DMA и технология нулевого копирования для оптимизации передачи больших файлов по сети
Разработка контроллеров DMA
Нет процесса ввода-вывода контроллера DMA
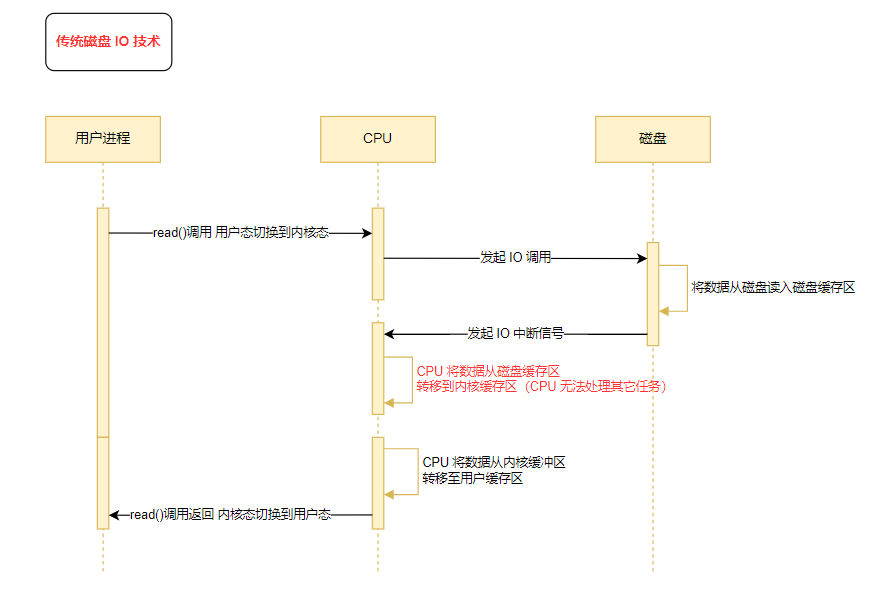
- Пользовательский процесс запущен read вызов,КОперационная системаотправлять I/O Запрос, процесс переходит в состояние блокировки;
- Операционная После того, как система получит запрос на прибытие, ЦП Выдайте соответствующие команды управления контроллеру диска, CPU Выпущен для выполнения других задач.
- После того как контроллер диска получает инструкцию, он начинает готовить данные и помещает их во внутренний буфер контроллера диска, а затем генерирует прерывание.
- После того, как ЦП получает сигнал прерывания, он считывает данные из буфера контроллера диска в регистр, а затем записывает их из регистра в буфер ядра. Во время этого процесса ЦП не может обрабатывать другие вещи.
- Когда в буфере ядра достаточно данных, ЦП копирует данные из буфера ядра в пользовательский буфер.
контроллер прямого доступа к памяти
- если CPU Передаваемые данные очень малы, поэтому проблема невелика, но если вам нужно скопировать большой объем данных, это точно невозможно, потому что CPU ресурсы очень ценны. Для решения этой проблемы появились DMA(Direct Memory Доступ, прямой доступ к памяти) технология.
- Проще говоря: в процессе I/O При передаче данных между устройствами и памятью вся работа по обработке данных передается контроллер прямого доступа к памяти,и CPU Больше не участвуйте ни в чем, связанном с передачей данных, поэтому CPU Потом можешь пойти заняться другими делами.
