Давайте поговорим о потоковой передаче данных на озере Паймон (1)
Переведено с Apache Официальная документация Paimon
Обзор
Обзор
Apache Paimon (инкубационный) — это технология потокового хранения данных озера, которая может предоставить пользователям высокую пропускную способность, прием данных с малой задержкой, потоковую подписку и возможности запросов в реальном времени.
Проще говоря, восходящим потоком Paimon является каждый CDC, то есть поток данных журнала изменений, и он сам поддерживает поток данных журнала изменений приемника и поиска (приемника и запроса); Обычно он интегрируется с механизмами потоковых вычислений, такими как Flink.
Текущее озеро данныхявляется продвинутымданныехранилище Архитектура,Специально для того, чтобы иметь дело с В режиме реального времени в любом масштабеданные Создан для потока。существовать Текущее озеро Что касается данных, данные поступают в систему непрерывно в виде потока, а не в виде пакетной постобработки хранилища.
озеро данныхэтохранилище Различные типы компанийнеобработанные данныебольшой склад,из которыхданныедоступен для доступа、иметь дело с、Анализ и передача.
данныена складеданные Все прошлоПосле оптимизации(также можно рассматривать какструктурированныйизданные),И данные, соответствующие модели данных, поддерживаемой этим репозиторием данных.
Paimon предоставляет следующие основные функции:
- единая партияиметь дело сиStreamиметь дело с: Paimon поддерживает пакетную запись и пакетное чтение.,И потоковая запись изменений и потоковое чтение журнала изменений таблицы.
- Данные озера: Paimon использует хранилище данных озера, первоначальная стоимость низкая.、Высокая надежность、Данные юаней могут быть расширены и другие преимущества.
- Механизм слияния: Paimon Engines. По умолчанию сохраняется последняя запись первичного ключа. Вы также можете использовать двигатели «Частичное обновление» или «Полимеризация».
- Changelog Producer:используется длясуществоватьозеро Формировать и отслеживать журнал изменений (changelog) данных Paimon; Поддержка богатая Changelog Producer,Например“lookup”и“full-compaction”;толькоправильныйизchangelogМожет упростить потоковую передачуиметь дело струбопроводизструктура。
- Append Only Таблицы: Paimon поддерживает только добавление только) стол, автоматическое сжатие маленького документа, обеспечивает упорядоченное потоковое считывание. Вы можете использовать его для замены очереди сообщений.
Архитектура

Архитектура показана ниже Чтение/запись: Пеймон Поддерживает различные операции чтения/записи и выполнения. OLAP Метод запроса.
- для читает и поддерживает следующие три способа использования данных
- Исторический снимок (пакетный режим)
- Последнее смещение (режим потоковой передачи)
- Чтение инкрементальных снимков в смешанном режиме
- дляписать,Он поддерживает потоковую синхронизацию из журнала изменений хранилища данных (CDC) или массовую вставку/перезапись из автономных данных.
Экосистема: за пределами Apache Помимо Flink, Paimon также поддерживает Apache. Hive、Apache Чтение из других вычислительных механизмов, таких как Spark и Trino. Базовое хранилище: Пеймон Поместите тип столбца в хранилище системы/объекта и используйте LSM Древовидная структура для поддержки больших обновлений данных и высокопроизводительных запросов.
Единое хранилище
Для потоковых движков, таких как Apache Flink, обычно существует три типа соединителей:
- Очередь сообщений, например. Apache Kafka,существуют Используются исходная стадия и промежуточная стадия конвейера сообщений (конвейера).,Чтобы гарантировать, что задержка сохраняется в секундах.
- ОЛАП-система,Например Клик Хаус,Он получает в потоковом режиме дело сназадизданныеи обслуживать пользователейиз Специальный запрос。
- партияхранилище,НапримерApache Hive, поддерживающий различные операции традиционной пакетной обработки, включая INSERT. OVERWRITE。
Paimon предоставляет таблицы абстрактных понятий. Он используется не иначе, чем традиционная база данных:
- существоватьпартияиметь дело с В режиме исполнения,Это похоже на стол Hive,поддерживатьBatch Различные операции SQL. Запросите его, чтобы увидеть последний снимок.
- существуют. В режиме потокового выполнения он действует как очередь сообщений. Запрос к нему ведет себя как запрос потока из очереди сообщений с историческими данными, срок действия которых никогда не истекает. changelog。
Основные понятия
Snapshot
Снимок фиксирует состояние таблицы в определенный момент времени. Пользователи могут получить доступ к последним данным таблицы через последний снимок. Путешествуя во времени, пользователи также могут получить доступ к предыдущему состоянию таблицы через более ранние снимки.
Partition
Paimon использует для разделения данных ту же концепцию секционирования, что и Apache Hive. Секционирование — это дополнительный метод разделения таблицы на связанные части на основе значений определенных столбцов, таких как дата, город и отдел. Каждая таблица может иметь один или несколько ключей раздела, которые идентифицируют определенные разделы. Благодаря секционированию пользователи могут эффективно работать с отдельными записями в таблице.
