Длинный обзор статьи! История развития моделей серии GPT за последние годы: от GPT-1 до GPT-4o (прошлая жизнь, настоящая жизнь)
Нажмите «AINLPer» выше и поставьте ему звездочку.
Больше полезных товаров, доставленных в кратчайшие сроки
введение
С выпуском ChatGPT внимание и количество крупных языковых моделей постоянно растет. Это привело человечество в эпоху больших моделей, и с последовательными итерациями последняя модель превратилась в GPT-4o. Среди многих крупных языковых моделей серия GPT привлекла большое внимание благодаря своей репрезентативности, а история ее развития и технологические инновации достойны углубленного обсуждения. Итак, сегодня я расскажу вам о развитии моделей серии GPT за последние годы. [См. «Большую языковую модель» Китайского университета Жэньминь]
Основной принцип модели серии GPT заключается в том, чтобы научить модель восстанавливать предварительно обученные текстовые данные и сжимать широкий спектр мировых знаний с помощью модели Transformer, которая содержит только декодер, чтобы модель могла получить комплексные возможности. В этом процессе двумя ключевыми элементами являются языковая модель Transformer, которая обучает модель точному предсказанию следующего слова, а также расширение языковой модели и данных предварительного обучения.
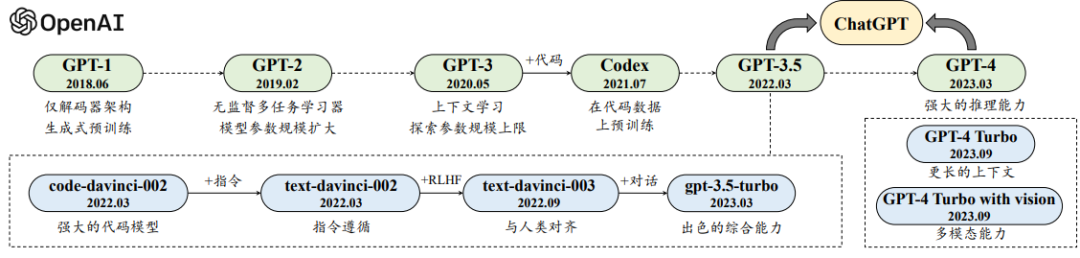
На рисунке выше показана схематическая диаграмма технологической эволюции модели серии GPT. Сплошная линия представляет четкий эволюционный путь, а пунктирная линия представляет более слабую эволюционную связь. Процесс разработки больших языковых моделей OpenAI можно разделить на четыре этапа: раннее исследование, установление маршрута, расширение возможностей и скачок возможностей. Каждый этап отмечает прогресс и развитие этой области.
GPT-1
В 2017 году Google выпустила модель Transformer. Эта архитектура быстро привлекла внимание команды OpenAI из-за своих значительных преимуществ в производительности. Впоследствии OpenAI переключила свои исследования и разработки на архитектуру Transformer и выпустила модель GPT-1 в 2018 году. GPT-1 — это архитектура Transformer, основанная на генеративном предварительном обучении. Она использует модель Transformer только с декодером и фокусируется на прогнозировании следующего элемента слова. Хотя масштаб параметров GPT-1 относительно невелик, он использует комбинацию неконтролируемого предварительного обучения и контролируемой точной настройки для улучшения общих возможностей модели по решению задач.
В том же году Google выпустила модель BERT, которая фокусировалась на задачах понимания естественного языка (NLU) и использовала только кодирующую часть Transformer. Модель BERT-Large достигла значительного улучшения производительности при выполнении множества задач NLU и стала в то время звездной моделью в области обработки естественного языка, возглавив волну исследований. Однако GPT-1 не привлек достаточного внимания в академическом сообществе, поскольку его масштаб сопоставим с BERT-Base, а его эффективность на наборах данных общественной оценки не достигла оптимального уровня. Хотя GPT-1 и BERT используют архитектуру Transformer, их прикладная направленность и дизайн архитектуры различны, и они представляют собой ранние исследования в области генерации естественного языка и понимания естественного языка соответственно. Эти ранние работы заложили основу исследований для последующих более мощных моделей GPT, таких как GPT-3 и GPT-4.
GPT-2
GPT-2 наследует архитектуру GPT-1, расширяет масштаб параметров до 1,5 миллиардов и использует крупномасштабный набор данных веб-страницы WebText для предварительного обучения. По сравнению с GPT-1, инновация GPT-2 заключается в попытке повысить производительность за счет увеличения размера параметров модели, одновременного удаления ссылки на тонкую настройку для конкретных задач и изучения использования неконтролируемых предварительно обученных языковых моделей для решения разнообразие последующих задач. Нет необходимости явно использовать данные аннотаций для точной настройки.
Основное внимание в GPT-2 уделяется многозадачному обучению, которое использует общую вероятностную форму для характеристики прогнозирования результатов различных задач и описывает входную, выходную информацию и информацию о задаче в форме естественного языка. Таким образом, последующий процесс решения задачи можно рассматривать как задачу генерации текста. В документе GPT-2 команда OpenAI объяснила причину, по которой предварительное обучение без учителя дает хорошие результаты в последующих задачах, то есть цель обучения с учителем для конкретной задачи по существу совпадает с целью обучения без учителя (моделирование языка). Все они направлены на предсказание следующего элемента слова. Следовательно, оптимизация глобальной цели обучения без присмотра — это, по сути, оптимизация цели обучения с контролируемой задачей.
