Эффективное построение озера данных и интеграция хранилищ данных: лучшие практики для крупномасштабной архитектуры данных
Каталог статей
- Озеро данных и хранилище данных: две разные концепции
- озеро данных
- хранилище данных
- Интеграция озера данных и хранилища данных
- единый каталог данных
- Очистка и преобразование данных
- Безопасность данных и контроль разрешений
- Анализ и визуализация данных
- Преимущества интеграции озера данных и хранилища данных
- будущие тенденции
- Облачное родное озеро данных
- Автоматизированная обработка данных
- Периферийные вычисления сливаются с озером данных
- в заключение
🎉Добро пожаловать в приложение технологии облачных вычислений Столбец~Эффективное построение озера данных и интеграция хранилищ данных: лучшие практики для крупномасштабной архитектуры данных
- ☆* o(≧▽≦)o *☆Привет~Я ОНО·Чэнь Хань🍹
- ✨Домашняя страница блога:IT·Блог Чен Хана
- 🎈Эта серия статей Столбец:Приложение технологии облачных вычислений
- 📜другой Столбец:Маршрут изучения Java Советы по собеседованию на Java Практические проекты по Java AIGCИскусственный интеллект Изучение структуры данных Приложение технологии облачных вычислений
- 🍹У автора статьи ограничены навыки и уровень. Если в статье есть ошибки, надеюсь, вы их исправите🙏.
- 📜 приветствую всехсосредоточиться на! ❤️
В сегодняшний информационный век,Данные считаются одним из самых ценных ресурсов. Предприятия все чаще полагаются на данные для принятия бизнес-решений и улучшения продуктов и услуг.,и способствовать инновациям. поэтому,Постройте эффективныйданные Архитектура становится критической。В этой статье мы углубимся в то, как Постройте эффективныйозеро данных(Data Lake) и объединить его с традиционным хранилищем объединение данных для удовлетворения потребностей крупномасштабной обработки данных.
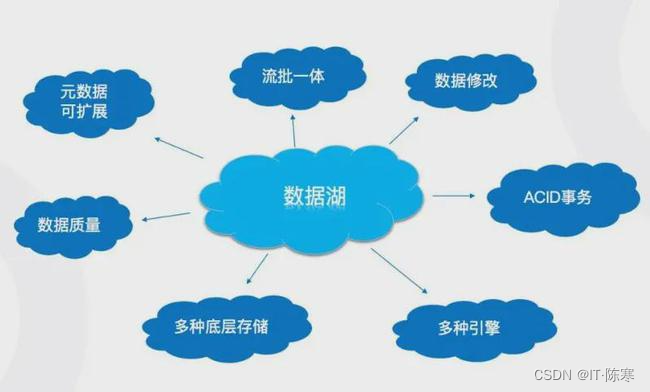
Озеро данных и хранилище данных: две разные концепции
Обсуждаем эффективность озера данныхихранилище Прежде чем сливать данные, давайте сначала разберемся с озером. данныхихранилище Основные понятия и различия данных.
озеро данных
озеро данные — это центральное хранилище для хранения огромных объемов исходных данных, которое включает в себя не только структурированные данные (например, таблицы библиотеки данных), но и неструктурированные данные (например, текстовые документы, изображения, аудио и видео и т. д.). озеро Главное преимущество данных — их Гибкость. и масштабируемость. данные могут храниться в необработанном формате без необходимости предварительного определения схемы или схемы. Это означает, что вы можете хранить любые типы данных в озере. данные, не беспокоясь о потере данных или несоответствии формата.
хранилище данных
иозеро данныхдругой,хранилище data — это хранилище для хранения очищенных, обработанных и определенных по схеме данных. хранилище данные обычно используются для поддержки бизнес-аналитики, отчетности и анализа данных. Их данные обычно организованы в табличной форме для облегчения запроса и анализа. хранилище данные обычно требуют Очистки, прежде чем данные попадут на склад. и преобразование данных, чтобы обеспечить согласованность и качество данных.