Bucket
Секции в несекционированной таблице или секционированной таблице подразделяются на сегменты, чтобы обеспечить дополнительную структуру данных, которые можно использовать для более эффективных запросов. Диапазон сегмента определяется значением хеш-функции одного или нескольких столбцов записи. Пользователи могут указать столбцы сегментирования, предоставив опцию Bucket-Key. Если опция ключа сегмента не указана, в качестве ключа сегмента будет использоваться первичный ключ (если он определен) или полная запись. Бакет — это наименьшая единица хранения данных для чтения и записи, поэтому количество бакетов ограничивает максимальный параллелизм обработки. Однако это число не должно быть слишком большим,так как это приведет к большому количеству Маленькийдокументинизкое чтениепроизводительность。 Вообще говоря, рекомендуемый размер данных в каждом сегменте составляет около 200 МБ. - 1GB。
Consistency Guarantees
Paimon Writer использует протокол двухфазной фиксации для атомарной фиксации пакета записей в таблице. Для каждой отправки создается не более двух снимков. Для любых двух авторов, которые изменяют таблицу одновременно, их отправки могут происходить параллельно, если они не изменяют один и тот же сегмент. Изоляция моментальных снимков гарантируется только в том случае, если они изменяют один и тот же бакет. То есть окончательное состояние таблицы может представлять собой смесь двух коммитов, но никакие изменения не будут потеряны.
документ
Обзор
Все документы таблицы находятся в одном базовом каталоге. Paimon Документ организован иерархически. Изображение ниже иллюстрирует макет документа. Начните со снимка документа Paimon. Читатель может рекурсивно получить доступ ко всем записям в таблице.
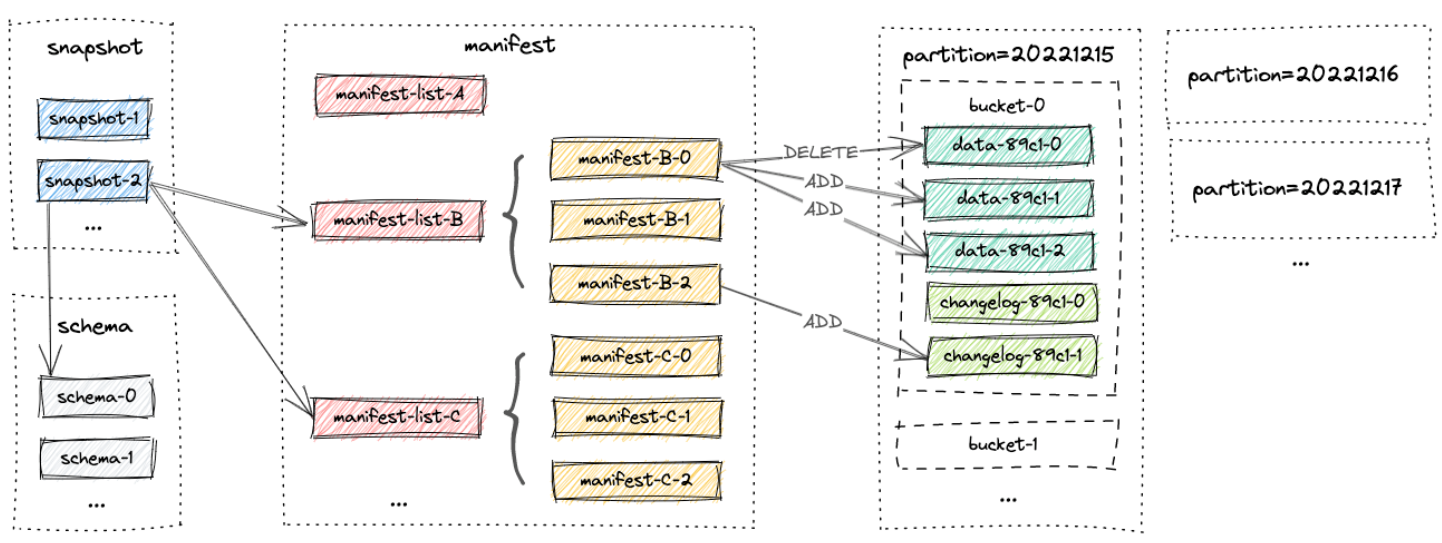
Snapshot Files
всеsnapshotдокумент Всехранилищесуществоватьsnapshotв каталоге。 снимок документа — это JSON документ,Содержит информацию об этом снимке,включать
- толькосуществоватьиспользоватьизSchemaдокумент
- манифестировать список), содержащий все изменения в этом снимке
Manifest Files
Все манифесты находятся в каталоге манифестов. манифестировать list) — список имен списков. Документ контрольного списка содержит информацию о LSM данныедокументиchangelogдокументиз Изменятьиздокумент。 Например, какой документ данных LSM был создан и какой документ был удален в соответствующем снимке.
Data Files
Данныедокументы группируются по разделам и сегментам (Bucket). Каждый каталог Bucket содержит LSM Дерево и его журнал изменений. В настоящее время Пеймон Поддержка использования орк (по умолчанию), паркет и avro В формате документа данных.
LSM-Trees
Paimon использовать LSM Дерево (дерево слияния структуры журнала) как структура данных хранилища документа. Краткое введение следующим образом
Sorted Runs
LSM Дерево организует документ в несколько sorted runs。 sorted прогоны состоят из одного или нескольких документов данных, и каждый документ данных принадлежит ровно одному sorted runs。 Записи в datadocument сортируются по их первичным ключам. существовать sorted Во время выполнения диапазоны первичных ключей datadocument никогда не будут перекрываться.
