[Flink] [Обновление] Статус серверной части и контрольной точки
Управление статусами
Вычисления с отслеживанием состояния — важная функция, которую должна реализовать платформа потоковой обработки, поскольку в несколько более сложных сценариях потоковой обработки необходимо записывать состояние, а затем постоянно обновлять его на основе новых входящих данных. Следующие сценарии требуют использования функции состояния потоковой обработки:
- данныев потокеизданные Есть дубликаты,Мы хотим дедуплицировать данные,Необходимо зафиксировать, какие данные попали в приложение,Когда поступают новые данные,Дедупликация оценивается по потоку изданных.
- Проверяет, соответствует ли входной поток определенному шаблону.,Необходимо преобразовать ранее вытекший из элемента в Статус из формы, кэшированной. например,Определить, продолжает ли повышаться температура в подаче датчика температуры.
- Выполните совокупный анализ в пределах временного окна и проанализируйте значение 75-го или 99-го процентиля определенного показателя в течение часа.
- Сценарий двухпотокового соединения.
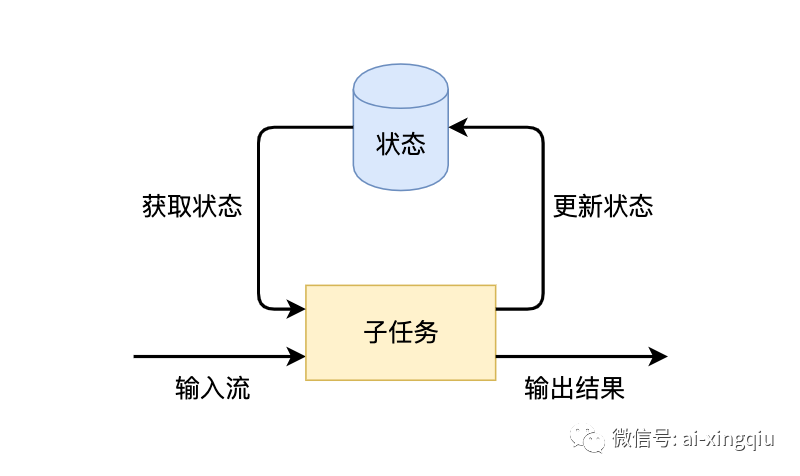
Оператор в Flink имеет несколько подзадач, и каждая подзадача распределена по разным экземплярам. Мы можем понимать состояние как переменную определенной подзадачи оператора в ее текущем экземпляре. Переменная записывает историческую информацию о потоке данных. По мере поступления новых данных мы можем комбинировать их с исторической информацией для выполнения расчетов.
Управляемое состояние и необработанное состояние
Flink имеет два основных типа состояния: управляемое состояние и необработанное состояние. Разницу между ними также можно прочитать из названия: Managed State управляется Flink, а Flink помогает с хранением, восстановлением и оптимизацией. Необработанное состояние управляется самим разработчиком и должно быть сериализовано им самим.
- | Managed State | Raw State |
|---|---|---|
Управление статусами Способ | Flink Работающий хостинг, автоматическое хранение, автоматическое восстановление, автоматическое масштабирование. | Пользователи управляют сами |
структура данных статуса | Общие структуры данных, предоставляемые Flink, такие как ValueState, ListState, MapState и т. д. | Необработанное состояние поддерживает только байты, и любую структуру данных верхнего уровня необходимо сериализовать в массив байтов. |
Сценарии использования | Большинство операторов | Пользовательский оператор |
Managed State
Управляемое состояние продолжает подразделяться и имеет два типа: состояние с ключом и состояние оператора.
Keyed State
Flink поддерживает экземпляр состояния для каждого значения ключа и разделяет все данные с одним и тем же ключом на одну и ту же задачу оператора. Эта задача будет поддерживать и обрабатывать состояние, соответствующее этому ключу. Когда задача обрабатывает фрагмент данных, она автоматически ограничивает область доступа состояния ключом текущих данных. Таким образом, все данные с одним и тем же ключом получают доступ к одному и тому же состоянию. Keyed State очень похоже на распределенную структуру данных карты значений ключа, которую можно использовать только в KeyedStream (после обработки оператором keyBy).
