CVPR 2024 | Baidu предлагает ViT-CoMer, новую визуальную основу, обновляющую задачу плотного прогнозирования SOTA
Поделиться этой статьей CVPR 2024 论文ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions,Зависит от Байду Предложите новую визуальную основу ВИТ-Ко Мер, обновление интенсивных задач прогнозирования SOTA。

- Ссылка на документ: https://arxiv.org/pdf/2403.07392.pdf.
- Адрес с открытым исходным кодом: https://github.com/Traffic-X/ViT-CoMer (приглашаем вас попробовать и поставить звездочку)
1. Эффект алгоритма
1.1. Результат взрыва
Эффект обнаружения SOTA
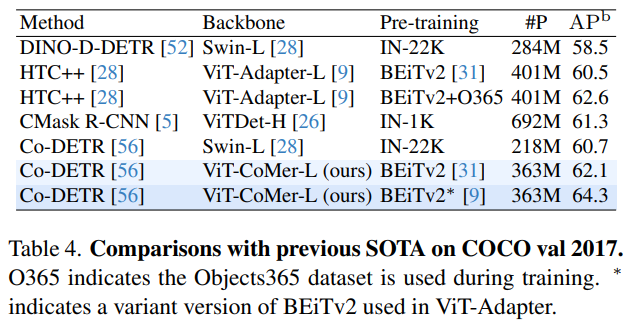
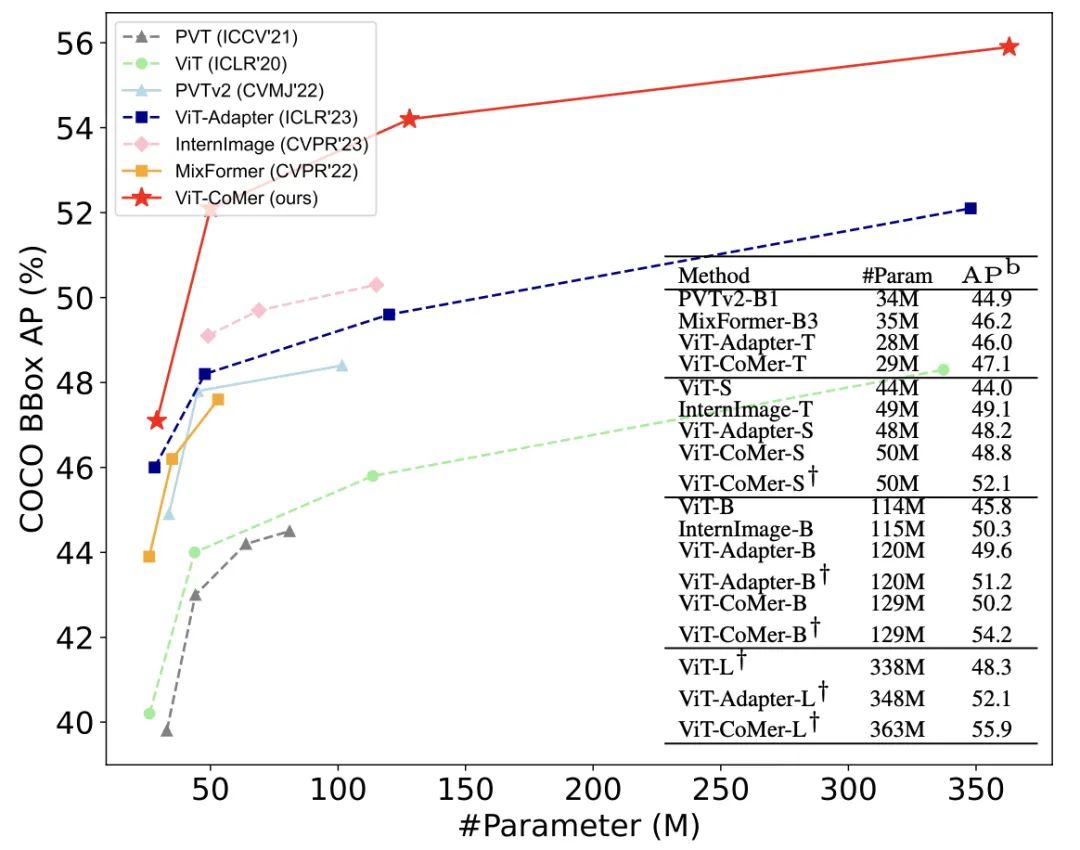
Без добавления дополнительных обучающих данных Ви Т-Ко Мер-Л хорошо справляется с тестом обнаружения целей. COCO Достигнуто 64,3% на val2017 AP。ранее протестированоSOTAалгоритмдляCo-DETR,без добавления дополнительныхданныечасCo-DETR的效果для60.7% AP использует ViT-CoMer для замены исходной магистрали (Swin-L) и использует BEiTv2*, предоставляемый ViT-Adapter, в качестве предварительного обучения. Его эффект обнаружения может достигать 64,3%. AP по сравнению с другими алгоритмами того же размера, ViT-CoMer, показывает лучшие результаты.
