D-YOLO решает трудности реализации | Сосредоточьтесь на модуле объединения функций + подсети функций без тумана, чтобы семейство YOLO не боялось дождя, тумана, ветра и снега

Неблагоприятные погодные условия, включая дымку, снег и дождь, приводят к ухудшению качества изображения, что часто приводит к снижению производительности сетей обнаружения на основе глубокого обучения. Большинство существующих методов пытаются исправить нечеткие изображения перед выполнением обнаружения объекта, что увеличивает сложность сети и может привести к потере потенциальной информации. Чтобы лучше интегрировать задачи восстановления изображений и обнаружения объектов, авторы разработали двухпутевую сеть с модулем объединения функций внимания, учитывающим как туманные, так и размытые характеристики. Авторы также предлагают подсеть, которая обеспечивает отсутствие тумана в сети обнаружения. В частности, D-YOLO повышает производительность сети обнаружения за счет минимизации расстояния между подсетью выделения четких признаков и сетью обнаружения. Эксперименты с наборами данных RTTS и FoggyCityscapes показывают, что D-YOLO работает лучше, чем самые современные методы. Это надежная система обнаружения, которая устраняет разрыв между удалением дымки на низком уровне и обнаружением на высоком уровне.
I Introduction
Обнаружение объектов является ключевой технологией компьютерного зрения и широко используется во многих областях, таких как производство, сельское хозяйство, здравоохранение, безопасность наблюдения, управление дорожным движением и автономные транспортные средства. Это связано с тем, что обнаружение объектов имеет двойную цель: классификацию и обнаружение объектов на изображении. В последние годы методы обнаружения объектов достигли значительного прогресса, особенно с внедрением глубоких сверточных нейронных сетей (DNN). Эти методы показывают замечательную эффективность и точность, что во многом способствует развитию смежных областей.
Однако большинство современных алгоритмов обнаружения целей тестируются на традиционных наборах данных, таких как MSCOCO, PASCAL-VOC и Imagenet. Однако, несмотря на высокую производительность на обычных изображениях, эти методы часто страдают от снижения эффективности обнаружения в суровых погодных условиях, особенно в туманную погоду, что является одной из наиболее распространенных ситуаций в реальных сценариях.
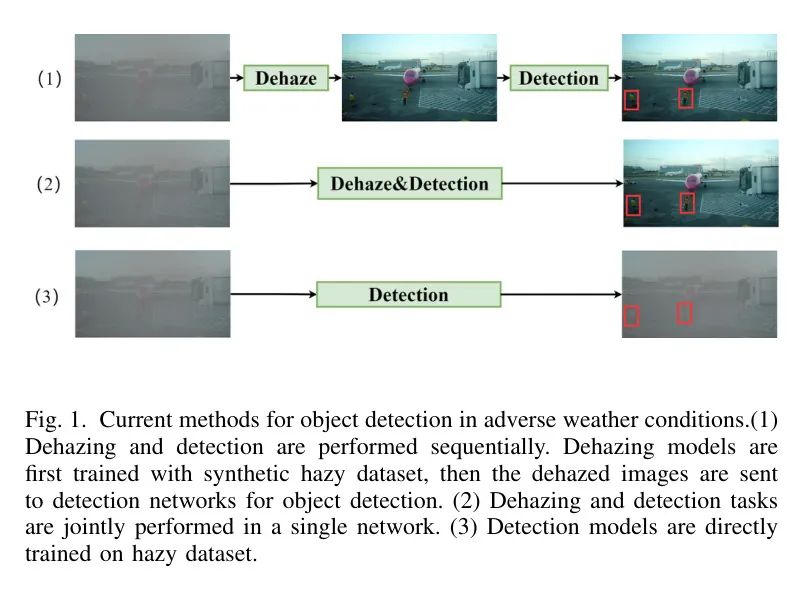
Как показано на рисунке 1, текущие решения можно разделить на три категории. Основные методы обнаружения целей в условиях тумана можно разделить на три категории. Наиболее распространенной стратегией является использование зрелых алгоритмов удаления дымки (таких как AOD-Net, MSBDN, Grid-dehazenet, DCP) для предварительной обработки входных изображений перед подачей их в сеть обнаружения. Однако эти методы имеют плохую способность к обобщению в реальных сценариях, поскольку восстановленные изображения могут потерять важные детали. Некоторые работы объединяют сети восстановления и обнаружения каскадным образом и используют совместные потери для оптимизации сети. В некоторых работах при обучении используются две независимые потери. Однако возросла вычислительная сложность и скорость рассуждений, что неприемлемо в сценариях с ограниченными ресурсами.
Авторы считают, что для решения этой проблемы хорошим подходом является замена восстановления низкого уровня адаптацией функций более высокого уровня. Модель D-YOLO состоит из трех основных компонентов:
- Очистить подмножество извлечения признаков
- Характеристика адаптера сети
- Детектор
Подсеть выделения четких признаков отвечает за извлечение признаков без тумана. Эти полученные функции затем передаются в подсеть обнаружения через подсеть адаптации функций. Подсеть адаптации признаков генерирует четкие признаки из входных туманных признаков. Кроме того, чтобы обеспечить более надежные результаты обнаружения, авторы реорганизовали модель в двойные пути и разработали модуль объединения функций внимания для соединения двух ветвей. При этом используются преимущества удаления дымки и туманной погоды для дальнейшего расширения возможностей представления модели и улучшения ее производительности в сложных погодных условиях. Все подсети и модули модели активируются во время обучения. Наконец, во время вывода подсеть четкого выделения признаков отключается, чтобы обеспечить быстрое и точное обнаружение объектов.
Исчерпывающие экспериментальные результаты на наборах реальных данных (сцены дорожного движения в реальном времени, вождение в тумане) и наборах синтетических эталонных данных (FoogyCityscapes) показывают, что D-YOLO значительно превосходит современные методы обнаружения объектов. Вклад работы автора можно резюмировать в трех аспектах.
В целом, есть три основных вклада.
- Автор представляет архитектуру двухветвевой сети и модуль объединения функций внимания.,Интегрируйте размытые и размытые функции,Это позволяет еще больше улучшить определение производительности.
