Давайте поговорим о потоковой передаче данных на озере Паймон (3)
Обзор
Если для таблицы не определен первичный ключ, по умолчанию она имеет тип «Только добавление таблицы». Согласно определению Bucket, у нас есть два разных режима только для добавления: «Добавить к масштабируемой таблице» и «Добавить к очереди». Эти два режима поддерживают разные сценарии и предоставляют разные функции. В таблицу можно вставить только одну полную запись. Удаление или обновление не поддерживается, а первичные ключи невозможно определить. Этот тип таблицы подходит для случаев использования, не требующих обновлений (например, синхронизации данных журналов).
Сценарии добавления конкретно относятся к сценариям без первичного ключа, таким как запись данных журнала, которые не имеют возможности напрямую обновлять обновления.
Append For Scalable Table
Его поддерживаемые функции следующие:
- Поддержка пакетного чтения и пакетной записи INSERT OVERWRITE
- Поддерживает потоковое чтение и запись, автоматическое объединение небольших файлов.
- Поддержка функций хранилища Lake, ACID, Time Travel
- сортировка по порядку и z-порядку
Definition
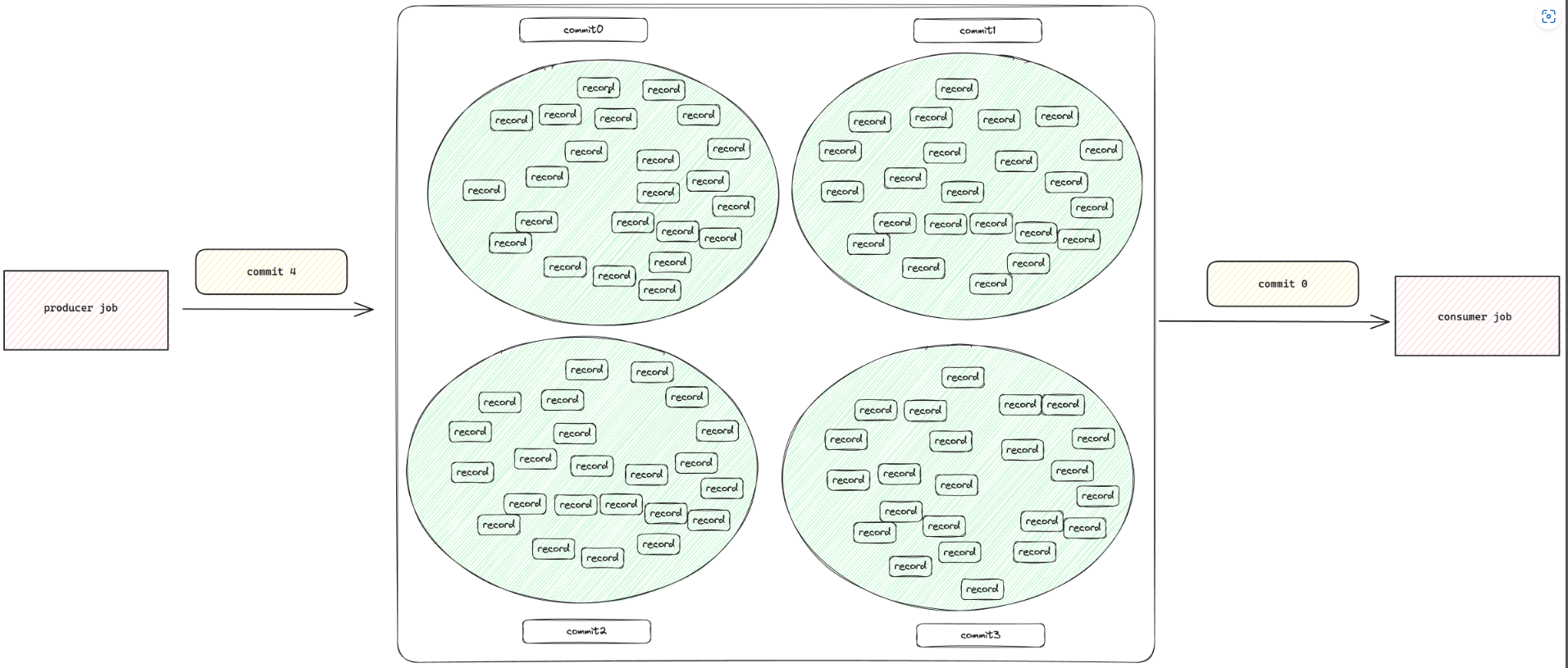
Определив в свойствах таблицы 'bucket' = '-1',Этой таблице можно назначить специальную схему(мы называем это"unaware-bucket модель"). В этом режиме все по-другому. У нас больше нет концепции сегментов, и мы не гарантируем порядок потокового чтения. Мы рассматриваем эту таблицу как пакетную автономную таблицу (хотя мы по-прежнему можем осуществлять потоковые операции чтения и записи). Все записи попадают в один каталог (мы помещаем их в ведро-0 для совместимости), и порядок уже не поддерживаем. Поскольку у нас нет понятия сегментов, мы больше не будем перемешивать входные записи по сегментам, что ускорит вставку.