Эффект сегментации SOTA
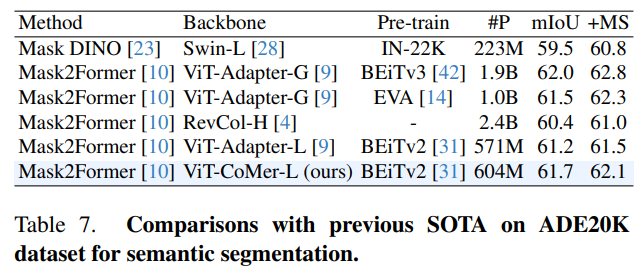
Ви Т-Ко Мер-Л в семантической сегментации benchmark ADE20K Получил 62,1% по валу mIoU, эффект SOTA с менее чем 1 миллиардом параметров.на основеMask2Formerразделениеалгоритм,Сравнение ViT-CoMer и других продвинутых магистральных сетей (таких как RevCol-H),Ви Т-Адаптер-Л и др.),Это видно из таблицы 7.,в аналогичном размере,«ВИТ-Ко Мералгоритм» добился СОТА-эффекта,Даже сравним с другими более крупными моделями (Ви Т-Адаптер-Г).,параметр 1Б)
Маленький размер, большая энергия
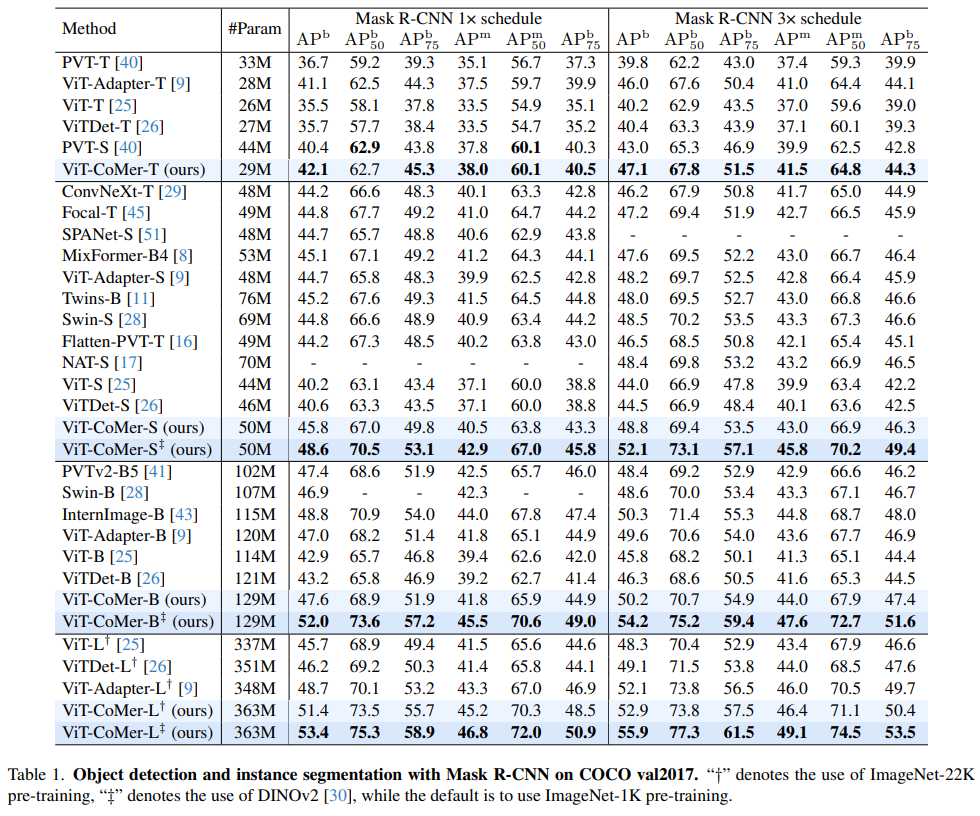
Малый можно использовать и как Большой, Ви Т-Ко Мер-С (1/6 Параметры Ви Т-Л ) для достижения результатов обнаружения, сравнимых с Ви Т-Л.на основе经典的Mask В системе обнаружения R-CNN мы сравнили влияние на набор данных COCO по томам и магистральным сетям и были удивлены, обнаружив, что ViT-CoMer-Small (только 1/6 параметров ViT-Large) может достичь того же эффекта. как ViT-Large, а при использовании более продвинутого предварительного обучения эффект улучшается за счет разницы поколений.
