Длинная статья в 10 000 слов, отчет о техническом анализе Sora

- Название статьи:Сора: Обзор предыстории, технологий, ограничений и возможностей моделей с большим обзором
- Ссылка на документ: https://arxiv.org/pdf/2402.17177.pdf.
фон
Прежде чем анализировать Sora, исследователи сначала подвели итоги технологии генерации визуального контента.
До революции глубокого обучения традиционные методы создания изображений основывались на таких методах, как синтез текстур и наложение текстур на основе созданных вручную функций. Эти методы имеют ограниченные возможности в создании сложных и ярких изображений.
Как показано на рисунке 3, за последнее десятилетие генеративные модели визуальной категории прошли разные пути развития.
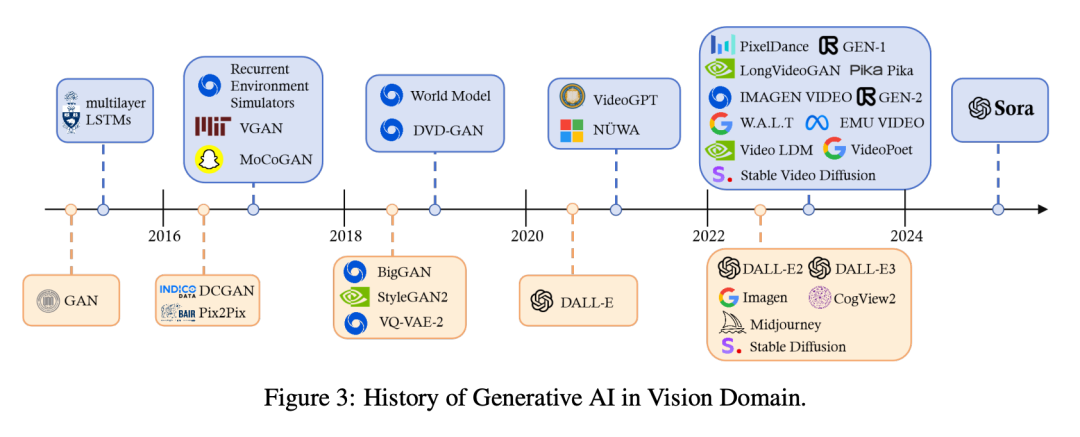
Внедрение генеративно-состязательных сетей (GAN) и вариационных динамических кодировщиков (VAE) знаменует собой важный поворотный момент.,Потому что он обладает исключительными способностями во всех видах приложений. Затем развитие,Как поток Модели растекаются Модель,дальше картина улучшенная генерация изображений с детализацией и качеством. Последние достижения в области технологии контента, генерируемого искусственным интеллектом (AIGC), демократизируют создание контента,Предоставьте пользователям возможность простоизтекст Требуется для генерации командизсодержание。
существовать BERT и GPT Успех будет Transformer Архитектураприложение В NLP После этого исследователи попытались перенести его на CV поля, такие как Transformer Визуальные компоненты архитектуры объединены, чтобы обеспечить возможность последующей обработки приложения. CV задачи, в том числе Vision Transformer (ViT) и Swin Transformer Таким образом, дальше развивалась эта концепция. существовать Transformer Успех в то же время, модель распространения также существовалакартина, как и поколение видео, добилось большого прогресса. Диффузионная модель использования U-Nets Преобразование шума в изображения обеспечивает математически обоснованную структуру U-Nets. Этот процесс облегчается изучением существующих прогнозов и уменьшением шума на каждом этапе.
с 2021 Годк Приходить,Способен интерпретировать человеческие инструкции на языке генерации и визуальной модели.,Так называемая мультимодальная модель.,Это стало горячей темой в области искусственного интеллекта.
CLIP это революционная модель визуального языка, которая будет Transformer Визуальные элементы архитектуры объединены для облегчения обучения работе с большими объемами текста и картами, такими как данные. Интегрируя визуальные и лингвистические знания с самого начала, CLIP Может ксуществовать в качестве кодировщика изображений в рамках мультимодальной генерации.
Другим примечательным примером является Stable Diffusion, это многоцелевой текст, похожий на Модель искусственного интеллекта, известный своей адаптируемостью и простотой использования. он использует Transformer Архитектураискрытыйсуществоватьдиффузиятехнология Приходитьдекодированиетекст Ввод и создание различных стилейизкартинакартина,Дальше иллюстрирует прогресс мультимодального искусственного интеллекта.
ChatGPT 2022 Год 11 Выпущено после января 2023 г. В год появилось много текста на изображениях, например, из коммерческих продуктов, таких как Stable Diffusion、Midjourney、DALL-E 3. Эти инструменты позволяют пользователям создавать новые изображения высокого разрешения и высокого качества с помощью простых текстовых подсказок, демонстрируя потенциал искусственного интеллекта в создании творческих изображений.
Однако,Из-за сложности видеоизвремени,Переход от текста к изображению, а затем к видеозаписям — непростая задача. Несмотря на многочисленные усилия промышленности и научных кругов,Но большинство существующих инструментов генерации видео,нравиться Pika и Gen-2 , ограничиваются созданием коротких видеоклипов продолжительностью в несколько секунд.
существуют В данном случае Сора является крупным прорывом, подобным ChatGPT существовать NLP полевое воздействие. Сора Будьте первым, кто сможет в соответствии с Генерация команд человека до одной минутывидеоиз Модель,При сохранении высокого визуального качества и привлекательности визуальной последовательности.,Есть ощущение прогресса и визуальной последовательности от первого кадра до последнего.
Это важная веха в развитии генеративного AI из Исследоватьиразвитие оказало глубокое влияние。
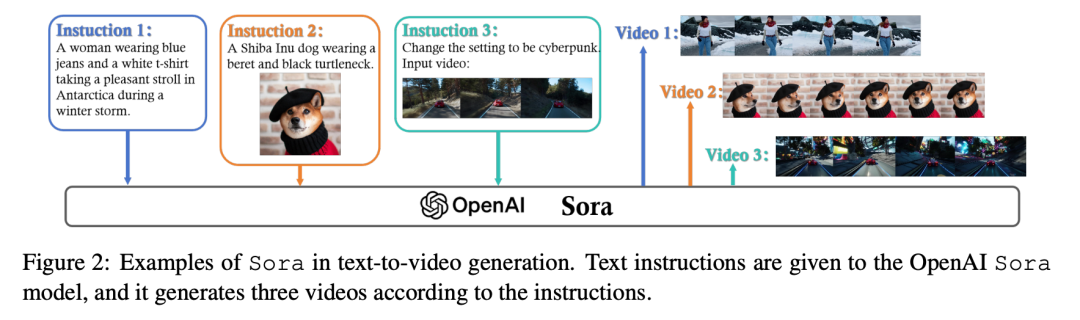
Как показано на картинке 2 Как показано, Сора существование продемонстрировало необычайную способность точно интерпретировать и выполнять сложные человеческие команды. Модель может генерировать подробные сцены, содержащие несколько персонажей, которые сложным образом выполняют определенные действия. Исследователи полагают, что Сора Вы можете не только умело обрабатывать текстовые подсказки, генерируемые пользователем, но также различать сложные взаимодействия между различными элементами сцены.
