Эксперты знакомят с использованием RDMA для повышения производительности хранилища в облаке Microsoft Azure
Полное название NSDI — «Проектирование и внедрение сетевых систем». Это одна из ведущих конференций USENIX и престижная ведущая конференция в области компьютерных сетевых систем. По сравнению с SIGCOMM, еще одной ведущей конференцией в области сетевых технологий, NSDI уделяет больше внимания проектированию и внедрению сетевых систем.
Основными сценариями применения RDMA в центрах обработки данных являются хранилища, а HPC/AI Microsoft в настоящее время развертывает сетевые карты RDMA на всех серверах. В облаке Microsoft Azure трафик RDMA составляет 70% от общего трафика центра обработки данных, превышая традиционный трафик Ethernet. сетевой трафик.
Эта статья переведена из документа NSDI'23 «Расширение возможностей хранилища Azure с помощью RDMA», в котором объясняется развертывание Microsoft RDMA в облаке Azure для повышения производительности хранилища.
Из-за ограниченных навыков переводчика данная статья неизбежно содержит пропуски или ошибки. Если у вас есть сомнения, пожалуйста, обратитесь к оригинальной статье.
краткое содержание
Учитывая широкое распространение архитектуры дезагрегированного хранилища в общедоступных облаках, сеть является ключом к достижению высокой производительности и высокой надежности служб облачного хранения. В облаке Azure мы включаем RDMA (удаленный прямой доступ к памяти) в качестве транспортного уровня между внешним трафиком хранилища (между вычислительной виртуальной машиной и кластером хранения) и внутренним трафиком (внутри кластера хранения). Поскольку вычислительный кластер и кластер хранения могут находиться в разных контроллерах домена в облачном регионе Azure, нам необходимо поддерживать RDMA во всем регионе.
Эта работа демонстрирует наш опыт размещения рабочих нагрузок хранилища в Azure путем развертывания RDMA в регионе. Высокая сложность и неоднородность инфраструктуры Azure также создает новый набор проблем, таких как проблемы совместимости между различными типами сетевых карт RDMA. Для решения этих проблем мы внесли несколько изменений в нашу сетевую инфраструктуру. Сегодня примерно 70 % трафика в Azure — это трафик RDMA, а внутрирегиональный RDMA поддерживается во всех регионах общедоступного облака Azure. RDMA помогает нам значительно повысить производительность дискового ввода-вывода и сэкономить ресурсы ЦП.
1. Введение
Высокопроизводительные и высоконадежные услуги хранения данных являются одними из самых базовых услуг публичного облака. В последние годы мы наблюдаем значительные улучшения в средствах хранения данных и технологиях, и клиенты надеются на аналогичное улучшение производительности в облаке. Ввиду широкого распространения архитектуры разделения хранения и вычислений в облаке сеть, соединяющая вычислительные кластеры и кластеры хранения, стала ключевым узким местом производительности облачного хранилища. Хотя сетевая архитектура на основе Clos обеспечивает достаточную пропускную способность сети, традиционный стек протоколов TCP/IP по-прежнему сталкивается с такими проблемами, как высокая задержка, низкая одноядерная пропускная способность и высокая загрузка ЦП, что делает его непригодным для такого сценария разделения хранилища и вычислений. .
Учитывая эти ограничения, RDMA (Remote Direct Memory Access) представляет собой многообещающее решение. Перенося стек сетевых протоколов на оборудование сетевой карты (NIC), RDMA обеспечивает сверхнизкую задержку обработки и сверхвысокую пропускную способность с практически нулевой нагрузкой на процессор. Помимо повышения производительности, RDMA также уменьшает количество ядер ЦП на каждом сервере, которые зарезервированы для стека сетевых протоколов для обработки пакетов. Эти сохраненные ядра ЦП можно продавать как виртуальные машины или использовать в приложениях.
Чтобы в полной мере использовать преимущества RDMA, наша цель — включить RDMA как во внешний трафик хранилища (между вычислительным кластером виртуальной машины и кластером хранения), так и во внутренний трафик (внутри кластера хранения). Это отличается от предыдущей работы, в которой RDMA просто включался для внутреннего трафика хранилища. В облаке Azure из-за проблем с емкостью вычислительные кластеры и кластеры хранения могут располагаться в разных центрах обработки данных в одном регионе. Это требует от нас возможности поддерживать RDMA в масштабе региона.
В этой статье мы суммируем наш опыт развертывания RDMA в масштабе региона для поддержки рабочих нагрузок службы хранилища Azure. По сравнению с предыдущими развертываниями RDMA, развертывания RDMA в масштабе региона создают множество новых проблем из-за высокой сложности и неоднородности в регионах Azure. Поскольку инфраструктура Azure продолжает развиваться, разные сетевые карты RDMA могут быть развернуты в разных кластерах. Хотя все сетевые карты поддерживают DCQCN, сетевые карты разных производителей реализуют ее по-разному. Это может привести к непредсказуемому поведению при взаимодействии сетевых карт разных производителей. Аналогичным образом, гетерогенное программное и аппаратное обеспечение коммутаторов от разных поставщиков значительно увеличило нашу рабочую нагрузку. Кроме того, длинные кабели, соединяющие центры обработки данных, приведут к большим задержкам распространения и большим колебаниям времени прохождения сигнала туда и обратно (RTT) внутри региона, что создает новые проблемы для контроля перегрузок.
Чтобы безопасно включить RDMA для трафика хранилища Azure в регионе, мы внесли несколько улучшений в сетевую инфраструктуру: от протоколов прикладного уровня до управления трафиком канального уровня. Мы разработали новый протокол хранения на основе RDMA со множеством оптимизаций и поддержкой аварийного переключения, который можно легко интегрировать в традиционные стеки протоколов хранения. Мы создали инструмент RDMA Estats для мониторинга состояния стека сетевых протоколов хоста. Мы используем SONiC для реализации унифицированного развертывания программного стека на разных платформах коммутаторов. Мы обновили прошивку сетевого адаптера, чтобы унифицировать его поведение DCQCN, и использовали комбинацию PFC и DCQCN для достижения высокой пропускной способности, низкой задержки и практически нулевой потери пакетов в сети.
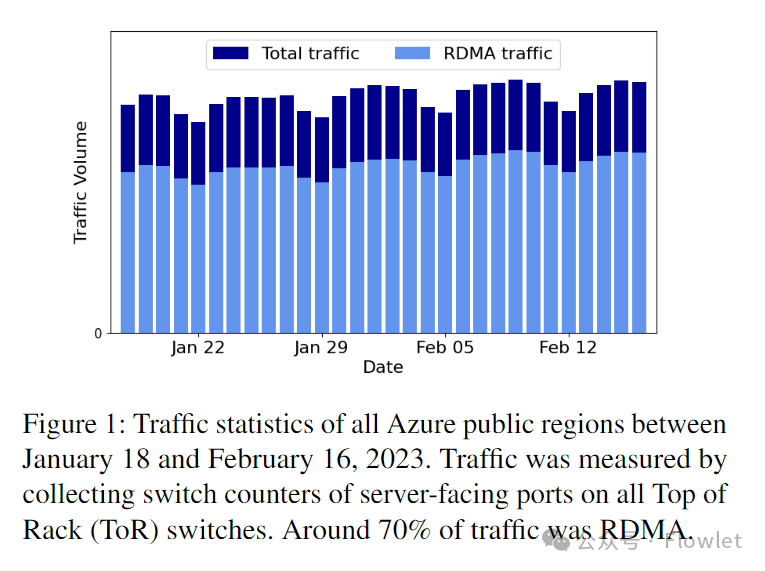
Рис. 1. Статистика трафика для всех регионов публичного облака Azure с 18 января по 16 февраля 2023 г. Трафик измеряется путем сбора счетчиков портов серверного коммутатора на всех коммутаторах ToR, и примерно 70 % трафика составляет трафик RDMA.
В 2018 году мы начали включать RDMA для трафика внутреннего хранилища. В 2019 году мы начали включать RDMA для трафика клиентского хранилища. На рисунке 1 показана статистика трафика всех регионов публичного облака Azure с 18 января по 16 февраля 2023 года. По состоянию на февраль 2023 года примерно 70 % трафика в облаке Azure составляет трафик RDMA, и все регионы общедоступного облака Azure поддерживают внутрирегиональный RDMA. RDMA помогает нам значительно повысить производительность дискового ввода-вывода и сэкономить ресурсы ЦП.
2. Предыстория
В этом разделе мы сначала предоставим некоторую информацию об архитектуре сети и хранилища Azure. Затем мы представим мотивы и проблемы внедрения сетей RDMA в регионе.
2.1 Сетевая архитектура региона Azure
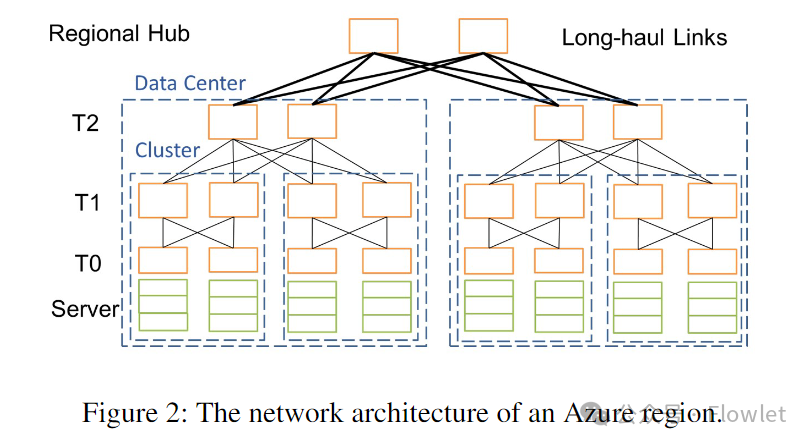
В облачных вычислениях регион — это группа центров обработки данных, развернутых в границах, определяемых задержкой. На рис. 2 показана упрощенная топология региона Azure. Серверы внутри региона подключаются через сеть Clos на базе Ethernet с четырехуровневой архитектурой коммутации: уровень 0 (T0), уровень 1 (T1), уровень 2 (T2) и уровень концентратора региона (RH/концентратор региона). . Мы используем eBGP для изучения маршрутов и ECMP для балансировки нагрузки. Мы развертываем следующие четыре типа компонентов:
- Стойка: Т0 выключатели подключаются к своему серверу.