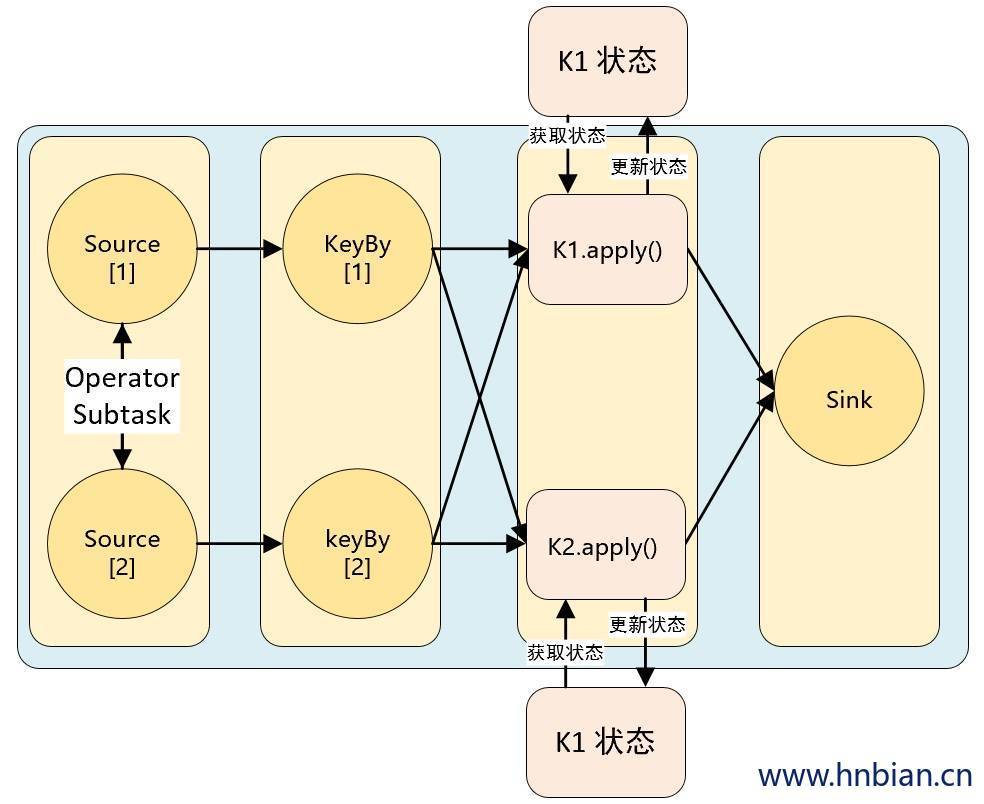
Существует пять типов ключевого состояния:
- ValueState: состояние значения, сохраняет одно значение типа T.
- ListState: состояние списка, сохраняет список типа T.
- MapState: состояние отображения, сохранение пар ключ-значение.
- ReducingState: состояние агрегации.
- AggregatingState: состояние агрегирования.
Operator State
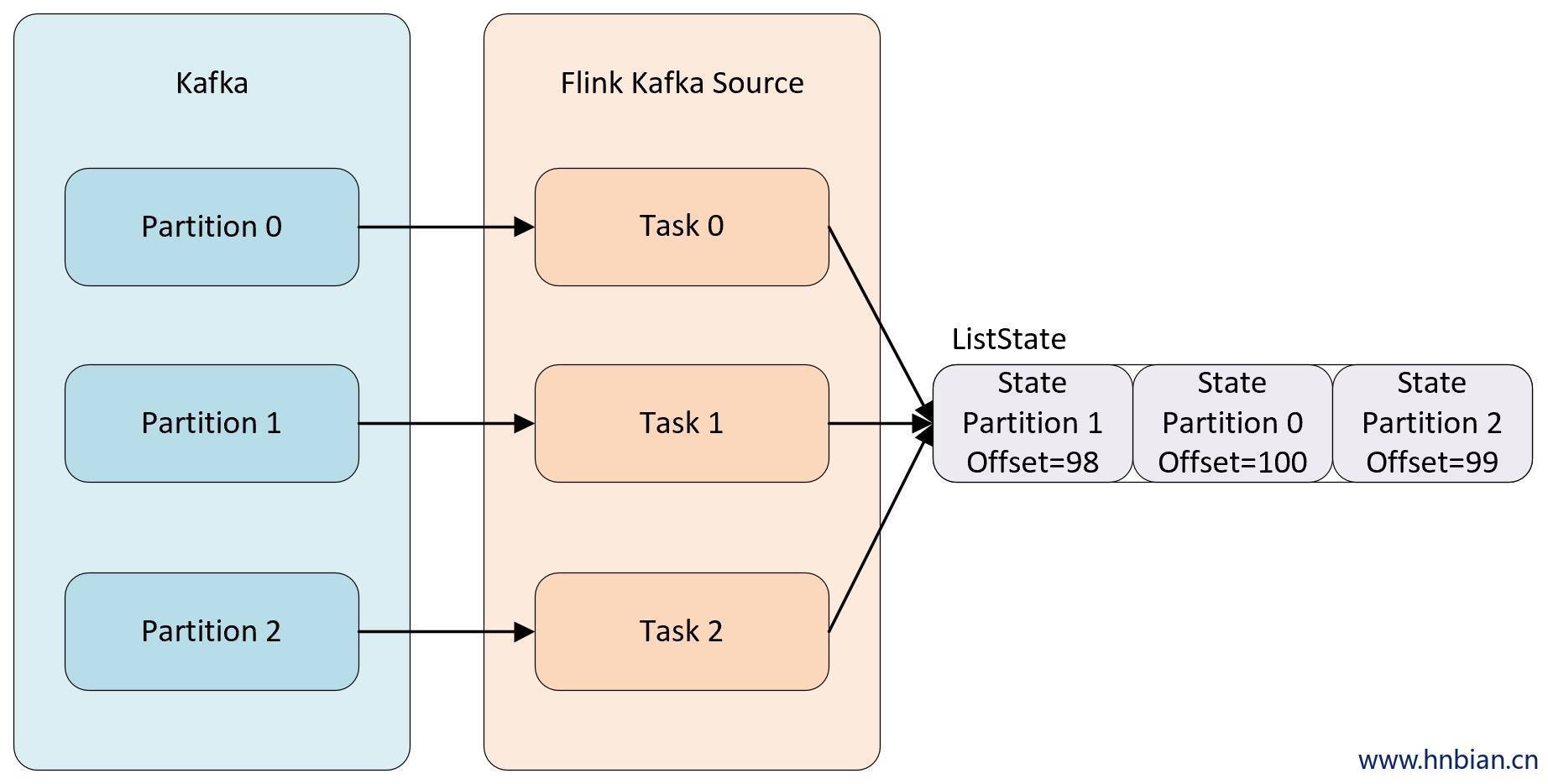
KeyedState находится в стадии разработки KeyBy Тип состояния, используемый при выполнении операций с состоянием позже, например Операторы Source и Sink не будут выполняться. KeyBy Операция: когда этому типу оператора также необходимо использовать состояние, как с ним работать? В это время вам нужно использовать Operator State(Статус оператора)Operator State обязан Operator Степень параллелизма в экземпляре, то есть одна степень параллелизма и одно состояние.
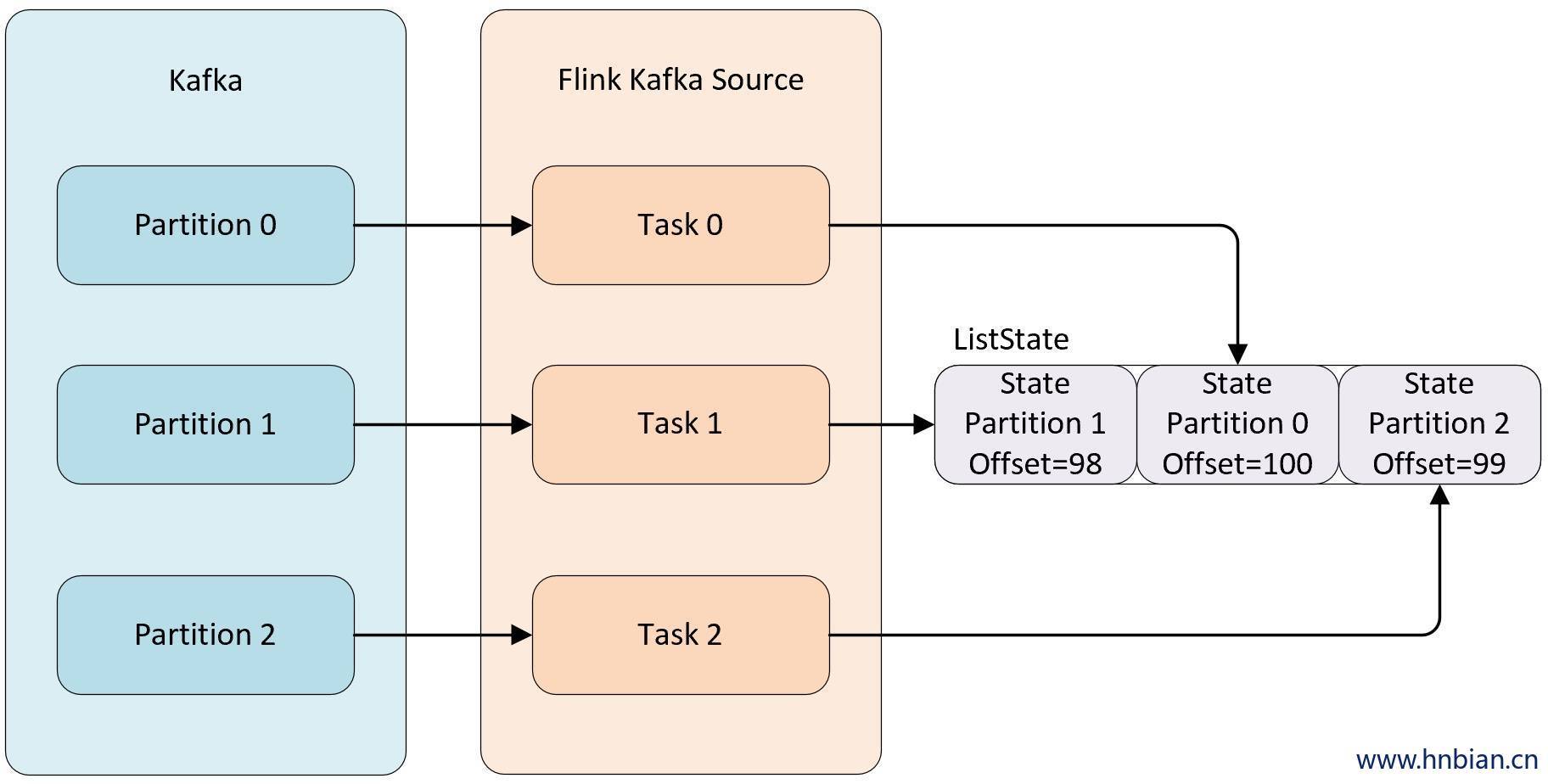
