DuckDB: внутрипроцессный анализ Python для небольших данных
DuckDB — это встроенная аналитическая база данных, которая может обрабатывать неожиданно большие наборы данных без поддержки распределенной многосерверной системы. Лучшая часть? Вы можете анализировать данные непосредственно из вашего приложения Python.
Переведено с DuckDB: In-Process Python Analytics for Not-Quite-Big Data,Джоав Джексон.
Питтсбург —— Даже при анализе очень больших наборов данных кластеризация не всегда требуется. Вы можете многое упаковать в запуск с открытым исходным кодом. DuckDB На одном сервере системы базы данных околотехнологического анализа.
Это в PyCon выступал несколько раз на Демо из Заключение о том, что Демо сравнивает существование Python Анализ производительности решений был дан на конференции программистов, состоявшейся на прошлой неделе. существуют там, они сравнивали системы, например, спрашивали Dask Является ли система лучше, чем Apache Spark Скорость анализа выше.
Однако, если вы можете вообще избежать настройки распределенной системы, вы сможете избежать многих проблем с обслуживанием.
как Kevin Kho и Han Wang существовать Демо Как объяснялось в разделе , вы можете получить множество преимуществ от одной машины, если правильно ее оптимизировать. Это DuckDB миссия.
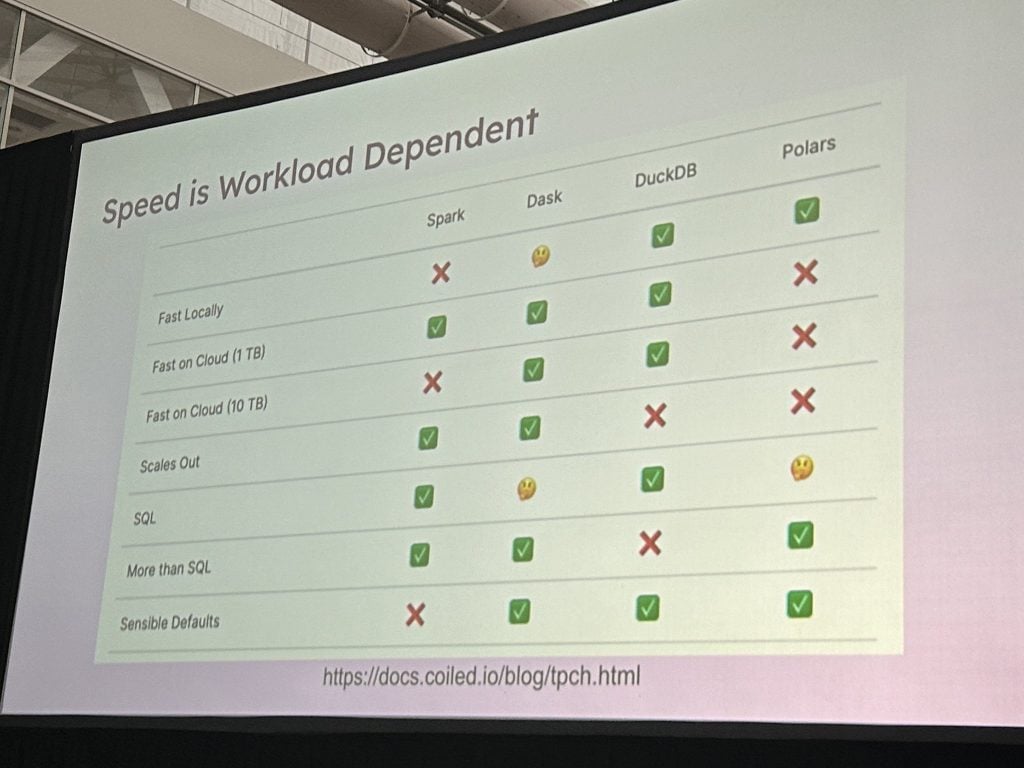
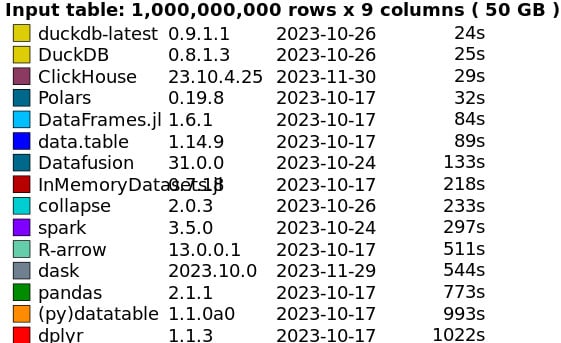
2021 Год, H20.ai существовать набор эталонов Протестировано DuckDB сравнивает скорость обработки различных аналогичных инструментов баз данных, популярных в науке о данных с открытым исходным кодом.
тестеры на 1000 Ван Син и 9 столбцы (ок. 0,5 ГБ) было выполнено пять запросов. Утка существ выполнил задание всего за две секунды. Это удивительно для одного компьютера, на котором работают изданные библиотеки. Еще более удивительно изда, что оно существует 14 Обрабатывается в течение нескольких секунд 1 Миллиарды строк (5 ГБ).
Эти цифры впечатляют, 2023 год год, DuckDB Команда возвращается и Скорректированные параметры конфигурации и обновленное оборудование.,и будет 5GB рабочая нагрузка снижается до двух секунд, при этом 0.5GB рабочая нагрузка сокращается до менее чем секунды.
это дажесуществовать 24 Обрабатывается в течение нескольких секунд 50GB загруженность - обычно Spark Зарезервировано для распределенных систем.
существовать Демо,Lyft Технический руководитель платформы машинного обучения Wang «Это ошеломляющая цифра. Улучшения ошеломляющие», — сказал он.
