CVPR 2023 | Видео AIGC, прогнозирование/вставка/генерация/редактирование кадров
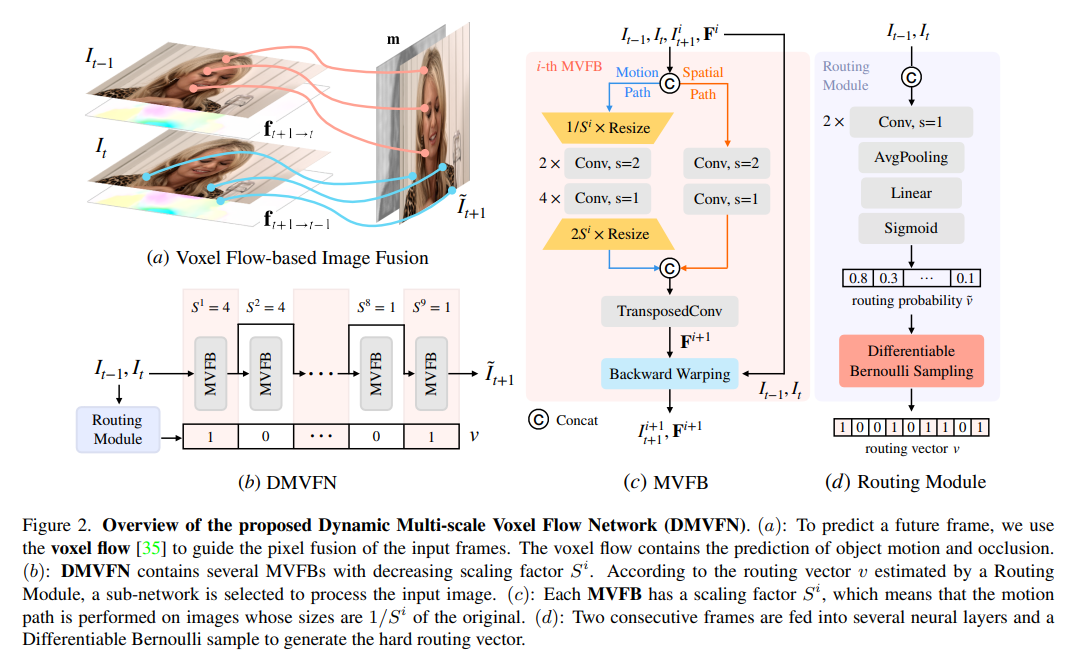
1、A Dynamic Multi-Scale Voxel Flow Network for Video Prediction
- видеопредсказывать(video прогнозирование) производительность была значительно улучшена благодаря передовым глубоким нейронным сетям. Однако большинство современных методов страдают от большого размера изображения и требуют дополнительных входных данных (например, семантических карт/карт глубины) для достижения хорошей производительности. По соображениям эффективности в этой статье предлагается динамическая многомасштабная сеть потоков вокселов (Dynamic Multi-scale Voxel Flow Network,DMVFN),Только на основе изображений RGB,Более высокая производительность прогнозирования может быть достигнута при меньших вычислительных затратах.,На порядок быстрее, чем предыдущие методы.
- DMVFNЯдро – это то, что может эффективно восприниматьвидеорамкаспорт Модуль масштабируемой дифференцируемой маршрутизации(differentiable routing модуль). После завершения обучения на этапе вывода для различных входных данных выбираются адаптивные подсети. Эксперименты с несколькими тестами показывают, что по сравнению с Deep Voxel Flow, DMVFN на порядок быстрее и превосходит производительность новейшего итерационного OPT в создании качества изображения.
