Давайте рассмотрим другой случай диагностики медленных задач SparkSql.
Сухие вещи — это скучно, поэтому на этих выходных я подробно объясню вам это в группе исходного кода~
Позавчера вечером меня включили в группу и дали серию медленных задач, что серьезно повлияло на впечатления. Время выполнения задач показано ниже. Некоторые задачи выполнялись в течение дня и еще не были завершены. Как мне начать. оптимизация?
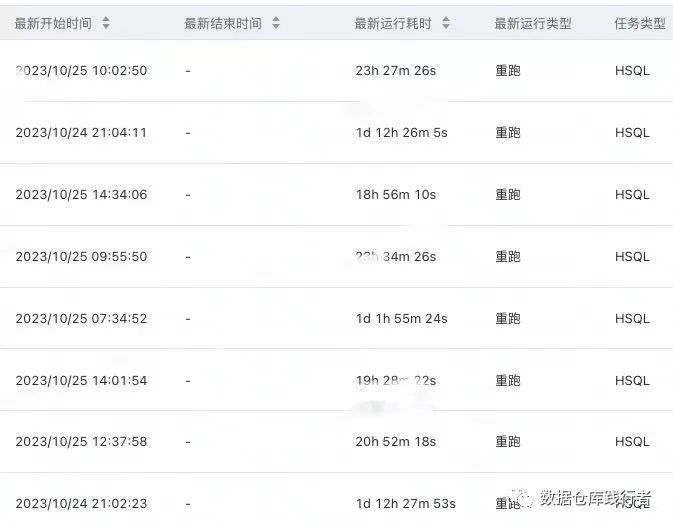
За последние полгода я оптимизировал и диагностировал сотни задач, но редко их обобщаю и записываю.
Процесс обнаружения проблем каждый раз очень прост, но на самом деле здесь задействовано много базовых навыков, таких как базовые навыки, используемые в этой оптимизации:
- Вы должны быть знакомы с планом выполнения sparksql или хотя бы понимать, что это такое.
- Стратегия выбора соединения SparkSQL, основные принципы, преимущества, недостатки и характеристики пяти основных классов реализации соединения, а также какой план выполнения следует создавать для каждого соединения.
- Система распределения и разделения
- Правило обеспечения требований
- Что такое узел Exchange (ShuffleExchangeExec) и когда будет создан узел Exchange?
Вот приблизительный план моих диагностических шагов:
1. Посмотрите на sparkwebui и посмотрите, какая работа и какой этап выполняются медленно.
2. Изучите код sql. В большинстве случаев код sql, в котором возникает эта проблема, очень длинный. Необходимо иметь достаточно терпения, чтобы прочитать код, а затем на основе диаграммы sql dag определить, какому сегменту sql соответствует медленная стадия.
3. Изучите план выполнения, чтобы увидеть, с каким типом узла связана текущая проблема: hashAgg, objHashAgg, sortAgg или sortMergeJoin и т. д. С одной стороны, зная тип текущего узла, потому что мы знаем его принцип работы? также означает, что вы знаете возможные проблемы с данными. Особенно, когда вы видите BroadcastNestedLoopJoin или Cartesianproduct, вам следует обратить на них особое внимание.
4. Посмотрите на страницу «Сводные метрики» этапа. Судя по выполненным задачам, среднему состоянию выполнения задач, определите, есть ли неравномерность данных, все ли задачи обрабатывают слишком много данных, есть ли медленные узлы и т. д.
5. Изучите данные в этом контексте SQL и проверьте, есть ли на уровне данных неравномерность данных, большие поля и т. д.
Вышеупомянутое с точки зрения разработки данных. Есть ли какие-либо улучшения? Если мы действительно не видим проблему с точки зрения SQL, нам нужны некоторые выводы, такие как:
- Объем информации, обрабатываемой каждой задачей, невелик.,И нет сложной логики вычислений.,Но он работает очень медленно --Есть ли отставание в производительности сервера?
- Если поменяем задачу, то будет ок, но в текущей очереди работать не будет - Проблема с кластером, где находится текущая очередь?
- ......