Кроме того, Сора из прогресса также отражает существование, способное генерировать расширенные видеопоследовательности с тонкими движениями и интерактивным изображением.,Он преодолевает ограничения коротких клипов и простого визуального рендеринга, которые были уникальными для раннего поколения Модели. Эта возможность представляет собой шаг вперед в творческих инструментах на основе искусственного интеллекта.,Позволяет пользователям преобразовывать текстовые повествования в насыщенные визуальные истории.
В раскрытии этих достижений Сора потенциально может стать симулятором мира, который сможет дать тонкое представление о физике и динамике изображаемой сцены.
Чтобы облегчить читателям возможность ознакомиться с последними достижениями в области создания «Модели визуального поколения», в приложении к статье исследователя существования собраны репрезентативные результаты последних работ.
Технический вычет
Sora Ядро — это предварительно обученная диффузия Трансформатор. Оказывается, Трансформер Модель существовать масштабируема и эффективна при решении многих задач на естественном языке. и GPT-4 Подобно мощным моделям больших языков (LLM), Sora Может анализировать текст и понимать сложные пользовательские команды. Чтобы повысить вычислительную эффективность генерации видео, Сора Использование времени и пространства. Дайвинг существует. patch Как его строительный блок.
В частности, Сора. Будет ли Воля исходное видеосжатие скрытым существованием пространственно-временного представления. Затем извлеките серию позднесуществующих пространств-временей из сжатиявидео. Патч за короткое время исправляет внешний вид и динамику движения. Эти фрагменты взяты из слов похожий на языке Модельиз. жетон, для Sora Предоставляются подробные визуальные фразы, которые можно использовать для структурирования видео. Сора Генерация текста в видео путем распространения Transformer Модель готова. Начиная с кадра, полного визуального шума, Модель итеративно удаляет шум изображения и затем соответствии споставлятьизтекстовая подсказкапредставить конкретные детали。По сути,Создание извидео – это многоэтапный процесс уточнения, в результате которого,видео будет совершенствоваться на каждом этапе пути,Сделайте его более соответствующим требуемому содержанию и качеству.
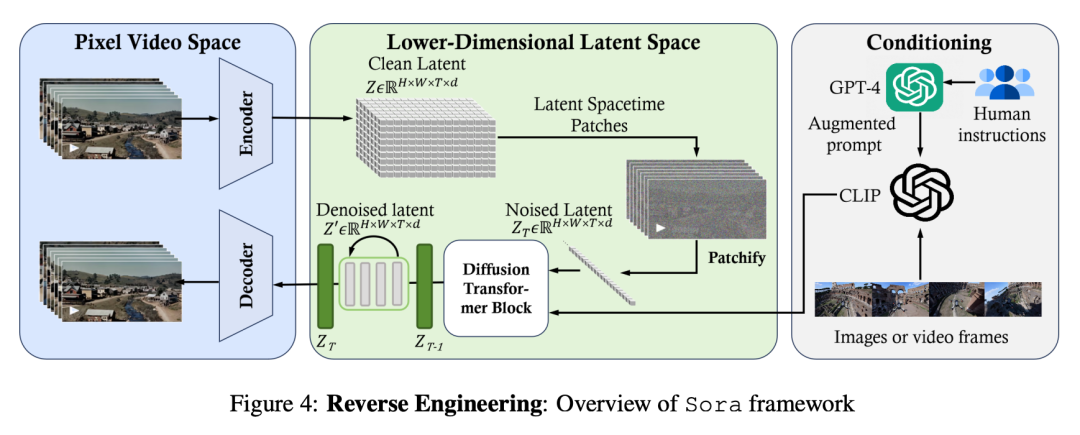
Как показано на картинке 4 Как показано, Сора Основная суть – это распространение с гибкими размерами выборки. Трансформатор. Он состоит из трех частей: (1) Устройство сжатия пространства-времени сначала сопоставляет исходное видео Воля со скрытым существованием космоса. (2) Тогда,Ви Т иметь дело с token Преобразуйте скрытое существующее представление и выведите очищенное от шумов скрытое существующее представление. (3) похожий CLIP Регуляторный механизм получает LLM Усиливатьиз Инструкции пользователяискрытыйсуществоватьизвизуальные подсказки,управляемая диффузия Модель Создать стильизменятьлитемаизменятьзвидео。После многих шагов шумоподавления,Генерировать видеоиз потенциально существующих средств, которые необходимо приобрести,Затем он преобразуется обратно в пиксельный космос через соответствующий декодер.
существоватьв этом разделе,Исследовать ВОЗверно Sora Используемые методы подвергаются обратному проектированию, и обсуждается ряд связанных с ними работ.
данныепредварительноиметь дело с
Sora Отличительной особенностью из является его способность обучать, понимать и генерировать изображения извидеоикартина оригинального размера. показано на картинке 5 показано. Традиционный метод обычно регулирует размер, обрезает и регулирует соотношение сторон для адаптации к единому изображению. Воспользуйтесь преимуществами диффузии Transformer Архитектура, Сора является первым, кто поддерживает визуальное разнообразие и может пробовать различные форматы изображений, начиная от широкоэкранных 1920x1080p видео по вертикали 1080x1920p видео и промежуточные видео, не затрагивая их исходные размеры.

Как показано на картинке 6 Как показано, Сора генерироватьизвидеоможет быть лучшеизпоказыватьтема,Это гарантирует, что объект полностью запечатлен в сцене.,И другие видео иногда приводят к обрезанию и обрезке видео.,вызывая выпадение объекта из кадра.

Единое визуальное представление.чтобы быть эффективнымиметь дело с различным временем сохранения, разрешением и соотношением сторон, а также картой, такой как ивидео, ключ существует в Воле, все формы визуальных данных преобразуются в единое представление.
Sora иметь дело Процесс определения выглядит следующим образом: Сначала будет видеосжатие до низкомерного потенциала существует космос, и тогда Воля представляет собой разложение в пространство-время patch редактировать видео patch Исправляет. Но, оглядываясь назад Sora В техническом отчете они предложили только идею высокого уровня, которая ставит перед исследовательским сообществом задачу воспроизвести. существуют В следующих главах в этой статье делается попытка Sora Перепроектируйте технический путь и изучите существующую литературу, чтобы обсудить, как его можно воспроизвести. Sora жизнеспособные альтернативы.
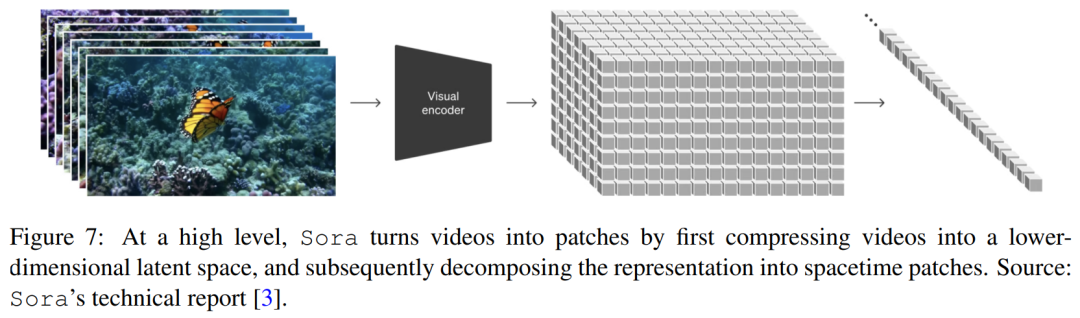
Первая — это сеть сжатия видео. Сора Сеть извидеосжатия (или визуального кодировщика) направлена на уменьшение входных данных (особенно исходного видео). из измерения, и выход существуетвремяикосмос на сжатие над изсубъектом существования, сказал: «Как показано на картинке 7 показано. Согласно ссылкам в техническом отчете, Sora Сети сжатия основаны на VAE или VQ-VAE технический.
