FedPylot, исследование обнаружения целей YOLOv7 в режиме реального времени и защиты конфиденциальности в рамках федеративной структуры обучения!

Интернет транспортных средств (IoV) становится ключевым компонентом автономного вождения и интеллектуальных транспортных систем (ИТС), обеспечивая обработку больших данных с малой задержкой в плотно взаимосвязанных сетях, включающих транспортные средства, инфраструктуру, пешеходов и облако. Беспилотные транспортные средства в значительной степени полагаются на машинное обучение (ML) и получают большую выгоду от богатых сенсорных данных, генерируемых на периферии, что требует принятия мер по согласованию обучения модели с защитой конфиденциальности конфиденциальных пользовательских данных. Федеративное обучение (FL) служит многообещающим решением для обучения сложных моделей машинного обучения в Интернете транспортных средств, которые могут защитить конфиденциальность участников дорожного движения, одновременно снижая накладные расходы на связь. В этой статье изучается использование федеративного обучения для оптимизации передовой модели YOLOv7 для решения проблем обнаружения целей в реальном времени в условиях неоднородности данных (включая дисбаланс, дрейф понятий и отклонение распределения меток). С этой целью мы представляем FedPylot, легкий прототип на основе MPI для моделирования экспериментов по федеративному обнаружению целей в системах высокопроизводительных вычислений (HPC), где мы используем гибридное шифрование для защиты связи между сервером и клиентом. В исследовании авторов учитываются точность, стоимость связи и скорость вывода, чтобы обеспечить сбалансированный подход к проблемам, с которыми сталкиваются беспилотные транспортные средства. Авторы показывают перспективы применения FL в IoV и надеются, что FedPylot обеспечит основу для будущих исследований по федеративному обнаружению целей в реальном времени. Исходный код доступен по адресу https://github.com/cyprienquemeneur/fedpylot.
I Introduction
Ожидается, что интеллектуальные транспортные системы (ИТС) изменят мобильность за счет повышения безопасности, оптимизации транспортных потоков, сокращения выбросов транспортных средств и расхода топлива, а также предоставления информационно-развлекательных услуг. Эта трансформация стала возможной благодаря достижениям в области машинного обучения (ML) и технологий связи «автомобиль ко всему» (V2X), которые способствуют беспрепятственному сотрудничеству между транспортными сетями, пешеходами и инфраструктурой, генерируя огромные объемы данных и интегрируя их в единый Интернет транспортных средств. (Ио В) [1]. Для обеспечения совместного использования данных IoV опирается на самые передовые технологии беспроводных сетей, которые могут обеспечить надежную и безопасную передачу на большие расстояния с малой задержкой [2].
В свою очередь, подключенные автономные транспортные средства, которые облегчают обмен информацией через IoV, могут улучшить их экологическую осведомленность, но их способность решать сложные навигационные задачи по-прежнему зависит от моделей машинного обучения (ML) [3].
Кроме того, хотя транспортные средства могут использовать несколько датчиков, таких как камеры, лидары, радары и системы GPS, для сбора мультимодальных данных, которые поддерживают машинное обучение и своевременное принятие решений, выгрузка обучения моделей в облако поднимает проблемы конфиденциальности, удобства использования и долгосрочной масштабируемости. вопрос.
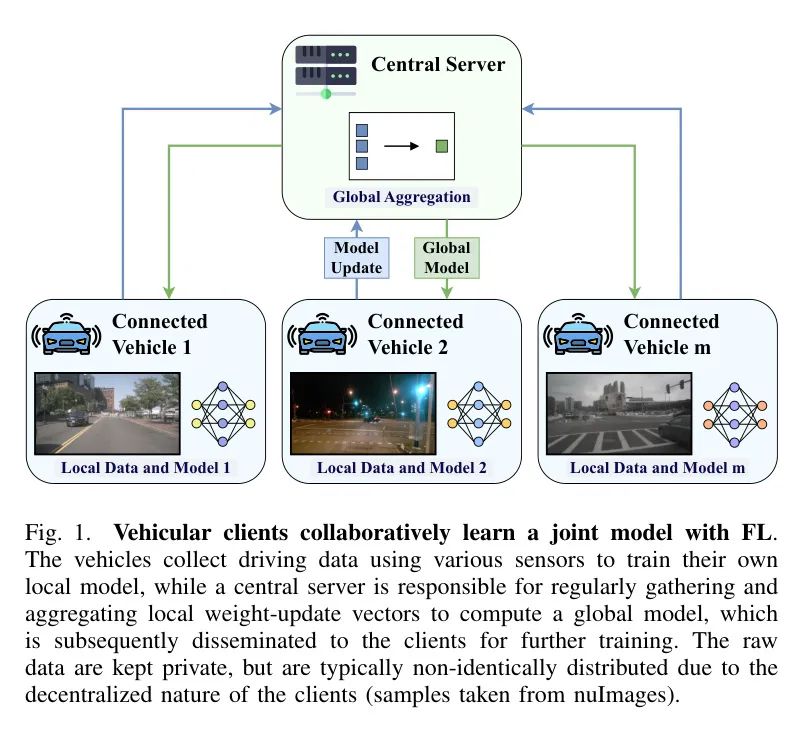
Чтобы облегчить эти проблемы, федеративное обучение (FL) было предложено в качестве решения, облегчающего сотрудничество в обучении граничных моделей и защищающего конфиденциальность пользователей, одновременно уменьшая узкие места связи, возникающие в IoV [4, 5]. В FL запрещен обмен необработанными данными, обучение происходит локально на пограничных клиентах, а затем используется центральный агент агрегации для регулярного сбора и объединения обновлений модели. Рисунок 1 иллюстрирует этот процесс в IoV, где основными клиентами являются транспортные средства, а центральные серверы агрегации стратегически расположены на границе сети, чтобы уменьшить задержку. Кроме того, пограничные серверы, рассредоточенные по определенной географической области, сами могут полагаться на облачные платформы для облегчения координации в масштабе или для обеспечения второго уровня агрегации [6].
Видение в реальном времени незаменимо для автономных транспортных средств, поскольку для достижения полной автономности вождения требуются сложные системы на основе зрения, которые могут достичь способностей восприятия на уровне человека в сложных и динамичных средах [7]. Во многих исследованиях изучался потенциал использования федеративного обучения (FL) для улучшения возможностей визуального восприятия транспортных средств и охвата распознавания дорожных знаков [8, 9, 10], обнаружения выбоин и других дорожных повреждений, семантической сегментации [14, 15] и т. д. обнаружение цели. Другие задачи, которые частично, но не исключительно, зависят от зрительного восприятия транспортного средства, также были исследованы с помощью FL, такие как прогнозирование траектории [32] и предотвращение столкновений [33]. Однако в этих исследованиях часто используются модели, которые не подходят для видения в реальном времени, или родственные, но устаревшие модели машинного обучения (МО). Это делает результаты менее применимыми для оценки осуществимости FL с помощью современных моделей машинного обучения в режиме реального времени. Напротив, в данном исследовании основное внимание уделяется YOLOv7, последнему члену серии YOLO (You Only Look Once) моделей обнаружения целей в реальном времени.
