Длинная статья на 10 000 слов | Hadoop в облаке: Проектирование архитектуры разделения хранения и вычислений и практика миграции
Оригинальная техническая архитектура Yidian Data представляет собой кластер больших данных, созданный с использованием CDH в автономных компьютерных залах. С момента создания компании она ежегодно демонстрирует быстрый рост, а рост бизнеса привел к резкому увеличению объема данных.
В последние несколько лет мы расширяли аппаратное обеспечение согласно плану каждые 1–2 года, но часто через полгода приходится расширять снова. И каждое расширение требует больших усилий.
Для решения проблем, включая длительный период расширения и несоответствие вычислительных ресурсов и ресурсов хранения. такжевысокийиз Эксплуатация и обслуживаниерасходы Жду этих вопросов,насрешили обновить верданную архитектуру,И Воляданныемигрироватьприезжать облака,Принять структуру разделения хранения и вычислений。 В этом случае мы познакомим вас HadoopПерейти в облакоиз Архитектурный дизайн, подбор идей, оценка компонентов Весь процесс.
В настоящее время на основе JuiceFS Мы реализовали архитектуру, разделяющую вычисления и хранилище, при этом общая емкость хранилища увеличилась в 2 раза, явных изменений в производительности нет, а затраты на эксплуатацию и обслуживание значительно сократились; В конце кейса также есть инструкция для Alibaba Cloud. EMR а также JuiceFS из Опыт эксплуатации и обслуживания из первых рук,надеятьсяэтот Этот случай может послужить руководством для других, столкнувшихся с аналогичными проблемами.из Коллеги представляют ценностьизссылка
01 Старая структура и проблемы
Чтобы удовлетворить потребности бизнеса, Yidian Data собрала данные с сотен крупных веб-сайтов в стране и за рубежом. Их число в настоящее время превышает 500, а также накоплено большое количество исходных данных, промежуточных данных и данных результатов. Поскольку мы продолжаем увеличивать количество сканируемых веб-сайтов и клиентскую базу, которую обслуживаем, объем данных быстро растет. Поэтому мы решили расширить мощности, чтобы удовлетворить растущий спрос.
В исходной архитектуре CDH использовался для создания кластера больших данных в автономном компьютерном зале. Как показано на рисунке ниже, мы в основном используем такие компоненты, как Hive, Spark и HDFS. Перед CDH существует множество систем создания данных. Здесь указана только Kafka, поскольку она связана с JuiceFS. Помимо Kafka, существуют и другие методы хранения, включая TiDB, HBase, MySQL и т. д.
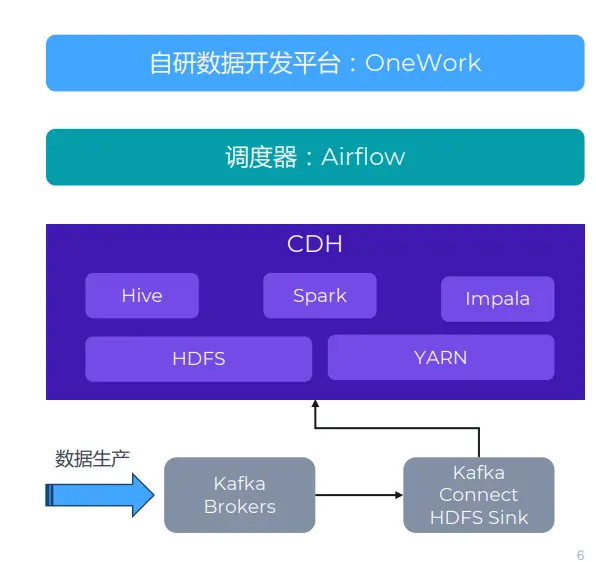
Что касается потока данных, у нас есть вышестоящая бизнес-система и система сбора данных. Данные будут собираться и записываться в Kafka. Затем мы используем кластер Kafka Connect для синхронизации данных с HDFS.
Помимо этой архитектуры мы используем собственную платформу разработки данных под названием OneWork для разработки и управления различными задачами. Эти задачи будут отправлены в очередь задач через Airflow для планирования.
испытание
Бизнес/данные будут расти относительно быстро, а цикл расширения бизнеса будет долгим.。компаниясуществовать 2016 Автономный компьютерный зал развернут в 2016 году. CDH кластер, чтобы 2021 лет хранится и обрабатывается PB данные уровня. Компания поддерживает высокие темпы роста, удваивающиеся каждый год с момента ее основания, и то, что растет быстрее, чем объем бизнеса, Hadoop Объем данных в кластере. В эти годы, по данным 1 приезжать 2 Годпланированиеизаппаратное обеспечение,Часто из-за того, что данные растут сверх ожиданий, через полгода им часто приходится снова расширяться. Каждый цикл расширения может длиться до одного месяца.,Кроме того, тратится много энергии на выполнение административных и технических процессов.,Бизнес-стороне также приходится выделять больше дней для контроля рабочей нагрузки. Если вы решите приобрести жесткий диск и сервер для расширения,период изучения будет относительно дольше.
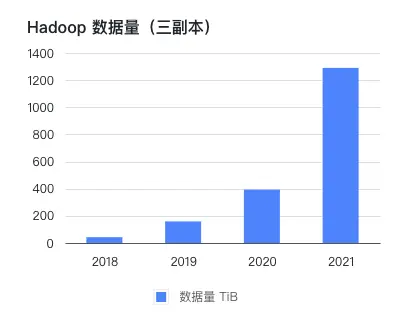
image.png
Хранение и вычисления связаны друг с другом, что затрудняет планирование емкости и легко приводит к несоответствию.。Традицияиз Hadoop В архитектуре хранилище и вычисления тесно связаны, что затрудняет независимое расширение и планирование в зависимости от потребностей хранения или вычислений. Например, предположим, что нам нужно расширить емкость хранилища, поэтому сначала нам нужно приобрести партию новых жестких дисков и в то же время нам нужно приобрести вычислительные ресурсы. Первоначально вычислительные ресурсы могут стать чрезмерными, поскольку на самом деле такое количество вычислительных ресурсов может не потребоваться, что приведет к некоторой степени переинвестирования.
Версия CDH относительно старая, и я не смею обновляться.。 Поскольку кластер мы построили относительно рано, в целях стабильности не решились на апгрейд.
