CVPR2024 | Для семантического восприятия реального изображения сверхвысокого разрешения команда Чжан Лея из Гонконгского политехнического института предложила SeeSR, исходный код которого открыт.
Подпишитесь на "AIWalker" и поставьте ему звездочку.
Отныне ИИ никогда не потеряется

https://arxiv.org/abs/2311.16518 https://github.com/cswry/SeeSR
Краткое содержание этой статьи
Получите выгоду от создания априоров благодаря мощным,Распространение предварительно обученного текста в изображение (T2I) Модельсуществовать становится все более популярной при решении реальных задач сверхразрешения изображений.。Однако,Сильное ухудшение качества изображения из-за входного низкого разрешения (LR),Разрушение локальной структуры может привести к неоднозначной семантике изображения.,Это, в свою очередь, приводит к воспроизведению изображений и контента высокого разрешения, которые могут содержать смысловые ошибки.,Таким образом, производительность сверхвысокого разрешения ухудшается.
Чтобы решить эту проблему,В данной статье предлагается метод семантического восприятия.,Создавайте реальные изображения сверхвысокого разрешения с лучшим сохранением семантической точности.。
- первый,Автор тренируетСредство извлечения подсказок с учетом деградации,Даже если существование сильно деградировало из-за,Он также может генерировать точные мягкие и жесткие семантические подсказки.。Жесткие семантические подсказки ссылаются на теги изображений.,Цель существования: улучшить способность T2 Modeliz к местному восприятию.,Мягкие семантические сигналы компенсируют жесткие семантические сигналы.,Предоставить дополнительныеиз Представлять информацию。Эти семантические сигналы могут стимулировать T2I Модель генерирует подробный и семантически точный результат.
- также,существовать в процессе рассуждения,Интегрируйте изображения LR в исходный дискретный шум,Чтобы смягчить диффузию, модель склонна генерировать слишком много случайных деталей из。
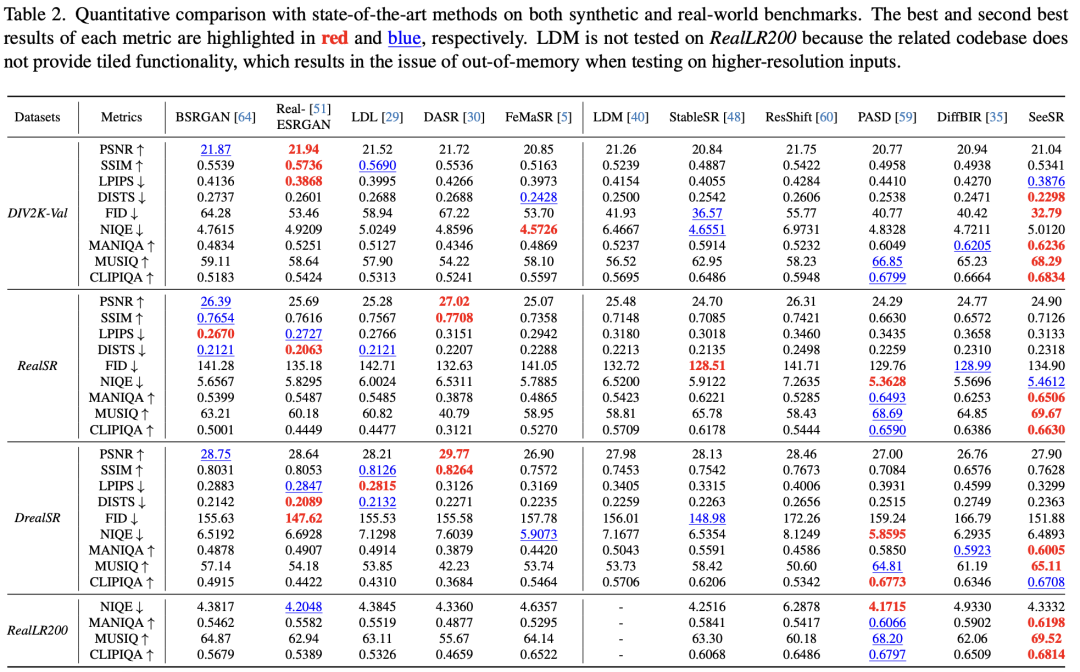
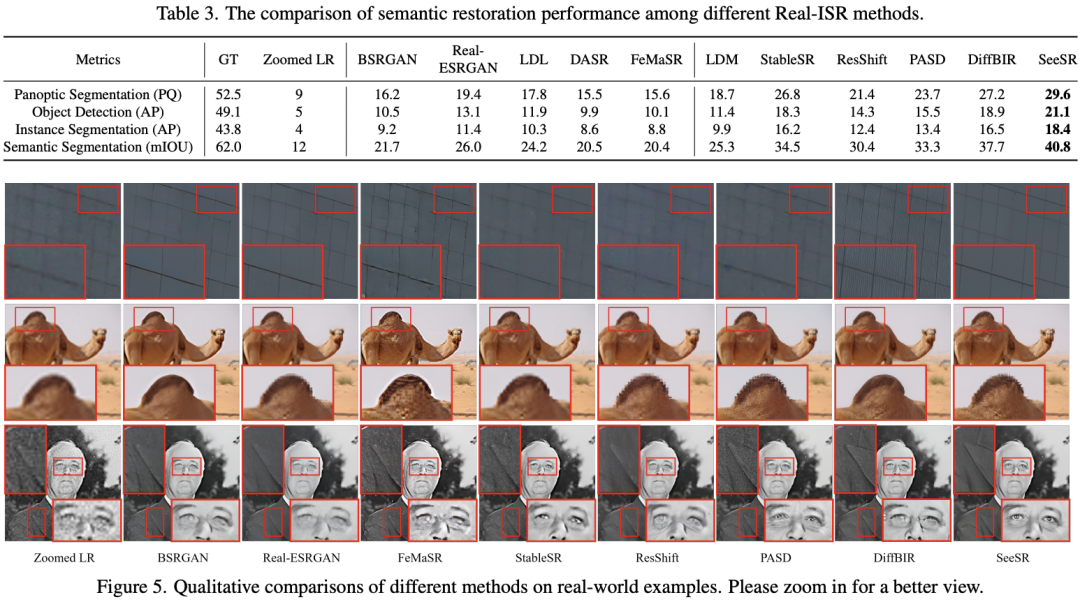
Эксперименты показывают, что авторский метод позволяет воспроизводить более реалистичные детали изображения и лучше сохранять семантику.
Отправная точка этой статьи