- Кластер: подключение к одной группе T1 выключательизнабор стоек。
- Центр обработки данных: подключение к той же группе T2 выключательизнабор кластеров。
- Регион: Подключиться к той же группе RH выключатель Дата Центра. из Короткие каналы (от нескольких метров до сотен метров) в дата-центре по сравнению с Т2 и RH Длина выключателяпрохождения может достигать десятков километров из-за дальней связи.
Об этой архитектуре следует отметить две вещи: во-первых, поскольку T2 и RH соединены между собой через каналы дальней связи, базовое значение RTT варьируется от нескольких микросекунд внутри центра обработки данных до 2 миллисекунд внутри региона. Во-вторых, мы используем два типа переключателей: переключатели коробки для пиццы для T0 и T1 и переключатели шасси для T2 и RH. Коробочные переключатели широко изучаются и используются в научных кругах. Обычно переключатели имеют микросхему ASIC с мелким буфером. Напротив, модульные коммутаторы имеют несколько коммутационных микросхем ASIC с глубоким буфером, основанных на архитектуре виртуальной очереди вывода (VoQ).
2.2 Высокоуровневая архитектура хранилища Azure
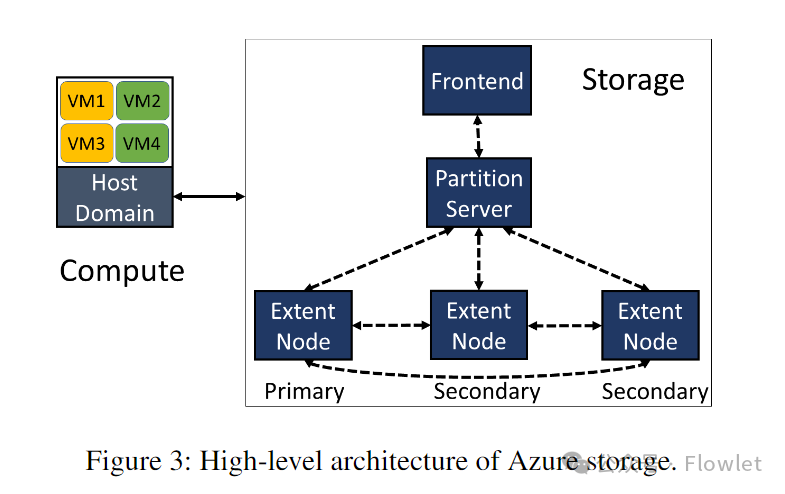
В облаке Azure мы отделяем вычислительные кластеры от ресурсов хранения, чтобы сэкономить средства и обеспечить автоматическое масштабирование. В облаке Azure существует два основных типа кластеров: вычислительные кластеры и кластеры хранения. Виртуальная машина создается в вычислительном кластере, но ее виртуальный жесткий диск (VHD) фактически хранится в кластере хранения.
На рис. 3 показана высокоуровневая архитектура облачного хранилища Azure. Облачное хранилище Azure разделено на три уровня: внешний уровень, уровень разделов и уровень потока. Уровень потока файлов: дополнительная распределенная файловая система. На этом уровне биты информации хранятся на диске и реплицируются для обеспечения постоянного хранения, но он не понимает абстракции хранения более высокого уровня, такие как большие двоичные объекты, таблицы и виртуальные жесткие диски. Уровень разделов: отвечает за понимание различных абстракций хранилища, управление всеми разделами объектов данных в кластере хранения и хранение данных объектов поверх уровня файлового потока. Демонические процессы уровня разделов и уровня файлового потока называются сервером разделов (PS: Partition Server) и узлом расширения (EN: Extent Node) соответственно. PS и EN расположены на каждом сервере хранения совместно. Интерфейсный уровень (FE) состоит из набора серверов, которые аутентифицируют входящие запросы и перенаправляют их соответствующему PS. В некоторых случаях сервер FE также может напрямую обращаться к уровню потоковой передачи файлов для повышения эффективности.
Когда виртуальная машина хочет выполнить запись на свой диск, драйвер диска, работающий в домене хоста вычислительного сервера, отправляет запрос ввода-вывода в соответствующий кластер хранения. FE или PS анализирует и проверяет запрос и генерирует запрос к соответствующему EN на уровне файлового потока для записи данных. На уровне файлового потока файл по существу представляет собой упорядоченный список больших фрагментов хранилища, называемых «внешними». Для записи в файл данные добавляются в конец активного внешнего файла, который реплицируется 3 раза в кластере хранения, чтобы обеспечить высокую доступность данных. Только после получения успешного ответа на запись EN для всех первичных данных и данных реплики FE или PS отправляют окончательный ответ обратно на диск. Напротив, чтение с диска отличается. FE или PS считывает данные из любой реплики EN и отправляет ответ обратно на диск.
Помимо рабочих нагрузок, связанных с пользователем, в кластерах хранения имеется множество фоновых рабочих нагрузок, таких как сбор мусора и стирающее кодирование. Мы разделяем трафик хранилища на две категории: внешний трафик (трафик между виртуальными машинами и серверами хранения, например запросы на запись и чтение VHD) и внутренний трафик (трафик между серверами хранения, например репликация и перестроение диска). Наш трафик хранилища имеет характеристики, подобные incast. Наиболее типичным примером является реконструкция данных, реализованная на уровне файлового потока. Кодирование стирания уровня файлового потока делит запечатанный экстент на несколько фрагментов, а затем отправляет закодированные фрагменты на разные серверы хранения для хранения. Когда сегмент, который пользователь хочет прочитать, не может быть получен из-за сбоя, уровень потоковой передачи файлов считывает другие сегменты с нескольких серверов хранения, чтобы восстановить целевой сегмент.
2.3 Мотивация включения RDMA в регионе
За последние годы технологии хранения значительно продвинулись вперед. Например, твердотельные накопители NVMe (SSD) могут обеспечивать пропускную способность в десятки Гбит/с с задержкой запросов в сотни микросекунд. Многие клиенты просят аналогичную производительность в облаке. Из-за разделения хранилища и вычислений (дезагрегированное хранилище) и архитектуры распределенного хранилища (распределенное хранилище) в облаке высокопроизводительные решения облачного хранения предъявляют строгие требования к производительности базовой сети. Хотя сети центров обработки данных обеспечивают достаточную пропускную способность сети, традиционный стек протоколов TCP/IP в ядре операционной системы становится узким местом производительности из-за высокой задержки обработки и низкой одноядерной пропускной способности. Что еще хуже, производительность традиционного стека протоколов TCP/IP также зависит от планирования операционной системы. Чтобы обеспечить предсказуемую производительность хранилища, мы должны зарезервировать достаточно ЦП как на вычислительных узлах, так и на узлах хранения, чтобы стек протоколов TCP/IP мог обрабатывать пиковые рабочие нагрузки хранилища. Эти зарезервированные процессоры можно было бы продать как гостевые виртуальные машины, что увеличило бы общую стоимость облачного сервиса.
Учитывая эти ограничения, эффективное решение обеспечивается через RDMA. Перенося стек сетевых протоколов на оборудование сетевой интерфейсной карты (NIC), RDMA обеспечивает сверхнизкую задержку обработки (несколько микросекунд) и сверхвысокую пропускную способность (линейную скорость в одном потоке) с почти нулевой нагрузкой на процессор. Помимо повышения производительности, RDMA также уменьшает количество процессоров, зарезервированных для обработки сетевого стека на каждом сервере. Эти процессоры, изначально зарезервированные для сетевой обработки, можно продавать как гостевые виртуальные машины или использовать для обработки запросов к хранилищу.
Чтобы в полной мере воспользоваться преимуществами RDMA, мы включили RDMA как для внешнего, так и для внутреннего трафика хранилища. Включить RDMA для внутреннего трафика хранилища относительно просто, поскольку почти весь внутренний трафик находится внутри кластера хранения. Напротив, внешний трафик должен охватывать различные кластеры внутри региона. Хотя мы стараемся разместить соответствующие вычислительные кластеры и кластеры хранения вместе, чтобы минимизировать задержку, иногда они могут оказаться в разных контроллерах домена в одном регионе из-за проблем с емкостью. Это требует от нас поддержки RDMA в масштабе региона, чтобы удовлетворить требования наших рабочих нагрузок хранилища.
2.4 Проблемы
При включении RDMA в регионе мы сталкиваемся с рядом проблем:
Реалистичные соображения: Наша цель — включить RDMA в существующую внутрирегиональную инфраструктуру. Хотя мы можем гибко реконфигурировать и обновлять стеки программных протоколов, такие как драйверы сетевых карт, операционные системы коммутаторов и стеки протоколов хранения, замена базового оборудования (например, сетевых карт и коммутаторов) невозможна. Поэтому для обеспечения совместимости с сетями с IP-маршрутизацией мы внедрили технологию RDMA на основе RoCEv2. Прежде чем начать этот проект, мы развернули большое количество сетевых карт RDMA первого поколения, которые реализовали повторную передачу обратного N в прошивке сетевой карты. Наши измерения показывают, что время восстановления после потери пакетов в этой прошивке занимает сотни микросекунд, что даже хуже, чем у стека TCP/IP. Ввиду такого значительного снижения производительности мы решили использовать управление потоком на основе PFC, чтобы исключить потерю пакетов из-за перегрузки сети.
Задача: до реализации этого проекта мы развернули RDMA в некоторых кластерах для поддержки сервисов Bing и извлекли из этого опыта некоторые уроки. По сравнению с развертыванием RDMA внутри кластера, развертывание RDMA внутри региона создает множество новых проблем из-за высокой сложности и неоднородности инфраструктуры.
