Девять методов оптимизации производительности сервисной архитектуры
Автор:jialiangsun
Недавно мы провели некоторую оптимизацию производительности службы. Среднее время службы пула статей и время p99 снизилось примерно на 80%. Среднее время службы нижней страницы событий снизилось более чем на 50%. Некоторые необоснованные конструкции. в основных проектах оптимизации, таких как использование данных передачи JSON между службами, логика обработки мониторинга и отчетности в основном процессе, дублирование данных, каждый раз запрашивающие нижестоящие службы, множественные трудоемкие операции, последовательные запросы и т. д. Эти проблемы оказывают серьезное влияние о выполнении услуги.
При проектировании архитектуры службы вы обычно можете использовать какое-либо промежуточное программное обеспечение для повышения производительности службы, например mysql, redis, kafka и т. д., поскольку это промежуточное программное обеспечение имеет хорошую производительность чтения и записи. Помимо использования промежуточного программного обеспечения для повышения производительности сервисов, мы также можем изучить, какие базовые конструкции они используют для достижения высокой производительности, и применить эти конструкции к нашей архитектуре сервисов.
Часто используемые методы оптимизации производительности можно разделить на следующие категории:
Девять способов оптимизировать производительность:
кэш
Оптимизация производительности,кэш – король,Итак, начнем с введения кэша. Кэш повсюду в наших проектах Архитектуры,Обычный запрос — это запрос, инициированный браузером.,просить Служитьконец Служить,Служитьконец Служить Запросить еще разданныев библиотекеданные,Для каждого чтения данных требуется как минимум два сетевых ввода-вывода.,Производительность будет хуже,Мы можем добавлять кэш на протяжении всего процесса, чтобы повысить производительность. Сначала тест браузера,Вы можете контролировать, использует ли браузер локальный кэш, через Expires, Cache-Control, Last-Modified, Etag и другие связанные поля.
Во-вторых, мы можем использовать локальное или какое-то промежуточное программное обеспечение на конце Служить для кэширования.,Например редис. Почему Redis такой быстрый,Главным образом потому, что данные хранятся в памяти.,Нет необходимости читать диск,Потому что скорость чтения памяти обычно в сотни и более раз превышает скорость чтения с диска;
Затем протестируйте его в библиотеке данных.,Обычно используется MySQL,данные MySQL хранятся на диске,Но чтобы улучшить производительность чтения и записи, MySQL,Будет использовать буферный пулкэшданные страницы. Когда mysql выполняет чтение, он считывает страницу данных в буферный пул в соответствии с степенью детализации страницы.,Страница данных в буферном пуле использует алгоритм LRU для исключения страниц, которые не использовались в течение длительного времени.,кэш Недавно посещенные страницы с данными.
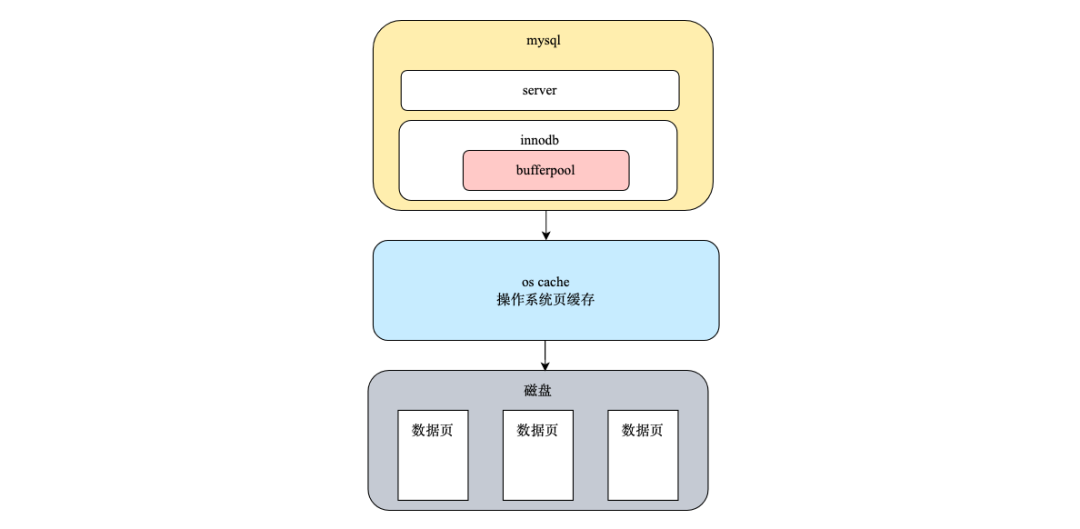
Кроме того, размеры кэшей процессора L1, L2 и L3 составляют всего лишь,Даже кэш браузера направлен на повышение производительности.,кэш Также происходит Служить Оптимизация Важный показатель производительности: при использовании кэша необходимо учитывать следующие моменты.
Какой кэш использовать?
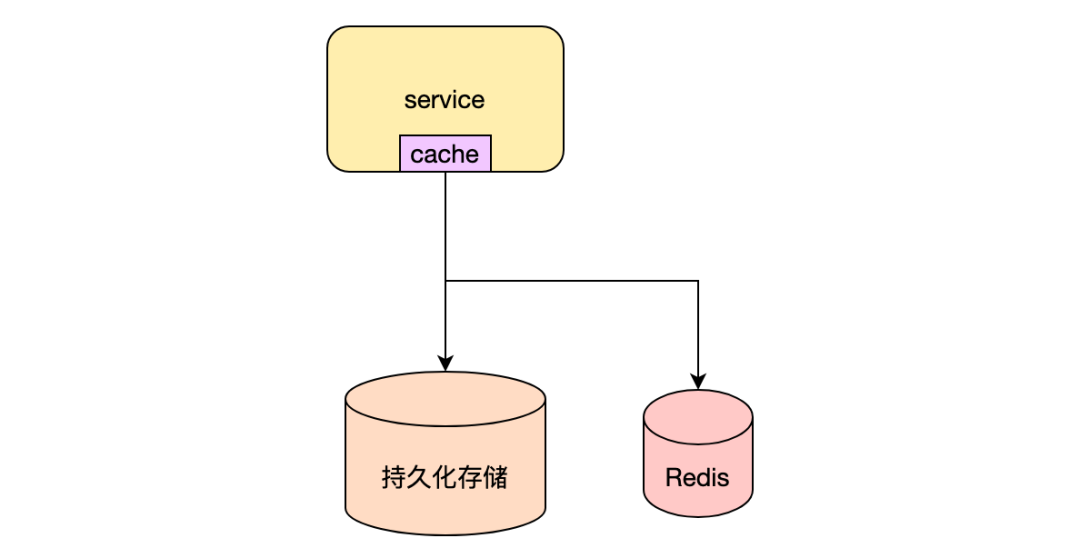
При использовании кэша вы можете использовать Redis или машинную память для кэшданных.,Преимущество использования Redis заключается в обеспечении согласованности чтения данных с разных машин.,Но чтение Redis увеличит ввод-вывод.,Несогласованность чтения данных может возникнуть при использовании кэшированной памяти.,Но скорость чтения хорошая. Например, количество прочтений данных статьи,Если использовать память машины в качестве кэша,Легко иметь несоответствия на разных машинах.,Пользователи будут запрашивать разные машины Служить для разного времени обновления.,Количество прочитанных чтений непоследовательно,Может случиться так, что количество чтений станет меньше,Пользовательский опыт не очень хороший. Для чтения чисел, которые часто меняются, удобнее использовать redis для унификации кэша.
Вы также можете объединить их, чтобы улучшить производительность Служить.,Например, в пуле контента Служить,Использование Redis и машинной памяти кэш Подробности статьи,Установите приоритет чтения данных из памяти машины.,Когда данные не существуют, будут читаться кэшданные в Redis.,Когда данные в Redis также не существуют,Считает полный объем данных в нижестоящем постоянном хранилище. Время истечения уровня памяти составляет 15 с.,Согласованность данных не гарантируется при их изменении.,Окончательная согласованность гарантируется за счет естественного истечения срока действия данных. кэшданные в Redis должны обеспечивать согласованность с данными в постоянном хранилище.,Как обеспечить согласованность, будет объяснено позже. Вы можете выбрать подходящее решение в соответствии с вашим бизнес-сценарием.
При использовании кэша вы можете использовать Redis или машинную память для кэшданных.,Преимущество использования Redis заключается в обеспечении согласованности чтения данных с разных машин.,Но чтение Redis увеличит ввод-вывод.,Несогласованность чтения данных может возникнуть при использовании кэшированной памяти.,Но скорость чтения хорошая. Например, количество прочтений данных статьи,Если использовать память машины в качестве кэша,Легко иметь несоответствия на разных машинах.,Пользователи будут запрашивать разные машины Служить для разного времени обновления.,Количество прочитанных чтений непоследовательно,Может случиться так, что количество чтений станет меньше,Пользовательский опыт не очень хороший. Для чтения чисел, которые часто меняются, удобнее использовать redis для унификации кэша.
Вы также можете объединить их, чтобы улучшить производительность Служить.,Например, в пуле контента Служить,Использование Redis и машинной памяти кэш Подробности статьи,Установите приоритет чтения данных из памяти машины.,Когда данные не существуют, будут читаться кэшданные в Redis.,Когда данные в Redis также не существуют,Считает полный объем данных в нижестоящем постоянном хранилище. Время истечения уровня памяти составляет 15 с.,Согласованность данных не гарантируется при их изменении.,Окончательная согласованность гарантируется за счет естественного истечения срока действия данных. кэшданные в Redis должны обеспечивать согласованность с данными в постоянном хранилище.,Как обеспечить согласованность, будет объяснено позже. Вы можете выбрать подходящее решение в соответствии с вашим бизнес-сценарием.