Благодаря бесчисленным постоянным улучшениям модель YOLO получила значительное признание в области компьютерного зрения и широко используется в различных приложениях, включая автономные транспортные средства, системы мониторинга и робототехнику [35]. Кроме того, в этом исследовании рассматривается применение YOLOv7 в рамках FL для обработки данных о ситуации автономного вождения, поступающих от транспортных средств, находящихся в разных географических точках и в разные периоды времени, в результате чего транспортные средства сталкиваются с неоднородными данными.
Результаты этой статьи можно резюмировать следующим образом:
- Автор разработал FedPylot,Прототип FL на основе интерфейса анализа сообщений (MPI).,Разработан специально для проведения экспериментов по объединенному обнаружению целей в системах высокопроизводительных вычислений (HPC).,и внедрил гибридную систему шифрования,Для защиты безопасности коммуникаций между участниками ФЛ.
- Насколько известно автору,Автор предлагает первую федеративную рамку для YOLOv7.,Позволяет проводить масштабные эксперименты. в авторской оценке,Авторы учитывали производительность прогнозирования, скорость вывода и накладные расходы на связь.,Акцент на локальную оптимизацию,И включает в себя динамику на стороне сервера и индивидуальную скорость обучения.
- Автор продемонстрировал FedPylot на двух связанных эпизодах с данными о беспилотном вождении.,и смоделированная неоднородность данных, вызванная пространственно-временными изменениями,Также учитываются дисбаланс, дрейф концепций и перекос в распределении меток. Граф классов путем включения двух распределений с длинным хвостом в авторскую стратегию разделения.,Авторы фиксируют неоднородность на разных уровнях детализации.,Также рассмотрите последовательность навигации.
Автор делает FedPylot открытым исходным кодом, надеясь, что он будет полезен проектам, связанным с федеративным обучением, в сообществе по обнаружению целей. FedPylot поддерживает возможность масштабирования до большого количества вычислительных узлов, при этом с ним легче начать работу, чем с высокоуровневыми средами федеративного обучения (например, FedML [36], PySyft [37], Flower [38]), интегрируя сложные пользовательские модели в высокоуровневые структуры, например, современные детекторы объектов, могут столкнуться с проблемами.
Оставшаяся часть этой статьи организована следующим образом. В разделе 2 представлен обзор основных концепций и инструментов, используемых в этой статье.
Далее в разделе 3 рассматривается текущая исследовательская литература по вопросам обнаружения объектов, федеративного обучения и автономного вождения. В разделе 4 автор подробно описывает теоретическую разработку прототипа авторского федеративного обучения. Раздел 5 посвящен знакомству с реализацией FedPylot и экспериментальными настройками автора. В разделе 6 представлен обзор экспериментальных результатов авторов. Наконец, раздел 7 завершает статью.
II Background
Федеративное обучение (FL) было предложено Мак Маханом и др. в 2016 году [39]. В традиционном FL клиенты участвуют в совместном обучении общей модели машинного обучения в нескольких раундах связи с помощью координационного сервера, не раскрывая свои соответствующие локальные наборы данных. Авторы предполагают горизонтальное разделение, при котором локальный набор данных клиента отличается выборками данных, но использует одно и то же пространство объектов. Размер каждого локального набора данных определяется как , где . Цель оптимизации – минимизировать
где – возможно невыпуклая локальная целевая функция клиента. В начале процесса обучения центральный сервер инициализирует глобальную модель на основе случайных или предварительно обученных весов и передает ее клиентам. В исходном и базовом алгоритмах FedAvg в начале раунда связи для участия в раунде случайным образом выбирается подмножество клиентов с индексом in. Затем эти клиенты получают общую модель с сервера и обучают ее локально на своих соответствующих локальных наборах данных в течение нескольких эпох, используя стохастический градиентный спуск (SGD) с локальными размерами мини-пакетов. Затем центральный сервер собирает обновленные локальные модели от каждого клиента и объединяет их, в результате чего создается следующий экземпляр глобальной модели.
Редди и др. [40] формализовали FedOpt как прямое обобщение FedAvg. В FedOpt больше не предполагается, что локальный оптимизатор клиента должен быть SGD, а правила обновления глобальной модели переформулируются как задача оптимизации. Предположим, что вектор обновления веса передается на сервер, который может агрегировать локальные обновления для формирования псевдоградиента, который затем передается в оптимизатор сервера. В частности, (2) эквивалентно
Это соответствует использованию SGD со скоростью обучения 1 в качестве оптимизатора сервера. Чтобы оценить сходимость процесса обучения, необходимо оценить глобальную модель. Оценка может выполняться на стороне сервера для отдельных наборов данных или для подмножества клиентов перед агрегированием результирующей локальной статистики. Исходный процесс FL можно варьировать по-разному, например, персонализированное федеративное обучение (pFL) позволяет обеспечить определенную степень настройки общей модели, которая больше не является уникальной для всех клиентов [41], в то время как некоторые реализации Blockchain обеспечивают полную децентрализацию, тем самым полностью устраняя необходимость в центральном сервере [42] также можно предположить вертикальное разделение, при котором локальные наборы данных различаются по пространству признаков, а не по пространству выборки [43].
Ii-A2 Data heterogeneity
При федеративном обучении (FL) данные часто неодинаково распределяются (не IID) по клиентам, что может привести к расхождению локальной модели во время обучения и снижению точности глобальной модели. Кайруз и др. [44] предложили несколько форм гетерогенности данных, три из которых имеют отношение к исследованиям авторов:
- Дрейф концепции: одна и та же этикетка может иметь совершенно разные характеристики для разных клиентов, например, из-за разных погодных условий, местоположения или временных масштабов.
- Неравномерность распределения тегов. Могут быть различия в распределении тегов данных между клиентами.,Например,Потому что возможность встретить те или иные теги связана со средой определенных конкретных клиентов.
- Дисбаланс: количество хранимых образцов данных может значительно различаться в зависимости от клиента.