Например, когда степень параллелизма источника Kafka, который использует данные Kafka, равна 3, по умолчанию каждая степень параллелизма использует данные из определенного раздела темы Kafka. Чтобы гарантировать, что в крайних случаях данные не будут потеряны, каждый Kafka. Источник Вы не можете сохранить смещение, соответствующее разделу, в Zookeeper по умолчанию. Вместо этого вам необходимо сохранить эти данные в состоянии и поддерживать эту часть данных самостоятельно. Когда параллелизм настроен, состояние необходимо перераспределить на параллелизме Оператора.
В большинстве сценариев разработки потоковой передачи данных нам не нужно использовать состояние оператора. Реализация состояния оператора в основном предназначена для источников и приемников, которые не имеют операций с ключами.
Объем состояния оператора ограничен задачами оператора. Это означает, что все данные, обрабатываемые одной и той же параллельной задачей, могут иметь доступ к одному и тому же состоянию, и это состояние является общим для одной и той же задачи. К состоянию оператора не может получить доступ другая задача того же или другого оператора.
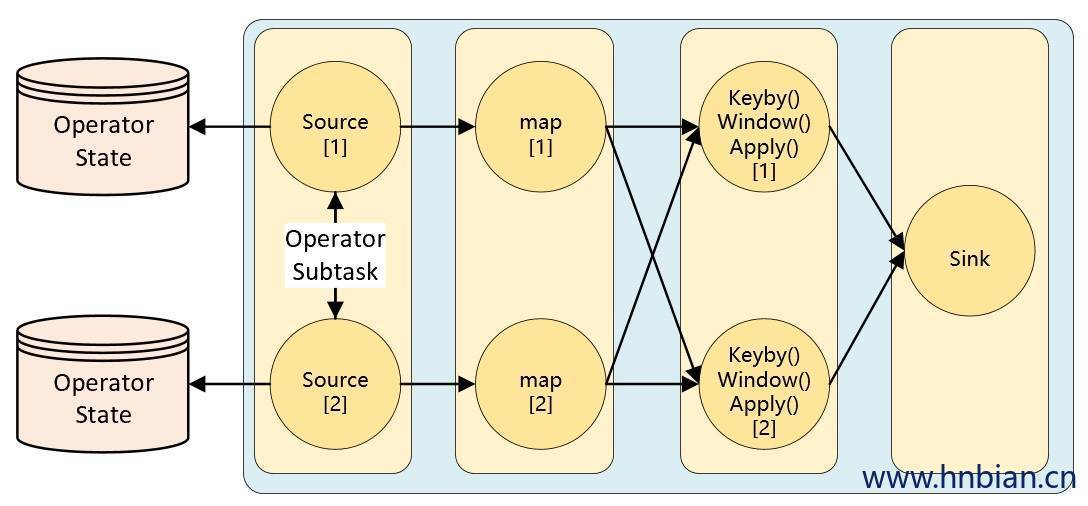
Flink предоставляет три основные структуры данных для статуса оператора:
- статус списка ( List state ): Статус Сериализуемый коллекция предметов
List,независимы друг от друга,Облегчает Статус после изменения параллелизма. из Переназначение. Эти объекты перераспределяются non-Keyed State тончайшая зернистость. В соответствии с различными методами доступа состояния существуют следующие два режима перераспределения:- Even-split redistribution: Каждый оператор сохраняет набор состояний в виде списка, и все состояние состоит из всех списков. Когда задание возобновляется или перераспределяется, все состояние будет равномерно распределено в соответствии с параллелизмом оператора. Например, оператор A Параллельное чтение – это 1. Содержит два элемента
element1иelement2,Когда количество одновременных чтений увеличивается до 2,element1будет назначено одновременному 0 начальство,element2нобудет назначено одновременному 1 начальство.