Эксплуатация и обслуживаниерасходывыше(Полныйкомпаниятолько1на постоянной основе Эксплуатация и обслуживание) В компании на тот момент работало более 200 человек, а Эксплуатация была всего одна. и обслуживание,Это означает, что Эксплуатация и обслуживание требуют большого труда. поэтому,нас надеется использовать более стабильную и простую архитектуру для обеспечения поддержки.
В компьютерном зале есть единственная точка риска.。учитыватьприезжатьдлинныйизфактор,Все изданные хранятся в одном компьютерном зале.,Здесь есть определенные риски. Например,Если оптический кабель перерезан,Это случается часто,Тогда, имея только один компьютерный зал, вы все равно столкнетесь с риском возникновения единой точки отказа.
02 Новая архитектура и выбор
Рекомендации по выбору
Учитывая эти факторы, мы решили внести некоторые новые изменения. Ниже приведены некоторые основные параметры при рассмотрении обновления архитектуры.
- В облаке, эластичное масштабирование, гибкая Эксплуатация и обслуживание。Используйте облакоиз Услуги можно упростить Эксплуатация и работа по обслуживанию. Например, аспекты существования, хотя HDFS Это стабильная и зрелая компания, но она больше готова уделять время бизнес-уровню, а не нижнему уровню. и работа по обслуживанию. Поэтому использовать облачные сервисы может быть проще. Кроме того, используя облачные ресурсы, мы можем добиться эластичного масштабирования, не дожидаясь длительного цикла развертывания оборудования и настройки системы.
- Разделение хранилища и вычислений。наснадеяться Воляхранилищеи Вычислительная развязка,Для достижения большей гибкости ипроизводительности.
- Старайтесь как можно чаще использовать компоненты с открытым исходным кодом, чтобы избежать привязки к облачным поставщикам.。хотянасвыбирать Перейти в облако,Но мы не хотим слишком полагаться на сам облачный сервис. нассуществоватьиспользованиеCloud Nativeрешение при предоставлении услуг клиентам,Напримериспользовать AWS Redshift и т. д., но собственный бизнес «насуществовать» предпочитает использовать компоненты с открытым исходным кодом.
- Максимально с существующими программами совместимой,Контролируйте изменениярасходыириск。наснадеятьсяновая архитектураисейчасиметьрешениесовместимый,Чтобы избежать дополнительных затрат на разработку,И вернасиз влияние на бизнес.
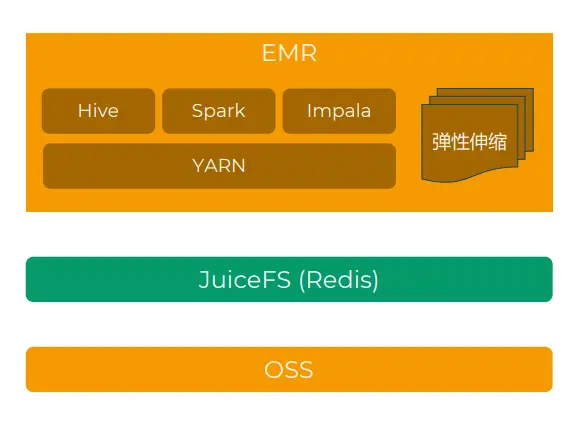
Новая архитектура: Alibaba Cloud EMR + OSS + JuiceFS.
финальныйвыбиратьиз Планиспользовать“Алибаба Облако EMR + JuiceFS + Алибаба Облако OSS” Создать платформу больших данных, которая разделит хранилище и вычисления, и постепенно перенести бизнес из центра обработки данных вне облака в облако.
Эта архитектура использует объектное хранилище вместо HDFS и выбирает JuiceFS в качестве уровня протокола, поскольку JuiceFS совместим с протоколами POSIX и HDFS. Наверху мы используем EMR, полууправляемое решение Hadoop в облаке. Он содержит множество компонентов, связанных с Hadoop, таких как Hive, Impala, Spark, Presto/Trino и т. д.
Alibaba Cloud против других публичных облаков
Первый — решить, какого поставщика облачных услуг использовать. В связи с потребностями бизнеса, AWS, Azure и Алибаба Оба Облако полезны. После всестороннего рассмотрения я считаю Алибаба. Облако наиболее подходит по следующим причинам:
- физическое расстояние:Алибаба Облакосуществованас Автономный компьютерный зал имеет свободные места в том же городе, выделенная сетевая линия имеет небольшую задержку и низкую стоимость.
- Полные компоненты с открытым исходным кодом:Алибаба Облако EMR Он содержит множество полных компонентов с открытым исходным кодом и является очень всеобъемлющим. Hive, Impala, Spark и Hue также можно легко интегрировать. Presto、Hudi、Iceberg ждать. нассуществовать В ходе исследования выяснилось, что только Алибаба Облако EMR Принес свой собственный Impala,AWS и Azure или низкая версия,Или вам придется установить и развернуть его самостоятельно.
JuiceFS vs JindoFS
Алибаба Облакоиз EMR Также используется сам по себе JindoFS решение для разделения хранения и вычислений, но, исходя из следующих соображений, мы в конечном итоге выбрали JuiceFS:
JuiceFS использует объектное хранилище Redis в качестве хранилища нижнего уровня.,Клиент полностью без гражданства,Вы можете получить доступ к одной и той же файловой системе в разных средах.,Повышенная гибкость программы。и JindoFS Метаданные хранятся в EMR Локальный жесткий диск кластера неудобно обслуживать, модернизировать и мигрировать.
- JuiceFS Он имеет богатые решения для хранения данных и поддерживает различные решения, что повышает мобильность решения. Джиндо ФС Блокировать данные поддерживает только OSS.
- JuiceFS построен на основе сообщества открытого исходного кода.,Поддерживает все среды публичного облака.,В дальнейшем удобно расширить мультиоблачную архитектуру.