кэшFAQ
1. Кэш-лавина: кэш-лавина означает одновременный сбой или истечение срока действия большого количества данных в кэше.,В результате большое количество запросов должно быть прочитано непосредственно в нижестоящую библиотеку данных.,Создание чрезмерной мгновенной нагрузки на библиотеку данных.,Обычное решение — рандомизировать время истечения срока действия, установленное кэшданными. В случае «Служить» статьи удалялись с использованием фиксированного срока действия + случайное значение.,Избегайте лавин.
2. Проникновение кэша: проникновение кэша относится к чтению данных, которые не существуют в дальнейшем.,В результате кэш не может попасть в цель.,Библиотека данных нисходящего потока запрашивается каждый раз. Такая ситуация обычно возникает при возникновении аномальных атак на онлайн-трафик или при удалении нисходящего трафика.,Для проникновения кэша можно использовать фильтр Блума для фильтрации несуществующих данных.,Или при чтении нисходящих данных не существует,Нулевые значения можно задать в кэше,Предотвратить постоянное проникновение. Событие Служить может привести к удалению статьи запроса.,Он заключается в использовании метода установки нулевого значения, чтобы предотвратить постоянное проникновение запроса удаленных данных в нисходящий поток.
3、 Распределение кэша: кэш Пробой относится к определенной горячей точкеданныесуществоватькэшсреднее одеялоудалитьили срок действия истек,В результате большое количество запросов к точкам доступа одновременно запрашивают библиотеку данных. Решением может быть установка более длительного срока действия данных точки доступа или использование распределенных блокировок, чтобы предотвратить одновременный доступ нескольких одинаковых запросов к нисходящей Служить. в новостном бизнесе,Такое часто случается с горячими новостями,Событие Служить использует синглфилг Голанга, чтобы гарантировать, что только один запрос на одну и ту же статью будет запрошен в нисходящем направлении одновременно.,Предотвратить поломку кэша.
4. Клавиша точки доступа: ключи точки доступа относятся к часто используемым ключам в кэше.,В результате объем сегментирования или повторного доступа ключа слишком велик. Ключи Hotspot можно распределять и хранить на нескольких ключах.,Например, сохраните ключ точки доступа + серийный номер.,Значения, хранящиеся в разных ключах, одинаковы,Случайный доступ к ключу во время доступа,Рассейте давление оригинального осколка с одним ключом, кроме того, вы также можете переместить ключ в память машины;,Избегайте чрезмерного давления на один узел Redis.,в новостном бизнесе,Этот метод используется для горячих статей.,Храните горячие статьи в памяти машины,Избегайте чрезмерных запросов Redis с одним сегментом для хранения горячих статей.
key val => key1 val 、 key2 val、 key3 val 、 key4 val
кэшликвидация
Размер кэша ограничен,Потому что надо удалить данные в кэше,Обычно для исключения данных можно использовать случайные алгоритмы LRU или LFU. LRU — один из наиболее часто используемых алгоритмов замены.,Удалите самые последние использованные данные,Нижний уровень может быть реализован с использованием структуры данных карта+двусторонняя очередь.
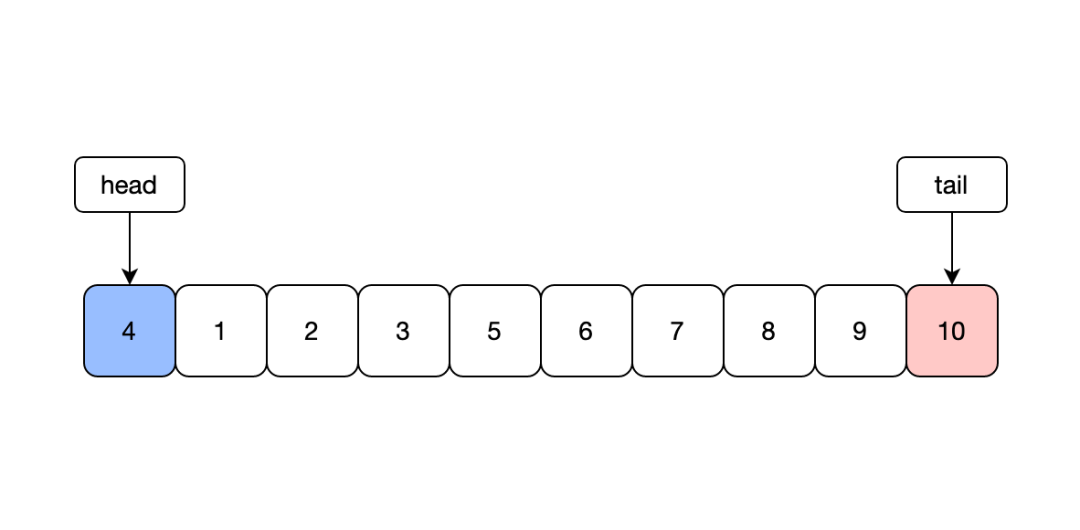
Самый родной алгоритм LRU имеет некоторые проблемы,Не знаю, сталкивался ли кто-нибудь с какими-либо проблемами перед использованием. Первое, что следует отметить, это наличие блокировки мьютекса в структуре данных.,Потому что golang вызовет панику при чтении и написании карты.,Вызывает исключение Служить. Использование блокировки мьютекса приведет к ухудшению общей производительности.,Вы можете использовать идею шардинга,Разделите весь LRUCache на несколько,Чтение одного из фрагментов кэша при каждом чтении,Уменьшите степень детализации блокировки для повышения производительности.,Распространенные пакеты локального кэша обычно реализуются таким образом.
type LRUCache struct {
sync.Mutex
size int
capacity int
cache map[int]*DLinkNode
head, tail *DLinkNode
}
type DLinkNode struct {
key,value int
pre, next *DLinkNode
}
mysql также будет использовать алгоритм LRU для буферизации. Страницы данных в пуле удаляются. Из-за упреждающего чтения в MySQL при чтении диска он не читает по требованию, а читает в соответствии с детализацией всей страницы данных. также можно прочитать соседние страницы данных, которые можно будет использовать в дальнейшем. кэы в пул буферов заранее. Если данные, считанные в следующий раз, будут в кэше, просто прочитайте память напрямую, не считывая с диска. Однако, если к предварительно считанной странице данных не было доступа, произойдет сбой упреждающего чтения. В этом случае исходная использованная страница данных будет удалена. MySQL будет буферизовать poolСвязанный список разделен на две части.,Один раздел - новое поколение,Один раздел - старое поколение,Соотношение по умолчанию между старым и новым поколениями составляет 7:3.,Если страница данных предварительно прочитана, она сначала будет добавлена к старому поколению.,Он будет загружен в новое поколение при доступе к странице данных.,Это предотвращает неиспользование предварительно считанной страницы данных и исключает использование «горячей» страницы данных. Кроме того, в MySQL обычно есть запросы на сканирование таблиц.,Будет последовательно запрашивать большое количество данных для загрузки в кэш,Затем удалите все горячие страницы данных в исходном кэше.,Эту проблему часто называют загрязнением буферного пула.,Страница данных в MySQL должна решить проблему загрязнения пула, когда старое поколение остается дольше настроенного времени, прежде чем старое поколение перейдет в новое поколение.
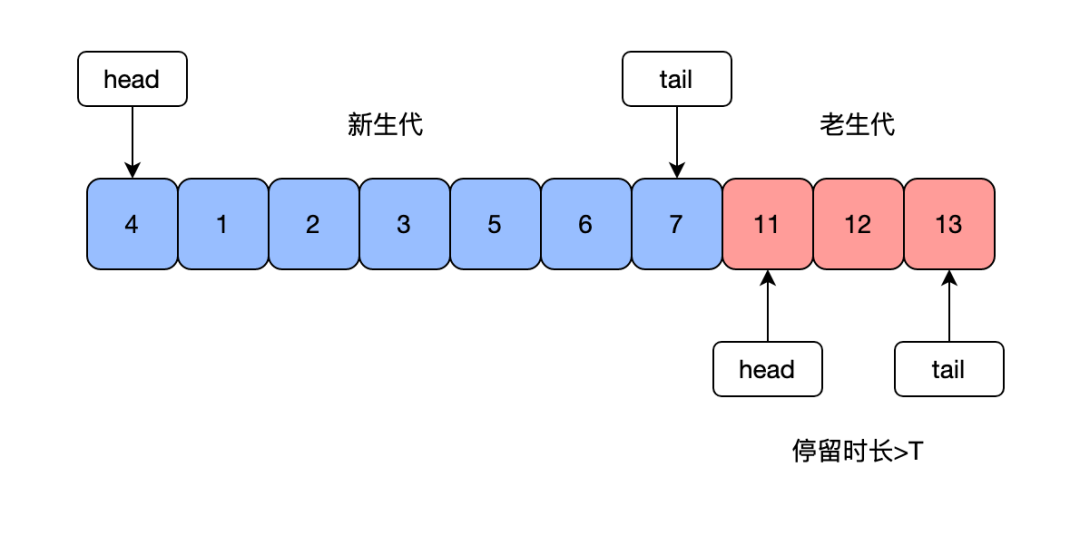
LRU также будет использоваться в Redis для устранения данных с истекшим сроком действия.,Если redis управляет всеми кэшданными через большой связанный список,Перемещайте данные, к которым последний раз осуществлялся доступ, в начало связанного списка каждый раз, когда они читаются или записываются.,Это серьезно повлияет на производительность чтения и записи Redis, а также увеличит дополнительное пространство для хранения.,Уменьшите общий объем хранилища. Redis добавляет поле времени последнего доступа к объектам в кэше,При удалении объектов,Будет использоваться случайная выборка,Выберите 5 значений случайным образом,Удалить последний посещенный,Это позволяет избежать перемещения узла каждый раз. Однако LRU также может пострадать от загрязнения кэша.,Чтение большого количества данных одновременно устранит «горячие точки» данных.,Таким образом, Redis может использовать LFU для удаления данных.,Это поле, которое заменяет исходное поле времени доступа на самое последнее время доступа + количество посещений.,Здесь необходимо отметить, что количество посещений — это не просто накопление времени.,Вместо этого временное затухание выполняется на основе разницы между временем последнего доступа и текущим временем.,Проще говоря, чем дольше посещение и чем меньше количество посещений, тем меньше расчетное значение.,Тем легче его устранить.