Имея эти выводы на руках, мы просим студентов, занимающихся разработкой или эксплуатацией и обслуживанием пакетов, прийти и провести исследование вместе, потому что этот уровень проблем не может быть решен в рамках наших профессиональных возможностей (ps: за исключением случаев, когда вы разносторонний талант, то есть, занимаясь разработкой данных, я также занимаюсь созданием, эксплуатацией и обслуживанием серверов, а также отвечаю за вторичную разработку и оптимизацию набора исходного кода. Неразрешимых проблем в принципе не существует).
Давайте поговорим о процессе:
1. Посмотрите на веб-интерфейс Jobs of Spark.
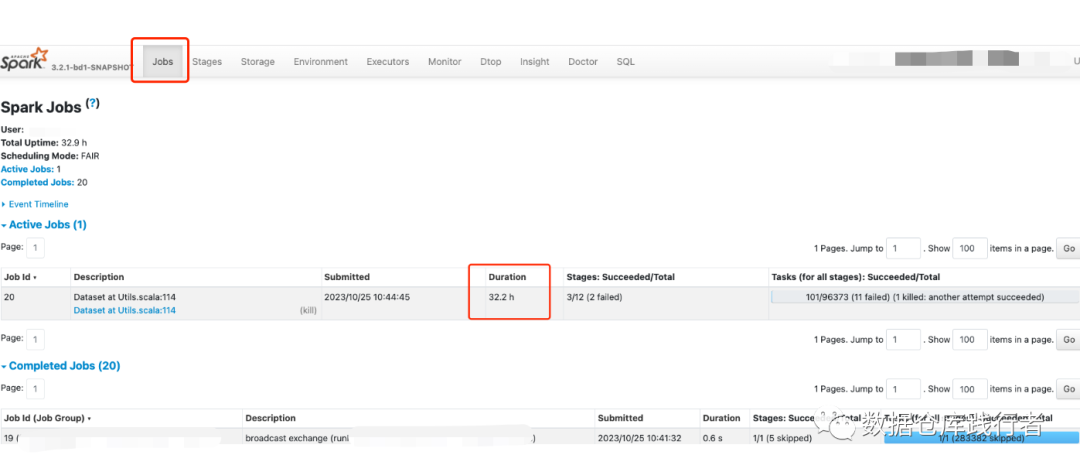
Я обнаружил, что задача с идентификатором задания 20 выполняется очень медленно. Прошло более 30 часов. Продолжайте нажимать на ссылку, чтобы перейти.
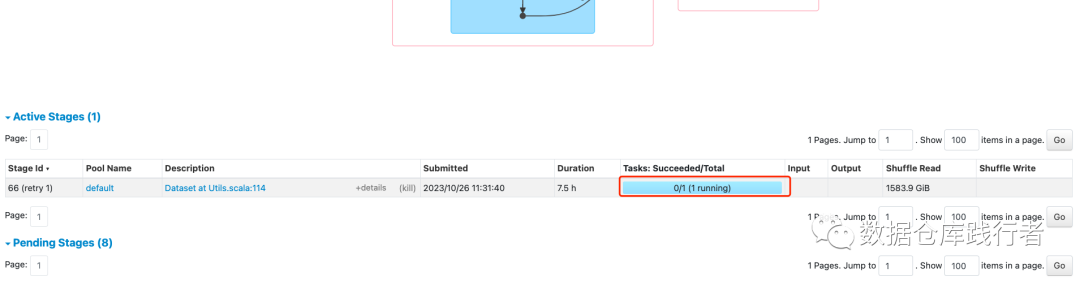
Я обнаружил, что в этом задании выполняется только одна задача, а объем случайного чтения довольно велик. Мое первое подозрение: данные искажены?
2. Найдите диаграмму DAG SQL, а затем определите, какому плану выполнения соответствует задача в точке зависания и каков контекст ввода и вывода.