- Автор предлагает метод эффективного и единообразного объединения задач восстановления и обнаружения на уровне функций.,Использование подмножества четкого извлечения признаков обеспечивает четкую информацию для обнаружения сети. Модуль четкого извлечения признаков активируется только во время обучения.,Таким образом, существующие уменьшают вычислительные затраты в процессе вывода.,При этом была достигнута удовлетворительная производительность.
- Автор разработал функцию сетевого адаптера,Эта подгруппа способна передавать четкую информацию из подгруппы четкого выделения признаков в сеть обнаружения приезжающих.,Помочь повысить точность D-YOLO в неблагоприятных погодных условиях.
II Related Work
Object detection
Обнаружение объектов является одной из наиболее важных задач в области компьютерного зрения и широко используется в транспорте, медицине, дистанционном зондировании и других сценариях. С улучшением вычислительной мощности и разработкой алгоритмов глубокого обучения сети глубокого обучения на основе CNN стали основным направлением текущих исследований по обнаружению целей. Методы обнаружения целей можно разделить на методы на основе якорного ящика, включая одноэтапные и двухэтапные алгоритмы, методы без якорного ящика и методы на основе трансформатора.
Для двухэтапного метода первым шагом является выбор предложения региона, а затем выполнение классификации и регрессии на основе предложения региона. Будучи широко признанным алгоритмом, RCNN сначала разрабатывает региональную сеть предложений (RPN) для генерации региональных предложений, а затем выполняет извлечение и обнаружение признаков для выбранных предложений. На основе этой структуры успех R-CNN привел к появлению большого количества вариантов, таких как Fast R-CNN, Faster R-CNN, Mask R-CNN, Cascade R-CNN, Libra R-CNN и Dynamic R-CNN. Си-Эн-Эн. По сравнению с одноэтапными методами, несмотря на свою значимость с точки зрения точности, метод, основанный на предложении региона, по-прежнему страдает от проблемы низкой скорости вывода, что затрудняет его применение в сценариях реального времени.
В одноэтапном методе предложения регионов и результаты обнаружения генерируются одновременно, что демонстрирует более высокую скорость вывода и небольшое снижение производительности обнаружения. Серия YOLO – самая популярная одноступенчатая сеть. Он делит входное изображение на несколько сеток, каждой сетке назначается несколько опорных точек, охватывающих различные формы и размеры, которые могут иметь объекты на изображении. После большого успеха YOLOv3 было создано множество улучшений и множество вариантов. В качестве еще одного типичного одноэтапного метода серия SSD использует наборы опорных точек и выполняет обнаружение на картах объектов различного разрешения.
Object detection in adverse weather conditions
Большинство основных сетей обнаружения в основном предназначены для общих ситуаций и оптимизированы для обработки высококачественных изображений при нормальных погодных условиях. Поэтому точность их обнаружения имеет тенденцию снижаться при недостаточном освещении или при встрече с такими препятствиями, как туман, что делает обнаружение целей в суровых погодных условиях проблемой, до сих пор не решенной полностью. Ключом к улучшению эффективности обнаружения в суровых погодных условиях является поиск наилучшего способа совмещения задач восстановления и обнаружения.
Существующие методы можно разделить на две категории в зависимости от порядка решения задач восстановления и обнаружения. Самый распространенный подход — предварительная обработка изображений низкого качества с использованием существующих алгоритмов восстановления для удаления тумана или дождя. Предварительно обработанные изображения затем вводятся в сеть обнаружения объектов для генерации результатов обнаружения. Хотя эти методы улучшают общее качество входного изображения, нет никакой гарантии, что этот метод улучшит производительность сети обнаружения, поскольку в предварительно обработанных изображениях могут отсутствовать важные скрытые функции.
Лю и др. [32] разработали адаптивную к изображению YOLO — комплексную структуру, которая каскадно выполняет устранение дымки и обнаружение. Некоторые исследования пытаются выполнить восстановление изображения и обнаружение объектов одновременно, чтобы смягчить влияние конкретной метеорологической информации. Хуанг и его коллеги разработали систему обнаружения с двумя подсетями, включая подсеть восстановления и подсеть обнаружения. Подсеть восстановления обучена на ImageNet и отвечает за преобразование размытых элементов изображения в четкие, тем самым смягчая эффекты размытия, вызванные туманной погодой.
В последнее время некоторые методы используют адаптацию предметной области для обнаружения объектов в суровых погодных условиях. Они предполагают, что существует значительный сдвиг между четкими изображениями, используемыми для обучения, и изображениями в суровых погодных условиях. Среди этих методов наиболее широко используемой стратегией является состязательное обучение. Например, Синдаги и др. [37] предложили неконтролируемую адаптивную сеть на основе априорных данных для обнаружения в суровых погодных условиях.
Чжан и др. [38] разработали адаптивный к предметной области YOLO для улучшения междоменной производительности класса моделей.
III Methodology
Overview
Общая архитектура D-YOLO, предложенная автором, показана на рисунке 2. В отличие от большинства существующих методов, авторы рассматривают проблему обнаружения целей в суровых погодных условиях с другой точки зрения. Синдаги и др. [37] предположили существование смещения области между чистыми и туманными изображениями. Исходя из этого, авторы полагают, что эту проблему можно решить посредством адаптации функций. Во-первых, автор разработал модуль адаптации признаков и подсеть извлечения признаков, которые вместе помогают сети обнаружения генерировать признаки без тумана из входных туманных изображений. Кроме того, чтобы сохранить важную информацию в туманных объектах, авторы также разработали модуль объединения функций внимания, который объединяет размытые и исходные туманные функции.