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} obj ;
Видно, что различные промежуточные программы внесли определенные оптимизации в традиционную стратегию устранения LRU, чтобы обеспечить производительность Служить. Мы также можем обратиться к различным стратегиям оптимизации для устранения кэш-ключа в нашей собственной Служить.
кэшданные Консистенция
Когда данные изменяются в библиотеке данных,Как обеспечить соответствие кэша данным в библиотеке данных,Обычно есть следующие решения: обновить кэш, а затем обновить БД.,Обновите БД, а затем обновите кэш.,Сначала обновите БД, а потом удалите кэш,Удалите кэш и затем обновите БД. Эти решения могут привести к несоответствию кэша данным в библиотеке данных.,Самый распространенный метод — обновить БД с последующим удалением кэша.,Потому что это решение имеет наименьшую вероятность вызвать несогласованность данных.,Но проблема несоответствия данных все равно останется. Например, в кэше Т1 нет данных.,данныебиблиотекаданныедля100,Запрос потока B кэш не запросил данные,Прочитайте data100 из библиотеки данных, а затем обновите кэш.,Но в это время поток A обновляет данные в библиотеке данных до 99.,Затем удалите данные в кэше в момент T4.,Но данных в кэше пока нет,Поток B обновляет только кэшданные до 100 на T5.,Это приведет к тому, что кэш будет несовместим с данными в библиотеке данных.
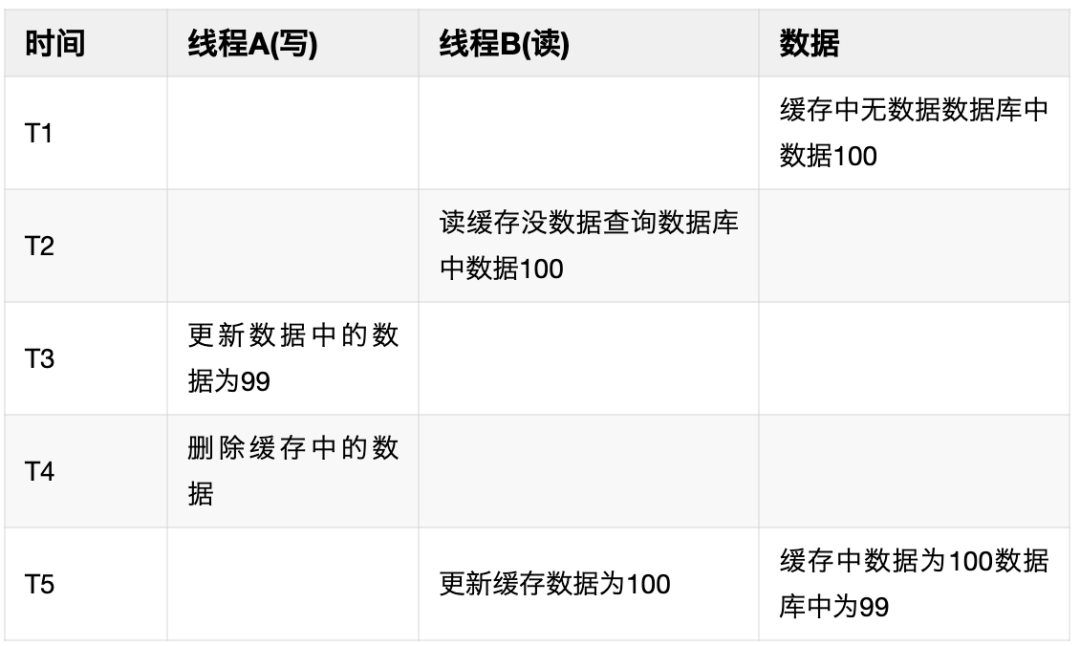
Чтобы обеспечить согласованность кэша с данными библиотеки data. Есть два часто используемых решения,Один из них — отложенное двойное удаление.,Сначала удалить,Последующие обновления библиотеки данных,Поспите немного, а затем удалите кэш. Это решение используется в пуле статей Служить для обеспечения согласованности данных.,Как реализовать отложенное удаление,Это простая очередь задержки, реализованная через канал на языке go.,Сторонняя очередь сообщений не введена.,В основном для предотвращения усложнения Служить еще одним способом подписки на бинлог изменений БД;,данные Обновлять БД только при обновлении,Используя журналы binlog БД,Разобрать операцию изменения для выполнения кэш-изменений,Сообщение не будет отправлено в случае сбоя обновления.,Окончательная согласованность достигается с помощью механизма повторных попыток очереди сообщений.
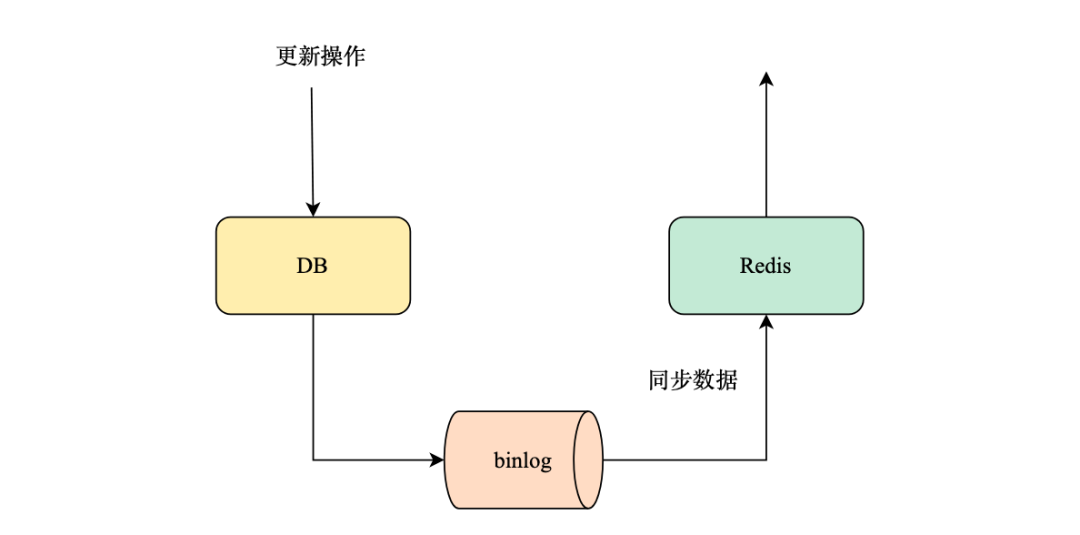
параллельная обработка
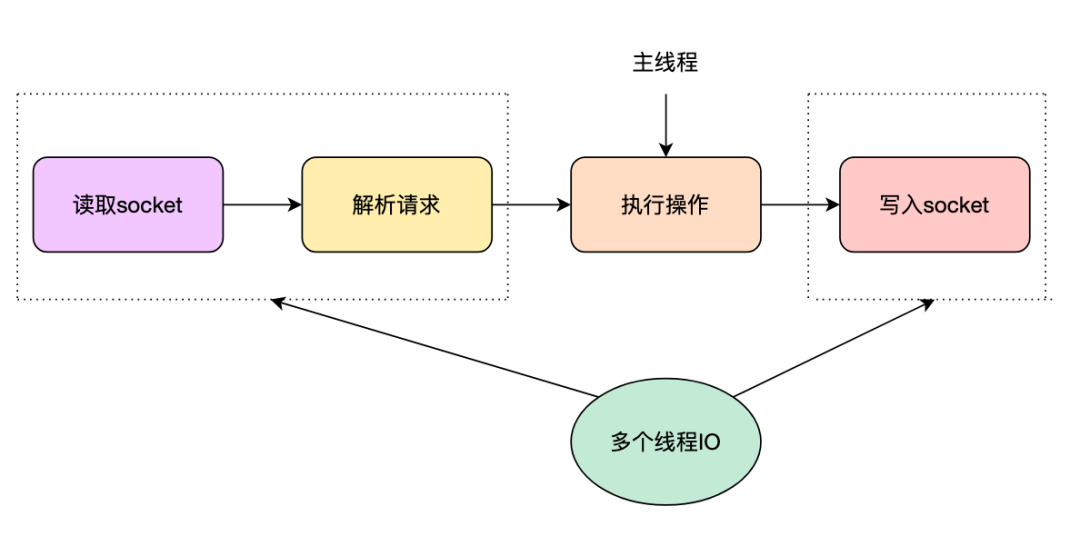
До версии Redis 6.0 она была известна как однопоточная модель. Она в основном использовала epllo для управления массовыми соединениями пользователей и использовала один поток для обработки пользовательских запросов через цикл событий. Преимущество заключается в том, что она позволяет избежать переключения потоков и конкуренции блокировки. и прост в реализации, но имеет недостатки. Также очевидно, что многоядерные ресурсы ЦП не могут быть эффективно использованы. По мере увеличения объема данных и параллелизма ввод-вывод стал узким местом Redis в производительности, поэтому многопоточная модель была введена в версии 6.0. Многопоточность Redis завершает наиболее трудоемкие операции чтения, анализа и записи сокета посредством одновременного выполнения нескольких операций ввода-вывода, а выполнение команд по-прежнему выполняется в одном потоке.