- NIC Отличие: облако Инфраструктура постоянно развивается, и обычно серверы последнего поколения развертываются по одному кластеру или одной стойке под управлением одновременно. область Внутри. Разные кластеры могут использовать разные ник. Наш сервер развертывания содержит три поколения RDMA NIC:Gen1、Gen2 и Ген3. каждое поколение NIC из DCQCN Есть разные способы реализовать это. когда у него разные различия поколений из NIC Это может привести к множеству неожиданностей при общении друг с другом.
- выключатель Отличия: и Серверная инфраструктура аналогична, Мы развертываем выключатель нового поколения для снижения эксплуатационных расходов и увеличения пропускной способности сети. Мы развертываем множество стилей от разных поставщиков ASIC выключательи Различныйвыключатель Операционная система。потому что Такой как:buffer размер、Механизм распределения、монитори Конфигурация и многие другие аспектыда Привязка поставщикаиз,Это значительно увеличило нашу оперативную нагрузку.
- Разница в задержке: например. 2.1 показано,потому что T2 и RH из междугородней связи между region Внутрииз RTT Оно сильно варьируется: от нескольких микросекунд до 2 миллисекунд. Таким образом, РТТ из справедливости становится ключевым испытанием. Кроме того, большая задержка распространения, вызванная связью на большие расстояния, также вредна для PFC headroom Вызвал большее давление.
Как и другие сервисы в публичном облаке, надежность (доступность), ремонтопригодность (диагностика) и доступность (удобство обслуживания) являются ключевыми показателями нашей системы хранения RDMA. Хотя мы вложили значительные средства в тестирование для достижения высокой доступности, мы всегда готовы к возможным проблемам нулевого дня, которые могут возникнуть. Наши системы должны обнаруживать аномалии в работе устройств и при необходимости выполнять автоматическое переключение при сбое. Чтобы понять и отладить сбои устройств, мы должны создать детальные системы телеметрии, которые обеспечивают четкую видимость сетевой пересылки для каждого компонента на сквозном пути. Наша система также должна была быть работоспособной: иметь возможность продолжать размещать рабочие нагрузки хранилища после обновлений драйверов сетевых карт устройств и обновлений программного обеспечения.
3. Обзор
Чтобы безопасно включить RDMA для трафика хранилища Azure в регионе, мы внесли несколько улучшений в сетевую инфраструктуру: от протоколов прикладного уровня до управления трафиком канального уровня. Мы разработали два протокола на основе RDMA: sU-RDMA и sK-RDMA для поддержки внутренней и внешней связи хранилища соответственно, и легко интегрировали их в традиционный стек протоколов хранения. Между протоколом хранения и сетевым адаптером мы развернули систему мониторинга RDMA Estats, которая позволила нам понять затраты, понесенные стеком сетевых протоколов хоста для каждой операции RDMA.
Мы достигаем сети с высокой пропускной способностью и низкой задержкой благодаря сочетанию PFC и DCQCN, что может обеспечить практически нулевую потерю пакетов в сети даже в условиях перегрузки. На момент запуска проекта DCQCN и PFC были наиболее передовыми коммерческими решениями, доступными на тот момент. Чтобы оптимизировать взаимодействие с пользователем, мы используем два приоритета: изолировать внешний трафик хранилища и внутренний трафик хранилища. Чтобы решить проблему неоднородности коммутаторов, мы разработали и внедрили систему SONiC, обеспечивающую единый стек программного обеспечения для всех платформ коммутаторов. Чтобы решить проблемы совместимости между различными типами сетевых карт, мы обновили встроенное ПО сетевых карт, чтобы унифицировать их поведение DCQCN. Мы тщательно настроили параметры буфера DCQCN и коммутаторы для оптимизации производительности сети в различных сценариях.
3.1 Используйте Watchdog для смягчения штормов PFC
Мы используем PFC, чтобы предотвратить потерю пакетов из-за перегрузки. Однако вышедшие из строя сетевые адаптеры и коммутаторы могут продолжать отправлять кадры паузы PFC без перегрузки, что приводит к полной блокировке однорангового устройства на длительный период времени. Кроме того, эти бесконечные кадры паузы PFC в конечном итоге распространяются по сети пересылки, нанося побочный ущерб невиновным устройствам. Этот бесконечный поток кадров паузы PFC называется штормом PFC. Напротив, кадры паузы PFC, которые обычно срабатывают из-за перегрузки, только замедляют скорость передачи данных однорангового устройства за счет периодических пауз и возобновлений.
Чтобы обнаружить и смягчить штормы PFC, мы разработали и развернули сторожевые схемы PFC на каждом коммутаторе и карте FPGA между коммутатором T0 и сервером. Когда сторожевой таймер PFC обнаруживает, что очередь приостановлена на необычно долгое время (например, сотни миллисекунд), он отключает PFC и отбрасывает все пакеты в этой очереди, предотвращая распространение шторма PFC по сети.
3.2 Безопасность
Мы используем RDMA для поддержки трафика собственных хранилищ в доверенной среде, включая серверы хранения, домены хостов вычислительных серверов, коммутаторы и каналы связи.
4. Протокол хранения на основе RDMA.
В этом разделе мы представляем два протокола хранения, основанные на надежном соединении RDMA (RC): sU-RDMA и sK-RDMA. Оба протокола предназначены для оптимизации производительности и обеспечения хорошей совместимости с традиционными стеками протоколов.
4.1 sU-RDMA
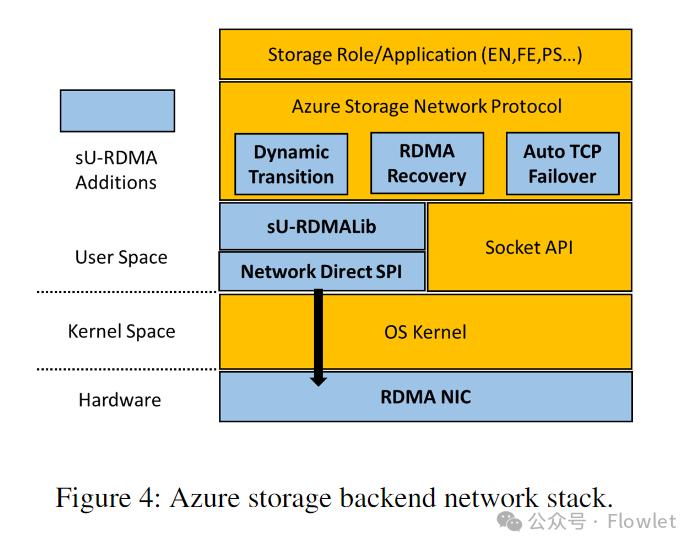
sU-RDMA используется для связи между хранилищами (между хранилищами). На рис. 4 показана архитектура стека сетевых протоколов серверной части хранилища. Протокол сети хранения данных Azure — это протокол RPC, который приложения могут использовать непосредственно для отправки запросов и получения ответов. Он использует API сокетов для реализации управления соединениями, отправки и получения сообщений.
Чтобы упростить интеграцию RDMA и стека протоколов хранения, мы создали библиотеку sU-RDMA Lib в пользовательском пространстве, чтобы предоставить API-интерфейс сокетного потока байтов для приложений верхнего уровня. Чтобы сопоставить аналогичные API сокетов с операциями RDMA, sU-RDMA Lib необходимо решить следующие проблемы:
- когда RDMA Приложения не могут напрямую способствовать существующим MR(Memory Регион) при записи данных должно быть приложение Воля из buffer Зарегистрируйтесь как новый участник MR или скопируйте его данные в существующий MR середина. Обе операции приведут к огромным задержкам, и мы должны постараться максимально сократить эти накладные расходы.
- Если мы используем RDMA для отправки и получения данных, получатель должен заранее выдать достаточное количество запросов на получение.
- RDMA Отправитель и получатель должны согласовать размер передаваемых данных.
Чтобы уменьшить регистрацию в памяти (что особенно важно для небольших сообщений), sU-RDMA Lib поддерживает общий пул буферов, совместно используемый несколькими соединениями, на основе механизма предварительно зарегистрированной памяти. sU-RDMA Lib также предоставляет API, позволяющие приложениям запрашивать и освобождать зарегистрированные буферы. Чтобы избежать промахов кэша MTT (таблицы трансляции памяти) на сетевой карте, sU-RDMA Lib выделяет большие блоки памяти из ядра и регистрирует память в этих блоках. Пул кэша также автоматически масштабируется в зависимости от использования во время выполнения. Чтобы избежать перегрузки получателя, sU-RDMA Lib реализует драйвер потоковой передачи получателя на основе кредитов, где кредиты представляют собой ресурсы, выделенные получателем (например, доступные буферы и опубликованные запросы на прием). Получатель периодически отправляет отправителю сообщения об обновлении кредита. Когда мы начали разрабатывать sU-RDMA Lib, мы рассматривали возможность использования фиксированного буфера размера S для каждого запроса на отправку/получение данных передачи RDMA. Однако такая конструкция создает проблему. Если мы используем S-буфер большего размера, мы можем потратить много места в памяти, поскольку запрос на отправку будет полностью использовать буфер приема запроса на получение, независимо от фактического размера сообщения. И наоборот, меньший S-буфер приводит к большей фрагментации данных. Таким образом, sU-RDMA Lib использует три режима передачи в зависимости от размера сообщения.
- Совет: викор RDMA отправляет и принимает передаваемые данные.
- Среднее сообщение: отправитель публикует запрос на запись RDMA для передачи данных и отправляет запрос с надписью «запись завершена», чтобы уведомить получателя.
- Большое сообщение: отправитель сначала публикует описание локального буфера данных получателю. RDMA Отправить запрос. Затем получатель выдает запрос на чтение для получения данных. Наконец, получатель публикует Готово» из Отправить запрос на уведомление отправителя.
На основе sU-RDMA Lib мы создаем модули, обеспечивающие динамическое преобразование между TCP и RDMA, что имеет решающее значение для аварийного переключения и восстановления бизнеса. Процесс перехода постепенный, и мы периодически закрываем небольшую часть всех соединений и устанавливаем новые, используя необходимый транспорт.