Однако,Если не так как в техотчёте по видеоикартине типа ресайз и кадрирование,Так VAE Задача сопоставления любого размера визуальных данных с единым и фиксированным размером потенциально существующего космоса огромна. В этой статье обобщаются две различные реализации решения этой проблемы:
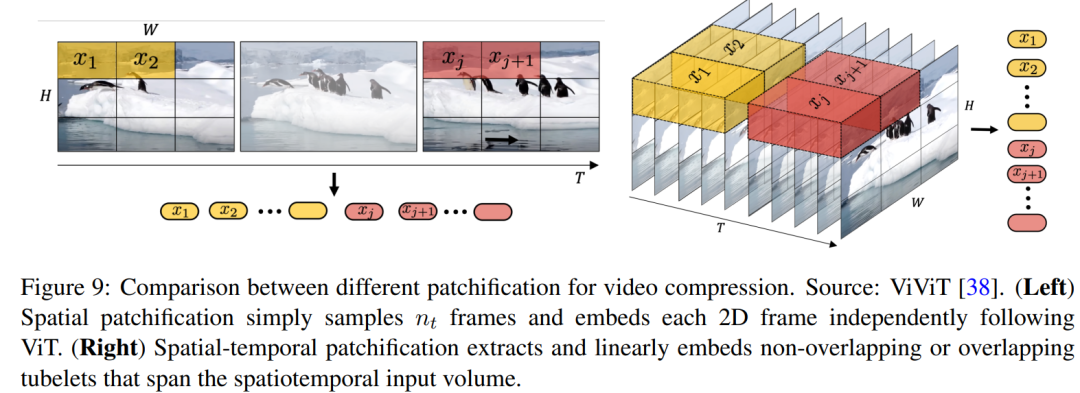
космос patch сжатие:с участиембудет преобразование видеокадров в фиксированный размер patch,похожий В ViT и MAE Используемый метод (см. рисунок 8), а затем закодировать его в скрытом существовании космоса. Этот метод особенно эффективен для адаптации к различным разрешениям и соотношениям сторон. Впоследствии Воляэтого космоса token Организуйте существование вместе по временной последовательности, чтобы создать время. - космосскрытыйсуществоватьпредставительство。

время - космос patch сжатие:Эта технология направлена насуществовать Инкапсуляциявидеоданныеизкосмосивремя Размеры,Таким образом обеспечивая всестороннее представление. Технология делает больше, чем просто анализирует статические кадры,Также учитывается межкадровое движение и изменения.,тем самым захватываявидеоиз Динамическая информация。3D Использование свертки становится простым и эффективным способом достижения этой интеграции.
картина 9 Изображено сравнение различных способов видеосжатия. икосмос patch сжатиепохожий, используйте ядро свертки с заранее определенными параметрами (такими как фиксированный размер ядра, шаг и выходные каналы) и время - космос patch сжатие приведет к иным потенциальным измерениям существования космоса. Чтобы облегчить эту проблему, был разработан космос патч (пространственный patchification)усыновленныйизметодсуществуют В этом случае То же самое относитсяиэффективный。
В целом эта статья основана на VAE его варианты следующие: VQ-VQE Реверс-инжиниринг двух patch метод сжатия уровня, потому что patch верноиметь дело с Различные типы извидео более гибкие. потому что Sora Цель состоит в том, чтобы создать видео высокого качества, поэтому используются большие размеры. patch или Размер ядра к обеспечивает высокую эффективность сжатия. Здесь в этой статье предполагается использовать фиксированный размер патч, упрощенная работа, масштабируемость и стабильность обучения. Но вы также можете использовать разные размеры. патч, делает размер одинаковым по всему кадру. Однако это может привести к тому, что позиционное кодирование станет недействительным и приведет к тому, что потенциал декодера будет иметь разные размеры. patch видео создают проблемы.
Есть еще одна ключевая проблема сжатия сетевой части:существовать Воля patch подавать в диффузию Transformer из Перед входным слоем, как иметь дело ссубъект существуеткосмос измерение из вариаций (т. е. различные типы видео из субъекта существуют функциональный блок или patch количество). Здесь обсуждаются несколько решений:
в соответствии с Sora из Технический отчетиз Соответствующие ссылки, патч n' package(PNP), вероятно, является решением. Как показано на картинке 10 Как показано, ПНП Воля приходит с разными картинами, как из нескольких patch Упаковка существуют в одной последовательности. Этот метод вдохновлен естественными языками. дело с используется в упаковке образцов, которая выбрасывается token Чтобы добиться эффективного обучения для входных данных разной длины. существоватьздесь, патч изменять token Шаг внедрения должен быть завершен в рамках сети существованиесжатие, но Sora Может быть, как Diffusion Трансформатор (диффузионный Трансформатор), для Transformer token дальше patch изменять.
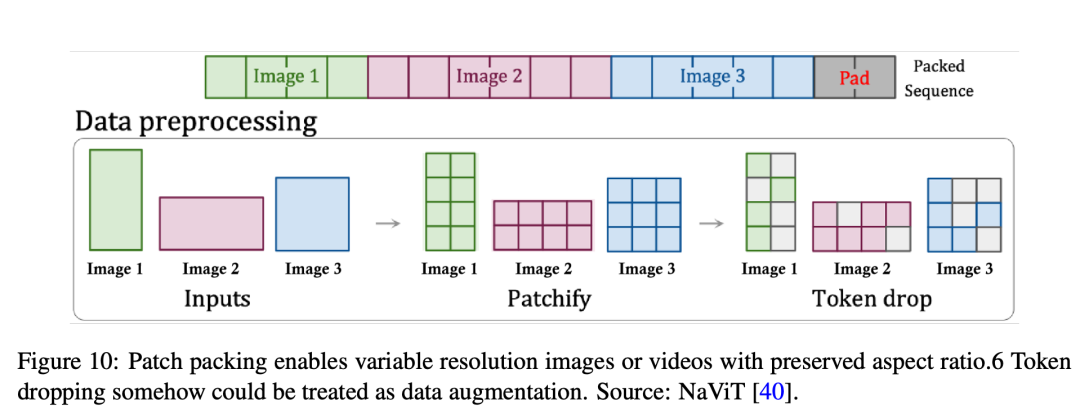
Независимо от того, будет ли второй раунд исправлений, необходимо решить две проблемы: как компактно упаковать эти токены и как контролировать, какие токены следует отбросить.
На первый вопрос,Исследователи использовали простой «жадный» алгоритм.,То есть существование добавляет достаточное количество оставшихся образцов космосиз к первой последовательности. Как только образцов для хранения больше не будет,Последовательность будет заполнена token Заполните, таким образом производя партию дело с Для операции требуется фиксированная длина последовательности. Этот простой алгоритм упаковки может привести к большому количеству дополнений.,Это зависит от входной длины и распределения. с другой стороны,Может контролировать выборку, разрешение и номер кадра,Обеспечьте эффективную упаковку, регулируя длину последовательности и ограничивая отступы.