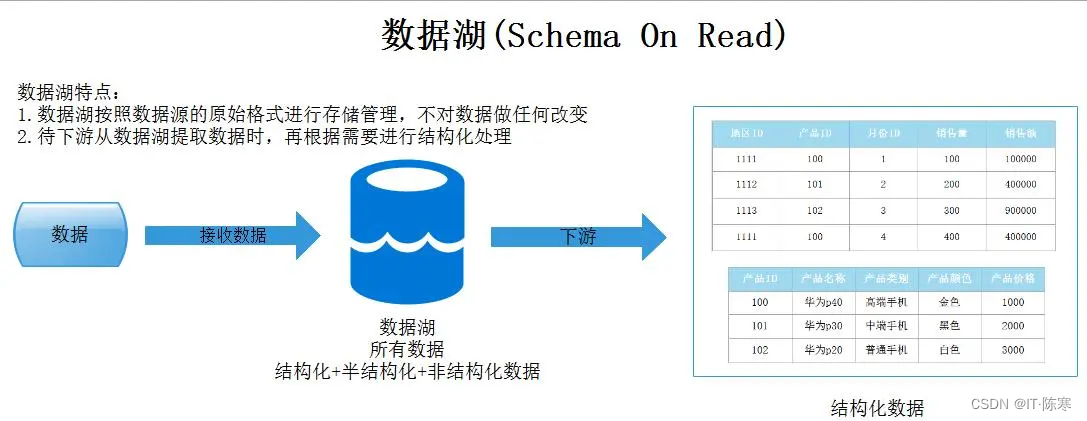
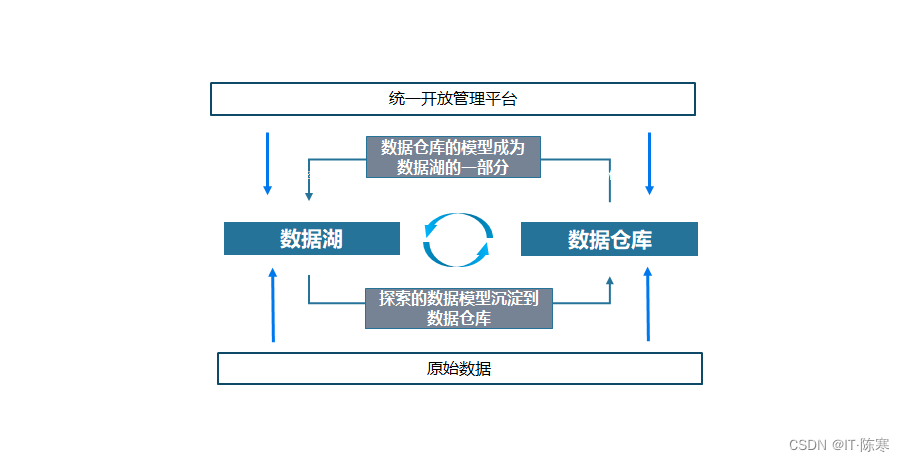
Интеграция озера данных и хранилища данных
Хотя озеро данныхихранилище данных имеют свои преимущества, но в условиях крупномасштабной обработки данных их объединение может достичь Лучшего. управление данные и анализ. Вот некоторые лучшие, которые сочетают в себе эти два практики。
единый каталог данных
Чтобы достичь озера данныхихранилище Для интеграции данных сначала требуется единый каталог данных. Каталог данных — это каталог, используемый для записи и управления хранилищем в озере. данныхихранилище Центральное расположение данных в данных. Этот каталог должен включать метаинформацию о данных, такую как источник данных, формат данных, качество данных и т. д.
# Пример кода: пример каталога данных
{
"data_source": "озеро данных",
"data_format": "Parquet",
"data_quality": "высокий",
"data_description": «Данные заказа на продажу»
}По единому каталогу данных,Вы можете легко найти и получить доступ к данным в озере данных и хранилище данных.,Не зная конкретных деталей хранения данных.
