Design2Code: Насколько далека фронтенд от безработицы?
недавно,Я прочитал много статей о восстановлении интерфейса ИИ.,До этого я написал сенсационную статью, в которой заставил копировать чужой сайт всего с одним URL-адресом.,Введено в соответствии с принципами внутри,Те, кто это прочитал, тоже должны знать,Недостатки этого подхода。То есть, хотя копировать чужие сайты легко, код, написанный ИИ, очень не ремонтопригоден. , даже самый простой список не записывается в виде list.map(it⇒item), а записывается один за другим в жесткой манере.
Произошел ли новый поворотный момент в автоматизированном интерфейсном проектировании?
Сегодня я увидел проект с открытым исходным кодом на GitHub, Design2Code: https://github.com/NoviScl/Design2Code.
Итак, реализован ли автоматизированный фронтенд-проект таким образом Ноев ковчег (могила) для наших партнёров по фронтенд-разработке? Давайте вместе приоткроем его загадочную завесу.
Этот проект с открытым исходным кодом связан с этой статьей https://arxiv.org/pdf/2403.03163.pdf, которая является частью этой статьи, посвященной практике написания кода, поэтому мы обычно можем прочитать статью непосредственно, чтобы понять ее принципы. С результатами он может ознакомиться напрямую. добился, раз он осмелился опубликовать тестовый код, значит, данные в этой статье более достоверны.
Авторами этой статьи являются четыре больших парня, а именно:

Основная цель их исследования — автоматическая генерация кода HTML/CSS, который может отображать веб-страницу на основе снимков экрана веб-дизайна. Их основная работа и вклад заключаются в следующем:
- Задача Design2Code была формально определена, и в качестве эталона оценки был создан тестовый набор, содержащий 484 реальных веб-страницы. В статье подробно описан процесс построения набора данных.
- Был разработан набор индикаторов автоматической оценки, включая визуальное сходство высокого уровня (сходство CLIP) и детальное сопоставление элементов (например, совпадение текста, совпадение макета и т. д.).
- Методы мультимодального улучшения подсказок, такие как подсказки для улучшения текста и саморедактируемые подсказки, предлагаются для повышения производительности коммерческих больших моделей (GPT-4V, Gemini) при выполнении этой задачи.
- На основе открытой модели CogAgent-18B была проведена специальная доводка для получения модели Design2Code-18B, производительность которой сравнима с коммерческой моделью Gemini.
- Путем ручной оценки и автоматических индикаторов выяснилось, что GPT-4V лучше всего справляется с этой задачей. Ручная оценка показывает, что 49% веб-страниц, созданных с помощью GPT-4V, достаточно для замены исходных справочных веб-страниц, а дизайн 64% веб-страниц оценивается как лучше, чем исходный справочный материал.
- Детальный анализ показывает, что модель с открытым исходным кодом все еще нуждается в улучшении для вызова визуальных элементов входной веб-страницы и создания правильного дизайна макета, в то время как такие аспекты, как текстовое содержимое и цвет, можно значительно улучшить за счет тонкой настройки.
Далее давайте посмотрим на некоторые данные из его статьи.
Тестирование производительности: автоматические показатели
Для автоматической оценки они рассматривали визуальное сходство высокого уровня (CLIP) и соответствие элементов низкого уровня (сопоставление блоков, текст, положение, цвет). Все базовые модели сравнивались по этим различным параметрам.
Видно, что GPT-4V еще далеко впереди, но обученная ими модель немного сильнее Gemini Pro.
Базовая производительность:Human Оценка (ручная оценка)
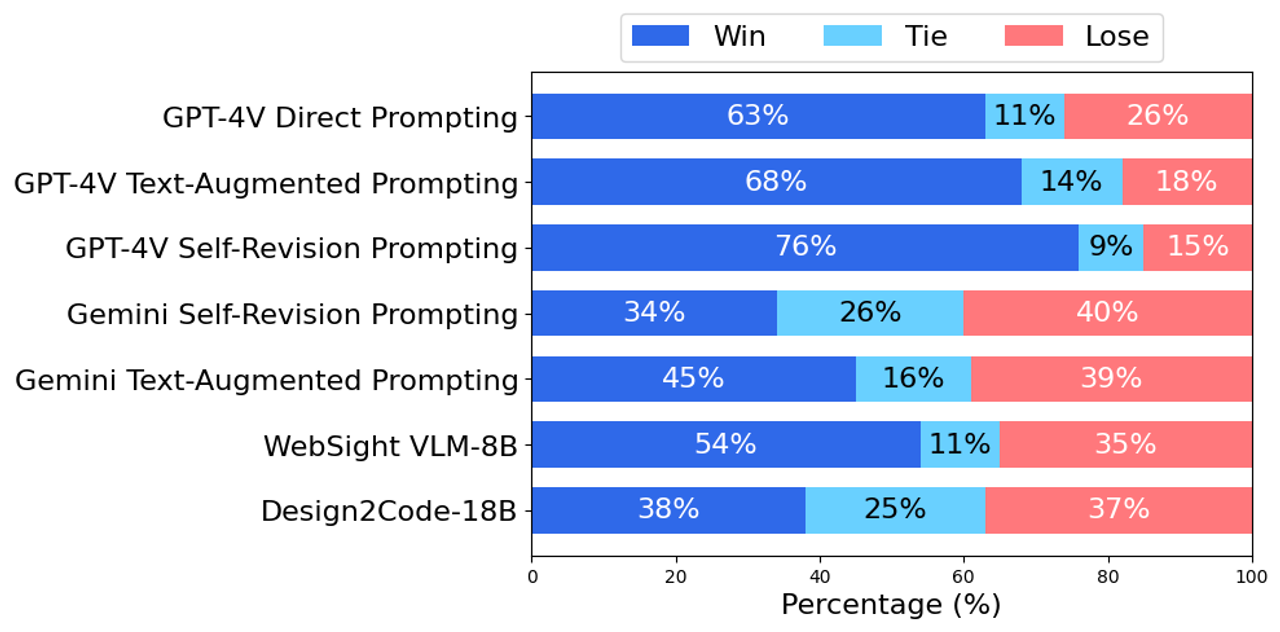
Итак, каковы код реализации этих методов? На самом деле, мы в порядке, понимая приглашение.