Различные шкалы имеют сильные эффекты
«Ви Т-Ко Мер» может достигать эффектов SOTA при различных масштабах параметров.同样на основеMask-RCNNОбнаружениерамка,Мы сравнили влияние различных магистралей на набор данных COCO.,Не сложно найти,Производительность ViT-CoMer превосходит другие продвинутые магистральные сети при различных масштабах параметров и различных конфигурациях обучения.
1.2.Производительность
Эффективность обучения и push-уведомлений очень мощная (содержимое Rebuttle будет добавлено в github позже)
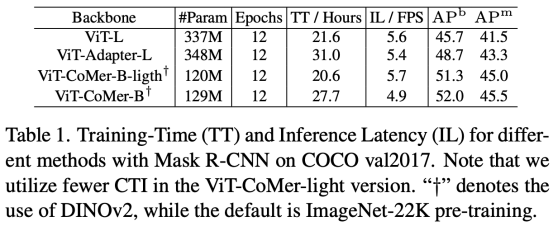
По тому же эффекту ViT-CoMer лучше справляется с обучением и выводом (более короткие затраты времени). На основе системы обнаружения Mask-RCNN сравниваются и анализируются характеристики ViT-Large, ViT-Adapter-Large и ViT-CoMer-Base-light. Видно, что ViT-CoMer-Base-light (с использованием маленького. количество модулей CTI) Получите лучшие результаты за более короткое время обучения и вывода.
1.3. Масштабируемость
Используйте расширенное предварительное обучение по нулевой цене.
