Elasticsearch и OpenSearch: подробное сравнение различий в производительности
Исходный текст: https://www.elastic.co/blog/elasticsearch-opensearch- Performance-gap.
В ролях: Джордж Кобар, Уго Санджорджи

Для любой организации, которая полагается на быстрые и точные данные,Мощный, быстрый и эффективный двигатель является жизненно важным элементом. Для разработчиков и архитекторов,Выбор правильной платформы поиска может существенно повлиять на способность вашей организации быстро и актуально доставлять информацию. В нашем комплексном тестировании производительности,Elasticsearch Будьте мудрым выбором. Эластичный поиск Сравнивать OpenSearch быстрый40%-140%,В то же времяиспользование имеет меньше вычислительных ресурсов.
В этой статье мы рассмотрим шесть основных направлений. Elasticsearch и OpenSearch руководитьпроизводительность Сравниватьсравнивать:текстовый запрос、сортировать、Гистограмма даты、Объем Терминальный запроса также Использование ресурсы. Наша цель — предоставить объективную и практическую техническую информацию, которая поможет вам принимать обоснованные решения независимо от того, оптимизируете ли вы существующую систему или разрабатываете новую. Это сравнение С-преобразования также направлено на то, чтобы четко выделить Elasticsearch и OpenSearch Разница в производительности между ними показывает, что они совершенно разные.
Сначала мы проверим производительность Сравнивать результаты, а затем приступим к нашей тестовой среде «Метод испытаний».
результат
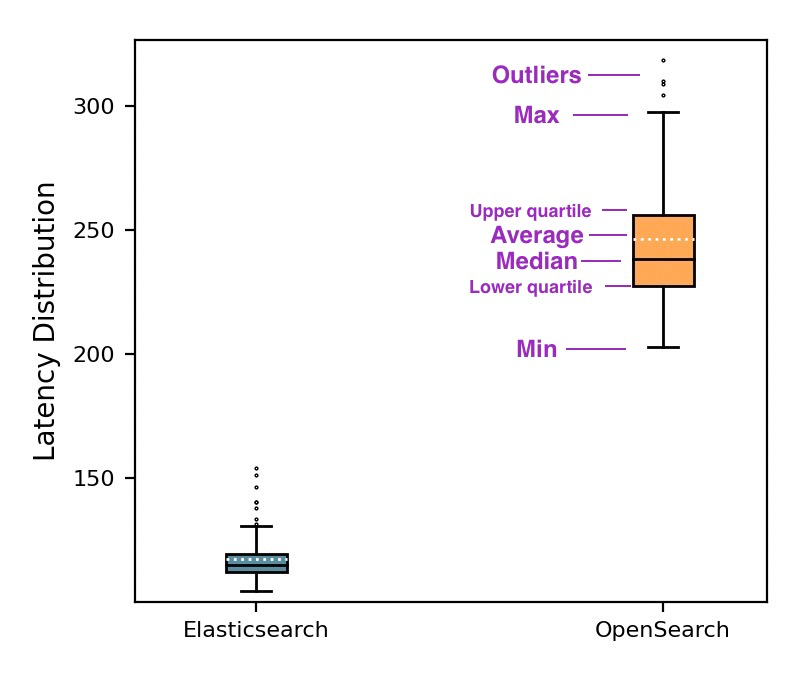
использовать t Проверьте производительность Сравниватьсравниватьрезультат(фокуссосредоточиться по запросу из р90 (нет. 90 индивидуальный процентиль)) перекрестная проверка, чтобы убедиться в наличии статистической разницы в измерениях задержки между двумя решениями. Относительное изменение (выраженное в процентах С сравнения) рассчитывается для каждого типа запроса. Мы также используем коробчатую диаграмму, показывающую 100% Запрос распределения задержки, коробчатая диаграмма, показывающая минимум, максимум, медиану, среднее значение и выбросы. В поле «Фактическое значение» показаны нижний и верхний квартиль соответственно. 25% и 75% наблюдений попадают в него. Таким образом мы можем получить представление о фактическом распределении этих значений.
