Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле
💡💡💡В этой статье проводятся самоисследования, инновации и улучшения: SPPF сочетается с перцептивной сверткой большого ядра UniRepLK, сверткой большого ядра + нерасширения, так что SPPF добавляет большое ядро, улучшает рецептивное поле и, в конечном итоге, повышает точность обнаружения.
1.SPP &SPPFпредставлять
YOLOv5 изначально принял структуру SPP и начал использовать SPPF после версии v6.0 (репозиторий). Основная цель — интеграция более масштабной (глобальной) информации. YOLOV8 использует SPPF Автор сравнивает SPP и SPPF, SPPF может достигать более высоких скоростей и меньшего количества FLOP, не влияя на mAP.

Слева — СПП, справа — СППФ.
2. Введение в принципы улучшения

бумага:https://arxiv.org/pdf/2311.15599.pdf
Аннотация: Сверточные нейронные сети с большим ядром (ConvNet) в последнее время привлекли к себе широкое внимание исследователей, но есть две ключевые нерешенные проблемы, которые требуют дальнейших исследований. 1) Архитектура существующей ConvNet с большим ядром во многом соответствует принципам проектирования традиционных ConvNet или Transformer, но архитектурный проект ConvNet с большим ядром до сих пор не решен. 2) Поскольку Transformer доминирует во многих модальностях, еще предстоит изучить, обладает ли ConvNet сильными общими возможностями восприятия в других областях, кроме зрения. В этой статье мы вносим свой вклад в двух аспектах. 1) Мы предложили четыре архитектурных принципа для проектирования ConvNet с большим ядром. Суть их заключается в том, чтобы использовать преимущества основных характеристик, которые отличают большие ядра от маленьких — глядя широко, но не глубоко. Следуя этим рекомендациям, предлагаемая нами ConvNet с большим ядром демонстрирует ведущие результаты в распознавании изображений. Например, наша модель достигает 88,0% точности ImageNet, 55,6% ADE20K mIoU и 56,4% COCO box AP, демонстрируя лучшую производительность и более высокую скорость, чем некоторые недавно предложенные сильные конкуренты. 2) Мы обнаружили, что большие ядра являются ключом к достижению превосходной производительности в тех областях, где ConvNet изначально не очень хорош. Благодаря определенным методам предварительной обработки, связанным с модальностью, предлагаемая модель достигает современной производительности в задачах прогнозирования временных рядов и распознавания звука даже без настройки архитектуры с учетом модальности.
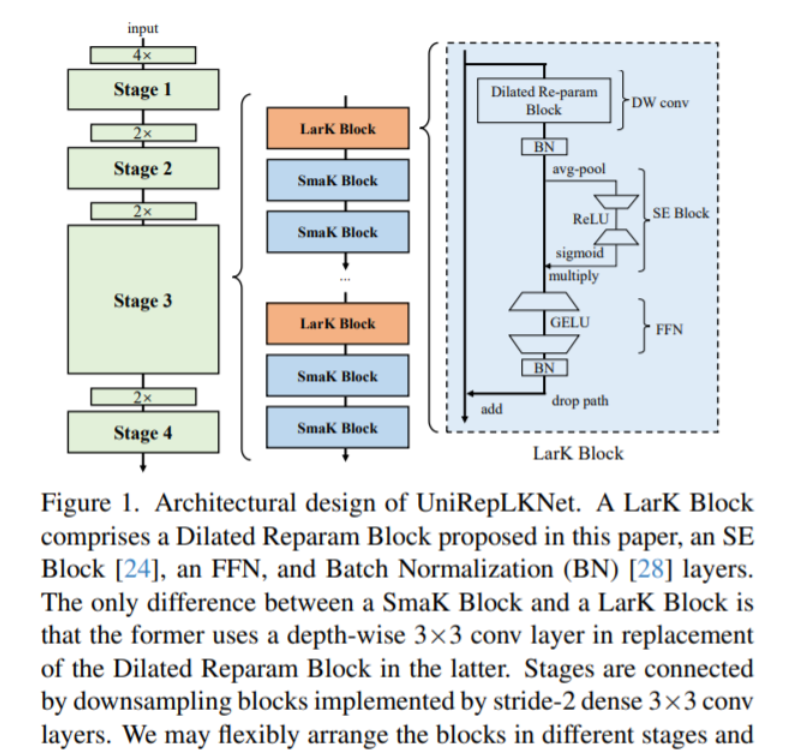
3. Принципиальная схема инноваций SPPF
Эффективное сочетание UniRepLKNetBlock и SPPF для инноваций