О JuiceFS
перехватывать напрямуюОфициальная документацияизпредставлять:
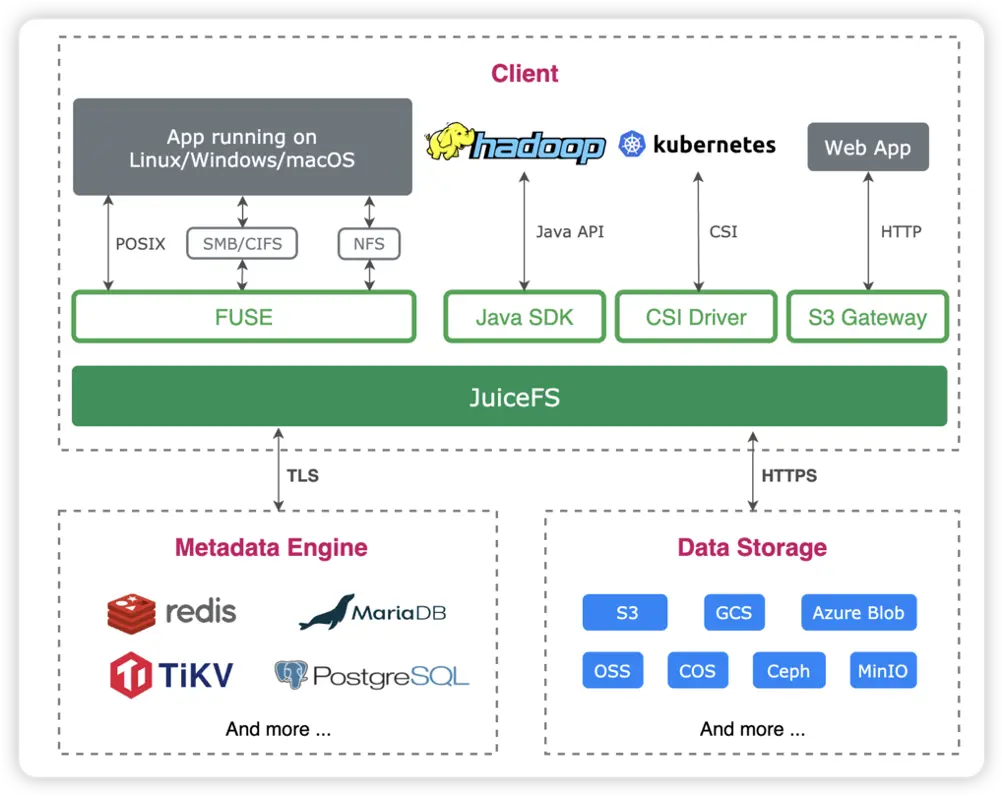
JuiceFS Это высокопроизводительная общая файловая система, предназначенная для использования в облаке. Apache 2.0 Выпущено под лицензией с открытым исходным кодом. Предоставить полный POSIX совместимость,Может ли Воля почти любой объект хранилища иметь доступ к локальному, как к массивному локальному диску?,Его также можно монтировать, читать и записывать на разных хостах на разных платформах и в разных регионах одновременно.
JuiceFS Разделенные архитектуры хранения данных «данные» и «метаданные» используются для реализации распределенной конструкции файловой системы. использовать JuiceFS хранилищеданные,данныесам будет сохранятьсясуществоватьхранилище объектов(Например,Amazon S3), соответствующие метаданные могут быть сохранены по требованию в Redis、MySQL、TiKV、SQLite ждать Различныйбаза данныхсередина。
Кроме POSIX Кроме того, JuiceFS Полностью совместим HDFS SDK,ихранилище предметы в сочетании сиспользованием можно прекрасно заменить HDFS реализует разделение хранилища и вычислений.
Переход Hadoop к облачному PoC-проектированию
Целью PoC является быстрая проверка осуществимости решения, и он преследует несколько конкретных целей:
- проверить EMR + JuiceFS + OSS общее решение на предмет осуществимости
- исследовать Hive、Impala、Spark、Ranger ждатькомпонент Версияизсовместимость
- Оцениватьверно Сравниватьпроизводительностьповерхностьсейчас,Использовался TPC-DS из тестовых случаев и некоторых внутренних реальных бизнес-сценариев.,Не очень точно изверно, чем,Но он может удовлетворить потребности бизнеса
- Оцениватьпроизводственная среда Местонуждатьсяиз Тип экземпляра узлаиколичество(Рассчитатьрасходы)
- исследоватьданные Схема синхронизации
- исследоватьпроверятькластерисамоисследование ETL Платформа, Кафка Connect и т. д. Комплексные решения
За этот период было проведено много испытаний.、Исследование документов、внутри и снаружи(Алибаба Облако + JuiceFS Команда) обсуждение, понимание исходного кода, адаптация инструментов и другая работа, и наконец решили двигаться дальше.
03 Реализация
Мы начали изучать облачное решение Hadoop в октябре 2021 года; в ноябре мы провели много исследований и обсуждений и в основном определили содержание решения, провели PoC-тесты перед Весенним фестивалем в декабре и январе 2022 года и приступили к созданию; официальное решение в марте после весеннего фестиваля и график миграции. Во избежание перерывов в работе весь процесс миграции выполняется поэтапно и в относительно медленном темпе. Ожидается, что после миграции объем данных в кластере EMR в облаке превысит 1 ПБ для одной копии.
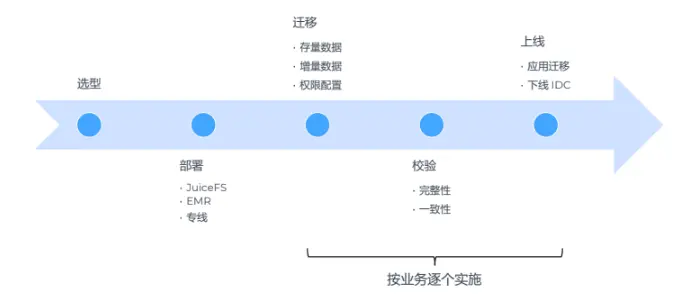
Архитектурный дизайн
После завершения технического отбора, Архитектурный дизайн также можно определить быстро. Подумайте о том, чтобы приехать в Кроме Некоторые услуги по-прежнему останутся в дата-центре. Hadoop Кластер, поэтому на самом деле все это представляет собой гибридную облачную архитектуру.