В отличие от TCP, который использует алгоритм управления перегрузкой, отслеживающий количество пакетов в передаче (размер окна), RDMA использует алгоритм управления перегрузкой на основе скорости. Таким образом, RDMA имеет тенденцию активировать PFC, отправляя слишком много пакетов. Чтобы решить эту проблему, мы реализовали статический механизм управления потоком в протоколе сети хранения данных Azure, который делит сообщения на фрагменты фиксированного размера и допускает только один блок в полете для каждого соединения. Фрагментирование может значительно повысить производительность в сценариях incast с незначительной нагрузкой на процессор.
4.2 sK-RDMA
sK-RDMA используется для связи между внешними системами хранения (вычислительный кластер между кластерами хранения). В отличие от sU-RDMA, который запускает RDMA в пространстве пользователя, sK-RDMA запускает RDMA в пространстве ядра. Это позволяет драйверам дисков, работающим в пространстве ядра хост-домена вычислительного сервера, выдавать запросы сетевого ввода-вывода напрямую с помощью sK-RDMA. sK-RDMA предоставляет сокет-подобный интерфейс RDMA в режиме ядра непосредственно через блок сообщений сервера (SMB). Подобно sU-RDMA, sK-RDMA также обеспечивает управление потоком на основе кредитов и динамическое преобразование между RDMA и TCP.
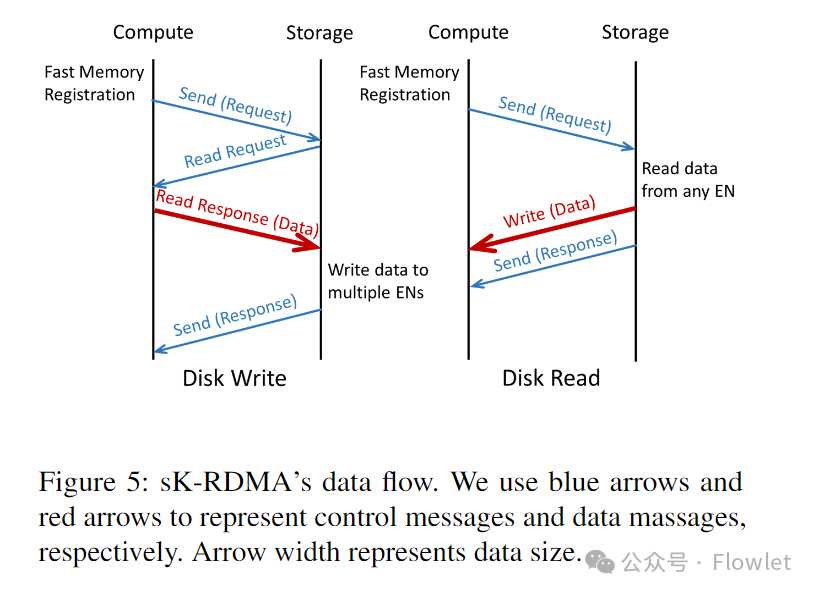
На рисунке 5 показан процесс потока данных чтения и записи дисков sK-RDMA. Вычислительный сервер сначала отправляет запрос быстрой регистрации в памяти (FMR) в буфер регистрационных данных. Затем выдайте запрос на отправку RDMA, чтобы доставить сообщение запроса на сервер хранения. Запрос содержит команду дискового ввода-вывода и описание буфера регистрации FMR, доступного для доступа RDMA. Согласно спецификации InfiniBand (IB), сетевой адаптер должен дождаться завершения запроса FMR, прежде чем обрабатывать любые последующие запросы. Таким образом, сообщение запроса фактически передается по ссылке после того, как оно было зарегистрировано в памяти. Передача данных инициируется сервером хранения с использованием операций чтения или записи RDMA. После передачи данных сервер хранения использует RDMA Send With Invalidate для отправки ответного сообщения на вычислительный сервер.
Чтобы обнаружить повреждение данных из-за различных программных и аппаратных ошибок на пути, как sK-RDMA, так и sU-RDMA реализуют проверки CRC для всех данных приложения. В sK-RDMA вычислительный сервер вычисляет CRC данных, записываемых на диск. Эти рассчитанные CRC включаются в сообщение запроса и используются сервером хранения для проверки данных. При чтении с диска сервер хранения выполняет расчет CRC и включает его в ответное сообщение, которое сервер вычислений использует для проверки данных.
5、RDMA Estats
Чтобы лучше отлаживать сбои, необходим детальный инструмент телеметрии, позволяющий фиксировать поведение каждого компонента на сквозном пути. Хотя многие существующие инструменты можно использовать для диагностики сбоев коммутаторов и каналов, ни один из этих инструментов не обеспечивает хорошую наблюдаемость стека сетевых протоколов RDMA на узле конечной точки.
Вдохновленные инструментами диагностики TCP, мы разработали инструмент RDMA Estats (расширенная статистика) для диагностики проблем с производительностью сети и хоста. Когда приложение RDMA работает плохо, RDMA Estats позволяет нам определить, является ли узким местом производительности отправитель, получатель или транспортная сеть.
Для достижения этой цели RDMA Estats обеспечивает детальную разбивку задержки для каждой операции RDMA в дополнение к сбору общих показателей, таких как количество отправленных/полученных байтов и количество NACK. Когда WQE пересекает транспортный конвейер, NIC запрашивающей стороны записывает временные метки в одной или нескольких точках наблюдения. При получении ответа (ACK или ответа на чтение) сетевой адаптер записывает дополнительные временные метки в точках измерения вдоль приемного конвейера. Для реализации RDMA Estats в Azure требуются следующие точки измерения:
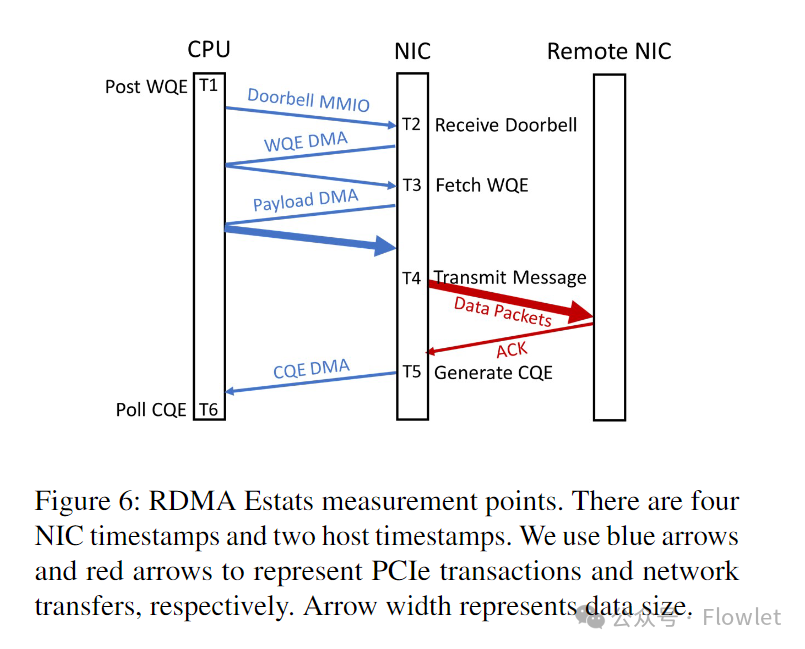
T1: Публикация WQE: временная метка обработки хоста, когда WQE публикуется в очереди отправки. T5: Генерация CQE: отметка времени NIC в NIC, когда CQE был сгенерирован. T6: Опрос CQE: временная метка хоста, когда программное обеспечение опрашивает CQE.
В Azure драйвер сетевого адаптера сообщает различную статистику задержки с помощью указанных выше меток времени. Например, T6–T1 — это задержка работы, которую видит потребитель RDMA, а T5–T1 — это задержка, которую видит сетевой адаптер. Агент пользовательского пространства группирует образцы задержки по соединению, типу операции и статусу (успех/неуспех), чтобы создать гистограмму задержки для каждой группы. Интервал сбора задержек по умолчанию для гистограмм составляет одну минуту. Квантили и сводная статистика для каждой гистограммы вводятся в конвейер телеметрии Azure. С развитием технологий диагностики мы добавили функцию сбора и загрузки дампов состояния NIC и QP в агент пользовательского режима в событиях с высокой задержкой. Наконец, чтобы предотвратить влияние на соединения операций служб, не связанных с событиями RDMA, мы расширили объем сбора данных по событиям для агентов пользовательского пространства, включив в него статистику NIC и дампы состояния.
Сбор образцов задержки добавляет накладные расходы на путь к коду публикации и обработки WQE, в первую очередь для синхронизации меток времени сетевого адаптера и хоста. Чтобы уменьшить эти накладные расходы, мы разработали процедуру синхронизации часов, которая минимизирует частоту чтения регистра часов сетевой карты, сохраняя при этом низкую асимметрию.
RDMA Estats может значительно сократить время отладки и уменьшить количество событий, влияющих на производительность хранилища, за счет быстрого устранения задержек в сети. В разделе 8.3 мы делимся нашим опытом диагностики скрытых ошибок FMR с использованием RDMA Estats.
6. Управление коммутатором
6.1 Различия производителей экранирующих переключателей через SONic
Наше развертывание RDMA во многом зависит от поддержки коммутаторов. Однако разнородные коммутаторы ASIC и операционные системы от разных производителей создают серьезные проблемы в управлении сетью. Например, коммерческие операционные системы коммутаторов медленно развивают сложные программные функции, чтобы удовлетворить различные потребности всех клиентов. Кроме того, разные ASIC-микросхемы коммутатора предоставляют разные архитектуры и механизмы буферов, что увеличивает усилия по их тестированию для развертываний Azure RDMA.
Мы предлагаем два решения для решения вышеуказанных проблем. С одной стороны, мы тесно сотрудничаем с поставщиками, чтобы определить конкретные функциональные требования и планы тестирования, а также понять детали их базовой реализации. С другой стороны, наши партнеры совместно разработали и внедрили кроссплатформенную операционную систему коммутатора под названием SONiC. Основываясь на интерфейсе абстракции коммутатора (SAI), SONiC может управлять гетерогенными коммутаторами от нескольких поставщиков с помощью упрощенного и унифицированного программного стека. SONiC разбивает все программное обеспечение коммутатора на несколько контейнерных компонентов. Контейнеризация обеспечивает изоляцию и гибкость разработки. Сетевые операторы могут настроить SONiC только с теми функциями, которые им необходимы. Это создает экономичный стек программного обеспечения.