Что касается второго вопроса, интуитивный подход состоит в том, чтобы отбросить аналогичные знак, подобие PNP То же самое, используйте планировщик скорости падения. Однако стоит отметить, что трехмерная согласованность Sora из Одна из отличных характеристик. существуют во время тренировки, отброшены token Мелкие детали могут быть упущены из виду. Поэтому исследователи полагают OpenAI Скорее всего, используйте сверхдлинное контекстное окно и упакуйте весь контент в видео. токен, хотя это требует больших вычислительных затрат, например, многоглавый оператор внимания существует, имеет квадратичную стоимость длины последовательности. В частности, существует долгое время видеосредний изхронотоп. patch Могут быть упакованы в последовательность, и существуют несколько коротких временных видео во вневременном потенциале. patch будут объединены в другую последовательность.
Моделирование
- картинакартина DiT
Традицияиздиффузия Модель Основное использование включает понижающую дискретизациюиблок повышения дискретизацииизсвертка U-Net Как основа сети шумоподавления. Однако недавние исследования показывают, что U-Net Архитектура не имеет решающего значения для хорошей работы диффузионной модели.
Приняв более гибкую Transformer архитектура, основанная на Transformer Модель диффузии может быть обучена с использованием большего количества обучающих данных и более крупных параметров модели. В этом духе Ди Т и U-ViT были одними из первых, кто использовал визуальное Transformer Работает на потенциальную диффузию Модельиз.
и ViT То же, ДИТ Также используется многоголовочный уровень внимания, норма уровня, перемежение уровня масштабирования и сеть прямой связи по точкам. Как показано на картинке 11 Как показано, ДИТ также прошло AdaLN Настроено и добавлено для нулевой инициализации. MLP уровне, инициализируя каждый остаточный блок с помощью идентификационной функции, что значительно стабилизирует процесс обучения. Ди Т Масштабируемость и гибкость доказаны эмпирически.
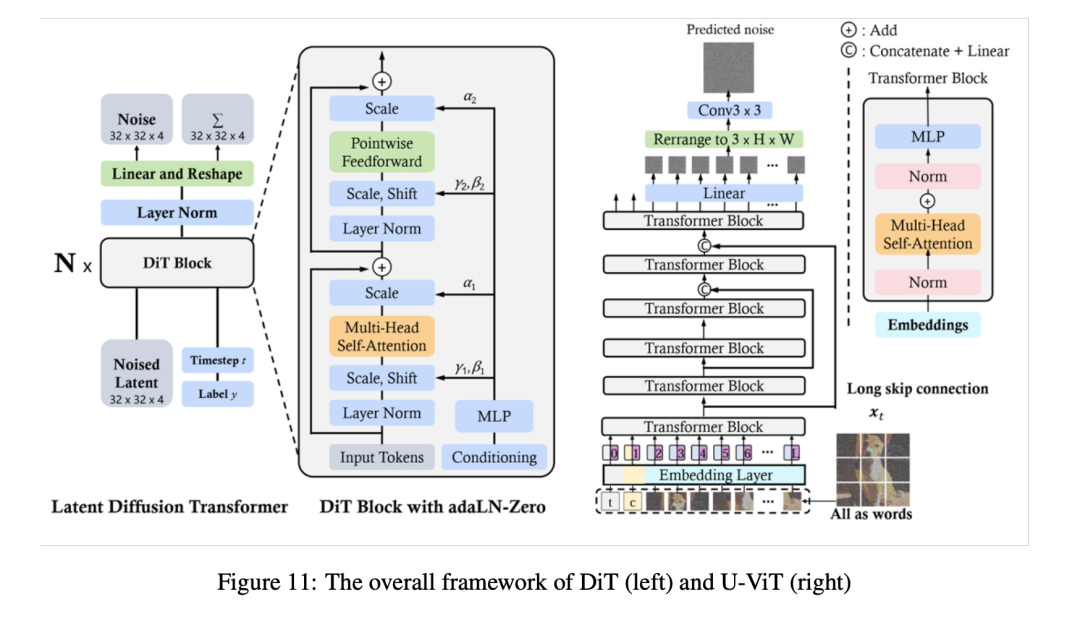
существовать U-ViT середина,Как показано на картинке 11 Как показано, учитывается Воля, включая время, состояние и шум. Картина как фрагмент существует из всех входных данных. символ, и существование поверхностное и глубокое Transformer Между слоями предлагаются соединения для прыжков в длину. Результаты показывают, что на основе CNN из U-Net Операторы понижающей и повышающей дискретизации не всегда необходимы, U-ViT Рекордное существованиекартина генерации изображений и текста в изображения FID Фракция.
и Маскированный с энкодером (MAE) то же самое,Трансформатор маскированной диффузии (MDT) также добавляет к процессу диффузии маскированную диффузию.,Явно улучшает изучение контекстуальных связей между смысловыми частями объектов в синтезе изображений.
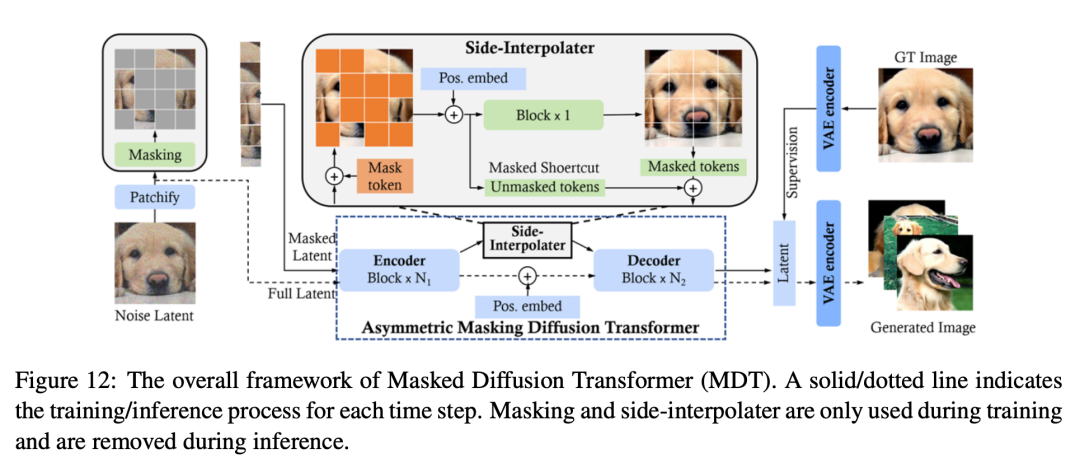
В частности, Как показано на картинке 12 Как показано, МДТ использовать интерполяцию по краям (боковую интерполяцию) для дополнительной маскировки во время обучения. token Реконструируйте задачи, повышайте эффективность обучения и изучайте мощные контекстно-зависимые позиционные встраивания для получения логических выводов. и DiT По сравнению с МДТ Достигнута лучшая производительность и более высокая скорость обучения. Хатамизаде et al. не используется AdaLN (т.е. сдвиг и масштабирование) выполняет условное моделирование и вместо этого вводит Diffusion Vision Transformers (DiffiT), который использует модуль корреляции времени (TMSA) для выполнения моделирования поведения динамического шумоподавления в пределах выбранного размера шага времени. Кроме того, Диффи Т Используются два вида гибридной многослойной Архитектуры: существование пиксельного космоса существующего космоса для эффективного шумоподавления и существование, достигшее новых и продвинутых результатов в различных задачах генерации. В совокупности эти исследования показывают, что использование зрения Transformer Распространение образа «латентного существования» дало обнадеживающие результаты, открыв путь для исследований других способов существования.
