DeepSeekMoE, первая крупномасштабная модель MoE с открытым исходным кодом в Китае | DeepSeekMoE: достижение максимальной экспертной специализации в экспертных смешанных языковых моделях |
Каталог статей
- 1. Предисловие
- 2. Основное содержание
- 3. Резюме
1. Предисловие
В эпоху больших языковых моделей смешанные экспертные модели (MoE) представляют собой многообещающую архитектуру для управления вычислительными затратами при масштабировании параметров модели. Однако традиционные архитектуры MoE (такие как GShard) активируют лучших экспертов среди N экспертов, но сталкиваются с проблемами в обеспечении специализации экспертов (т. е. знания, полученные каждым экспертом, не перекрываются и сфокусированы). В ответ исследователи предложили архитектуру DeepSeekMoE для достижения максимальной экспертной специализации. Он включает в себя две основные стратегии:
- Сегментируйте экспертов на
и активируйте его из
сделать активируемую экспертную комбинацию более гибкой;
- Воля
Разделение экспертов на общих экспертов направлено на сбор общих знаний и сокращение дублирования среди экспертов по маршрутизации.
от 2B Начиная со скромной шкалы параметров, исследователи продемонстрировали DeepSeekMoE 2B производительность, сравнимая с GShard 2.9B Для сравнения, экспертные параметры и сумма расчета последнего равны GShard 2.9B из 1,5 раза。также,Когда общее количество параметров одинаково,Производительность DeepSeekMoE 2B практически близка к плотному аналогу.,Это MoE Модель устанавливает верхний предел. Впоследствии исследователи будут DeepSeekMoE расширить до 16B параметры, результаты показывают, что его производительность сравнима с LLaMA2 7B Вполне, сумма расчета всего LLaMA2 7B из 40%. Кроме того, исследователи будут DeepSeekMoE изпараметррасширить до 145B из Первоначальные попытки постоянно проверяли его относительную GShard Архитектура имеет огромные преимущества и показывает, что производительность можно сравнить с DeepSeek 67B Сопоставимо, просто 28,5% (может даже 18.2%)изсумма расчета.
Многократная публикация. Модели, коды и документы были выпущены одновременно:
- Модельскачать:https://huggingface.co/deepseek-ai
- Тонкая настройка кода:https://github.com/deepseek-ai/DeepSeek-MoE
- технический отчет:https://github.com/deepseek-ai/DeepSeek-MoE/blob/main/DeepSeekMoE.pdf

2. Основное содержание
Какую проблему пытается решить эта статья?
Целью этой статьи является решение проблемы вычислительных затрат, с которой сталкивается модель большого языка (LLM) при расширении шкалы параметров. В частности, он предлагает метод под названием DeepSeekMoE из Новый тип Mixture-of-Experts (MoE) Архитектура, для высшей специализации экспертов из.
MoE Архитектура разбита на несколько экспертов Воля Модель,Каждый специалист специализируется на конкретной задаче,отисуществовать保持параметр规模изпри одновременном снижении вычислительных затрат。然и,Существующий MoE Архитектура сталкивается с проблемами в обеспечении экспертной специализации,То есть знания, полученные каждым экспертом, должны быть непересекающимися и целенаправленными. DeepSeekMoE две основные стратегии:
- Детальное разделение экспертов: разделение на более мелкие единицы экспертами Воли,Больше гибкости для активации экспертных портфелей,от И добиться более тонкой декомпозиции знаний и специализации.
- Изоляция общих экспертов. Некоторые эксперты назначаются общими экспертами.,Они всегда активны,Используется для сбора и интеграции общих знаний в различных контекстах.,от при этом уменьшая избыточность параметров в других экспертах маршрутизации.
В данном исследовании экспериментально подтверждено DeepSeekMoE В разных масштабах (2Б, 16Б и 145B параметры) по изпроизводительности. В то же время исследователь воляирует производительность и существующие MoE модель (например,GShard)и Плотныймодель (например, Dense×16) сравнивали. Результаты показывают, что DeepSeekMoE существующая поддерживает вычислительную эффективность и в то же время способна достигать уровня, близкого к существующей Моделиизпроизводительности или даже превосходящего ее.
Каковы соответствующие исследования?
