Давайте поговорим о нескольких методах вызова между микросервисами.
Привет всем, я Букай Чен~
В микросервисной архитектуре для выполнения функции необходимо вызвать множество служб. То, как сервисы вызывают друг друга, стало ключевым вопросом в микросервисной архитектуре.
Есть два способа сказать Сервисный вызов.,Один из нихRPCСпособ,Другой Один из нихУправляемый событиямиСпособ,Вот как отправлять сообщения.
Метод обмена сообщениями является слабосвязанным, что лучше, чем сильно связанный режим. RPC превосходит, но Режим RPC также имеет свое место, если используется в подходящих сценариях.
Мы всегда говорим о связи, но что означает связь?
Тип муфты
Временная связь:клиент и Служить Для работы оба терминала должны быть онлайн одновременно.。При отправке сообщения,Очередь приема сообщений должна быть запущена.,Но программа фоновой обработки временно не работает и на нее это не повлияет.
Муфта производительности:клиент и Служить Мощность обработки конца должна соответствовать。При отправке сообщения,Не имеет значения, если мощности фоновой обработки недостаточно.,Очередь сообщений будет действовать как буфер.
Интерфейсное соединение:RPCВызывается с меткой функции,А очередь сообщений — это всего лишь сообщение. Например, после покупки товара вам необходимо вызвать функцию доставки Служить.,Если вы отправляете сообщение,Затем просто отправьте сообщение о том, что товар куплен.
Соединение режима отправки:RPCЭто точка-точка Способ,Нужно знать, кто другая сторона,Преимущество состоит в том, что он может передавать возвращаемое значение. Сообщения могут быть как «точка-точка», так и «точка-точка».,Вы также можете использовать трансляцию,Это уменьшает сцепление,Но это также затрудняет возврат значений.
Давайте проанализируем эффекты этих связей один за другим. Во-первых, временная привязка. Для большинства приложений требуется получить ответ немедленно, поэтому даже если вы используете очередь сообщений, фон должен работать постоянно. Подпишитесь на общедоступную учетную запись: Колонка технологий Ма Юаня, ответьте ключевым словом: «1111», чтобы получить внутреннее руководство Alibaba по настройке производительности Java.
Во-вторых, объединение пропускной способности. Если у вас есть требования ко времени для ответов, то функция буферизации очереди сообщений бесполезна, поскольку вам нужен своевременный ответ.
Что действительно необходимо, так это автоматическое масштабирование.,Он может автоматически регулировать мощность обработки Служить в соответствии с количеством запросов. третий и четвертый,Соединение интерфейса и соединение режима передачи,Эти двое действительно Режим Слабость РПК.
Событийный подход
Мартин Фаулер разделил событийно-ориентированное управление на четыре способа (что вы подразумеваете под «событийно-ориентированным»). Одним из них является знакомое уведомление о событиях, а другим — источник событий.
Уведомление о событии означает, что микросервисы не обращаются друг к другу напрямую, а сотрудничают, отправляя сообщения. Источник событий немного похож на учет: он записывает все события в постоянный слой хранения, а затем на его основе строит приложения. Подпишитесь на общедоступную учетную запись: Колонка технологий Ма Юаня, ответьте ключевым словом: «1111», чтобы получить внутреннее руководство Alibaba по настройке производительности Java.
На самом деле, с точки зрения применения они не должны принадлежать к одной и той же категории, их использование совершенно разное. Уведомление о событии — это метод вызова (или интеграции) микросервисов, и его следует отделить от RPC. Источник событий — это способ хранения данных, и его следует отделить от базы данных.
Метод уведомления о событии
Давайте рассмотрим это на конкретном примере. В приведенном ниже примере есть три микросервиса: «Служба заказов», «Служба поддержки клиентов» и «Служба продуктов».

Давайте сначала поговорим о чтении данных. Предположим, вы хотите создать «Заказ». В этом процессе вам нужно прочитать данные «Клиент» и «Продукт».
Если вы используете уведомление о событиях, вы можете создавать только доступные для чтения таблицы «Клиент» и «Товар» локально в «Услуге заказов» и синхронизировать данные с помощью сообщений.