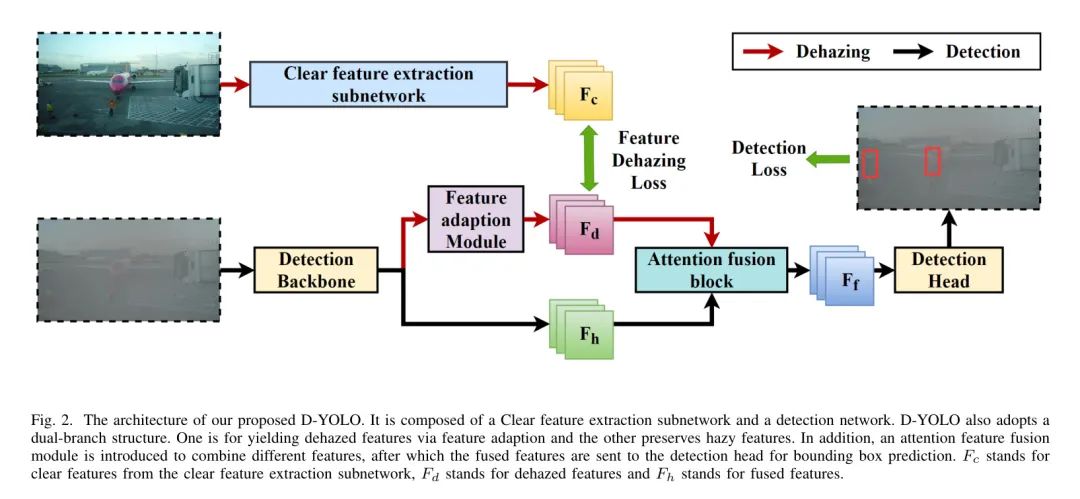
Clear feature extraction network
В предложенной авторами сети подсеть выделения четких признаков (CFE) отвечает за анализ особенностей входного четкого изображения и передает их модулю адаптации признаков. Поскольку функции, извлеченные из туманных изображений, содержат информацию о загрязнении, четкие функции, предоставляемые подсетью CFE, имеют большой потенциал. Эти особенности могут существенно помочь авторской модели четко идентифицировать объекты на изображениях на этапе обучения.
За последнее десятилетие было разработано множество глубоких сверточных сетей для улучшения возможностей извлечения признаков из изображений, среди которых VGG16, ResNet50 и DarkNet53 являются одними из наиболее плодотворных сетей. Эти архитектуры широко использовались в качестве магистральных сетей для извлечения признаков в различных задачах компьютерного зрения благодаря их высокой производительности и структурным инновациям. В этом исследовании авторы выбирают DarkNet53 в качестве подсети выделения четких признаков для извлечения семантической информации из четких изображений. Многомасштабные объекты выбираются в качестве сгенерированной карты объектов (
), эти функции затем проходят через сверточный уровень 1x1, а затем отправляются в подсеть адаптации функций. потому что
Канал между и Fa может быть разным. Следует отметить, что подсеть CFE активируется только на этапе обучения.
Feature adaption module
Модуль FA действует как адаптер для получения полезной информации в подсети четкого извлечения признаков. Преобразованные функции затем передаются в модель слияния внимания. Структура модуля FA представлена в таблице 1. В предложенном автором D-YOLO трехмасштабные элементы магистральной сети обнаружения используются для оснащения модуля FA. Структура модуля адаптации функций представлена в таблице 1.
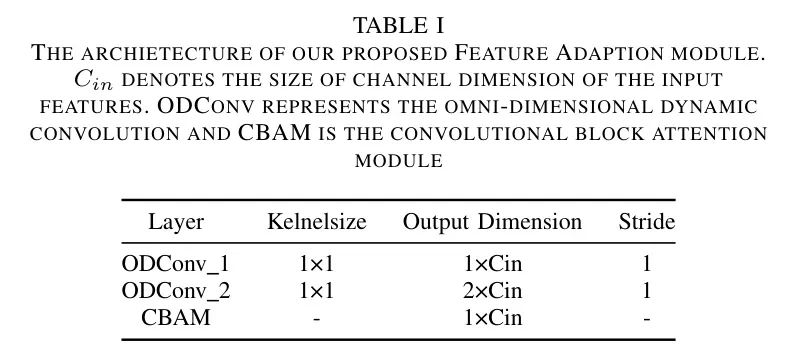
Автор видит, что модуль адаптации признаков состоит из двух сверточных слоев и модуля сверточного блока внимания (CBAM).
Направленная на канал потеря расходимости KL используется в адаптере для оптимизации и стабилизации процесса обучения, тем самым устраняя
и
разрыв между. Функция потерь, используемая для обучения модуля FA, выражается следующим образом:
здесь,
и
Представляют карты функций из модуля CFE и модуля FA соответственно.
Представляет температуру дистилляции, которая в эксперименте установлена равной 1. Кроме того, чтобы повысить производительность модуля FA, авторы применяют разные веса к функциям в разных масштабах. Как показано в формуле, в опытах автора
、
、
одеялоустановлен на0.7、0.2и0.1,Поскольку низкоуровневая карта объектов существует, она предоставляет ценные знания при более высоких разрешениях.,Это улучшает целевую информацию.
Omni-dimensional dynamic convolution
Полномерная динамическая свертка (Омни-мерная динамическая свертка, ODConv) — это расширенная версия структуры сверточной нейронной сети (CNN).,Он использует механизм многомерного внимания на различных ядрах свертки для достижения динамической свертки. Этот новый метод может значительно улучшить возможности извлечения и представления признаков во всех аспектах. существуетD-YOLOсередина,ODConv используется как сверточный уровень внутри модуля адаптации функций.
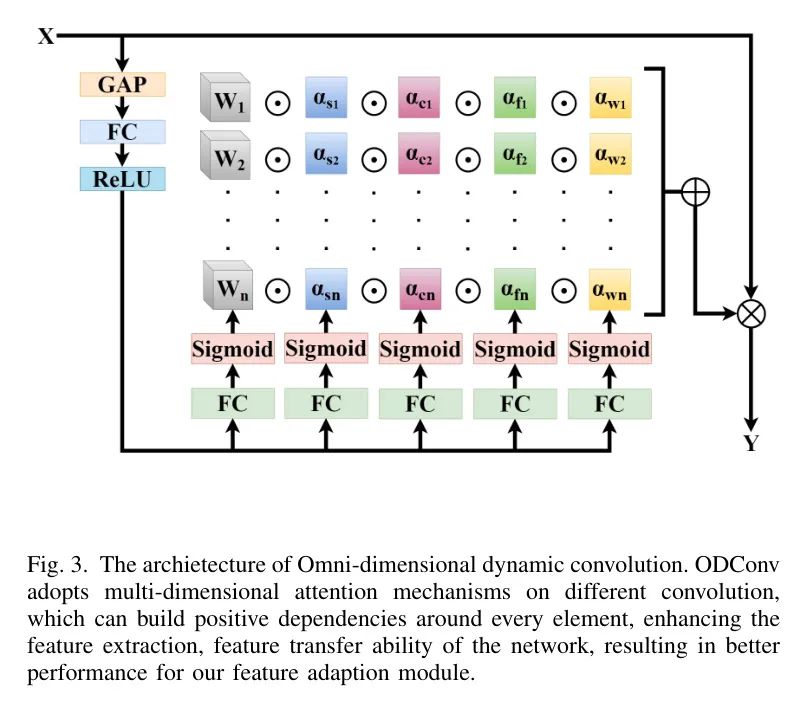
Архитектура ODConvset показана на рисунке 3. Учитывая входную карту объектов x,Сначала он сжимается в вектор признаков той же длины, что и входной канал, посредством операции глобального среднего пула каналов (GAP). Затем,Затем этот вектор признаков передается через полностью связный слой и четыре головные ветви. Каждая головная ветвь состоит из полностью связного слоя и функции softmax или сигмовидной функции.,Создать нормализованное внимание
,
,
,
. Рисунок 4.