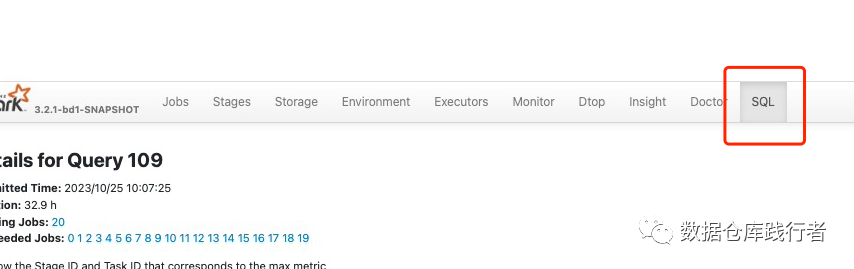

Как и выше, мы наконец нашли диаграмму dag, соответствующую зависшей задаче, то есть BroadcastHashJoin. Левая таблица представляет собой промежуточный результат после серии вычислений. Правая таблица также содержит только один фрагмент данных после серии вычислений. используется вещание, которое является более всеобъемлющим. Картина следующая:
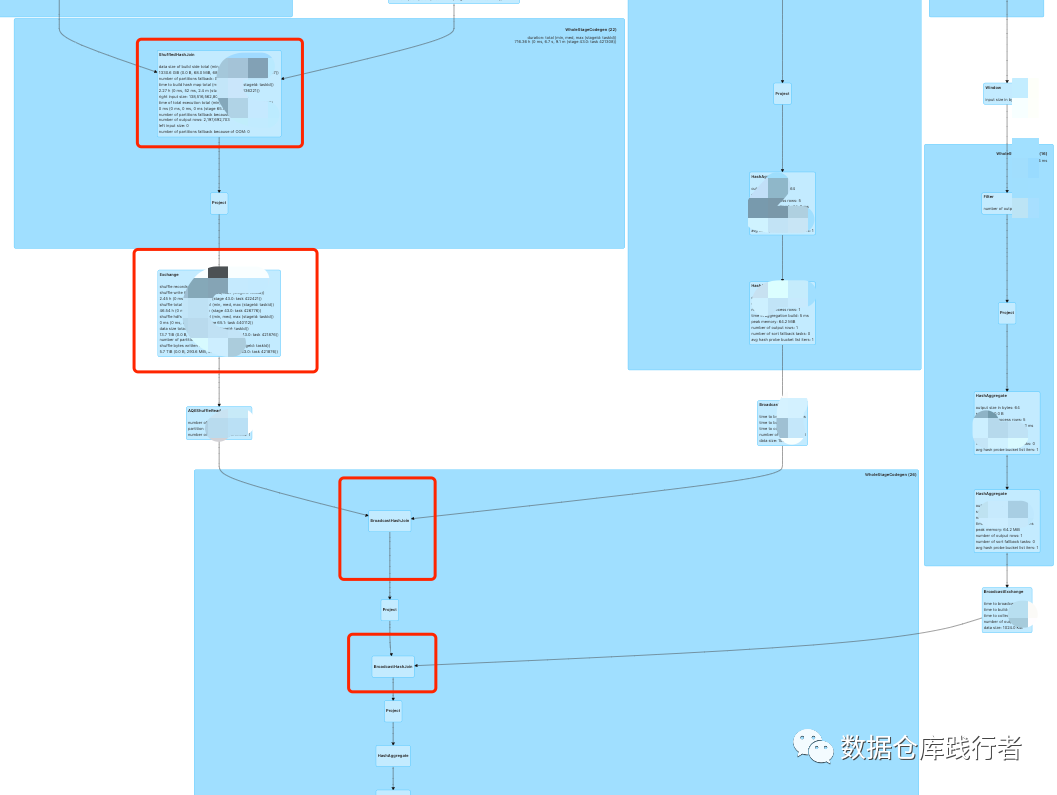
Из диаграммы дага видно, что объем данных в левой таблице действительно очень большой. Задача только одна и она определенно будет работать медленно, однако, исходя из понимания объединения, правая таблица уже была. транслируется. Левая таблица теоретически больше не нуждается в узле обмена (перетасовки), но здесь действительно имеется дополнительная перетасовка.
3. Посмотрите на конкретную логику SQL (большой тест)
После упрощения и снижения чувствительности, прикрепите его сюда. Это действительно очень сложный SQL. Это также самый этап тестирования. При настоящей оптимизации нужно терпеливо читать код. Ха-ха, иногда мне не хочется читать. второй код, который я написал. Опять же, читать чужой код действительно непросто.