- Union redistribution: Каждый оператор сохраняет набор состояний в виде списка. Все состояние состоит из всех списков. При возобновлении или переназначении задания каждый оператор получит все данные о статусе. Союз redistribution режим checkpoint метаданные будут созданы для каждого оператора из subTask из смещенной информации. Если список Когда база государства велика, не используйте этот метод перераспределения. Потому что легко вызвать ООМ.
- Вызовите другой, чтобы получить объект статуса из интерфейса, буду Например, используйте другой алгоритм распределения статуса.
getUnionListState(descriptor)буду использовать union redistribution алгоритм, иgetListState(descriptor)Он прост в использовании even-split redistribution алгоритм. - После инициализации объекта состояния мы передаем
isRestored()Метод определяет, следует ли восстанавливаться после предыдущего сбоя, если метод возвращает значение.trueЭто означает восстановление после неисправности, и будет выполнена следующая логика восстановления.
- Even-split redistribution: Каждый оператор сохраняет набор состояний в виде списка, и все состояние состоит из всех списков. Когда задание возобновляется или перераспределяется, все состояние будет равномерно распределено в соответствии с параллелизмом оператора. Например, оператор A Параллельное чтение – это 1. Содержит два элемента
- статус трансляции ( Broadcast state ): Если у оператора несколько задач, и статус каждой задачи одинаковый, то этот частный случай наиболее подходит для применения широковещательного статуса.
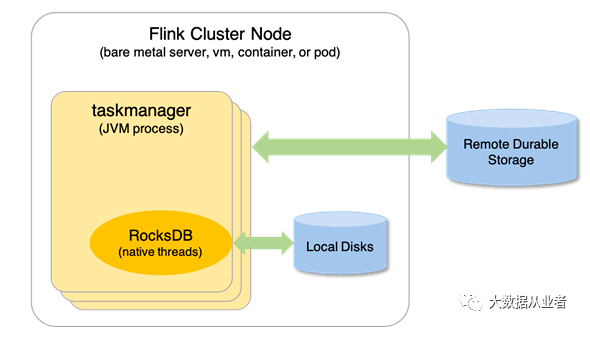
Статус бэкэнда и контрольная точка
- Задняя часть статуса сохраняется в локальном статусе.
- Checkpoint — это регулярное резервное копирование статуса на стороннее хранилище.,Такие как hdfs,выше наблюдения,Удобно восстановить работу при повторном запуске задания.