- использовать контроллер прямого доступа к После запоминания процесс передачи данных выглядит следующим образом:
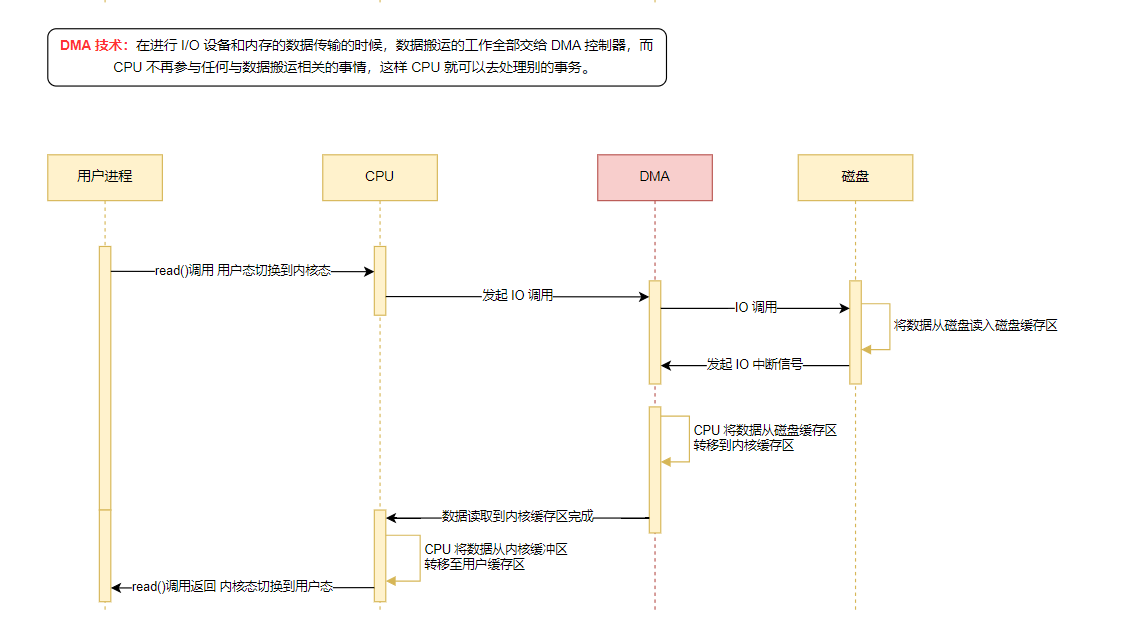
- Пользовательский процесс запущен read вызов,КОперационная системаотправлять I/O Запрос, процесс переходит в состояние блокировки;
- Операционная После того, как система получит запрос на прибытие, ЦП Отправить запрос на DMA , CPU Выпущен для выполнения других задач.
- DMA дальше I/O Запрос на отправку дискового контроллера, После того как контроллер диска получает инструкцию, он начинает готовить данные и помещает их во внутренний буфер контроллера диска, а затем генерирует прерывание.
- После получения сигнала прерывания DMA копирует данные из буфера контроллера диска в кэш ядра (ресурсы ЦП в это время не заняты, и ЦП может выполнять другие задачи).
- Когда DMA считывает достаточно данных в буфер ядра, он отправляет сигнал прерывания в ЦП, и ЦП копирует данные из буфера ядра в пользовательский буфер.
Примечание: рано DMA Только держисуществоватьна материнской плате,сейчассуществовать I/O Устройств становится все больше, а требования к передаче данных становятся все более сложными, поэтому каждое I/O Каждое устройство имеет свой собственный контроллер прямого доступа к памяти。Насколько плоха традиционная производительность передачи файлов?