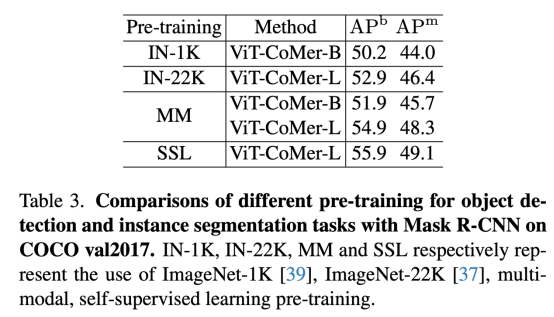
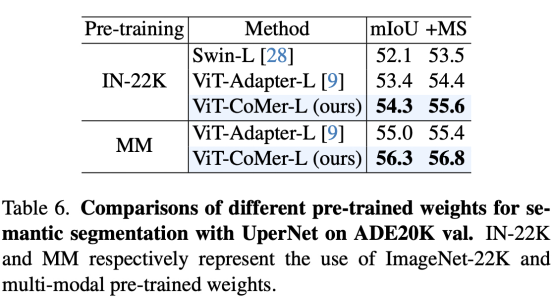
Ви Т-Ко Мер может напрямую загружать различные предобучения (такие как ImagNet-1K, ImageNet-22K, MM и т.д.).на основеMask-RCNNОбнаружение和UperNetразделениерамка,Используйте Imagenet-1K последовательно,Предварительно обученная ветвь инициализации ViT, такая как Imagenet-22K и мультимодальность. Из Таблицы 3 и Таблицы 6 мы видим, что чем сильнее предтренировочный,алгоритм Чем лучше.
Эффективно совместим с различными платформами алгоритмов.
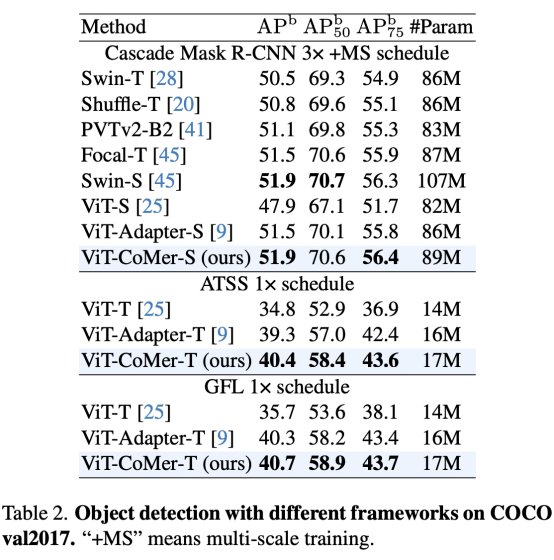
ViT-CoMer может быть напрямую встроен в различные системы обнаружения.ВоляViT-CoMerМигрировать вCascade Из таблицы 2 видно, что в таких средах обнаружения, как Mask-RCNN, ATSS и GFL, ViT-CoMer более эффективен, чем другие магистральные сети.
Легко адаптируется к различным трансформерам
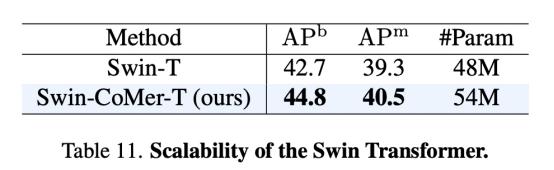
CoMer может не только адаптироваться к структуре ViT, но и другие базовые магистральные сети (например, Swin) также могут быть легко адаптированы.我们尝试ВоляCoMerМигрировать вViTКромеTransformerрамкасередина,Мы были приятно удивлены, обнаружив,CoMer также может сыграть в этом свою роль.,Как видно из таблицы 11,После адаптации эффект X-CoMer лучше, чем у базовой модели.
Эффективная стратегия PEFT (контент с опровержением будет добавлен на github позже)
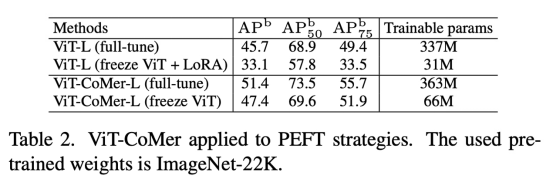
CoMer также можно использовать в качестве эффективной стратегии PEFT.когда мыfreezeжитьViTчасть,Обучайте только некоторые параметры CoMer,Видно, что эффект CoMer лучше, чем у LoRA (ViT-CoMer-L (заморозка ViT) > ViT-L(full-tune) > ViT-L(freeze ViT + LoRA))。
Задачи плотного прогнозирования – это не предел
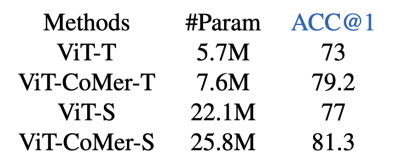
Помимо задач плотного прогнозирования, мы также опробовали влияние Ви Т-Ко Мера на задачи классификации. Мы сравнили результаты ViT и ViT-CoMer на наборе данных Imagenet, и эксперимент показывает, что наш алгоритм по-прежнему очень конкурентоспособен.