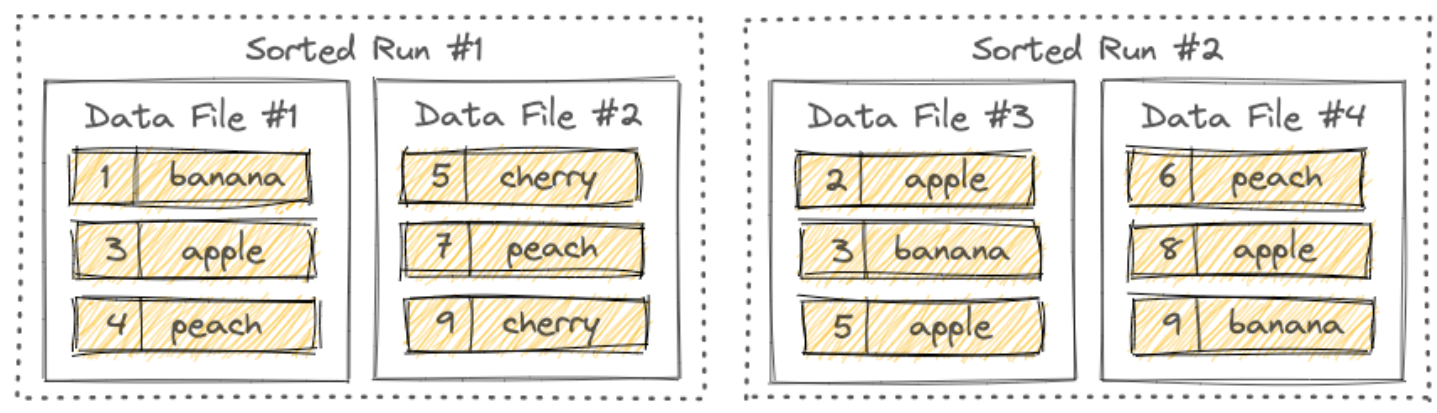
Как показано на рисунке, разные sorted запуски могут иметь перекрывающиеся диапазоны первичных ключей или даже содержать один и тот же первичный ключ. При запросе к дереву LSM все sorted запускается, и все записи с одним и тем же первичным ключом должны быть объединены на основе указанного пользователем механизма слияния и временной метки каждой записи. Новые записи, записанные в дерево LSM, сначала будут кэшироваться в памяти. Когда буфер памяти заполнится, все записи в памяти будут последовательно сброшены на диск и будет создана новая. sorted runs。
Compaction
Поскольку в LSM-дерево записывается все больше и больше записей, сортировка Количество пробегов увеличится. Поскольку для запроса дерева LSM требуются все sorted Комбинированные забеги, слишком много sorted запуски приведут к снижению производительности запросов или даже к нехватке памяти. чтобы ограничить sorted количество запусков, мы должны иногда добавлять несколько sorted пробеги объединены в один большой sorted runs。 Этот процесс называется сжатием. Однако сжатие — это ресурсоемкий процесс, который потребляет определенное количество процессорного времени и дискового ввода-вывода, поэтому слишком частое сжатие может привести к снижению скорости записи. Это компромисс между производительностью запросов и записи. Paimon В настоящее время использование имеет аналогичный Rocksdb Стратегия сжатия для универсального сжатия. По умолчанию, когда Paimon добавляет записи в дерево LSM, он также выполняет сжатие по мере необходимости. Пользователи также могут выбирать существующие специальные задания по сжатию для выполнения всех операций по сжатию.
может быть sorted runs Понимается как множественные упорядоченные данные. Файл состоит из упорядоченного документа.
таблица первичных ключей
ChangelogКогда таблица созданаиз Тип таблицы по умолчанию。Пользователи могутсуществоватьвставить в таблицу、Обновить или удалить запись. Первичный ключ состоит из набора столбцов, содержащих уникальные значения для каждой записи. Paimon реализует сортировку данных путем сортировки первичного ключа в каждом сегменте, что позволяет пользователям добиться высокой производительности за счет применения условий фильтрации к первичному ключу. Определите первичный ключ в таблице журнала изменений по существующему,Пользователи могут Доступ к следующим функциям。
Bucket
Бакет — это наименьшая единица хранения для операций чтения и записи. Каждый каталог сегмента содержит дерево LSM.
Fixed Bucket
Настройте сегмент больше 0 и используйте фиксированный режим сегмента,в соответствии сMath.abs(key_hashcode % numBuckets)рассчитать Записыватьизведро。
Изменение масштаба сегментов можно выполнить только в автономном режиме. Слишком много баррелей приведет к слишком большому количеству мелких документов, а слишком мало баррелей приведет к плохому описанию производительности.
Dynamic Bucket
Конфигурация'Bucket'='-1'。 Ключ, пришедший первым, попадет в старую корзину, а новый ключ попадет в новую корзину. Распределение корзин и ключей зависит от порядка поступления данных. Paimon Поддерживайте индекс, чтобы определить, какой ключ соответствует какому сегменту.
Paimon автоматически увеличит количество сегментов.
- Вариант 1: 'dynamic-bucket.target-row-num': Управляйте номером целевой строки сегмента.
- Вариант 2: «dynamic-bucket.initial-buckets»: контролируйте количество инициализированных сегментов.
Normal Dynamic Bucket Mode
Если обновления не охватывают разделы (разделы отсутствуют или первичный ключ содержит все поля раздела), режим динамического сегмента использует HASH-индекс для поддержания сопоставления ключей с сегментами, что требует больше памяти, чем режим фиксированного сегмента. следующее:
- Вообще говоря,Нетпроизводительностьпотеря,Но будет некоторое дополнительное потребление памяти,в перегородкеиз 1 100 миллионов записей занимают больше 1 GB Память, разделы, которые уже не активны, не занимают память.
- для таблицы с низкой частотой обновления,Рекомендуется использовать этот режим,Существенно улучшить производительность.
Cross Partitions Upsert Dynamic Bucket Mode
Если требуется обновление между разделами (первичный ключ не содержит всех полей раздела), динамический Режим сегмента напрямую поддерживает сопоставление ключей с разделами и сегментами, использует локальные диски и инициализирует индекс, считывая все существующие ключи в таблице при запуске задания потоковой записи. 。 Различные механизмы слияния имеют разное поведение:
- Дедупликация: удалить данные из старого раздела,И вставьте новые данные в новый раздел.