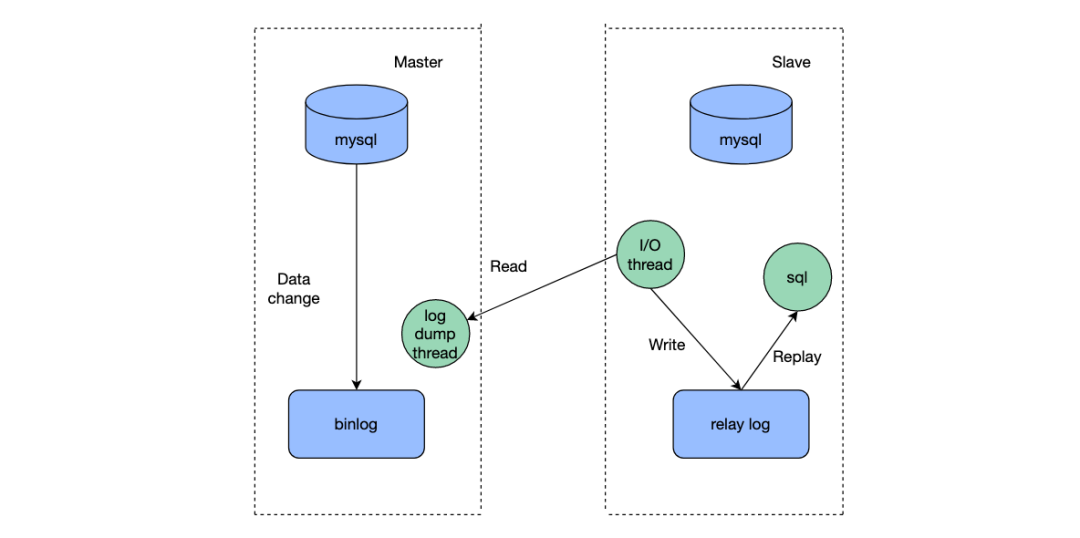
Процесс синхронизации master-slave в mysql считывает binlog основной библиотеки из базы данных через I/Othread, записывает журнал в журнал ретрансляции, а затем sqlthread выполняет релейный журнал для синхронизации данных. Среди них sqlthread выполняется одновременно несколькими потоками для ускорения синхронизации данных и предотвращения задержек синхронизации между главным и подчиненным устройствами. Многопоточность SQLthread также прошла через несколько итераций версий: от распределения в один и тот же поток в соответствии с измерением таблицы для синхронизации данных до распределения в один и тот же поток в соответствии с измерением строки.
Параллельная обработка размером с потоки,Кластер размером с Redis,Помимо разделения тем Kafka, несколько клиентов используются для параллельной обработки, чтобы улучшить производительность чтения и записи Служить. В нашем проекте «Служить» пропускную способность «Служить» можно повысить, создав несколько контейнеров для внешней «Служить».,Служить может внутренне преобразовывать несколько последовательных операций ввода-вывода в параллельную обработку.,Сократить время отклика интерфейса,Улучшите пользовательский опыт. Существуют взаимозависимости для ввода-вывода,Возможно многоэтапное дозирование. параллельная обработка.,Другое распространенное решение — использовать DAG для ускорения выполнения.,Однако следует отметить, что DAG будет иметь высокие затраты на разработку и обслуживание.,Вам необходимо выбрать подходящее решение, исходя из вашего бизнес-сценария. Распараллеливание имеет не только преимущества и недостатки.,Распараллеливание может привести к серьезной диффузии чтения.,А частое переключение потоков оказывает определенное влияние на производительность.
Пакетная обработка
Отправка сообщений Kafka не записывается брокеру напрямую. Процесс отправки заключается в отправке сообщений, отправленных в одну и ту же тему и в один и тот же раздел, в одну и ту же очередь через компонент секционирования основной функции, а поток отправителя постоянно втягивает сообщения. очередь. Отправляйте брокеру партиями. Используйте обработку сообщений пакетной отправки, чтобы сэкономить много сетевых ресурсов и повысить эффективность отправки.
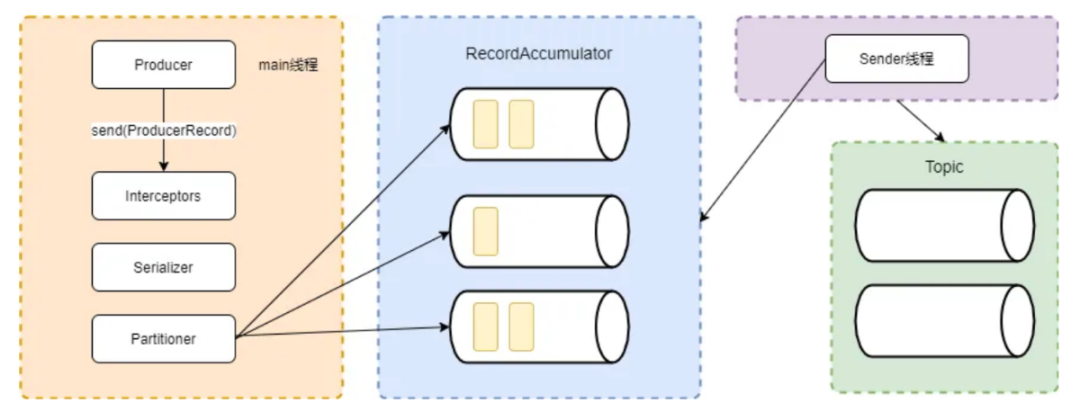
Существует два метода сохранения данных Redis: RDB и AOF. После того, как AOF выполнит команду и запишет ее в память, она будет записана в буфер AOF. Вы можете выбрать подходящее время для записи данных из буфера AOF на диск. и обновите его. Время на диске контролируется параметром addfsync, который имеет три значения: всегда, каждую секунду и нет. Среди них всегда будут сбрасываться на диск после выполнения каждой команды, чтобы обеспечить надежность данных; каждая секунда записывается на диск пакетами каждую секунду, и это означает, что операционная система не выполняет операцию синхронизации. диск обратной записи. Если Redis работает ненормально, существует риск потери данных при выходе. Время, когда команда AOF сбрасывается на диск, влияет на производительность записи службы redis. Обычно она настроена на запись на диск в пакетном режиме каждую секунду, чтобы сбалансировать производительность записи и надежность данных.
Когда мы читаем нижестоящие сервисы или базы данных, мы можем запрашивать несколько фрагментов данных одновременно, чтобы сэкономить сетевой ввод-вывод; при чтении Redis мы также можем использовать сценарии конвейера или Lua для обработки нескольких команд для повышения производительности чтения и записи; -end запрашивает файлы js или Для небольших изображений несколько файлов или изображений js можно объединить и вернуть вместе, чтобы уменьшить количество внешних соединений и повысить производительность передачи. Также важно отметить, что пакетная обработка нескольких фрагментов данных может снизить пропускную способность, а сам нисходящий поток не поддерживает слишком много пакетных данных. В этом случае несколько фрагментов данных могут быть запрошены одновременно в пакетах. Для разных идентификаторов статей, настроенных в разных компонентах события, лежащего в основе службы страниц, последующие службы контента будут одинаково запрашиваться пакетами для получения сведений о статье. Количество пакетов также будет ограничено, чтобы предотвратить слишком большой объем данных в одном пакете. большой.
Сжатие и объединение данных
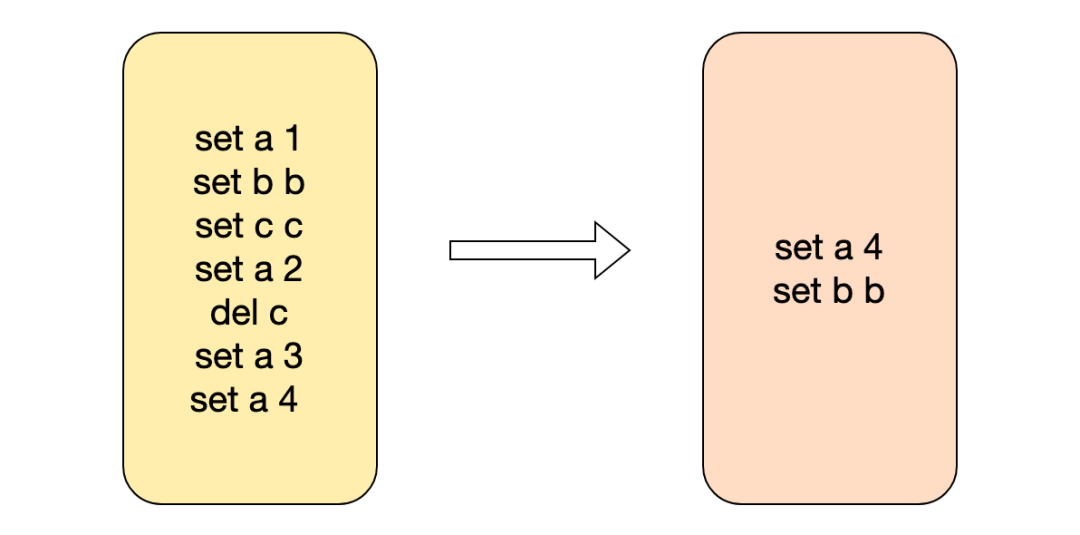
Перезапись AOF в Redis использует команду bgrewriteaof для перезаписи файла AOF. Поскольку AOF представляет собой журнал записи добавления, для одного и того же ключа может быть несколько команд изменения, в результате чего файл AOF будет слишком большим. Загрузка файла AOF станет медленной. redis перезапускается, в результате чего время запуска становится слишком длинным. Вы можете использовать команду перезаписи, чтобы сохранить только одну запись изменений одного и того же ключа, уменьшив размер файла AOF.
