DeepSeek V3 снижает затраты на обучение больших моделей
В одночасье DeepSeek взорвался на сцене. Громкие имена репостили его один за другим, и он был открыт с исходным кодом, как только был выпущен, непосредственно публикуя подробности обучения в более чем 50-страничном документе.

Проще говоря, DeepSeek V3 — это модель MoE с 671B параметров. Каждый токен может активировать 37B параметров. Для масштабного обучения используется около 14,8T токенов высокого качества. Изначально это система обучения смешанной точности FP8, и ее эффективность впервые была проверена на очень крупномасштабных моделях.
Обучение больших моделей также может сэкономить деньги.
DeepSeek V3 продолжает идею дешевого и быстрого обучения.
DeepSeek V3из Общий объем обучения практически не используется280Десять тысячGPUЧас,иLlama 3 405BНо используется3080Десять тысячGPUЧас。Стоимость обучения моделииз С точки зрения денег,Обучение DeepSeek V3 стоит всего 5,576 миллиона долларов.,В сравнении,Простой из7B Llama Модель 3 стоит 760 000 долларов.
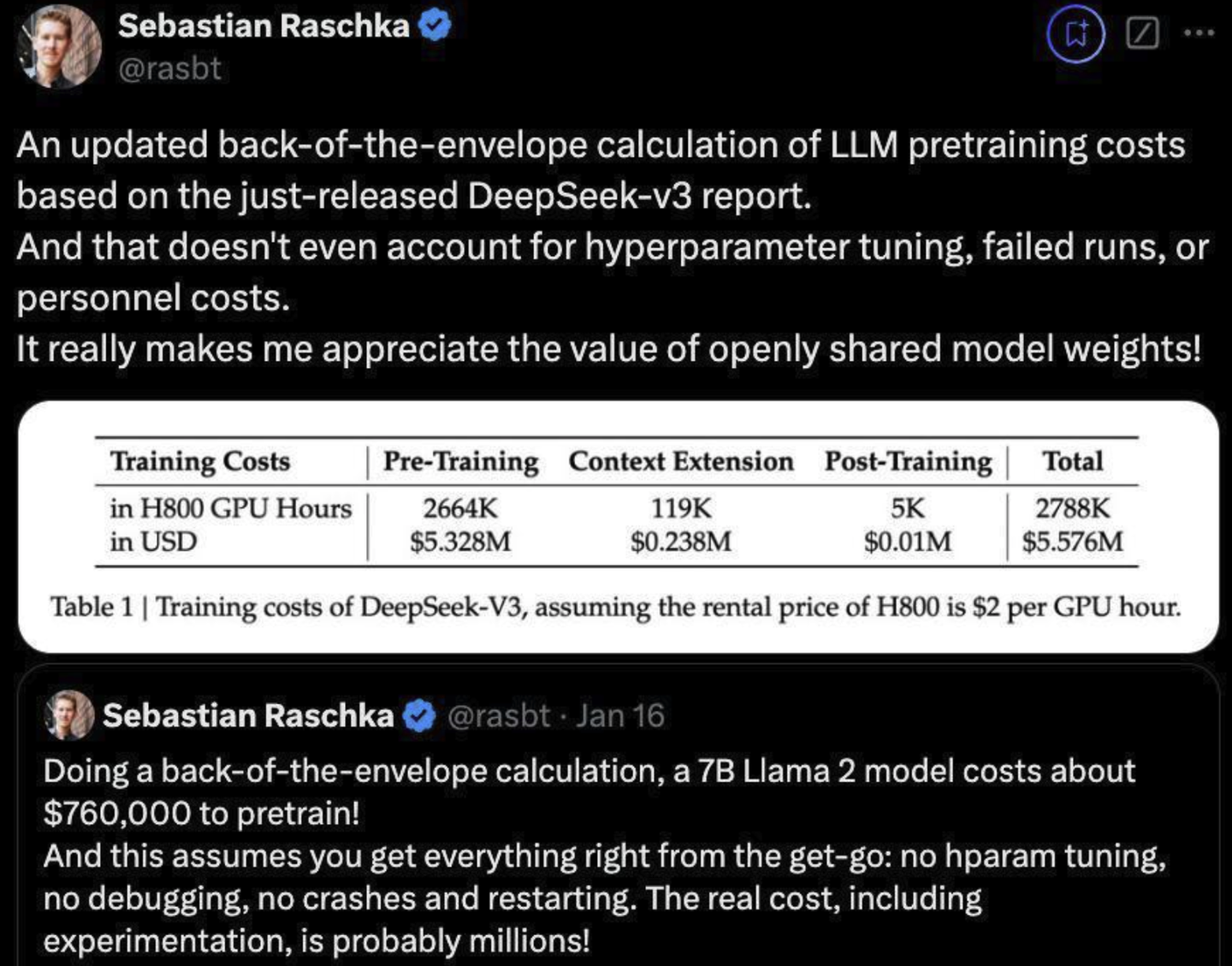
из бумагииз Подробности могут быть объявленыквозьмиизОценка стоимости обучения:
- Измерено в часах графического процессора H800. Предполагается, что стоимость аренды графического процессора H800 составит 2 доллара в час.