Кроме того, взгляды, высказанные в интервью с основателем OpenAI, очень похожи на дискуссии в документе GPT-2. Он считает, что то, что изучают нейронные сети, — это определенное представление в процессе генерации текста, а текст, генерируемый этими моделями, на самом деле является проекцией реального мира. Чем точнее языковая модель предсказывает следующее слово, тем выше точность мировых знаний и тем выше разрешение, достигаемое в процессе.
Таким образом, модель GPT-2 исследует новую структуру многозадачного обучения за счет расширения шкалы параметров и использования неконтролируемого предварительного обучения с целью повышения универсальности и гибкости модели и уменьшения зависимости от точной настройки для конкретных задач. В то же время он также подчеркивает важность языковых моделей для понимания и создания текста на естественном языке, а также для улучшения понимания мировых знаний за счет точного прогнозирования следующего токена.
GPT-3
OpenAI выпустила знаковую модель GPT-3 в 2020 году. Размер параметра ее модели был расширен до 175B, что более чем в 100 раз превышает размер GPT-2, что означает последнюю попытку расширить модель. Перед обучением GPT-3 OpenAI провела достаточные экспериментальные исследования, включая попытки создания моделей уменьшенных версий, сбор и очистку данных, методы параллельного обучения и т. д. Эти усилия заложили основу для успеха GPT-3.
GPT-3 впервые предложил концепцию «контекстного обучения», позволяющую большим языковым моделям решать различные задачи посредством многократного обучения, устраняя необходимость тонкой настройки для новых задач. Этот метод обучения позволяет единообразно описывать обучение и использование GPT-3 в форме языкового моделирования, то есть на этапе предварительного обучения прогнозируются последующие текстовые последовательности в заданных контекстуальных условиях, а на этапе использования выводится правильное решение на основе описание задачи и пример плана. GPT-3 хорошо справляется с задачами обработки естественного языка, а также демонстрирует хорошие возможности решения задач, требующих сложных рассуждений или адаптации предметной области. В документе отмечается, что контекстное обучение дает особенно значительный прирост производительности для больших моделей, тогда как прирост для небольших моделей меньше.
Успех GPT-3 доказывает, что расширение нейронных сетей до очень больших масштабов может значительно улучшить производительность модели, а также устанавливает технический путь, основанный на методах обучения подсказкам, предоставляя новые идеи и методы для будущей разработки больших языковых моделей.
InstructGPT
OpenAI улучшает модель GPT-3 двумя основными способами: обучением данных кода и согласованием предпочтений человека. Прежде всего, чтобы устранить недостатки GPT-3 в программировании и решении математических задач, OpenAI в 2021 году запустила модель Кодекса, которая была доработана на данных кода GitHub и значительно улучшила ее возможности решения сложных задач. Кроме того, производительность выполнения связанных задач еще больше повышается за счет разработки контрастного метода обучения встраиванию текста и кода. Эти работы привели к разработке модели GPT-3.5, показавшей, что обучение данным кода играет важную роль в повышении общей производительности модели, особенно способности кодирования.
Во-вторых, OpenAI начала исследования по согласованию предпочтений людей с 2017 года, используя алгоритмы обучения с подкреплением для изучения данных о предпочтениях, помеченных людьми, для улучшения производительности модели. В 2017 году OpenAI предложила алгоритм PPO, который стал стандартом для последующих технологий выравнивания человека. В 2022 году OpenAI запустила InstructGPT, который официально создал алгоритм обучения с подкреплением RLHF на основе отзывов людей, с целью улучшить способность модели GPT-3 согласовываться с людьми, улучшить возможности выполнения инструкций и уменьшить создание вредного контента, который очень опасен. важно для больших языковых моделей. Безопасное развертывание имеет решающее значение.
OpenAI описывает технический маршрут исследования выравнивания в своем техническом блоге.,И Подвести итог определил три многообещающих направления исследований: использование обратной связи с людьми для обучения систем искусственного интеллекта, помощь в оценке человеком и проведение исследований по согласованию. Благодаря этим усовершенствованным технологиям,OpenAI назвал улучшенную модель GPT GPT-3.5,Он не только демонстрирует более сильные комплексные возможности,Это также знаменует собой важный шаг, сделанный OpenAI в исследовании модели большого языка.
ChatGPT
В ноябре 2022 года OpenAI выпустила ChatGPT, службу приложений для разговоров с искусственным интеллектом, основанную на модели GPT. ChatGPT использует технологию обучения InstructGPT и оптимизирован для разговорных возможностей. Он обучается на данных диалогов, созданных человеком, демонстрируя богатые мировые знания, сложные возможности решения проблем, возможности отслеживания и моделирования контекста многоходового диалога, а также способность соответствовать человеческим ценностям. ChatGPT также поддерживает механизм плагинов, который расширяет его функции и превосходит возможности всех предыдущих систем человеко-машинного диалога, привлекая большое внимание общества.