Используя этот режим, вы можете Hive стол заменен на Lake поверхность.
Compaction
В режиме неосведомленного сегмента мы не выполняем сжатие в модуле записи, а используем Compact координатор для сканирования небольших файлов и отправки задачи сжатия в Compact Worker. Таким образом, мы можем легко выполнить параллельное сжатие простого каталога данных. В потоковом режиме, если вы запустите вставку sql во flink, топология будет такой:
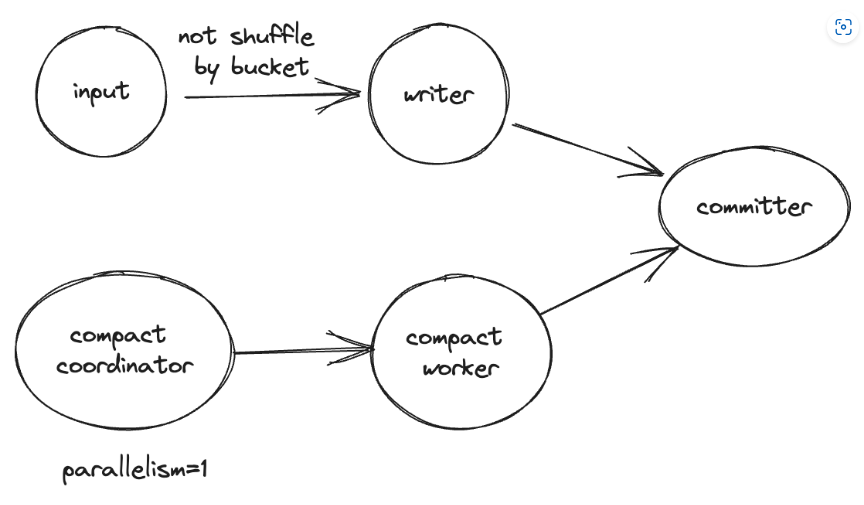
Он делает все возможное для сжатия небольших файлов, но если один небольшой файл остается в разделе в течение длительного времени и в раздел не добавляются новые файлы, координатор сжатия удаляет его из памяти, чтобы уменьшить использование памяти. После перезапуска задания оно сканирует небольшие файлы и снова добавляет их в память. Параметры, управляющие поведением сжатия, точно такие же, как и для параметра «Добавить к очереди». Если для параметра «только запись» установлено значение true, компактные координаторы и компактные рабочие процессы удаляются из топологии. Автоматическое сжатие поддерживается только в режиме потоковой передачи Flink Engine. Также можно запустить задание сжатия в flink с помощью операции flink в paimon и отключить все остальные сжатия, установив режим «только для записи».
Sort Compact
Неупорядоченные данные в каждом разделе могут привести к медленному выбору, а сжатие может замедлить вставку. Рекомендуется установить для задания вставки режим «только запись» и запускать операцию сжатия сортировки разделов после завершения сбора данных для каждого раздела.
Streaming Source
Режим «неосознанного ведра» Append Only Table поддерживатьПотоковое чтение и письмо,Но порядок уже не гарантирован. Вы не можете думать об этом как об очереди, а как об озере с мусорными баками. Каждая подача будет генерировать новую запись хранилища binbin. чтобы прочитать приращение, но bin Записи будут перетекать куда захотят, и мы получим их в любом возможном порядке. в Добавить For В режиме очереди записи сохраняются не в корзине, а в записи. в трубе. Записывать хранилище, мы можем прочитать новое изхранилище Записать чтобы прочитать приращение, но bin Записи будут перетекать куда захотят, и мы получим их в любом возможном порядке. в Добавить For В режиме очереди записи сохраняются не в корзине, а в записи. в трубе.
бункер: ящик для хранения
Streaming Multiple Partitions Write
Потому что количество задач записи, которые должен обрабатывать Paimon-sink, равно: количество разделов, в которые записываются данные * количество сегментов в каждом разделе. Поэтому нам нужно постараться контролировать количество задач записи для каждой задачи paimon-sink, чтобы они распределялись в разумных пределах. Если каждая задача приемника обрабатывает слишком много задач записи, это не только вызовет проблему слишком большого количества маленьких файлов, но также может вызвать ошибки нехватки памяти. Кроме того, ошибка записи приведет к появлению потерянных файлов, что, несомненно, увеличивает стоимость поддержки paimon. Нам нужно максимально избегать этой проблемы. Для заданий flink с включенным автоматическим слиянием мы рекомендуем попытаться настроить параллелизм paimon-sink в соответствии со следующей формулой (это применимо не только к таблицам, предназначенным только для добавления, но и к большинству сценариев):
(N*B)/P < 100 (This value needs to be adjusted according to the actual situation)
N(the number of partitions to which the data is written)
B(bucket number)
P(parallelism of paimon-sink)
100 (This is an empirically derived threshold,For flink-jobs with auto-merge disabled, this value can be reduced.