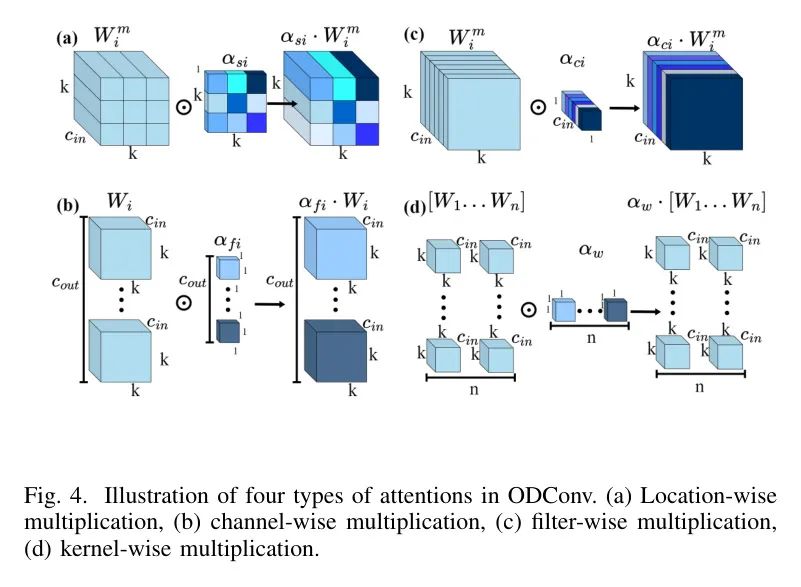
Каждое внимание представляет собой уникальный способ умножения, включая позиционное, канальное, фильтрующее и ядерное. Эти четыре типа внимания постепенно объединяются с n ядрами свертки.
Умножить,Позволяет odconv учитывать как пространственную, так и канальную информацию.,Это расширяет возможности представления функций сверточных нейронных сетей. существуетD-YOLOсередина,Автор использует ODconv в качестве сверточного слоя модуля адаптации функций.,Улучшить возможности адаптации и извлечения функций. таким образом,Автор может получить более точные характеристики удаления матовости.,Тем самым улучшая производительность обнаружения.
Attention feature fusion module
Чтобы лучше сочетать размытые и размытые характеристики,Предлагается уникальный модуль слияния функций внимания (AF) с туманным восприятием. Устраненные объекты могут содержать информацию о загрязнении.,Когда модуль удаления дымки работает плохо,Может привести к падению производительности. поэтому,Крайне важно создать модуль слияния, чтобы решить проблему семантического несоответствия между объектами с устраненной дымкой и исходными неясными объектами. Структура модуля объединения признаков авторского внимания представлена на рисунке 5.
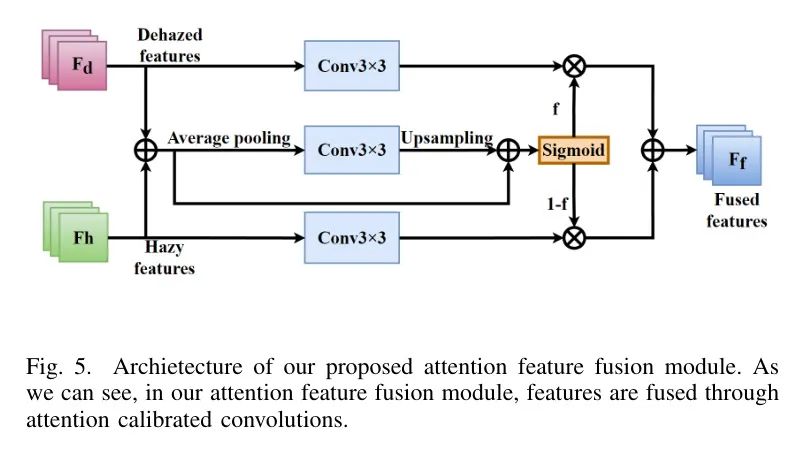
Конкретно,Сначала автор выполняет операцию поточечного сложения туманных и размытых признаков, чтобы получить слияние X. впоследствии,Автор существования применил особенности слияния
Среднее объединение расширяет рецептивное поле. Затем функция передается через
Сверточная обработка ядер свертки и последовательная обработка оператора билинейной интерполяции. Кроме того, после операции повышения дискретизации добавляется короткое соединение, образующее T. Эти операции можно выразить в виде функции (2).
Затем автор вводит признак Т в сигмовидную функцию, чтобы нормализовать ее в карту внимания. Кроме того, автор использует оригинальные возможности ввода
и
применяемый
ядро свертки. наконец,Объедините входные функции после свертки карты внимания, умножая элементы один на один.,Автор получил характеристики приезжать
. Этот процесс можно выразить как (3).
В отличие от существующих методов объединения внимания, которые полагаются на размеры каналов, авторский модуль использует пул средних pxr вместо глобального среднего пула. Каждое пространственное местоположение способно не только адаптивно включать окружающий его информационный контекст в виде встраивания из исходного масштабного пространства, но и моделировать межканальные зависимости.
поэтому,существуют без значительного увеличения вычислительной сложности,Поле зрения сверточного слоя было значительно расширено. Во-вторых,AFF одновременно кодирует функции туманности и удаления дымки. Он способен сохранять важную пространственную информацию, которая имеет решающее значение для создания различительных и выборочных карт внимания для целевых мест.