Тест DuckDB для систем больших данных, 2003 г.
в заключение? Wang отметим, что удивительное количество самопровозглашенных проектов в стиле «больших данных» не требуют Spark Или другие распределенные решения: они хорошо вписываются в один сервер. Принятие этого подхода устраняет множество накладных расходов на управление распределенной системой и сохраняет весь код на локальном компьютере.
Представляем DuckDB
DuckDB Много чего происходит, это существование 2018 Недавние аналитические отношения, созданные за годы SQL Система баз данных. Две вещи сразу отличают ее от других платформ данных.
- это будет SQL и Python объединить,Предоставляет язык запросов выражений для разработчиков/аналитиков.,Язык выполняется против самого процесса приложения.
- Он предназначен для работы только на одной машине. Это особенность,а не недостаток,Потому что это устраняет все сложности запуска платформы данных на распределенной платформе.
Alex Monahan существоватьдругой Pycon Демо сказал: «Как только проблема будет решена Pandas Если он слишком велик, вам придется создать огромную распределенную систему. Это как расколоть грецкий орех большим молотком. Это не эргономично. "Монэм да MotherDuck Front-end инженер-программист, компания предоставляет Duck Сервис бессерверной аналитики.
DuckDB из Два основателя——Hannes Mühleisen(Генеральный директор)и Mark Raasveldt(главный технический директор)——Основан DuckDB Labs,Обеспечить коммерческую поддержку системы данных Библиотека.,Система предназначена для обеспечения быстрого и простого в развертывании анализа среднего размера.
они начинаются с Небольшая база данных, способная Я думаю, что черпаю из этого много вдохновения. DuckDB да Списокиз SQLite без далинеиз SQLite。
Duck иметь Python стиль интерфейса, также созданный специально для научного сообщества, занимающегося данными. данные будут проанализированы, смоделированы и визуализированы. Ученые, изучающие данные, как правило, не используют Библиотеку данных, хотя полагаются на CSV Документы и другие неструктурированные или полуструктурированные источники данных. Утка Разрешение им встраивать операции с данными непосредственно в сам код.
Этот получает MIT Лицензионное программное обеспечение с открытым исходным кодом C++ Написано так, что это быстро.
DuckDB Он предназначен для быстрой работы и полного использования всех ядер и иерархий кэша сервера. и SQLite обрабатывать по одной строке за раз на основе строкового движка библиотеки Duck Возможна обработка за один раз 2048 Весь вектор строк.
Это да от Python Единая двоичная установка установщика, доступная для нескольких платформ, все из которых предварительно скомпилированы, поэтому их можно загрузить и запустить из командной строки или через клиентские библиотеки. Есть даже версия существования запустить в браузере,через веб-сборку.
Это процесс внутри приложения,и записать на диск,Это означает, что он не защищен сервером. RAM ограничения, он может использовать весь жесткий диск, таким образом обрабатывая TB уровень размера данных открывает путь. В отличие от базы данных клиент-сервер, она не использует сторонний транспортный механизм для передачи данных с сервера клиенту. Вместо этого, как SQLite Аналогично, приложение можно использовать как Python Вызов части для извлечения данных существует в одном и том же пространстве памяти.
«Вы читаете, что оно существует там, где оно существует», — объяснил Монахан.
Вы можете записывать фреймы данных в базу данных разными способами, включая определяемые пользователем функции, полную корреляцию. API、 Ibis Библиотека для одновременной записи кадров данных в несколько внутренних источников данных и PySpark, но с использованием других операторов импорта.
Как DuckDB и Python работают вместе
Помимо командной строки, он поставляется с 15 языковой клиент. Питон да – самый популярный из, но есть и Node、JBDC и ОБДК. он может читать CSV、JSON Файл, Апач Iceberg документ. Дак ДБ Можно читать изначально Pandas、Polaris и Arrow файл без копирования данных в другой формат. Только с большинством SQL В отличие от системы «изданные Библиотеки», она «существованные» сохраняет исходные данные при приеме.
«Так что это может вписаться во многие рабочие процессы», — Монахан. объяснять.
Он также может читать файлы в Интернете, в том числе с GitHub (через FTP)、Amazon S3、Azure Blob Хранение и Google Cloud Storage файл. он может выводить TensorFlow и Тензор Питорха。
DuckDB использует очень похожий на Python вариант SQL, который может автоматически принимать фреймы данных.
Монахан создал образец приложения «Hello World», чтобы проиллюстрировать:
# !pip install duckdb
import duckdb
duckdb.sql("SELECT 42").fetchall()Будет сгенерирован следующий вывод:
[(42,)]Долженданные Библиотекаиспользовать PostgreSQL в качестве основы, хотя SQL Внесли некоторые изменения,Чтобы упростить язык,Также да, чтобы расширить его функциональность.

DuckDB Расширить и упростить SQL путь (Алекс Monahan существовать Pycon речь дальше)
Большие данные мертвы?
Короче говоря, DuckDB да А имеет революционный замысел: быстрая библиотека данных, она позволяет проводить анализ на одном компьютере даже для очень больших изданных наборов. это вопросы Решения на основе больших данных необходимость.
существовать 2023 Год MotherDuck В широко распространенном посте в блоге под провокационным названием « Большие данные мертвы”,Jordan Tigani утверждает, что «большинству приложений не требуется обрабатывать большие объемы данных».
«Объем обработки, необходимый для аналитической рабочей нагрузки, почти наверняка меньше, чем вы можете себе представить», — написал он.,существуют, прежде чем инвестировать в более дорогие изданные складские библиотеки или системы распределенного анализа.,Рассмотрим сначала простое и значимое программное обеспечение для анализа, основанное на одном компьютере.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
