Давайте поговорим о проблеме многопользовательских одновременных вызовов API в ChatGLM3.
Пожалуйста, указывайте источник при перепечатке:https://www.cnblogs.com/zhiyong-ITNote
фон
В настоящее время в компании4открытьA10изGPUна сервереразвертывать ПонятноChatGLM3Открытый исходный код Модель;Затемразвертывать Понятно官方默认изweb_demo、api_demoДва режима;重新设计Понятно前端,Поддерживает вызовы клиентов H5 и Android. Но я обнаружил проблему, заключающуюся в том, что к нему невозможно получить доступ одновременно.
Проблемное явление
Когда Android и H5 одновременно вызывают API-интерфейс ChatGLM (интерфейс потоковой передачи),Возврат от одного из клиентов — это нормально.,Но ответ от другого клиента - это искаженный код (пустые данные после декодирования),в то же время Модель Сообщить об ошибке。Сообщить об ошибке内容与问题请看issue。



Официальный ответ следующий:

Позже я протестировал модель развертывания с несколькими картами, например с 3 картами. На данный момент она может поддерживать менее 3 вызовов пользователей, но не более.
Анализ проблемы
Поскольку я не имею специальности, не связанной с искусственным интеллектом, я не специализируюсь на этом.,Так что это сразу немного сложно;Позже в ЖипуAI开放平台изРуководство по использованию - Руководство по ограничению скорости В статье я обнаружил, что он поддерживает одновременные вызовы, но сказано, что существует ограничение на количество параллелизма. Поэтому, согласно моему анализу, между выпущенной моделью и моделью на открытой платформе должна быть определенная разница, и эта разница заключается в возможности параллелизма модели. В конце концов, когда вызывается внешний API, в конечном итоге вызывается потоковый/непоточный интерфейс внутри модели. Другими словами, интерфейс внутри этой модели не поддерживает параллельные вычисления. Внутри модель представляет собой структуру нейронной сети-трансформера, но ее возможности параллельного выполнения не так просты. В конце концов, объем вычислений, задействованных в модели, огромен. В конечном счете, это возможность параллельных вычислений трансформатора. 后来找到个遇到同样情况из博文,不过和我们изразвертывать方式还是有区别из。Mosec развертывает чатglm2-6B В этой статье я проанализировал возникшие проблемы и решения. К этому моменту я, вероятно, понимаю, почему при одновременном вызове API модели возвращаются искаженные символы (пустые данные).