Специалисты по федеративному обучению разработали несколько стратегий для моделирования неоднородности данных в экспериментах. В классификации изображений широко изучается перекос меток, а распределение Дирихле часто используется для создания искусственной сегментации наборов данных без IID [45]. Напротив, в таких задачах, как обнаружение объектов, неоднородность данных многогранна и лучше всего моделируется путем выявления естественных семантических сегментаций в наборе данных, таких как погода или местоположение в ITS. Для решения проблемы неоднородности данных было предложено множество популярных методов, включая, помимо прочего, FedProx [46], который вводит проксимальный член для каждой локальной целевой функции для повышения устойчивости к локальным обновлениям переменных SCAFFOLD [47]. использует управляющие переменные для уменьшения дисперсии и балансировки отклонений клиентов и MOON [48], который применяет контрастное обучение на уровне модели для коррекции локального обучения на основе сходства между представлениями модели; Однако многие из этих алгоритмов изначально были разработаны для классификации изображений и могут не работать должным образом при применении к более сложным задачам зрения [49]. Другие методы более легко совместимы с обнаружением объектов, и авторы обсуждают их ниже. Стратегии, основанные на замене SGD на стороне сервера более продвинутыми оптимизаторами ML, такими как Adam [50], ортогональны вышеупомянутым стратегиям и могут улучшить сходимость в настройках, отличных от IID [40]. Аналогичным образом, Hsu и др. [45] придали импульс оптимизации на стороне сервера, создали FedAvgM и эмпирически продемонстрировали улучшение производительности в гетерогенных дистрибутивах. В FedAvgM глобальное обновление включает в себя термин скорости, который накапливает прошлые псевдоградиенты с экспоненциальной скоростью затухания, контролируемой постоянным коэффициентом импульса. FedAvgM можно обобщить, добавив дополнительную постоянную скорость обучения, поэтому правило обновления будет следующим:
Среди них сумма восстанавливается до исходного алгоритма FedAvg. Momentum также можно применять на уровне клиента для повышения стабильности локальных обновлений, сохраняя при этом конвергенцию в настройках, отличных от IID [51, 52]. Было также показано, что запуск федеративного обучения после этапа предварительного обучения вместо случайной инициализации с использованием прокси-данных, доступных на сервере, улучшает стабильность глобальной агрегации и устраняет разрыв с централизованным обучением, даже если данные неоднородны [53, 54].
Ii-A3 Other challenges in FL
FL порождает множество других проблем, таких как разработка стимулов для поощрения клиентов с крупнейшими пулами данных к участию в процессе объединения, обеспечение справедливости среди клиентов, учет неоднородности клиентских вычислительных возможностей, разработка структур FL и накладные расходы на ограничения. Более того, несмотря на дополнительные преимущества защиты конфиденциальности FL, он не лишен рисков. Злоумышленники могут получить доступ к исходным данным обучения или снизить целостность обучения, проводя такие атаки, как инверсия модели и отравление обновления модели. Состязательные методы, такие как безопасные многосторонние вычисления [55], гомоморфное шифрование [56] и дифференциальная конфиденциальность [57], могут помочь облегчить эту проблему, но могут увеличить вычислительные и коммуникационные издержки или вызвать снижение производительности.
Object detection
Обнаружение объектов является одной из задач компьютерного зрения. Модель пытается обнаружить все экземпляры интересующего целевого класса на изображении и определить их местоположение и пространственный диапазон с помощью ограничивающих рамок [58]. При обнаружении объектов в реальном времени скорость вывода модели также имеет решающее значение для реализации задачи и обычно измеряется в миллисекундах или кадрах в секунду (FPS). Глубокое обучение оказало значительное влияние на обнаружение объектов за последнее десятилетие, и современные детекторы объектов часто основаны на сверточных нейронных сетях. Двухэтапные детекторы объектов, такие как R-CNN [59] и SPP-Net [60], сначала генерируют предложения региона, прежде чем отправлять их в модель классификации, тогда как одноэтапные детекторы объектов, такие как YOLO [61], SSD [ 62] и RetinaNet [63] находят и классифицируют объекты за одну операцию, что обычно делает их быстрее, но менее точно. Как одноэтапные, так и двухэтапные детекторы объектов обычно полагаются на методы постобработки немаксимального подавления (NMS) для фильтрации перекрывающихся прогнозов и сохранения только наиболее подходящих ограничивающих рамок для данного объекта. В последнее время интерес вызывают детекторы объектов на основе трансформаторов, такие как детекторы-трансформаторы (DETR) [64]. DETR устраняют необходимость во многих компонентах, разработанных вручную (таких как NMS), при выполнении сквозного обнаружения, и в настоящее время предпринимаются усилия, чтобы сделать их пригодными для настроек в реальном времени [65].
Наиболее часто используемые метрики для оценки прогностической эффективности детекторов объектов рассмотрены Падилья и др. [66], а авторы приводят краткий обзор ниже. Ниже порогового значения точность положения прогнозируемой ограничивающей рамки определяется отношением области перекрытия к области объединения со значением GT, называемым соотношением пересечения к объединению (IoU).
Если , то прогноз считается верным. После установления критериев для определения правильности обнаружения можно получить точность и полноту модели, где TP, FP и FN представляют собой истинно положительные, ложноположительные и ложноотрицательные результаты соответственно. Средняя точность модели для класса на пороге интерполируется из площади под кривой точности отзыва (AUC). Общая точность модели, оцененная на наборе данных, содержащем классы, называется средней точностью и определяется как
Использование только одного порогового значения для сравнения модели может быть неудовлетворительным. Поэтому средняя точность обычно усредняется между десятью пороговыми значениями IoU (от 50% до 95% с шагом 5%), а полученная метрика называется просто mAP.
YOLOv7
YOLOv7 — новейший представитель серии одноступенчатых детекторов объектов реального времени YOLO. На момент выпуска в июле 2022 года он был самым быстрым и точным детектором объектов в диапазоне от 5 до 160 кадров в секунду, имел меньше параметров, чем модели с аналогичными характеристиками, и меньше параметров, чем до сих пор широко используемый YOLOv5 [67]. Качественный скачок. YOLOv7 обучается с нуля на наборе данных MS COCO [68] с использованием оптимизированных структур и методов, называемых обучаемым набором бесплатных подарков. Это включает в себя запланированные репараметризованные свертки, основанные на анализе путей градиентного потока, и новую стратегию присвоения меток, а также включение некоторых ранее существовавших концепций, таких как встраивание пакетной нормализованной статистики непосредственно в сверточные слои для вывода, неявное знание YOLOR [69] включено в сверточные слои. слои для сложения и умножения, а также использование модели экспоненциального скользящего среднего (EMA) в качестве окончательной модели вывода. Пакет бесплатных подарков увеличивает стоимость обучения и производительность прогнозирования модели без увеличения задержки во время вывода — концепция, которая обсуждалась в YOLOv4 [70]. YOLOv7 также представляет архитектурные улучшения, в том числе Extended-ELAN, улучшенный вариант Efficient Layer Aggregation Network (ELAN) [71], который может бесконечно штабелировать вычислительные блоки, сохраняя при этом возможности обучения, и новый композитный метод масштабирования для объединения моделей, который сохраняет свойства и оптимальная структура модели.