IV Experiment and Analysis
Dataset
Авторы обучили предложенную сеть с помощью следующей схемы оптимизации: Для набора данных, поскольку наборы данных, доступные для обнаружения целей в суровых погодных условиях, ограничены, авторы создали набор данных для обнаружения тумана на основе набора данных VOC. Чтобы получить изображения тумана, авторы использовали известную модель атмосферного рассеяния для создания синтетического тумана, как показано в следующем уравнении.
здесь,J(x) представляет собой чистое изображение,A относится к глобальному атмосферному свету.,И t(x) относится к диаграмме передачи в среде,Его можно рассчитать по:
в
Представляет параметр атмосферного рассеяния, d(x) относится к глубине сцены, которую можно определить как:
здесь,
Представляет евклидово расстояние от текущего пикселя до центрального пикселя, w. и h Относится к количеству строк и столбцов изображения соответственно. В авторском эксперименте автор изменил глобальные параметры атмосферного освещения. A установлен на 0,5, при случайном изменении параметров атмосферного рассеяния
Установите значение от 0,07 до 0,12 для контроля уровня тумана.
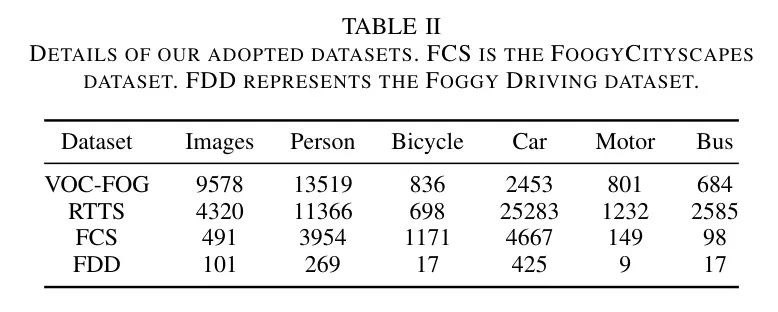
Чтобы обеспечить единообразие меток в разных наборах данных, авторы используют только RTTS данные ориентированы на целевые категории (т. е. автомобили, автобусы, мотоциклы, велосипеды и люди) VOC Изображения набора данных для создания обучающего набора. При обработке оригинала VOC После этих чистых изображений в наборе данных авторы получили 9578 Туманные изображения, используемые для обучения (VOC-Foggy).
Iv-B1 Testset
Учитывая, что существует очень мало опубликованных реальных систем обнаружения в суровых погодных условиях,,Оценить и сравнить жизнеспособность D-YOLO и других предложенных автором методов обнаружения при неблагоприятных погодных условиях.,Авторы выбрали три разных набора тестов.,Включает один набор синтетической туманной погоды и два набора реальной туманной погоды.
Эпизод с данными о вождении в тумане - это эпизод с туманными данными в реальном мире.,Для обнаружения объектов и семантической сегментации. Он включает в себя 466 экземпляров транспортных средств (т. е. легковых автомобилей, автобусов, поездов, грузовиков, велосипедов и мотоциклов) и 269 экземпляров людей (т. е. людей и велосипедистов).,Экземпляры маркированы на основе 101 реального изображения туманной погоды. также,Хотя в наборе данных «Вождение в тумане» имеется восемь аннотированных целевых категорий.,Но автор выбирает для обнаружения только указанные выше пять целевых категорий.,Чтобы обеспечить согласованность между обучением и тестированием.
RTTS — это относительно полная база данных, доступная в условиях естественного тумана. Она содержит 4322 реальных изображения тумана и пять аннотированных целевых категорий. Учитывая, что в реальном мире сложно или даже невозможно запечатлеть пары туман/четкое изображение, Ли и др. предложили набор данных RTTS для оценки способности алгоритма устранения дымки к обобщению в реальных сценах с точки зрения задач.
FoggyCityscapesЭто синтетический туман, имитирующий туман реальной сцены.данныенабор。Каждое изображение тумана создается с помощьюCityscapesчеткое изображениеи Рендеринг карты глубины。поэтому,Foggy Ярлык иданные подразделения в Cityscapes унаследован от Cityscapes. Всего в наборе FoggyCityscapes 34 категории. с Фогги Как и в наборе «Вождение», автор фильтрует изображения и теги на основе пяти категорий, упомянутых выше.
Implementation Details
D-YOLO использует оптимизатор SGD для обучения,Начальная скорость обучения составляет 0,01. Автор также использует стратегию затухания косинусного отжига для корректировки скорости обучения. Автор устанавливает количество эпох обучения на100., выбран размер лота на16. существовать во время тренировки,В дополнение к изображениям туманной погоды из коллекции данных VOC-Foggy.,Автор также отправляет исходное четкое изображение приезжатьCFE подсеть, чтобы извлечь четкие характеристики и поделиться им с сетью обнаружения.
существовать во время тренировки,Политика улучшения данных Mosaic отключена.,Поскольку эта стратегия может увеличить сложность обучения сети адаптера функций.,Тем самым влияя на общую производительность всей сети. Сеть адаптера функций сначала обучается в течение 30 эпох. существовать в оставшихся 70 раундах,Веса в модуле передачи функций заморожены.,Потому что по сравнению с задачей обнаружения,Потери для задач адаптации функций сходятся быстрее,Весь процесс обучения может снизить точность результатов обнаружения. Автор существует и обучил авторскую Модель на одном процессоре RTX3090GPU.
Comparison with State-of-the-art Methods
В экспериментах авторов средняя средняя точность (mAP) была выбрана в качестве показателя количественной оценки предлагаемого набора данных VOC-Foggy. Сравнение проводится между десятью различными алгоритмами. Автор выбирает YOLOv8n в качестве базовой линии автора.