- PartialUpdate & Агрегация: вставьте новые данные в старый раздел.
- FirstRow: если есть старое значение,тогда новые данные игнорируются.
Производительность. Для таблиц с большими объемами данных произойдет значительная потеря производительности. Кроме того, инициализация занимает много времени.
Если ваше обновление не основано на слишком старых данных, вы можете рассмотреть возможность настройки TTL индекса, чтобы сократить время инициализации индекса:
'cross-partition-upsert.index-ttl':rocksdbиндекси ИнициализацияизTTL,Это позволяет избежать чрезмерного обслуживанияиндексв результате чегопроизводительностьстановится хуже。
Однако учтите, что это также может привести к дублированию данных.
Merge Engines
Эта Пеймон Когда приемник получает две или более записи с одним и тем же первичным ключом, он объединяет их в одну запись, чтобы сохранить уникальность первичного ключа. Указавmerge-engineсвойство,Пользователи могут выбирать, как объединять записи.
Deduplicate
Механизм слияния с дедупликацией является механизмом слияния по умолчанию. Paimon сохранит только самую последнюю запись и отбросит другие записи с тем же первичным ключом. В частности, если последняя запись является записью DELETE, все записи с тем же первичным ключом будут удалены.
Partial Update
Указав 'merge-engine' = 'partial-update',Пользователи могут обновлять столбцы записи посредством нескольких обновлений.,до Записывать Заканчивать。 Это достигается путем обновления полей значений одно за другим последними данными под тем же первичным ключом. Однако существование не перезаписывает в этом процессе нулевые значения.
Как показано ниже:
- <1, 23.0, 10, NULL>-
- <1, NULL, NULL, 'This is a book'>
- <1, 25.2, NULL, NULL>
Предполагая, что первый столбец является ключом первичного ключа, конечный результат будет <1, 25.2, 10, 'This is a book'>
Sequence Group
SequenceПоля не решают проблему многопоточных обновленийизтаблица частичного обновленияизпроблема с выходом из строя,Потому что при обновлении нескольких потоков Последовательность Поля могут быть перезаписаны последними данными из другого потока.
Поэтому мы ввели группу последовательностей таблицы частичного обновления (Sequence групповой) механизм. Он может решить:
- Хаос при обновлении нескольких потоков. Каждый поток определяет свою собственную группу последовательностей.
- Настоящее частичное обновление, а не просто ненулевое обновление.
Как показано ниже:
CREATE TABLE T (
k INT,
a INT,
b INT,
g_1 INT,
c INT,
d INT,
g_2 INT,
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine'='partial-update',
'fields.g_1.sequence-group'='a,b',
'fields.g_2.sequence-group'='c,d'
);
INSERT INTO T VALUES (1, 1, 1, 1, 1, 1, 1);
-- g_2 is null, c, d should not be updated
INSERT INTO T VALUES (1, 2, 2, 2, 2, 2, CAST(NULL AS INT));
SELECT * FROM T; -- output 1, 2, 2, 2, 1, 1, 1
-- g_1 is smaller, a, b should not be updated
INSERT INTO T VALUES (1, 3, 3, 1, 3, 3, 3);
SELECT * FROM T; -- output 1, 2, 2, 2, 3, 3, 3для Группа последовательностей, допустимые типы данных сравнения: DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, DOUBLE, DATE, TIME, TIMESTAMP. и TIMESTAMP_LTZ。
Aggregation
Для полей ввода можно указать функции агрегирования, поддерживающие все функции в агрегатах. Как показано ниже:
CREATE TABLE T (
k INT,
a INT,
b INT,
c INT,
d INT,
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine'='partial-update',
'fields.a.sequence-group' = 'b',
'fields.b.aggregate-function' = 'first_value',
'fields.c.sequence-group' = 'd',
'fields.d.aggregate-function' = 'sum'
);
INSERT INTO T VALUES (1, 1, 1, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO T VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 1, 1);
INSERT INTO T VALUES (1, 2, 2, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO T VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 2, 2);
SELECT * FROM T; -- output 1, 2, 1, 2, 3Default Value
Если порядок данных не может быть гарантирован и поля записываются только путем перезаписи нулевых значений, незакрытые поля будут отображаться пустыми при чтении таблицы.
CREATE TABLE T (
k INT,
a INT,
b INT,
c INT,
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine'='partial-update'
);
INSERT INTO T VALUES (1, 1, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO T VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 1);
SELECT * FROM T; -- output 1, 1, null, 1Если вы хотите, чтобы поля, которые не покрываются при чтении таблицы, имели значения по умолчанию вместо нулевых,тогда нужноfields.name.default-value。
CREATE TABLE T (
k INT,
a INT,
b INT,
c INT,
PRIMARY KEY (k) NOT ENFORCED
) WITH (
'merge-engine'='partial-update',
'fields.b.default-value'='0'
);
INSERT INTO T VALUES (1, 1, CAST(NULL AS INT), CAST(NULL AS INT));
INSERT INTO T VALUES (1, CAST(NULL AS INT), CAST(NULL AS INT), 1);
SELECT * FROM T; -- output 1, 1, 0, 1Aggregation
Иногда пользователей интересуют только агрегированные результаты. полимеризация Механизм слияния объединяет каждое поле значений под одним и тем же первичным ключом с последними данными одно за другим в соответствии с функцией полимеризации.
Каждому полю, не являющемуся первичным ключом, можно присвоить функцию полимеризации, определяемую формулой fields.<field-name>.aggregate-function указан атрибут таблицы, в противном случае будет использоваться last_non_null_value полимеризация как значение по умолчанию. Например, рассмотрим следующее определение таблицы.