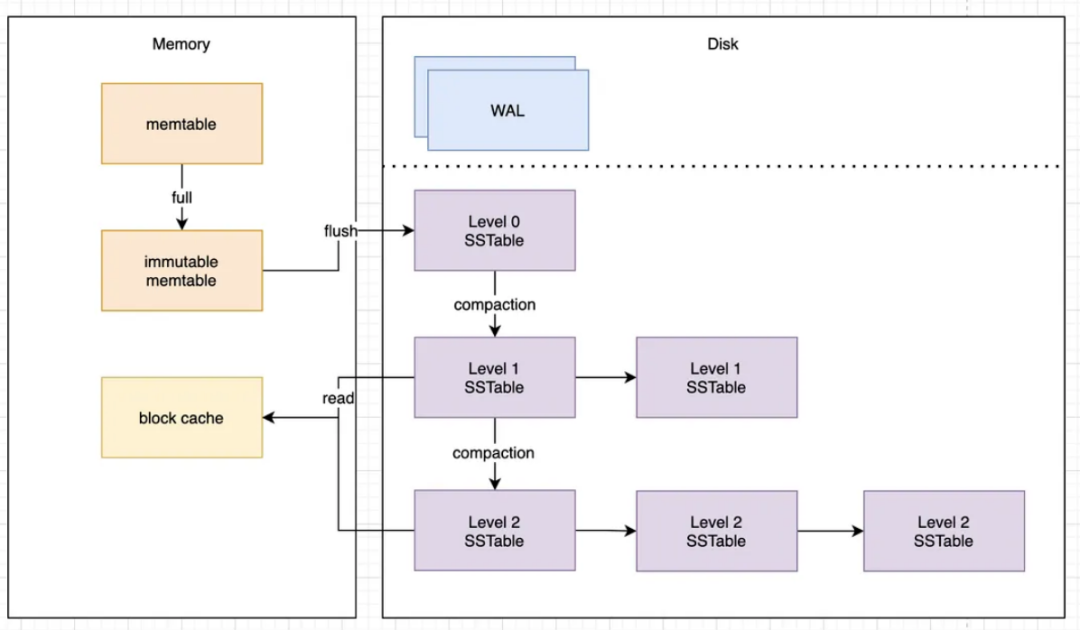
Базы данных Nosql, такие как Hbase и cassandra, в области больших данных имеют очень высокую производительность записи. Их базовая структура данных хранения — это LSM-дерево (дерево слияния со структурой журнала). Основная идея этой структуры данных — добавление записей и накопление. определенный объем данных перед объединением в более крупный сегмент, и для удаления данных добавляется только одна запись об удалении. Аналогично, существует несколько записей модификации для ключа. Преимуществом такой структуры хранения является высокая производительность записи, но очевидны и недостатки, такие как избыточность данных и большой размер файла. В основном за счет объединения сегментов в потоках несколько небольших файлов объединяются в файлы большего размера, чтобы уменьшить размер файла хранилища и повысить эффективность запросов.
Когда Kafka передает данные, сжатие данных может быть включено на стороне производителя и потребителя. После того, как сторона производителя сжимает данные, сторона потребителя автоматически распаковывает сообщение при его получении, что может эффективно сократить дисковое пространство и потребление полосы пропускания во время передачи по сети, тем самым снижая затраты и повышая эффективность передачи. Обратите внимание, что производитель и потребитель указывают один и тот же алгоритм сжатия.
На волне снижения затрат и повышения эффективности одним из способов снижения стоимости Redis является сжатие данных, хранящихся в Redis, для снижения затрат на хранение. Микросервис реконструированного контента использует мгновенное сжатие для постоянного хранения всего объема данных. это всего лишь 40%-50% исходных данных, есть и другие; Первый способ — изменить вызовы между службами с протокола http json на протокол pb trpc. Поскольку данные, закодированные протоколом pb, меньше, это повышает эффективность передачи. При оптимизации службы преобразуйте исходный протокол запроса табуляции из json в pb. . , сокращая задержку на несколько миллисекунд. Кроме того, данные хранятся в микросервисе контента. Используя кодирование flutbuffer, он имеет более высокую степень сжатия и более высокую скорость кодирования и декодирования, чем protobuffer, он также может запутывать, сжимать и передавать несколько файлов JS/CSS, он также может вручную вызывать данные, хранящиеся в es api, объединяет сегменты для уменьшения объема памяти; Объем хранимых данных увеличивает скорость запросов; еще одна распространенная проблема в нашей работе заключается в том, что интерфейс возвращает много избыточных данных, которые предоставляются службой интерфейса, а не настроены для текущего сценария. соблюдать принцип минимизации интерфейса, тратя много ресурсов полосы пропускания и снижая эффективность передачи.
Разблокировано
Redis позволяет избежать конкуренции блокировок в одном потоке и частого переключения между потоками для достижения такой высокой производительности чтения и записи.
Атомарный пакет предоставляется на языке go, который в основном используется для синхронизации данных между различными потоками без блокировки. По сути, он инкапсулирует инструкции атомарных операций, предоставляемые базовым процессором. Кроме того, исходной моделью планирования языка Go была модель GM. Все потоки уровня ядра, которые хотят выполнить горутину, должны получать блокировки из глобальной очереди, поэтому конкуренция между различными потоками является жесткой, а эффективность планирования очень низкой.
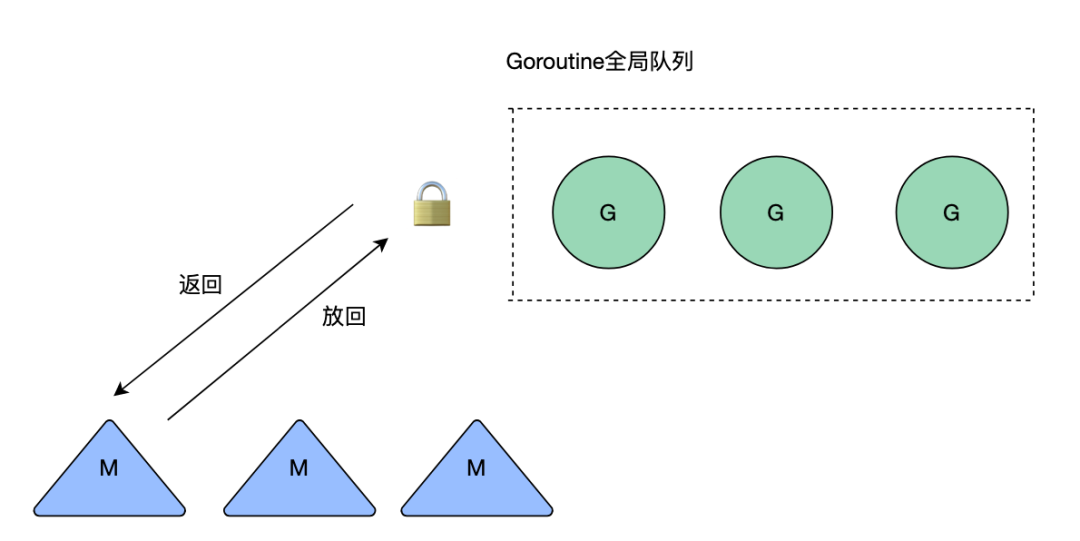
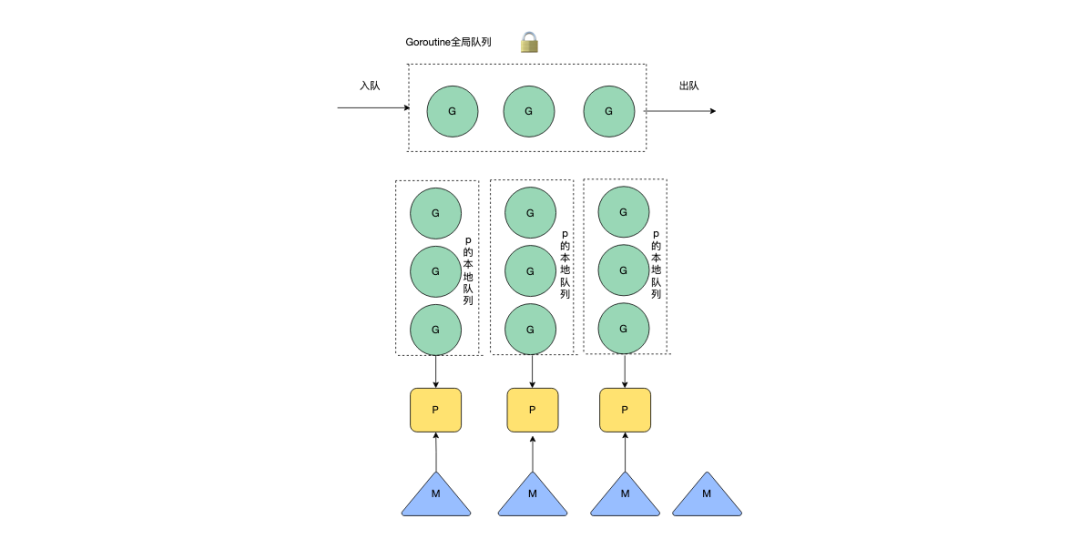
Впоследствии был введен P (процессор). Когда каждый M (поток) хочет выполнить G (горонтину), его необходимо связать с P. Для выполнения G в P будет существовать локальная очередь, которую можно только читать и записывать. текущим M (в редких случаях G может быть украден из других сопрограмм). Нет необходимости блокировать чтение локальной очереди P. Это значительно повышает эффективность планирования G за счет уменьшения конкуренции блокировок.
mysql использует mvcc для обеспечения согласованности и изоляции данных при одновременном чтении и записи нескольких транзакций.,Это также одно из разблокированных конструктивных решений для решения проблемы одновременного чтения и записи. В основном это реализуется путем поддержания нескольких цепочек версий для записей изменений каждой строки данных.,Чтение снимка реализовано путем сокрытия столбцовrollptr и undolog. Когда транзакция работает с данными строки,Какая версия данных будет считываться в зависимости от текущего идентификатора транзакции и уровня изоляции транзакции.,Для повторяемого чтения просмотр чтения создается в начале транзакции.,Это представление чтения используется во всех последующих транзакциях. В дополнение к использованию mvcc, чтобы избежать блокировок мьютексов в MySQL,Bufferpool также может установить несколько,Уменьшите степень детализации блокировок за счет нескольких буферных пулов.,Улучшение производительности чтения и записи,Это также решение для оптимизации.
В повседневной работеatomic.value можно использовать для хранения данных в сценариях, где требуется больше операций чтения и меньше записи, что снижает конкуренцию блокировок и повышает производительность системы. Например, данные в службе конфигурации хранятся с использованиемatomic.value; Чтобы повысить производительность чтения, syncmap отдает приоритет использованию атомарной операции чтения, а затем выполняет операцию блокировки мьютекса для выполнения грязных операций. Syncmap также можно использовать, когда происходит больше чтения и меньше записи.