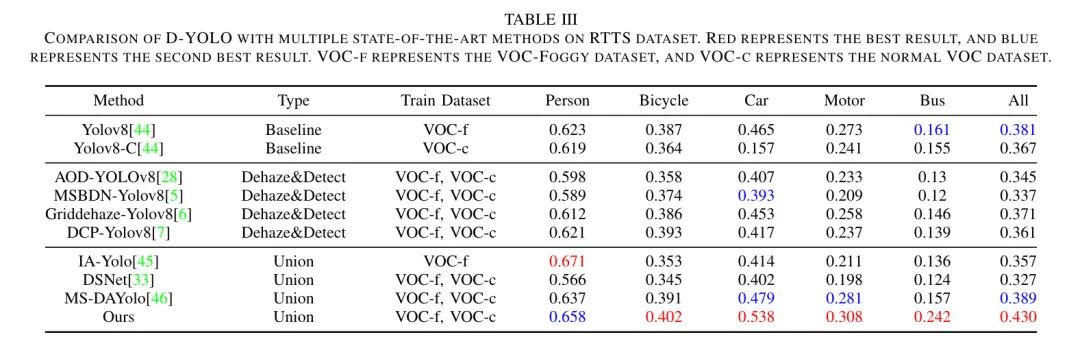
Как показано в таблице 3, выбранные алгоритмы можно разделить на три категории:
- Baseline : Baseline Модель тренируется непосредственно на расплывчатых или четких изображениях.
- Удаление дымки и обнаружение(D&D):Двухэтапный подход к изображению дымки,Сначала пропустите изображение дымки через удаление дымки. Модель,Обработанные изображения затем вводятся в предварительно обученную базовую модель «Приехать».
- соединение:существовать Одновременная тренировка на изображениях дымки для устранения дымкии Задачи обнаружения。
V-C1 Comparisons on Real-World Dataset
Сначала автор протестировал предложенный автором метод на наборе данных RTTS. Как видно из таблицы 3, D-YOLO достигает более высокого значения mAP почти во всех категориях по сравнению с другими 10 современными (SOTA) методами.
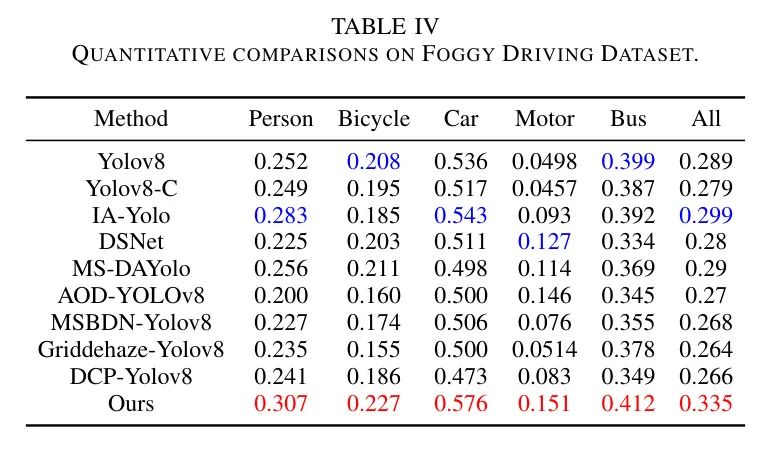
также,По результатам вождения в туманный день данные приведены в Таблице 4.,Авторы по-прежнему отмечают, что приезжатьD-YOLO работает лучше, чем другие методы-кандидаты. Это связано с тем, что модуль адаптации и объединения функций, специально разработанный автором, позволяет сети извлекать богатую информацию из туманных и обычных сцен.,Это имеет решающее значение для преодоления последствий суровых погодных условий.
V-C2 Comparisons on Synthetic Dataset
Также оценивалась производительность авторского набора синтетических данных «Модельсуществовать». Из таблицы 5,Результаты набора Citiscapes-туманные показывают, что,D-YOLOсуществовать имеет больший потенциал для обнаружения объектов в условиях тумана. также,Автор обнаружил, что если второй этап обнаружения Модельсуществовать обучен на изображениях туманной погоды,Независимо от того, какой алгоритм удаления запотевания используется,Результаты испытаний будут серьезно ухудшены. Несоответствия между обучающим набором (туманные изображения) и тестовым набором (размытые изображения) могут указывать на явный сдвиг домена.,В результате снижается обнаружение производительности.
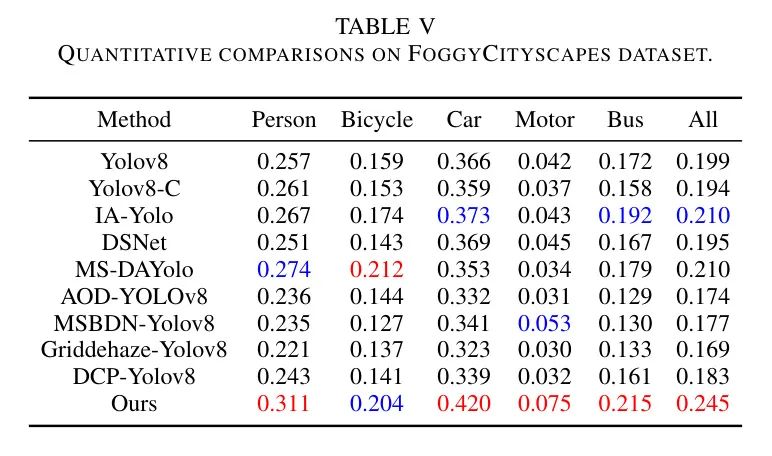
поэтому,существуют авторский эксперимент,Второй этап обнаружения Модель всегда предварительно обучается на туманных изображениях. существование ИА-Йоло,Восстановление изображения и обнаружение объекта выполняются последовательно.,контролируется потерей обнаружения,За задачи восстановления отвечает модуль DIP собственной разработки. существуютDSNet,Противотуманная сеть представляет собой AOD-net.
Qualitive comparison
Для качественного сравнения,Авторы сравнивают D-YOLO с ведущим в настоящее время методом IA-Yolo. Как показано на рисунке 6.,Автор показывает результаты обнаружения деревьев приезжать из набора FoggyCityscapes. Автор может читать приезжать,D-YOLO способен генерировать больше целей обнаружения с более высокой точностью и достоверностью.

существоватьIA-yoloсередина,Задачи обнаружения и восстановления управляются только одной функцией потерь. Однако,Как показано на картинке,Выход IA-Yolo отличается от других моделей.,Это потому, что существование выходит за пределы тумана,IA-Yolo также включает ряд традиционных методов обработки изображений. Это хорошо для обнаружения целей,Но это делает IA-Yoloсуществовать менее надежной основой с точки зрения улучшения определения производительности в туманных погодных условиях.
Efficiency analysis
Авторы также оценили эффективность D-YOLO. Скорость вывода и количество параметров приведены в таблице. Все эксперименты проводились на одном RTX3090 RTTS. разрешение изображения
. Авторы сравнили D-YOLO с различными методами удаления дымки и обнаружения, а также с IA-Yolo.