Давайте поговорим о записи данных. Если вам нужно создать нового «Клиента» или изменить информацию «Клиента» при создании «Заказа», вы можете перейти на страницу создания пользователя в интерфейсе, а затем создать пользователя в разделе «Клиент». Служба поддержки клиентов» Отправьте сообщение «Пользователь создан» еще раз. Служба заказа получит сообщение и обновит локальную таблицу «Клиенты».
Это не очень хороший пример использования управления событиями, поскольку преимущество управления событиями заключается в том, что разные программы могут выполняться независимо друг от друга без каких-либо связей. Но теперь «Службе заказов» необходимо дождаться создания «Службы клиентов», прежде чем она сможет продолжить работу, чтобы завершить полное создание «Заказа». Главным образом потому, что «Заказ» и «Клиент» сами по себе логически тесно связаны. Вы не можете создать «Заказ» без «Клиента».
В этом случае сильной связи также можно использовать RPC. Вы можете создать менеджер более высокого уровня для управления вызовами между этими микросервисами, чтобы «Службе заказов» не приходилось напрямую вызывать «Службу клиентов».
Конечно, это не развязывает по сути, а просто передает связку на верхний уровень, но по крайней мере теперь «Сервис заказов» и «Сервис обслуживания клиентов» не могут влиять друг на друга. Причина, по которой эти тесные связи невозможно искоренить, заключается в том, что они тесно связаны в бизнесе. Подпишитесь на общедоступную учетную запись: Колонка технологий Ма Юаня, ответьте ключевым словом: «1111», чтобы получить внутреннее руководство Alibaba по настройке производительности Java.
Давайте возьмем еще один пример покупок. После выбора товара пользователь осуществляет «Оформление заказа».,Сформировать «Заказ»,Тогда требуется «оплата»,Затем заберите товар из "Инвентара",Наконец-то отправлено методом «Отгрузка».,Каждый из них является микросервисом. В этом примере используется Режим Можно использовать как RPC, так и методы уведомления о событиях.
При использовании режима RPC,Зависит от“Order”Сервисный вызовите нескольких других Служить, чтобы завершить всю функцию. При использовании метода уведомления о событии, после завершения «Оформления заказа» Служить, «Заказать Размещено», сервис «Оплата» получает сообщение, принимает платеж пользователя и отправляет сообщение «Оплата». получено» сообщение.
Служба «Инвентаризация» получает сообщение, забирает товар со склада и отправляет сообщение «Товар доставлен». Служба «Отгрузка» получает сообщение, отправляет товар и отправляет сообщение «Товар отправлен».
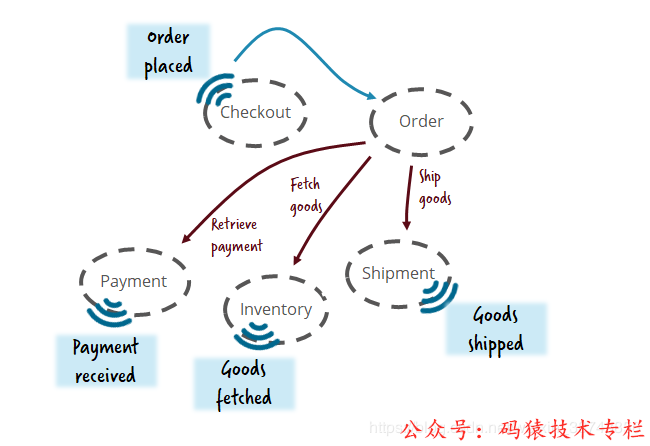
В этом примере использование событийного управления является хорошим выбором, поскольку после того, как каждая служба отправляет сообщение, она не требует обратной связи. Это сообщение принимается следующим модулем для выполнения следующего действия, а требуемое время также превышает. предыдущий свободный. Преимущество использования событийного управления в том, что оно снижает степень связанности. Недостаток в том, что сейчас вы не можете найти в программе этапы всего процесса покупки.