Очистка и преобразование данных
Хотя озеро данные позволяют хранить необработанные данные, но данные обычно необходимо обработать, прежде чем их можно будет использовать для анализа. и преобразование данных。Этохранилище Основная особенность данных. На озере Фьюжн данныхихранилище Когда данные можно узнать из хранилища данныхиз Очистка и преобразование обработать данные, применить их к озеру данныхсерединаизданные。
# Пример кода: Очистка и преобразование данных
# отозеро данных Получите оригиналданные
raw_data = data_lake.get_data(«Данные заказа на продажу»)
# Выполнить Очистку и преобразование данныхдействовать
cleaned_data = data_warehouse.clean_and_transform(raw_data)
# Сохраните очищенные данные в хранилище. данных
data_warehouse.store_data("Очищенные данные заказа на продажу", cleaned_data)
Безопасность данных и контроль разрешений
На озере Фьюжн данныхихранилище данных, безопасность данных и контроль доступа имеют решающее значение. Вам необходимо убедиться, что только авторизованные пользователи могут получить доступ к данным и изменить их. хранилище Данные обычно предоставляют мощные функции контроля разрешений, которые можно использовать для управления правами доступа к данным. Эти функции также можно распространить на озеро. данные для того, чтобы обеспечить озеро данные в данных полностью защищены.
Анализ и визуализация данных
один разозеро данныхихранилище слияние данных, вы можете использовать различные методы анализа и визуализация данныхинструменты для изученияианализироватьданные。Эти инструменты можно подключить к Unityизданные Оглавление,и получить данные из,Нет необходимости знать, где хранятся данные. Это делает анализ данных более гибким и эффективным.
# Пример кода: Анализ и визуализация данных
# Подключитесь к единому каталогу данных с помощью инструментов анализа.
analysis_tool.connect(data_catalog)
# Выберите данные для анализа из каталога данных.
selected_data = analysis_tool.select_data(«Данные заказа на продажу»)
# провести анализ и визуализация данныхдействовать
analysis_tool.analyze_and_visualize(selected_data)Преимущества интеграции озера данных и хранилища данных
Слияниеозеро данныхихранилище данные дают несколько преимуществ:
- Гибкость и масштабируемость:озеро данных обеспечивает гибкость хранения данных различных типов и форматов, а хранилище data обеспечивает возможность очистки и преобразования данных. В сочетании вы получаете лучшее из обоих миров.
- Лучшее управление данными:единыйизданные Оглавлениеиданные Процесс очистки помогает улучшить управлениеданные,Улучшите качество и согласованность данных.
- Более эффективный анализ данных:Анализ и визуализация Инструмент данных может легко подключаться к единому каталогу данных, обеспечивая более эффективный анализ данныхопыт。
- Более надежная защита данных:С помощьюхранилище С помощью функции контроля разрешений данных вы можете обеспечить безопасность данных, и только авторизованные пользователи смогут получить доступ к данным и изменить их.
будущие тенденции
Поскольку спрос на крупномасштабную обработку данных продолжает расти,Тенденция объединения озерных данных с хранилищами данных будет и дальше усиливаться. будущее,Мы можем ожидать появления новых инноваций и технологий.,Повысить эффективность и масштабируемость обработки данных.
Облачное родное озеро данных
Облачное родное озеро данные - это своего рода общие метод построения данных на платформе облачных вычислений. Он использует возможности облачных вычислений по гибкости и управлению ресурсами, чтобы обеспечить данными легче управлять и расширять. Будущее, облачное родное озеро данные станут озером Один из основных трендов в построении данных.
Автоматизированная обработка данных
Автоматизированная обработка данных — это метод, который использует технологии машинного обучения и искусственного интеллекта для автоматического выполнения очистки, преобразования и анализа данных. будущее,Мы можем ожидать появления новых инструментов автоматизации.,Сократить ручное вмешательство и повысить эффективность обработки данных.
Периферийные вычисления сливаются с озером данных
С развитием периферийных вычислений озеро данных будет сочетаться с периферийными вычислениями,Для поддержки обработки и анализа данных на периферийных устройствах. Это приведет к увеличению количества приложений в сфере Интернета вещей и автоматизации.
в заключение
Интеграция озера данных и хранилища Данные представляют собой важную тенденцию в области архитектуры данных. Через единый каталог данных Очистка и преобразование данных、Безопасность данных и контроль разрешений,и анализ и визуализация Благодаря применению инструментов обработки данных мы можем лучше управлять крупномасштабными данными и анализировать их. В будущем с облаками родное озеро данных、Автоматизированная обработка данныхипериферийные вычисленияизразвивать,Мы можем рассчитывать на новые инновации и прорывы в области обработки данных. Эти технологии предоставят предприятиям больше возможностей, основанных на данных.,Стимулируйте развитие бизнеса и инновации.
🧸Конец



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