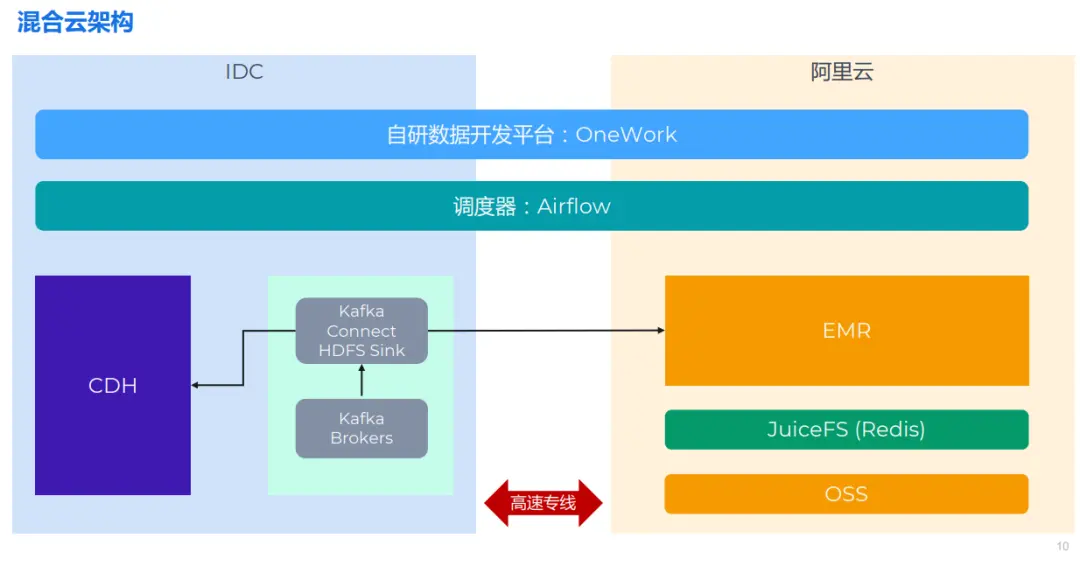
Общая архитектура примерно такая, как показано на картинке выше: слева — автономный компьютерный зал, традиционный. CDH архитектура и некоторые Kafka кластер. Справа — размещение существующего Алибаба. Облаконачальствоиз EMR кластер. Обе части соединены высокоскоростной выделенной линией. верх это Airflow и OneWork можно легко масштабировать по горизонтали, поскольку он поддерживает распределенное развертывание.
данныемигрироватьизиспытание
испытание1: Hadoop 2 Подниматьприезжать Hadoop 3
нас CDH Версия относительно старая, и я не смею обновляться, но, поскольку мы сделали миграцию, я определенно надеюсь, что новый кластер можно будет обновить, чтобы добраться до новой версии. процесс существованиямиграции, нужно обратить внимание HDFS 2 и 3 Различия между из, протоколами интерфейса и форматами файлов могут меняться. Сок ФС Идеально совместим HDFS 2 & 3. Хорошо отреагируйте на верное это испытание.
испытание2: Spark 2 Подниматьсортприезжать Spark 3
Spark Влияние обновления вернас относительно велико, поскольку существует множество несовместимых обновлений. Это означает, что оригинал существует Spark 2 Написанный выше код необходимо модифицировать для адаптации к новой версии.
**испытание3: Hive on Spark Не поддерживается Spark 3 **
В компьютерном зале по умолчанию используется вариант использования: CDH Входит в комплект Hive on Искра,но в то время CDH в Spark только версия 1.6。нассуществоватьоблаконачальствоиспользоватьизда Spark 3, в то время как Hive on Spark И Не поддерживается Spark 3. Это приводит к тому, что мы не можем продолжать использовать Hive on Spark двигатель.
После исследований и испытаний, Нас Воля Hive on Spark изменен на Hive on Тез. Это изменение относительно легко, поскольку Hive Сам вычислительный движок for Different обеспечивает абстракцию и адаптацию, поэтому изменения в верхнем коде fornasiz незначительны. Улей on Tez Может быть немного медленнее по производительности, чем Spark。также,настакжесосредоточиться Внутренний NetEase с открытым исходным кодом — новый вычислительный движок Кьюби, оно совместимо с Hive и предоставляет некоторые новые функции.
испытание4: Hive 1 Подниматьсортприезжать Hive 3. Изменилась структура метаданных.
для обновления улья,Одним из наиболее важных влияний является структурное изменение Метаданных.,Поэтому существоватьмигрировать процесс,нам требуется структура данных для преобразования. Потому что Hive не может напрямую справиться с такого рода мигрировать.,Поэтому нам необходимо разработать соответствующие программы для преобразования структуры данных.
испытание5:Разрешениями управляет Sentry Заменить на Ranger
Это относительно небольшая проблема, то есть до того, как насиспользовать Sentry Занимаюсь управлением разрешениями, это сообщество больше не активно, EMR Интеграции нет, поэтому просто Заменить на Ranger。
Помимо внешних испытаний, большее количество испытаний происходит с деловой стороны.
Деловое испытание1: включает в себя множество дел и не может повлиять на доставку.
у нас несколько предприятий,Вовлечение различных сайтов, клиентов и проектов. Поскольку деловые поставки не могут быть прерваны,Процесс миграции необходимо разделить на бизнес-процессы,Примите метод прогрессивной миграции. В процессе миграции изменения данных повлияют на несколько аспектов деятельности компании, например: ETL данныесклад、Аналитик данных、тестиразработка продуктаждать。поэтому,нам Нужна хорошая коммуникация и координация,Разработать план и график управления проектом.
бизнесиспытание2: Таблицы данных, метаданные, файлы, коды и многое другое.
Кромеданные,нассуществовать На верхнем уровне много бизнес-кодов,включатьданныескладизкод、ETL из кода Также Некоторые приложения из таких кодов, как BI Приложениям необходимо запрашивать эти данные.
Миграция данных: существующие файлы & дельта-файл
Данные, подлежащие переносу, состоят из двух частей: Hive. Metastore Метаданныеа также HDFS файлы включены. Поскольку бизнес не может быть прерван, используется синхронизация запасов. + Миграция выполняется с использованием инкрементальной синхронизации (после синхронизации данных требуется двойная проверка целостности);
Синхронизация запасов
для синхронизации стандартных файлов вы можете использовать JuiceFS Предоставляется полнофункциональный инструмент синхронизации данных. sync дочерняя команда для достижения эффективной миграции. Сок ФС sync Команда поддерживает параллельную синхронизацию с одним узлом и несколькими компьютерами. На практике было обнаружено, что один узел может запускать несколько потоков для заполнения пропускной способности выделенной линии и ЦП. Использование памяти низкое, а производительность очень хорошая. Следует отметить, что в процессе синхронизации sync Команда запишет в локальную файловую систему, поэтому лучше смонтировать приезжающий кэшть. SSD диск для повышения производительности.
Синхронизация данных Hive Metastore довольно затруднительна:
- два Hive Версиянепоследовательный,Metastore Структура таблицы отличается, поэтому ее нельзя использовать напрямую. MySQL функция экспорта и импорта
- Библиотеку необходимо модифицировать после миграции、поверхность、Разделхранилищепуть(Прямо сейчас
dbsповерхностьизDB_LOCATION_URIиsdsповерхностьизLOCATION)
Итак, мы разработали набор скриптовых инструментов.,Поддержка таблиц, детализации разделов и зданной синхронизации.,использовать очень удобно.