Конфигурация, связанная со статусом серверной части
Имя конфигурации | значение по умолчанию | иллюстрировать |
|---|---|---|
state.backend | - | Рекомендуется настроить его как RocksDB. |
state.backend.latency-track.keyed-state-enabled | false | Отслеживать ли задержку операций с ключевыми состояниями. Рекомендуется не включать. |
state.backend.latency-track.sample-interval | 100 | Отслеживайте операции, которые занимают более 100 мс. |
state.backend.latency-track.history-size | 128 | Отслеживайте количество операций, которые занимают много времени |
table.exec.state.ttl | - | Время ttl серверной части состояния обычно используется в сценариях присоединения, чтобы предотвратить слишком большой размер серверной части состояния, приводящий к сбою задания. |
конфигурация, связанная с контрольно-пропускным пунктом
Имя конфигурации | значение по умолчанию | иллюстрировать |
|---|---|---|
execution.checkpointing.interval | - | Время срабатывания контрольной точки, контрольная точка будет срабатывать каждый период времени. Рекомендуется, чтобы общая конфигурация составляла около 1-10 минут. |
execution.checkpointing.mode | EXACTLY_ONCE | EXACTLY_ONCE: гарантированно будет точным один раз; AT_LEAST_ONCE: хотя бы один раз. Предложить EXACTLY_ONCE |
state.backend.incremental | false | Включить ли инкрементную контрольную точку, рекомендуется включить ее |
execution.checkpointing.timeout | 10min | Рекомендуется установить таймаут контрольной точки больше, около 30 минут. |
execution.checkpointing.unaligned.enabled | false | Включать ли невыровненную контрольную точку, рекомендуется не включать |
execution.checkpointing.unaligned.forced | false | Следует ли принудительно включать неприсоединенные контрольные точки |
execution.checkpointing.max-concurrent-checkpoints | 1 | Максимальное количество одновременных КПП |
execution.checkpointing.min-pause | 0 | Минимальное время паузы между двумя контрольными точками |
execution.checkpointing.tolerable-failed-checkpoints | - | Допустимое количество последовательных сбоев контрольных точек. |
execution.checkpointing.aligned-checkpoint-timeout | 0 | Тайм-аут контрольной точки выравнивания |
execution.checkpointing.alignment-timeout | 0 | Ссылка: выполнение.checkpointing.aligned-checkpoint-timeout (истек) |
execution.checkpointing.force | false | Форсировать ли контрольную точку (срок действия истек) |
state.checkpoints.num-retained | 1 | Количество сохраненных контрольных точек |
state.backend.async | true | Включить ли асинхронную контрольную точку (срок действия истек) |