Причины и решения
При одновременном вызове после того, как модель обработала запрос, возвращаемый тензор распознает eos_token, и модель будет считать, что все запросы обработаны, поэтому возвращаются пустые данные. Итак, стратегия решения, которую я имею в виду на данный момент, заключается в пакетной обработке запросов в рамках модели. Этот код нелегко изменить,Должны быть стратегии реализации и решения с открытым исходным кодом. Позже я подумал о фреймворке тонкой настройки LLaMA-Factory.,У них также есть api_demo,Вы также должны столкнуться с такими проблемами,Поэтому был поднят вопрос,К счастью, в конце концов есть еще одно решение.,Видетьissue。
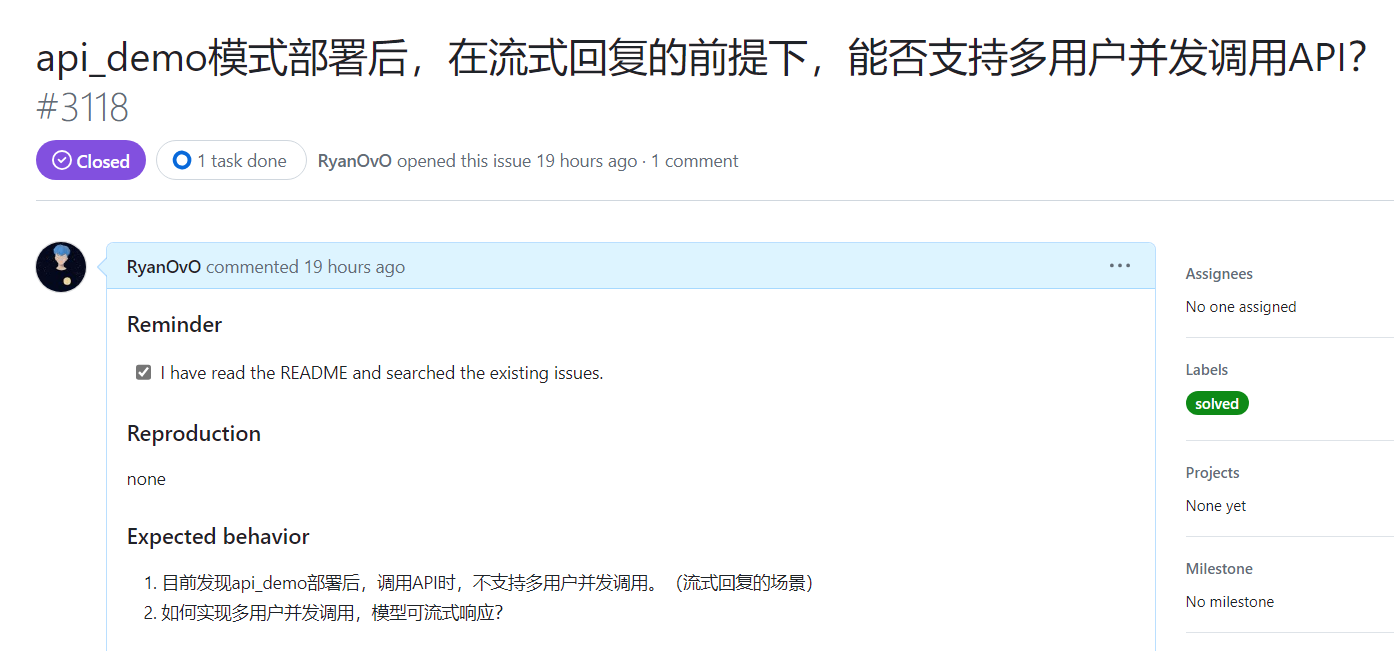

LLaMA-Factory официально реализует параллельную потоковую передачу через vllm. Это еще не проверено. После беглого просмотра кода теоретически существует проблема:
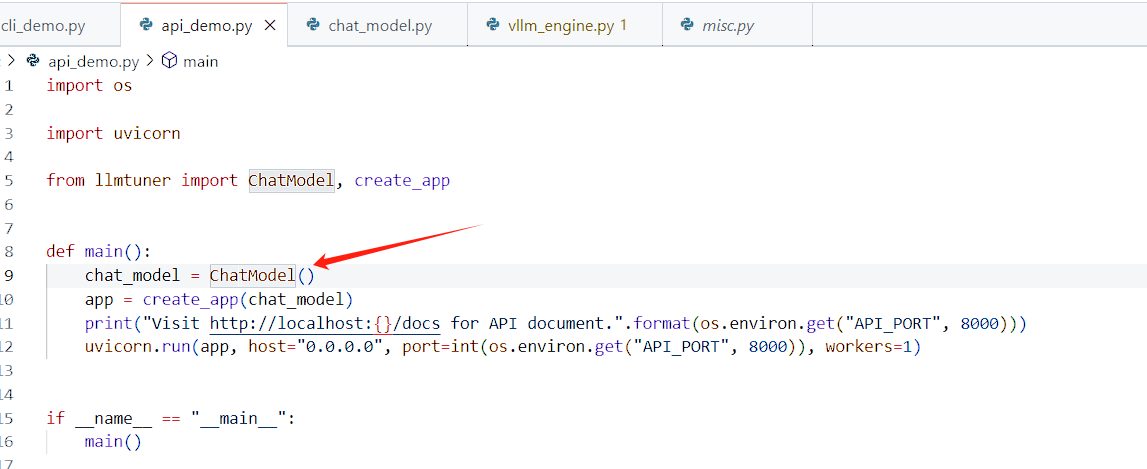
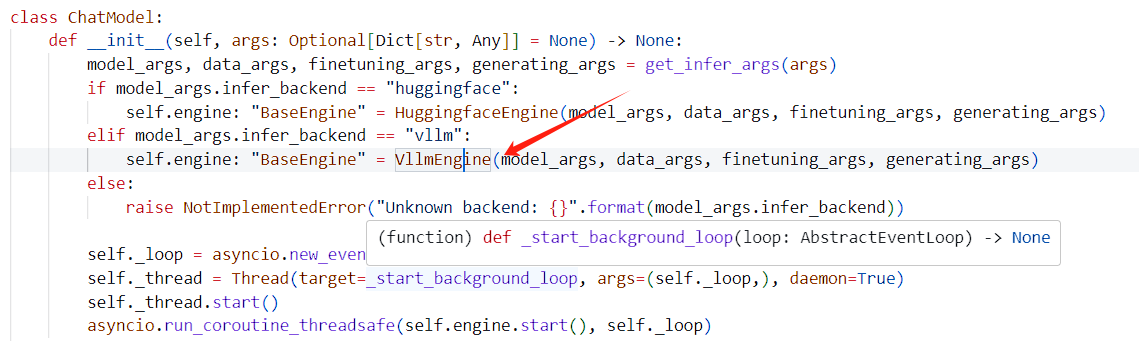
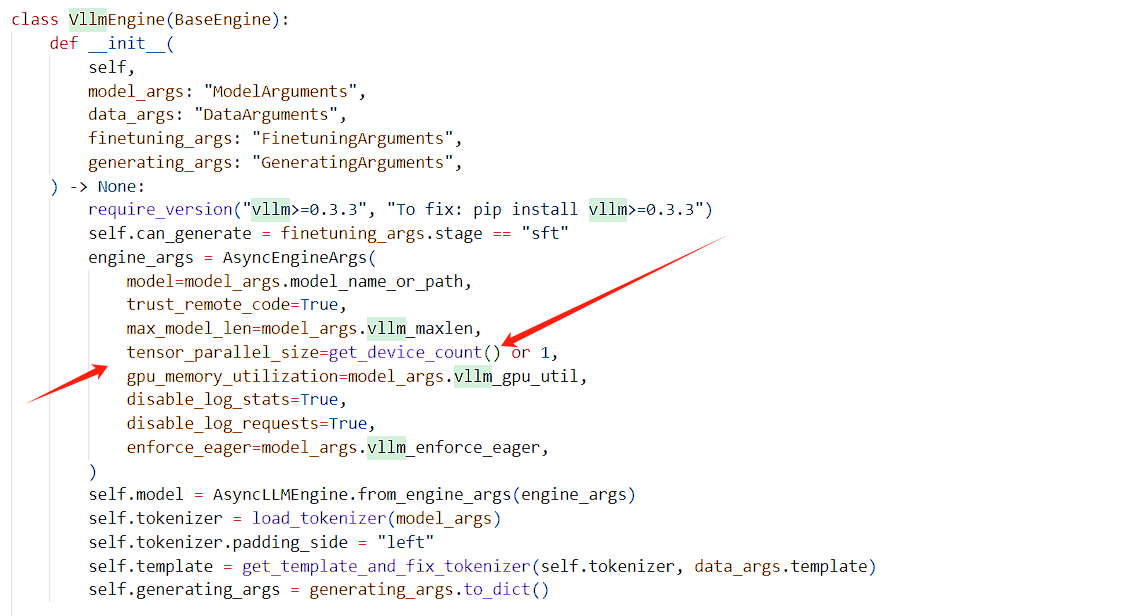
Пожалуйста, указывайте источник при перепечатке:https://www.cnblogs.com/zhiyong-ITNote



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