- сейчассуществовать,Подумайте об этом, все,если на нашем сервере должна быть предусмотрена функция передачи файлов,Что следует сделать? Самый простой способ — прочитать файл на диске.,Затем отправляется клиенту по сетевому протоколу. Обычно задействованы следующие два системных вызова:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);- Конкретная блок-схема выглядит следующим образом:
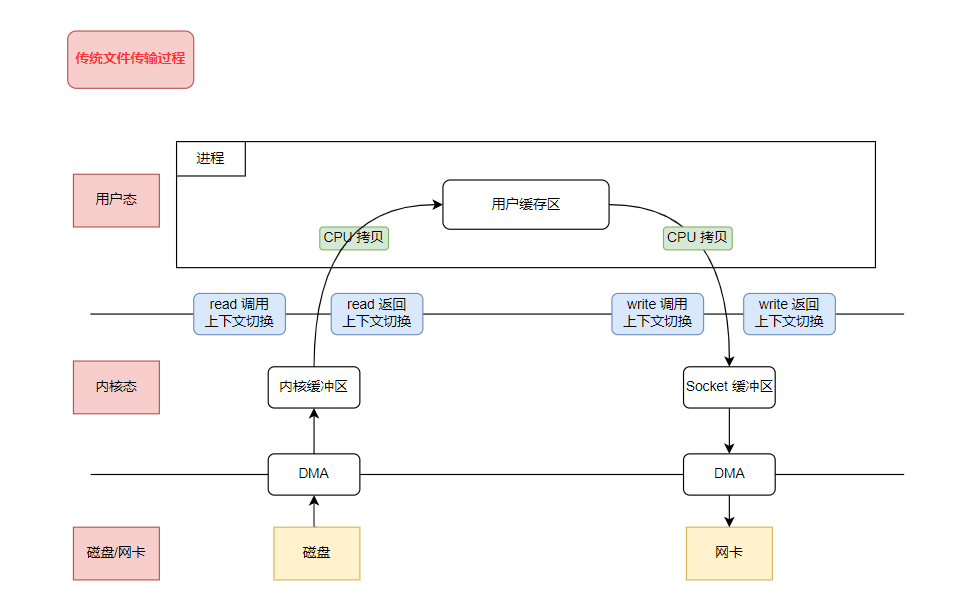
- Давайте посмотрим, что произошло в целом в процессе. Было 2 системных вызова (4 переключения контекста) и 4 копии данных (2 копии CPU, 2 копии DMA).
- Хотя время переключения контекста очень короткое и составляет от десятков наносекунд до нескольких микросекунд, в сценариях с высоким уровнем параллелизма оно может легко повлиять на производительность. В то же время мы обнаружили, что хотя мы передали только один фрагмент данных, мы скопировали его 4 раза. Нет сомнений в том, что слишком много копий данных займут ресурсы нашего процессора.
- поэтому,если Мы хотим оптимизировать весь процесс передачи файлов,Тогда основная идея оптимизации — уменьшить переключение контекста между пользовательским режимом и режимом ядра и уменьшить копирование данных.
Как оптимизировать производительность передачи файлов
- Выше мы упоминали, что хотим оптимизировать весь процесс передачи файлов. Основная идея оптимизации — уменьшить переключение контекста между пользовательским режимом и режимом ядра и уменьшить количество копий данных.
- Мы знаем, что переключение контекста на самом деле вызвано системными вызовами, поэтому сокращение количества системных вызовов может уменьшить переключение контекста. В то же время в сценарии передачи файлов наш пользовательский процесс не обрабатывает данные, поэтому нельзя ли скопировать данные в пространство пользователя? Ответ — да, поэтому нет необходимости в существовании пользовательского буфера во время передачи файлов.
Технология нулевого копирования
- На основе двух вышеупомянутых пунктов оптимизации была разработана Технология нулевого копирования,Технология нулевого копирования обычно имеет следующие два решения реализации.,Давайте поговорим конкретно о том, как это уменьшает количество переключений контекста и копий данных:
mmap + write
sendfilemmap + write
- в традиционных документах IO процесссередина,мы должныиспользовать read Вызов для чтения данных из буфера ядра в область пользовательского буфера. Чтобы уменьшить накладные расходы на этом этапе, мы используем. mmap() заменять read():
buf = mmap(file, len);
write(sockfd, buf, len);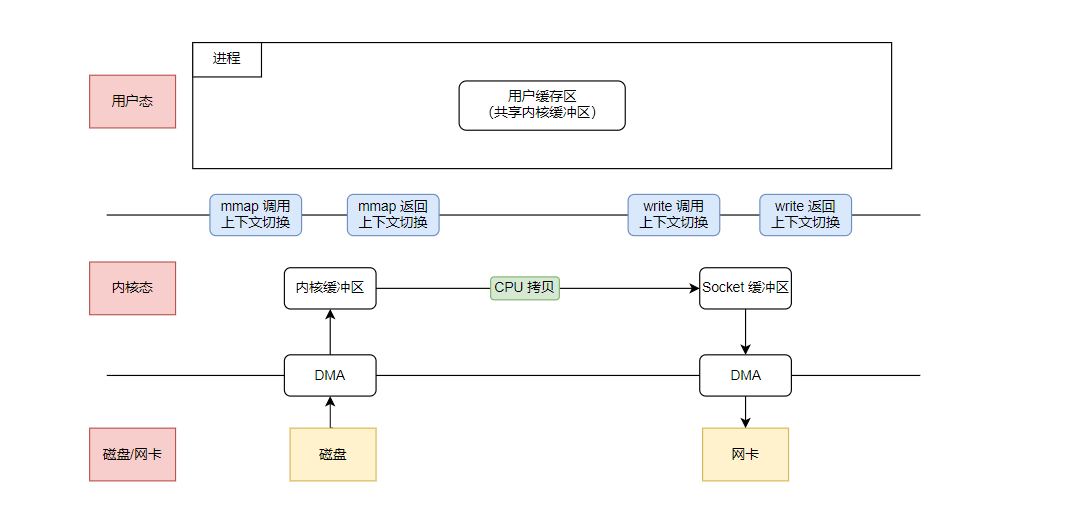
- После того как пользовательский процесс вызывает метод mmap(), DMA копирует данные с диска в буфер ядра. Пользовательский процесс и ядро используют этот буфер совместно.