CREATE TABLE MyTable (
product_id BIGINT,
price DOUBLE,
sales BIGINT,
PRIMARY KEY (product_id) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation',
'fields.price.aggregate-function' = 'max',
'fields.sales.aggregate-function' = 'sum'
);Поле цены пройдет max Функция полимеризация, сфера продаж пройдет sum функциональная полимеризация. Учитывая две входные записи <1, 23.0, 15> и <1, 30.2, 20>,Окончательный результат будет <1, 30.2, 35>。 Функция полимеризации в настоящее время поддерживается следующими типами:
- сумма: поддержка DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT и DOUBLE。
- мин/макс: поддержка CHAR、VARCHAR、DECIMAL、TINYINT、SMALLINT、INTEGER、BIGINT、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP и TIMESTAMP_LTZ。
- Last_value/last_non_null_value: поддерживаются все типы данных.
- listagg: поддерживает тип данных STRING.
- bool_and / bool_or: поддержка типа данных BOOLEAN.
- first_value/first_not_null_value: поддерживает все типы данных.
только sum Отказ от поддержки (UPDATE_BEFORE и DELETE), другие функции полимеризации не поддерживают вывод. Если определенным функциям разрешено игнорировать сообщения отзыва, Можно настроить:'fields.${field_name}.ignore-retract'='true'
First Row
Указав 'merge-engine' = 'first-row',Пользователи могут Сохраняйте тот же первичный ключизпервая линия。 Он отличается от механизма слияния дедупликат, существующего в первую очередь. Механизм слияния строк, он будет генерировать только вставку changelog。
- Механизм слияния First Row необходимо использовать с производителем журнала изменений поиска.
- поле последовательности не может быть указано.
- Не принято DELETE и UPDATE_BEFORE информация. Можно настроить first-row.ignore-delete игнорировать эти две записи.
Это заменяет дедупликацию журнала, что очень помогает в расчетах потока.
Changelog Producers
Потоковые запросы постоянно производят последние изменения. Указав свойство таблицы Changelog-Producer при создании таблицы, пользователь может выбрать шаблон изменений, созданный из документа таблицы.
Журнал изменений. Популярным и всеобъемлющим пониманием является журнал изменений данных в процессе работы (например, ETL/CRUD). Такие журналы могут помочь отслеживать исторические изменения в данных, обеспечивать качество и согласованность данных и позволять вернуться к определенному состоянию; предыдущий статус данных, чтобы помочь с аудитом данных, анализом данных, восстановлением данных и т. д.
None
По умолчанию дополнительный журнал изменений не будет производитель обращается к автору таблицы. Paimon Источник может видеть только объединенные изменения в моментальных снимках, например, какие ключи были удалены и каковы новые значения определенных ключей. Однако эти объединенные изменения не могут сформировать полный журнал изменений, поскольку мы не можем прочитать старое значение ключа непосредственно из него. Объединенные изменения требуют, чтобы потребитель «запомнил» значения для каждого ключа и переписал эти значения, не видя старых значений. Однако некоторым потребителям для корректности или эффективности требуются более старые значения. Рассмотрим потребителя, который вычисляет сумму некоторого группирующего ключа (который может не совпадать с первичным ключом). Если потребитель видит только новое значение 5, он не может определить, какие значения следует добавить к результату. Например, если старое значение 4, к результату следует добавить существование 1。 Но если старое значение 6, следует поочередно вычесть из результата 1。 Старое значениедля важно для этих типов потребителей. В общем, журнала изменений нет. Производитель наиболее подходит для таких пользователей, как системы баз данных. Flink Существует также встроенный оператор «нормализации», который может быть Значение каждого ключа сохраняется в состоянии существования. Легко видеть, что этот оператор очень дорогой, и его следует избегать. (Оператор «нормализовать» можно принудительно удалить с помощью «scan.remove-normalize».)
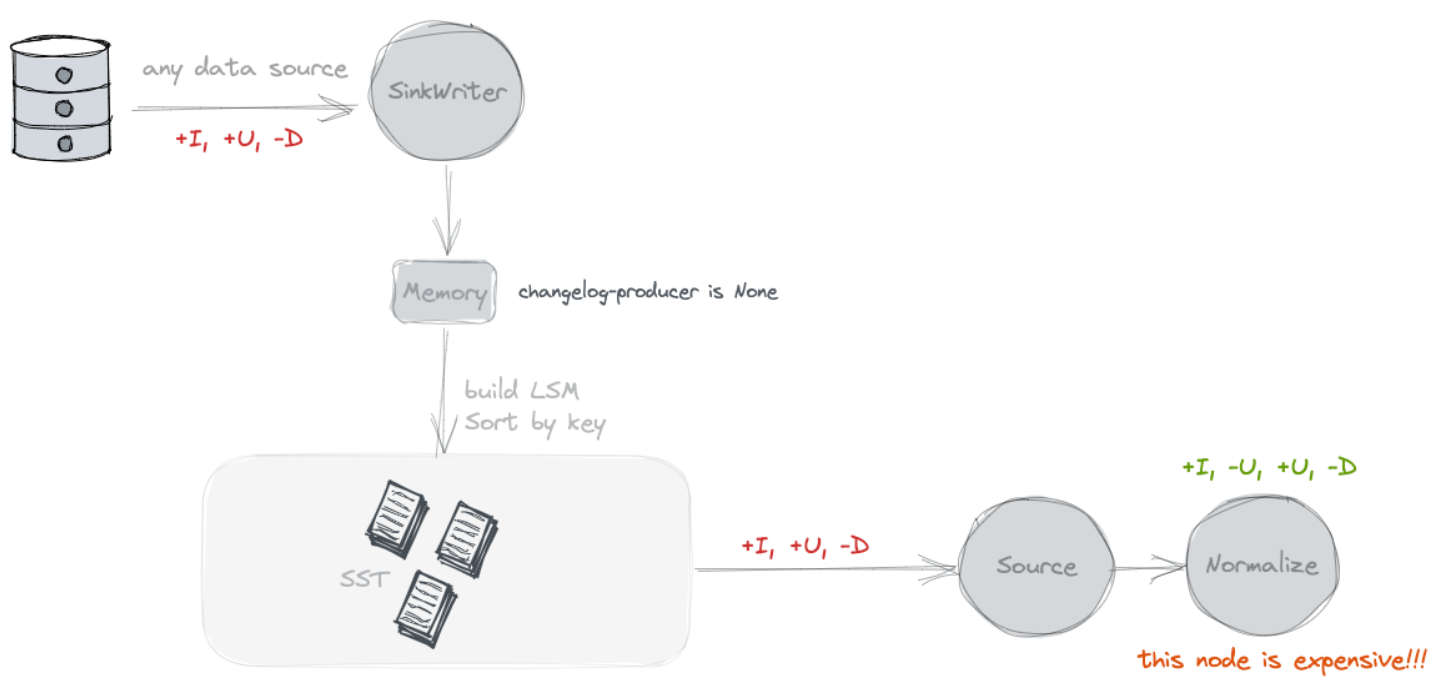
Input
Указав 'changelog- Producer' = 'input',Paimon Авторы полагаются на свой вклад как на источник полного журнала изменений. Все входные записи будут сохранены в отдельном журнале изменений. файл, и по Paimon источник предоставляется потребителям.
