Эта статья познакомит вас с прошлым и настоящим тонкой настройки больших моделей.
Предисловие

Серия статей о технологиях оперативного проектирования была обновлена до семи глав, охватывающих различные сценарии использования в экосистеме разработки ИИ и предоставляющих достаточно практичные методы оперативного проектирования. Теперь, когда вызовы больших моделей становятся все проще и проще, стоимость токенов также значительно снизилась, и разработчики ИИ могут легко выполнять инкапсуляцию API и вторичную разработку. Некоторые платформы даже поддерживают тонкую настройку индивидуальных сценариев, что способствует процветанию модели «ИИ+» на рынке.
Эта серия статей откроет колонку «Точная настройка больших моделей». В первой статье мы начнем с основных концепций, объясним эволюцию и развитие технологии точной настройки больших моделей в простой для понимания форме. и помогите всем понять тонкую настройку с помощью простых примеров кода и основных концепций и методов. Я надеюсь, что с помощью этой статьи читатели смогут освоить весь процесс тонкой настройки больших моделей от нуля до его освоения, легко приступить к работе и не испытывать давления на реальной практике.
Если вы считаете, что этот контент полезен для вас, поддержите и обратите внимание. Ваша поддержка будет моей мотивацией продолжать творить. Спасибо всем за вашу поддержку!
1. Основные понятия больших моделей

1.1 Что такое большая модель?
Некоторые читатели уже имеют общее представление о больших моделях, но они часто читают и узнают что-то новое. Давайте рассмотрим основные концепции больших моделей. Большие модели, как следует из названия, — это модели машинного обучения огромных размеров. Вы можете себе представить, что это что-то вроде сверхмощного «мозга» с миллиардами или даже десятками миллиардов «нейронов» (то есть параметров модели). Эти «мозги» могут обрабатывать самую разнообразную информацию, понимать сложные языки, распознавать объекты на изображениях и даже генерировать нужный вам текст.
Например,что мы часто слышимGPT(напримерGPT-3)иBERT,Это типичная большая модель. Эти модели обучаются на больших объемах данных.,Получил «общие» знания,Затемпроходитьтонкая настройка,Может быстро адаптироваться к различным специфическим задачам. например,Вы просите BERT провести анализ настроений,Он может определить, является ли статья положительной или отрицательной, если вы позволите GPT написать ее;,Он может продолжать писать с того начала, которое вы ему дали.,Даже генерирует очень плавный контент. Основные особенности больших моделей,Это их огромный размер,Они могут «работать через границы» между различными задачами.,Он просто универсальный «универсал».
1.2 Преимущества и проблемы больших моделей

Преимущества: Почему большие модели так популярны?
1.Супер способность к обучению: Самым большим преимуществом больших моделей является то, что они могут получить очень подробные знания из огромных объемов данных. Подобно эксперту, прочитавшему бесчисленное количество книг, он может понять проблему через богатый контекст. Например, такие модели, как GPT, «видят» огромные объемы текстовых данных, поэтому они обладают очень сильными возможностями в понимании и генерации языка. Хотите ли вы написать статью, сделать перевод или создать креативный рекламный текст, он с легкостью сделает это.
2.Одна модель для решения нескольких задач: Кажется, что большая модель может объяснить все. Его можно использовать для решения множества различных задач, будь то классификация текста, анализ настроений, машинный перевод или создание диалогов. Вам необходимо лишь предоставить ему небольшой объем данных о целевых задачах и после небольшой «тонкой настройки» вы сможете использовать его для решения конкретных практических задач.
3.Возможность миграции между доменами.: Большие модели могут не только хорошо справляться с одной задачей, но и быстро адаптироваться к задачам в других областях посредством «переноса обучения». Например, BERT изначально был разработан для задач понимания языка, но благодаря тонкой настройке он также может решать такие задачи, как анализ документов в медицинской сфере и анализ юридических документов.