- После того как пользовательский процесс вызывает метод read(), ЦП копирует данные из буфера ядра в буфер Socket.
sendfile
- Хотя весь описанный выше процесс сокращает две копии данных, все равно остается 4 переключения контекста.
- В ядре Linux версии 2.1 функция системного вызова sendfile() предусмотрена специально для отправки файлов. Форма функции следующая, что позволяет еще больше сократить системные вызовы:
#include <sys/socket.h>
// Первые два параметра — это файловый дескриптор места назначения и источника соответственно. Последние два параметра — это смещение источника и длина данных. Возвращаемое значение — это длина фактических данных.
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
- Таким образом, для одной передачи файла нам понадобится всего 3 копии данных и 2 переключателя контекста.
SG-DMA(The Scatter-Gather Direct Memory Access)
- если Поддержка сетевых карт SG-DMA(The Scatter-Gather Direct Memory Доступ) технологии (и общие DMA другое), sendfile() Вызов будет дополнительно оптимизирован и удален. CPU Скопируйте данные из буфера ядра в socket буферная зонапроцесс,данныепрямойкопировать из буфера ядраприезжатьсетевая картасередина。
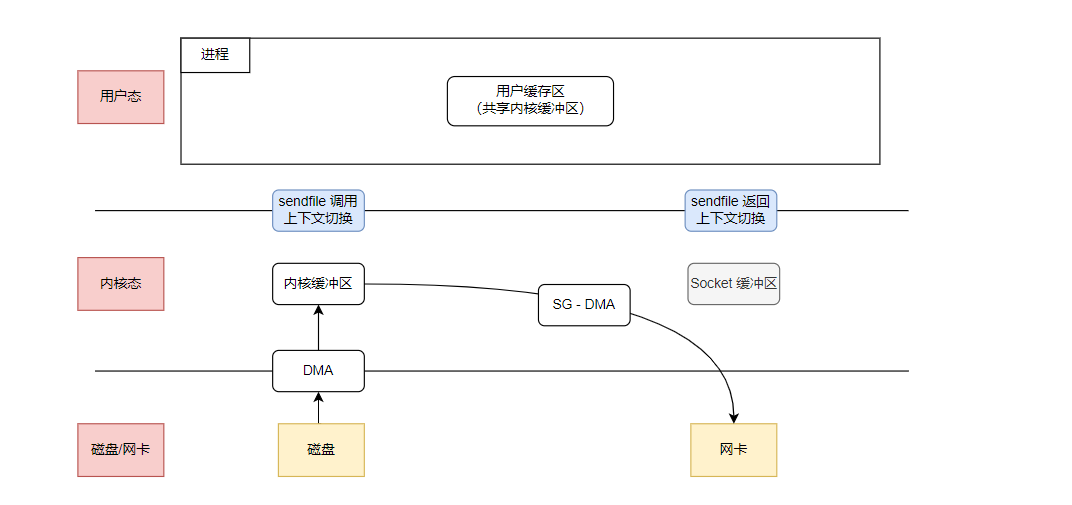
- Это настоящая технология нулевого копирование (нулевая копия), так как нам не пришлосьиспользовать на протяжении всего процесса CPU Вместо этого скопируйте данные через DMA осуществить передачу.
