CVPR 2024 | Краткое описание 11 управляемых винсентийских картинок! Преобразование текста в изображение на основе диффузионной модели
1、ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models

Генерации 3D-ресурсов уделяется много внимания, вдохновленное недавним успехом создания 2D-контента с текстовым управлением. Существующие методы преобразования текста в 3D используют предварительно обученные модели диффузии текста в изображение для решения проблем оптимизации или точной настройки. синтетические данные, что часто приводит к созданию нефотореалистичных 3D-объектов без фона.
В этой статье предлагается использовать предварительно обученную модель преобразования текста в изображение в качестве априорной и научиться генерировать многовидовые изображения из одного процесса шумоподавления на реальных данных. В частности, объемный 3D-рендеринг и межкадровые уровни внимания интегрированы в каждый блок существующей модели преобразования текста в изображение. Кроме того, авторегрессионная генерация предназначена для визуализации более согласованных трехмерных изображений с любой точки зрения. Модель обучена с использованием набора данных реальных объектов и продемонстрировала свою способность генерировать экземпляры с различными высококачественными формами и текстурами.
Полученные результаты являются последовательными и имеют хорошее визуальное качество по сравнению с существующими методами (снижение FID на 30% и снижение KID на 37%). https://lukashoel.github.io/ViewDiff/
2、NoiseCollage: A Layout-Aware Text-to-Image Diffusion Model Based on Noise Cropping and Merging
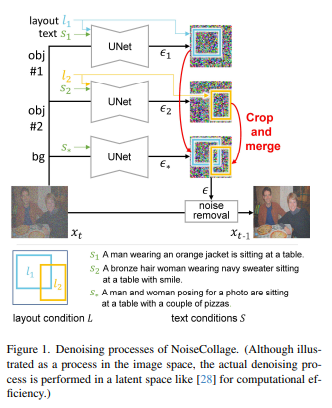
Генерация текста в изображение с учетом макета — это задача создания многообъектных изображений, которые отражают условия макета и условия текста. Текущие модели распространения текста в изображения с учетом макета по-прежнему страдают от некоторых проблем, включая несоответствие между текстом и условиями макета и снижение качества генерируемых изображений.
В этой статье для решения этих проблем предлагается новая модель диффузии текста в изображение с учетом макета, называемая NoiseCollage. В процессе шумоподавления NoiseCollage независимо оценивает шум каждого объекта, затем обрезает и объединяет их в один шум. Эта операция помогает избежать несоответствия условий, другими словами, она помещает нужный объект в нужное место.
Результаты качественной и количественной оценки показывают, что NoiseCollage превосходит по производительности некоторые современные модели. Также было показано, что NoiseCollage можно интегрировать с ControlNet, используя края, эскизы и скелеты поз в качестве дополнительных условий. Результаты экспериментов показывают, что эта интеграция может повысить точность компоновки ControlNet. https://github.com/univ-esuty/noisecollage
3、Discriminative Probing and Tuning for Text-to-Image Generation