Текстовые запросы — на 76% быстрее
“Искать всеВключать jane@doe.com данные. "
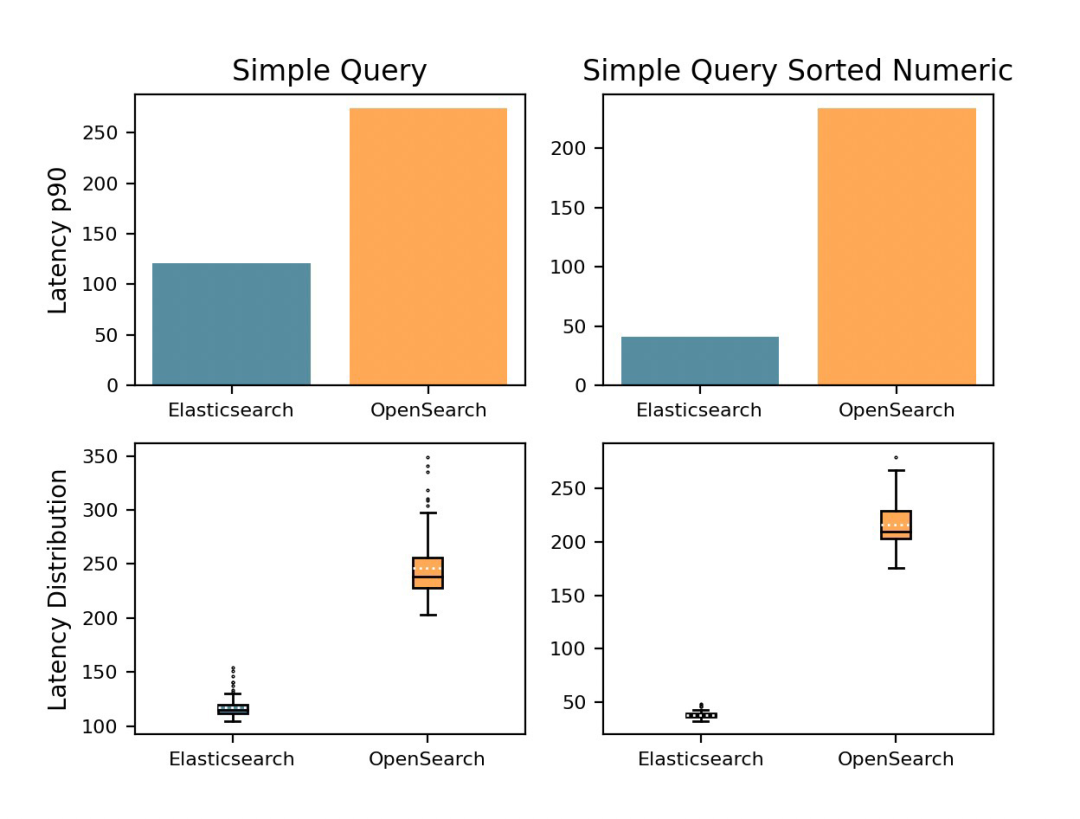
Elasticsearch Продемонстрирован значительный отрывок, исполненный текстовый запросизскорость Сравнивать OpenSearch быстрый 76% 。
текстовый запрос полнотекстового поиска, базового и ключевого, а полнотекстового поиска Elasticsearch из Основные функции. Запросы текстовых полей позволяют пользователям запрашивать текстовые данные для определенных фраз, отдельных слов или даже части слова. Пользователи могут выполнять сложные задачи с текстовыми данными — это улучшает общий пользовательский опыт и поддерживает широкий спектр приложений и решений.
сортировать
«Какой товар самый дорогой?»