Если бизнес-логика имеет свои относительно фиксированные процессы и шаги, то использование RPC или управления бизнес-процессами (BPM) позволяет более удобно управлять этими процессами. Какой вариант выбрать в этом случае? На мой взгляд преимущества и недостатки примерно равны. С технической точки зрения выбирайте событийно-ориентированный, а с точки зрения бизнеса — RPC. Однако сейчас все больше и больше людей используют уведомление о событиях в качестве метода интеграции микросервисов, и, похоже, оно стало стандартным методом вызова между микросервисами.
Поиск событий
Это подрывной дизайн. Он записывает все данные в системе в виде событий. Его постоянное хранилище называется хранилищем событий, которое обычно строится на основе базы данных или очереди сообщений (например, Kafka выше) и предоставляет интерфейс для этого. рабочие события, такие как события чтения, записи и запроса. Источник событий предлагается в рамках Domain-Driven Design.
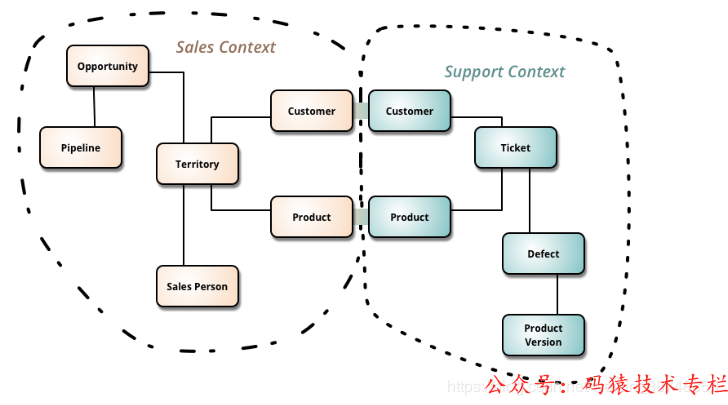
В DDD есть очень важная концепция — ограниченный контекст, которую можно использовать для разделения микросервисов. Каждый ограниченный контекст может быть микросервисом. Ниже приведен пример ограниченного контекста. На рисунке ниже представлены две службы «Продажи» и «Поддержка».
Одним из ключей к ограниченным контекстам является то, как обрабатываются общие члены, в данном случае «Клиент» и «Продукт». В разных ограниченных контекстах значение, использование и свойства объектов общих членов будут несколько отличаться. DDD рекомендует, чтобы эти общие члены создавали свои собственные классы (включая таблицы базы данных) в своих соответствующих ограниченных контекстах, а не совместно использовали . Согласованность данных можно поддерживать посредством синхронизации данных. Это будет подробно объяснено ниже.
Источник событий — это метод хранения микросервисов, который представляет собой детали внутренней реализации микросервисов. Таким образом, вы можете решить, какие микросервисы являются событийно-ориентированными, а какие нет, без необходимости делать все ваши сервисы событийно-ориентированными. Обычно для всего приложения существует только одно хранилище событий, и разные микросервисы взаимодействуют друг с другом, отправляя и получая сообщения в хранилище событий.
Хранилище событий можно разделить на разные потоки (эквивалентно темам в очереди сообщений) для использования объектами домена в разных микросервисах.
Недостатком источника событий является запрос данных, который можно решить двумя способами. Первый заключается в прямом запросе потока, который подходит только для ситуаций, когда поток относительно мал и запрос относительно прост.
Если запрос сложный, следует использовать второй метод, который заключается в создании базы данных, доступной только для чтения, и помещении необходимых данных в базу данных для запроса. Данные в базе данных обновляются путем прослушивания соответствующих событий в хранилище событий. Подпишитесь на общедоступную учетную запись: Колонка технологий Ма Юаня, ответьте ключевым словом: «1111», чтобы получить внутреннее руководство Alibaba по настройке производительности Java.
Метод хранения базы данных может сохранять только текущее состояние, но источник событий хранит все исторические состояния, поэтому при необходимости его можно воспроизвести до состояния в любой момент истории, что имеет большие преимущества. Но здесь не обошлось без проблем.
Во-первых, его программа относительно сложна, поскольку события являются первоклассными гражданами, и вам необходимо организовать бизнес-логику в соответствии с событиями, а затем использовать события для управления программой. Во-вторых, сложнее изменить событие или его формат, поскольку старые события уже хранятся в хранилище событий (события похожи на журналы и доступны только для чтения), и изменить их невозможно. их.