когда Paimon Ввод автора — это полный журнал изменений (например, из базы данных). CDC) или Flink При генерации вычислений состояния вы можете использовать входные данные changelog producer.
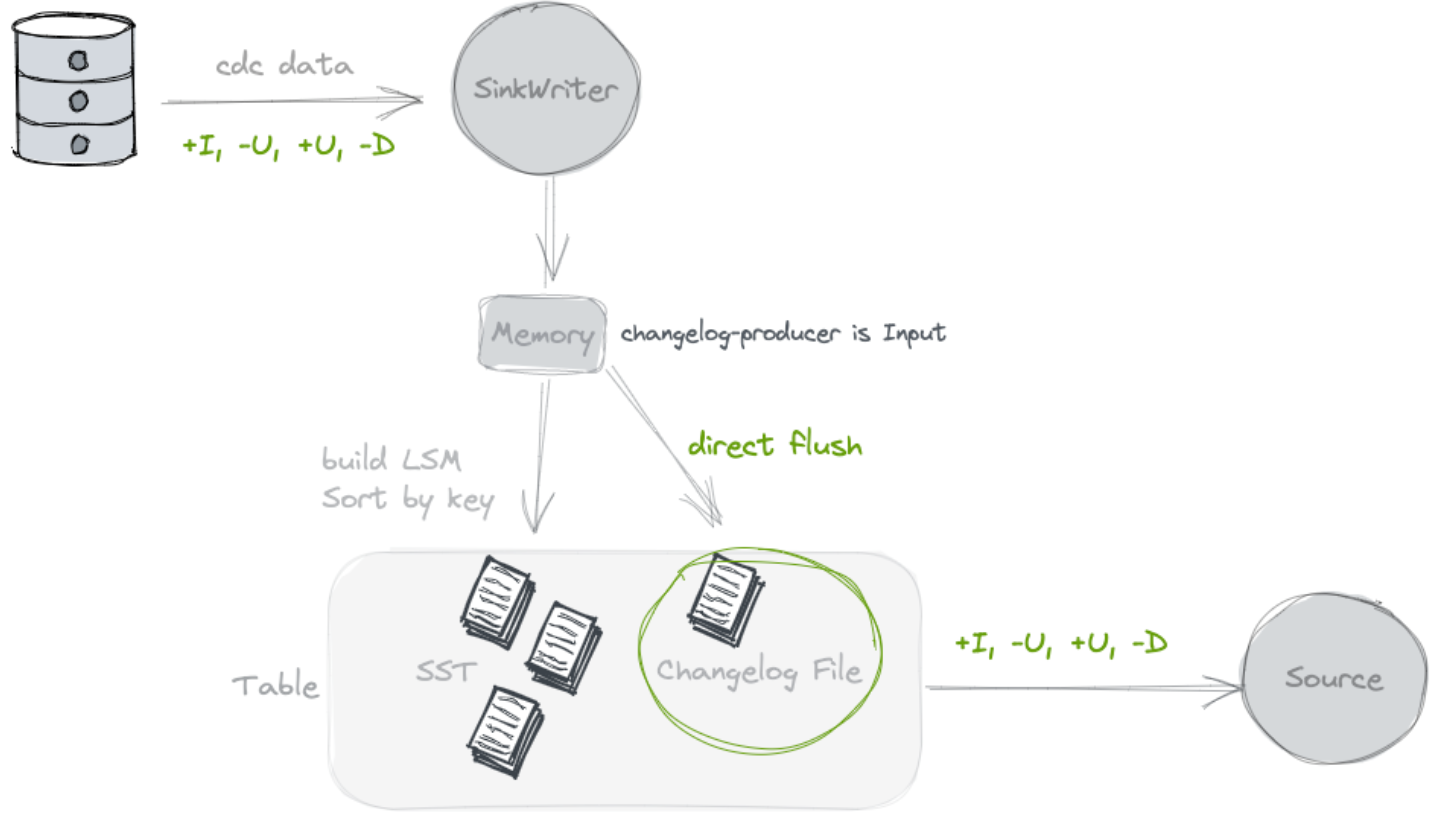
Lookup
Если ваш ввод не дает полного журнала изменений, но вы хотите избавиться от дорогостоящего оператора «нормализации», вы можете рассмотреть возможность использования «поиска». changelog producer. Указав'changelog- Producer' = «поиск», Paimon генерирует журнал изменений с помощью «поиска» перед записью существующих данных фиксации.