В более общем смысле, YOLOv7 представляет собой модель на основе опорных точек, использующую Feature Pyramid Network (FPN) [72]. Автор представляет YOLOv7-tiny и YOLOv7, модели P5, предназначенные для периферийных и обычных графических процессоров соответственно, и YOLOv7-W6, модель P6, предназначенную для облачных графических процессоров. Метод составного масштабирования применяется к YOLOv7 для получения YOLOv7-X и к YOLOv7-W6 для получения YOLOv7-E6, YOLOv7-D6, YOLOv7-E6E, где последний заменяет ELAN на Extended-ELAN в качестве основной вычислительной единицы. Рекомендуется, чтобы входное разрешение обучения для модели P5 было , а для модели P6 – . Изображения, вводимые в YOLOv7, изменяются до заданных входных размеров с сохранением соотношения сторон и при необходимости с применением отступов. Во время обучения потери рассчитываются путем суммирования трех подфункций, которые уравновешиваются заранее заданными гиперпараметрами усиления. Эти подфункции измеряют производительность модели в различных модальностях задачи обнаружения целей. В частности, потеря классификации и потеря объективности используют общую потерю двоичной перекрестной энтропии (BCE), в то время как подфункция потери регрессии ограничивающего прямоугольника основана на потере полного пересечения над объединением (CIoU) [73]. Все варианты YOLOv7 используют функцию активации SiLU (кроме YOLOv7-tiny, где используется LeakyReLU), стратегия SimOTA [74] в YOLOX представлена в назначении меток, мозаике, смешивании и улучшении переворота влево-вправо, накоплении градиента, автоматическом гибриде. точность Половинная точность во время обучения, вывода и NMS при постобработке.
В дополнение к обнаружению 2D-объектов YOLOv7 был расширен для поддержки оценки позы и сегментации экземпляров, а также предоставляет вариант точки без привязки YOLOv7-AF с базовой производительностью, сравнимой или превосходящей более поздние версии, включая YOLOv6 3.0 [75] и YOLOv8 [76] ]. YOLOv7 используется в качестве основы для YOLOv9 [77], который представляет программируемую градиентную информацию (PGI) и обобщенные эффективные сети агрегации слоев (GELAN).
III Related work
Ниже авторы кратко рассматривают предыдущую работу по применению федеративного обучения (FL) для обнаружения 2D-объектов в автономных транспортных средствах. Рджуб и др. [16] изучали объединенное обнаружение объектов в реальном времени, применяя оригинальную модель YOLO в сценариях вождения в суровых погодных условиях. Чен и др. [17] изучали FL при обнаружении целей транспортных средств с использованием модели SSD в условиях ограничений связи и вычислений. Боммель [18], а позже Рджуб и др. [19] использовали YOLOv5 и YOLOR соответственно для решения дилеммы разреженных аннотаций данных FL при обнаружении целей в режиме реального времени для автономных транспортных средств с помощью методов активного обучения. Дай и др. [20] предложили структуру FLAME для облегчения исследования онлайн-обнаружения объединенных объектов для непрерывной передачи данных автономными транспортными средствами, что они продемонстрировали с помощью YOLOv2 [78]. Ван и др. [21] разработали CarlaFLCAV, открытую платформу моделирования FL, которая поддерживает широкий спектр задач автомобильного зондирования, включая обнаружение целей с использованием YOLOv5, и решает проблемы оптимизации сетевых ресурсов и размещения дорожных датчиков. Чи и др. [22] использовали систему обнаружения объектов с полуконтролем учителя и проводили обучение FL на немаркированных данных, собранных во время вождения, с учетом небольшого количества тщательно отобранных существующих данных, используя Faster-R-CNN [79]. Рао и др. [23] предложили FedWeg, разреженный процесс обучения FL, который они оценили на YOLOv3 [80] для адаптации к вычислительным и коммуникационным ограничениям в Интернете транспортных средств. Су и др. [24] предложили FedOD, междоменную структуру pFL, основанную на дистилляции нескольких учителей для обнаружения объектов, и подтвердили свое предложение на наборе данных автономного вождения с использованием RetinaNet. Наконец, Ким и др. [25] предложили двухэтапную стратегию обучения под названием FedSTO и рассмотрели полуконтролируемое объединенное обнаружение целей в гетерогенных ситуациях. При использовании YOLOv5 локальный набор данных клиента транспортного средства полностью немаркируется, в то время как помеченные данные. Доступно только на центральном сервере.
Напротив, другие исследователи обратили свое внимание на мультимодальные данные. В частности, Чжэн и др. [26] предложили AutoFed, платформу FL специально для обнаружения транспортных средств с высоты птичьего полета, где неоднородность данных возникает из-за включения нескольких модальностей зондирования, и была обучена на нескольких устройствах NVIDIA Jetson TX2. Специальная двухэтапная система. Детектор объектов был разработан для соответствия данным лидара и радара. Мишра и др. [27] выступают за полностью децентрализованную систему автономного вождения FL на основе блокчейна, которая использует смарт-контракты, называемые в статье «роевым обучением», и проверили их на Complex-YOLOv4 [81] Предложение для обнаружения целей в 3D-облаке точек. Кроме того, Чи и др. [28] показали, что обнаружение объединенных 3D-объектов можно улучшить за счет включения инфраструктуры в процесс объединения кластеров, и включили в эксперименты сложную многоэтапную систему восприятия, в которой карты объектов, извлеченные из облаков точек, обрабатываются визуальный трансформер.
Наше предложение отличается от предыдущей работы тем, что мы фокусируемся на объединенной оптимизации новейших детекторов объектов в реальном времени и представляем всестороннюю оценку их производительности, позволяя при этом крупномасштабное моделирование в центрах обработки данных. Стратегия сегментации, подробно описанная авторами в разделе V.C, имеет особенности, отсутствующие в этих статьях. Авторы также представляют одну из немногих работ, в которой предусмотрена открытая реализация.
В двух статьях опробован YOLOv8 и представлен FedProx+LA, метод FL для решения проблемы неравномерного распределения меток в транспортных сетях, который показал улучшенную производительность и скорость сходимости при обнаружении целей [29], а также метод адаптивного кластерного FL, используемый для решения проблем хранения и пропускной способности. ограничений, что подтверждено для обнаружения транспортных средств в различных погодных условиях и условиях освещения [30]. Однако в этих работах рассматривалась только нано-версия YOLOv8, самая маленькая версия, которая предназначена для периферийных устройств и имеет ограниченные возможности обучения. Это еще раз подчеркивает необходимость обеспечения поддержки крупномасштабных экспериментов с ФЛ. Пожалуй, наиболее похожим на предложение автора является прототип, предложенный Джаллепалли и др. [31], который, насколько известно автору, является единственным вкладом в федеративную оптимизацию детекторов объектов для автономного вождения в среде HPC. Заменив YOLOv3 на YOLOv7, авторы обеспечивают более высокое разнообразие данных, больше клиентов, реалистичные настройки, отличные от IID, больше оптимизированных локальных и серверных конфигураций, а также измеряют стоимость связи нескольких вариантов модели и скорость вывода, что значительно улучшает предыдущие. работать путем замены низкоуровневой связи на основе сокетов с MPI и симметричной схемой шифрования Fernet более безопасной гибридной схемой шифрования.