Соответствующие исследования в основном сосредоточены на следующих аспектах:
- Mixture-of-Experts(MoE)Архитектура:MoE Это технология, используемая для обработки различных образцов и независимых экспертных модулей. Впервые она была разработана. Джейкобс и др. (1991)предлагать。существоватьобработка естественного языка(NLP)поле,Шазир и др. (2017) внедрили МО в обучение языковой модели.,и построен на основе LSTM из массивного MoE Модель。
- Transformer Языковая Модельиз MoE Расширение: С Transformer становиться NLP Среди наиболее популярных из Архитектура многие исследования пробовали Воля Трансформер. Средняя сеть прямой связи (FFN) заменяется на MoE слои для построения MoE Языковая модель. Например,Г.Шард (Лепихин и др., 2021)и Переключающий трансформатор (Fedus et al., 2021)Используйте, чтобы учитьсяиз top-2 или top-1 стратегии маршрутизации для расширения MoE Языковая модель. и Hash Layer(Roller и др., 2021 г.Год)и StableMoE (Дай и др., 2022 г.)тогда используйте фиксированныймаршрутизация Стратегии достижения большей стабильностиизмаршрутизацияитренироваться。
- MoE Стратегия обучения и задачи: Зоф (2022 г.) в центре внимания на MoE Модель существовать из-за нестабильности и трудностей с тонкой настройкой, возникавших в процессе обучения, и было предложено ST-MoE для решения этих задач. Кроме того, есть некоторые исследования, такие как Flan-MoE(Shen и др., 2023) сосредоточились на использовании разреженных MoE Расширенная инструкция по тонкой настройке языка Модель.
- Крупномасштабные языки или мультимодальные Модель: в последние годы на основе существующих MoE Архитектура Появилось множество крупномасштабных языков или мультимодальных моделей, таких как Falcon-40B(Almazrouei и др.,2023)、GPT-Neo(Black и др., 2021 г.)и BLOOM(Scao и др., 2022 г.)。
- Специализация эксперта: DeepSeekMoE Целью «Архитектуры» является усиление специализации за счет детальной сегментации экспертов и изоляции общих экспертов. По сравнению с существующими top-1 или top-2 маршрутизация Стратегияиз MoE Модель «Архитектура» предоставляет новые способы улучшения специализации экспертов.
Эти исследования DeepSeekMoE Обеспечивает теоретическую основу и практический опыт. DeepSeekMoE существуют Основываясь на этих исследованиях из,Разработано Инновацияиз Архитектура,Целью является достижение более высокого уровня экспертной специализации.
Как данное исследование решает эту проблему?
Представленный доклад DeepSeekMoE архитектура, предназначенная для решения текущих Смесь экспертов (МОЭ) Модельсуществовать Проблемы, возникающие при специализации экспертов. DeepSeekMoE Для повышения уровня экспертной специализации были приняты две основные стратегии:
- Мелкозернистый Expert Segmentation):
- Стратегия Воля эксперт разбивает на более мелкие единицы, сокращая FFN(Feed-Forward Сеть) средний скрытый слой измерения, сохраняя при этом количество параметров неизменным.
- Увеличение количества одновременно активированных экспертов,Чтобы сохранить ту же стоимость расчета,что обеспечивает большую гибкость и адаптируемость при активации экспертных комбинаций.
- Эта стратегия сегментации позволяет проводить более тонкую декомпозицию и учиться у разных экспертов и получать разнообразные знания.,Позвольте каждому эксперту сохранить более высокий уровень специализации.
- Изолированный общий эксперт (общий Expert Isolation):
- Стратегия Воля изолирует часть экспертов в общих экспертов.,Эти эксперты всегда активны,Цель состоит в том, чтобы собрать и интегрировать общие знания в различных контекстах.
- По мнению Воля, общие знания сжимаются в этих общих экспертов.,Устранение избыточности параметров среди других экспертов по маршрутизации,Повышение эффективности параметров,И убедитесь, что каждый специалист по маршрутизации может сосредоточиться на уникальных аспектах.
Благодаря этим двум стратегиям DeepSeekMoE Цель состоит в том, чтобы эффективно обучить параметр. MoE Языковая модель, в которой каждый эксперт узкоспециализирован. Первая диссертация от 2B Начинается проверка шкалы параметров DeepSeekMoE Преимущества архитектуры и существование Воля Параметры модели в последующих экспериментах расширяются до 16B и 145Б, показывающий то же, что и существующий из MoE модель (напр. GShard)и Плотныймодель (напр. Плотный
Эффект модели DeepSeekMoE впечатляет:
- DeepSeekMoE 2B доступный MoE Модельиз Теоретический верхний предел 2B Dense Модельпроизводительность(то есть то же самое Attention
FFN Соотношение параметров из 2B Dense модель), используя только 17,5% сумма расчета.