4.Уменьшите зависимость от аннотированных данных: Как правило, машинное обучение требует большого количества размеченных данных, а этап предварительного обучения больших моделей позволяет им уже обладать очень сильными «врожденными знаниями». Поэтому, когда мы их настраиваем, требуемые данные аннотаций относительно невелики, и мы можем добиться хороших результатов даже на небольших наборах данных.
Задача: даже большие модели не идеальны
Огромные накладные расходы на вычисления и хранение: Хотя большие модели очень мощные, они также «требуют ресурсов». Обучение этих моделей требует большой вычислительной мощности, часто требующей сверхмощных серверов GPU или TPU. Без адекватной аппаратной поддержки обучение этих моделей может оказаться очень дорогостоящим. Представьте себе, что каждый раз, когда вы тренируете большую модель, счета за электроэнергию растут как взрыв, а стоимость оборудования достигает астрономических размеров.
Риск переобучения: Хотя большие модели являются мощными, они могут легко впасть в «переоснащение», если данные недостаточно велики или недостаточно хороши. Другими словами, если данные обучения, которые мы им предоставляем, недостаточно репрезентативны, модель может запомнить шум в данных вместо изучения полезных закономерностей. Это похоже на студента, который просто запоминает учебник, не понимая концепций, и «застревает», сталкиваясь с новыми вопросами на экзамене.
Ограниченные сценарии применения: Хотя большие модели хорошо справляются со многими задачами, они не все. В некоторых сценариях, которые предъявляют строгие требования к вычислительным ресурсам, таких как приложения реагирования в реальном времени, большие объемы логических выводов на стороне устройства и т. д., большие модели кажутся «подавляющими». В настоящее время нам, возможно, придется подумать о том, как сжимать или оптимизировать большие модели, обеспечивая при этом производительность.
Проблема «черного ящика» моделей: Хотя большие модели могут предоставлять мощные возможности прогнозирования и генерации, они часто подобны «черному ящику», и нам трудно четко понять, как они приходят к определенному выводу. В некоторых областях, требующих высокой интерпретируемости, таких как здравоохранение, финансы и т. д., вопрос интерпретируемости модели особенно важен. Представьте, что вы хотите использовать ИИ для постановки медицинского диагноза. Если врач не может понять процесс принятия решений с помощью ИИ, он может чувствовать себя неловко.
2. Концепция тонкой настройки
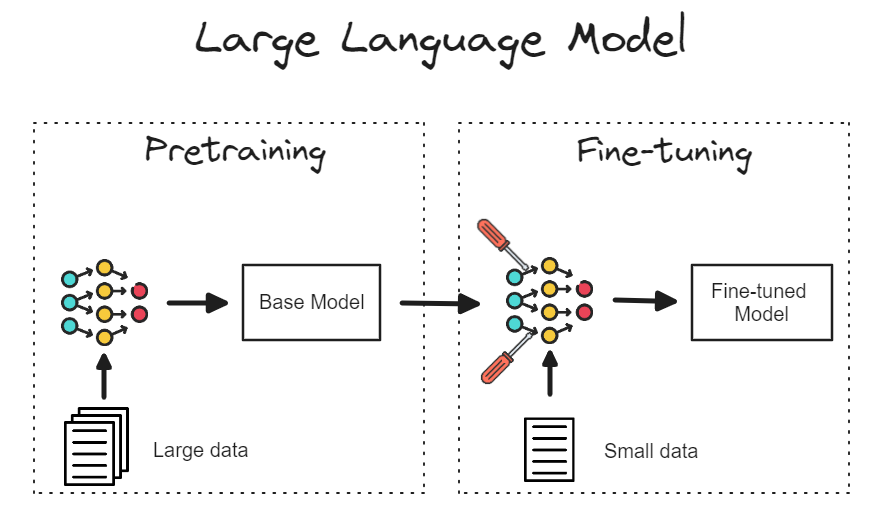
2.1 Концепция тонкой настройки
Можно поставить "тонкая настройка”Думайте об этом как о добавлении чего-то к и без того мощному инструменту.“точная регулировка”,Сделайте его более подходящим для текущей рабочей задачи. Проще говоря,тонкая настройкаТо есть в модели, обученной в больших масштабах.(напримерBERT、GPTждать)по сути,Повторное обучение с использованием относительно небольших объемов данных,Сделайте так, чтобы эта модель лучше справлялась с конкретной задачей.