Чтобы раскрыть генеративный потенциал предварительно обученных моделей T2I, избегая при этом семантических искажений в выходных данных Real-ISR, авторы исследовали использование трех репрезентативных стилей семантических сигналов, включая стиль классификации, стиль заголовка и стиль меток. В частности, автор использует подсказки в стиле категории, стиле заголовка и стиле тега соответственно.
- Категориальные подсказки предоставляют только одну метку категории для всего изображения, что делает его устойчивым к ухудшению качества изображения из-за его глобального представления.。Однако,Такие подсказки не способны обеспечить семантическую поддержку локальных объектов.,Особенно существование содержит несколько сущностей из сцены. Как показано на рисунке. Как показано на рисунках 1(b) и 1(f).,Извлечение категориальных сигналов из изображений LR и HR с помощью,Real-ISRрезультат практически неотличим от получения изрезультата с использованием пустой подсказки (см. рисунок 1(e)).
- Подсказки к заголовку содержат предложение, описывающее соответствующее изображение.,По сравнению с категоричными подсказками,Предоставляет более подробную информацию。Однако,У него все еще есть два недостатка. первый,из Избыточные предлоги и наречия в таких подсказках могут отвлечь внимание T2I Модельиз на деградацию объекта. Во-вторых,Из-за ухудшения качества изображения LR из-за удара,Семантические ошибки склонны к возникновению. Как показано на рисунке 1(c),Из-за некорректного извлечения заголовка из изображения LR.,T2IМодель неправильно воссоздала птицу вместо корабля.
- Помеченные подсказки предоставляют информацию обо всех категориях объектов на изображении.,По сравнению с подсказками в заголовке,Предоставьте более подробное описание объекта。Даже если это не предусмотренообъектинформация о местоположении,Было обнаружено, что T2IМодель также может выравнивать семантические сигналы с соответствующими областями изображения благодаря своим базовым возможностям семантической сегментации. К сожалению, это,Похоже на: Модель подзаголовка,Маркировка Модель также подвержена ухудшению качества изображения из-за,Это приводит к ошибкам в смысловых подсказках и смысловым искажениям результата реконструкции. Как показано на рисунке 1(d),Неправильная смысловая подсказка «самолет» приводит к искажению реконструкции корабля.