Поскольку источники событий и уведомления о событиях на первый взгляд выглядят одинаково, многие люди не понимают их различий. Уведомление о событиях — это всего лишь метод интеграции микросервисов, источник событий не используется внутри программы, а внутренняя реализация по-прежнему является традиционным методом базы данных.
Сообщения отправляются только при интеграции с другими микросервисами. При источнике событий события являются первоклассными гражданами, и нет необходимости в базе данных. Все данные хранятся в виде событий.
Хотя у практиков источников событий есть разные мнения, многие люди считают, что источники событий — это не метод интеграции микросервисов, а метод внутренней реализации микросервисов. Таким образом, в системе некоторые микросервисы могут использовать источники событий, а другие микросервисы могут использовать базы данных.
Если вы хотите интегрировать эти микросервисы, вы можете использовать уведомление о событиях. Обратите внимание, что необходимо различать два разных события. Одно из них — внутреннее событие микрослужбы, которое является относительно детальным. Событие такого типа отправляется только в поток этой микрослужбы и используется только при трассировке событий.
Другой тип также касается других микросервисов и является относительно крупномасштабным. Событие такого типа будет помещено в другой поток или потоки и использовано несколькими микросервисами для интеграции между сервисами. Преимущество этого подхода в том, что он ограничивает объем событий и уменьшает влияние нерелевантных событий на программу. Подробности см. в разделе «События домена и источники событий».
Источник событий существует уже давно. Хотя его популярность растет (особенно в последние два года), в целом о нем говорят много людей, но мало кто использует его в производственных средах. Причина в том, что это слишком сильно подрывает текущую архитектуру и требует внесения изменений в структуру хранения данных и способ работы программы, что по-прежнему несет в себе определенные риски.
Кроме того, микросервисы образуют целостную систему, начиная с развертывания программ, обнаружения и регистрации сервисов и заканчивая мониторингом и устойчивостью сервисов (Service Resilience). Хотя они также поддерживают сообщения, их зрелость гораздо ниже. Мне еще предстоит много работать самому.
Что интересно, Kafka продвигал его как инструмент, управляемый событиями, и добился больших успехов. Но это не было распознано системой отслеживания событий.
В большинстве источников событий используется хранилище событий с открытым исходным кодом, называемое Evenstore, или хранилище событий, основанное на определенной базе данных. Лишь относительно немногие люди используют Kafka в качестве хранилища событий.
Но если вы используете Kafka для реализации уведомления о событиях, проблем вообще не возникнет. В целом, сорсинг событий является определенной задачей для большинства компаний, и при его применении необходимо найти подходящий сценарий. Если вы хотите попробовать, вы можете сначала протестировать ситуацию с помощью микросервиса.
Хотя управление событиями еще немного сыро, в долгосрочной перспективе я по-прежнему очень оптимистичен по этому поводу. Как и другие новые технологии, поиск событий требует широкомасштабных применимых сценариев для его продвижения. Например, контейнерные технологии стали мейнстримом из-за популярности и продвижения микросервисов.
Применимые сценарии источников событий ранее были ограничены библиотеками учета и исходного кода, которые имели большие ограничения. Блокчейн может стать следующей возможностью, поскольку он также использует технологию поиска событий.
Кроме того, в будущем ИИ будет внедрен в конкретные программы, придав программе функцию обучения. Режим RPC не имеет адаптивной функции. Сама по себе управляемость событиями обладает способностью реагировать на события, что является основой самообучения. Таким образом, эта технология определенно будет востребована в долгосрочной перспективе, но, вероятно, не станет массовой в краткосрочной перспективе (3-5 лет).
Режим RPC
Метод RPC — это удаленный вызов функций, таких как RESTFul, gRPC и DUBBO. Как правило, это синхронно, и результаты можно получить немедленно. На практике большинство приложений требуют немедленных результатов. В этом случае синхронный метод имеет больше преимуществ и проще код.