https://github.com/NoviScl/Design2Code/blob/main/Design2Code/prompting/gpt4v.py
Прямые подсказки
def direct_prompting(openai_client, image_file):
'''
{original input image + prompt} -> {output html}
'''
## the prompt
direct_prompt = ""
direct_prompt += "You are an expert web developer who specializes in HTML and CSS.\\n"
direct_prompt += "A user will provide you with a screenshot of a webpage.\\n"
direct_prompt += "You need to return a single html file that uses HTML and CSS to reproduce the given website.\\n"
direct_prompt += "Include all CSS code in the HTML file itself.\\n"
direct_prompt += "If it involves any images, use \\"rick.jpg\\" as the placeholder.\\n"
direct_prompt += "Some images on the webpage are replaced with a blue rectangle as the placeholder, use \\"rick.jpg\\" for those as well.\\n"
direct_prompt += "Do not hallucinate any dependencies to external files. You do not need to include JavaScript scripts for dynamic interactions.\\n"
direct_prompt += "Pay attention to things like size, text, position, and color of all the elements, as well as the overall layout.\\n"
direct_prompt += "Respond with the content of the HTML+CSS file:\\n"
## encode image
base64_image = encode_image(image_file)
## call GPT-4V
html, prompt_tokens, completion_tokens, cost = gpt4v_call(openai_client, base64_image, direct_prompt)
return html, prompt_tokens, completion_tokens, costТекстовые расширенные подсказки
def text_augmented_prompting(openai_client, image_file):
'''
{original input image + extracted text + prompt} -> {output html}
'''
## extract all texts from the webpage
with open(image_file.replace(".png", ".html"), "r") as f:
html_content = f.read()
texts = "\\n".join(extract_text_from_html(html_content))
## the prompt
text_augmented_prompt = ""
text_augmented_prompt += "You are an expert web developer who specializes in HTML and CSS.\\n"
text_augmented_prompt += "A user will provide you with a screenshot of a webpage, along with all texts that they want to put on the webpage.\\n"
text_augmented_prompt += "The text elements are:\\n" + texts + "\\n"
text_augmented_prompt += "You should generate the correct layout structure for the webpage, and put the texts in the correct places so that the resultant webpage will look the same as the given one.\\n"
text_augmented_prompt += "You need to return a single html file that uses HTML and CSS to reproduce the given website.\\n"
text_augmented_prompt += "Include all CSS code in the HTML file itself.\\n"
text_augmented_prompt += "If it involves any images, use \\"rick.jpg\\" as the placeholder.\\n"
text_augmented_prompt += "Some images on the webpage are replaced with a blue rectangle as the placeholder, use \\"rick.jpg\\" for those as well.\\n"
text_augmented_prompt += "Do not hallucinate any dependencies to external files. You do not need to include JavaScript scripts for dynamic interactions.\\n"
text_augmented_prompt += "Pay attention to things like size, text, position, and color of all the elements, as well as the overall layout.\\n"
text_augmented_prompt += "Respond with the content of the HTML+CSS file (directly start with the code, do not add any additional explanation):\\n"
## encode image
base64_image = encode_image(image_file)
## call GPT-4V
html, prompt_tokens, completion_tokens, cost = gpt4v_call(openai_client, base64_image, text_augmented_prompt)
return html, prompt_tokens, completion_tokens, costВизуальная подсказка о пересмотре
def visual_revision_prompting(openai_client, input_image_file, original_output_image):
'''
{input image + initial output image + initial output html + oracle extracted text} -> {revised output html}
'''
## load the original output
with open(original_output_image.replace(".png", ".html"), "r") as f:
original_output_html = f.read()
## encode the image
input_image = encode_image(input_image_file)
original_output_image = encode_image(original_output_image)
## extract all texts from the webpage
with open(input_image_file.replace(".png", ".html"), "r") as f:
html_content = f.read()
texts = "\\n".join(extract_text_from_html(html_content))
prompt = ""
prompt += "You are an expert web developer who specializes in HTML and CSS.\\n"
prompt += "I have an HTML file for implementing a webpage but it has some missing or wrong elements that are different from the original webpage. The current implementation I have is:\\n" + original_output_html + "\\n\\n"
prompt += "I will provide the reference webpage that I want to build as well as the rendered webpage of the current implementation.\\n"