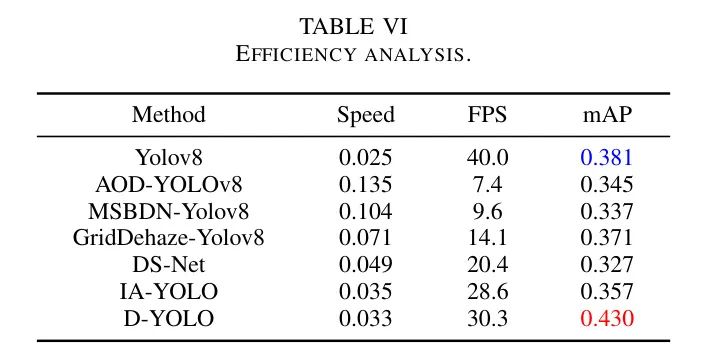
Как показано в Таблице 6,D-YOLOсуществовать имеет большое преимущество в количестве параметров и скорости вывода.,Обеспечиваются прогнозы в реальном времени и повышается производительность.
Experiments on rainy condition
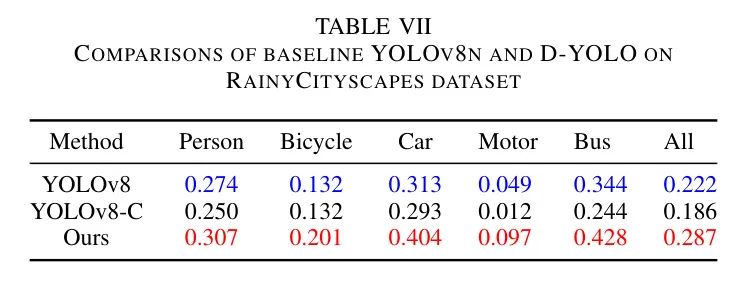
Чтобы дополнительно изучить способность D-YOLO к обобщению в других суровых погодных условиях, автор использовал набор данных RainyCityscapes для оценки способности обнаружения D-YOLO в дождливых условиях. Набор данных RainyCityscapes содержит 10 620 синтетических изображений дождливой погоды и восемь аннотированных целевых категорий (легковые автомобили, поезда, грузовики, мотоциклы, автобусы, велосипеды, велосипедисты и пешеходы). Каждое четкое изображение сочетается с 36 вариациями. В качестве обучающего набора было выбрано 3600 изображений, а в качестве тестового — 1800 изображений.

как упоминалось выше,Во всех аннотациях автор сохраняет только пять упомянутых выше целевых категорий. В сравнения включены предложенные автором бенчмарки Yolov8, Yolov8-Cи и D-YOLO. Как показано в таблице,Производительность D-YOLO лучше, чем у других моделей. На рисунке 7 показаны результаты обнаружения бенчмарка YOLOv8nиD-YOLO. Это можно увидеть,Предложенная автором сеть способна идентифицировать больше целей с более высокими показателями достоверности.,Еще одно доказательство существования неблагоприятных погодных условий,D-YOLO обладает возможностями обобщения.
Ablation Studies and Analysis
Была проведена серия исследований абляции, включая различные комбинации модулей, разные функции потерь и разные веса потерь.
V-G1 Module combination
существуют Автор исследует архитектуру D-YOLO,Автор систематически изучал влияние различных модулей и сети на общую производительность Модели. Сюда входят модуль четкого выделения функций, модуль объединения функций внимания и модуль улучшения функций. Стоит отметить, что,Когда модуль объединения функций внимания опущен,По умолчанию используется архитектура с одной ветвью.
Кроме того, автор также экспериментировал с эффектом ODConv в модуле FA. Авторы сравнили его с обычной сверткой и SEAttention, который имеет структуру, аналогичную ODConv, но включает только веса внимания канала.
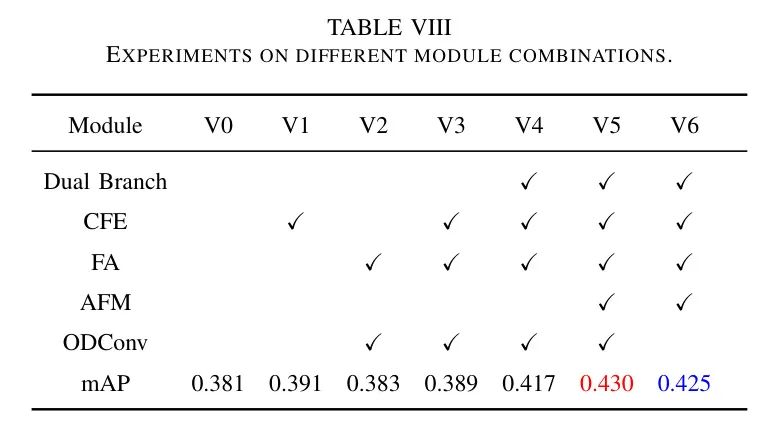
Как показано в Таблице 8, эмпирические результаты авторов указывают на,Модуль объединения функций внимания подсети CFE существует и играет ключевую роль в повышении производительности всей сети. Интеграция этих компонентов значительно повышает эффективность Модели.,Доказывая свою незаменимость при оптимизации конструкции архитектуры обнаружения целей.,Особенно существуют плохие погодные условия.