Сервисный шлюз (API-шлюз)
Люди, знакомые с микросервисами, возможно, знают Сервисный шлюз (API-шлюз). Когда пользовательскому интерфейсу необходимо вызвать множество микросервисов,Требуется понимание интерфейса каждого Служить,Это большая работа.
Поэтому я создал Фасад, используя шлюз служб для инкапсуляции нескольких микросервисов, так что пользовательскому интерфейсу нужно только вызывать шлюз служб, и нет необходимости иметь дело с каждым микросервисом. Ниже приведен пример схемы шлюза API:
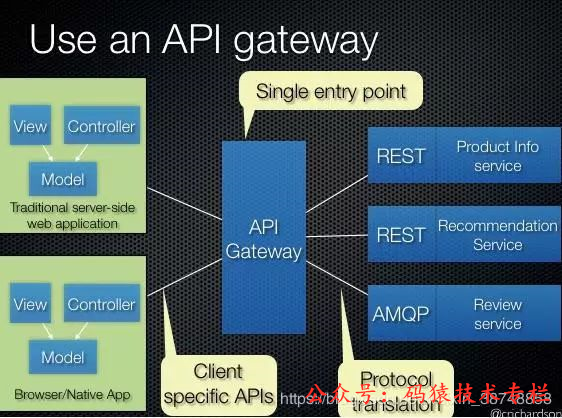
Сервисный шлюз (API-шлюз) не предназначен для решения проблемы жесткой связи вызовов между микросервисами, а в основном для упрощения работы клиента. Фактически, его также можно использовать для уменьшения связи между функциями.
При использовании API Gateway после изменения интерфейса службы вам может потребоваться изменить только API Gateway вместо изменения каждого клиента, вызывающего эту функцию, тем самым уменьшая связанность программы.
Сервисный вызов
Вы можете воспользоваться идеями API Gateway, чтобы уменьшить связанность вызовов RPC. Например, вы можете организовать несколько микросервисов, чтобы сформировать полную функциональную комбинацию сервисов и предоставить унифицированный интерфейс сервисов для внешнего мира. Эта идея чем-то похожа на описанный выше API-шлюз. Оба они централизуют сервисы для предоставления крупномодульных (грубо детализированных) сервисов вместо мелкодетализированных сервисов (тонко детализированных).
Однако созданная таким образом комбинация служб может быть пригодна для использования только одной программой и не будет иметь большой общей ценности. Поэтому, если есть подходящий сценарий, используйте его, иначе не надо его форсировать. Хотя мы не можем уменьшить связь между службами RPC, мы можем уменьшить влияние этой тесной связи.
Уменьшите влияние тесной связи
Каковы основные проблемы жесткой связи? Просто обновления на клиенте и сервере не синхронизированы. Сервер всегда обновляется первым. Клиентов может быть много. Нереально требовать их обновления одновременно. У них есть свои собственные графики развертывания, и они обычно предпочитают выполнять обновление во время следующего развертывания.
Обычно есть два пути решения этой проблемы:
Поддержка нескольких версий одновременно: эта рабочая нагрузка относительно велика, поэтому большинство компаний не примут этот подход.
Обратная совместимость на стороне сервера. Это более общий подход. Например, вы хотите добавить новую функцию или некоторым клиентам требуется добавить новый параметр к исходной функции, но другим клиентам этот параметр не нужен. На этот раз вам нужно создать новую функцию, похожую на исходную функцию, но имеющую еще один параметр. Таким образом, могут быть удовлетворены потребности новых и старых клиентов. Его преимуществом является обратная совместимость (конечно, в зависимости от используемого вами протокола).
Недостаток в том, что когда в будущем придут новые клиенты, они будут сбиты с толку, увидев две похожие функции, и не будут знать, какую из них использовать. И чем дольше время, тем серьезнее становится. На вашем сервере может быть не так много дополнительных функций, но похожих функций становится все больше, поэтому выбор становится невозможным.
Его решение — использовать протокол RPC, поддерживающий обратную совместимость. Лучшим на данный момент является Protobuf gRPC, особенно с точки зрения обратной совместимости.