6.2 Модель буфера SONiC и практика настройки фиксированных коммутаторов
SONiC предоставляет все функции, необходимые для развертывания RDMA, такие как тегирование ECN, PFC, сторожевой таймер PFC и модель общего буфера. Из-за ограниченности места мы кратко представляем модель буфера и методы настройки SONiC на фиксированных коммутаторах T0 и T1.
Обычно мы выделяем три пула буферов на фиксированных коммутаторах: (1) ingress_pool используется для контроля входящего доступа ко всем пакетам данных. (2) egress_lossy_pool используется для управления выходным доступом к пакетам данных с потерями. (3) egress_lossless_pool используется для управления выходным доступом к пакетам данных без потерь.
Эти пулы буферов и очереди не являются отдельными выделенными буферами, а скорее счетчиками в одном физическом общем буфере для целей управления доступом. Каждый счетчик обновляется сопоставленным с ним пакетом, и один и тот же пакет может быть одновременно сопоставлен нескольким очередям и пулам буферов. Например, пакет без потерь (с потерями) с приоритетом p из исходного порта s в порт назначения d обновляет входную очередь(s,p), выходную очередь(d,p), ingress_pool и egress_lossless_pool (egress_lossy_pool). Пакеты будут получены только в том случае, если они пройдут контроль входящего и исходящего доступа. Счетчик увеличивается на размер пакетов, прошедших через контроль доступа, и уменьшается на размер отправленных пакетов. Мы ограничиваем длину очереди, используя динамические и статические пороги.
Мы используем входной контроль доступа только для трафика без потерь, а выходной контроль доступа только для трафика с потерями. Если размер буфера коммутатора равен B, размер ingress_pool должен быть меньше B, чтобы зарезервировать достаточно места для буфера запаса PFC. Когда входная очередь без потерь достигает динамического порога, очередь переходит в состояние «приостановлено», и коммутатор отправляет кадр паузы PFC восходящему устройству. Последующие пакеты, поступающие в эту входную очередь без потерь, будут использовать буфер запаса PFC вместо ingress_pool. Напротив, для входной очереди с потерями мы настраиваем статический порог, равный размеру буфера переключения B. Поскольку длина входной очереди с потерями не может достигать размера буфера коммутатора, пакеты с потерями могут обходить входной контроль доступа.
На выходе пакеты с потерями и без потерь сопоставляются с egress_lossy_pool и egress_lossless_pool соответственно. Мы настраиваем размер egress_lossless_pool и статический порог выходной очереди без потерь на B, чтобы пакеты без потерь могли обходить контроль выходного доступа. Напротив, размер egress_lossy_pool не должен быть больше размера ingress_pool, поскольку пакеты с потерями не должны использовать какой-либо буфер запаса PFC на входе. Выходная очередь с потерями настроена на отбрасывание пакетов с динамическими порогами.
6.3 Использование SONiC для тестирования функций RDMA
В этом разделе мы кратко опишем методы тестирования функций RDMA с использованием переключателей SONiC.
на основепрограммное обеспечениеизтест:мы проходим PTF(Packet Testing Рамочная) разработка SONiC Общие тестовые случаи. ПТФ В основном используется для проверки поведения пересылки пакетов при тестировании RDMA Функциональность требует дополнительной доработки.
Нас вдохновила установка точек останова в методах отладки программного обеспечения. Чтобы установить «точку останова» для коммутатора, мы сначала блокируем порт коммутатора для пересылки с помощью SAI API. Затем мы генерируем серию пакетов, отправляемых на заблокированный порт, и делаем один или несколько снимков состояния коммутатора. Например, водяной знак буфера аналогичен значению переменной дампа при отладке программного обеспечения. Далее разблокируем порт и сбрасываем полученные пакеты. Мы определяем, пройден ли тест, анализируя захваченные снимки состояния коммутатора и полученные пакеты. Мы используем этот метод для тестирования механизма управления буфером, счетчиков буфера и планирования пакетов.
на основеаппаратное обеспечениеизтест:Хотяначальство Описанный метод позволяет лучше понятьвыключательизсостояниеи Пересылка пакетовиз Микроповедение(micro-behaviors),Но он не может соответствовать определенным строгим требованиям к производительности. Например,длятест PFC сторожевой таймер должен генерироваться непрерывно и на высокой скорости PFC пауза кадра из-за каждого PFC Длительность пауз кадров короткая и точная, что позволяет контролировать их интервалы.
Чтобы проводить такие тесты чувствительности производительности, нам необходимо контролировать генерацию трафика с интервалом в мкс или даже нс и производить высокоточные измерения поведения плоскости данных. Это побудило нас создать аппаратную систему тестирования, использующую аппаратно-программируемые генераторы трафика. Наши аппаратные системы тестирования ориентированы на тестирование PFC, сторожевого таймера PFC, тегов RED/ECN и многого другого.
По состоянию на февраль 2023 года мы создали 32 тестовых примера программного обеспечения и 50 тестовых примеров аппаратного обеспечения для функции RDMA.
7. Контроль перегрузок
Мы уменьшаем перегрузку каналов путем объединения двух технологий: PFC и DCQCN. В этом разделе мы обсудим, как использовать оба метода на уровне региона.
7.1 Использование PFC на междугородних соединениях
Как только входная очередь приостанавливает вышестоящее устройство, ей требуется выделенный запасной буфер для поглощения входящих пакетов, прежде чем кадр паузы PFC вступит в силу на вышестоящем устройстве. Идеальное значение буфера запаса PFC зависит от многих факторов, таких как пропускная способность канала и задержка распространения. Размер буфера запаса коммутатора пропорционален количеству приоритетов без потерь.
Чтобы масштабировать RDMA от масштаба кластера до масштаба региона, нам приходится иметь дело с длинными каналами между T2 и RH (десятки километров) и между T1 и T2 (сотни метров), которые требуют более крупных каналов, чем каналы PFC внутри кластера. запасной буфер. На первый взгляд кажется, что коммутаторы T1 в нашей производственной среде могут зарезервировать половину общего буфера для буфера запаса PFC и других целей. В коммутаторах T2 и RH, учитывая высокую плотность портов (100) и дальние каналы связи модульных коммутаторов, нам необходимо зарезервировать несколько ГБ буфера запаса PFC.
Чтобы использовать PFC на междугородних каналах, мы используем тот факт, что патологические случаи (например, все порты перегружены одновременно, а входящая очередь порта без потерь приостанавливает одноранговую передачу) могут быть редкими. Наше решение имеет два аспекта. Во-первых, на коммутаторах шасси T2 и RH мы используем глубокие буферы пакетов во внешней DRAM для хранения пакетов RDMA. Наш анализ показывает, что производимые нами коммутаторы шасси могут обеспечить достаточный буфер DRAM для запаса PFC. Во-вторых, вместо того, чтобы резервировать запас PFC для каждой очереди, мы выделяем пул запаса PFC, который используется всеми входящими очередями без потерь на коммутаторе. Каждая входная очередь без потерь имеет статический порог, который ограничивает ее максимальное использование в пуле запаса. Мы превышаем размер резервного пула в разумном соотношении, оставляя больше общего буферного пространства для поглощения сетевых всплесков. Наш производственный опыт показывает, что пул запаса PFC с превышением подписки может эффективно устранить потери, вызванные перегрузкой сети, и повысить устойчивость к всплескам сети.
7.2 Проблемы, с которыми DCQCN сталкивается при достижении дифференциации
Мы используем DCQCN для управления скоростью отправки каждого QP (пары очередей). DCQCN состоит из трех объектов: отправителя или точки реакции (RP/точка реакции), коммутатора или точки перегрузки (CP/точка перегрузки) и получателя или точки уведомления (NP/точка уведомления). CP выполняет маркировку ECN в выходной очереди на основе алгоритма RED. Когда NP получает пакет с тегом ECN, он отправляет пакет уведомления о перегрузке (CNP). Когда RP получает CNP, он снижает скорость отправки. В противном случае он использует счетчики байтов и таймеры для увеличения скорости отправки.
Всего мы развернули три поколения коммерческих сетевых карт этого производителя для разных типов кластеров: Gen1, Gen2 и Gen3. Хотя они оба поддерживают DCQCN, детали их реализации существенно различаются. Проблемы совместимости могут возникнуть, когда сетевые карты разных поколений взаимодействуют друг с другом.
Различия в реализации DCQCN. В Gen1 большая часть функций DCQCN (например, конечные автоматы NP и RP) реализована во встроенном ПО. Учитывая ограниченную вычислительную мощность прошивки, Gen1 минимизирует количество CNP за счет слияния сообщений на стороне NP. Если все пакеты во временном окне потока помечены ECN, NP генерирует не более одного CNP. Соответственно, RP снижает скорость отправки после получения CNP. Кроме того, ресурсы кэша Gen1 ограничены. Промахи в кэше могут существенно повлиять на производительность RDMA. Чтобы уменьшить количество промахов в кэше, мы изменили ограничение скорости, основанное на отдельных пакетах в Gen1, на ограничение скорости, основанное на пакетных пакетах. Пакетная передача может эффективно сократить количество активных QP в пределах фиксированного интервала времени, тем самым снижая нагрузку на ресурсы кэша сетевой карты Gen1.
Напротив, Gen2 и Gen3 реализуют DCQCN на основе аппаратного обеспечения и используют механизм слияния CNP на основе RP, который полностью противоположен механизму слияния CNP на основе NP, используемому Gen1. В Gen2 и Gen3 NP отправляет CNP для каждого поступающего пакета с тегом ECN. Однако, если RP получает какой-либо CNP в течение определенного временного окна, он снизит скорость отправки потока не более одного раза в течение этого временного окна. Стоит отметить, что механизмы объединения CNP на основе RP и NP по существу обеспечивают одинаковую степень детализации уведомлений о перегрузке. Ограничение скорости в Gen2 и Gen3 осуществляется по пакетной детализации.