IV System design
Несколько подключенных автономных транспортных средств собирают видеоданные в режиме реального времени с помощью бортовых камер, одновременно участвуя в объединенном обучении общей модели обнаружения объектов с использованием архитектуры YOLOv7. Сервер выступает в роли координатора системы FL, отвечая за сбор и агрегацию обновлений локальной модели, оптимизацию на стороне сервера и распространение параметров модели. Сервер имеет собственный тщательно отобранный репрезентативный набор данных, который используется для оценки качества глобальной модели в конце каждого раунда связи. В экспериментах авторов использовался оптимизатор сервера FedAvgM (4), хотя FedPylot также поддерживает FedAdagrad, FedAdam и FedYogi [40]. Чтобы более точно отразить состояние модели при развертывании, оценка выполняется на модели с измененными параметрами, которая имеет меньше параметров, но сохраняет те же прогнозные характеристики, что и базовая модель. Раунд связи состоит из фиксированного количества локальных эпох обучения, общих для всех клиентов, и общий размер пакета используется независимо от размера обучающего набора, поэтому шаги локальной оптимизации могут различаться между клиентами. Для простоты авторы предполагают полное участие клиента в каждом раунде, метки обучающих данных доступны на периферии, а агрегирование является синхронным.
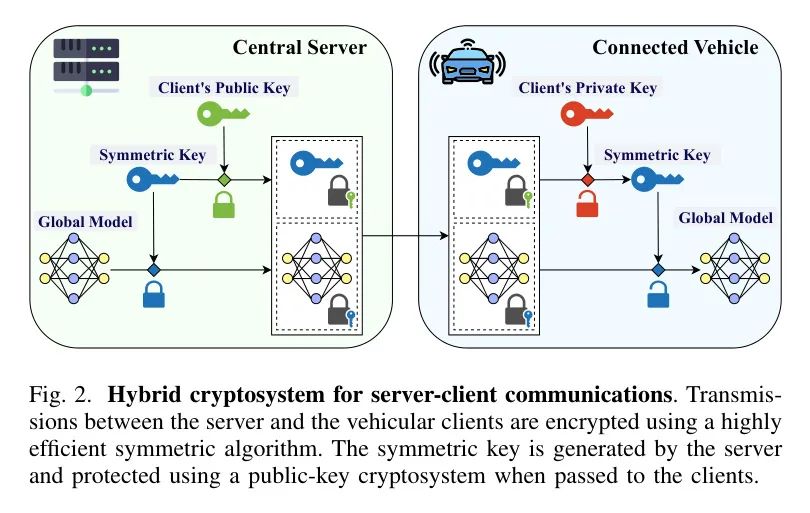
Связь между участниками защищена гибридной системой шифрования. Он состоит из комбинации высокоэффективного алгоритма симметричного шифрования для шифрования открытого текста, но требующего, чтобы отправитель и получатель имели один и тот же симметричный ключ, и более практичного, но на несколько порядков более дорогого алгоритма шифрования с открытым ключом, который симметричен только при передаче. Используется ключ. защитить его от атак противников. Авторы спроектировали систему так, что каждый клиент транспортного средства генерирует пару открытого и закрытого ключей в начале процесса объединения и немедленно отправляет свой открытый ключ на сервер. В то же время сервер генерирует новый симметричный ключ в начале каждого раунда и использует его для шифрования глобальной модели, а затем передает два ключа вместе клиенту (как показано на рисунке 2), или, если это считается разъединить Ключ и модель. Если практичнее поменяться, передайте их отдельно. Клиенты могут использовать этот же ключ для расшифровки глобальной модели и шифрования своих локальных обновлений. Гибридное шифрование простое и подходит для сред с ограниченной задержкой. На практике это требует лишь незначительных накладных расходов на связь, и, по мнению авторов, накладные расходы на шифрование преобладают над затратами на обучение модели. Однако это применимо только в том случае, если допустимо раскрытие обновлений модели на сервере. Если это условие не соблюдается, необходимо добавить передовые технологии конфиденциальности, такие как упомянутые в разделе 2 A3. Процесс объединения обобщен в алгоритме 1, а остальные детали представлены в следующем разделе.

V Experiments
Prototype implementation details
V-A1 Federated simulation
Шифрование V-A2
Гибридная система шифрования для защиты связи между участниками федеративного обучения реализована с использованием пакета шифрования Python. Схема инкапсуляции ключа основана на схемах заполнения RSA [86] и OAEP [87], тогда как для инкапсуляции данных используется 256-битный симметричный ключ с использованием алгоритма Advanced Encryption Standard (AES) [88] и режима Галуа/Счетчика ( GCM) [89] и scrypt как функцию получения ключа на основе пароля [90]. AES-GCM требует использования криптографического случайного числа при каждом новом шифровании для предотвращения атак повторного воспроизведения. В схеме автора 12-байтовое случайное число, используемое каждый раз при шифровании данных, и значение соли, используемое при создании нового симметричного ключа, генерируются с использованием пакета секретов Python, чтобы гарантировать использование криптостойких случайных чисел. Шифрование с использованием AES-GCM также создает 16-байтовый тег аутентификации, который можно безопасно передавать вместе с одноразовым номером и зашифрованным текстом, чтобы гарантировать целостность и подлинность сообщения.