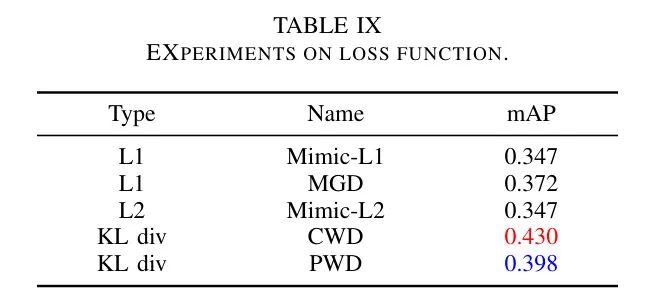
V-G2 Loss function
также,Авторы также сравнили различные функции потерь. существуют Экспериментальный,Авторы рассмотрели пять различных вариантов.,Охватывает дивергенцию L1, L2иKL: MimicLoss, MGDLoss (соответствующая управляемая дистилляция), CWDLoss (канальная дистилляция) и PWDLoss. MimicLossиMGDLoss основан на L1Loss,В то время как CWDиPWD основан на дивергенции Кульбака-Лейблера (KL). Как показано в Таблице IX,Эмпирические данные автора свидетельствуют о том, что,Функция потерь на основе L1 обычно имеет снижение Модель,Это можно объяснить строгим характером потери L1.,это накладывает сильные ограничения,Может отрицательно повлиять на сходимость модели.,привести к Модельпроизводительностьотклонить。
Напротив,Дивергенция KL как мера сходства двух распределений вероятностей,сосредоточьтесь на относительном распределении признаков,и имеют тенденцию смягчать влияние нерелевантной справочной информации. существующая сеть, обученная с учетом ограничений дивергенции KL, демонстрирует повышенную устойчивость к неблагоприятным погодным условиям.,и значительное улучшение точности. существуют среди оцененных убытков,CWDLoss показывает лучшую производительность. Это связано с тем, что между туманным и четким изображением существует смещение домена.,В основном проявляется в различиях размеров каналов. уменьшить масштаб
и
Расстояние между распределениями каналов помогает улучшить производительность модели в условиях тумана.
Iv-B3 Attention mechanism
Автор исследовал влияние различных механизмов внимания в модуле слияния функций внимания и избирательно комбинировал SKC (селективный Kernel свертка)иAFF(Слияние функций внимания)作为作者比较середина的竞争方法。существоватьSKCсередина,Применение внимания к каналу с помощью глобального среднего пула,Затем есть полностью связный слой и функция softmax. существуютAFF,Внимание рассчитывается по двухветвевой структуре.,Извлеките глобальную и локальную информацию соответственно.
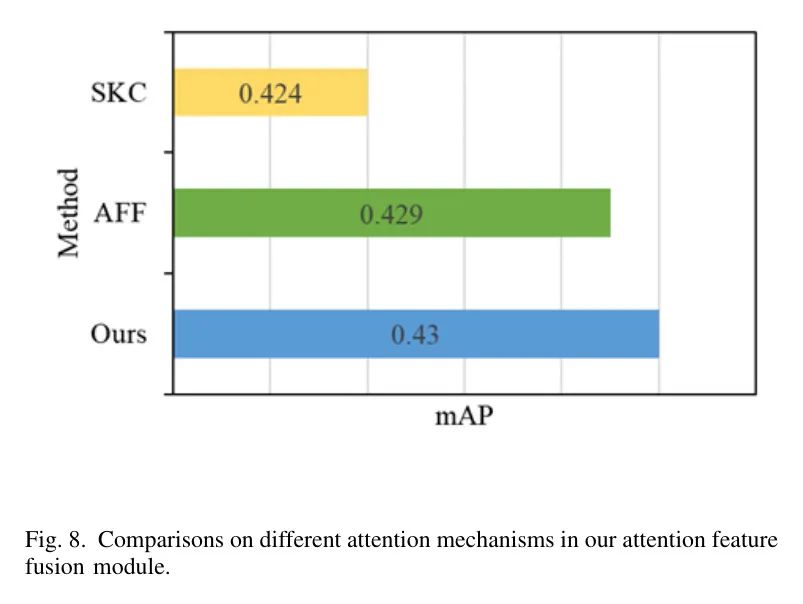
Принято D-YOLO
средний пул,И со структурой короткого замыкания,Полностью связанные слои заменены сверточными слоями.,существования снижает сложность, сохраняя при этом одноветвевую структуру. Эта конструкция позволяет модулю объединения функций внимания автора одновременно обрабатывать информацию о канале и положении.,И вычислительные затраты ниже. Автор существующие РТЦданные сравнивает разные механизмы внимания на съемочной площадке.,Результаты показаны на рисунке 8.,Вниманию автора особенность «Модельсуществовать» превосходит другие конкурирующие методы на mAP.
Loss weight
Чтобы еще больше повысить эффективность обнаружения D-YOLO в суровую погоду, автор использует несколько функций потерь. Потери в этом исследовании в основном состоят из двух частей: потеря обнаружения
потери от матовости
. Соответственно, используйте
и
корректировать
и
пропорция. исследовать
и
Для наилучшего сочетания авторы провели обширные эксперименты с набором данных RTTS. Следует отметить, что помимо фиксированных весовых параметров автор также использует динамический вес со штрафом за градиент.
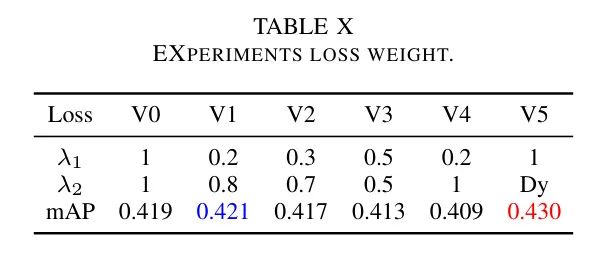
С течением времени, по мере прохождения обучения,
Постепенно коэффициент снижается до 1. Как показывают данные таблицы 10, введение
Значительно помогает улучшить производительность модели, когда
Наиболее эффективные результаты наблюдаются при динамическом взвешивании.
V Conclusion
В этой статье авторы предлагают единую систему внимания для обнаружения объектов в суровых погодных условиях, названную D-YOLO. D-YOLO состоит из трех ключевых компонентов. Подсеть выделения четких признаков отвечает за извлечение деталей без дымки из неухудшенных изображений. Выходные данные модуля извлечения четких признаков отправляются в модуль адаптации признаков, где признаки удаления матовости генерируются посредством адаптации предметной области.
также,Автор также разработал модуль объединения функций внимания.,Он полностью интегрирует функции запотевания и предотвращения запотевания.,Эффективно улучшайте взаимодополняемость и богатство целевых функций. существуют синтетические, качественные и количественные оценки на реальных наборах данных.,D-YOLO превосходит существующие современные алгоритмы. Однако,Д-ЙОЛО существует до сих пор с трудом распознает объекты в очень сложных сценах. будущее,Сочетание трансферного обучения и разработки более эффективных методов адаптации функций станет ценным направлением исследований.
ссылка
[1].D-YOLO a robust framework for object detection in adverse weather conditions.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