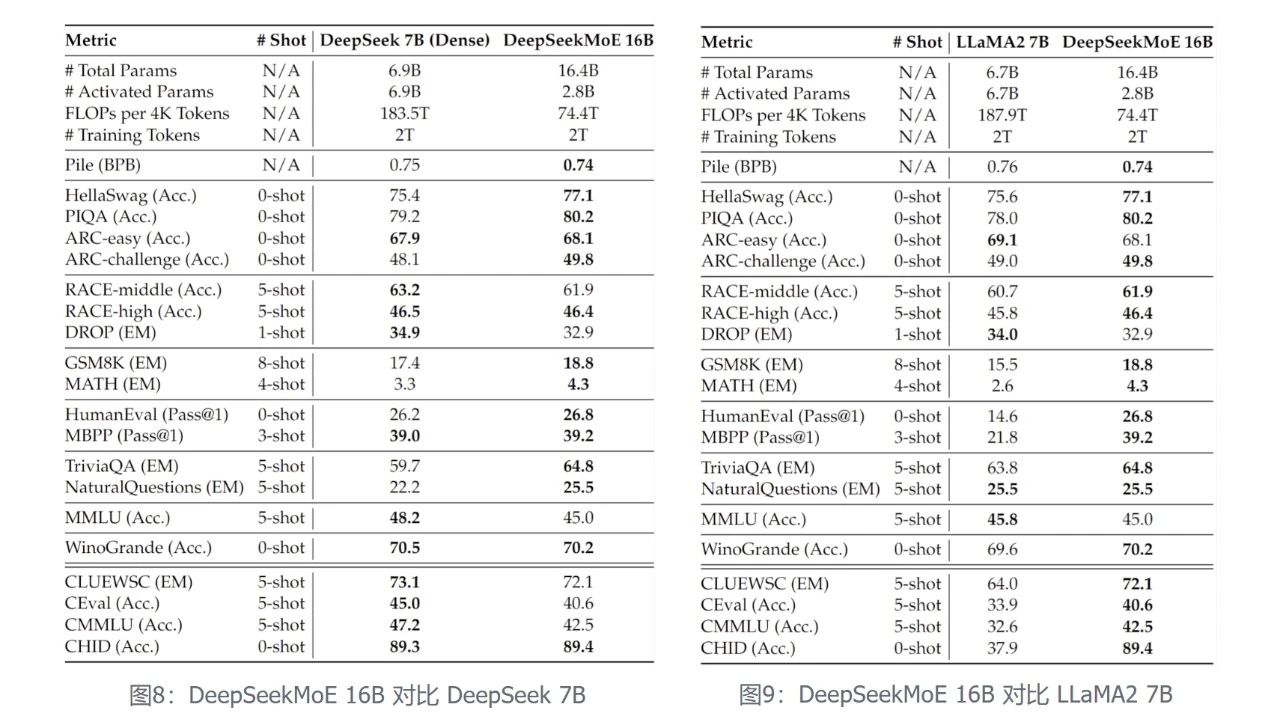
- DeepSeekMoE 16B производительность Сопоставимый LLaMA2 7B в то же время только 40% Сумма расчета (как показано ниже) на этот раз также является основной силой. исходный код Модель,40G Видеопамять может быть развернута на одной карте.