Datasets
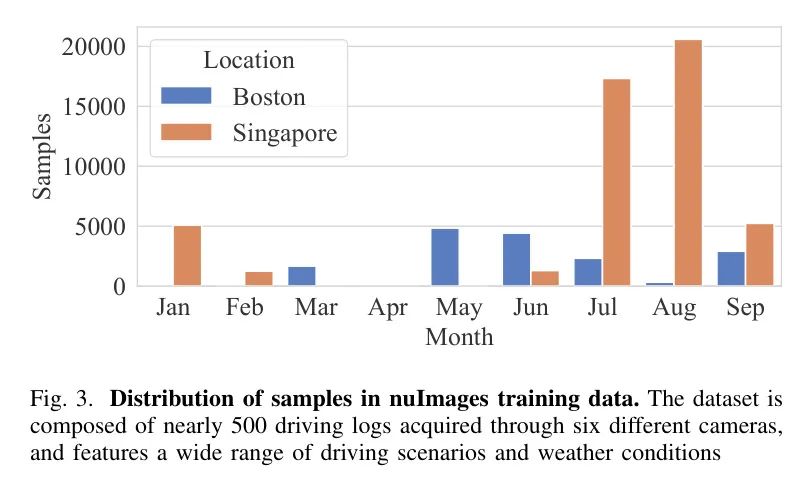
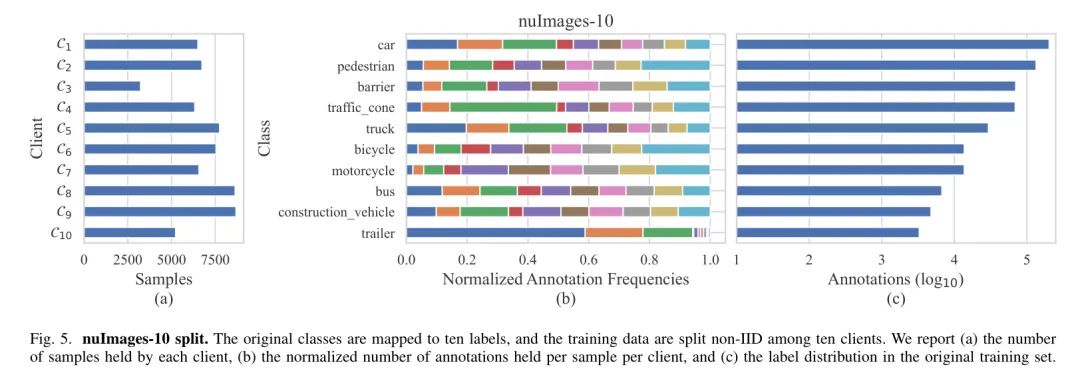
картина3:Пример распределения обучающих данных nuImages.Долженданные Джи Юджин500журнал вождения,Снято шестью разными камерами,Охватывает изображения широкого спектра сценариев вождения и погодных условий.,Размер всех образцов составляет . Данные собираются с помощью шести камер, которые обеспечивают 360-градусный обзор вокруг автомобиля.,Есть небольшое совпадение. Эти сцены были сняты с января по сентябрь в Бостоне и Сингапуре.,Как показано на рисунке 3.,Включает дождь, снег и ночные сцены.,Это делает nuImages значительно более разнообразным, чем KITTI. nuImages также включает 23 различные категории, распределенные по длинному хвосту. В авторском эксперименте,Авторы не рассматривали предопределенные немаркированные тестовые наборы KITTI и nuImages. В обоих случаях,Ограничивающая рамка представлена абсолютными координатами ее верхнего левого и нижнего правого углов.,Поэтому сначала нам нужно преобразовать аннотацию ограничивающей рамки в формат YOLO.,Ограничивающая рамка представлена нормализованными координатами центра, шириной и высотой рамки.
Авторы провели эксперименты на двух соответствующих наборах данных для автономного вождения: подмножестве обнаружения 2D-объектов набора тестов машинного зрения KITTI [91] и nuImages [92], расширенной версии nuScenes, предназначенной для обнаружения 2D-объектов. KITTI — это новаторский и до сих пор широко популярный тест, который обеспечивает синхронизацию стереоскопических изображений RGB, GPS-координат и облаков точек LiDAR, а также поддерживает обнаружение 2D- и 3D-объектов. Однако ему не хватает разнообразия данных о погоде и условиях освещения, местоположении и целевой ориентации. Подмножество обнаружения 2D-объектов KITTI не имеет ранее существовавшего разделения обучения/проверки и содержит 7481 аннотированное изображение, причем наиболее распространенным размером является (с некоторыми небольшими вариациями). KITTI содержит категорию _DonCare_, которая соответствует регионам с немаркированными целями и была исключена из экспериментов авторов, в результате чего в наборе данных осталось восемь категорий. nuImages содержит около 500 журналов поездок разной длины и организован в виде реляционной базы данных с 67 279 аннотированными тренировочными изображениями и независимым предопределенным набором проверки, содержащим 16 445 аннотированных изображений.
Стратегия разделения данных
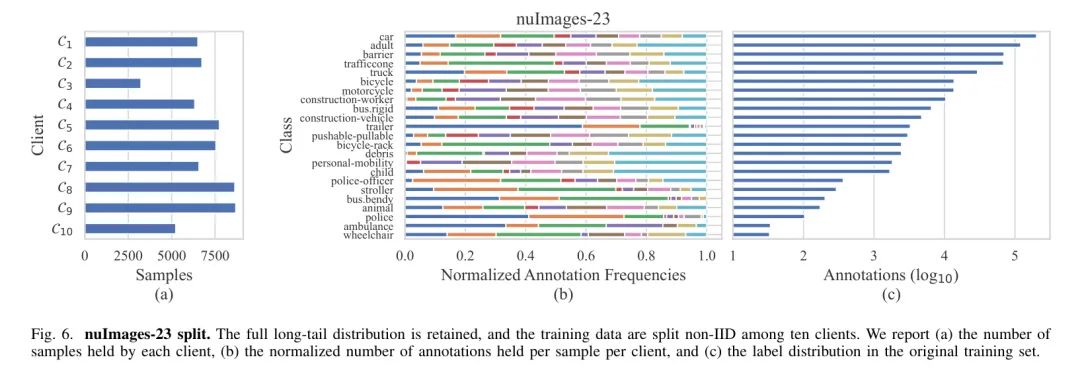
Поскольку KITTI представляет собой набор данных с низкой дисперсией, который не может легко выполнить естественное семантическое разделение данных, он используется в качестве настройки IID автора. Автор случайным образом выбрал 25% обучающих данных и сохранил их на центральном сервере, а остальные выборки были равномерно распределены между пятью клиентами, как показано на рисунке 4. Что касается nuImages, авторы полагались на пространственно-временные метаданные в обучающем наборе для создания разделов, отличных от IID, для создания дисбаланса, смещения понятий и искаженного распределения меток. Набор данных, хранящийся на сервере, представляет собой только данные проверки, предварительно определенные nuImages, а подразделение обучения устроено следующим образом. Клиент получает данные, собранные в Бостоне за три месяца (март и май, июнь, июль и сентябрь) соответственно, а клиент получает данные, собранные в Сингапуре, в январе и феврале. Данные Сингапура с июня по август, чрезмерно представленные в обучающем наборе, распределяются между клиентами до минимального порога неоднородности данных. Наконец, клиент получает данные за сентябрь по Сингапуру. Кроме того, автор реализовал два сопоставления категорий для nuImages, чтобы наблюдать влияние длинного распределения набора данных на объединенную оптимизацию. Результаты картирования, скопированные с конкурса nuScenes, авторы называют набором данных nuImages-10, в котором сохраняются только десять категорий, а базовый набор данных, содержащий все 23 категории, называется nuImages-23. Авторы отмечают, что описанная выше стратегия разделения естественным образом приводит к дисбалансу и неравномерному распределению меток, как показано на рисунках 5 и 6, причем последнее еще больше усугубляется, когда включено полное распределение с длинным хвостом. В частности, различия в распределении меток становятся очевидными только для редких классов между разными клиентами только благодаря навигационной последовательности, тем самым иллюстрируя, как авторское разделение отражает гетерогенность на разных уровнях детализации.