Он определяет интерфейс для каждого сервиса, который является нейтральным интерфейсом, не имеющим ничего общего с языками программирования. Затем вы можете использовать инструменты для генерации кодов реализации на каждом языке для использования на разных языках. Переменные, определенные функцией, пронумерованы, и переменные могут быть необязательного типа, что лучше решает проблему совместимости функций.
Используя приведенный выше пример, когда вы хотите добавить необязательный параметр, вы определяете новую необязательную переменную. Поскольку это необязательно, исходному клиенту не нужно предоставлять этот параметр, поэтому никаких изменений в программе не требуется.
Новый клиент может предоставить этот параметр. Вам просто нужно уметь обрабатывать обе ситуации одновременно на стороне сервера. Таким образом, на сервер не добавляются новые функции, но новые потребности пользователей удовлетворяются, и он по-прежнему обратно совместим.
Существует ли верхний предел количества микросервисов?
В общем, количество микросервисов не должно быть слишком большим, иначе возникнет тяжелая нагрузка на эксплуатацию и обслуживание. Необходимо прояснить одну вещь: популярность микросервисов обусловлена не техническими инновациями, а удовлетворением потребностей управления. Когда одна программа становится большой, требования ко времени развертывания каждого модуля различаются, а также требования к оптимизации сервера. Более того, в команде большое количество людей, что затрудняет координацию и управление.
После разделения программы на микросервисы каждая команда отвечает за несколько сервисов, которыми легче управлять, и каждая команда также может внедрять инновации в своем темпе, но это приносит огромные проблемы с эксплуатацией и обслуживанием. Поэтому, когда микросервисы только появились, я всегда чувствовал, что это шаг назад и принесет больше вреда, чем пользы. Но поскольку другого решения проблемы управления нет, нам приходится стиснуть зубы.
К счастью, проблемы, вызванные микросервисами, решаемы. Лишь позже, когда микросервисы создали полную систему автоматизации, от интеграции программ до развертывания, от полного отслеживания ссылок до регистрации, а также обнаружения, обнаружения и регистрации сервисов, рабочая нагрузка микросервисов была уменьшена.
Хотя микросервисы технически бесполезны, их популярность во многом способствовала развитию новых технологий, таких как контейнерные технологии, сервисная сетка (Service Mesh) и полноканальное отслеживание. Однако технических преимуществ у него пока нет.
Пока однажды я не понял, что отладка производительности одной программы на самом деле очень сложна (трудно изолировать узкое место. Однако после того, как микросервис настроен с полным отслеживанием ссылок, суть можно быстро найти). Кажется, что микросервисы — это не все недостатки с технической точки зрения, у них есть и хорошие стороны. Однако степень детализации микросервисов не должна быть слишком высокой, иначе рабочая нагрузка все равно будет слишком велика.
Компания среднего размера может позволить себе дюжину или десятки микросервисов, но если их сотни или даже тысячи, это определенно не то, с чем может справиться средняя компания. Хотя существующие инструменты уже готовы и весь процесс, связанный с микросервисами, в основном автоматизирован, это все равно добавляет много работы.
Несколько лет назад Мартин Фаулер предложил начать с монолитной программы (подробности см. в MonolithFirst), а затем постепенно разделить функции на микросервисы. Но позже кто-то возразил против этого предложения, и он несколько смягчился.
Это хорошая идея, если монолитная программа не слишком велика. Размер программы можно измерить количеством таблиц базы данных. Я видел большие отдельные программы с сотнями таблиц. Это слишком много, и ими сложно управлять. В обычных условиях микросервис может иметь от двух-трех таблиц до пяти-шести таблиц и обычно не более десяти таблиц. Но если вы хотите сократить количество микросервисов, вы можете ослабить этот стандарт до двадцати таблиц.
Используйте это как примерное руководство для создания микропрограмм. Если после некоторого использования вы все еще чувствуете, что он слишком велик, постепенно разделите его. Конечно, сервисы, созданные по этому стандарту, больше похожи на композиции сервисов, чем на отдельные микросервисы. Но это снизит для вас рабочую нагрузку. Если это не влияет на инновационный прогресс бизнес-подразделения, это хорошее решение.