Несмотря на достижения в области генерации текста в изображение, предыдущие методы часто страдают от проблем несовпадения текста и изображения, таких как путаница отношений в сгенерированных изображениях. Существующие решения включают операции перекрестного внимания для лучшего понимания комбинаций или интеграцию больших языковых моделей для улучшения планирования помещений. Однако возможности выравнивания, присущие моделям T2I, все еще недостаточны.
Рассматривая связь между генеративным и дискриминативным моделированием, мы предполагаем, что дискриминационная способность моделей T2I может отражать их возможности выравнивания текста и изображения во время генеративного процесса. Ввиду этого рекомендуется повысить различительную способность моделей T2I для достижения более точного выравнивания текста и изображения при генерации.
Предлагается дискриминационный адаптер, основанный на модели T2I, для изучения их дискриминационных возможностей в двух репрезентативных задачах и использования дискриминационной точной настройки для улучшения калибровки текста и изображения. Преимущество дискриминационного адаптера заключается в том, что механизм самокорректировки может использовать дискриминантный градиент для лучшего согласования сгенерированного изображения с текстовыми подсказками во время вывода.
Комплексная оценка трех эталонных наборов данных (включая сценарии распределения и выхода из распределения) демонстрирует превосходную генеративную эффективность метода. В то же время он обеспечивает самые современные дискриминационные характеристики при решении двух дискриминационных задач по сравнению с другими генеративными моделями. https://github.com/LgQu/DPT-T2I
4、Dysen-VDM: Empowering Dynamics-aware Text-to-Video Diffusion with LLMs
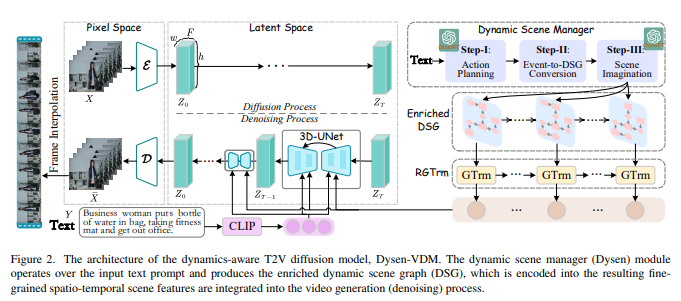
Синтез текста в видео (T2V) привлекает все большее внимание в научных кругах, где новая диффузионная модель (DM) оказалась более эффективной по производительности, чем предыдущие методы. Хотя существующие современные DM хорошо справляются с созданием видео высокого разрешения, они все еще имеют значительные ограничения при моделировании сложной временной динамики (например, неупорядоченное движение, грубое видеодвижение).
В этой работе изучаются методы улучшения восприятия DM динамики видео для генерации высококачественного T2V. Вдохновленный человеческой интуицией, разработан новый модуль динамического менеджера сцен (называемый Dysen), включающий (шаг 1) извлечение ключевых действий в соответствующем временном порядке из входного текста (шаг 2) преобразование плана действий в граф динамической сцены (DSG). представление и (шаг 3) обогатить сцену в DSG, чтобы предоставить достаточные и разумные детали. Используя существующие мощные LLM (такие как ChatGPT) для контекстного обучения, Dysen достигает (почти) динамического временного понимания на человеческом уровне. Наконец, видео DSG с богатой детализацией боевых сцен кодируется в мелкозернистые пространственно-временные функции и интегрируется в базовый T2V DM для генерации видео.
Эксперименты на популярном наборе данных T2V показывают, что Dysen-VDM всегда превосходит предыдущие методы по значительным преимуществам, особенно в сложных боевых сценах.
5、Face2Diffusion for Fast and Editable Face Personalization

Персонализация лиц направлена на вставку конкретных лиц с изображений в предварительно обученный текст в модели распространения изображений. Однако предыдущие методы по-прежнему имеют проблемы с сохранением сходства идентичности и редактируемости, поскольку они подходят для обучающих выборок.
В этой статье предлагается метод Face2Diffusion (F2D) для легко редактируемой персонализации лица. Основная идея F2D — удалить из процесса обучения информацию, не имеющую отношения к личности, чтобы предотвратить проблемы переобучения и улучшить редактируемость закодированных лиц. F2D содержит следующие три новых компонента: 1) Многомасштабный кодировщик идентификационных данных обеспечивает четкое разделение идентификационных функций, сохраняя при этом преимущества многомасштабной информации, тем самым улучшая разнообразие поз камеры. 2) Управление выражением лица отделяет выражение лица от личности, улучшая управляемость выражения лица. 3) Регуляризация шумоподавления на основе категорий побуждает модель научиться шумоподавлять лица, тем самым улучшая текстовое выравнивание фона.
Обширные эксперименты с набором данных FaceForensics++ и различными подсказками показывают, что этот метод обеспечивает лучший баланс между идентичностью и точностью текста по сравнению с предыдущими современными методами. https://github.com/mapooon/Face2Diffusion
6、LeftRefill: Filling Right Canvas based on Left Reference through Generalized Text-to-Image Diffusion Model