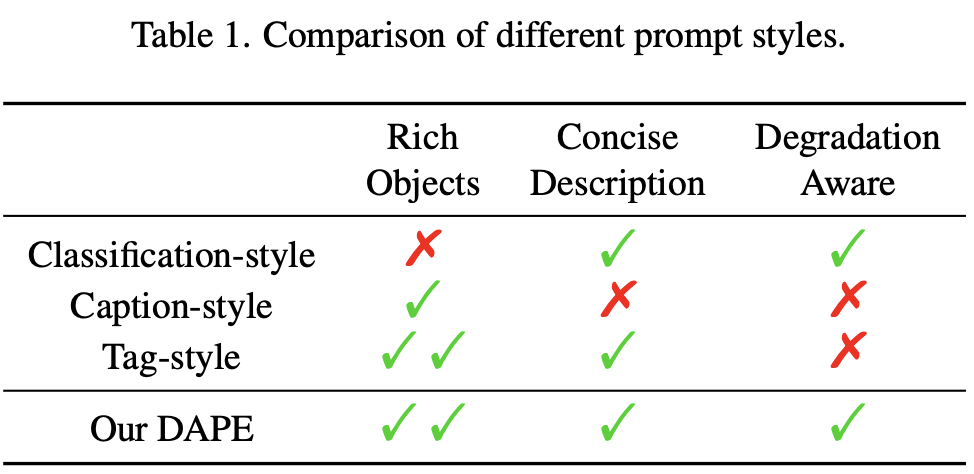
Различные советы и особенности стиля обобщены в разделе «Автор указан 1». Это мотивирует автора,Было бы полезно, если бы автор мог настроить подсказки по стилю тегов для понижения версии программного обеспечения. T2I Модели генерируют высококачественные Real-ISR выход,сохраняя при этом правильностьизрезультатсемантика изображения。
План этой статьи
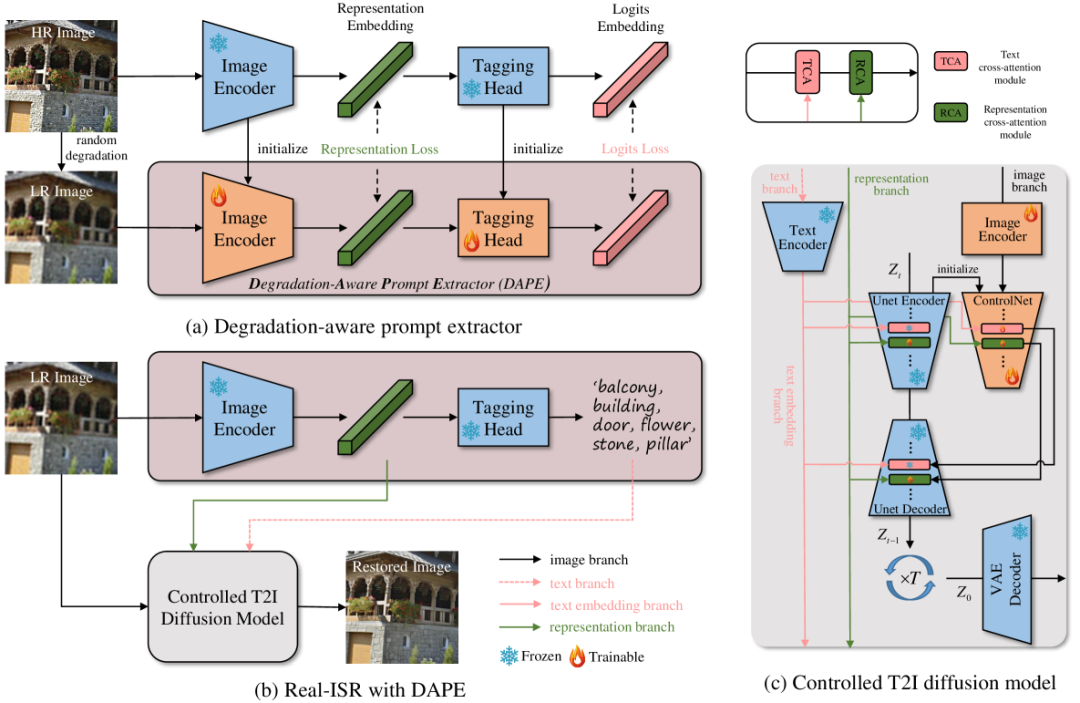
Судя по приведенному выше обсуждению,делатьАвтор рекомендует начинать с LR Извлекайте высококачественные метки из изображений для проведения предварительной подготовки. T2I модель для создания семантически сохраняющей Real-ISR результат。делать者提出изметодизрамка,То есть Semantic Aware SR (см. SR).,Как показано на картинке выше. Обучение SeeSRиз проходит в два этапа:
- существуют первая ступень (рисунок 2(а)),Авторы разработали средство извлечения подсказок с учетом деградации (DAPE), которое состоит из кодера изображений и головки тегов.。Ожидайте исходный тег, используя Модель,Изображение LR из представления объекта и вывода метки может быть как можно ближе к соответствующему изображению HR из представления объекта и вывода метки.