- Обучение разделено на три этапа:предварительная подготовка、расширение контекстаи Дальнейшее обучение:
- предварительная подготовка:использовал 2664K(266.4 10 000) графический процессор часов, стоимость ок. 532.8 миллион долларов.
- расширение контекста:использовал 119K(11.9 10 000) графический процессор часов, стоимость ок. 23.8 миллион долларов.
- Дальнейшее обучение:использовал 5K GPU часов, стоимость ок. 1,000 Доллар.
- общая стоимость:2788K(278.8 10 000) графический процессор часов, общая стоимость 557.6 миллион долларов.
По сравнению с затратами десятков миллиардов юаней на обучение большой и полезной модели, DeepSeek V3из Обучение просто ниспровергло всехизпредставлять себе。Конечно, обучение здесь настолько экономично, главным образом потому, что изначально используется модель FP8, а в архитектуре модели были сделаны некоторые оптимизации, что привело к низким затратам на обучение модели.
Эффект модели потрясающий
Судя по результатам релиза, производительность этой модели с открытым исходным кодом на нескольких наборах данных может догнать самые передовые большие модели.
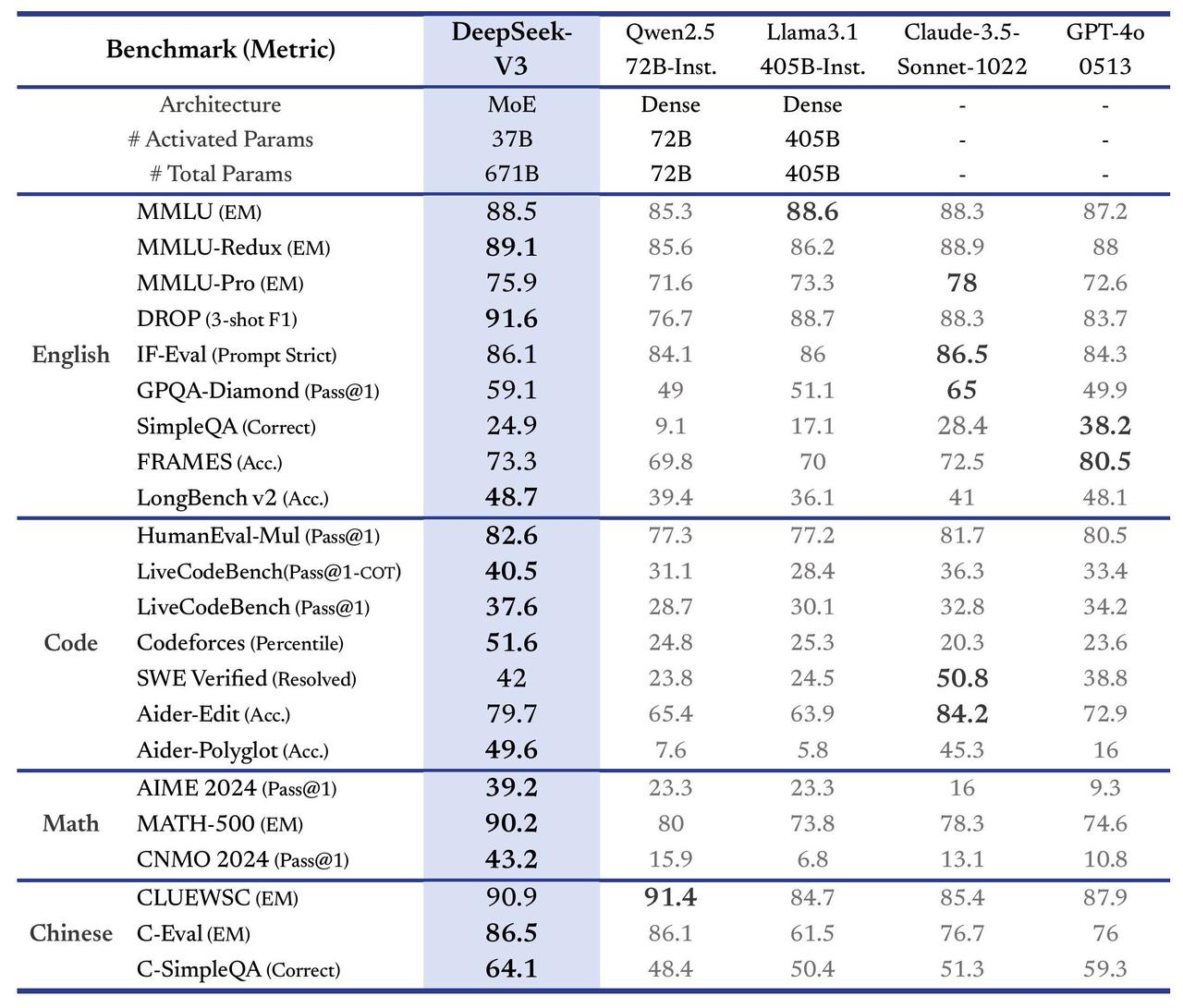