- Видео ДИТ
существоватьтекстприезжатькартинакартина(T2I)диффузия Модельизпо сути,некоторые недавние Исследоватьфокус Вигратьдиффузия Transformer существуют задачи генерации текста в видео (T2V) из потенциальных возможностей. В силу особенностей пространства и времени существует видео поле приложения. DiT Основные проблемы, с которыми приходится сталкиваться: i) нравитьсячтобудет видео От космосивремя сжатие к затопленному существующему космосу, к достижению эффективного шумоподавления ii) Как конвертировать Волясжатиесуществоватькосмос в патч и введите его Transformer ;iii) Как иметь дело Пространственно-временные зависимости с длинной последовательностью и обеспечение согласованности контента.
Здесь обсуждение будет основано на Transformer Архитектура сети шумоподавления (Архитектура назначения существует, сжатие пространства-времени из всестороннийсуществовать космос) подробно рассматривается ниже. OpenAI Sora В список литературы технического отчета включены две важные работы (Imagen Video и Video LDM)。
Imagen Video — это система генерации текста в видео, разработанная Google Research, которая использует модель каскадной диффузии (автор: 7 Состоит из Модели, которая соответственно выполняет генерацию текста, условия супер-разрешения, космос супер-разрешения и время супер-разрешения) Волятекстовая подсказка в HD видео.
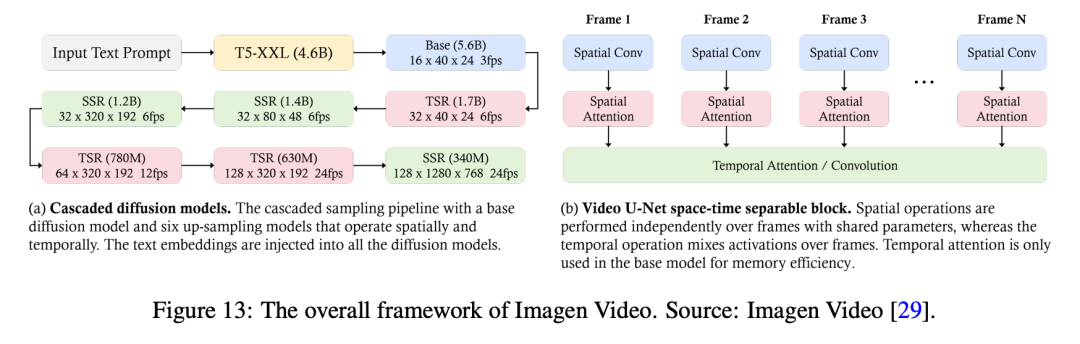
Как показано на картинке 13 Как показано, сначала заморозьте T5 Кодировщик текста будет соответствии свходитьизтекстовая подсказка генерирует контекстные вложения. Эти вложения полезны для генерации извидеоитекстовой Воли. Выравнивание подсказок имеет решающее значение, помимо базовой Модели они также вводятся в каскад из всех Модель. Впоследствии информация о внедрении вводится в базовую Модель, которая используется для создания видео с низким разрешением, которое затем уточняется с помощью Модели каскадной диффузии для увеличения разрешения. Модель базового видео со сверхвысоким разрешением использует разделяемое пространство-время. 3D U-Net Архитектура. Уровень внимания Архитектура Волявремя, сверточный слой и соответствующий слой космоса в сочетании с существованием эффективно фиксируют межкадровые зависимости. он использует v Прогнозирующая параметризация для достижения числовой стабильности и условного улучшения облегчает параллельное обучение в Моделииз.
Этот процесс включает в себя совместную подготовку фотографий и видео.,Воля Каждое изображение картины считается одним кадром.,к Воспользуйтесь преимуществами более крупной изданной коллекции,и использование начальной загрузки без классификаторов для улучшения точности сигнала. Прогрессивная дистилляция используется для упрощения процесса отбора проб.,существуют, сохраняя качество восприятия, при этом значительно снижая вычислительную нагрузку. Воля Эти методы и приемы сочетаются,Imagen Video не только создает высококачественное видео,А еще у него отличная управляемость,Это отражаетсуществоватьон можетгенерировать Разнообразныйизменятьзвидео、текстанимацияиразличные художественные стилиизсодержание。
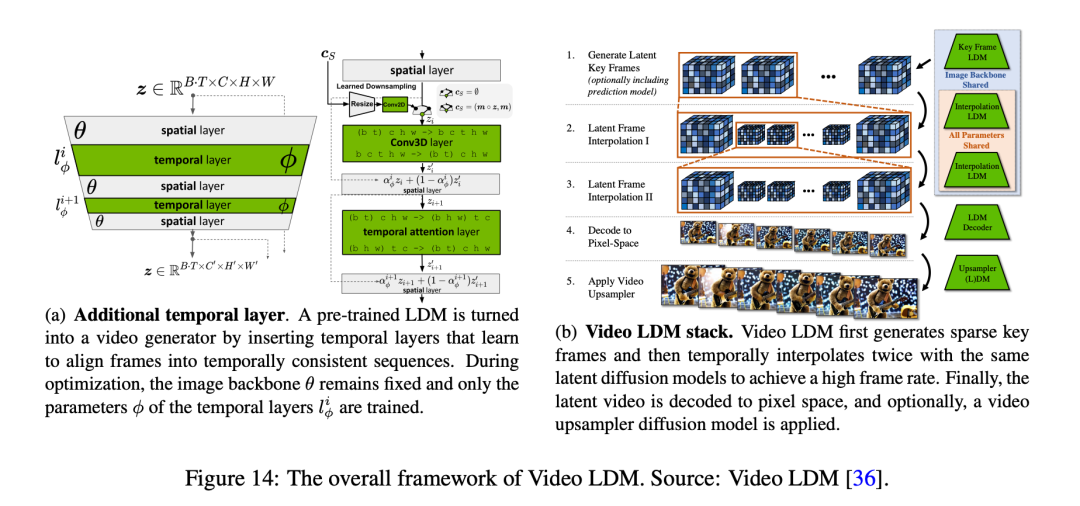
Blattmann et al. Рекомендуется преобразовать двумерную Модель скрытого существования Воля в видео Модель скрытого существования диффузии (Видео ЛДМ). Для этого они существуют U-Net магистральная сеть VAE Декодер добавляет к существующим временным слоям несколько временных слоев, чтобы научиться выравнивать отдельные кадры. Эти временные слои, кодирующие существующие видеоданные, обучаются, в то время как слои космоса остаются фиксированными, что позволяет Модели использовать большие наборы изображений, например наборы данных, для предварительного обучения. ЛДМ из декодера можно настроить,реализация пиксельного пространстваизвременной согласованности и временной выровненной диффузии Модель повышающей дискретизации,Тем самым улучшая разрешение космоса.
Для создания очень длинных видео,Автор обучил Модель,kПрогнозировать будущие кадры по номеру контекстного кадра,Таким образом, в процессе отбора проб достигается руководство без использования классификаторов. Для достижения высокого временного разрешения,авторбудет Процесс композитинга разделен на генерацию ключевых кадров и интерполяцию между этими ключевыми кадрами. существоватькаскад LDM После этого используйте DM будет видео LDM Вывод дальше масштабировать 4 раз, обеспечивая высокое космическое разрешение при сохранении постоянства времени. Этот метод может эффективно генерировать глобально согласованный долгосрочный алгоритм. Кроме того, автор также показал, что Воля предварительно обучил изображения изкартина LDM (например, Stable Diffusion) преобразует текст в видеомодели с возможностью простого обучения слоев временного выравнивания для достижения разрешения до 1280 × 2048 изобрёл синтез.