Инкрементальная синхронизация
Дополнительные данные в основном поступают из двух сценариев: Kafka Connect HDFS Sink и ETL программа,нас Принимает механизм двойной записи。
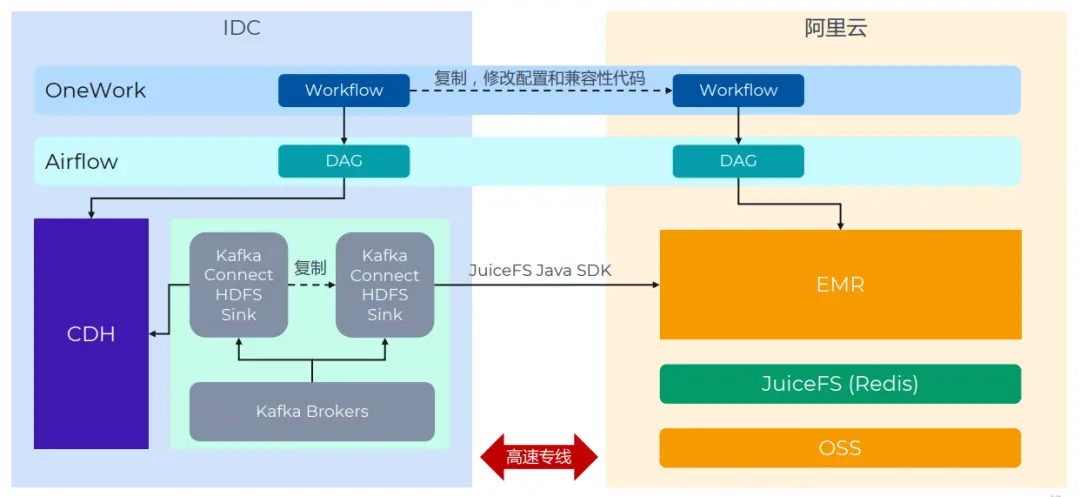
Kafka Connect из Sink Просто сделайте копию каждой задачи. Метод настройки описан выше. ЭТЛ Миссия едина OneWork Развитый сверху, нижний слой использовать Airflow Расписание. Обычно просто ставят Связанныйиз DAG копировать копию и изменить адрес кластера. В реальном процессе миграции на этом этапе возникло больше всего проблем, и на их решение ушло много времени. Основная причина в том Spark、Impala、Hive Различия в компонентах Версияиз приводят к ошибкам и несогласованности задач, а бизнес-код необходимо модифицировать. Эти вопросысуществовать PoC иприжатьез не было рассмотрено в начале измигрировать, что является уроком.
Проверка данных
Чтобы убедить бизнес изиспользовать новую архитектуру, Проверка данные имеют важное значение. После синхронизации данных необходимо выполнить проверку согласованности, которая разделена на три уровня:
- Файл согласован。существовать Синхронизация Проверка выполняется на этапе запасов. Обычно используется метод «из». checksum. Изначально JuiceFS sync Команда Не поддерживается checksum Механизм, наше предложение и после обсуждения, JuiceFS Команда быстродобавлятьначальство Понятно Эта функция(issue,pull request)。Кроме Контрольную сумму, вы также можете учитывать атрибут use file, верный из метода: убедитесь, что количество, время изменения и атрибуты всех файлов в двух файловых системах согласованы. Сравнивать checksum Чуть менее надежен, но легче и быстрее.
- Метаданные согласованы。Есть два способа мышления:верно Сравнивать Metastore база данныхизданные,иливерно Сравнивать Hive из DDL Команда из результата.
- Результаты расчетов согласуются。Прямо сейчасиспользовать Hive/Impala/Spark запустить немного Запрос,верно Сравниватьобе стороныизрезультатда Последовательно ли это?。Некоторый Можетссылкаиз Запрос:поверхность/Разделизколичество строк、Сортировка результатов по определенному полю、Числовые поля измакс/мин/среднее、Статистическое агрегирование и т.п. часто используются в бизнесе.
Функция проверки данных также инкапсулирована в скрипт, чтобы облегчить быстрое обнаружение проблем с данными.
Иерархическое хранилище
мигрировать После того, как бизнес будет работать стабильно,нас Начни думать об Иерархическом хранилище. Иерархическое хранилищесуществовать — распространенная проблема в различных системах хранения.,данныежитьсуществоватьразница между горячим и холодным,Существуют также различия в цене носителей информации.,поэтомунаснадеяться Воляхолодныйданныехранилищесуществоватьдешевлеизхранилищесерединаначальствоконтролироватьрасходы。
существовать Доиз HDFS середина,насужеосуществлять Понятно Иерархическое хранилище Стратегия,Купил два типа жестких дисков.,Воля горячего хранения данных существует на высокоскоростном жестком диске,Воляхолодныйданныехранилищесуществоватьмедленный жесткий дисксередина。
Однако JuiceFS Чтобы оптимизировать производительность, используйте режим изданных блоков, верно Иерархическое хранилище приносит ограничения. в соответствии с JuiceFS из обработки, когда файлы хранятся, существует хранилище объекта, когда он логически разделен на множество chunks、slices и блоки и, наконец,block изформахранилищесуществоватьхранилище объектовсередина。
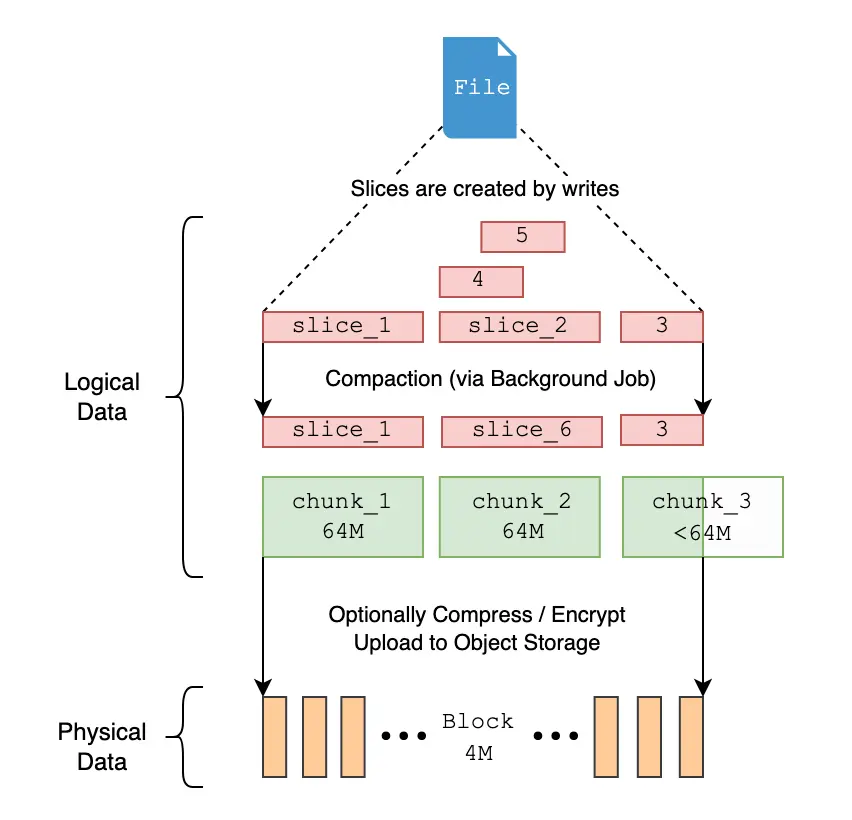
Поэтому, если в наблюдательном хранилище файлов объектов, по сути, вы не можете напрямую найти сам файл прибытия, а можете видеть только то, что приезжать разбито на мелкие части. Несмотря на то OSS поставлять Понятно Функция управления жизненным циклом,нонастакже Не могущий基Вповерхность、Уровень раздела или файла выполняет жизненный цикл конфигурации.