state.savepoints.dir | - | папка для хранения точек сохранения |
state.checkpoints.dir | - | папка для хранения контрольных точек |
state.storage.fs.memory-threshold | 20kb | Минимальный размер файла состояния |
state.storage.fs.write-buffer-size | 4 * 1024 | Размер буфера записи по умолчанию для потоков контрольных точек, записываемых в файловую систему. |
Конфигурация, связанная с RocksDb
Имя элемента конфигурации | значение по умолчанию | иллюстрировать |
|---|---|---|
state.backend.rocksdb.checkpoint.transfer.thread.num | 4 | Количество потоков, используемых для загрузки и скачивания файлов |
state.backend.rocksdb.write-batch-size | 2mb | Максимальный объем памяти, потребляемый Rocksdb при записи |
state.backend.rocksdb.predefined-options | DEFAULT | DEFAULT:всеизRocksDbКонфигурация Всезначение по умолчанию。 SPINNING_DISK_OPTIMIZED: оптимизировать параметры RocksDb при записи на жесткий диск. SPINNING_DISK_OPTIMIZED_HIGH_MEM: Оптимизация параметров при записи на обычный жесткий диск требует потребления большего объема памяти FLASH_SSD_OPTIMIZED: оптимизация при записи на флэш-диск SSD. |
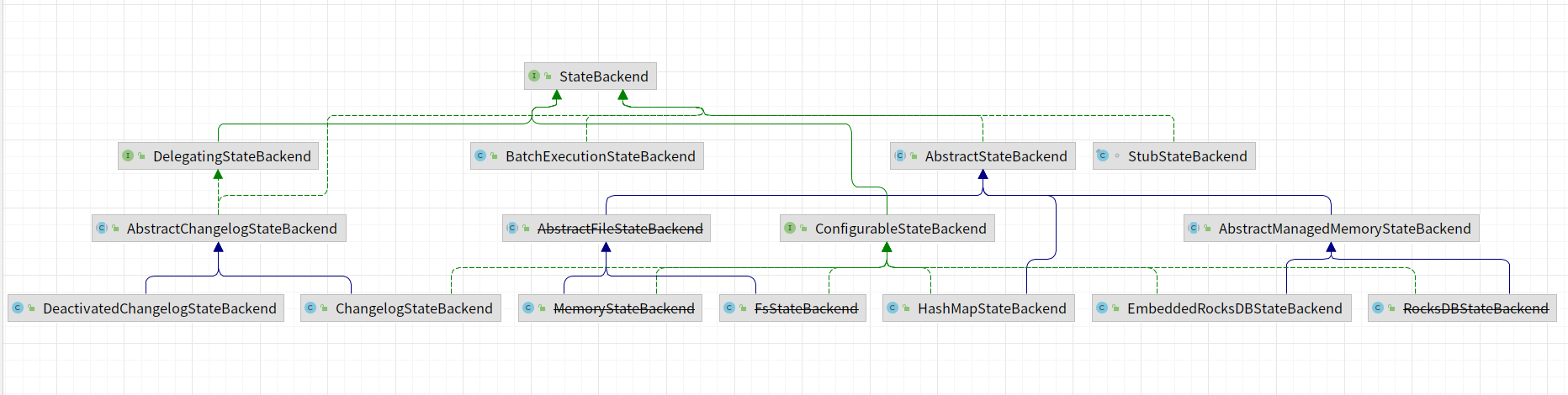
Государственная серверная реализация
Диаграмма классов реализации StateBackend,В версии 1.17,Срок действия части статуса задняя часть истек,например:MemoryStateBackend、RocksDBStateBackend、FsStateBackendждать。
После удаления состояния с истекшим сроком действия оставшийся бэкэнд выглядит следующим образом:
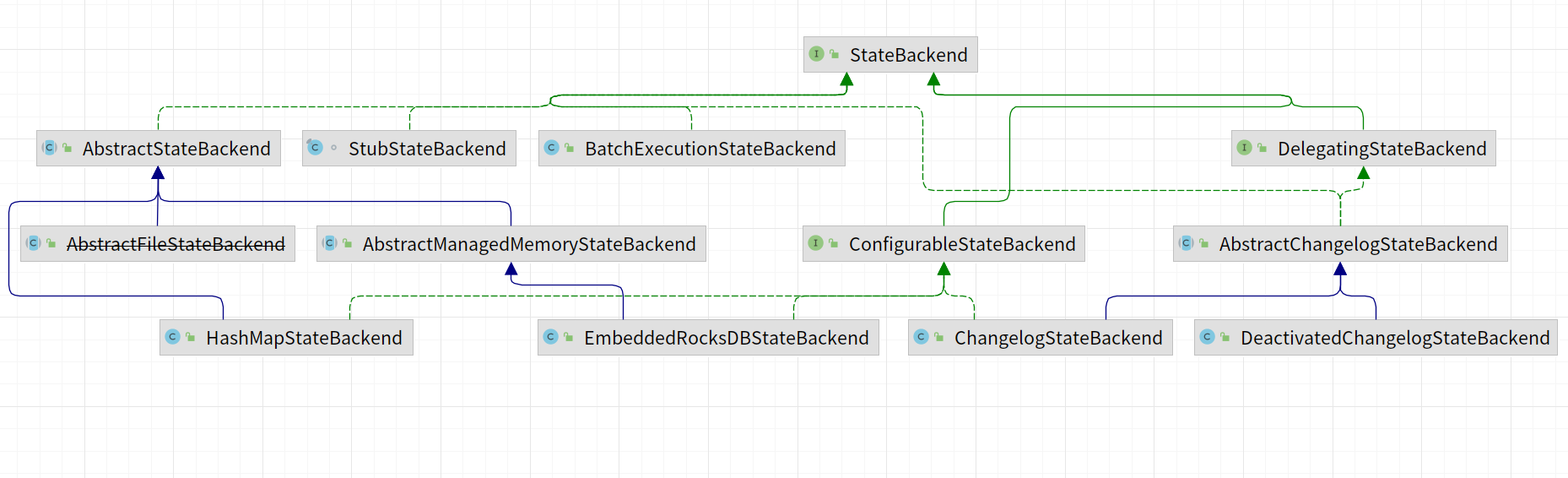
HashMapStateBackend
Сохраните серверную информацию о состоянии задания в памяти TaskManager. Если TaskManager выполняет несколько задач параллельно, вся совокупная информация должна быть сохранена в текущей памяти TaskManager. Данные в основном хранятся в куче памяти в виде объектов Java. Форма ключ/значение операторов состояния и окон будет содержать хеш-таблицу, в которой хранятся значения состояния и триггеры.
Формат хранения в памяти определяется следующим образом:
/** So that we can give out state when the user uses the same key. */
private final HashMap<String, InternalKvState<K, ?, ?>> keyValueStatesByName;Применимые сценарии
- Есть более крупный состояние, дольше window больше key/value Статус из Job。
- Все сценарии высокой доступности.
Рекомендуется также managed memory Установите значение 0, чтобы обеспечить выделение максимального объема памяти для JVM код пользователя включен.
EmbeddedRocksDBStateBackend
Сохраните статус текущих заданий в RocksDb.