Технология нулевого копирования Приложение
- Наши наиболее часто используемые kafka Сразуиспользовать Понятно Технология нулевого копирование, тем самым значительно улучшая I/O пропускная способность, которая также kafka Одна из причин, почему он может обрабатывать огромные объемы данных.
- kafka Часть передачи реализует базовый вызов Java NIO Карри transferTo метод,если Linux Поддержка системы sendfile() системный вызов, затем transferTo() На самом деле, в конце концов придется использоватьприезжать sendfile() Функция системного вызова.
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}- существуют в тех же аппаратных условиях,Тест разницы в производительности традиционной передачи файлов и передачи файлов с нулевым копированием,использовать Понятно Технология нулевого копирование близко к сокращенному 65% время, что может значительно улучшить нашу пропускную способность:
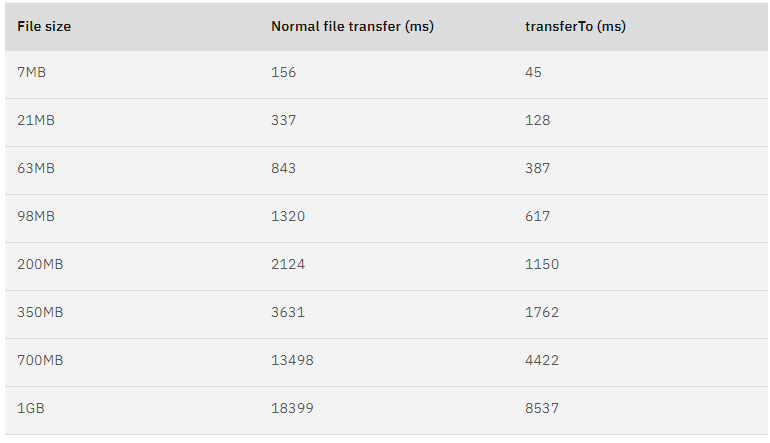 Тестовые данные нулевого копирования.png
Тестовые данные нулевого копирования.png
Какой метод следует использовать для передачи больших файлов?
- Прежде чем разобраться в этой проблеме, мы сначала поймем две концепции. PageCache и Прямой ввод-вывод。
Роль PageCache (буфера ядра)
- Буфер записи: при записи данных алгоритм ввода-вывода ядра кэширует как можно больше запросов ввода-вывода в PageCache и, наконец, объединяет их в более крупный запрос ввода-вывода на диск, сокращая операции по адресации диска.
- Чтение кэша: ядро предварительно считывает соседнее содержимое данных и кэширует некоторые «горячие» данные в PageCache, сокращая доступ к диску и повышая скорость доступа.
Прямой ввод-вывод
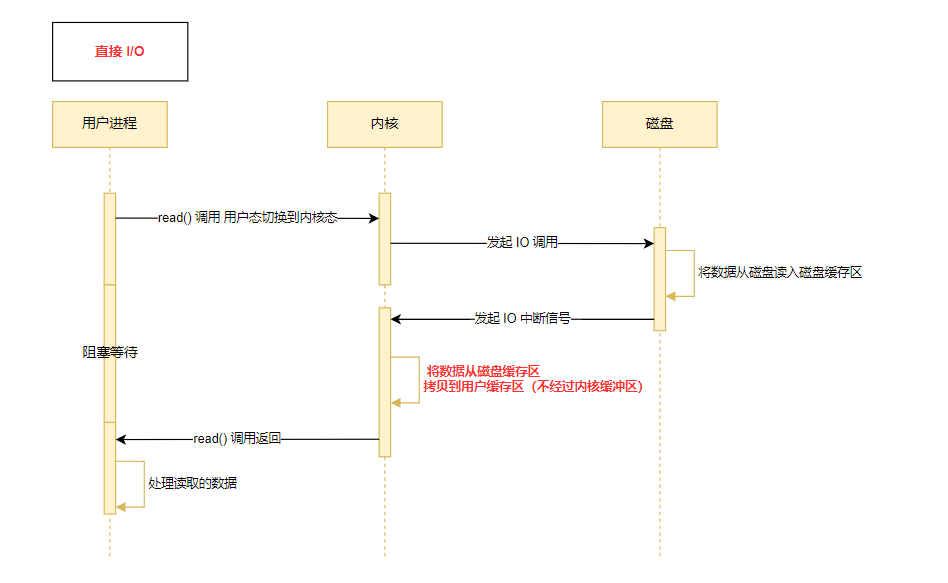
Прямой ввод-вывод Применимые сценарии
- В самом приложении реализовано кэширование дисковых данных, поэтому необходимости в PageCahe , Уменьшите потребление, вызванное копированием буфера ядра. Такие как существуют MySQL Вы можете открыть Прямой в базе данных. ввод-вывод, по умолчанию не включен.