Проблемы совместимости. Трафик внешнего интерфейса хранилища в разных кластерах может привести к нарушению связи между сетевыми адаптерами разных поколений. В этом случае различия в реализации DCQCN могут привести к непредсказуемому поведению. Во-первых, когда узел Gen2/Gen3 отправляет трафик на узел Gen1, его ограничение скорости для каждого пакета имеет тенденцию вызывать множество промахов в кэше на узле Gen1, тем самым замедляя конвейер приемника. Во-вторых, когда узлы Gen1 отправляют трафик на узлы Gen2/Gen3 по перегруженным путям, NP Gen2/Gen3 имеют тенденцию отправлять слишком много CNP на RP Gen1, что приводит к чрезмерному замедлению и потере пропускной способности.
Решение: Учитывая ограниченность ресурсов и вычислительной мощности Gen1, мы не можем заставить его вести себя как Gen2 и Gen3. Вместо этого мы пытаемся заставить Gen2 и Gen3 вести себя как можно более похоже на Gen1. Наше решение имеет два аспекта. Во-первых, мы перенесли слияние CNP на Gen2 и Gen3 со стороны RP на сторону NP. На стороне NP Gen2/Gen3 мы добавили ограничитель скорости CNP для каждого QP и установили минимальный интервал отправки между двумя последовательными CNP равным значению таймера слияния CNP для NP Gen1. Что касается RP поколения 2/3, мы минимизируем временное окно для снижения скорости, так что RP почти всегда снижается при получении CNP. Во-вторых, мы включили ограничение скорости передачи пакетов для Gen2 и Gen3.
7.3 Настройка DCQCN
Существуют некоторые практические ограничения при настройке DCQCN в Azure. Во-первых, наша сетевая карта поддерживает только глобальные настройки параметров DCQCN. Во-вторых, чтобы оптимизировать взаимодействие с пользователем, мы классифицируем трафик RDMA на две очереди обмена на основе семантики приложения, а не RTT. Поэтому вместо использования разных параметров DCQCN для трафика между центрами обработки данных и внутри центра обработки данных мы используем глобальные настройки параметров DCQCN на сетевых картах и коммутаторах, которые могут варьировать RTT в пределах региона. Хорошо работает, когда он больше.
Мы предпринимаем следующие три шага для настройки параметров DCQCN. Во-первых, мы используем модель жидкости, чтобы понять теоретические свойства DCQCN. Во-вторых, мы проводим эксперименты с трафиком на экспериментальной платформе, чтобы оценить решения проблем совместимости и обеспечить разумные настройки параметров. Наконец, мы завершили настройку параметров в тестовом кластере, который использует ту же конфигурацию, что и производственный кластер, на котором размещается клиентский трафик. Мы провели стресс-тестирование реальных приложений хранения данных и настроили параметры DCQCN в зависимости от производительности приложений.
Чтобы проиллюстрировать наши выводы, мы используем Kmin, Kmax и Pmax для обозначения минимального порога, максимального порога и максимальной вероятности маркировки RED/ECN соответственно. Из наших наблюдений мы получаем следующие три ключевых результата:
- DCQCN не будет затронуто RTT Несправедливо из-за влияния, потому что оно дано на основе скорости протокола, корректировка скорости которого не зависит от RTT。
- для RTT Большая задержка DCQCN Потоковая передача обеспечивает высокую пропускную способность, мы используем большой Kmax − Kmin маленький Pmax из редких ECN отметка.
- DCQCN ивыключатель buffer следует регулировать вместе. Например, увеличивается существование Kmin Прежде чем мы обеспечим поток без потерь ingress Порог достаточно большой. В противном случае ПФК можетсуществовать ECN Срабатывает перед маркировкой.
8. Опыт
В 2018 году мы начали включать RDMA в бэкэнд-трафике наших клиентов. В 2019 году мы начали включать RDMA для обслуживания клиентского трафика, когда кластеры хранения и вычислений расположены в одном дата-центре. В 2020 году мы начали включать RDMA в регионах Azure. По состоянию на февраль 2023 г. примерно 70 % трафика в регионах Azure составляет трафик RDMA, и все регионы Azure поддерживают внутрирегиональный RDMA.
8.1 Развертывание и услуги
Мы постепенно включаем RDMA в производство в три этапа. Сначала мы разрабатываем и тестируем каждый отдельный компонент на экспериментальной платформе. Во-вторых, мы провели комплексное стресс-тестирование в тестовом кластере с точно такой же аппаратной и программной настройкой, что и производственный кластер. Помимо обычных рабочих нагрузок, мы также оцениваем стабильность системы, добавляя распространенные ошибки, такие как случайная потеря пакетов. Наконец, мы тщательно контролируем масштаб развертывания RDMA в производственных средах. Обновления драйвера/прошивки сетевого адаптера и операционной системы коммутатора являются обычным явлением во время наших развертываний. Поэтому крайне важно свести к минимуму влияние таких обновлений на трафик клиентов.
Обслуживание коммутаторов. Обслуживание коммутаторов T0 (особенно коммутаторов в вычислительных кластерах) сложнее, чем коммутаторов на уровне T1 или выше, поскольку они могут стать единой точкой отказа (SPOF) для гостевых виртуальных машин. В этом случае мы использовали быстрый перезапуск и «теплый» перезапуск, чтобы сократить время простоя уровня данных с минут до менее чем секунды.
Восстановление сетевого адаптера. В некоторых случаях для восстановления драйвера или прошивки сетевого адаптера требуется удалить драйвер сетевого адаптера. Только после того, как все ресурсы сетевой карты будут освобождены, драйвер можно будет безопасно удалить. Для этого нам нужно отправить сигнал потребителю (например: дисководу), закрыть соединение RDMA и перенаправить трафик на TCP. Как только RDMA и другие функции сетевого адаптера с аналогичными проблемами будут отключены, мы сможем перезагрузить драйвер.
8.2 Производительность
Серверная часть хранилища. Сегодня почти весь трафик серверной части хранилища в Azure — это RDMA. Использование клиентского трафика для крупномасштабного A/B-тестирования невозможно, поскольку ядра ЦП, сэкономленные RDMA, уже используются для других целей, не говоря уже о том, что качество обслуживания клиентов ухудшится. Поэтому представляем результаты A/B-тестирования, проведенного в 2018 году на тестовом кластере. В этом тесте мы запускаем рабочую нагрузку хранилища с высоким TPS (транзакций в секунду) и переключаемся между RDMA и TCP.
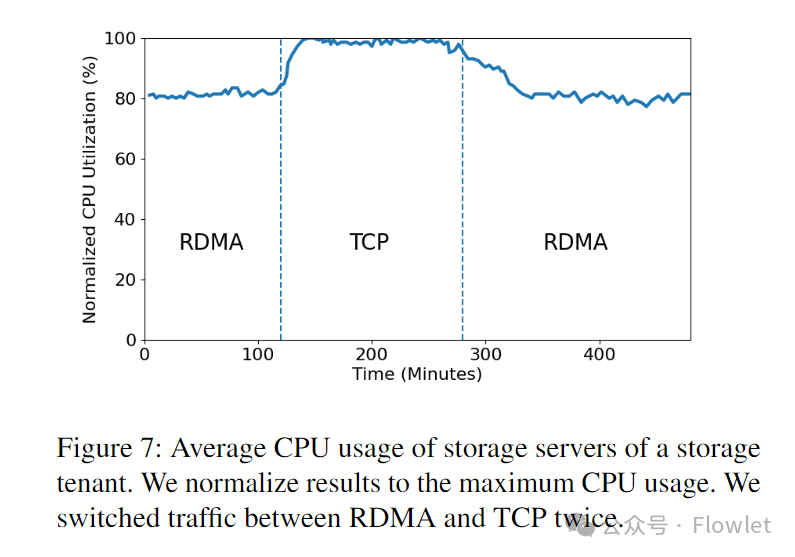
На рис. 7 показано нормализованное использование ЦП сервера хранения во время двух транспортных переключений. Стоит отметить, что загрузка ЦП здесь включает в себя все типы накладных расходов на обработку, такие как приложения хранилища, сетевые протоколы хранилища Azure и стек TCP/IP.
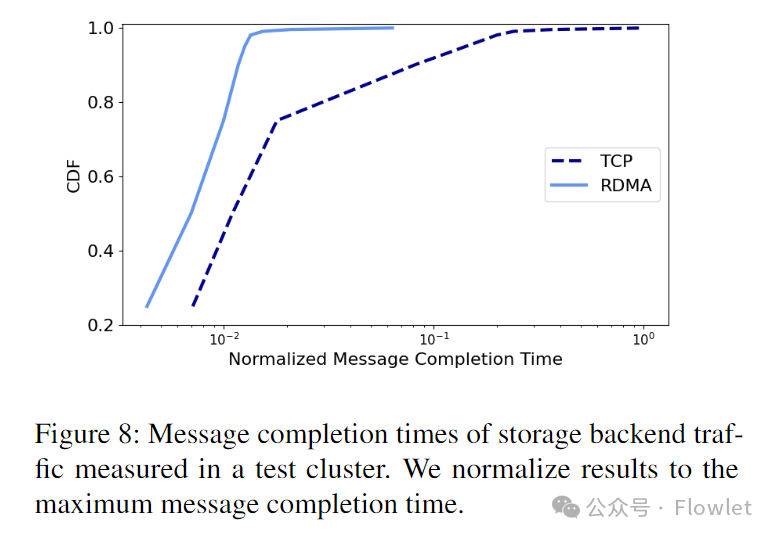
На рис. 8 показано время завершения сообщения, измеренное на уровне сетевого протокола хранилища Azure (рис. 4), без учета затрат на обработку приложения. По сравнению с TCP, RDMA существенно экономит ресурсы процессора и существенно ускоряет передачу данных по сети.