2. Мотив
Текущая магистральная сеть Transformer имеет следующие проблемы при выполнении интенсивных задач прогнозирования:
- Магистральная сеть ViT выполняет интенсивные задачи прогнозирования (обнаружение、сегментация и т. д.) работает плохо;
- Специально созданные магистрали необходимо переобучать, что увеличивает затраты на обучение;
- Основа адаптации взаимодействует только с ViT и сверточными функциями.,Отсутствует информационное взаимодействие между объектами разных масштабов.
В ответ на три вышеупомянутые проблемы компания Vit-CoMer провела следующие оптимизации:
- Что касается вопросов 1 и 2, мы разработали новую магистральную сеть плотного прогнозирования.,Он объединяет функции ViT и CNN. Поскольку сеть сохраняет полную структуру ВИТ,Таким образом, вы можете эффективно использовать различные предварительно обученные веса ViT с открытым исходным кодом.,В то же время сеть объединяет функции многомасштабной свертки в многорецептивном полевом пространстве.,Это решает проблему отсутствия взаимодействия между функциями ViT и единым масштабом представления.
- В ответ на вопрос 3 спроектирован модуль двустороннего взаимодействия CNN-Transformer, который может не только обогащать и усиливать признаки между собой, но и одновременно объединять многомасштабные признаки между уровнями, тем самым получая более богатую семантическую информацию. и облегчение обработки задач плотного прогнозирования.
3. Планируйте
3.1. Общая основа
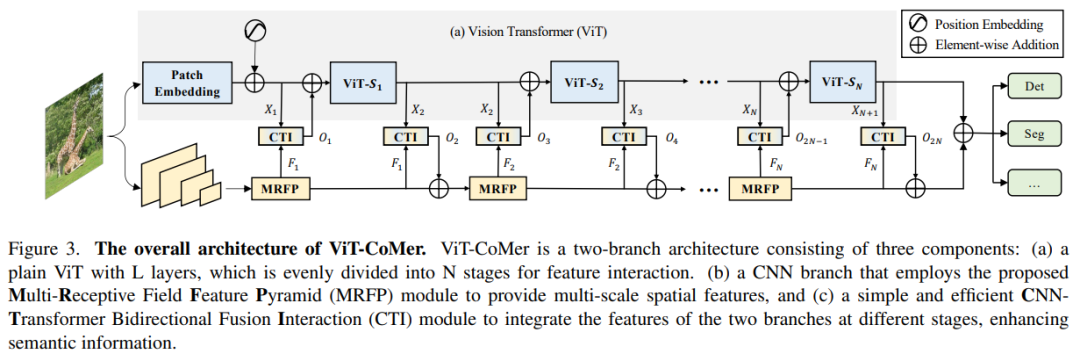
Архитектура сети ViT-CoMer очень проста (как показано на рисунке 3), в которой ViT занимает основную часть (как показано в красном блоке 1), адаптируясь к облегченной структуре CNN (как показано в зеленом блоке). Вся структура содержит 2 ключевых модуля: MRFP (например, Green 2) и CTI (например, Green 3). Основная функция MRFP — дополнять информацию о многомасштабных и локальных функциях. Роль CTI заключается в расширении информации о различных архитектурных особенностях.
3.2. Модуль пирамиды характеристик мультирецепторного поля (MRFP).