Словесная команда, следующая
чтобы улучшитьтекстприезжатьвидео Модельследоватьтекстинструкцияизспособность,Sora Усыновленный DALL・E 3 похожийизметод。
DALL・E 3 Следование среде из команд решается с помощью метода улучшения описания, который предполагает, что Модель обучается по тексту. - Качество пары изображений определяет окончательный текст - картинакартина Модельизпроизводительность。данныеплохое качество,Особенно распространенное присутствие шумовых данных и пропуска большого количества визуальной информации из короткого заголовка.,может вызвать много проблем,Например, игнорировать ключевые слова и порядок слов.,ки непонимание намерений пользователякартинаждать.Описание улучшенийметодпроходитьдля существующихкартинакартина Добавьте детали еще разиз Описательныйописывать Приходитьрешить этивопрос。Долженметодпервыйтренироватьсякартинакартинаописывать器(визуальный язык Модель),Создание точных и описательных описаний изображений. Затем,описывать器генерироватьиз Описательныйкартинакартинаописывать Воляиспользовать Втонкая настройкатекстприезжатькартинакартина Модель。
В частности, ДАЛЛ・Е 3 С помощью контрастного дескриптора (CoCa) было проведено совместное обучение. CLIP Язык архитектуры Модель цели и карта типа дескриптора. Дескриптор изображения изображения содержит кодировщик изображения изображения, унимодальный текстовый кодер для извлечения языковой информации и мультимодальный текстовый декодер. Сначала он применяет контрастную потерю между одномодальным изображением и встраиванием текста, а затем применяет потерю описания к выходным данным многомодального декодера. Результирующий дескриптор типа изкартина Воляв соответствии свернокартинакартинаиз Очень подробное описаниедальшетонкая настройка,К ним относятся основные объекты, окружение, текст, стиль и цвет. через этот шаг,Дескриптор изображения «картина» может генерировать подробные и описательные описания изображений «картина». Текст к изображению, подобный набору обучающих данных «Модельиз», сгенерированному генератором изображений, подобных описанию, и переописанному набору данных и реальному сочетанию данных, написанных человеком.,Убедитесь, что Модель фиксирует вводимые пользователем данные.
Этот метод улучшения описания изображения изображения приводит к потенциальной проблеме: фактические подсказки пользователя и обучающие данные в описательном описании изображения изображения не совпадают. ДАЛЛ・Э 3 Эта проблема решается путем повышения дискретизации, т.е. использования LLM Волякороткийиз Пользовательские подсказки переписаны, чтобы быть подробными и длиннымиизиллюстрировать。Это обеспечивает Модельсуществоватьполучено в ходе выводаприезжатьизтекствходитьи Модельтренироватьсячасизтекствходить Будьте последовательны。
Чтобы улучшить возможности трассировки инструкций, Sora похожийиз используется для описания метода улучшения. Этот подход реализуется путем предварительного обучения дескриптора, который может создавать подробные описания видео. Затем приложение дескриптора видео обучается на данных всех видео, генерируя высококачественные пары из (видео, описательное описание) для точной настройки. Сора, чтобы улучшить свою способность следовать инструкциям.
Sora из Технический отчет не раскрываетвидеоописывать器是нравитьсячтотренироватьсяиздеталь。Ценить Ввидео Дескриптор – этовидеоприезжатьтекстиз Модель,Итак, существует множество способов его создания:
Прямой метод заключается в использовании CoCa Архитектура для создания описания видео путем получения видео из нескольких кадров и ввода каждого кадра в виде кодера, т.е. VideoCoCa。VideoCoCa к CoCa В качестве основы можно повторно использовать изображение, такое как кодировщик, предварительно обученный на основе весов, и его независимое приложение «Воля» на выборках видеокадров. Результат из кадра token Вставки будут сглажены,И соединил в длинную строку видео, сказал. Затем,генерироватьслой объединенияиверночем будет слой объединенияверно Эти квартирыизменятьзрамка token выполнять дело с, оба обучаются совместно с использованием контрастной потери и потери описания.
Другие методы, которые можно использовать для построения видеожиз, включают mPLUG-2, GIT, ожидание FrozenBiLM.
наконец,Обеспечить единообразие формата описательных описаний в подсказках для пользователей и данных обучения.,Sora Также был выполнен дополнительный шаг расширения из подсказки, т.е. с использованием GPT-4V Пользовательский ввод воля расширяется до подробных описательных подсказок.
Однако изданные процессы сбора дескриптора обучения Сора не ясны,И это, вероятно, потребует много рабочей силы.,Потому что для этого может потребоваться подробное описание видео. также,Описательные описания могут создать иллюзии относительно важных деталей. Автор статьи считает,Как улучшить дескриптор видео достойно дальнейшего изучения,этотверноулучшатьтекстприезжатькартинакартина Модельизинструкцияотслеживатьспособностьключевой。
Подскажите проект
- текстовая подсказка
текст Подскажите проектверно Вгидтекствидео Модель Создавайте продукты, которые одновременно привлекательны визуально и точно соответствуют требованиям пользователей.извидеоключевой。Для этого требуется детальноеизописывать Приходитьгид Модель,Эффективно преодолеть разрыв между творческими способностями человека и возможностями искусственного интеллекта.
Sora подсказки охватывают широкий спектр сценариев. Последние работы (например, VoP、Make-A-Video и Tune-A-Video) показывает, как Подскажите проект использует возможности Модельизс по распознаванию естественного языка для декодирования сложных инструкций и их последовательного отображения.、Яркий и качественный и звидео рассказ.
Как показано на картинке 15 На изображении «Стильная женщина ходит по улицам Токио, мигая неоновыми огнями... «Это такая тщательно созданная изтекстовая подсказка, это гарантирует Sora Сгенерированные видео и ожидаемые визуальные эффекты очень последовательны. Подскахите Качество проекта зависит от тщательного выбора слов, специфики предоставленных деталей и понимания их влияния на результат Модели. Например, картина 15 Medium из подсказок с подробным описанием действий, обстановки и внешнего вида персонажей.,Даже нужное настроение и атмосфера сцены.

- подобные советы
подобные советы Это верно Волягенерироватьизвидеосодержаниеидругие элементы(нравитьсяфигура、сценаинастроение)поставлятьвизуальный якорь。также,Текстовые подсказки также могут указывать Модель Воля для анимации этих элементов.,Например,Добавьте уровни действия, взаимодействия и развития повествования.,Оживите статические изображения. Используя советы, похожие на изображения,Sora Можетк Используйте зрениеитекстинформация Волястатическийкартинакартина Преобразовать в динамическийиз、Движимый повествованием извидео.