Например, предположим, что у вас есть очень умный помощник (например, GPT-4o), который много знает по многим темам, но может быть не очень хорош в ваших отраслевых знаниях. Например, он понадобится вам для анализа медицинского текста. Чтобы он лучше понимал терминологию и знания в области медицины, вы предоставляете ему несколько медицинских текстов для доработки, чтобы он мог давать более точные ответы в медицинских сценариях.
Проще говоря, точная настройка похожа на то, чтобы большую модель «специализировать» на определенной области или задаче, а не «охватывать все». Это может помочь модели перейти от общей «энциклопедии» к «эксперту» по конкретной задаче.
2.2 Зачем нужна тонкая настройка
Предположим, вы хотите обучить большую модель с нуля, для чего требуется огромное количество данных и вычислительных ресурсов. Процесс долгий и очень дорогой. Вместо того, чтобы делать это, лучше напрямую использовать уже обученную модель (например, BERT, GPT-4 и т. д.), а затем «настроить» ее в соответствии с вашими потребностями для достижения хороших результатов. Таким образом, вы не только сэкономите время и затраты на масштабное обучение, но и получите хорошие результаты за короткое время.
Хотя на этапе предварительного обучения большие модели усвоили много «общих» знаний, каждая задача имеет свои уникальные требования. Например, анализ настроений, генерация текста, системы ответов на вопросы и т. д., хотя все они представляют собой задачи обработки естественного языка, фокус и метод обработки каждой задачи различны. Благодаря тонкой настройке мы можем заставить большие модели более точно выполнять конкретные задачи, точно так же, как настраиваемые инструменты для лучшего удовлетворения реальных потребностей. Хотя предварительно обученная модель хорошо справляется с большинством задач, она может быть не самой лучшей во всех сценариях. Благодаря тонкой настройке мы можем обучаться на данных конкретных задач и дополнительно оптимизировать производительность модели для достижения более высокой точности в конкретной области или задаче.
Если вы обучаете модель непосредственно с нуля, вам обычно требуется много помеченных данных. Преимущество точной настройки состоит в том, что она позволяет добиться лучших результатов при очень небольшом количестве размеченных данных. Это связано с тем, что большая модель уже усвоила большой объем общих знаний во время предварительного обучения, поэтому для точной настройки, чтобы она хорошо работала при выполнении конкретной задачи, ей требуется лишь небольшой объем данных, связанных с задачей. Точная настройка также может сделать модели «персонализированными». Например, система ответов на вопросы в коммерческой сфере и система ответов на вопросы в медицинской сфере требуют совершенно разных знаний. Благодаря тонкой настройке мы можем заставить одну и ту же большую модель хорошо работать в обеих областях, но выдавать разные ответы в соответствии с разными потребностями, достигая «индивидуальных» результатов.
3. Процесс разработки и доводки больших моделей.