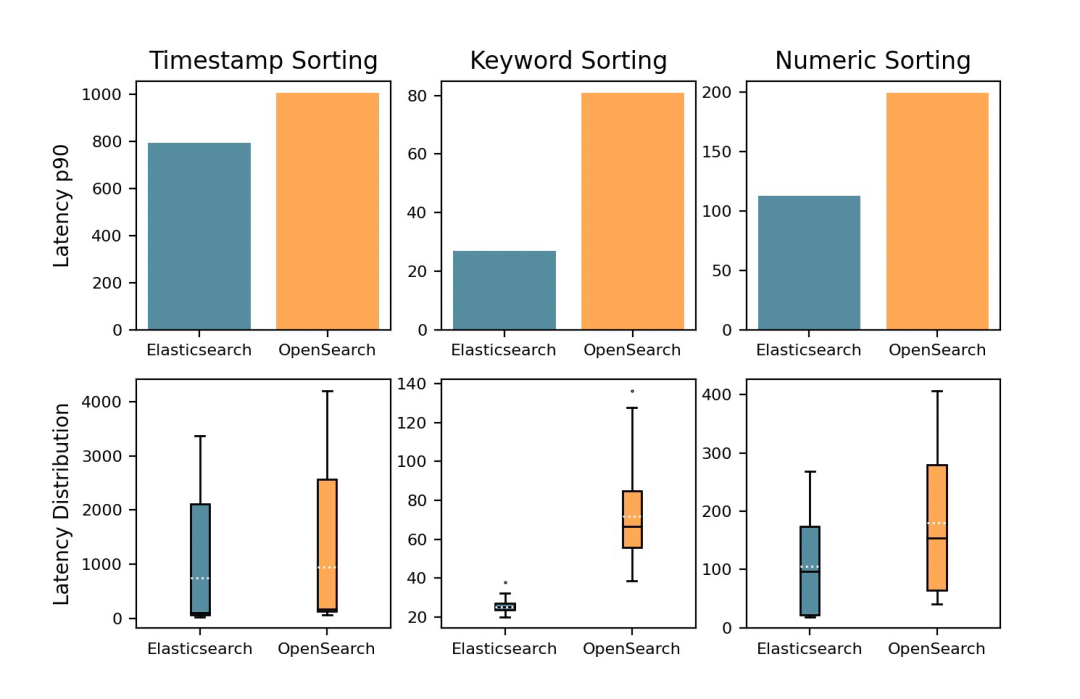
В паре простой текстовый запросрезультатруководитьсортироватьчас,Elasticsearch изпроизводительность Сравнивать OpenSearch Удивительно выше 140%. Кроме того, Elasticsearch из метки времени, ключевого слова и номера сортировки запроса по времени выполнения добавляются быстрее соответственно. 24%、97% и 53%。
Сортировать Да Процесс упорядочения данных в определенном порядке (например, в алфавитном, числовом или хронологическом порядке). Сортировать полезно для поиска результатов на основе определенных критериев, гарантируя, что вашим клиентам будет представлен наиболее подходящий изрезультат. Это расширяет возможности пользователя и повышает общую эффективность поиска важных функций.
Гистограмма даты
“Показать одининдивидуальныйв соответствии счасмеждусортироватьиз Все данныеизгистограмма”
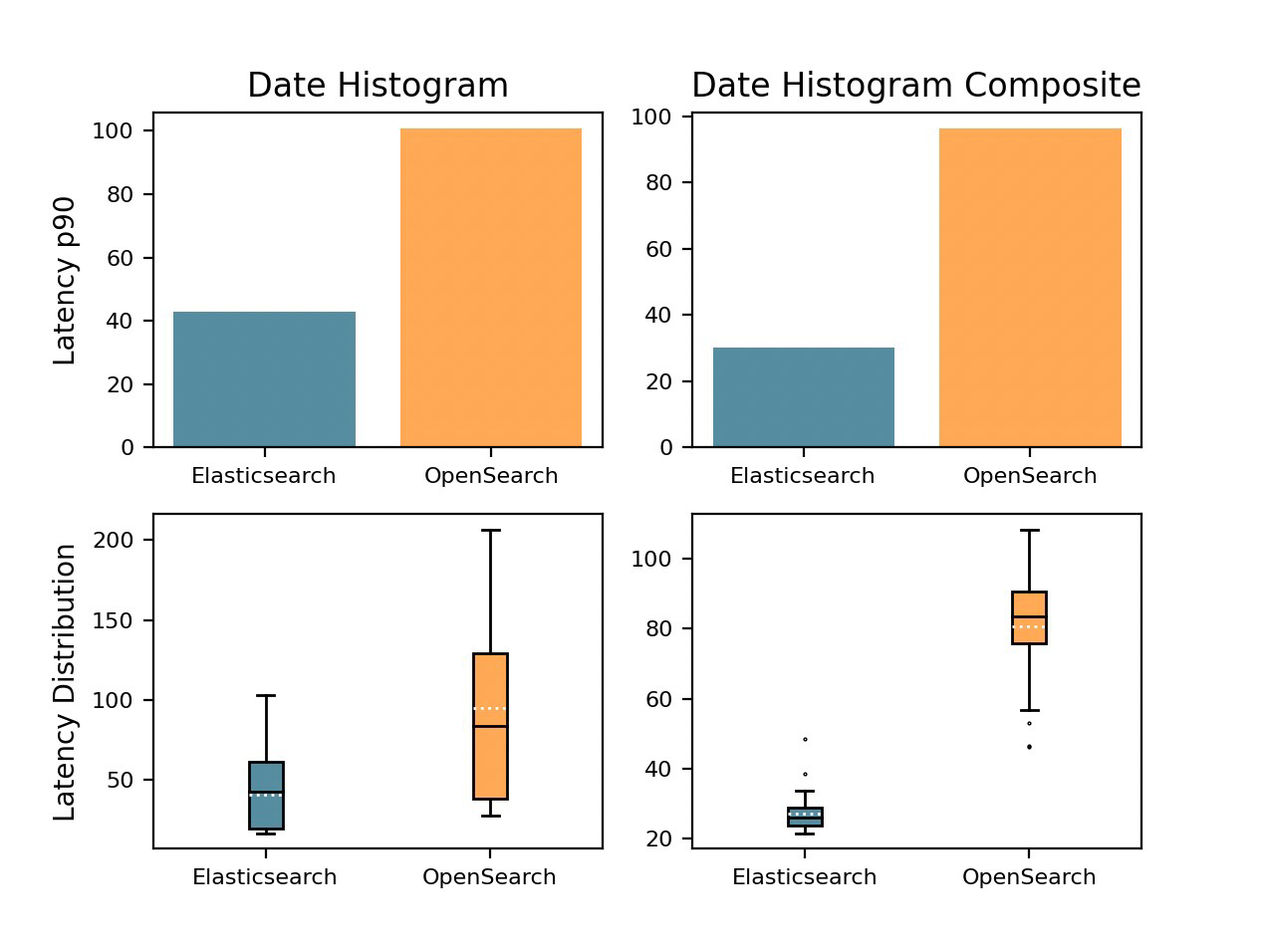