3.1 Инновация SPPF присоединяется к YOLOv8
3.1.1 UniRepLKNet_SPPFприсоединитьсяultralytics/nn/sppf/UniRepLKNet_SPPF.py
Основной код:
class UniRepLKNetBlock(nn.Module):
def __init__(self,
dim,
kernel_size,
drop_path=0.,
layer_scale_init_value=1e-6,
deploy=False,
attempt_use_lk_impl=True,
with_cp=False,
use_sync_bn=False,
ffn_factor=4):
super().__init__()
self.with_cp = with_cp
# if deploy:
# print('------------------------------- Note: deploy mode')
# if self.with_cp:
# print('****** note with_cp = True, reduce memory consumption but may slow down training ******')
self.need_contiguous = (not deploy) or kernel_size >= 7
if kernel_size == 0:
self.dwconv = nn.Identity()
self.norm = nn.Identity()
elif deploy:
self.dwconv = get_conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=dim, bias=True,
attempt_use_lk_impl=attempt_use_lk_impl)
self.norm = nn.Identity()
elif kernel_size >= 7:
self.dwconv = DilatedReparamBlock(dim, kernel_size, deploy=deploy,
use_sync_bn=use_sync_bn,
attempt_use_lk_impl=attempt_use_lk_impl)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
elif kernel_size == 1:
self.dwconv = nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=1, bias=deploy)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
else:
assert kernel_size in [3, 5]
self.dwconv = nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, padding=kernel_size // 2,
dilation=1, groups=dim, bias=deploy)
self.norm = get_bn(dim, use_sync_bn=use_sync_bn)
self.se = SEBlock(dim, dim // 4)
ffn_dim = int(ffn_factor * dim)
self.pwconv1 = nn.Sequential(
NCHWtoNHWC(),
nn.Linear(dim, ffn_dim))
self.act = nn.Sequential(
nn.GELU(),
GRNwithNHWC(ffn_dim, use_bias=not deploy))
if deploy:
self.pwconv2 = nn.Sequential(
nn.Linear(ffn_dim, dim),
NHWCtoNCHW())
else:
self.pwconv2 = nn.Sequential(
nn.Linear(ffn_dim, dim, bias=False),
NHWCtoNCHW(),
get_bn(dim, use_sync_bn=use_sync_bn))
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if (not deploy) and layer_scale_init_value is not None \
and layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, inputs):
def _f(x):
if self.need_contiguous:
x = x.contiguous()
y = self.se(self.norm(self.dwconv(x)))
y = self.pwconv2(self.act(self.pwconv1(y)))
if self.gamma is not None:
y = self.gamma.view(1, -1, 1, 1) * y
return self.drop_path(y) + x
if self.with_cp and inputs.requires_grad:
return checkpoint.checkpoint(_f, inputs)
else:
return _f(inputs)
def reparameterize(self):
if hasattr(self.dwconv, 'merge_dilated_branches'):
self.dwconv.merge_dilated_branches()
if hasattr(self.norm, 'running_var') and hasattr(self.dwconv, 'lk_origin'):
std = (self.norm.running_var + self.norm.eps).sqrt()
self.dwconv.lk_origin.weight.data *= (self.norm.weight / std).view(-1, 1, 1, 1)
self.dwconv.lk_origin.bias.data = self.norm.bias + (self.dwconv.lk_origin.bias - self.norm.running_mean) * self.norm.weight / std
self.norm = nn.Identity()
if self.gamma is not None:
final_scale = self.gamma.data
self.gamma = None
else:
final_scale = 1
if self.act[1].use_bias and len(self.pwconv2) == 3:
grn_bias = self.act[1].beta.data
self.act[1].__delattr__('beta')
self.act[1].use_bias = False
linear = self.pwconv2[0]
grn_bias_projected_bias = (linear.weight.data @ grn_bias.view(-1, 1)).squeeze()
bn = self.pwconv2[2]
std = (bn.running_var + bn.eps).sqrt()
new_linear = nn.Linear(linear.in_features, linear.out_features, bias=True)
new_linear.weight.data = linear.weight * (bn.weight / std * final_scale).view(-1, 1)
linear_bias = 0 if linear.bias is None else linear.bias.data
linear_bias += grn_bias_projected_bias
new_linear.bias.data = (bn.bias + (linear_bias - bn.running_mean) * bn.weight / std) * final_scale
self.pwconv2 = nn.Sequential(new_linear, self.pwconv2[1])
class SPPF_UniRepLK(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
self.UniRepLK = UniRepLKNetBlock(c_ * 4, kernel_size=k)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(self.UniRepLK(torch.cat((x, y1, y2, self.m(y2)), 1)))3.1.2 yolov8_SPPF_UniRepLK.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF_UniRepLK, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
Подробности см.: https://blog.csdn.net/m0_63774211/category_12511737.html.
от CSDN AI, маленький монстр



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.
Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