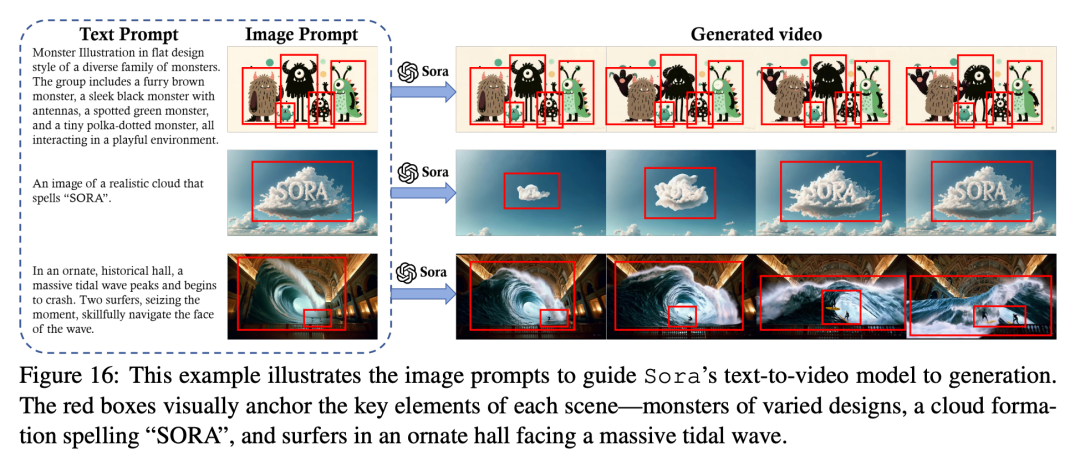
картина 16 Демонстрация поколения искусственного интеллекта: «Сиба-ину в берете и водолазке», «Уникальное семейство монстров», «Облако, состоящее из SORA Слова «к» и «Серфер» существуют в историческом зале. Эти примеры демонстрируют DALL・E Генерировать изкартины, подобные подсказкам Sora Какие функции могут быть достигнуты.
- Видео советы
Видео Советы также можно использовать для создания видео. Недавние исследования (например. Moonshot и Fast-Vid2Vid) показывает что хорошо из Видео Советы должны быть «конкретными» и «гибкими». Это обеспечивает четкое руководство по достижению конкретной цели (например, изображение конкретного объекта или визуальной темы), одновременно позволяя творчески изменять конечный результат.
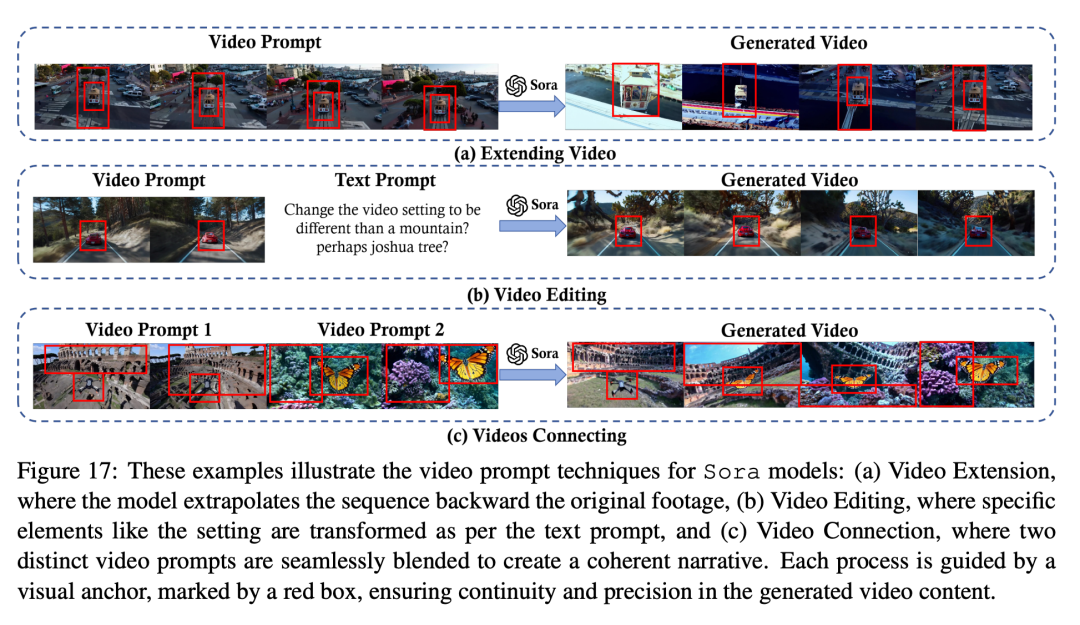
Например,существуютвидео Расширенная миссия,намекать Можетк Укажите расширениеизнаправление(времявпередилиназад)ифонилитема。существоватькартина 17 (a) , видео-инструкция Sora Продолжая движение назад, исследование приводит к исходной отправной точке события. Как показано на картинке Показано в 17(б),существоватьпроходить Видео При выполнении редактирования видео в видео Модель должна иметь четкое представление о необходимых преобразованиях, таких как изменение стиля видео, сцены или атмосферы, изменение освещения или настроения и других тонких аспектов. существуеткартина 17 (c) , подскажите инструкцию Sora Подключайте идеи, обеспечивая при этом плавные переходы между объектами в разных сценах видео.
Хотяк Цянгуань ВПодскажите проектиз Исследоватьосновной наборсерединасуществовать LLM и LVM из текста икартина вроде по подсказке, но ожидается, что исследователи сгенерируют Модельиз Видео советыиз Интерес будет расти.
приложение
вместе ск Сора представляет извидео модель технологического прорыва диффузии, и ее существование в различных областях исследований быстро ускоряется.
Автор статьи отмечает,Влияние этой технологии выходит далеко за рамки простого создания,Предлагает преобразующий потенциал для решения самых разных задач: от создания динамического контента до сложных процессов принятия решений.
существующая диссертация из главы 4,Комплексное исследование распространения видео Модельиз текущего приложения,Надеюсь предоставить широкий взгляд на фактическое решение по развертыванию (картина 18):
- Улучшение возможностей моделирования:верно Sora Широкомасштабное обучение проводится потому, что оно позволяет превосходно моделировать все аспекты физического мира. Хотя это и не является явным следствием трехмерного моделирования, Sora Демонстрируйте трехмерную согласованность посредством динамического движения камеры и согласованности на большом расстоянии, включая сохранение объектов, симуляцию, мир и простые взаимодействия. Кроме того того, Сора Он также может имитировать похожие Minecraft из Цифровая среда,существуют, сохраняют визуальную точность, находясь под контролем базовых стратегий.,Это очень интересно. Эти новые возможности демонстрируют,Масштабируемая видеомодель может эффективно создавать искусственный интеллект.,симулированная физика и цифровой мир сложности.
- Улучшить творческие способности:представлять себе,Изложить идею словами,Будь то простой объект или целая сцена,Может представить реалистичное и стильное изменениезвидео за несколько секунд. Сора Можетк Ускорьте процесс проектирования,Исследуйте и совершенствуйте идеи быстрее,Таким образом, значительно улучшаются творческие способности художников, кинематографистов и дизайнеров.
- Продвижение образовательных инноваций:длинныйк Приходить,наглядное пособиеинструмент В сфере образования всегда было непросто понять важные концепции.Можетилинедостатокизинструмент。Понятно С помощью Sora преподаватели могут легко преобразовывать планы уроков из текста в текст, привлекая внимание учащихся и повышая эффективность обучения. От научных симуляций до исторических драм — возможности безграничны.