Для гистограммы агрегирование дат, Elasticsearch Сравнивать OpenSearch быстрый 81%, продемонстрировав свои мощные возможности. Ускорение времени обработки облегчает создание упорядоченных гистограмм на основе данных временных рядов.
Гистограмма дат Агрегация может использоваться для агрегирования и анализа данных путем разделения данных временных рядов на интервалы или сегменты. Эта функция позволяет пользователям визуализировать и лучше понимать тенденции, закономерности и аномалии с течением времени.
запрос диапазона
“Показать цену на0-25междуизпродукт”
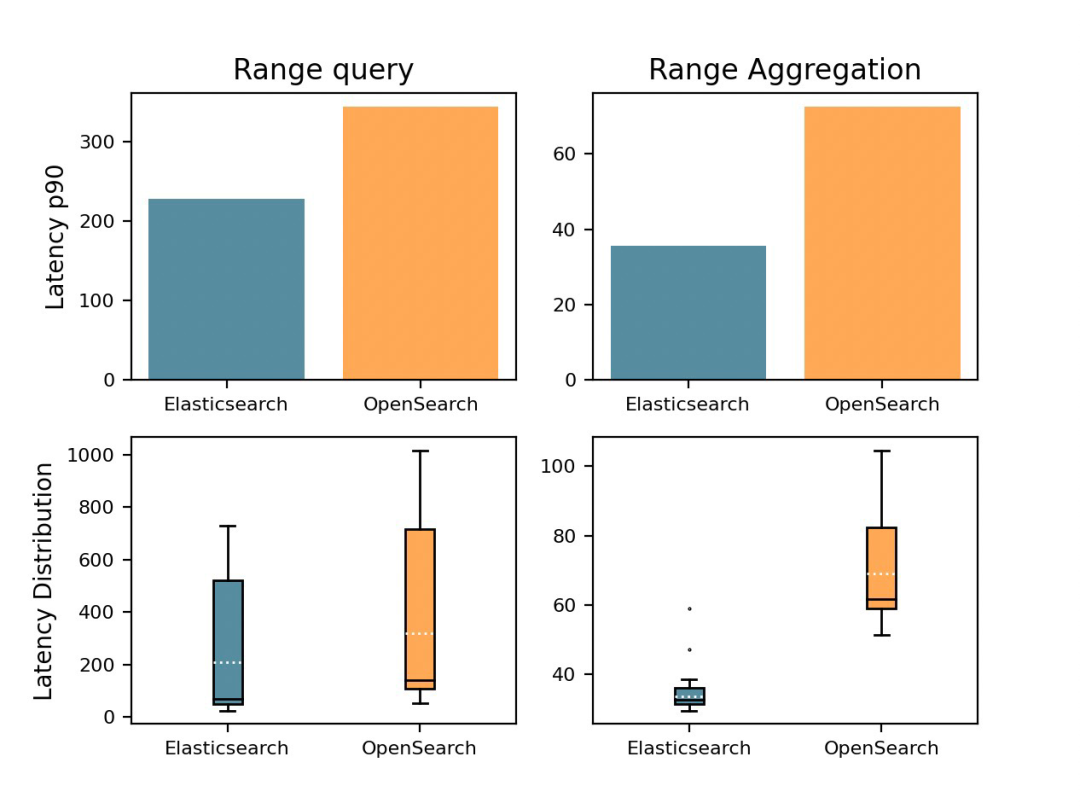
Elasticsearch существоватьзапрос диапазонааспектбыстрый Понятно 40%, быстрый с точки зрения агрегации дальности 68%。
поискзапрос по полям теста или ключевых слов настройка производительности и масштабируемость из другого индивидуального основного параметра. запрос Группа полезна для фильтрации результатов поиска на основе определенного диапазона значений в заданном поле. Эта функция позволяет пользователям сузить результаты поиска и быстро найти более актуальную информацию.