prompt += "I also provide you all the texts that I want to include in the webpage here:\\n"
prompt += "\\n".join(texts) + "\\n\\n"
prompt += "Please compare the two webpages and refer to the provided text elements to be included, and revise the original HTML implementation to make it look exactly like the reference webpage. Make sure the code is syntactically correct and can render into a well-formed webpage. You can use \\"rick.jpg\\" as the placeholder image file.\\n"
prompt += "Pay attention to things like size, text, position, and color of all the elements, as well as the overall layout.\\n"
prompt += "Respond directly with the content of the new revised and improved HTML file without any extra explanations:\\n"
html, prompt_tokens, completion_tokens, cost = gpt4v_revision_call(openai_client, input_image, original_output_image, prompt)
return html, prompt_tokens, completion_tokens, costИтак, каковы характеристики каждого из этих методов?
- Прямые подсказки:
- Этот метод напрямую использует снимок экрана веб-страницы, предоставленный пользователем, в качестве входных данных, а затем генерирует код HTML+CSS на основе снимка экрана.
- Преимущество в том, что операция проста, и пользователю нужно только предоставить снимок экрана.
- Недостаток заключается в том, что, поскольку он полагается только на информацию об изображении, он может быть недостаточно точным при извлечении текста и распознавании элементов, особенно если качество скриншота невысокое или элементы содержат много деталей.
- Текстовые расширенные подсказки:
- Этот метод добавляет всю текстовую информацию, извлеченную с веб-страницы, в метод прямого запроса.
- Пользователь предоставляет снимок экрана веб-страницы и весь соответствующий текстовый контент, а система на основе этой информации генерирует код HTML+CSS.
- Преимущество состоит в том, что точность сгенерированного кода можно повысить за счет добавления текстовой информации, особенно при работе с текстовым содержимым и макетом.
- Недостатком является то, что для извлечения текста веб-страницы требуются дополнительные шаги.
- Визуальная подсказка о пересмотре:
- Этот метод используется для изменения существующих реализаций HTML. Он использует не только исходное входное изображение, но также исходное выходное изображение, а также HTML-код и текст, извлеченные из ссылочной веб-страницы.
- Пользователи предоставляют исходные снимки экрана веб-страницы, текущую реализацию HTML (которая может быть неправильной) и снимки экрана веб-страницы, созданные с помощью этой реализации HTML, и система будет пересматривать и улучшать их на основе этой информации.
- Преимущество состоит в том, что он может вносить целевые исправления в существующие реализации и особенно подходит для корректировки и улучшения деталей с целью повышения качества окончательной реализации.
- Недостатком является то, что требуется больше входной информации, включая исходный HTML-код и визуализированные снимки экрана, а также высокая сложность операции.
Судя по результатам, метод подсказки саморедактирования GPT-4V будет лучше: эффект следующий:

с картинки,мы можем видеть,На уровне реставрации,Абсолютно невозможно сказать 100%,Даже 80% могут быть немного неохотными.,Это для визуальных дизайнеров с пиксельными глазами.,Это абсолютно неприемлемо. поэтому,Получите этот код автоматического преобразования AI,Внесение корректировок все еще может потребовать много энергии.,кто может гарантировать,Это лучше, чем писать от руки,Тогда эффективнее сотрудничать со вторым пилотом «парным программированием (ха-ха)».?Я думаю, что опытные разработчики интерфейса,Мне не терпится побороться с различными моделями, автоматически генерируемыми клиентским кодом.,Пусть судят дизайнеры с пиксельными глазами,Кто еще является королем в этой области?
Подвести итог
Хотя,в этой статье,Нам нужно подтвердить значение Design2Code.,Это может снизить порог фронтенд-разработки.,Но я не согласен, что это может заменить фронтенд-разработку в краткосрочной перспективе.,Бумага такжеБыла проанализирована детальная производительность каждой модели.,Укажите на недостатки модели с открытым исходным кодом.,Например, необходимо улучшить такие аспекты, как вызов элементов ввода и создание макетов.。Это также в основном определяет разработку интерфейса автоматизации.,Также признается, что автоматизации проектирования клиентской части еще предстоит пройти долгий путь.,Но к счастью,Видя направление шаг за шагом,нравиться,10 лет назад,Кто бы верил, что GPT так доминирует?



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