Суть системы флэш-продаж заключается в точном увеличении или уменьшении запасов продуктов при высокой степени параллелизма без перепродажи или недопродажи. Поэтому всем пользователям необходимо использовать блокировку мьютекса, чтобы изменить количество запасов при получении продукта. Существование мьютекса неизбежно станет узким местом системы, но система продажи флэш-памяти представляет собой высокопараллельный сценарий, поэтому оптимизация блокировки мьютекса является важным методом оптимизации для повышения производительности системы флэш-продажи.
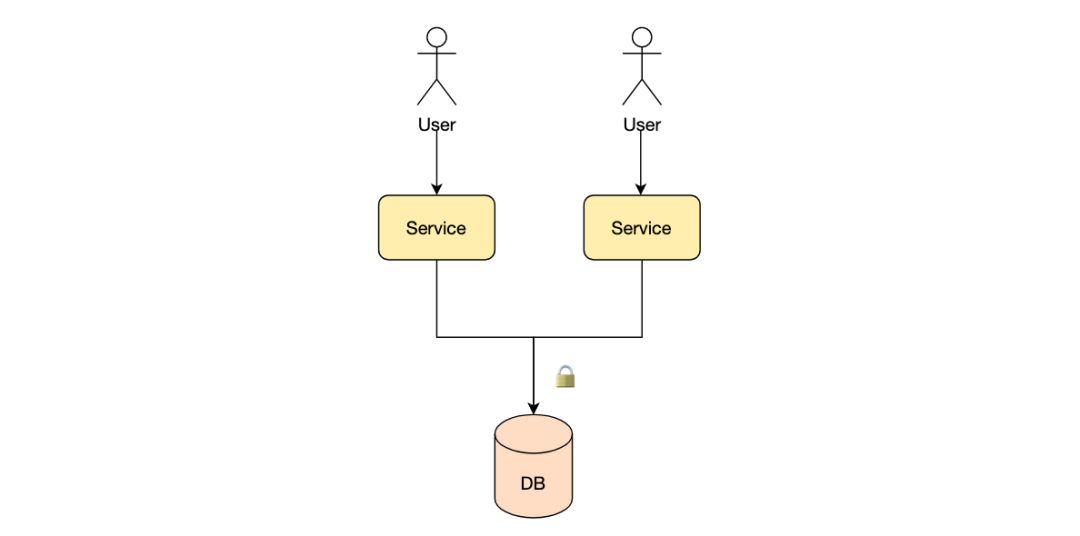
Одним из дизайнерских решений «Разблокировано» является использование очередей сообщений.,Для операции флэш-продажи в системе флэш-продаж: Асинхронная обработка.,Публикация сообщения в очереди сообщений для операции мгновенной продажи.,Таким образом, поведение всех пользователей при мгновенной продаже формирует очередь «первым пришел — первым ушел».,Успешно приобретать товары могут только пользователи, ранее добавленные в очередь сообщений. Поток, который использует сообщения из очереди для внесения изменений в инвентарь, представляет собой один поток.,Поэтому конфликта в работе БД не будет.,Никакой операции блокировки не требуется.
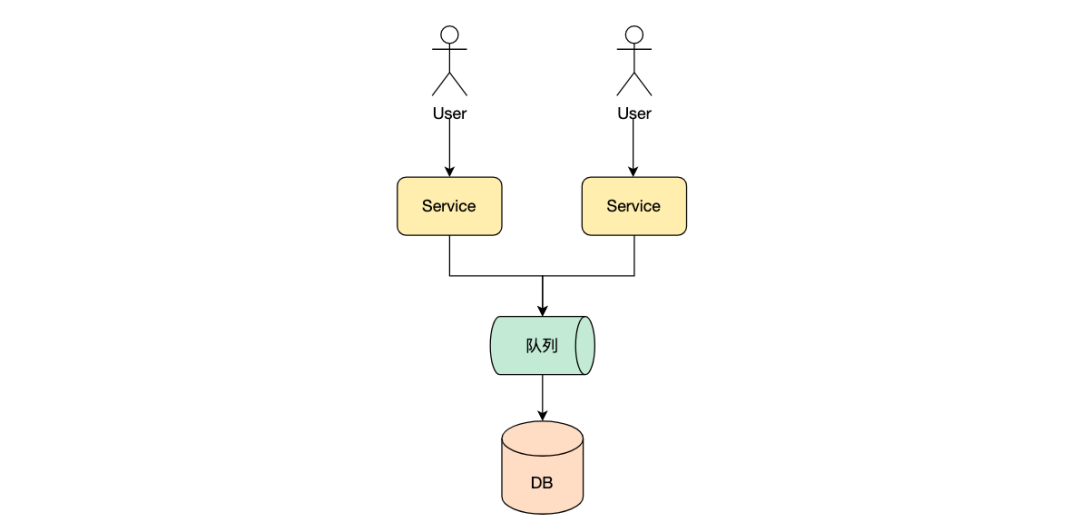
Другой метод оптимизации может относиться к модели GMP Голанга.,Разделите инвентарь на несколько частей,Загружается отдельно на локальный сервер Служитьсервера.,Таким образом, при изменении запасов можно избежать конкуренции замков между несколькими машинами. Если локальный сервер представляет собой один процесс,Следовательно, своего рода Разблокированная Архитектура также может быть сформирована, если она многопроцессная;,Перед внесением изменений необходимо заблокировать локальный инвентарь.,Но распределите инвентарь локально на сервере,Уменьшена детализация блокировки.,Улучшить общую производительность.
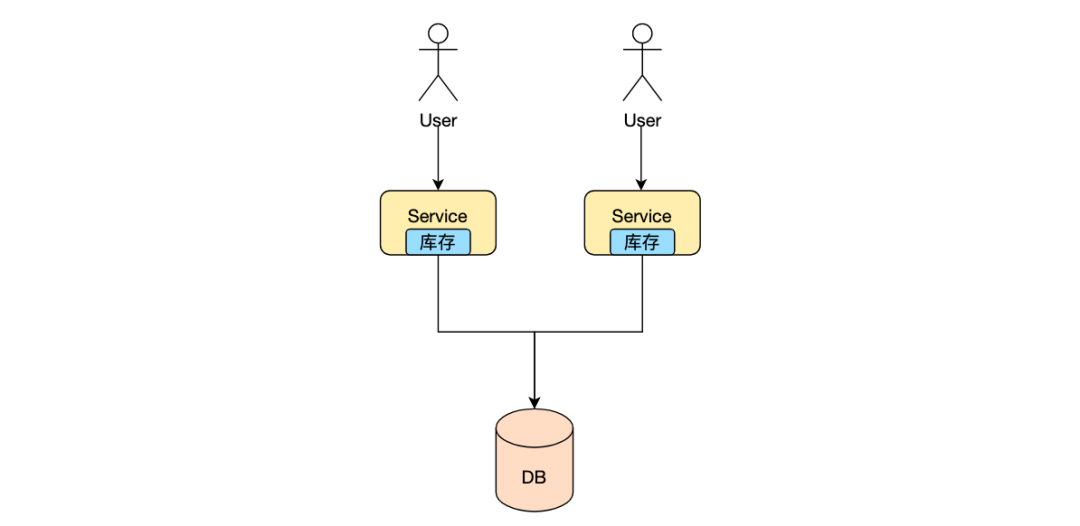
Пишите последовательно
Механизм хранения MySQL InnoDB обычно рекомендует использовать первичные ключи с автоматическим приращением вместо uuid при создании первичных ключей. Основная причина заключается в том, что нижний уровень InnoDB использует деревья B+ для хранения данных. Каждый листовой узел представляет собой страницу данных, которая хранит несколько элементов. запись данных, данные на странице хранятся упорядоченным образом через связанный список, а страницы данных хранятся через двусторонний связанный список. Поскольку uuid неупорядочен, его можно вставить в середину страницы данных, на которой уже недостаточно места, в результате чего страница данных будет разделена на две новые страницы данных для вставки новых данных, что повлияет на общую производительность записи.
Кроме того, процесс записи в mysql не записывает каждый раз измененные данные непосредственно на диск, а модифицирует буфер в памяти. Страница данных, хранящаяся в пуле, записывает изменения страницы данных в журналы отмены и binlog, чтобы гарантировать, что изменения данных не будут потеряны. Каждый раз, когда журнал записывается, он добавляется в конец файла журнала. последовательно на диск. При внесении изменений в данные передать Пишите последовательно log, позволяет избежать случайной записи страниц данных диска и повышает производительность записи. Это преобразует случайные записи в Пишите. Идеи постоянно отражаются во многих промежуточных программах.
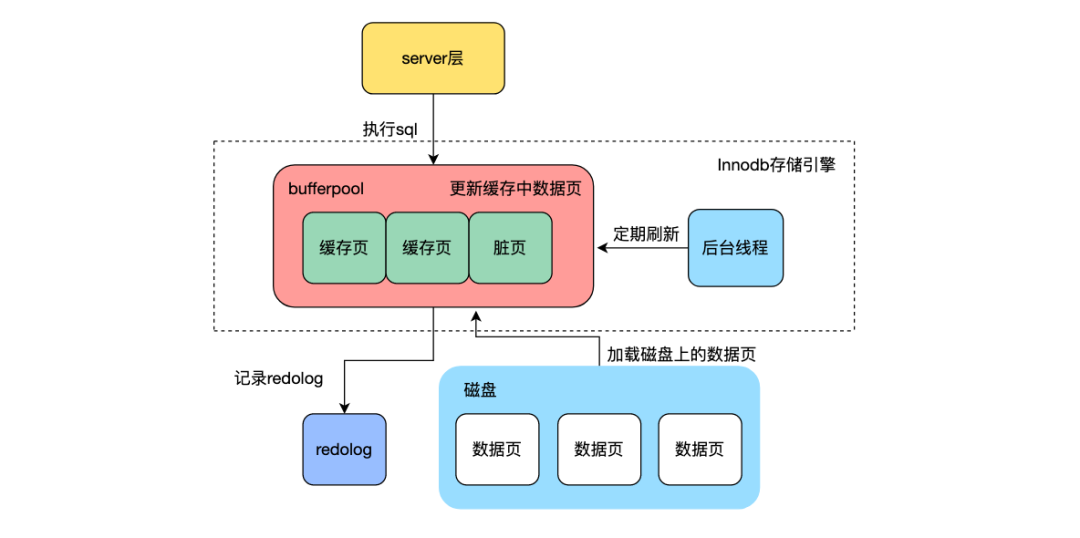
Каждый раздел в Kafka представляет собой упорядоченную неизменяемую очередь сообщений.,Новые сообщения будут постоянно добавляться в конец раздела.,Каждый раздел состоит из нескольких сегментов,Один сегмент соответствует одному физическому файлу журнала.,Написание файлов журналов сегментов в Kafka также выполняется постоянно. Преимущество Пишите постоянно заключается в том, что он позволяет избежать постоянного времени поиска и вращения диска.,Значительно улучшить производительность записи.