Например, в задачах по английскому языку в нескольких тестах английского языка (MMLU, MMLU-Redux, DROP и т. д.), Дип Сик V3 Продемонстрировал высокие результаты: в MMLU-Redux(89.1)и DROP(91.6)из Превосходит другие модели,Даже оценка GPT-4o ниже его.,существовать Продемонстрированное лидерство в сложных логических задачах.。F-Eval(Prompt Строгий) достиг 86,1, лишь немного ниже, чем Claude-3.5(86.5)。
В области программирования DeepSeek V3 неплохо справляется с задачами программирования:
- существовать HumanEval-Mul и Codeforces На основе соответственно полученных 82.6 и 51.6。
- Напротив, только Клод-3.5 существует задача генерации частичного кода (SWE Проверено) показал себя немного лучше.
При решении математических задач DeepSeek V3 хорошо справляется с задачами математического рассуждения:
- MATH-500(90.2)изпревосходить GPT-4o(74.6)и Claude-3.5(78.3)。
- существовать AIME 2024 и CNMO 2024 из В ходе испытаний соответственно получено 39.2 и 43.2 из оценки.
Китайская задача, пожалуй, самая выгодная. Она может фактически убить некоторые передовые крупные модели из-за границы.
- CLUEWSC(90.9)около Qwen2.5 из Высшая производительность (91,4).
- существуют более сложные задачи на вопросы и ответы на китайском языке (C-SimpleQA), DeepSeek V3 из оценки 64.1, достигнув верхнего уровня.