However, please note that you are only transferring part of the work to the user-compaction-job, you still have to deal with the problem in essence,
the amount of work you have to deal with has not been reduced, and the user-compaction-job still needs to be adjusted according to the above formula.)Вы также можете write-buffer-spillable установлен на true,writer Может пролиться Запись на диск. Это максимально уменьшает размер небольших файлов. Чтобы использовать эту опцию, flink Для кластера требуется локальный диск определенного размера. Это для тех, кто в k8s Использовать на flink особенно важно для людей.
Для таблиц, доступных только для добавления, вы можете установить write-buffer-for-append параметры. Установите этот параметр установленным правда, писатель будет использовать Segment Кэши пула Записываются, чтобы избежать OOM.
Example
Ниже приведен пример создания таблицы, доступной только для добавления, и указания ключа сегмента.
CREATE TABLE MyTable (
product_id BIGINT,
price DOUBLE,
sales BIGINT
) WITH (
'bucket' = '-1'
);Append For Queue
Его поддерживаемые функции следующие:
- Строго гарантируем заказ и можем привести к очереди сообщений
- Поддержка водяных знаков и выравнивания
- Автоматически объединять небольшие файлы
- Поддержка Consumer-ID (аналогично Group-ID)
Definition
В этом режиме только добавление Таблица рассматривается как очередь, разделенная сегментами. Каждая Запись в одном и том же сегменте строго сортируется, и потоковое чтение будет передавать Запись в нисходящий поток строго в порядке записи. используйте этот режим,Никакой специальной настройки не требуется,вседанныебудет поставлен в очередьизсформировать ведро。также можно определитьbucketиbucket-keyдобиться большегоиз Параллелизмидисперсияданные。
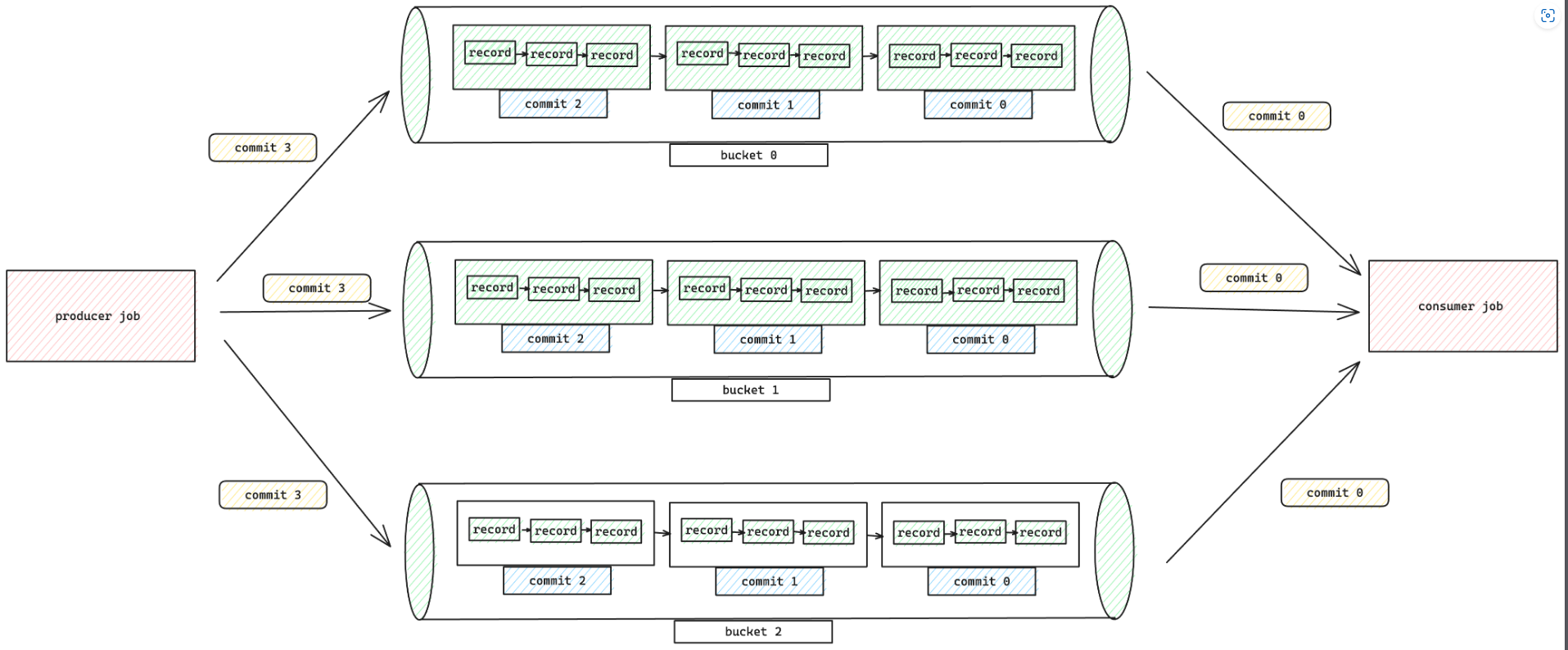
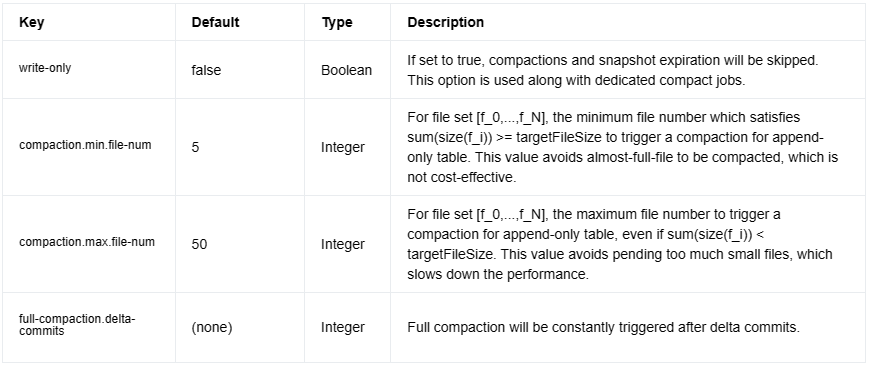
Compaction
По умолчанию узел-приемник автоматически выполняет сжатие, чтобы контролировать количество файлов. Следующие параметры управляют стратегией сжатия:
Streaming Source
В настоящее время только движок Flink поддерживает поведение источника потоковой передачи.
Streaming Read Order
Для потокового чтения Запись генерируется в следующем порядке:
- Для любых двух Запись с двух разных разделов из