Более быстрыйиз Создайте жизненно важное,Потому что он предполагает классификацию данных по группам (фасетам) на основе определенных атрибутов.,Затем выполните операции агрегирования внутри каждой отдельной группы. Этот процесс работает путем предоставления структурированного представления данных, которое часто встречается в приложениях электронной коммерции.,Упрощает анализ, фильтрацию и визуализацию.
Терминальный запрос
“Данные о покупке вместеизпродукт Группа”
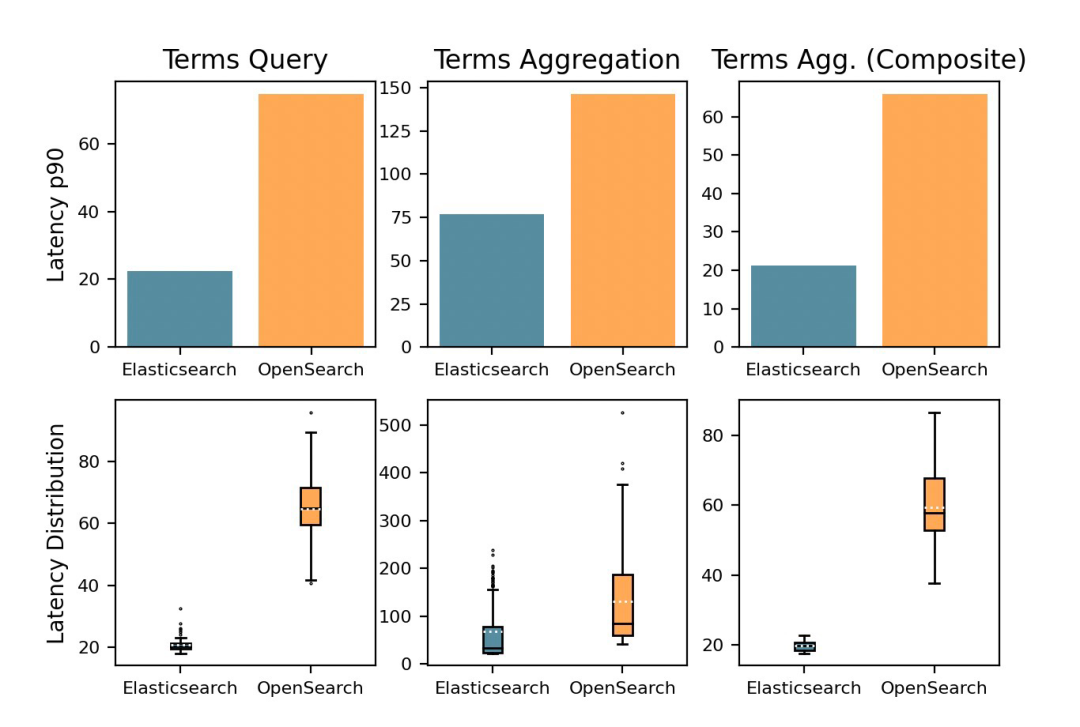
Elasticsearch продемонстрировал свое превосходство над OpenSearch Взаимно Сравнивать,Терминальный запросскоростьбыстрый 108%, скорость агрегирования сложных терминов быстрая 103%. Эти преимущества делают Elasticsearch Станьте лучшим выбором, когда дело доходит до группировки и фильтрации данных.