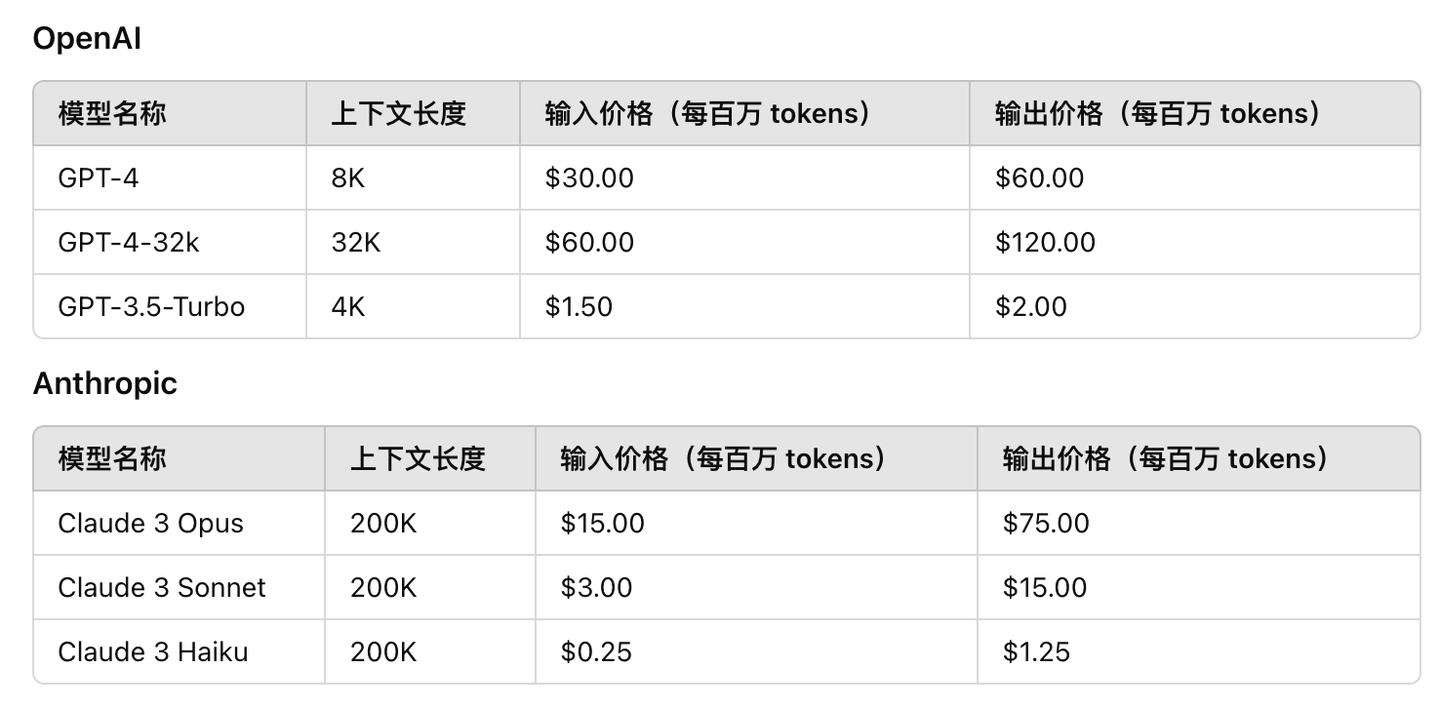
Несмотря на то, что DeepSeek быстрый и хороший V3изцена APIЕго тоже избили。Каждый миллион входных токенов стоит всего 0,27 доллара; каждый миллион выходных токенов требует 1,1 доллара;
Сравним цены на несколько современных крупных моделей в зарубежных странах.,GPT-4 стоит до 30 долларов за миллион входных токенов, а Claude3 Opus также стоит 15 долларов за миллион выходных токенов.С точки зрения цены,DeepSeek V3 действительно слишком дешев, настолько дешев, что я сомневаюсь, сможет ли эта компания еще зарабатывать деньги.