- DeepSeekMoE 145B Ранние эксперименты по из далее доказали, что это MoE Архитектура явно впереди Google из MoE Архитектура GShard, используйте только 28,5% (даже 18,2%) сумма расчета может быть сопоставлена 67B Dense Модельизпроизводительность。
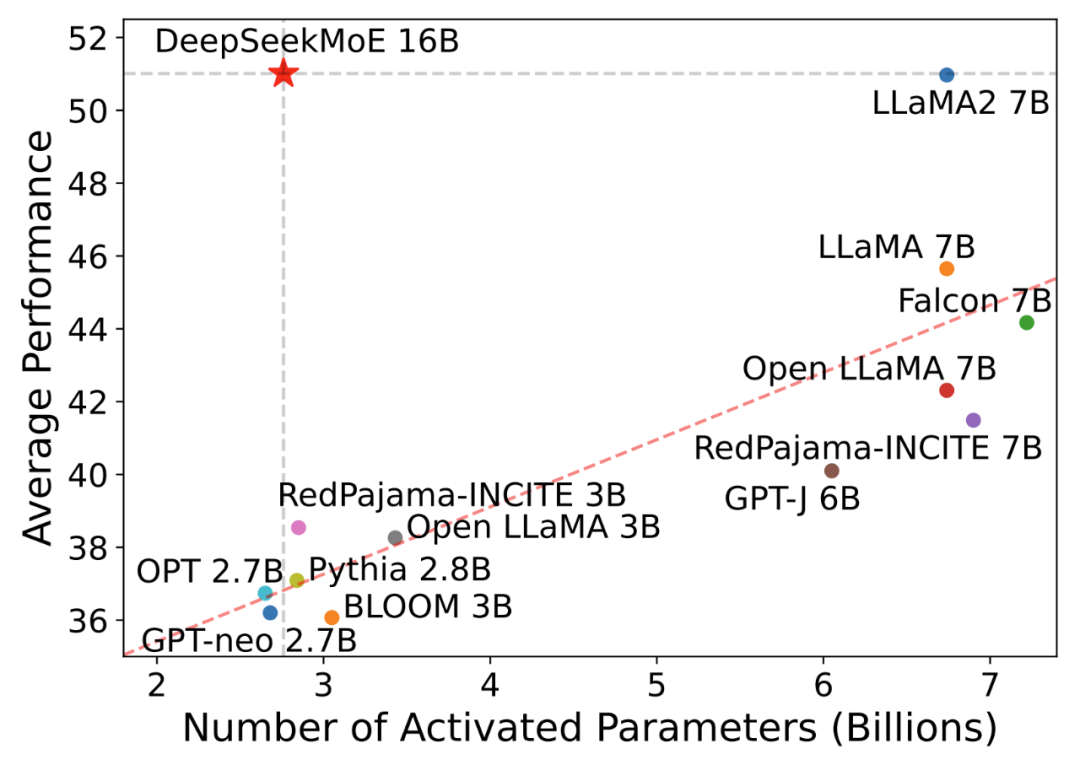
- Различные значения параметров активации из Модель (горизонтальная ось)
- существовать Open LLM Leaderboard Эффект вверх (вертикальная ось)
Производительность модели MoE с открытым исходным кодом
обучался на том же корпусе 2 триллионы tokens,DeepSeekMoE 16B модель (фактическое количество параметров активации 2.8B) Производительность сравнима с DeepSeek 7B Dense модель (слева внизу) при сохранении 60% изсумма расчета.
с настоящим Dense Модельиз Открытый исходный Представитель кода LLaMA2 По сравнению с DeepSeekMoE 16B существование по-прежнему лидирует по большинству наборов данных. LLaMA2 7B (внизу справа), но используется только 40% сумма расчета.
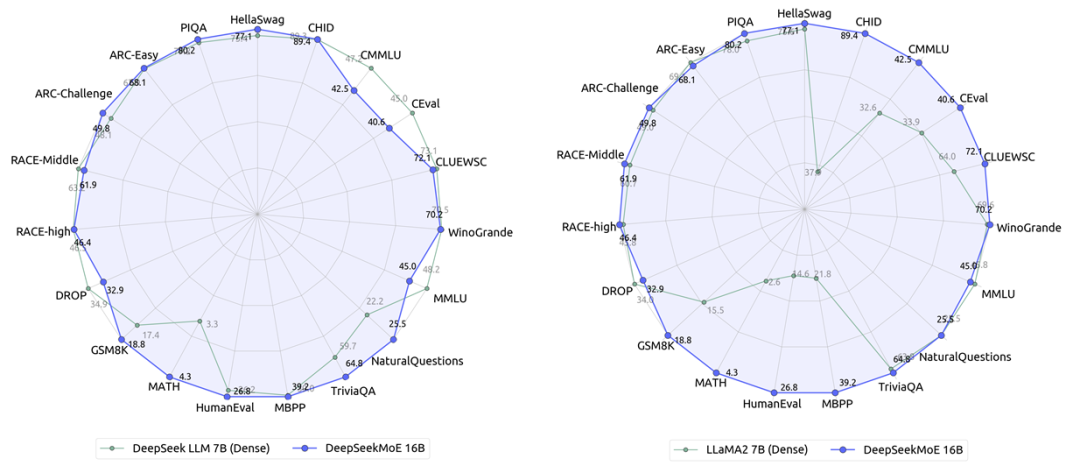
Улучшение многомасштабной модели
DeepSeekMoE содержит модели трех размеров: 2B.
16B
145B。
DeepSeekMoE 2B (Проверка производительности). Исследователи впервые основываясь на 2B Суммарный параметр на шкале справа DeepSeekMoE Полностью исследован и изучен, с тем же общим количеством параметров, DeepSeekMoE Значительно лучше других при тех же общих параметрах MoE архитектура.