В этой статье предлагается LeftRefill, новый метод, который эффективно использует большие модели диффузии текста в изображение (T2I) для синтеза изображений на основе ссылок. Как следует из названия, LeftRefill объединяет эталонное представление и целевое представление по горизонтали в качестве общего входного файла. Эталонное изображение занимает левую сторону, а целевой холст — правую. Затем LeftRefill рисует целевой холст справа на основе левой ссылки и конкретных инструкций по задаче. Эта форма задачи похожа на восстановление контекста, похожее на работу человека-художника.
Эта новая форма эффективно изучает структурные и текстурные соответствия между эталоном и целью без необходимости использования дополнительных кодировщиков изображений или адаптеров. Информация о задачах и представлениях вводится через модуль перекрестного внимания в модели T2I, а эталонная возможность нескольких представлений дополнительно демонстрируется через переработанный модуль самообслуживания. Это позволяет LeftRefill выполнять согласованную генерацию в качестве общей модели без необходимости тонкой настройки или модификации модели во время тестирования. Таким образом, LeftRefill можно рассматривать как простую и унифицированную структуру для решения проблемы синтеза по ссылкам.
Например, LeftRefill используется для решения двух разных задач: восстановления на основе эталонов и синтеза новой перспективы на основе предварительно обученной модели StableDiffusion. https://github.com/ewrfcas/LeftRefill
7、InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models

Крупномасштабная модель диффузии изображения в текст (T2I) демонстрирует способность генерировать связные изображения на основе текстовых описаний, обеспечивая широкий спектр приложений для создания контента. Несмотря на то, что существует некоторый контроль над такими аспектами, как положение объекта, поза и контуры изображения, все еще существует пробел в управлении взаимодействием между объектами в сгенерированном контенте. Управление взаимодействием между объектами в сгенерированных изображениях может привести к значимым приложениям, таким как создание реалистичных сцен с интерактивными персонажами.
В этой работе изучается проблема согласования моделей диффузии T2I с информацией о взаимодействии человека и объекта (HOI), которая состоит из троичных меток (человек, действие, объект) и соответствующих ограничивающих рамок. Предлагается модель управления взаимодействием под названием InteractDiffusion, которая расширяет существующую предварительно обученную модель диффузии T2I, чтобы обеспечить лучший условный контроль взаимодействий. В частности, информация HOI токенизируется, и взаимосвязь между ними изучается посредством интерактивного внедрения. Уровень условного самообслуживания, который обучает токены HOI визуальным токенам, обучается для лучшего кондиционирования существующих моделей диффузии T2I.
Модель обладает способностью контролировать взаимодействие и положение и намного превосходит существующие базовые модели по показателям обнаружения HOI, а также по большей точности FID и KID. https://jiuntian.github.io/interactdiffusion/
8、MACE: Mass Concept Erasure in Diffusion Models

Быстрое распространение крупномасштабных моделей распространения текста в изображения вызвало растущую обеспокоенность по поводу их потенциального неправильного использования для создания вредного или вводящего в заблуждение контента. В этом документе предлагается структура тонкой настройки под названием MACE для задачи стирания концепции MASS (MACE). Эта задача предназначена для предотвращения создания моделью изображений с нежелательными понятиями при появлении соответствующего запроса. Существующие методы исключения понятий обычно позволяют обрабатывать менее пяти понятий, при этом трудно найти баланс между устранением синонимов понятий (широта) и сохранением нерелевантных понятий (специфичность). Напротив, MACE изменил ситуацию, успешно расширив объем исключения до 100 концепций и добившись эффективного баланса между общностью и конкретикой. Это достигается за счет использования уточнения перекрестного внимания в закрытой форме и тонкой настройки LoRA, совместно исключая информацию из нежелательных концепций.
Более того, MACE объединяет несколько LoRA без взаимного вмешательства. MACE тщательно оценивается по четырем различным задачам: устранение объектов, устранение знаменитостей, устранение явного контента и устранение художественного стиля. Результаты показывают, что MACE превосходит предыдущие методы во всех задачах оценки. https://github.com/Shilin-LU/MACE
9、MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis

предложить задачу создания нескольких экземпляров (MIG) для одновременного создания нескольких экземпляров с разнообразным управлением в одном изображении. Учитывая предопределенный набор координат и соответствующие им описания, задача состоит в том, чтобы гарантировать, что сгенерированные экземпляры расположены точно в указанных местах и чтобы все свойства экземпляров соответствовали соответствующим описаниям. Это расширяет сферу текущих исследований генерации единичных экземпляров, поднимая их до более разнообразного и практического измерения.
Вдохновленный идеей «разделяй и властвуй», для решения задач MIG представлен инновационный подход, называемый контроллером многоэкземплярной генерации (MIGC). Сначала задача MIG разбивается на несколько подзадач, каждая из которых предполагает затенение одного экземпляра. Для обеспечения точной раскраски каждого экземпляра введен механизм расширенного внимания. Наконец, все цветные экземпляры объединяются, предоставляя необходимую информацию (SD) для точного создания стабильного распространения между несколькими экземплярами. Для оценки эффективности генеративной модели при выполнении задачи MIG предоставляются тест COCO-MIG и процесс оценки.
Обширные эксперименты проводятся с предлагаемым тестом COCO-MIG, а также с различными широко используемыми тестами. Результаты оценки демонстрируют отличные возможности управления моделью с точки зрения количества, местоположения, атрибутов и взаимодействий. https://migcproject.github.io/
10、One-dimensional Adapter to Rule Them All: Concepts, Diffusion Models and Erasing Applications

Широкое использование коммерческих моделей диффузии и моделей распространения с открытым исходным кодом (DM) при преобразовании текста в изображение привело к снижению рисков и предотвращению нежелательного поведения. Все существующие в академических кругах методы исключения концепций основаны на полной настройке параметров или на основе спецификаций, из-за чего наблюдаются следующие проблемы: 1) Изменения генерации в направлении эрозии: дрейф параметров в процессе целевого исключения приведет к изменениям в процесс генерации и потенциальная деформация даже в той или иной степени разрушают другие концепции, что более очевидно в случае исключения нескольких концепций. 2) Невозможность переноса и неэффективное развертывание: устранение предыдущей концепции, специфичной для модели, препятствует гибкому сочетанию концепций и бесплатное использование других моделей Transfer, что приводит к линейному росту стоимости развертывания по мере увеличения количества сценариев развертывания.
Чтобы добиться неинтрузивного, точного, настраиваемого и переносимого исключения, структура исключения построена на 1D-адаптере, позволяющем одновременно исключать несколько концепций из большинства DM в нескольких сценариях применения исключения. Концепция. Полупроницаемые структуры вводятся в любую твёрдую ткань в виде мембраны (СПМ), чтобы научиться целенаправленному устранению и эффективно смягчить изменения и явления эрозии с помощью новой стратегии тонкой настройки скрытого закрепления. После получения SPM можно гибко комбинировать и вставлять в другие DM без специальной доработки, а также своевременно и эффективно адаптировать к различным сценариям. В процессе генерации механизм активации транспорта динамически регулирует проницаемость каждого SPM в ответ на различные входные сигналы, еще больше сводя к минимуму влияние на другие концепции.
Количественные и качественные результаты примерно по 40 концепциям, 7 DM и 4 приложениям по исключению демонстрируют превосходные возможности SPM по исключению. https://lyumengyao.github.io/projects/spm
11、FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models

В последние годы был достигнут значительный прогресс в разработке генеративных моделей преобразования текста в изображение. Оценка качества создаваемых моделей является одним из важных этапов процесса разработки. Процесс оценки может потребовать значительных вычислительных ресурсов, что делает нецелесообразным проведение необходимой регулярной оценки производительности модели (например, мониторинг прогресса обучения). Поэтому стремятся повысить эффективность оценки путем выбора репрезентативного подмножества набора данных текстового изображения.
В этой статье систематически изучаются варианты дизайна, включая критерии выбора (особенности текстуры или метрики на основе изображений) и степень детализации выбора (уровень сигнала или уровень набора). Обнаружив, что выводы из предыдущей работы по выбору подмножества обучающих данных не применимы к этой проблеме, был предложен FlashEval, алгоритм итеративного поиска, предназначенный для оценки выбора данных. Продемонстрируйте эффективность FlashEval при ранжировании моделей диффузии с различными конфигурациями, включая архитектуру, уровень квантования и сэмплер, в наборах данных COCO и DiffusionDB. Подмножество из 50 элементов, в котором осуществляется поиск, обеспечивает качество оценки, сравнимое с подмножеством из 500 элементов, выбранным случайным образом для аннотаций COCO на невидимых моделях, что приводит к десятикратному ускорению оценки. Сжатые подмножества этих часто используемых наборов данных будут выпущены, чтобы облегчить разработку и оценку алгоритмов распространения, а FlashEval будет открыт с открытым исходным кодом в качестве инструмента для сжатия будущих наборов данных.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