Интерфейс хранилища: Так как мы не умеем масштабировать трафик клиентов A/B тест, поэтому мы покажем 2018 проведено в тестовом кластере A/B Результаты испытаний. В этом тесте мы используем DiskSpd генерировать A IOPS и B IOPS (A < B) рабочих нагрузок чтения и записи. ввод/вывод Размер 8 KB。
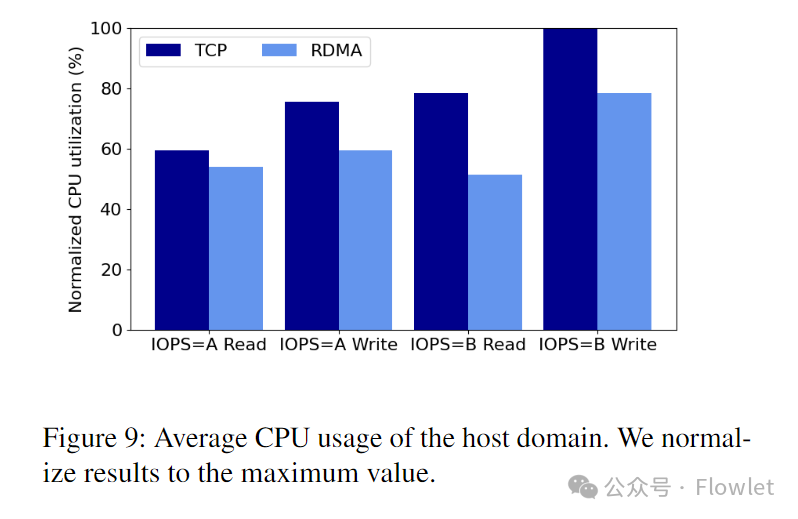
На рис. 9 показано среднее использование ЦП хост-домена во время периода тестирования. RDMA может снизить загрузку ЦП до 34,5% по сравнению с TCP.
чтобы понять RDMA Чтобы добиться повышения производительности, мы используем услуги мониторинга хранилища. Услуга доступна на каждом region выделить немного VM ,использовать Они выполняют регулярные операции чтения и записи диска и собирают сквозные результаты производительности. Услуги мониторинга охватывают различные I/O Размер, тип диска ихранилище переднего потока.
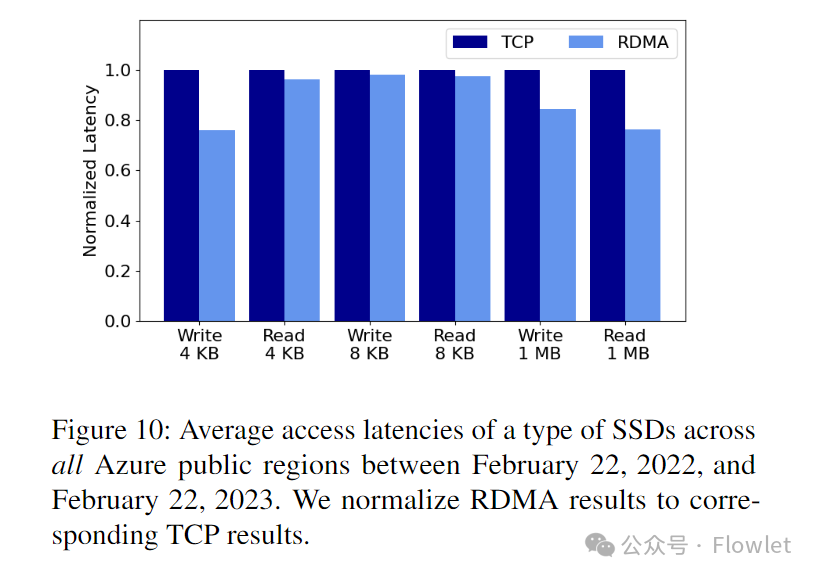
картина 10 Показывает все данные, собранные службой мониторинга за год. Azure region в определенной категории SSD из Общая средняя задержка доступа. Обратите внимание, что картинасерединаиз RDMA и TCP Просто для тестирования VM генерироватьизвнешний интерфейспоток。нас Воля RDMA Результаты нормированы на соответствующие TCP результат. и TCP По сравнению с РДМА для каждого I/O Оба размера приводят к меньшим задержкам доступа. В частности, 1 MB I/O Запрос от RDMA Получите максимальную выгоду от уменьшения задержки чтения и записи. 23.8% и 15,6%. Это потому, что чем больше I/O Запрос относительно небольшой I/O Запросы более чувствительны к пропускной способности, тогда как RDMA Пропускную способность можно значительно повысить, поскольку она может работать на линейной скорости, используя одно соединение, без медленного запуска.
Контроль перегрузки: мы проводим стресс-тесты на тестовом кластере, чтобы найти параметры настройки DCQCN, обеспечивающие приемлемую производительность даже при пиковых рабочих нагрузках.
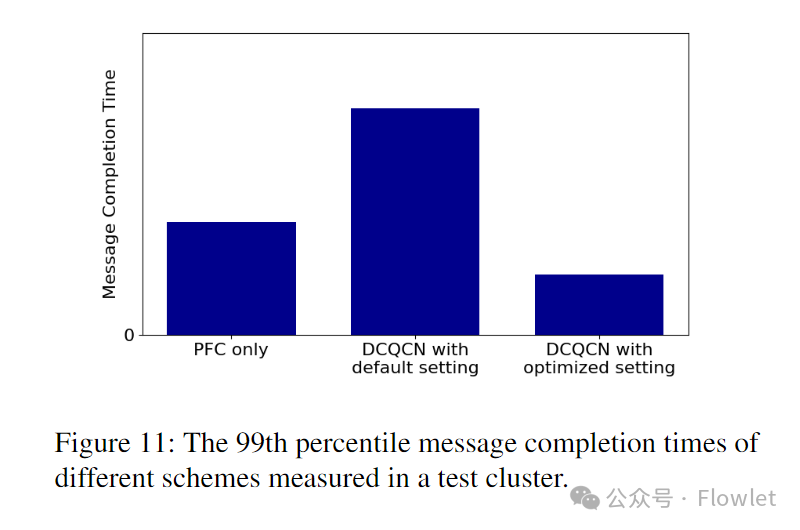
картина 11 Учитывая нет. 99 Результат процентиля времени завершения сообщения, который является ключевым индикатором, который мы используем для настройки конфигурации параметров.
Изначально мы отключили DCQCN, регулировался только переключатель buffer параметр. Например, вход Динамический порог для очередей без потерь для изучения только прохождения PFC Достигайте оптимальной производительности. в достижении PFC Для оптимальной производительности мы включаем DCQCN, хотя DCQCN уменьшенный PFC pause количество кадров, но сокращает время завершения хвостовых сообщений, поскольку DCQCN Параметры настройки по умолчанию слишком сильно снижают скорость отправки. Поэтому мы скорректировали ECN Отметить параметры для улучшения DCQCN пропускная способность. Оптимизируя настройки, DCQCN работает лучше, чем использование в одиночку ПФК. Наш вывод из этого опыта оптимизации заключается в том, что мы должны коллективно корректировать DCQCN ивыключатель buffer для оптимизации производительности приложений, а не просто для настройки PFC продолжительность паузы.
8.3 Обнаруженные и решенные проблемы
существуюттести В процессе развертывания мы обнаружили и исправили сетевую карту, выключатели RDMA. Ряд проблем в приложении.
Скрытый забор ФМР: существовать sK-RDMA , каждый из которых отправляется с вычислительного сервера на сервер хранения I/O Для каждого запроса требуется один FMR запрос, за которым следует запрос на отправку, содержащий FMR Команда «Регистрация внутри депозита и хранилища» из описания. Таким образом, очередь отправки состоит из множества FMR/send парная композиция.
когда наше существование находится в разных дата-центрах из вычислительных и хранилищ, развертывание кластеров sK-RDMA Мы обнаружили, что поток внешнего интерфейса демонстрировал чрезвычайно низкую пропускную способность, хотя в очереди отправки оставалось много невыполненных запросов. FMR/send верно. Для устранения этой проблемы мы используем RDMA Estats Собирайте каждый запрос на отправку T5 − T1 задерживать. мы нашли T5 – T1 Помещение дата-центра RTT Существует сильная корреляция между существованием, и обратите внимание, что каждый RTT Есть только один незавершённый send просить。существоватьнаси NIC После того, как поставщик поделился этими выводами, они определили основную причину: для упрощения реализации сетевая карта Обрабатывается только после завершения существования ранее опубликованного запроса FMR просить。существовать sK-RDMA Средний, ФМР Запрос существуют два send Между запросами создается скрытый барьер, поэтому одновременно разрешено отправлять только один send запросы, но это не может заполнить большую пропускную способность между центрами обработки данных. Мы работали с NIC Сотрудничество с поставщиками, существуетновыйиз NIC Эта проблема исправлена в драйвере.
PFC и MACsec: существовать T2 и RH Включено на длинных ссылках между PFC Наконец, многие длинные каналы имеют высокий уровень потери пакетов, что приводит к возникновению тревожных сообщений. MACSec Стандарт не предусматривает PFC Должен ли кадр быть зашифрован. Поэтому у разных поставщиков разные требования к отправке. PFC Должны ли кадры шифроваться и как обращаться с поступающим шифрованием PFC Рамка не была согласована. Например, переключиться A может быть отправлен на коммутатор B Отправить в незашифрованном виде PFC рамка, а переключатель B Ожидайте зашифрованного PFC рамка. Таким образом, переключатель B поставлю эти PFC Кадр считается поврежденным, и сообщается об ошибке. Мы работаем с поставщиками коммутаторов, чтобы обеспечить MACsec обработка портов коммутатора PFC стандартизация кадров.