Design of experiments
В первой серии экспериментов авторы использовали FedAvg в качестве базовой линии. Локальные и серверные оптимизаторы являются SGD и имеют фиксированную скорость обучения 0,01 и 1 соответственно.
Второй метод федеративного обучения, FedOpt, фокусируется на оптимизации на стороне клиента. Оптимизатором на стороне сервера по-прежнему является SGD, но авторы адаптировали исходный процесс обучения YOLOv7 для соответствия федеративным настройкам и использования точно настроенных гиперпараметров по умолчанию. В частности, параметры модели разделены на три группы: смещение, параметры пакетной нормализации, а остальные параметры, к которым применяется снижение веса, выбираются в качестве немасштабированной константы регуляризации. Каждая группа принимает свою собственную стратегию планирования скорости обучения за один цикл, которая состоит из периода линейного прогрева, за которым следует отжиг по косинусному затуханию. Скорость обучения группы смещения изначально равна 0,1, а остальных двух групп равна 0. Все скорости обучения постепенно становятся 0,01 в период разминки и 0,001 в период спада. Для обеспечения синхронизации авторы зафиксировали для периода прогрева фиксированное количество эпох, общее для всех клиентов (30 и 15 для KITTI и nuImages соответственно). Кроме того, в FedOpt изначально применяется импульс Нестерова с начальным коэффициентом импульса 0,8, который линейно увеличивается до 0,937 во время разминки и после этого остается постоянным. Авторы решили не агрегировать локальный импульс, тем самым уменьшая накладные расходы на коммуникацию, но заставляя клиентов поддерживать постоянное состояние между эпохами обучения. Возможным улучшением FedPylot могла бы стать реализация дополнительного варианта импульса на уровне клиента без сохранения состояния для поддержки использования независимо от уровня участия. Во всех вышеперечисленных случаях автор использовал архитектуру YOLOv7 на основе исходной точки привязки, с весами в MS. Предварительное обучение на COCO, с использованием изменения размера почтового ящика 640, размера пакета 32, улучшения мозаики и горизонтального переворота, вероятности 1,0 и 0,5 соответственно, порог достоверности 0,001, порог IoU NMS на тестовых данных 0,65 и коэффициент усиления 0,05 соответственно. , 0,3 и 0,7 для регрессии ограничивающего прямоугольника, классификации и потери объективности. Там, где это применимо, авторы позволяют скорости обучения и факторам импульса варьироваться в зависимости от эпохи общения, чтобы учесть коммуникационные ограничения в IoV. Локальная модель EMA не имеет агрегирования, и политика планирования поддерживается локально. FedAvg и FedOpt сравнивались на протяжении 150 эпох обучения, а также эпох разной продолжительности, в то время как для FedOptM авторы специально сосредоточились на настройке 30 эпох, чтобы обеспечить больше шагов по оптимизации сервера. FL сравнивали с процессом централизации по умолчанию, где модель обучалась без изменений на всех данных в течение 150 эпох. Для простоты продолжительность разминки остается такой же, как и в эксперименте с объединением.
VI Results
Effects of client-side optimization
Эволюция потерь обучения и mAP для централизованного обучения, FedAvg и FedOpt показана на рисунке 7, и авторы сообщают о высочайшей точности тестирования, достигнутой для каждого параметра в таблице 1.
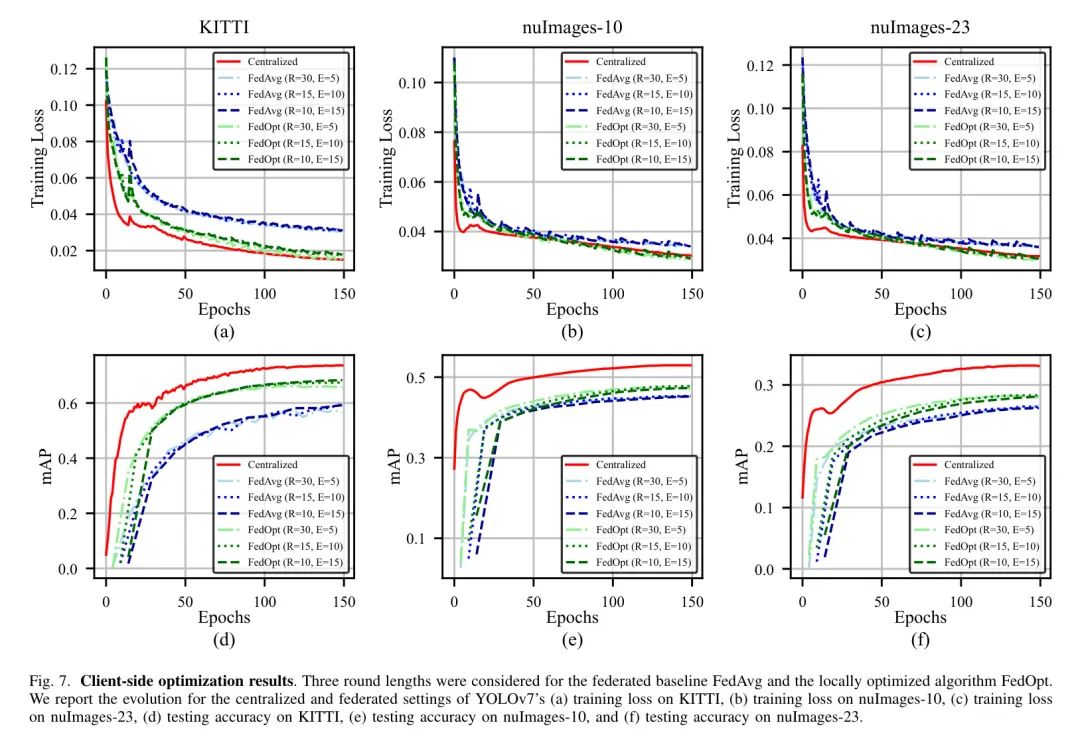
В федеративной настройке совокупные потери при обучении получаются из средневзвешенного значения локальных потерь, рассчитанных для каждого клиента в соответствии с уравнением (1), тогда как mAP получается путем запуска набора невидимых примеров, хранящихся на центральном сервере, после Алгоритм 1. Это измеряется путем оценки глобальной модели в конце каждого раунда связи. Схема расширенной локальной оптимизации обеспечивает последовательное повышение производительности на всех уровнях неоднородности, особенно в настройке независимого и идентично распределенного (IID), где улучшенные локальные обновления не компенсируются отклонением клиентов. Более длительные периоды обучения полезны для независимых и одинаково распределенных (IID) данных, но также не приводят к ухудшению качества в гетерогенных условиях, что объясняется выбором авторов стратегии разделения и использованием предварительно обученных весов. По сравнению с централизованной настройкой снижение производительности более выражено на nullmages-23, чем на nullmages-10, что подтверждает, что включение дистрибутивов с длинным хвостом отрицательно влияет на федеративную оптимизацию.