WITH s1 AS (
SELECT id,
xx,
....
FROM table1
WHERE date = '${date}'
AND id IN (1111)
),
s2 AS (
SELECT id,
did,
MAX(
XX
) AS xx
FROM table2
WHERE date = '${date}'
AND id IN (1111)
GROUP BY
id,
did
),
s3 AS (
SELECT id,
s_id,
SUM(xx) AS xx
FROM table3
WHERE date = '${date}'
GROUP BY id,
s_id
),
s4 AS (
SELECT id,
s_id,
xx
FROM (
SELECT xx
FROM table
WHERE date = '${date}'
GROUP BY
xx
) t1
LEFT JOIN
(
SELECT xx
FROM table
WHERE date = '${date}'
GROUP BY
xx
) t2
ON t1.xx = t2.xx
AND t1.xx = t2.xx
),
s5 AS (
SELECT id,
xx
FROM (
SELECT id,
xx,
row_number() OVER(
PARTITION BY
id
ORDER BY
xx ASC
) rn
FROM (
SELECT xx
FROM table
WHERE date BETWEEN '${date-14}' AND '${date-1}'
AND id = 1111
GROUP BY
xx
) m1
) m2
WHERE rn BETWEEN 3 AND 7
GROUP BY
id
),
s6 AS (
SELECT id,
xx
FROM (
SELECT id,
xx,
row_number() OVER(
PARTITION BY
id
ORDER BY
xx ASC
) rn
FROM (
SELECT xx
FROM (
SELECT xx
FROM (
SELECT xx
FROM table
WHERE date BETWEEN '${date-14}' AND '${date-1}'
AND id IN (1111)
GROUP BY
xx
) t1
LEFT JOIN
(
SELECT xx
FROM table
WHERE date BETWEEN '${date-14}' AND '${date-1}'
AND id IN (1111)
GROUP BY
xx
) t2
ON t1.xx = t2.xx
AND ..
)
GROUP BY
xx
) m1
) m2
WHERE rn BETWEEN 3 AND 7
GROUP BY
id
)
INSERT OVERWRITE TABLE tablexx PARTITION (date = '${date}')
SELECT xx
FROM (
SELECT xx
FROM s1
LEFT JOIN
s2
ON s1.id = s2.id
AND s1.did = s2.did
LEFT JOIN
s3
ON s1.s_id = s3.s_id
AND s1.id = s3.id
LEFT JOIN
s4