Стоит ли выбирать микросервисы? Если одна программа больше не управляема,Тогда у вас нет выбора. Если нет проблем с управлением,Тогда микросервисы принесут вам только проблемы и неприятности. на самом деле,У большинства компаний не так много вариантов,Используйте только микросервисы,Однако вы можете создать меньше микросервисов. Если вы все еще не можете решить,Есть компромиссный план,“Внутренний микросервисный дизайн”。
Внутренний микросервисный дизайн
На первый взгляд эта конструкция выглядит как единая программа, имеющая только одно хранилище исходного кода, одну базу данных и одно развертывание, но внутри программы она может быть спроектирована по идее микросервисов. Его можно разделить на несколько модулей, каждый модуль представляет собой микросервис и может управляться разными командами.
Используйте эту картинку в качестве примера. Каждый закругленный квадрат на этом рисунке — это примерно микросервис, но мы можем спроектировать его как единую программу с пятью микросервисами внутри.
Каждый модуль имеет свою собственную таблицу базы данных, и все они находятся в одной базе данных, но доступ к модулям между базами данных невозможен (не устанавливайте внешние ключи к таблицам базы данных между модулями).
«Пользователь» (в модуле «Управление конференцией») — это общий класс, но его имя, значение и использование в разных модулях различны, а его члены также различны (например, в «Обслуживании клиентов» он называется «Клиент») .
DDD (Domain-Driven Design) рекомендует не разделять этот класс, а создавать в каждом ограниченном контексте (модуле) новый класс с новым именем.
Хотя данные в их базах данных должны быть примерно одинаковыми, DDD рекомендует создавать новую таблицу в каждом ограниченном контексте и синхронизировать данные между ними.
Это так называемый «Внутренний». микросервисный "дизайн" на самом деле DDD,Но микросервисов еще не было,Поэтому это выглядит как единая программа тела,А вот интерьер уже спроектирован микросервисами.
Его книга была опубликована в 2003 году и пользовалась в то время большой известностью. Однако он больше ориентирован на разработку бизнес-логики и его сложнее реализовать. Поэтому о нем много говорят, но редко используют.
Лишь десять лет спустя, после появления микросервисов, люди обнаружили, что на самом деле это микросервис внутри, и при проектировании микросервисов необходимо руководствоваться его идеями, поэтому его снова обновили, и на этот раз он стал еще более мощным. , и это дошло до каждого. Любой, кто говорит о микросервисах, должен говорить о DDD. Однако десять лет спустя книга по программному обеспечению все еще может служить руководством для разработки новых технологий, и это очень достойно восхищения.
Преимущество этой конструкции заключается в том, что это единая программа, устраняющая проблемы с развертыванием, эксплуатацией и обслуживанием, вызванные множеством микросервисов. Но он спроектирован внутри микросервисов. Если в будущем его нужно будет разделить на микросервисы, это будет проще. Что касается момента разделения, это не технический вопрос.
Если различные команды, ответственные за эту монолитную программу, не могут договориться о графиках развертывания, оптимизации серверов и т. д., то ее необходимо разделить.
Конечно, вам также придется иметь дело с различными проблемами, связанными с эксплуатацией и обслуживанием. Внутренний микросервисный дизайн – компромиссное решение,Если вы хотите опробовать микросервисы,Но не хочу слишком сильно рисковать,Это хороший выбор.
в заключение
Существует два способа звонка между микросервисами.,RPC и драйверы событий. eventdrive — лучший способ,Потому что он слабо связан. Но если бизнес-логика тесно связана,Режим Также возможен RPC (его преимущество в том, что код проще), а также можно выбрать подходящий протокол (Protobuf gRPC), чтобы уменьшить вред, причиняемый такой тесной связью.
Из-за сходства между источником событий и уведомлением о событиях многие люди путают эти два понятия, но на самом деле это совершенно разные вещи. Число микросервисов не должно быть слишком большим. Сначала можно создать более крупные микросервисы (больше похожие на композицию сервисов).
Если вы все еще не уверены, стоит ли использовать архитектуру микросервисов, вы можете начать с «Внутреннего микросервисный Начнём с «дизайна», а потом постепенно разделимся.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