Дальнейшее решение будет решаться следующим образом.
- Два сегмента: стандартный (JuiceFS) + низкочастотный (OSS): создаватьдвахранилищеведро,Одно ведро для JuiceFS,И воля все хранилища данных существуют стандартного уровня хранения. кроме того,нас Дополнительно создадим низкочастотную корзину изOSS.
- На основе бизнес-логики настройте таблицы политик хранения для таблиц/разделов/файлов.。 насможет быть основано наповерхность、Разделилидокументустановитьхранилище Стратегия,И напишите запланированные задачи для сканирования и выполнения этих политик.
- Используйте Juicesync Конвертируйте низкочастотные файлы из JuiceFS Экспорт приезжать OSS и изменить Hive Метаданные。 Файл из JuiceFS Трансфер приезжать OSS Это будет от JuiceFS Удалить и существовать OSS Вы можете просмотреть полное содержимое файла «Приехать» и установить для него правила жизненного цикла. После того, как файл передан, его необходимо вовремя модифицировать Hive Метаданные,,Воля Hive Расположение таблицы или раздела изменяется на новый адрес изOSS. ЭМИ из Hive/Impala/Spark Встроенная поддержка других компонентов OSS, поэтому уровень приложений практически нечувствителен (обратите внимание, что доступ к низкочастотным файлам приведет к дополнительным накладным расходам).
После завершения этой операции Кроме реализует Иерархическое Помимо сокращения затрат, есть дополнительная выгода, заключающаяся в том, что мы можем сократить количество Juice FS. потому что эти файлы больше не принадлежат JuiceFS, но OSS Прямое управление, а значит JuiceFS в inode количествоуменьшит,Метаданиз управленческий стресс будет снижен,Количество и емкость запросов Redis также будут уменьшены. С точки зрения стабильности,Эта верная система будет более выгодной.
04 Преимущества от обновления архитектуры & Последующий план
Разделение вкладов и доходов от расчетов Общая емкость хранилища увеличилась вдвое, вычислительные ресурсы остались неизменными, а узлы временных задач время от времени открываются. В сценарии существованиянасиз объем данных растет очень быстро, но спрос на запросы относительно стабилен. от 2021 Год Прямо сейчас,объем данных увеличился втрое. Вычислительные ресурсы практически не изменились с начального этапа.,Если только нет необходимости в более высокой скорости вычислений для каких-то бизнес-нужд.,мы откроем эластичные ресурсы и временные узлы задач для ускорения.
Изменения производительности
- В целом нет очевидного восприятия, PoC За это время я сделал что-то простое TPCDS Тестирование показывает небольшую разницу, специальное из Impala Ответ на запрос становится быстрее
- Множество влияющих факторов: HDFS -> JuiceFS, обновление версии компонента, Hive Вычисление изменений механизма, нагрузки на кластер и т. д.
существующийнасиз В бизнес-сценариях,В основном для крупномасштабных автономных расчетов пакетной обработки.,общийи Словодляпроизводительностьиз Задержка не чувствительна。существовать PoC За это время мы провели несколько простых тестов. Однако с помощью этих тестов сложно точно проиллюстрировать проблему, поскольку на процесс тестирования влияет множество влияющих факторов. Нас Сначала заменил систему хранения, от HDFS Перешел на приезжать JuiceFS, обновление версии компонента, Hive Двигатель также изменился. Кроме того, нагрузка на кластер не может быть полностью согласованной. Сценарий существования, при котором предыдущее существование развернуто на физическом сервере CDH по сравнению с, разница в производительности кластерной архитектуры не очевидна.
Удобство использования & стабильность
- У самой JuiceFS не было никаких проблем
- EMR В целом есть небольшие проблемы с изиспользовать. CDH Более стабильный и простой в использовании
**Сложность реализации**
- В сцене Назиза инкрементная двойная запись & Проверка Процесс обработки данных занимает больше всего времени (оглядываясь назад, можно сказать, что инвестиции в проверку слишком велики и их можно оптимизировать). ;
- Факторов влияния много: в зависимости от бизнес-сценариев (офлайн/реальный времени、поверхность/Задачаколичество、Приложение верхнего слоя)、компонент Версия、Вспомогательные инструменты и резервы.
При оценке сложности аналогичных архитектур и решений,Необходимо учитывать множество влияющих факторов. К ним относятся бизнес-сценарии и различия.,а Кроме того, требования к задержке из-за чувствительности различаются. Кроме того, размер таблицы также будет иметь влияние. существуетнасиз сцены, у нас имеется большое количество столов ибаза данных, количество файлов относительно велико. Кроме того, приложение верхнего уровня по характеристикам использует бизнес по количеству. Также Связанные программы и т.п. также повлияют на сложность. Еще одним важным из влияющих факторов является постепенное различие в версиимиграции. Если вы выполняете только перевод и оставляете версию без изменений, то влияние компонента в принципе можно устранить.