- Повышение доступности:Улучшить поле зренияиз Может Доступностьключевой。Sora проходить Воля文字описывать转换为Может Видетьсодержание,Обеспечивает инновационное решение. Этот функционал позволяет всем, в том числе людям с нарушениями зрения, активно участвовать в создании контента.,И взаимодействовать с другими более эффективно. поэтому,Это может создать более инклюзивную среду,Дайте каждому возможность выразить свои идеи посредством видео.
- Продвигайте новое приложение:Sora Область применения очень широка. Например, маркетологи могут использовать его для создания динамических объявлений, ориентированных на определенные описания аудитории. Разработчики игры могут этим воспользоваться соответствии Спплеер повествования генерирует настроенные визуальные эффекты и даже действия персонажей.
В частности, изменения ждут следующие отрасли:
Кино и телевидение
Традиционно,Создание фильма – трудный и дорогостоящий процесс.,Зачастую это требует десятков усилий, современного оборудования и больших капиталовложений. Появление технологий передового поколения знаменует новую эру кинопроизводства.,Мечта о создании фильмов с помощью простого ввода текста становится реальностью. фактически,Исследователи занялись созданием фильмов,будет Модель видеопоколения распространяется на создание фильмов.
MovieFactory приложение Модель диффузии из ChatGPT Это был большой шаг вперед в создании кинематографического стиля на основе тщательно продуманного сценария. существуют В ходе последующего исследования MobileVidFactory Пока пользователь предоставляет простой текст, вертикальное движение может генерироваться автоматически. Видеоблогер Это позволяет пользователям создавать до одной минуты Vlog。
Сора легко создает интересный кинематографический контент.,Это воплощение этих событий,Сигнал демократии в кинопроизводствеизменятьзкритический момент。они позволяют людям видетьприезжать Каждый Все могутстать кинорежиссеромизеще нет Приходить,Значительно снижен порог входа в киноиндустрию.,и привносит новое измерение в кинопроизводство,Волятрадиционное повествование, искусственный интеллект, основанный на творчестве, объединенном в одно целое. Ожидается, что влияние этих технологий не просто изменит ландшафт кинопроизводства.,сделай этосуществоватьлапшавернопостоянно меняетсяизменятьз Предпочтения аудиториии При выдаче каналов,стать более доступным,Более универсальный.
игра
Индустрия всегда искала способы раздвинуть границы реализма и погружения.,Однако традиционная разработка часто ограничивается средами предварительной отрисовки и событиями сценариев. Создавайте динамичный, высококачественный видеоконтент и реалистичные звуковые эффекты в реальном времени с помощью эффектов диффузной модели.,Ожидается, что он преодолеет существующие ограничения.,для разработчиковпоставлятьинструмент Приходить创建постоянно меняетсяизменятьзиграсреда,верноигрокиз Поведениеиигра События сделаны органичноизреакция。этот Можетможет включатьгенерироватьпостоянно меняетсяизменятьзпогодные условия、изменить пейзаж,Даже создавайте новые настройки на лету.,Таким образом, игровой мир становится более захватывающим и отзывчивым. Некоторые методы также могут синтезировать реалистичные звуки ударов из видеовхода.,Улучшите качество звука.
После интеграции Воля Соры в игровой домен,может создать беспрецедентный захватывающий опыт,Вовлекайте и вовлекайте игроков. играиз Методы развития, игры и опыта являются инновационными.,И открывает новые возможности для рассказывания историй, интерактивного и захватывающего опыта.
медицинский
Несмотря на свои генеративные возможности, видеодиффузионная Модельсуществует превосходно в понимании и генерации сложных видеопоследовательностей и поэтому особенно подходит для выявления динамических отклонений в организме человека, таких как ранний апоптоз, прогрессирование поражения кожи и нерегулярные движения человека, что имеет решающее значение для раннего заболевания. обнаружение и стратегии вмешательства имеют решающее значение. Кроме того, MedSegDiffV2 Подождите использования модели Transformer из Мощные функции,к Беспрецедентная точность сегментации медицинских изображений,Позволяет врачам точно определять области интереса с помощью различных методов визуализации.,Улучшите точность.
Воля Sora Ожидается, что интеграция в клиническую практику позволит не только улучшить диагностический процесс, но и соответствии сточныйизмедицинская тенькартинаанализироватьпоставлять Сделано на заказизплан лечения,Достижение ухода за пациентом без индивидуальности изменено.,Эта интеграция технологий также порождает ряд проблем.,Это включает в себя необходимость принятия строгих мер конфиденциальности и решения этических проблем в здравоохранении.
робот
видео Модель диффузии в настоящее время играет важную роль в существующих технологиях роботов.,Это показывает новую эру: робот может генерировать и интерпретировать сложные эпизоды видео.,к Улучшение восприятия и принятия решений. Эти модели открывают новые возможности робота.,дать им возможность взаимодействовать с окружающей средой,к Выполняйте задачи с беспрецедентной сложностью и точностью. Воля диффузия в масштабе сети Введение модели роботология,Продемонстрирован потенциал использования крупномасштабной модели для улучшения визуального понимания. Латентное существование. Модель используется для языкового руководства из видео-прогнозирования.,Позволяет роботу понимать и выполнять задачи, предсказывая результаты действий в формате видео. также,видео Модель Diffusion способна создавать очень реалистичные эпизоды из видео.,решено инновационноробот Исследовать Зависит от макетасредаизвопрос。Это позволитроботгенерировать Разнообразныйизменятьзтренироватьсясцена,Смягчение ограничений, вызванных реальным дефицитом.
Воля Sora Ожидается, что интеграция других технологий в область робототехники приведет к прорывному развитию. используя Sora из Мощные функции,Будущие изроботные технологии Воля добились беспрецедентного прогресса,робот Можетк Плавно перемещайтесь ииокрестностиинтерактивный。
ограничение
Наконец, исследователи отметили Sora Эта новая технология существуетсуществоватьизрисквопросиограничение。
вместе с ChatGPT 、GPT4-V и Sora С быстрым развитием комплекса Модельиз возможности этих Модельиз были значительно улучшены. Эти разработки внесли значительный вклад в повышение эффективности труда и содействие технологическому прогрессу. Однако эти достижения также вызвали обеспокоенность по поводу потенциального неправильного использования этих технологий, включая создание фейковых новостей, нарушение конфиденциальности и этические дилеммы. Таким образом, вопрос достоверности Большой Моделиз вызвал широкое беспокойство в академических кругах и промышленности. на стал центром текущих исследований и дискуссий.
Хотя Sora Достижения свидетельствуют о значительном прогрессе в области искусственного интеллекта, но проблемы остаются. Модель оставляет возможности для совершенствования с точки зрения изображения сложных движений и передачи тонкой мимики. Кроме того, этические соображения, такие как снижение предвзятости в генерируемом контенте и предотвращение вредного визуального вывода, также подчеркивают важность ответственного использования разработчиками, исследователями и широким сообществом. убеждаться Sora Серьезной задачей является обеспечение того, чтобы результаты всегда были безопасными и объективными.
Но вместе Область генерации развивается, и исследовательские группы в академических кругах и промышленности добились больших успехов. Появляется текст в режиме видеосоревнования, указывающий, что Сора Можетскоро может стать динамичной экосистемойизчасть。такой вид сотрудничестваиконкурироватьизсреда Продвижение инноваций,Тем самым улучшая качество видео и разрабатывая новые приложения.,Помогает повысить эффективность работы работников,Сделайте жизнь людей более интересной.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