MRFP состоит из пирамиды признаков и сверточного слоя мультирецепторных полей. Пирамида функций может предоставить богатую многомасштабную информацию, а последняя расширяет восприимчивое поле за счет различных ядер свертки, расширяя возможности моделирования функций CNN на больших расстояниях. Этот модуль показан на рисунке 4.
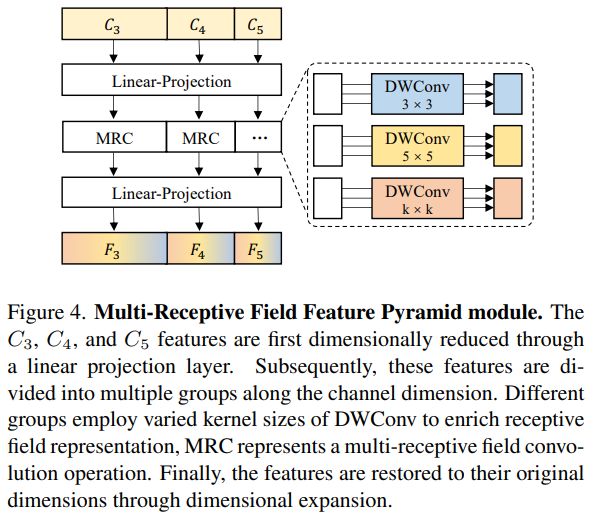
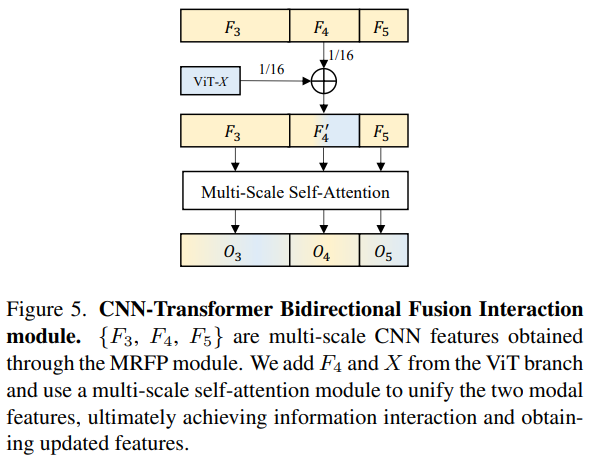
3.3.CNN-Трансформаторный двусторонний интерактивный термоядерный модуль (CTI)
CTI — это метод объединения функций между архитектурами, как показано на рисунке 5. Без изменения структуры ViT вводятся многомасштабные функции CNN. Поскольку ViT представляет собой одномасштабную функцию, а CNN является многомасштабной функцией, функции того же масштаба, что и ViT, в CNN добавляются непосредственно во время реализации ( Преимущество, просто и эффективно). В то же время над добавленными функциями выполняются многомасштабные операции самообслуживания, так что на функции разных масштабов также можно ссылаться и улучшать. Благодаря модулю двустороннего взаимодействия CTI решает проблему отсутствия локального информационного взаимодействия и неиерархических функций в ViT, одновременно расширяя возможности моделирования на больших расстояниях и семантического представления CNN.
4.Эффекты визуализации
Визуальный сравнительный анализ обнаружения целей и сегментации экземпляров

По сравнению с ВИТ:С картинки6Это можно увидеть,ViT-CoMer создает более иерархические многомасштабные функции,Богатые локальные края и текстуры,Улучшено обнаружение объектов и сегментация экземпляров.

По сравнению с ViT-Adapter (контент Rebuttle будет добавлен на github позже):С картинки1Это можно увидеть,ViT-Adapter и ViT-CoMer имеют богатую многомасштабную текстурную информацию.,Но по сравнению с Ви Т-Адаптером, Детализация информации у «Ви Т-Ко Мер» еще выше. Пожалуйста, прочитайте исходный текст и код для более подробной информации.
Reference Xia, C., Wang, X., Lv, F., Hao, X., & Shi, Y. (2024). ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