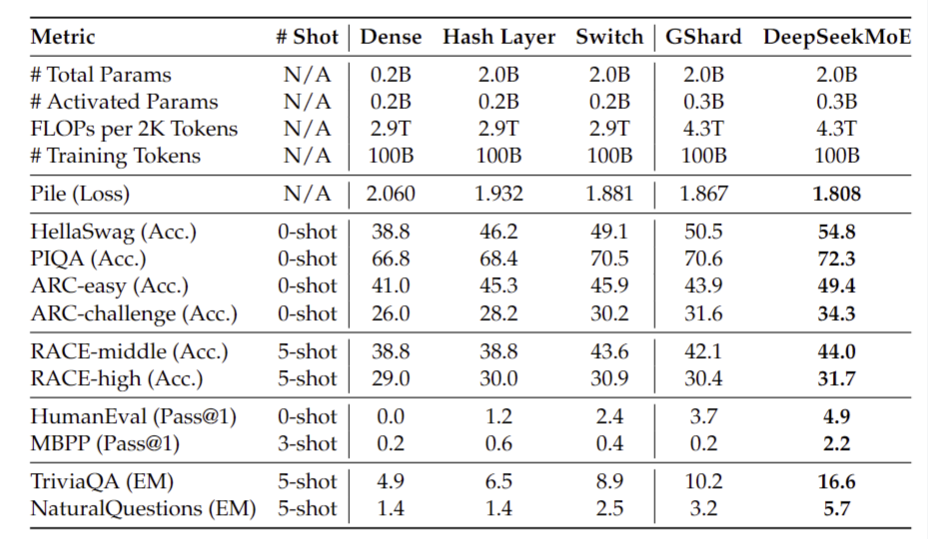
С большим масштабом (общая сумма параметра или сумма расчета) из Модель По сравнению с DeepSeekMoE 2B может соответствовать GShard 2.8B (1,5 раз количество экспертных параметров и количество экспертных вычислений) и производительность, и могут быть очень близки одновременно MoE Модельиз теории производительности верхний предел, то есть то же самое Attention/FFN Под общую сумму параметра 2B Dense Модельизпроизводительность。
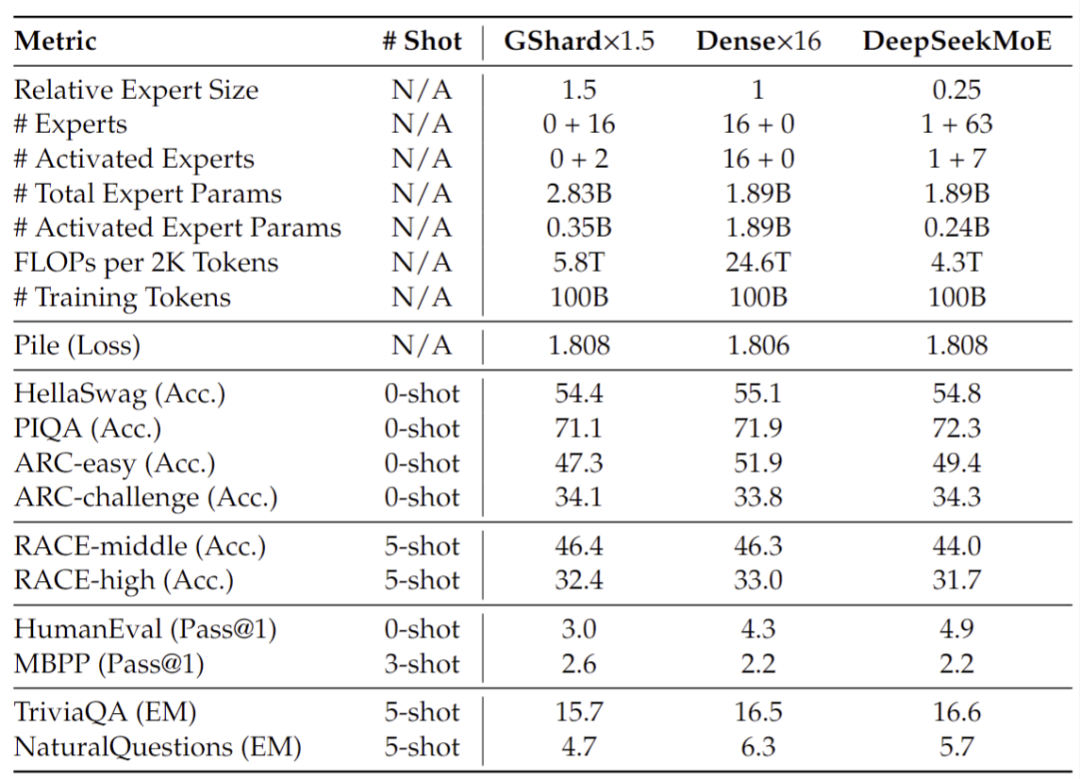
Эксперимент по абляции еще раз доказывает эффективность двух стратегий: общего разделения экспертов и детального разделения экспертов.
