улучшить производительность онлайн-задач. мои ограниченные возможности, ошибки в статье неизбежны. Надеюсь, каждый сможет помочь их исправить после их обнаружения. Большое спасибо.
Наконец, подведем итог: в этой статье в основном анализируется основной процесс записи DataStream Flink в таблицу Hudi:
- Процесс генерации HoodieRecord DataStream, этот процесс будет выполнять процесс загрузки индекса;
- В процессе записи и отправки потока данных HoodieRecord Flink сначала группирует его в соответствии с индексом, находит адрес файла, соответствующий данным, затем записывает данные на диск, а затем использует координатора оператора для выполнения операции фиксации в соответствии с завершение контрольно-пропускного пункта и запись полного процесса ввода данных;
- Процесс сжатия файла Hudi: для асинхронного процесса сжатия Flink сгенерирует компактный план выполнения после отправки, затем сериализует и сохранит план в каталоге таблицы Hudi и, наконец, прочитает каталог таблицы Hudi через новый план оператора и выполнит сжатие, и наконец, выполните операцию фиксации после завершения компактирования. На этом этапе весь процесс записи Flink разобран.
Конечно, из-за ограниченного объема в этой статье не рассматриваются подробно архитектура и концепции Flink и Hudi, а также не рассматривается оптимизация производительности записи Flink в Hudi. Анализ производительности записи Flink в Hudi будет добавлен позже. .



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