ON s1.s_id = s4.s_id
AND s1.id = s4.id
LEFT JOIN
s5
ON s1.id = s5.id
LEFT JOIN
s6
ON s1.id = s6.id
) mid
GROUP BY
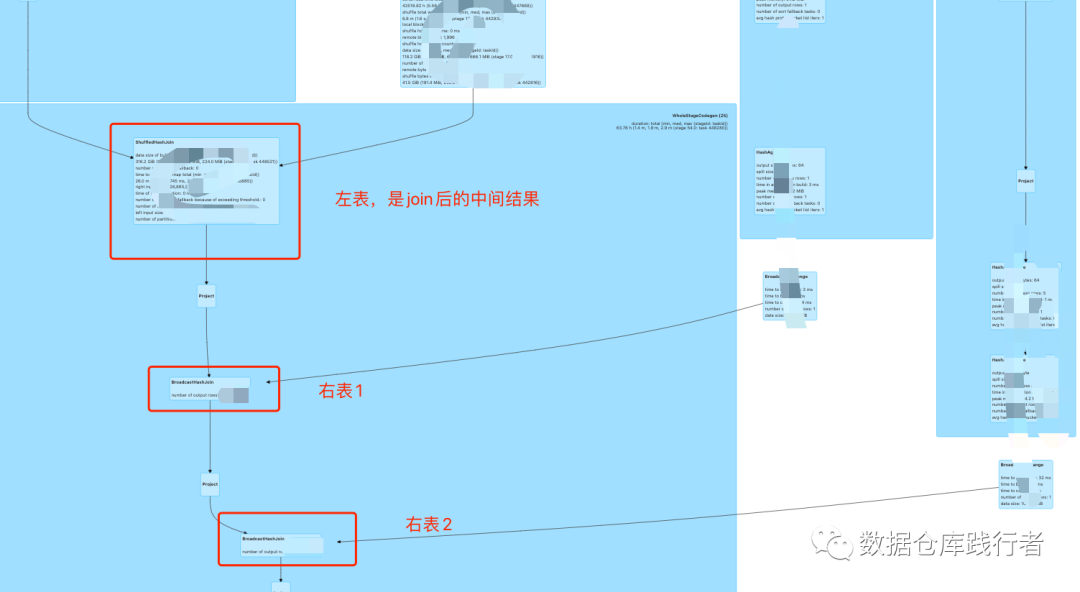
xx6 с... как... В сочетании с диаграммой дага обнаружение застрявшей точки представляет собой два последних шага:

Возможно, мы знаем причину. Значение ключа — только 1111, что является горячей клавишей. Когда мы обрабатываем такое соединение, один из способов — разрешить трансляцию правой таблицы, если правая таблица достаточно мала, чтобы левая таблица была. не требует перемешивания, что позволяет избежать перетасовки данных в ключе горячей точки во время перемешивания.
Однако, когда мы смотрим на план выполнения, транслируется правая таблица. В это время в основном определяется, что существует проблема с планом выполнения, созданным с помощью sparksql.
Обычный план выполнения должен быть таким:
Давайте сравним эти два плана выполнения вместе:
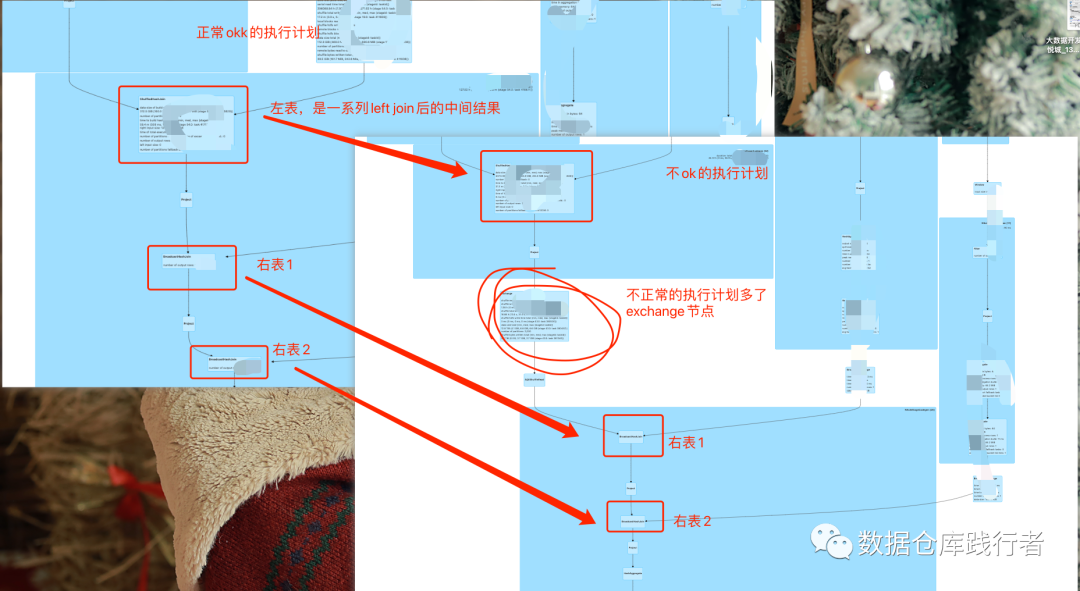
в заключение:
С sql проблем нет, как и с данными, поэтому я подозреваю, что в плане выполнения, сгенерированном sparksql, есть неправильный случай. Версия Spark, которую мы используем внутри, была разработана в ходе вторичной разработки. Мы сообщаем о проблеме. Возвращаясь к студентам, которые разработали пакет и установили резервные параметры версии Spark, данные нового дня работают нормально.




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