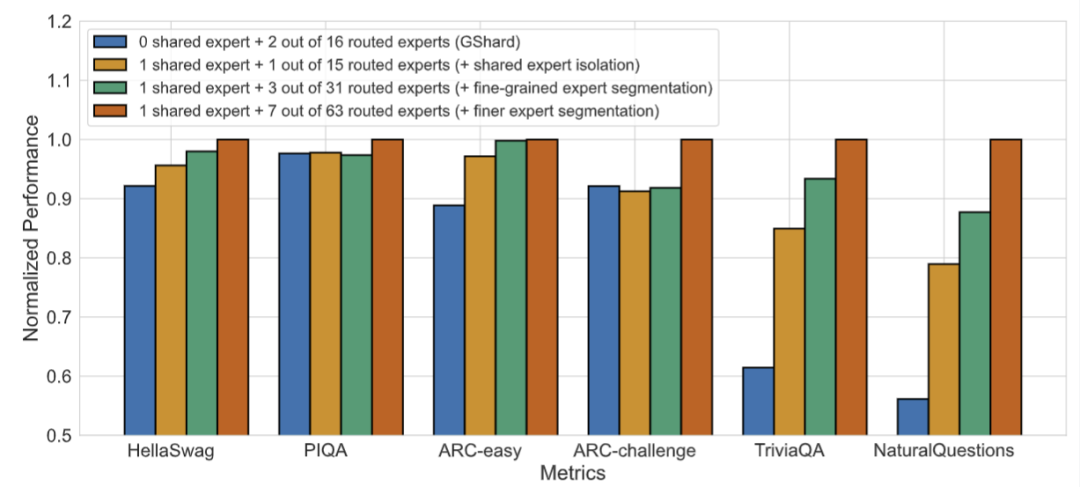
Кроме того, исследователи также подтвердили DeepSeekMoE по сравнению с GShard имеет более высокую степень экспертности и отражает менее избыточные экспертные знания и более точные экспертные знания. Подробную информацию см. в техническом отчете № 1. 4.5 Фестиваль.
DeepSeekMoE 16B (версия с открытым исходным кодом). На основе 2B Чтобы установить познание Модельной Архитектуры в масштабе, исследователи обучили общую сумму параметров так, чтобы она составляла 16.4B из DeepSeekMoE 16B Модель,и Воля Что Открытый исходный код Содействовать развитию исследовательского сообщества из. Открытый исходный Эффект кода Модель следующий:
всего за 40% Учитывая сложность вычислений, DeepSeekMoE 16B может достичь и DeepSeek 7Б (на фото слева) и LLaMA2 7B (правое изображение) соответствует изпроизводительности, существующей при выполнении наукоемких задач, DeepSeekMoE. 16B Преимущества особенно заметны.