Бэкэнд CreateKeyedStateBackend
- нагрузка
RocksDB JNI libraryСвязанныйJarСумка。 - Подайте заявку на объем памяти, необходимый RocksDB. Основной код находится в классе SharedResources и функции getOrAllocateSharedResource. Ресурсы будут заблокированы перед подачей заявки на них.,После успешной блокировки блокировки будут применены необходимые ресурсы. Код блокировки следующий:
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new MemoryAllocationException("Interrupted while acquiring memory");
}Прежде чем подавать заявку на ресурсы, вам необходимо определить, была ли заявка на ресурс по типу. Если на ресурс уже была подана заявка, она не будет применена повторно. Если нет, вам необходимо подать заявку. Код приложения следующий:
private static <T extends AutoCloseable> LeasedResource<T> createResource(
LongFunctionWithException<T, Exception> initializer, long size) throws Exception {
final T resource = initializer.apply(size);
return new LeasedResource<>(resource, size);
}- Создайте ресурсный контейнер, включая предопределенные параметры оптимизации RocksDB и т. д.
private RocksDBResourceContainer createOptionsAndResourceContainer(
@Nullable OpaqueMemoryResource<RocksDBSharedResources> sharedResources,
@Nullable File instanceBasePath,
boolean enableStatistics) {
return new RocksDBResourceContainer(
configurableOptions != null ? configurableOptions : new Configuration(),
predefinedOptions != null ? predefinedOptions : PredefinedOptions.DEFAULT,
rocksDbOptionsFactory,
sharedResources,
instanceBasePath,
enableStatistics);- Инициализация RocksDBKeyedStateBackend загрузит данные из каталога в RocksDB.
restoreOperation =
getRocksDBRestoreOperation(
keyGroupPrefixBytes,
cancelStreamRegistry,
kvStateInformation,
registeredPQStates,
ttlCompactFiltersManager);
RocksDBRestoreResult restoreResult = restoreOperation.restore();
db = restoreResult.getDb();
defaultColumnFamilyHandle = restoreResult.getDefaultColumnFamilyHandle();Ниже показана диаграмма классов реализации restoreOperation, которая в основном включает следующие классы реализации.
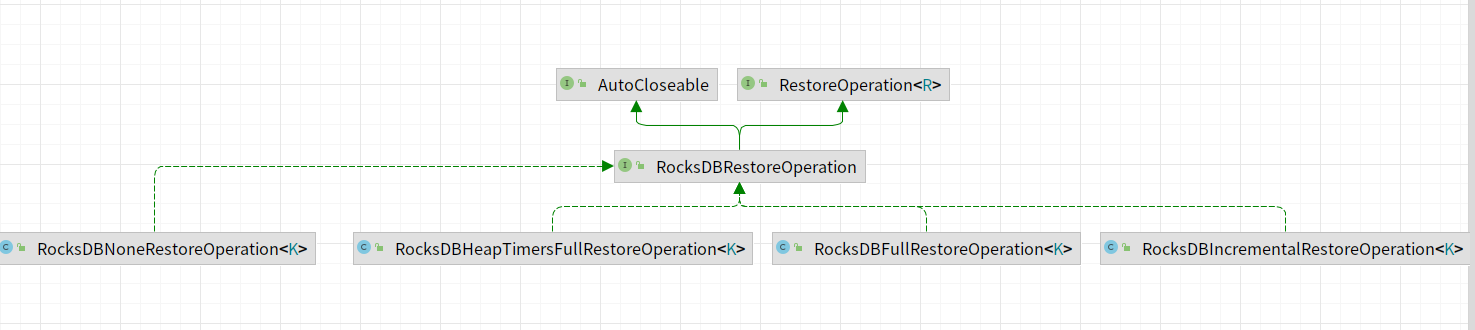
RocksDBIncrementalRestoreOperation
В основном реализует восстановление данных RocksDB из инкрементных снимков. Основная функция — восстановление(). Основные различия:
- restoreWithRescaling: из нескольких инкрементальных состояний сзади восстановление части требует расширения и сжатия. Во время этого процесса будет создан временный экземпляр RocksDB для закрытия групп ключей. Временный RocksDB будет перенесен в реальный экземпляр RocksDB.
- RestorationWithoutRescaling: инкрементальное изменение состояния с одного пульта дистанционного управления. частичное восстановление, расширение или сжатие не требуется.
if (isRescaling) {
restoreWithRescaling(restoreStateHandles);
} else {
restoreWithoutRescaling(theFirstStateHandle);
}Принцип реализации restartWithRescaling
- Выберите оптимальныйKeyedStateHandle.
- Инициализируйте экземпляр RocksDB.
- Конвертировать группы ключей из временной RocksDB в Base RocksDBданные библиотеки.
Принцип реализации restartWithoutRescaling
RocksDBFullRestoreOperation
RocksDBHeapTimersFullRestoreOperation
RocksDBNoneRestoreOperation
ChangelogStateBackend
DeactivatedChangelogStateBackend



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