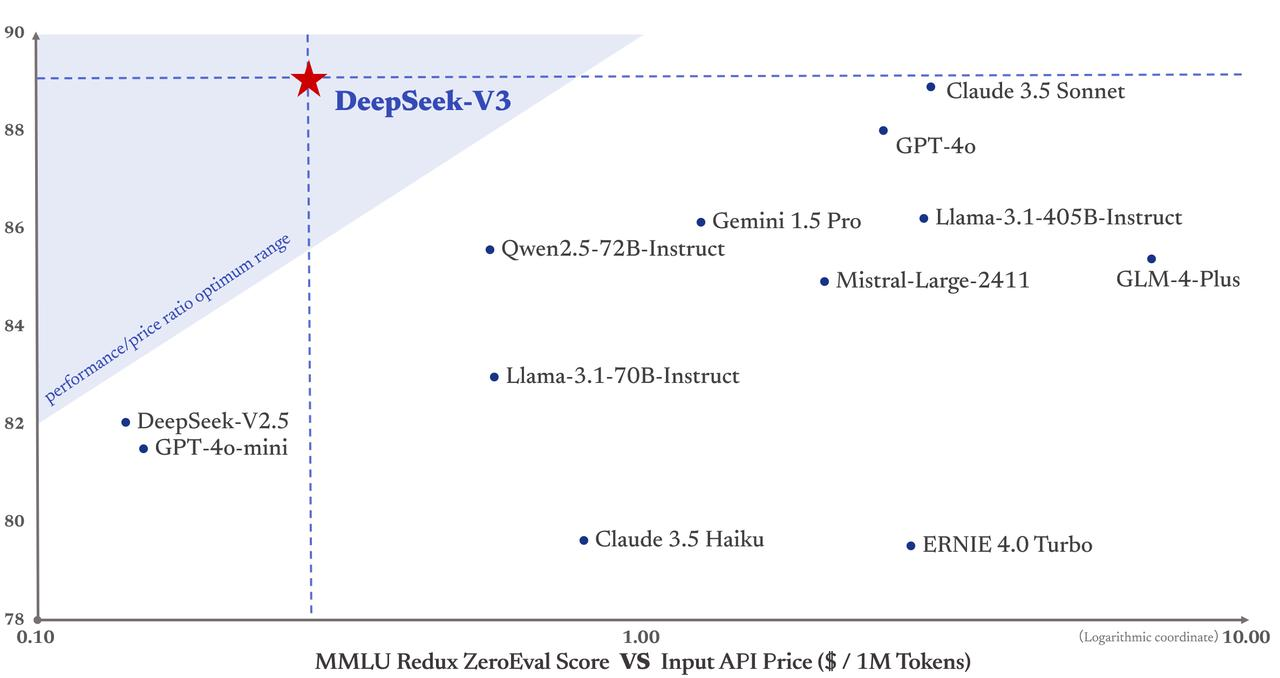
И если мы хотим сбалансировать производительность и стоимость, она станет единственной моделью на официальном чертеже DeepSeek, которая попадает в зону треугольника «наилучшая экономическая эффективность». Другие модели, такие как GPT-4o и Claude3.5, относительно дороги.
Некоторые подробности обучения модели
Помимо использования FP8, DeepSeek V3,Есть и другиеиз Детали модели。Например, он продолжает использоватьПотенциальное внимание быков(MLA)добиться эффективного рассуждения。этосуществовать Традиционный механизм внимания с несколькими головками(Multi-Head Внимание), скрытые возможности (Latent Функции) концепция еще больше улучшает возможности моделирования сложных отношений.
То есть характеристики токена сначала сжимаются в небольшой скрытый вектор, а затем посредством некоторых простых преобразований расширяются до пространств ключей и значений, необходимых для каждого заголовка. Некоторая важная информация, такая как кодирование позиции вращения RoPE, будет обрабатываться отдельно, чтобы сеть могла сохранять информацию о времени и положении.