GPT-4
Вслед за ChatGPT OpenAI выпустила GPT-4 в марте 2023 года. Это важное обновление моделей серии GPT, впервые расширяющее режим ввода с одного текста до режима изображения и двойного текста. GPT-4 значительно лучше GPT-3.5 при решении сложных задач и показывает отличные результаты на человекоориентированных экзаменах.
Исследовательская группа Microsoft провела масштабное тестирование GPT-4 и полагала, что он демонстрирует потенциал общего искусственного интеллекта. GPT-4 также подвергся шестимесячному итеративному согласованию, что улучшило реакцию безопасности на вредоносные или провокационные запросы. OpenAI подчеркнула важность безопасной разработки GPT-4 в своем техническом отчете и применила стратегии вмешательства для смягчения потенциальных проблем, таких как галлюцинации и утечки конфиденциальной информации.
GPT-4 представил механизм «атаки красной команды» для уменьшения генерации вредоносного контента, создал инфраструктуру обучения глубокому обучению и представил механизм обучения с предсказуемым расширением. Что еще более важно, GPT-4 создал полную инфраструктуру обучения глубокому обучению, а также представил предсказуемый и масштабируемый механизм обучения, который может точно предсказать конечную производительность модели с меньшими вычислительными затратами в процессе обучения модели.
GPT-4V
OpenAI внесла важные технические обновления в модели серии GPT-4 и выпустила GPT-4V (сентябрь 2023 г.) и GPT-4 Turbo (ноябрь 2023 г.). Эти обновления значительно улучшили визуальные возможности и безопасность модели. GPT-4V фокусируется на безопасном развертывании визуальных данных и подробно обсуждает соответствующие стратегии оценки и снижения рисков, тогда как GPT-4 Turbo был оптимизирован во многих аспектах, включая улучшение общих возможностей модели, расширение источников знаний и поддержку более длинного контекста. windows, оптимизирована производительность и цена, а также представлены новые функции.
В том же году OpenAI запустила API Assistants, чтобы повысить эффективность разработки и дать разработчикам возможность быстро создавать интеллектуальных помощников для конкретных задач. Кроме того, новая версия модели GPT еще больше расширяет мультимодальные возможности, повышает производительность задач и расширяет объем возможностей за счет GPT-4 Turbo с Vision, DALL·E-3, TTS и другими технологиями, усиливая ядро модели GPT. GPT-модель крупных моделей экосистем приложений.
GPT-4o
14 мая этого года на весенней конференции OpenAI была представлена новая флагманская модель «GPT-4o». Буква «o» в GPT-4o означает «omni», что происходит от латинского «omnis». В английском языке «омни» часто используется как корневое слово для выражения понятия «все» или «все». GPT-4o — это большая мультимодальная модель, которая поддерживает любую комбинацию ввода текста, звука и изображения и может генерировать любую комбинацию вывода текста, звука и изображения. Он особенно хорош в визуальном и звуковом понимании по сравнению с существующими моделями.
GPT-4o может выполнять рассуждения в режиме реального времени с использованием звука, изображения и текста, принимая любую комбинацию текста, аудио и изображений в качестве входных данных и генерируя любую комбинацию текста, аудио и изображения в качестве выходных данных. Он может реагировать на аудиовход минимум за 232 миллисекунды и в среднем за 320 миллисекунд, что аналогично времени реакции человека при разговоре. Кроме того, GPT-4o может регулировать тон речи: от драматического до холодного и роботизированного, чтобы соответствовать различным сценариям общения. Что интересно, GPT-4o также имеет функцию пения, что добавляет больше удовольствия и развлечений.
GPT-4o не только конкурирует с GPT-4 в традиционных текстовых возможностях. Производительность Turbo сравнима, но API Быстрее и дешевле 50%。Подвести итого говоря, с GPT-4 Turbo По сравнению с GPT-4o скорость увеличена 2 раз цена снижается вдвое, а лимит ставки увеличивается 5 раз. ГПТ-4о Текущее контекстное окно 128k, крайний срок предоставления модели 2023 Год 10 луна.
Подвести итог
Хотя модели серии GPT достигли значительного научного прогресса в области искусственного интеллекта, они все еще имеют некоторые ограничения, такие как возможность генерации галлюцинаций с фактическими ошибками или потенциально рискованных реакций в некоторых случаях. Столкнувшись с этими проблемами, разработка более умных и безопасных моделей больших языков рассматривается как долгосрочная исследовательская задача.
Чтобы эффективно снизить потенциальные риски использования этих моделей, OpenAI принимает стратегию итеративного развертывания для постоянного улучшения и оптимизации моделей и продуктов посредством многоэтапного процесса разработки и развертывания. Эта стратегия отражает акцент на безопасности и эффективности на протяжении всего жизненного цикла, чтобы гарантировать, что большие языковые модели могут активно развиваться, одновременно решая возникающие проблемы и проблемы.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
