CVPR 2024 | Обзор направлений улучшения диффузионной модели на основе 6 статей
1、Accelerating Diffusion Sampling with Optimized Time Steps

Диффузионно-вероятностные модели (DPM) показали замечательную эффективность при создании изображений с высоким разрешением, но их эффективность выборки все еще нуждается в повышении, поскольку обычно требуется большое количество шагов выборки. Последние достижения в применении решателей ОДУ более высокого порядка к DPM позволяют генерировать высококачественные изображения с меньшим количеством шагов выборки. Однако большинство методов выборки по-прежнему используют одинаковые временные шаги, что неоптимально при использовании небольшого количества шагов.
Чтобы решить эту проблему, предлагается общая структура для разработки задачи оптимизации, которая ищет более подходящий временной шаг для конкретного численного решателя ОДУ в DPM. Цель этой задачи оптимизации — минимизировать расстояние между фундаментальным решением и соответствующим численным решением. Эффективное решение этой задачи оптимизации занимает не более 15 секунд.
Обширные эксперименты с DPM в пиксельном и скрытом пространстве, безусловной и условной выборке показывают, что в сочетании с современным методом выборки UniPC в сочетании с равномерным временным шагом для таких данных, как CIFAR-10. и ImageNet Set, согласно оценке FID, оптимизация временного шага значительно повышает производительность генерации изображений.
2、DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models

Создание изображений высокого разрешения с использованием диффузионных моделей требует больших вычислительных затрат, что приводит к неприемлемой задержке для интерактивных приложений. DistriFusion предлагается решить эту проблему, используя параллелизм между несколькими графическими процессорами. Метод разделяет входные данные модели на несколько патчей и назначает каждый графическому процессору. Однако простая реализация этого алгоритма нарушит взаимодействие между патчами и приведет к потере точности, а учет этого взаимодействия приведет к огромным накладным расходам на связь.
Чтобы решить эту дилемму, наблюдается большое сходство между входными данными соседних этапов диффузии и предлагается параллелизм участков смещения, который использует последовательный характер процесса диффузии путем повторного использования предварительно вычисленной карты признаков предыдущего временного шага, поскольку текущий шаг обеспечивает контекст . Таким образом, методы поддерживают асинхронную связь и могут передаваться по конвейеру посредством вычислений. Обширные эксперименты показывают, что этот метод можно применить к последнему Stable Diffusion XL без потери качества и добиться ускорения до 6,1 раз по сравнению с устройством NVIDIA A100. Исходный код уже открыт по адресу: https://github.com/mit-han-lab/distrifuser.
3、Balancing Act: Distribution-Guided Debiasing in Diffusion Models
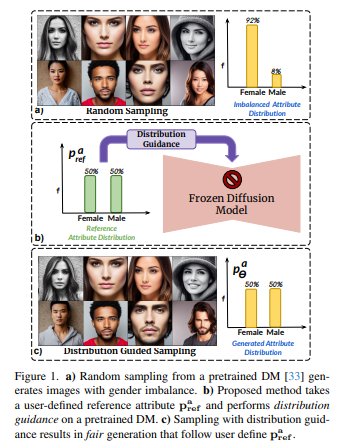
Модели диффузии (DM) отражают смещение, присутствующее в наборе обучающих данных. Особое беспокойство вызывает случай с лицами, когда DM отдают предпочтение определенным демографическим группам перед другими (например, женщины перед мужчинами). В этой работе предлагается метод устранения смещения DM, не полагаясь на дополнительные данные или переобучение модели.
В частности, предлагается метод Distribution Guidance, который заставляет сгенерированное изображение следовать заданному распределению атрибутов. Для достижения этой цели скрытые функции шумоподавления UNet созданы с использованием богатой семантики групп населения, и эти функции можно использовать для управления созданием debias. Обучите предиктор распределения атрибутов (ADP), небольшой многоуровневый персептрон, который сопоставляет скрытые функции с распределениями атрибутов. ADP обучается с использованием псевдометок, созданных существующими классификаторами атрибутов. Введенные Руководство по распределению и ADP обеспечивают справедливое производство.
Этот метод уменьшает смещение по одному/множеству атрибутов и обеспечивает значительно лучшую базовую производительность, чем предыдущие методы, с точки зрения моделей безусловного и текстового распространения. Кроме того, предлагается следующая задача по обучению классификатора справедливых атрибутов путем генерации данных, которые перебалансируют обучающий набор.
4、Few-shot Learner Parameterization by Diffusion Time-steps
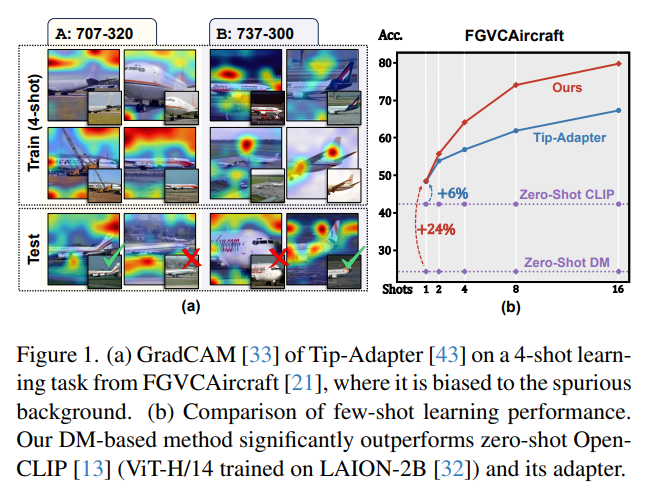
Даже при использовании больших мультимодальных базовых моделей обучение в несколько этапов остается сложной задачей. Без соответствующего индуктивного смещения трудно сохранить тонкие атрибуты класса, удаляя при этом заметные визуальные атрибуты, не имеющие отношения к метке класса.
Было обнаружено, что временные шаги модели диффузии (DM) могут изолировать тонкие атрибуты класса, т. Е. Поскольку прямая диффузия добавляет шум к изображению на каждом временном шаге, тонкие атрибуты часто теряются на более ранних временных шагах, чем существенные атрибуты. На основании этого предлагается обучающийся алгоритм с несколькими шагами по времени (TiF). Адаптеры низкого ранга для конкретного класса обучены для DM с текстовым условием, чтобы компенсировать недостающие атрибуты, позволяя точно реконструировать исходное изображение из зашумленного изображения с учетом подсказок. Таким образом, на меньших временных шагах адаптеры и подсказки по сути представляют собой параметризации с лишь тонкими свойствами класса. Для тестового изображения эту параметризацию можно использовать для извлечения только тонких атрибутов класса для классификации. При выполнении различных мелкодетализированных и настраиваемых задач обучения, состоящих из нескольких шагов, учащийся TiF значительно превосходит OpenCLIP и его адаптеры по производительности.
5、Structure-Guided Adversarial Training of Diffusion Models