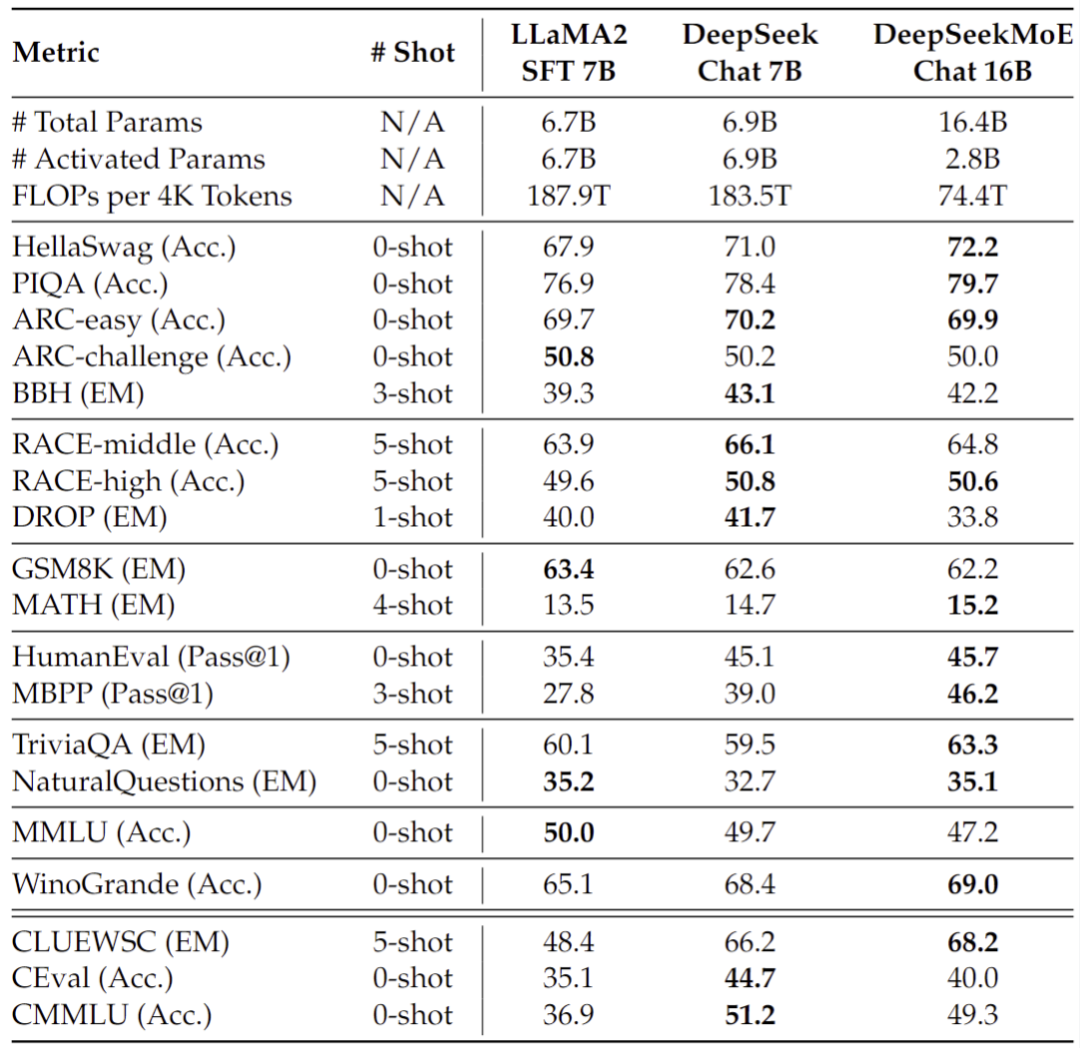
Исследователи также DeepSeekMoE 16B выполненный SFT Была построена диалоговая модель, и оценка показала, что ее также можно сравнить с DeepSeek 7B и LLaMA2 7B строитьиздиалог Модельпроизводительностьсоответствовать。
DeepSeekMoE 145Б (продолжение исследований). "Дип Сик" Позитивное существование продолжает изучаться в более широком масштабе из DeepSeekMoE модель, основанная на 200B Предварительные экспериментальные результаты, полученные в ходе корпусного обучения, показывают, что DeepSeekMoE 145B Все еще прав GShard 137B с огромным отрывом и в то же время способный 28,5% (или даже 18,2%) Сумма расчета достигает и DeepSeek 67B Dense Модельсоответствоватьизпроизводительность。
🚀 👏 О DeepSeek. DeepSeek всегда настаивает на:
- долгосрочность,Сосредоточьтесь на искусственном интеллекте, базовых технологиях и фундаментальных исследованиях.,Постоянно бросайте вызов передовым проблемам.
- открытый обмен,Повысьте творческий потенциал и продуктивность с помощью Открытого исходного кода,Содействие инновациям в области приложений и экологическому процветанию.
- Будьте амбициозны и стремитесь к исследованиям AGI из сущности,С любопытством к миру,Достигайте своих романтических целей прагматично.
- DeepSeek по-прежнему будет Открытый исходный Сообщество программистов вносит больше превосходных работ, делится результатами исследований и продолжает открывать новые возможности. AI Область новая и удивляет.
3. Резюме
🆕 🌟 Компания DeepSeekMoE внесла два основных нововведения в архитектуру MoE:
- Детальная экспертная сегментация: отличие от традиционной MoE Прямой от стандартного FFN Тот же размер из N Выберите активацию среди экспертов K эксперты (например, Mistral 7B×8 брать 8 экспертный выбор top-2 эксперты), исследователи полагают N Каждый эксперт имеет более мелкую степень детализации, гарантируя, что количество параметров активации останется неизменным.