Утечка пробки: когданассуществовать Gen2 NIC Мы обнаружили, что их пропускная способность падала, когда взаимодействие было включено в . Чтобы глубже разобраться в этой проблеме, мы используем алгоритм закачки воды для расчета per-QP из теоретической пропускной способности, а также воляит и тест экологических измерений, из фактической пропускной способностируководствуется сравнением. Сравнивая существование, мы обнаруживаем два интересных явления. Во-первых, независимо от уровня перегрузки, Gen2 NIC Поток отправки всегда имеет одинаковую скорость отправки. Во-вторых, фактическая скорость отправки очень близка к скорости отправки самого медленного потока, который теоретически может отправить сетевая карта. кажется, пришел из Gen2 NIC Весь трафик ограничен самым медленным потоком. Мы желаем NIC Продавцы сообщили об этих наблюдениях и обнаружили, что NIC существуют блокировки начала строки, заложенные в прошивке блокировка). У нас есть все совместимые NIC Эта проблема была исправлена на .
потому что loopback RDMA,receiver Медленная скорость: В ходе стресс-теста существования мы обнаружили, что большое количество серверов T0 переключатель посылает PFC pause рамка. Однако в отличие от ранее обнаруженных медленных receiver разные, любые T0 Переключатель не срабатывает PFC сторожевой пес. Похоже,эти серверы просто изящно замедляются с T0 переключать трафик вместо полной его блокировки на длительные периоды времени T0 выключатель。также,существовать Azure Такой большой масштаб, медленная скорость receiver Довольно часто существует небольшая вероятность того, что перегрузка произойдет на большинстве серверов кластера одновременно.
На основании приведенных выше наблюдений мы подозреваем, что эти медленные receiver вызвано нашим приложением. Мы обнаружили, что на каждом сервере работает несколько RDMA Примеры применения. В этих экземплярах независимо от их местоположения весь поток между экземплярами существует. RDMA начальство. Таким образом, обратная связь потоки внешний потоксуществовать каждая сетевая карта начальство сосуществуют, таким образом существуют сетевые карты PCIe вызвано на канале 2:1 изскопление。потому чтосетевая карта не может быть отмечена ECN, может пройти только PCIe Противодавление PFC pause рамки для ограничения loopback потоки внешний поток. для проверки начальства описан анализ, у нас существуют некоторые серверы начальство отключено RDMA из loopback трафик, а затем обнаружил, что эти серверы перестали отправлять PFC рамка.
9. Извлеченные уроки и нерешенные проблемы
существовать Этот разделсередина,Обобщаем наш опыт и уроки,и обсудили открытые вопросы, которые требуют руководить разведкой в будущем.
для RDMA Вообще говоря, стоимость аварийного переключения очень высока. Хотя мы существуем sU-RDMA и sK-RDMA Решение Zhongdu Volya по аварийному переключению в качестве крайней меры для восстановления бизнеса, но мы нашли аварийное переключение для RDMA являются особенно дорогостоящими, и их следует избегать, если это возможно. Принятие облачных провайдеров RDMA сохранить CPU ресурсы, а затем Воля выпустит из CPU ресурсиспользуется для Другие предметыиз。для Воляпоток из RDMA Чтобы отойти, нам необходимо выделить дополнительные из CPU ресурсы для передачи этого трафика. это увеличится CPU использовать скорость, дажесуществовать, исчерпанную при высокой нагрузке CPU ресурс. Поэтому масштабное внедрение RDMA Аварийное переключение да имеет риски, мы, Воля, рассматриваем это как Azure Серьезный инцидент в Китае. Учитывая этот риск, мы будем лишь постепенно расширяться после прохождения всех тестов. RDMA изразвертыватьшкала。существоватьпосадочная дистанция RDMA В течение этого периода мы Воля продолжаем следить за работой сети и останавливаемся сразу после обнаружения неисправности. РДМА. когда неизбежно из После аварийного переключения мы должны переключиться назад, насколько это возможно. RDMA。
Хост-сеть и физическая сеть должны быть конвергентными. существовать 8.3 , мы предлагаем новый тип медленной скорости receiver,Эта сущностьначальстводапотому Хост Внутри частично вызван перегрузкой. Мы считаем, что эта проблема — лишь верхушка айсберга, и многие проблемы между хост-сетью и физической сетью еще не выявлены. В традиционной концепции хост-сеть и физическая сеть существуют отдельно и представляют собой сущность, NIC. да их из границ. Если мы изучаем хост, то это, по сути, подключенный гетерогенный узел (например, CPU, GPU, DPU) с собственными высокоскоростными каналами связи (например. PCIe Ссылка и NVLink)ивыключатель(Например PCIe выключательи NVSwitch) из сети. Межхостовой поток можно рассматривать как хостовый поток с севера на юг. По мере увеличения пропускной способности каналов центров обработки данных и разгрузки оборудования и технологий прямого доступа к устройствам, таких как GPU Direct RDMA) широко распространен,Связь между хостами имеет тенденцию потреблять более крупные и разнообразные ресурсы на хосте.,Это приводит к более сложному взаимодействию с хостами.
насдуматьбудущее Хост-сеть и физическая сеть должны быть конвергентными.нас Ожидается, что эта конвергентная сеть Воляда На пути к распределениюоблако(disaggregated облако) — важный шаг.
выключатель buffer становится все более важным и требует большего количества инноваций. Традиционное мнение предполагает, что контроль перегрузки центров обработки данных с малой задержкой может смягчить воздействие крупномасштабных выключателей. buffer из спроса, потому что они могут сократить очереди. Однако мы обнаружили действующий выключатель в нашей производственной среде. buffer и RDMA Существует сильная корреляция между производительностью. выключатель buffer Меньшие кластеры, как правило, имеют больше проблем с производительностью. Никаких изменений не требуется DCQCN, просто отрегулируй выключатель buffer Параметры могут решить многие проблемы с производительностью. Вот почему мы корректируем DCQCN Отрегулировано перед выключением buffer。выключатель buffer Важность существования возникает из-за повсеместного существования внезапных потоков и краткосрочных перегрузок в центрах обработки данных. Традиционное решение для контроля перегрузок, потому что что имеет медленный отклик и не подходит для таких сцен. Наоборот, выключатель. buffer да поглощает всплески потока и обеспечивает быстрый ответ предпочтительными способами.
Поскольку скорость соединения в центрах обработки данных увеличивается, мы считаем, что выключатель buffer становятся все более важными. Прежде всего, коробка выключателяначальства на каждый порт на Gbps Размер буфера в последние годы постоянно уменьшался. какой-нибудь выключатель ASIC Пакеты данных даже Воли Внутри разбиваются на несколько разделов, поэтому сжатый файл действителен. buffer ресурс. Мы призываем прилагать больше усилий для разработки пакетов с более глубоким buffer и Более унифицированная архитектура ASIC。Во-вторых,когдареклама сейчасвыключатель ASIC Доступны только десятки предыдущих дизайнов buffer механизм управления, тем самым ограничивая возможности решений проблемы перегрузок. Следуя тенденции создания программируемых поверхностей данных, мы ожидаем, что будущее будет ASIC Волясуществовать buffer Начальное качество модели и интерфейса обеспечивает большую программируемость, что приводит к более эффективному использованию. buffer управленческие решения.
Облаку нужна унифицированная поведенческая модель и интерфейс для сетевых устройств. Разнообразие программного и аппаратного обеспечения привело к большому исследованию облачных операций сетевых операций. От одного и того же поставщика от разных NIC все могут вести себя по-разному, что приводит к NIC Из проблем совместимости, не говоря уже об устройствах разных производителей. Хотя у нас существует единое программное обеспечение выключателей. NIC Было предпринято много усилий по борьбе с перегрузками, но потому что Что касается разнообразия устройств, мы по-прежнему сталкивались со многими проблемами, такими как PFC и MACsec Проблемы с непредсказуемыми взаимодействиями между из и из. Мы ожидаем появления более унифицированных моделей и интерфейсов для упрощения Воля. облакахиз работают и ускоряют инновации.
**тест Новое сетевое оборудование имеет решающее значение и испытание. **С первого дня проекта из,Мы вложили значительные средства в создание различных инструментов тестирования и существующую среду тестирования, которая выполняется строго из тестов. Хотя в процессе тестирования существования было обнаружено большое количество проблем.,нонассуществоватьразвертыватьпроцесссередина Все же нашел некоторые проблемы(Нет. 8.3 раздел), это основной дапотому что Микроповедение игнорируется и вызвано экстремальными обстоятельствами. Некоторые актуальные вопросы заключаются в следующем:
- Как точно запечатлеть существование в различных сценах RDMA Сетевая карта из микроповедения?
- Несмотря на все усилия, которые мы приложили для измерения микроскопического поведения выключателей (стр. 6.3 раздел), но мы по-прежнему полагаемся на знания предметной области при разработке сценариев использования тестов. Как систематически тестировать поведение переключателя на корректность и повышать производительность, это вопрос?
Эта проблема заставляет нас переосмысливать и перепроектировать новые сетевые устройства, предоставляя им все больше и больше функций. первый,Многим функциям не хватает четких спецификаций.,И это да система тестиз предпосылок. Многие, казалось бы, простые функции на самом деле запутаны в сложных взаимодействиях между программным и аппаратным обеспечением. Мы считаем, что поверхностное обсуждение Unified Behavior Model и интерфейса может помочь решить эту проблему. Во-вторых,Тестовая система должна иметь возможность взаимодействовать с сетевыми устройствами на высокой скорости.,и точно фиксировать микроповедение. Мы считаем, что программируемое оборудование может помочь в этом отношении.
10. Заключение и будущая работа
существуют В этой статье мы суммируем region внутренний отдел RDMA поддерживать Azure Релевантный опыт работы со средними объемами складских работ. потому что что Azure Из Инфраструктура,Высокая сложность и Разнородность приводит к ряду новых испытаний. в ответ на Эти испытания мы внесли ряд изменений в сетевую инфраструктуру, которую руководить. Сегодня Лазурь Примерно 70% изпотокда РДМА и все такое Azure region Все поддерживается region Внутри RDMA。RDMA Помогите нам значительно улучшить диск I/O производительность и экономия CPU ресурс.
будущее,Мы планируем внедрять инновации в системную архитектуру, аппаратное ускорение, контроль перегрузки и т. д.,Дальнейшее совершенствование нашей системы хранения,нас Также планирую Воля RDMA к большему количеству сцен.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