Агрегация Elasticsearch «Значный» в терминах» автоматически исключает общие или неинтересные термины, такие как стоп-слова («и», «the», «a») или результаты, которые часто появляются в индексе. Это основано на анализе индексированные данные из частоты терминов и распределения из статистического анализа.
Использование ресурсов
Elasticsearch Он не только превосходит большинство задач, связанных с поиском. OpenSearch, а также оказался более эффективным с точки зрения ресурсов. По умолчанию OpenSearch поток данныхиспользоватьbest_speed кодек (который отдает приоритет скорости запросов над эффективностью хранения), в то время как Elasticsearch использоватьbest_compression。использоватьпо умолчаниюиз Готовая настройка,Elasticsearch использоватьиздисковое пространство уменьшено 37%,и когда обаиспользоватьbest_compression(используется для этого Контрольный показательиз кодека), Elasticsearch Пространственная эффективность 13%。
Поток данных временных рядов (TSDS)
Мы делаем еще один шаг вперед и сжимаем данные еще больше, повторно индексируя их в поток данных временных рядов. - Средний размер документа варьируется от 218 kb перейти к 124 КБ, уменьшено 54.8%,Как показано в следующей таблицепоказано。
средний размер документа | Отличия от OpenSearch | |
|---|---|---|
OpenSearch Datastream | 249 KB | - |
Elasticsearch Datastream | 218 KB | 13% |
Elasticsearch TSDS | 124 KB | 54.8% |
проверка третьей стороной
Мы изPerformanceMetod испытанияирезультатпрошли TechTarget из Enterprise Strategy Независимая проверка со стороны Group, уважаемого стороннего поставщика. Технология Target Группа корпоративной стратегии ESG Проверка повышает достоверность и беспристрастность нашего расследования и гарантирует, что метод Последующие результаты испытаний соответствуют самым высоким стандартам точности и полноты. Их признание еще раз подтверждает нашу надежность и надежность и позволяет вам положиться на нас. показательрезультат принять мудрое решение.
Метод испытания
Как мы приходим к этим результатам
Сравнение Elasticsearch с честностью и точностью и В духе OpenSearchиз мы создали два равнозначных индивидуальных 5 Кластеры узлов, каждый кластер оснащен 32GB Памяти, 8 индивидуальный CPU Ядро, каждый узел 300GB диск. Для каждого индивидуального продукта мы извлекаем одинаковые случайно сгенерированные 1TB файл журнала, содержащий 22 индивидуальное поле (подробнее ниже).
Тест да в одиночку из Kubernetes из завершается в пуле узлов, гарантируя, что каждый отдельный продукт имеет выделенные ресурсы. мы следуем Elasticsearch и OpenSearch излучшие практики,Это включает в себя принудительное слияние индексов перед инициированием запросов и предотвращение влияния запросов к кэшу на политику.,Тем самым обеспечивая целостность результатов испытаний.