- если для scan.plan-sort-partition установлено значение true, то сначала из Записывания будет сгенерировано значение раздела с меньшим значением.
- в противном случае,Время создания раздела будет сгенерировано ранее из Записания.
- Для любых двух Записей из одного раздела и одной ведра первой будет записана первая.
- Для любых двух Записей из одного раздела, но из двух разных сегментов,Разные сегменты обрабатываются разными задачами.,Между ними нет никаких гарантий порядка.
Watermark Definition
Определим водяной знак для чтения таблицы Paimon:
CREATE TABLE T (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);
-- launch a bounded streaming job to read paimon_table
SELECT window_start, window_end, COUNT(`user`) FROM TABLE(
TUMBLE(TABLE T, DESCRIPTOR(order_time), INTERVAL '10' MINUTES)) GROUP BY window_start, window_end;Вы также можете включить выравнивание водяных знаков Flink, что гарантирует, что ни один источник/разделение/осколок/раздел не увеличит свой водяной знак намного больше, чем остальные:

Bounded Stream
Streaming Source Его также можно ограничить, задав scan.bounded.watermark Чтобы определить конечное условие режима ограниченного потока, чтение потока будет прекращено до тех пор, пока не будет достигнуто большее значение. watermark Снимок.
водяной знак на снимке генерируется автором, например, указывая источник Kafka и объявляя водяной знак определение. Когда этот источник Kafka используется для записи в таблицу Paimon, снимок таблицы Paimon генерирует соответствующий водяной знак, так что функциональность ограниченных водяных знаков можно использовать при потоковой передаче этой таблицы Paimon.
CREATE TABLE kafka_table (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka'...);
-- launch a streaming insert job
INSERT INTO paimon_table SELECT * FROM kakfa_table;
-- launch a bounded streaming job to read paimon_table
SELECT * FROM paimon_table /*+ OPTIONS('scan.bounded.watermark'='...') */;Example
Ниже приведен пример создания таблицы, доступной только для добавления, и указания ключа сегмента.
CREATE TABLE MyTable (
product_id BIGINT,
price DOUBLE,
sales BIGINT
) WITH (
'bucket' = '8',
'bucket-key' = 'product_id'
);ссылка
на основе Apache Paimon из Append обработка таблицы Apache Paimon озеро данных в реальном времени Streaming Lakehouse склад База



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