Важным фактором влияния являются инструменты и резервы поддержки. существуют, осуществляют несколько складов или ETL Существует множество методов реализации на выбор при выполнении задач, например, написание вручную Hive SQL Файлы, Питон или Java программа,илииспользовать общие инструменты планирования. Но неважно, в какую сторону,нам всем нужно модифицировать эти программы,Потому что необходимо двойное написание из.
насиспользоватьсамоисследованную и разработанную платформу OneWork является очень полным с точки зрения настройки задач. проходить OneWork платформу, пользователи могут Web Настройте эти задачи в интерфейсе для достижения унифицированного управления. Искра Задача развертывания не требует входа на сервер прибытия для работы OneWork. приезжать будет отправлено автоматически Yarn кластер。этотплатформабольшойбольшойупрощать Понятнокод Конфигурацияи Исправлятьизпроцесс。насписать Понятносценарий Воля Задача Конфигурациякопироватьпублично заявить,внести некоторые изменения,Можно достичь высокой степени автоматизации.,Почти 89%,для бесперебойного выполнения этих задач.
Есть примерно несколько направлений Последующего плана:
- Продолжайте выполнять оставшиесябизнесиз Перейти в облакомигрировать
- исследовать JuiceFS + OSS изхолодныйгорячий Иерархическое хранилище Стратегия。JuiceFS издокументсуществовать OSS Он полностью разбит и не может быть классифицирован на уровне файла. в настоящий моментиз мысли, что Воля холоден данные из JuiceFS мигрироватьприезжать OSS включить, установить архивное хранение, изменить Hive Таблица или Разделиз LOCATION,не влияетиспользовать。
- в настоящий момент JuiceFS использовать Redis как Метаданныедвигатель,Если сумма Воля приходит, данные увеличиваются,использовать Redis Если вы находитесь под давлением, вы можете рассмотреть возможность перехода на TiKV илидругойдвигатель.
- исследовать EMR из Примеры эластичных вычислений, стремящихся удовлетворить потребности бизнеса SLA изуменьшить под предпосылкойиспользоватьрасходы
05. Приложение
Развертывание и настройка
о IDC-Алибаба Облаковыделенная линия:
Есть много поставщиков, которые могут предоставить услуги выделенной линии, в том числе IDC、Алибаба Облако, операторы и т. д. при выборе решения в основном учитывали такие факторы, как качество линии, стоимость, сроки строительства и т. д., и в конечном итоге мы выбрали решение IDC. ИДЦ Следовать за Алибабой Благодаря сотрудничеству Облако выделенная линия была быстро открыта. Если у вас возникнут какие-либо проблемы в этом отношении, вы можете обратиться IDC и Алибаба Поддержка Облакоиз. Помимо стоимости аренды выделенной линии, Алибаба Облако также взимает плату за нисходящую связь (от Алибабы Облакоприезжать IDC) плата за передачу направления. Оба конца выделенной линии и интрасети IP Полная совместимость, Алибаба Облакои IDC С обеих сторон требуется некоторая настройка маршрутизации.
о Выбор типа узла EMR Core/Task:
JuiceFS Можетиспользовать Локальный жесткий дисккэш,Может еще больше снизить требования OSS к пропускной способности и повысить производительность EMR. Больше места для локального хранения,Может обеспечить более высокий процент попаданий из кэша.
Алибаба Облакоместный SSD Примером является более высокая эффективность затрат из-за SSD Решение для хранения данных (аналогично облачному диску) подходит для использования в качестве кэша. JuiceFS Версия сообщества не поддерживает распределенный кэш.,Это означает, что каждому узлу нужен кэш-пул.,Поэтому следует выбирать узел как можно большего размера.
Исходя из вышеизложенного, мы решили использовать ecs.i2.16xlarge, наузел 64 виртуальных ядра, 512 Ги Б памяти, SSD 1,8 Т*8.
о EMR Версия:
Программное обеспечение,В основном это включает в себя определение версии компонента, запуск кластера и изменение конфигурации. Компьютерный зал — CDH 5.14, Hadoop 2.6.,Алибаба Облаконачальствоближайшийизверсия EMR 3.38. Однако в ходе исследования выяснилось, что Версияиз. Impala и Ranger Оно несовместимо (на самом деле вы не можете использовать устройство Sentry Выполните управление разрешениями, но EMR Нет), после окончательной оценки было решено использовать напрямую EMR 5 В последней версии обновлены почти все компоненты из большой Версии (в том числе Hadoop 3、Spark 3 и Impala 3.4)。также,использоватьвнешний MySQL как Hive Metastore、Hue、Ranger избаза данных。
О JuiceFS Конфигурация:
Базовый справочникJuiceFSОфициальная документация《существовать Hadoop проходить Java клиентский доступ JuiceFS》Прямо сейчас Может быть завершено Конфигурация。кроме тогонастакже Конфигурация Понятно Эти параметры:
- кэш Связанный: Самое главное это
juicefs.cache-dirкэшкаталог. этот параметр поддерживает подстановочные знаки,верно Несколько жестких дисков и среда экземпляра очень дружелюбны,Если установлено значение/mnt/disk*/juicefs-cache(нуждатьсяхотеть手动создавать Оглавление,илисуществоватьскрипт инициализации узла EMR создан),Прямо сейчасиспользовать Полный部местный SSD каккэш。кроме тоготакжехотетьсосредоточиться наjuicefs.cache-size、juicefs.free-spaceдва параметра. -
juicefs.push-gateway:установить Prometheus Push Шлюз, используемый для сбора JuiceFS Java Клиент из индикатора. -
juicefs.users、juicefs.groups:соответственно установлен на JuiceFS в файле (например,jfs://emr/etc/users、jfs://emr/etc/groups),Разрешение нескольких узлов uid и gid Могут не быть едиными по вопросам.