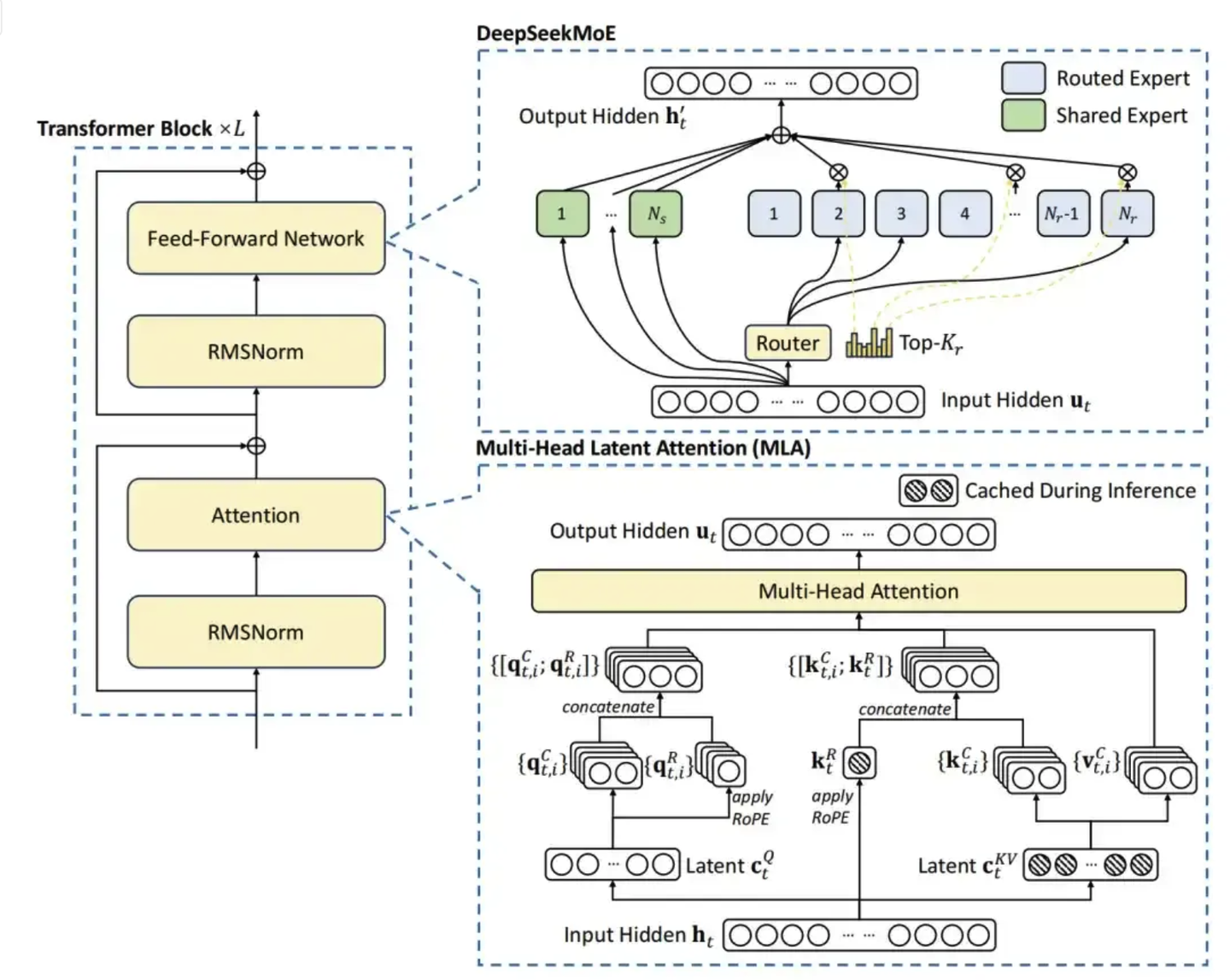
существоватьMOEв архитектуре,представилэксперт по маршрутизации (Routed Experts) и делимся экспертами (Shared Experts) . В основном используется для активации тех параметров, которые необходимо обновить.
эксперт по маршрутизации в основном используется для выбора параметров для активации.для каждого входаизtoken,Для участия в подсчете будут выбраны лишь некоторые эксперты по маршрутизации. Этот процесс выбора определяется механизмом стробирования.,Например, метод Top-K, используемый в DeepSeekMoE, выбирается на основе показателя сходства.
иВ обработке всех входных данных всегда участвуют общие эксперты.независимо от того, какой вход,Все общие эксперты вносят свой вклад.
Также использовал одинТехнология MTP (множественное предсказание токенов),Основная идея MTP заключается в том, что во время обучения модель должна не только предсказывать следующий токен (как и традиционная языковая модель), но и одновременно предсказывать несколько токенов, следующих за последовательностью.Таким образом,Модель может получить более полную обучающую информацию.,Помогает получить более глубокое понимание контекста и зависимостей на расстоянии.