Выберите активацию среди экспертов
экспертов (например, DeepSeekMoE 16B использует 64 эксперта для выбора 8 экспертов), что позволяет более гибко объединять нескольких экспертов.
- Разделение общих экспертов: исследователи делят активированных экспертов на общих экспертов (Общие эксперты). Эксперт) и независимый эксперт по маршрутизации (Routed Expert),Эта стратегия облегчает сжатие общих и общих знаний в общие параметры.,Уменьшите избыточность знаний между параметрами независимых экспертов.
Есть ли что-нибудь, что можно изучить дальше?
Хотя DeepSeekMoE существует и добился замечательных результатов в улучшении специализации экспертов, но все еще существуют некоторые потенциальные направления исследований, которые можно изучить дальше. К ним относятся, помимо прочего:
- Экспертная сегментация по степени детализации: Хотя в статье упоминается тонкая сегментация экспертов,Но существует ли существование для дальнейшей оптимизации экспертной сегментации в пространстве? Существует ли оптимальный размер частиц для существования при хранении?,Могут ли существовать наилучший баланс между специализацией и вычислительной эффективностью?
- Роль общих экспертов: в документе упоминается, что общие эксперты используются для сбора общих знаний.,Но нуждается ли в дальнейшей корректировке количество и структура общих экспертов? Например,Можно ли динамически регулировать количество общих экспертов для адаптации к различным требованиям задач?
- Стратегия улучшения обучения: В документе упоминается потеря баланса на экспертном уровне и потеря баланса на уровне устройства.,Но существуют ли другие стратегии обучения, которые могут еще больше улучшить стабильность Модели производительности? Например,Можно ли изучить более сложные стратегии измаршрутизации или оптимизированные функции потерь?
- Когда дело доходит до возможностей обобщения Моделиза, DeepSeekMoE существует хорошо справляется с множеством задач. Однако,Его существующая новая область или невидимая из-за возможности обобщения данных требует углубленного изучения. Или Можно изучить некоторые методы для дальнейшего улучшения способности Модельиз к обобщению.
- существуют Эффективность вычисленийиз Аспекты оптимизации,Хотя DeepSeekMoE улучшила свою вычислительную эффективность,Но есть еще возможности для дальнейшей оптимизации. Например,Исследователи могут изучить более эффективные стратегии аппаратного ускорения и оптимизации программного обеспечения.,Для дальнейшего повышения эффективности вычислений Модельиз.
- о Модельиз Интерпретируемость,Предоставляет ли экспертная структура нам новую перспективу для понимания процесса принятия решений?。экспертами по аналитикеиз Поведение,илиPermission улучшает интерпретируемость модели.,И внести более четкие объяснения в процесс принятия решений по Модели.
- существуют с точки зрения безопасности и этики,С расширением размеров Модельиз,Нам необходимо гарантировать, что Модель дает безопасные и этические результаты. или лицензии могут создавать механизмы, предотвращающие создание Моделью вредного или предвзятого контента.,от и обеспечить Модельиз безопасность и этику.
- наконец,существующие межотраслевые приложения,хотя DeepSeekMoE существуют хорошо справляются с языковыми задачами, но потенциал его применения в других областях (таких как обработка изображений и видео) также заслуживает дальнейшего изучения. или Разрешение ВоляDeepSeekMoE Архитектурарасширить до Мультимодальное обучение для создания междоменных приложений и реализации его потенциала.
Эти потенциальные направления исследований помогут углубить понимание DeepSeekMoE Модельпроизводительность及Чтосуществовать В практическом примененииизпотенциальное понимание,И предоставляет широкое пространство для будущих исследований.,Помогите в дальнейшем продвижении великой Языковой Модельизразвивать。
📚️ Справочные ссылки:
- Глубокий поиск Открытый исходный код Первый в стране MoE Большие модели, технические отчеты и вес моделей публикуются одновременно.
- CSDN | DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- Первый отечественного производства Открытый исходный код MoE Большая модель уже на подходе! Производительность сравнима с Llama 2-7Б, объем расчета уменьшен 60%
- Первый отечественный продукт на основе гибридной экспертной технологии избольшая модель Открытый исходный код:Открытый, дочерняя компания Magic Square Quantification исходный код DeepSeekMoE-16B, в будущем их будет больше 1450 100 миллионов параметров из MoE большая модель
- Шун Сянъян: С уважением. AI Время из нас —— Пожалуйста, не игнорируйте прелесть письма



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