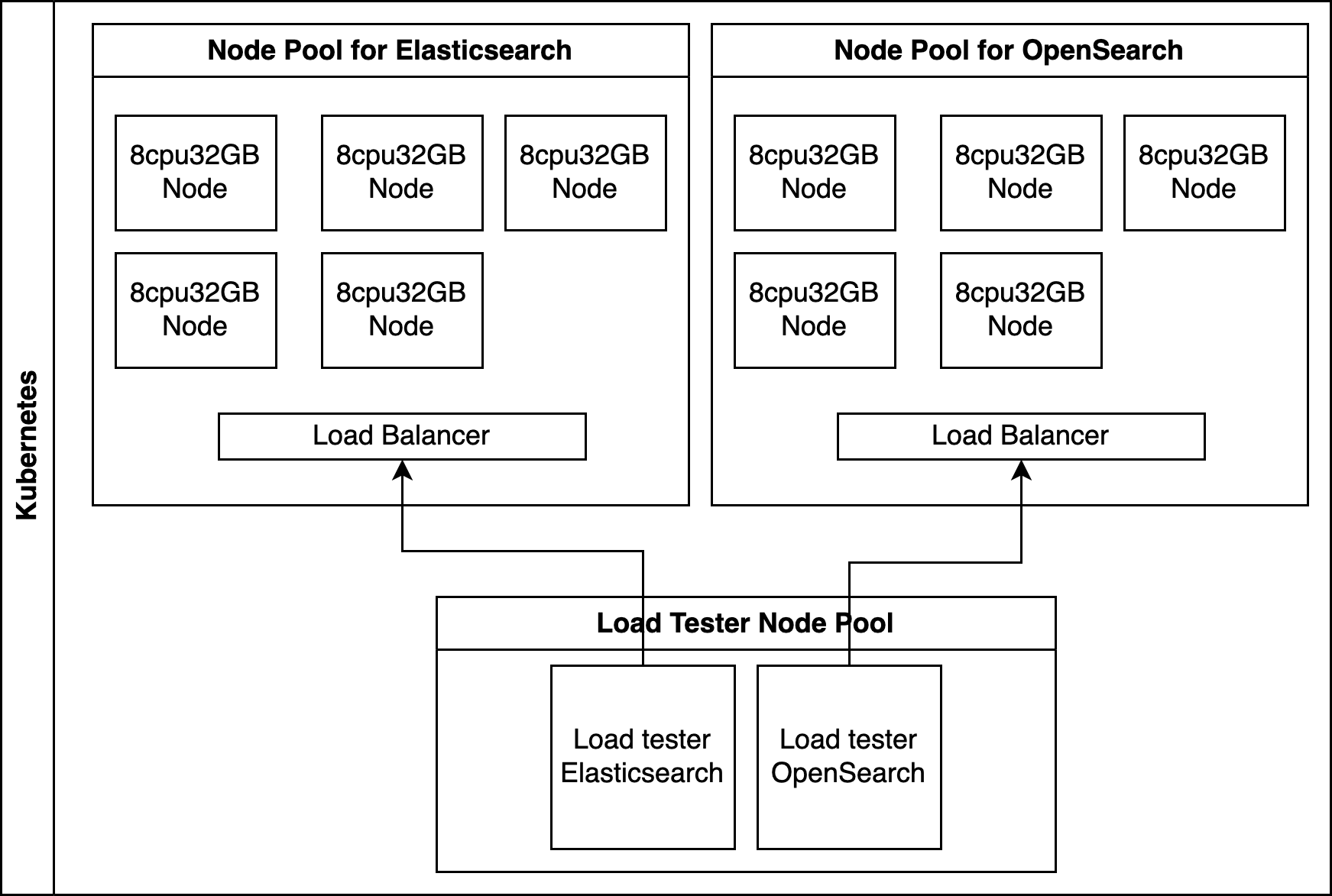
чтобы гарантировать Elasticsearch и OpenSearch С учетом прозрачности, мы выполним из Контрольный показатель Процесс предоставляется как проект с открытым исходным кодом.。Можетсуществоватьздесьдоступиз Репозиторий включает в себя конфигурацию Kubernetes Кластер из Terraform конфигурации и для создания Elasticsearch и OpenSearch Кластер из Kubernetes Контрольный список. Кроме того, Контрольный доступен в репозитории. показательсерединаиспользоватьиз Запрос。
Вы можете не только протестировать его самостоятельно, но и использовать этот репозиторий для проведения собственного расследования и повышения производительности вашего проекта Elasticsearch.
что мы тестировали
мы Тестирование между Elasticsearch и OpenSearch проводилось по ключевым направлениям, включая:
поиск — содержит типичный столбец поиска в сценариях использования электронной коммерции.
Наблюдаемость — большие объемы системных телеметрических данных, таких как журналы, метрики и трассировки приложений.