Ранняя стадия: традиционное обучение модели
представлять себе,Ранние модели машинного обучения были похожи на произведения искусства, вырезанные вручную.——Каждая деталь требует тщательной резьбы.。с самого началалинейная регрессия、дерево решенийприезжатьМашина опорных векторов (SVM)ждать,Хотя эти модели работают хорошо,Но большинство из них требуют от нас подготовки больших объемов конкретных данных для каждой задачи. Эти модели часто медленно обучаются.,И каждый раз, когда проблема решается,Часто приходится начинать с нуля,Не легко переносится на другие задачи. О реализации кода,Традиционные методы обучения кажутся очень простыми: вы определяете сеть с нуля.,Сбор данных,Вручнуюразработка функций(То есть какие функции выбраны для обучения),Затем оптимизируйте его итеративно,Постепенно корректируйте вес сети. Ниже приведен простой традиционный код обучения нейронной сети:
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# Загрузить набор данных
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=42)
# Создайте простую модель нейронной сети
model = MLPClassifier(hidden_layer_sizes=(50,), max_iter=1000)
# Модель обучения
model.fit(X_train, y_train)
# Точность тестовой модели
accuracy = model.score(X_test, y_test)
print(f"Точность модели: {accuracy:.4f}")
на этом этапе,разработка функцийзанимать центральное положение。То есть,Качество вашей модели во многом зависит от вашего выбора и конструктивных особенностей. Вам придется вручную «сообщить» машине, какие функции вы считаете важными.,Это все равно, что надеть на него пару «очков».,Пусть это будет видно яснее. Этот процесс очень трудоемкий,И часто легко пропустить важную информацию из-за ограниченности человеческих знаний.
Расцвет глубокого обучения
Затем,Вошел вглубокое обучениеэпоха,Модели начинают становиться сложнее и умнее. Появление глубоких нейронных сетей (DNN) и сверточных нейронных сетей (CNN),Позвольте машинному обучению преодолеть множество ограничений. Особенно в области распознавания изображений, распознавания речи и других областях.,глубокое обучение блеск,Точность также значительно повышается. Хотя эти модели работают лучше, чем традиционные методы.,Но их обучение все равно придется начинать с нуля.,То есть каждое обучение должно полностью опираться на большой объем обучающих данных.
ноглубокое обучение Здесь также есть свои узкие места——Требуются большие объемы данных и вычислительная мощность.。несмотря на это,Прорыв на этом этапе заложил основу для более поздней большой модели тонкой настройки. Нейронные сети имеют все больше и больше слоев,Модели становятся больше,Наборы данных также становятся больше,«Обучаемость» моделей машинного обучения совершила качественный скачок. Например,我们可к看приезжать一个基于PyTorchизCNNМодельное обучениекод,Это сложнее, чем код традиционных нейронных сетей.,Но все равно обучение с нуля:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# Загрузка и предварительная обработка данных
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
# Определите модель CNN
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(32*28*28, 10)
def forward(self, x):
x = self.conv1(x)
x = x.view(-1, 32*28*28)
x = self.fc1(x)
return x
# Создание экземпляра модели и обучение
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Модель обучения
for epoch in range(5): # 5 раундов обучения
for inputs, labels in trainloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
Предложение парадигмы предварительной подготовки и тонкой настройки
Затем,2018 год,我们迎来了一个革命性из概念——предварительная подготовка-тонкая настройка(Pretrain-Finetune)范式из提出。кBERTиGPT为代表из Предварительно обученная модель, полностью изменил способ обучения модели. На этом этапе разработчикам уже не нужно начинать обучение с нуля, а на основе «универсальной модели», обученной на больших данных. настройка。
Проще говоря, режим предварительной тренировки и точной настройки снимает ограничения традиционного обучения модели с нуля. Его основная идея заключается в следующем: сначала использовать большой объем общих данных для «предварительного обучения» модели, чтобы она могла изучить некоторые общие знания (например, синтаксис и семантику языковой модели), а затем «точно настроить» ее; по конкретным задачам. Этот метод позволяет нам не начинать обучение каждый раз с нуля, а использовать изученные «общие знания» для выполнения конкретных задач лишь с небольшим количеством размеченных данных.