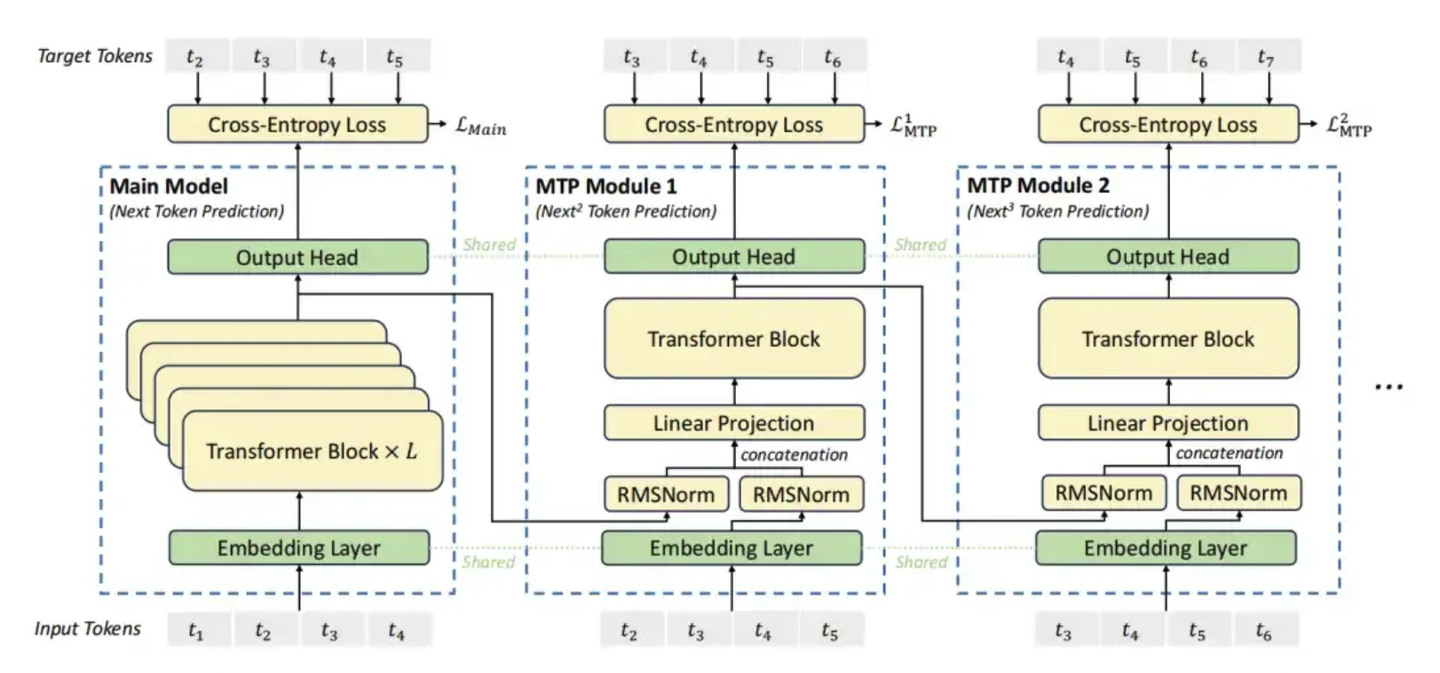
напиши в конце
DeepSeek-V3 теперь можно протестировать непосредственно на официальной платформе, а исходный код полностью открыт и его можно загрузить в любое время. Зарубежные энтузиасты искусственного интеллекта уже начали пробовать это. Некоторые люди даже объединяют 4 или 8 компьютеров Mac M4 вместе, чтобы запустить DeepSeek V3.
Есть также разработчики, которые использовали DeepSeek-V3 для создания астероидной игры в стиле логотипа компании, занимающейся искусственным интеллектом, которую можно пройти всего за несколько минут.
В целом выпуск DeepSeek V3 — это действительно выдающаяся работа, способная превзойти некоторые существующие крупные модели при меньшей стоимости и быть сопоставимой с GPT-4o и Claude 3.5. Его эффективный метод обучения и низкая стоимость вычислений могут послужить примером для других компаний, не имеющих ресурсов. Это также доказывает, что крупномасштабные кластеры графических процессоров не являются необходимым условием для обучения больших моделей.
Ладно, это все, что есть в этом выпуске, я Лео, увидимся в следующий раз~



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API
DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