Пишите Постоянно в основном используется в сценариях, где выполняется большое количество дисковых операций ввода-вывода, Выберите первичный ключ с автоинкрементом при создании таблицы MySQL в ежедневной работе.,Или последовательно считывать и записывать данные при синхронизации библиотеки данных.,Избегайте разделения страниц данных в базовом механизме хранения страниц.,Это также в определенной степени улучшит производительность письма.
Шардинг
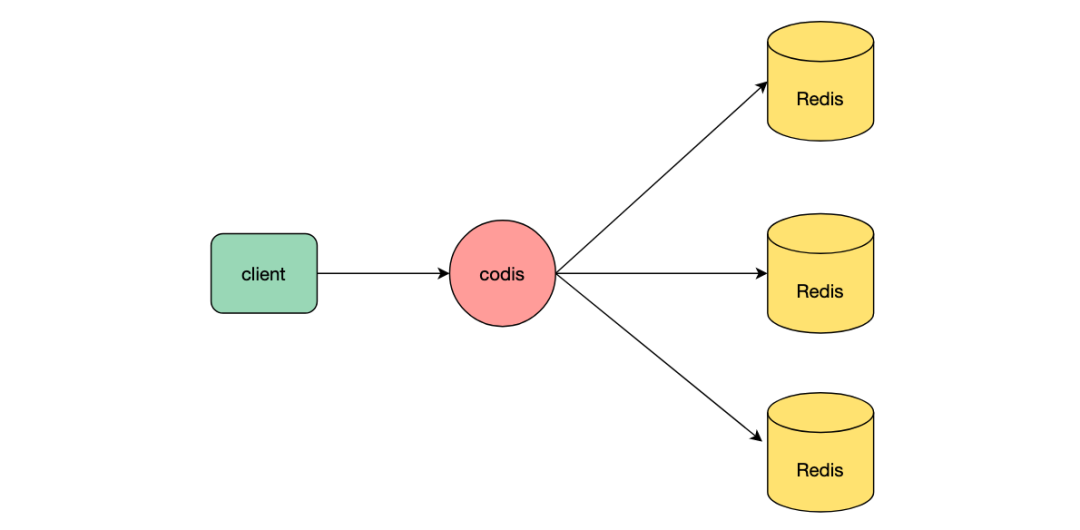
Redis имеет однопоточный процесс выполнения команд. Одна машина имеет хорошую производительность чтения и записи. Однако емкость машины и количество подключений одной машины в конечном итоге ограничены. Поэтому Redis неизбежно будет иметь возможность чтения. и напишите верхний предел и верхний предел хранилища. Появление кластера Redis призвано решить проблему узкого места в производительности чтения и записи Redis с одним компьютером. Кластер Redis автоматически фрагментирует данные на несколько узлов. Каждый узел отвечает за часть данных. World, преодолевая ограничения Redis для хранения данных на одной машине, а также верхние ограничения на чтение и запись, улучшают возможности высокого параллелизма всей службы. В дополнение к официально запущенному режиму кластера, режим прокси-сервера codis также распределяет данные по разным узлам. codis формирует кластер из нескольких полностью независимых узлов Redis и перенаправляет запросы на определенный узел через codis для увеличения емкости хранилища службы и производительности чтения и записи. .
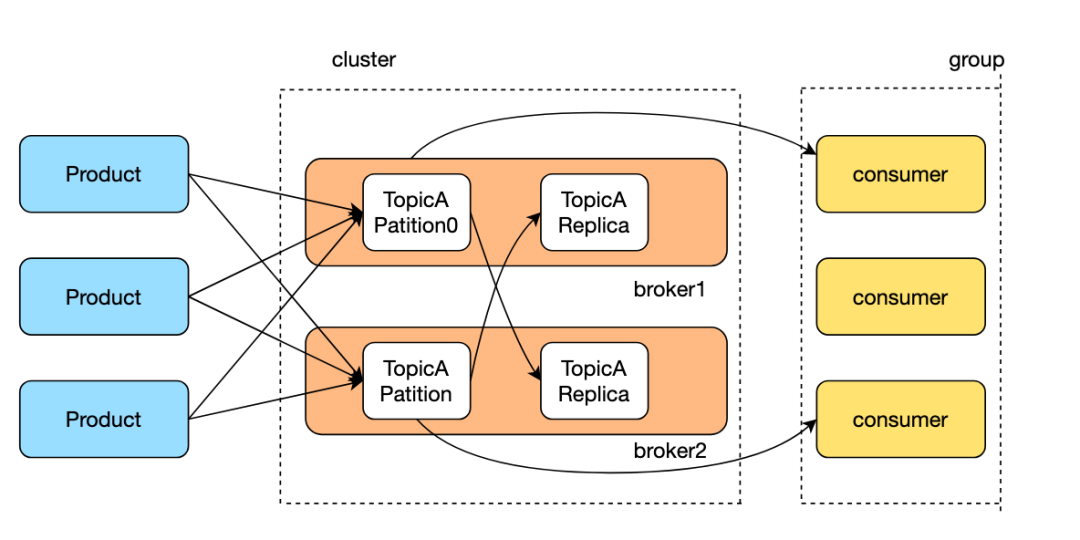
Точно так же каждая тема в Kafka также поддерживает несколько разделов, которые распределяются по нескольким брокерам, что снижает нагрузку на чтение и запись на одном компьютере. Увеличивая количество разделов, потребители могут получать сообщения параллельно, улучшая горизонтальность Kafka. масштабируемость и пропускная способность.
В новостях каждый день будет появляться большое количество фотографий, текстов и видео.,Нижний слой хранится через tdsql,Идеи хранения Шардинга можно взять на вооружение отдельно.,Храните изображения, тексты, видео или другие медиафайлы в разных библиотеках данных или таблицах данных.,Ежедневный объем производства одного и того же носителя также будет очень большим.,В это время один и тот же носитель можно разделить на несколько таблиц данных.,Дальнейшее улучшение емкости хранилища и пропускной способности библиотеки данных. Еще один способ оптимизировать хранение — разделить горячее и холодное хранилище.,Новейшие данные используют высокопроизводительное машинное хранилище.,Раньше количество посещений старых данных было низким.,Использование машинного хранилища с низкой производительностью,Экономьте расходы.
В процессе микро-Служить реконструкция,данные необходимые для синхронизации,Синхронизировать все данные, хранящиеся в общей базе данных, с новым хранилищем контента микро Служить через Kafka,Ожидаемое количество запросов в секунду при синхронизации — до 15 000. Поскольку каждый раздел Kafka может быть использован только одним потребителем.,Для достижения ожидаемого количества запросов в секунду,Следовательно, для достижения этой цели необходимо создать более 750 разделов.,Однако слишком большое количество разделов в Kafka приведет к очень медленной перебалансировке.,Влияет на производительность,Стоимость и ремонтопригодность не высоки. Перенять идею Шардинга,Вы можете поместить данные в тот же раздел,Шардинг памяти по нескольким каналам через потребителя,Используются независимые сопрограммы, соответствующие разным каналам.,Несколько сопрограмм обрабатывают сообщения одновременно для повышения скорости обработки.,После успешного потребления напишите в соответствующий канал успеха.,Единый поток offsetMaker использует сообщение об успешном отправке смещения.,Обеспечить надежность потребления сообщений.
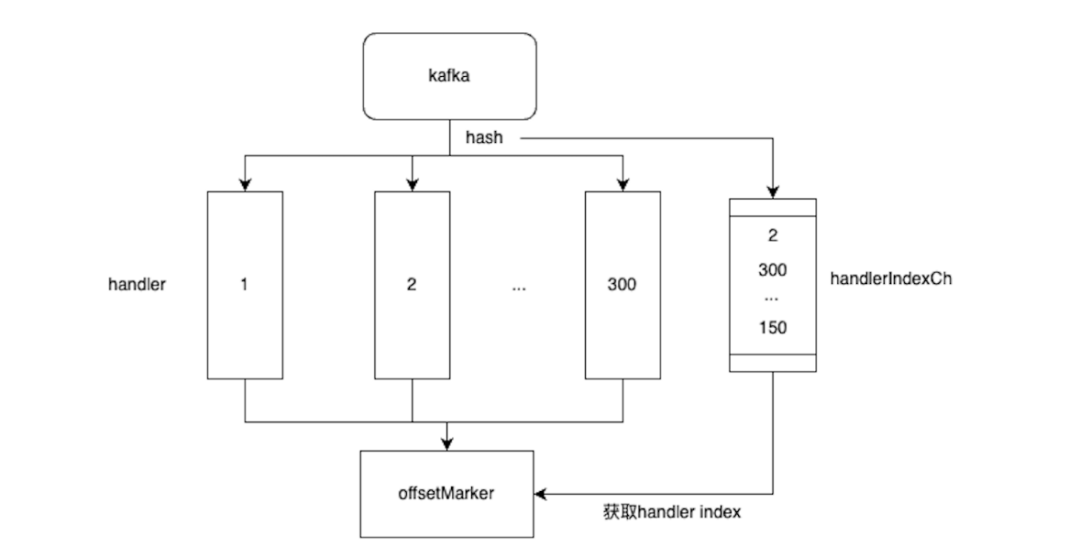
избегать запроса
Чтобы улучшить производительность записи, когда MySQL записывает данные для страниц данных в пуле буферов, он напрямую изменяет страницы данных пула буферов и записывает повтор для страниц данных, которых нет в памяти, он не загружает данные немедленно; страницы на диске в буферный пул, но записывает только изменения в буфере. , данные будут объединены при последующем чтении страниц данных на диске в пул буферов. Следует отметить, что этот метод используется только для неуникальных индексов. При записи уникальных индексов данные на диске необходимо объединить. каждый раз. Только прочитав пул буферов, мы можем определить, существуют ли данные. Для уже существующих данных будет возвращена ошибка вставки.