- Сами данные слишком велики, и их трудно поместить в кэш PageCahe. В то же время они занимают PageCahe, в результате чего другие «горячие» данные становятся недействительными и вызывают дополнительные издержки производительности.
В итоге
- Из двух приведенных выше пунктов мы видим: Вопрос: Можно ли перемещать небольшие файлы в область кэша пользователя вместо области кэша ядра? отвечать: 1. использовать буфер ядра При копировании данных из дискового буфера можно использовать DMA 2. Теоретически стоимость данных, попадающих в пользовательский кэш, больше, чем стоимость данных, поступающих в буфер ядра.
- Для передачи небольших файлов мы можем уменьшить количество переключений контекста и копий данных и повысить производительность.
- Но для больших файлов,Уже не подходит Технология нулевого копирования на основе PageCahe,и Это должно бытьиспользовать Прямой ввод-вывод Кстати, и во избежание больших файлов Прямой ввод-вывод Принося долгосрочные перегрузки, мы можем использовать Прямой ввод-вывод + асинхронный I/O способ передачи больших файлов.

Nginx серединаиз Технология нулевого копированияи Прямой ввод-вывод
- существовать nginx , оба поддерживают Технология нулевого копирования,Также поддерживает Прямой ввод-вывод Мы можем настроить его в зависимости от размера файла следующим образом:
location /file/ {
sendfile on;
aio on;
directio 1024m;
}- Когда размер файла меньше 1024M часиспользовать Технология нулевого копирования,когдабольше, чем когдаиспользоватьпрямой IO технология.
Профиль
👋 привет, я Lorin Лорейн, один Java Разработчик бэкэнд-технологий!девиз:Technology has the power to make the world a better place.
🚀 Моя страсть к технологиям — это моя мотивация продолжать учиться и делиться ими. Мой блог — это место об экосистеме Java, серверной разработке и последних технологических тенденциях.
🧠 Будучи энтузиастом серверных технологий Java, я не только с энтузиазмом изучаю новые возможности языка и глубину технологий, но также с радостью делюсь своими идеями и передовым опытом. Я верю, что обмен знаниями и сотрудничество с сообществом могут помочь нам расти вместе.
💡 В моем блоге вы найдете подробные статьи об основных концепциях Java, базовой технологии JVM, часто используемых платформах, таких как Spring и Mybatis, управлении базами данных, таких как MySQL, промежуточном программном обеспечении для обработки сообщений, таком как RabbitMQ и Rocketmq, оптимизации производительности и т. д. Я также поделюсь некоторыми советами по программированию и методами решения проблем, которые помогут вам лучше освоить программирование на Java.
🌐 Я поощряю взаимодействие и создание сообщества, поэтому, пожалуйста, оставляйте свои вопросы, предложения или запросы по темам и дайте мне знать, что вас интересует. Кроме того, я буду делиться последними новостями Интернета и технологий, чтобы вы всегда были в курсе последних событий в мире технологий. Я с нетерпением жду возможности вместе с вами двигаться вперед по пути технологий и исследовать безграничные возможности мира технологий.
📖 Следите за обновлениями моего блога и давайте вместе стремиться к техническому совершенству.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