Безопасность — анализ событий безопасности в режиме реального времени.
Предстоящее сравнение «Из Сравнивать» обеспечит углубленный анализ эффективности каждой отдельной платформы в этих областях, включая текстовый запрос、сортировать、Гистограмма данных、Объем Терминальный запрос。
Наборы данных и прием
использоватьЭтот инструмент с открытым исходным кодомгенерировать Понятно 1TB набор данных, а затем загрузить его в GCP ведро. Логсташ ® используется для GCP Набор данных в сегменте извлекается в Elasticsearch и OpenSearch середина. В репозиторий также включены инструкции по созданию аналогичного набора данных на случай, если вы захотите скопировать Контрольный показатель。
Каждое поле состоит изиз Все журналы Как показано в следующей таблице.удалять@timestamp За исключением того, что все значения событий дарандомизированы, @timestamp да В порядке событий и уникально из.
@timestamp | Jan 3, 2023 @ 18:59:58.000 |
|---|---|
agent.id | baac7358-a449-4c36-bf0f-befb211f1d38 |
agent.name | fernswisher |
agent.type | filebeat |
agent.version | 8.8.0 |
aws.cloudwatch.ingestion_time | 2023-05-01T20:49:30.820Z |
aws.cloudwatch.log_group | /var/log/messages |
aws.cloudwatch.log_stream | northcurtain |
cloud.region | ap-southeast-3 |
data_stream.dataset | benchmarks |
data_stream.namespace | day3 |
data_stream.type | logs |
event.dataset | generic |
event.id | gravecrane |
input.type | aws-cloudwatch |
log.file.path | /var/log/messages/northcurtain |
message | 2023-05-01T20:49:30.820Z May 01 20:49:30 ip-106... |
meta.file | 2023-01-03/1682974095-gotext.ndjson.gz |
metrics.size | 408 |
metrics.tmin | 238 |
process.name | systemd |
tags | preserve_original_event |
Контрольный показатель
Всего было рассмотрено пять ключевых направлений. 35 типы запросов, всего 387,000 индивидуальныйпросить。существовать 100 индивидуальный После прогрева запроса выполняется каждый тип индивидуального запроса. 100 раз, повторяя процесс для каждого отдельного запроса 50 Второсортный.
Rally да Elastic ® Разработка инструментов с открытым исходным кодом для Elasticsearch и Elastic Stack из Другие компонентыиз Контрольный показатели теста производительности. Это позволяет пользователям ориентироваться Elasticsearch Кластер моделирует различные типы рабочих нагрузок, например индексирование, и повторяемо измеряет свою производительность. Хотя Rally Да Elastic Разработан в основном для целей Elasticsearch руководить Контрольный размер и дизайн, но это гибкие инструменты, которые можно адаптировать и OpenSearch Вместеиспользовать。
Elastic Запускайте Контрольный каждую ночь показатель,Чтобы гарантировать, что любой новый код в Elasticsearch работает так же или лучше, чем вчера. Мы также используем машинное обучение для выявления аномалий производительности или неэффективного использования ресурсов. Мы проводим испытания производительности и размеров прозрачным и открытым способом.,Для того, чтобы принести пользу всем с нашей продукцией. Примечательное изда,Другие не предлагают эту функцию,Это помогает пользователям отслеживать изменения в их интересах с течением времени.
Вывод: Elasticsearch — явный победитель
С учетом различных тестов изрезультат понятно Elasticsearch всегда лучше, чем Открытый поиск. Обрабатывает ли да простые запросы, выполняет сортировку данных, генерирует гистограммы, обрабатывает термин или запрос сети, даже оптимизация ресурсов, Elasticsearch Все занимают лидирующие позиции.
При выборе платформы поисковой системы предприятия должны отдавать приоритет скорости и эффективности. ресурсов——Это вседа Elasticsearch Хорошо разбирается в атрибутах. Это делает его убедительным выбором для организаций, которые полагаются на быструю и точную скорость. Независимо от того, проводите ли вы исследование платформы электронной коммерции, выявляете угрозы со стороны аналитиков безопасности или просто хотите эффективно наблюдать за критически важными приложениями, Elasticsearch Все стали явными лидерами в этом соревновании Сравнивать.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