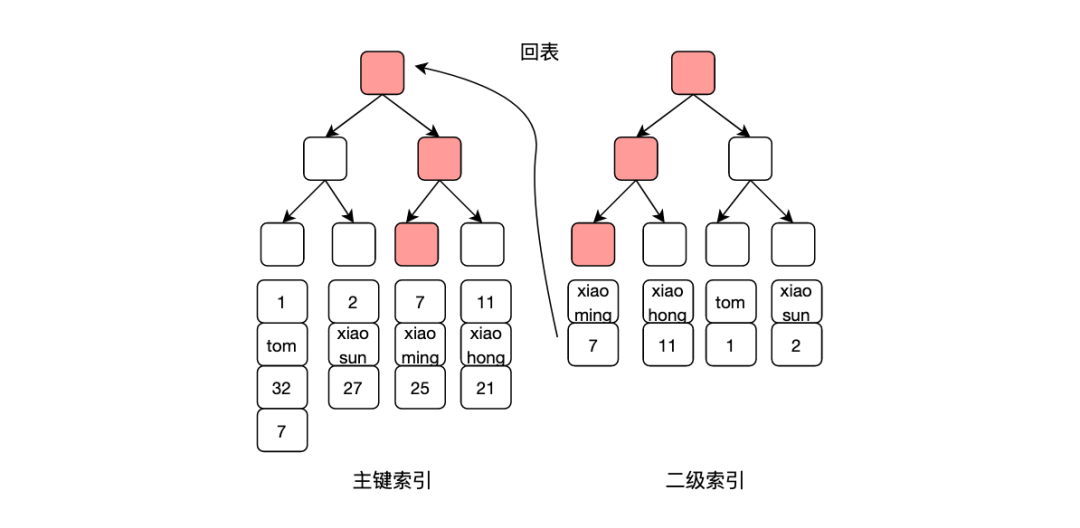
Кроме того, запросы MySQL, такие как select * from table, где name = 'xiaoming', если поле имени имеет вторичный индекс, поскольку этот запрос равен *, это означает, что все поля в строке являются обязательными, и операция возврата таблицы Если требуются только поля идентификатора и имени, вы можете изменить оператор запроса, чтобы выбрать идентификатор и имя из таблицы, где имя = «xiaoming», чтобы вы могли найти необходимые данные только по вторичному индексу имени, избегая таблицы. возвращать операции и сокращать один ввод-вывод, улучшать скорость запросов.
Вы можете использовать кэш, объединять файлы css и js и т. д. в веб-приложениях.,Избегайте или сокращайте http-запросы,Улучшите скорость загрузки страниц и удобство работы с пользователем.
В повседневных мобильных приложениях для разработки можно использовать отложенную загрузку для данных с несколькими вкладками. Запрос будет инициирован только после того, как пользователь перейдет на новую вкладку, что позволит избежать множества бесполезных запросов. При итерации серверной разработки некоторые функциональные поля больше не отображаются на сервере, но сервер по-прежнему будет возвращать поля данных. Эти ненужные поля данных можно получить из источника данных и обработать в автономном режиме, чтобы избежать бесполезных запросов. Кроме того, законность параметров запроса может быть точно проверена при получении данных. Например, при запросе информации о голосовании идентификатор голосования конфигурации операции может быть недопустимым параметром, таким как «» или «0», если параметры запроса. не проверены. Если они проверены, может быть много бесполезных запросов ввода-вывода. Кроме того, все экспериментальные параметры пользователя обычно запрашиваются при входе в функцию. Экспериментальные параметры используются только во время эксперимента. После того, как эксперимент отключен, запрос на отключение экспериментальной платформы ab не может быть выполнен. в автономном режиме в неэкспериментальные периоды, улучшите скорость отклика интерфейса.
Объединение
Golang — современный родной язык, поддерживающий высокий уровень параллелизма.,Технология «Объединение» имеет большое применение в модели GMP. Что касается уничтожения горутины, она не уничтожается непосредственно после использования.,Вместо этого он помещается в локальную очередь ожидания P.,Когда G потребуется создать в следующий раз, G будет напрямую взят из очереди ожидания для повторного использования, аналогично создание и уничтожение M сначала будет получено или освобождено из глобальной очереди; Кроме того, sync.pool в golang можно использовать для сохранения повторно используемых объектов.,Избегайте потребления, вызванного повторным созданием и уничтожением объектов, и уменьшите давление gc.
Базы данных, такие как mysql, также предоставляют пулы соединений, которые могут заранее создавать определенное количество соединений для обработки запросов к базе данных. При поступлении запроса вы можете выбрать простаивающее соединение из пула соединений для его обработки. После завершения запроса соединение возвращается в пул соединений, чтобы избежать накладных расходов, вызванных созданием и уничтожением соединения, а также повысить производительность базы данных.
В повседневной работе вы можете создать пул потоков для обработки запросов. При поступлении запроса выберите простаивающий поток из пула соединений для его обработки. После завершения обработки верните его в пул потоков, чтобы избежать потребления, вызванного. создание потоков в Интернете. Это очень распространено в сценариях, требующих высокой степени параллелизма, например в платформах.
Асинхронная обработка
Асинхронная обработка также широко используется в библиотеке данных.,Например, bgsave Redis,bgrewriteof — это команда, используемая для асинхронного сохранения файлов RDB и AOF соответственно.,bgsave вернет успех сразу после выполнения,Основной поток разветвляет поток для сохранения сгенерированного в памяти снимка на диск.,Основной поток продолжает выполнять команды клиента; redis удаляет ключи двумя способами: del и unlink.,Для команды del он удаляется синхронно,Освободите память напрямую,При встрече с большим ключом,Операция удаления приведет к зависанию Redis.,А unlink — это способ асинхронного удаления,После выполнения для ключа делается только отметка о недостижимости.,Перезагрузка памяти осуществляется асинхронными потоками.,Не блокирует основной поток.
Синхронизация master-slave MySQL поддерживает асинхронную репликацию, синхронную репликацию и полусинхронную репликацию. Асинхронная репликация означает, что главная база данных возвращает результаты клиенту сразу после выполнения отправленной транзакции и не заботится о том, синхронизировала ли подчиненная база данных данные. Синхронная репликация означает, что главная база данных выполняет отправленную транзакцию, и все подчиненные базы данных выполнили ее; Транзакция вернет результат клиенту; полусинхронная репликация означает, что после завершения выполнения главной базы данных по крайней мере одна подчиненная база данных получила и выполнила транзакцию, прежде чем вернуть ее клиенту. Существует множество методов, главным образом потому, что клиент асинхронной репликации имеет высокую производительность записи, но существует риск потери данных. Его можно использовать в сценариях, где требования к согласованности данных не высоки. Синхронный метод имеет низкую производительность записи и подходит для таких случаев. сценарии, в которых требования к согласованности данных высоки. Кроме того, производители и потребители Kafka могут использовать асинхронные методы для отправки и использования сообщений, но использование асинхронных методов может привести к проблемам с потерей сообщений. Для асинхронной отправки сообщения можно использовать метод с функцией обратного вызова. В случае сбоя отправки функция обратного вызова будет использоваться для обнаружения сбоя, и будет выполнена последующая компенсация сообщения.
существовать Делать Служить Оптимизация Что касается производительности, я обнаружил, что некоторые предыдущие отчеты о мониторинге, отчеты о воздействии и другие операции находятся в основном процессе. Эту часть функции можно использовать как Асинхронную. обработка, уменьшите задержку интерфейса. Кроме того, после того, как пользователи опубликуют новость, они напишут новость на индекс личной страницы, обработают картинки, просмотрят заголовки или добавят баллы активности пользователям и т. д., вы можете использовать Асинхронную обработка,Здесь Асинхронная обработка — это действие по отправке сообщения для отправки сообщения в очередь сообщений.,Различные сценарии используют сообщения в очереди сообщений и выполняют соответствующую логическую обработку.,Такая конструкция обеспечивает производительность записи,Это также отделяет бизнес-логику различных сценариев.,Улучшите ремонтопригодность системы.
Подвести итог
Основное содержание этой статьи итогруководить Служить Оптимизация Есть несколько способов использования производительности, каждый из которых отражен в нашем часто используемом промежуточном программном обеспечении. Я думаю, что в этом также смысл узнать больше об этом промежуточном программном обеспечении. Изучение их заключается не только в том, чтобы научиться его использовать. Используя их, вы также сможете изучить лежащие в их основе отличные дизайнерские идеи, понять, почему они спроектированы таким образом и каковы преимущества такого дизайна. Позже мы подберем модели в Архитектуре или сделаем Служить Оптимизацию. производительность будет иметь некоторую помощь. Также Оптимизация Метод производительности также обеспечивает конкретные методы реализации.
Мы надеемся улучшить наше понимание этого метода оптимизации с помощью примеров практического применения. Кроме того, чтобы оптимизировать производительность службы, вам все равно придется начинать с собственной архитектуры службы, анализировать трудоемкое распределение и загрузку ЦП цепочки вызовов службы, а также оптимизировать проблемные вызовы и функции RPC.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