Модели диффузии продемонстрировали превосходную эффективность в различных генеративных приложениях. Существующие модели в основном сосредоточены на моделировании распределения данных посредством минимизации взвешенных потерь, но их обучение в основном делает упор на оптимизацию на уровне экземпляра, игнорируя ценную структурную информацию в каждом мини-пакете данных.
Чтобы устранить это ограничение, введен метод состязательного обучения диффузионных моделей (SADM), ориентированный на структуру. Заставляет модель изучать структуру многообразия между выборками в каждом обучающем пакете. Чтобы гарантировать, что модель отражает реальную структуру многообразия в распределении данных, предлагается новый дискриминатор структуры, позволяющий различать реальную структуру многообразия и сгенерированную структуру многообразия, играя в игру с генератором диффузии посредством состязательного обучения.
SADM значительно улучшает существующие диффузионные преобразователи, превосходя существующие методы на 12 наборах данных в задачах генерации изображений и междоменной точной настройки для генерации изображений с учетом классов с разрешениями 256×256 и 512×512. Новые записи FID составляют 1,58 и 2,11 соответственно. .
6、Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models

Большинство моделей диффузии предполагают, что обратный процесс подчиняется распределению Гаусса. Однако это приближение не было строго проверено в особых точках (t=0 и t=1), особенно в сингулярностях. Неправильное обращение с этими точками может вызвать проблемы со средней яркостью в приложениях и ограничить создание изображений с чрезмерной яркостью или глубокой темнотой.
В данной статье рассматривается этот вопрос с теоретической и практической точки зрения. Во-первых, устанавливается граница погрешности аппроксимации обратного процесса и демонстрируются его гауссовы характеристики на сингулярных шагах по времени. На основе этого теоретического понимания подтверждается, что особая точка при t=1 может быть устранена условно, тогда как особая точка при t=0 является внутренним свойством. На основе этих важных выводов предлагается новый метод plug-and-play SingDiffusion для обработки выборки начальных сингулярных временных шагов, который может не только эффективно решить проблему средней яркости без дополнительного обучения, но и улучшить возможности их генерации, тем самым достигая значительно более низкий показатель FID. https://github.com/PangzeCheung/SingDiffusion



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