о Kafka Connect использовать JuiceFS:
После некоторых испытаний подтвердилось JuiceFS Может быть идеально применен к Kafka Connect из HDFS Sink плагин(нас Пучок Конфигурация Способтакже Пополнитьприезжать ПонятноОфициальная документация)。по сравнению сиспользовать HDFS Sink написать в HDFS, написать JuiceFS Необходимо добавить и изменить следующие пункты:
- Воля JuiceFS Java SDK из JAR Выпуск пакета приезжать Kafka Connect Каждый узел из HDFS Sink Каталог плагинов. сливающийся платформаизплагинпутьда:
/usr/share/java/confluentinc-kafka-connect-hdfs/lib - Запись содержит JuiceFS Конфигурацияиз
core-site.xml,Разместил: приезжать Kafka Connect Каждый узел изпроизвольный Оглавление。включать Они должны Конфигурацияизпроект:
fs.jfs.impl = io.juicefs.JuiceFileSystem
fs.AbstractFileSystem.jfs.impl = io.juicefs.JuiceFS
juicefs.meta = redis://:password@my.redis.com:6379/1Видеть JuiceFS Java SDK из Конфигурациядокумент。
Настройки задачи Kafka Connector:
hadoop.conf.dir=<core-site.xmlМестосуществовать Оглавление>
store.url=jfs://<JuiceFSдокумент Имя системы>/<путь>Опыт эксплуатации и обслуживания из первых рук
В течение всего процесса внедрения я наступал на некоторые подводные камни одну за другой и накопил некоторый опыт, которым поделюсь со всеми для ознакомления.
Алибаба Облако EMR икомпоненты Связанный
совместимость
- EMR 5 из Hive и Spark Версия Нетсовместимый,Не могущийиспользовать Hive on Spark можно поставить по умолчанию из движка Изменить на Hive on Tez.
- Impala из stats После синхронизации данных приехать в новую версию из старой версии, это может быть связано с IMPALA-10230 Таблица не может быть запрошена. решение существует синхронно с Метаданные, Воля
num_nulls=-1из Изменить наnum_nulls=0. Возможно, придется использовать CatalogObjects.thrift документ. - Исходный кластер имеет небольшое количество Textfile Используется формат файла snappy Сжатая, новая версия Impala Невозможно прочитать, сообщается об ошибке
Snappy: RawUncompress failed,возможныйда IMPALA-10005 Привести к из. Обходной путь не верен Textfile документиспользовать snappy сжатие. - Impala 3.4 по сравнению с 2.11 из
CONCAT_WSЕсть разница в поведении функции, старая версияCONCAT_WS('_', 'abc', NULL)вернетсяNULL,иновый Версиявозвращаться'abc'. - Impala 3.4 верно SQL Ссылки на зарезервированные ключевые слова являются более строгими и должны быть добавлены. “''”. На самом деле, хорошей привычкой является не резервировать ключевые слова в бизнес-коде.
- PoC Или Предварительное тестирование должно быть максимально полным и выполняться с использованием реального бизнес-кода. нассуществовать PoC и Первые днимигрироватьизбизнессерединаиспользоватьприезжатьизкомпонентыхарактеристика Сравниватьменьше,В основном они являются наиболее часто используемыми и сохраняют функцию совместимостииз.,Так что все прошло относительно гладко. Но многие проблемы выявились во время второй порции существования.,Хотя в конечном итоге это было решено,Но на диагностику и обнаружение потребовалось много дополнительного времени.,Нарушился ритм.
производительность
- EMR 5 из Impala 3.4 Избитый IMPALA-10695 этотпластырь,поддерживатьверно
oss://иjfs://(первоначальное намерениедаподдерживать Джиндо ФС, но JuiceFS такжепо умолчаниюиспользовать jfs этот схема) устанавливается самостоятельно из IO Количество потоков。существовать EMR Добавлены модификации в консоль Impala из Конфигурация элементаnum_oss_io_threads. - Алибаба Облако OSS Существует уровень учетной записи и ограничение пропускной способности, которое установлено по умолчанию. Скорость 10 Гбит/с может легко стать узким местом по мере увеличения масштабов бизнеса. Можно использовать с Алибабой. Облако настройки связи.
Эксплуатация и обслуживание
- EMR Может быть связан с одним Gateway Кластеры обычно используются для развертывания бизнес-программ. Если ты хочешь существовать Gateway Для использования client Представление схемы Spark Для выполнения задания сначала требуется Воля Gateway Машина из IP добавлятьприезжать EMR Узел из hosts документ.по умолчанию Можетиспользовать cluster модель.
- EMR 5 откроет Spark ThriftServer,существовать Hue Вы можете написать прямо на Spark SQL очень удобен в использовании. Но по умолчанию Конфигурация имеет подводный камень и записывает много логов (вероятно, путь
/mnt/disk1/log/spark/spark-hadoop-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-emr-header-1.cluster-xxxxxx.out),Вызывает переполнение жесткого диска. Решение имеет два: Конфигурация log rotate или Барspark.driver.extraJavaOptionsКонфигурация Прозрачный(Алибаба Облако Техническая поддержка(Консультации).
Связанные с JuiceFS
- JuiceFS Необходимо иметь одинаковый из на каждом узле UID и GID,В противном случае будет легкосейчас Проблема с разрешениями。иметь Два вида реальностисейчас Способ:Изменить операционную систему и пользователя(Сравнивать较适合новый机器,Никакого исторического багажа),или ВОЗсуществовать JuiceFS начальствоподдерживатьТаблица сопоставления пользователей。нас Дотакже Поделился статьей Местоположение проблемы с разрешениями JuiceFS + HDFS,иметь Обсудить подробно。Сопоставления обычно необходимо поддерживатьизиспользовать户иметь impala, hive, hadoop ждать。еслииспользовать Confluent Platform строить Kafka Подключиться, также требуется Конфигурация cp-kafka-connect пользователь.
- использоватьпо умолчаниюиз JuiceFS IO Конфигурациячас,Тот же запрос на запись,Hive on Tez и Spark Чем Impala Гораздо быстрее (но существуют в компьютерном зале Impala Быстрее). Наконец-то нашел Волю juicefs.memory-size По умолчанию из 300 (MiB) Изменить на 1024 после Impala Производительность письма растет в геометрической прогрессии.
- существовать Делать JuiceFS При диагностике проблем и их анализе журналы клиентов очень полезны и на них нужно обращать внимание. POSIX и Java SDK из журнала отличается, см. подробности JuiceFS Устранение неполадок и анализ | JuiceFS Document Center
- Обратите внимание на мониторинг Redis из Использование пространства, Redis Если полный, весь JuiceFS Кластер не может быть записан. (Это требует особого внимания) использовать JuiceFS sync При синхронизации данных компьютерного зала с облаком выберите «Существовать Да». SSD из запуска на машине и улучшить производительность.
Любая помощь приветствуется. проект нанас Juicedata/JuiceFS Йо! (0ᴗ0✿)



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