Приведите пример,Вы можете попросить BERT сначала использовать массивные текстовые данные, чтобы изучить основные правила языка.,再让它根据少量из情感分析数据руководитьтонкая настройки, может быть немедленно использован для задач классификации настроений. Этот метод значительно повышает эффективность обучения модели, а также позволяет быстро применять крупномасштабные Предварительно обученная модель。这时изкод开始有了巨大из变化,Предварительно обученная модельбыл загружен,руководитьтонкая настройка (тонкая настройка) под конкретную задачу. Например, тонкая Метод настройки BERT для классификации текста заключается в следующем:
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
# Загрузите предварительно обученную модель BERT и токенизатор.
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Подготовьте набор данных (при условии, что необходимая предварительная обработка текста выполнена)
train_texts = ["I love this!", "I hate this!"]
train_labels = [1, 0]
# Кодируйте данные
encodings = tokenizer(train_texts, truncation=True, padding=True, max_length=512)
train_dataset = torch.utils.data.TensorDataset(torch.tensor(encodings['input_ids']), torch.tensor(train_labels))
# Определить параметры обучения
training_args = TrainingArguments(output_dir='./results', num_train_epochs=3, per_device_train_batch_size=8)
# Использование трейнера для тонкая настройка
trainer = Trainer(model=model, args=training_args, train_dataset=train_dataset)
trainer.train()
这种предварительная подготовка+тонкая настройкаиз方式极大地简化了开发流程。你不再需要自己从零开始训练一个庞大из模型,Просто сделайте это на «базовой модели», о которой у вас уже есть много знаний., адаптируйте под свои задачи. Появление этого подхода ознаменовало появление крупных моделей тонкая В новую эпоху настройки эффективность обучения повысилась как никогда раньше.
точно настроенная эволюция
С ростом популярности крупных моделей технология тонкой настройки постоянно развивается и оптимизируется. Изначально тонкая настройка просто обучала модель в течение нескольких раундов, а затем применяла ее к конкретным задачам, но с развитием технологий методы тонкой настройки становились все более разнообразными.
Стратегии замораживания и оттаивания: Сначала Тонкий процесс настройки часто включает в себя обучение всей модели.,Но позже я узнал,Заморозить определенные слои модели,Обучайте только части высокого уровня,Это может повысить эффективность тренировок и снизить риск переобучения. например,Мы можем заморозить нижний уровень BERT (общее знание языка, которое было изучено).,Толькотонкая настройка верхнего слоя для адаптации под конкретные задачи.
# Заморозьте первые несколько слоев модели BERT.
for param in model.bert.parameters():
param.requires_grad = FalseРегулировка скорости обучения: Начальный этап настройка通常采用固定из学习率,И по мере накопления опыта,Планирование скорости обучениясталтонкая Важная технология в настройке. Динамически регулируя скорость обучения (например, сначала увеличивая, а затем уменьшая), мы можем В процессе настройки предотвращается пропуск модели оптимального решения, а также повышается стабильность и точность модели.
многозадачное обучение: современныйтонкая настройкаиз一个重要趋势是многозадачное обучение。проходить让一个模型同时学习多个任务,Он может делиться знаниями между задачами,Дальнейшее улучшение способности модели к обобщению. например,BERT тренирует несколько языковых задач одновременно во время предварительного обучения.,Может помочь модели лучше понять различные типы входных данных.
Инкрементная тонкая настройка: С углублением применения больших моделей методы тонкой настройки становятся более гибкими. В настоящее время многие приложения требуют, чтобы модели постоянно «постепенно обучались» в сценариях реального времени. Иными словами, модели представляют собой не просто однократную точную настройку для статических данных, но требуют постоянной корректировки и оптимизации при поступлении новых данных. Этот подход позволяет крупным моделям поддерживать возможности непрерывного обучения.
С помощью примеров кода мы можем не только увидеть теоретическую разработку точной настройки больших моделей, но также увидеть, как технологический прогресс постепенно изменил реальный процесс разработки. От первоначального ручного обучения до введения предварительного обучения и тонкой настройки и современных более совершенных стратегий тонкой настройки — весь процесс позволяет разработчикам машинного обучения создавать все более и более мощный интеллект за более короткий период времени.
Если есть какие-либо ошибки, пожалуйста, оставьте сообщение для консультации. Большое спасибо.
Это все по этому вопросу. Меня зовут фанат. Если у вас есть вопросы, смело оставляйте сообщение для обсуждения. Увидимся в следующем выпуске масштабной доработки модели.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