- Научитесь из DAPE копируется на второй этап (рис. 2(b)),Извлечение представлений и меток объектов (в виде текстовых подсказок) из входных изображений LR.,这些特征表示и标签делать为预训练 T2I Моделирование управляющих сигналов для создания визуально приятных и семантически правильных Real-ISR результат。
Во время вывода необходим только второй этап для обработки входного изображения. На рисунке 2(c) показано совместное взаимодействие ветви изображения, ветви представления функций и ветви текстовых подсказок при управлении предварительно обученной моделью T2I.
Напоминание о деградации
DAPE настраивается на основе предварительно обученной модели меток (т. е. ОЗУ). Как показано на рисунке 2(а), изображение HR
Встраивание представлений через выходные данные модели замороженной метки
и встраивание логитов
Служит якорем для наблюдения за обучением DAPE. LR-изображения y получаются путем применения случайной деградации к x и подачи их в обучаемый кодер изображений и маркировочную головку. Чтобы сделать DAPE устойчивым к ухудшению изображения, мы заставляем встраивание представления и встраивание логитов ветки LR быть близкими к встраиванию ветки HR.
После тренировки,DAPE Просто играй из LR играет ключевую роль в извлечении надежных семантических подсказок из изображений.。Советы можно разделить на две категории:Жесткое напоминание(то есть из заголовка тегаизтекст метки)и мягкие подсказки(то есть из кодера изображенийиз Представляет встраивание)。Как показано на картинке。Как показано на картинке2(b)и2(c)показано,Жесткие подсказки передаются непосредственно во встроенный в T2IМодель кодировщик стоп-текста.,улучшить свое местное понимание. Насыщенность текстовых подсказок контролируется заранее заданным пороговым значением. Если порог слишком высок,Точность категорий прогнозов повысится,Но это повлияет на скорость отзыва,наоборот. поэтому,Используйте подсказки с мягкими метками, чтобы компенсировать ограничения жестких подсказок.,Не зависит от порога,Избегайте проблемы низкой информационной энтропии, вызванной подсказками с жесткими категориями.
См. обучение SR
Рисунок 2(c) иллюстрирует подробную структуру модели контролируемой диффузии T2I. Учитывая успешное применение ControlNet при генерации условного изображения, мы используем его в качестве контроллера нашей модели T2I для целей Real-ISR. Конкретно,
- Мы проведем предварительное обучение SD Модельсерединаиз Unet Кодировщик клонируется как обучаемая копия для инициализации. ControlNet。
- Чтобы включить мягкие сигналы в процесс распространения, мы используем PASD Для изучения семантического руководства предлагается механизм перекрестного внимания. Добавьте модуль Representation Cross Attention (RCA) в Unet в месте после модуля «Перекрестное внимание к тексту» (TCA). Обратите внимание, что случайная инициализация RCA Модули и энкодеры клонируются одновременно.
- Помимо текстовой ветки и ветки представления, для реконструкции также необходима ветка изображений. HR играть роль в имидже. мы будем LR Изображение передается через обучаемый кодер изображений для получения LR Отправьте существующее изображение и импортируйте его в Контрол Нет. Структура обучаемого кодера изображений такая же, как и структура серединаiz.
Вложение LR времени вывода
SD Ждите предварительные тренировки T2IСуществовать Модель Фаза обучения не полностью преобразует изображение в случайный гауссов шум. Однако,существовать в процессе рассуждения,Большинство существующих методов SDizReal-ISR используют случайный гауссов шум в качестве отправной точки.,привести кРазличия в обработке шума между обучением и выводом。

существовать Real-ISR В ходе миссии мы заметили, что эта разница заставляет Модель воспринимать деградацию как необходимость улучшения содержания, особенно гладких областей, таких как существование, как показано на рисунке. 3 из顶行показано。Чтобы решить эту проблему,Мы предлагаем встроить задержку LR непосредственно в исходный случайный гауссов шум согласно планировщику обучающего шума.。Эта стратегия работает для большинства, основываясь на SD из Real-ISR метод. Как показано на картинке 3 из底行показано,Предлагаемая стратегия внедрения LR (LRE) значительно устраняет несогласованность между обучением и выводом.,Обеспечивает более точную отправную точку для распространения Модели.,Это подавляет большое количество артефактов в области неба.。
Эксперимент в этой статье





Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