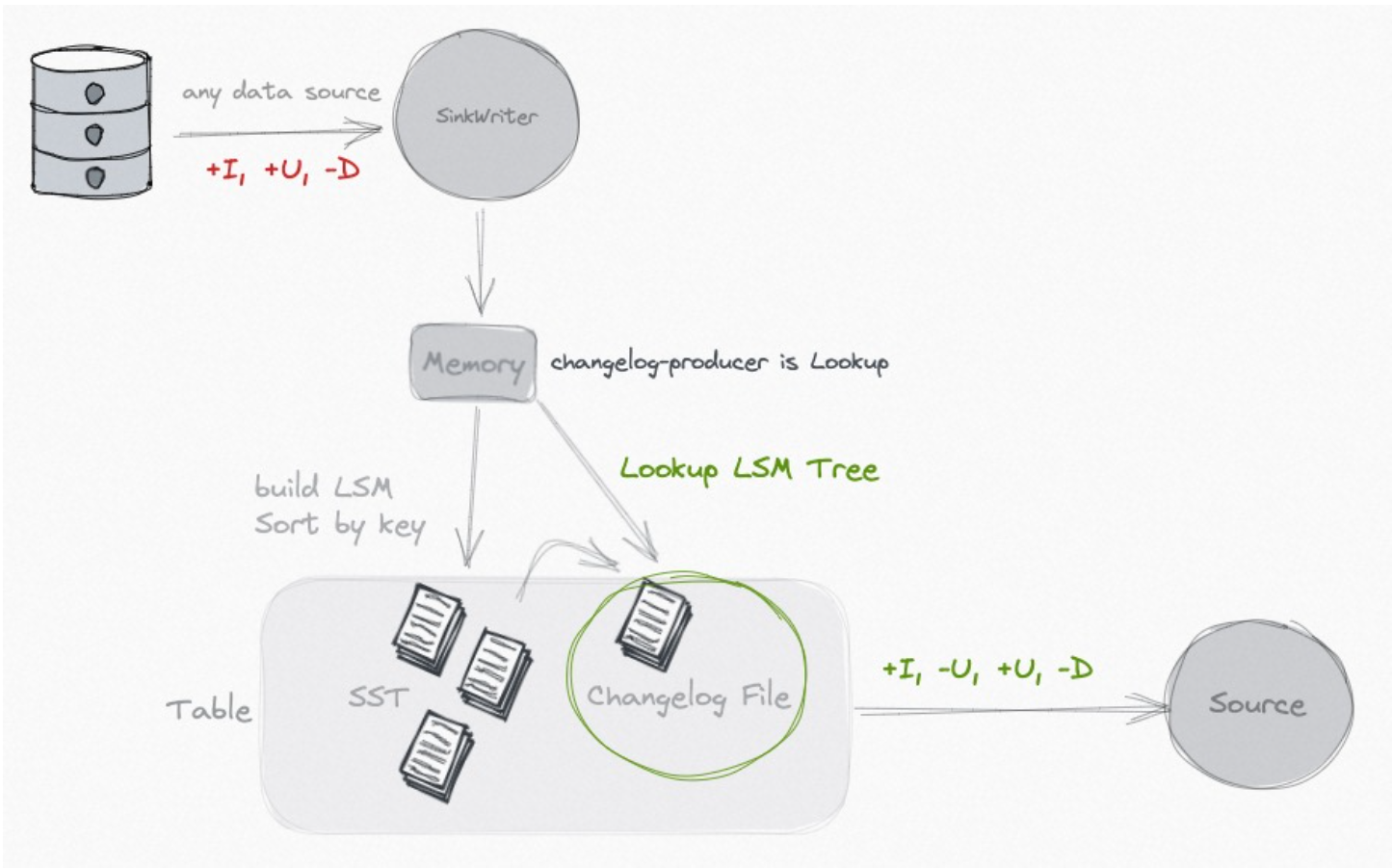
Lookup Если данные будут кэшироваться в памяти и на локальном диске, вы можете использовать следующие параметры для настройки производительности:

Lookup changelog- Producer поддерживатьchangelog- Producer.row-deduplicateчтобы избежать генерации -U, +U для одной и той же записи changelog。
Full Compaction
Если вы чувствуете, что «поиск» потребляет слишком много ресурсов, вы можете рассмотреть возможность использования журнала изменений «полного сжатия». Производитель, который может разделить запись данных и создание журнала изменений, больше подходит для сценариев с высокой задержкой (например, 10 минут). )。 Указав 'changelog- Producer' = 'full-compaction',Paimon Результаты полных сжатий будут сравниваться, а различия генерируются в виде журнала изменений. На задержку журнала изменений влияет частота полного сжатия. Указав full-compaction.delta-commits Свойства таблицы, существуют инкрементные фиксации (контрольная точка контрольно-пропускной пункт) будет продолжать срабатывать full compaction。 По умолчанию установлено значение 1, поэтому каждая контрольная точка выполняет полное уплотнение и генерирует изменение log。
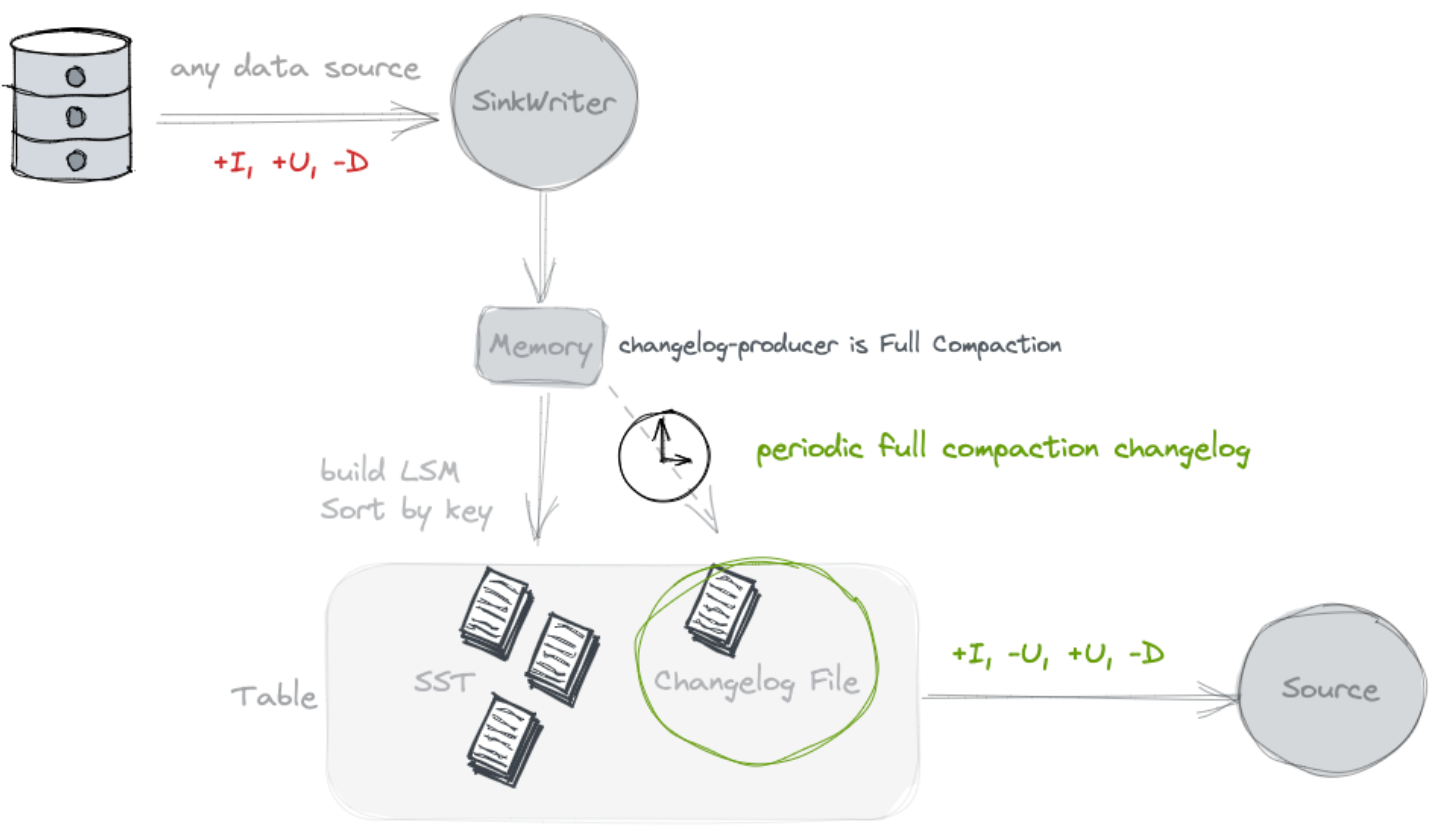
Full-compaction changelog- Producer Поддержка журнала изменений- Producer.row-deduplicate чтобы избежать генерации -U, +U для одной и той же записи Журнал изменений.
Sequence Field
По умолчанию таблица первичных Ключи определяют порядок слияния на основе порядка ввода (последняя введенная запись будет объединена последней). Однако в условиях существования распределенных вычислений могут возникать ситуации, которые приводят к путанице в данных. В это время,Вы можете использовать поле времени какsequence.field,Например:
CREATE TABLE MyTable (
pk BIGINT PRIMARY KEY NOT ENFORCED,
v1 DOUBLE,
v2 BIGINT,
dt TIMESTAMP
) WITH (
'sequence.field' = 'dt'
);Независимо от порядка ввода, используйте самое большое поле последовательности. Запись со значением будет последней объединенной записью. Sequence Auto Padding: Когда запись обновляется или удаляется, поле последовательности должно увеличиваться и не может оставаться прежним. для -Uи+U их поля последовательности должны быть разными. Если вы не можете выполнить это требование, Paimon Предоставляет возможность автоматического заполнения полей последовательности.
- 'sequence.auto-padding' = 'row-kind-flag': Если вы используете то же значение для -Uи+U, как Mysql То же, что «op_ts» (время внесения изменений в библиотеку данных) в Binlog. Рекомендуется использовать флаг типа строки автозаполнения, который будет автоматически различать -U (-D) и +U (+I).
- Недостаточная точность: если предоставленное поле последовательности не соответствует точности.,Примерно секунды или миллисекунды,может бытьsequence.auto-padding устанавливается от секунд до микро или от миллисекунд до микро, так что точность порядкового номера равна Будет компенсировано системой до микросекунд.
- Составной режим: например, «второй-микро, флаг типа строки», сначала добавьте микро ко второму, затем заполните флаг типа строки.
Row Kind Field
По умолчанию таблица первичных клавиши Определяет тип строки на основе входной строки. Вы также можете определить «rowkind.field», чтобы использовать поле для извлечения типа строки. Допустимые строки типа строки должны быть «+I», «-U», «+U» или «-D».



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