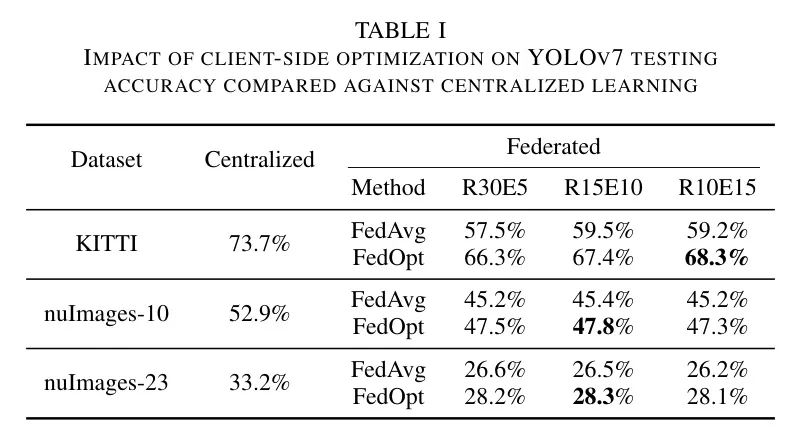
Ablation on server learning rate and momentum
Полная информация о поиске по сетке представлена на рисунке 8. Влияние FedOptM на скорость обучения и динамику серверной стороны на точность теста показано на рисунке 8. Авторы комментируют улучшение по сравнению с FedOpt для сопоставимого количества и длины раундов связи. Обучение на KITTI очень стабильно, оно выигрывает от более высокой скорости обучения на стороне сервера, а mAP достигает (+1,3%). Меньшие улучшения наблюдаются на нульмаге-10 (+0,1%), а вот на более разнородном нульмаге-23 (+0,3%) небольшие значения импульса приносят небольшие, но стабильные улучшения. Однако выбор высокого коэффициента импульса (например, 0,9) приводит к значительному увеличению количества обновлений, что существенно нарушает процесс обучения и приводит к неточным прогнозам на неравномерных данных. Качественное сравнение FedAvg и FedOptM показано на рисунке 9.

Communication costs and inference speed
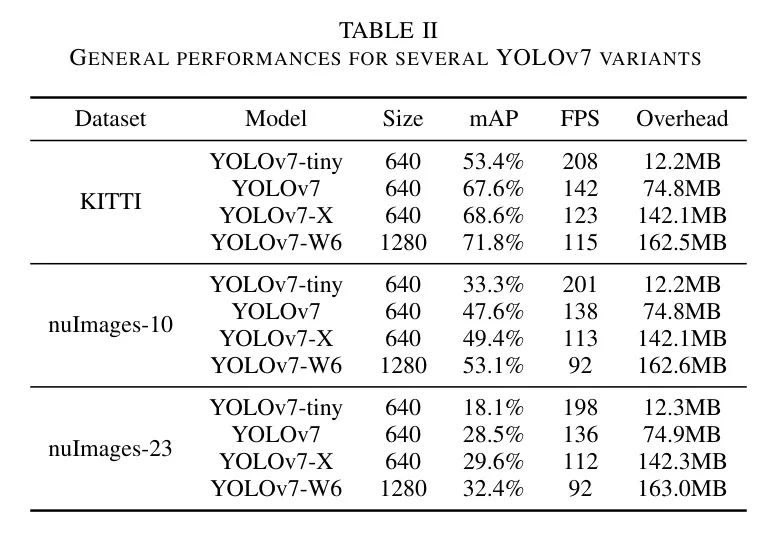
Авторы измерили точность тестирования и скорость вывода различных вариантов YOLOv7 в наборах данных KITTI, nulmages-10 и nulmages-23, а также накладные расходы, возникающие при взаимодействии сервер-клиент во время обучения. Авторы рассмотрели три модели P5 (YOLOv7-tiny, YOLOv7, YOLOv7-X) и базовую модель P6 (YOLOv7-W6) и представили свои результаты в Таблице 2. Используемый алгоритм интегрированного обучения — FedOptM, и авторы повторно использовали гиперпараметры сервера, которые обеспечили наилучшую производительность в экспериментах по абляции. Для YOLOv7-W6 размер почтового ящика увеличивается с 640 пикселей до 1280 пикселей, а размер обучающего пакета уменьшается с 32 до 8. Обучение длилось 30 раундов общения по 5 эпох каждый, при этом все остальные гиперпараметры оставались постоянными для всех вариантов модели. Для сравнения измерения задержки проводились в отдельной среде Colab, отдельно от обучения модели, а результаты для KITTI и nullmages были усреднены по 20 и 5 запускам соответственно. Как и в исходном тесте YOLOv7, авторы измеряли задержку при размере пакета 1 кадр/с на V100 после повторной параметризации и отслеживания модели, но без преобразования модели в ONNX или TensorRT. Учитывается только вывод модели, поэтому затраты на предварительную и постобработку (включая NMS) не учитываются. Затраты на связь указываются в мегабайтах, при этом изучаемые параметры симметричного шифрования между сервером и клиентом передаются точно, при этом количество передач в два раза больше, чем у участвующих клиентов в раунде. Стоимость первой трансляции модели с полным набором предварительно обученных весов немного выше стоимости, указанной в таблице. Использование половинной точности при передаче модели снижает накладные расходы на связь и легко реализуется, а реализацию более продвинутых методов сжатия модели авторы оставляют на будущее.
VII Conclusion
Это демонстрирует потенциал интегрированного обучения, позволяющий обнаруживать объекты и удовлетворять потребности автономных транспортных средств в обработке данных в режиме реального времени.
Выводы авторов подчеркивают надежность федеративной оптимизации YOLOv7 в условиях реалистичных ограничений гетерогенности, и авторы надеются, что FedPylot сможет привлечь дальнейшие исследования и внедрить современное обнаружение объектов в область федеративного обучения.
Некоторые возможные будущие улучшения, которые авторы рассматривают для FedPylot, включают поддержку дополнительных детекторов объектов, возможности мультимодального восприятия, расширенные методы конфиденциальности, асинхронные конфигурации и конфигурации с низким уровнем участия, а также персонализацию модели.
В этом исследовании авторы выступают за использование федеративного обучения для решения проблем конфиденциальности и масштабируемости, присущих Интернету вещей. Авторы предлагают FedPylot, прототип клиент-сервера на основе MPI, который использует гибридное шифрование для моделирования федеративного обучения современных детекторов объектов в системах HPC.
ссылка
[1].FedPylot: Navigating Federated Learning for Real-Time Object Detection in Internet of Vehicles.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