- https://huxiaotaostasy.github.io/DMVFN/
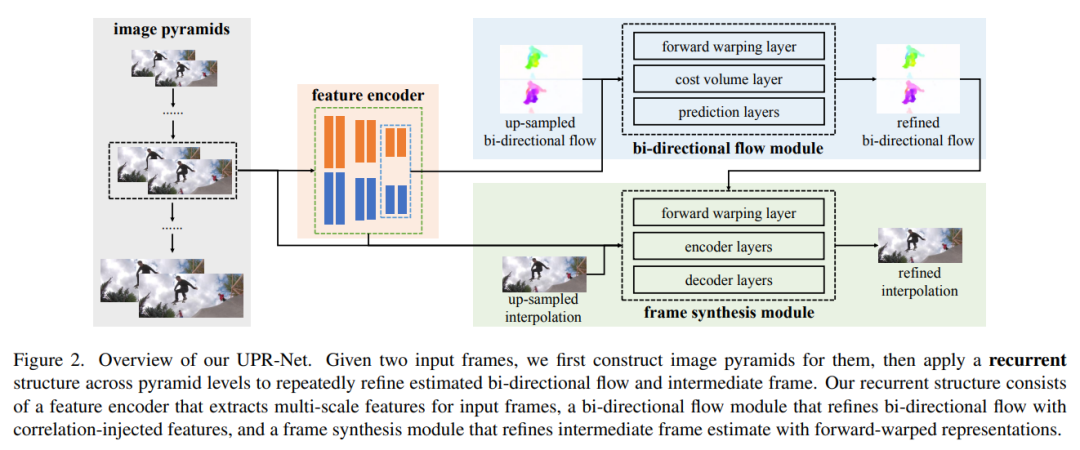
2、A Unified Pyramid Recurrent Network for Video Frame Interpolation
- Синтез, управляемый потоком synthesis),Предоставляет общий кадр для интерполяции кадров.,где оптический поток, по оценкам, управляет синтезом промежуточных кадров между двумя последовательными входами. В этой статье предлагается новая унифицированная пирамидальная рекуррентная сеть (UPR-Net) для интерполяции кадров. UPR-Net использует гибкую пирамидальную рамку,Использование облегченных модулей контура для оценки двунаправленного потока и синтеза промежуточных кадров. на каждом уровне пирамиды,Он использует оцененные двунаправленные потоки для создания представлений прямой деформации для синтеза кадров, охватывающих уровни пирамиды;,Это обеспечивает итеративную оптимизацию оптического потока и промежуточных кадров. Стратегии итеративного синтеза могут значительно повысить надежность интерполяции кадров в ситуациях с большим движением.
- Хотя базовая версия на базе UPR-Net чрезвычайно легкая (1,7М параметров),Но он показывает хорошие результаты в широком диапазоне тестов. Код и обучение модели серии UPR-Net находятся по адресу https://github.com/srcn-ivl/UPR-Net.
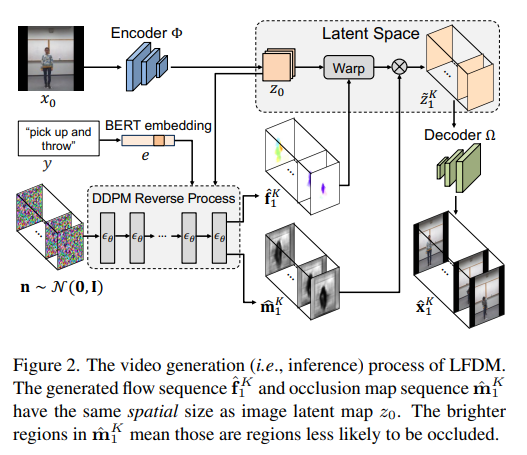
3、Conditional Image-to-Video Generation with Latent Flow Diffusion Models
- Условное изображение для видео (Условное поколения изображения в видео (cI2V), целью которого является синтез нового plausible видео. Ключевой задачей задачи cI2V является одновременное создание пространственного облика и временной динамики, соответствующих заданным изображениям и условиям.
- В данной статье предлагается метод, основанный на новом типе модели подповерхностной диффузии (латентной flow diffusion models,LFDM) метод cI2V. По сравнению с предыдущим прямым синтезом,LFDM лучше использует пространственный контент данного изображения,Деформации выполняются в скрытом пространстве для синтеза деталей и движения. Обучение LFDM разделено на два независимых этапа: (1) Этап обучения без присмотра.,Для обучения автокодировщиков скрытого потока для генерации пространственного контента.,где предиктор потока используется для оценки потенциального потока между парами кадров (2) этап условного обучения,Для обучения модели диффузии (DM) на основе 3D-UNet для генерации временного скрытого потока. LFDM требует только изучения низкоразмерного скрытого пространства потока для генерации движения.,Вычислительная эффективность.
- Полностью протестировано на нескольких эпизодах данных.,Докажите, что LFDM неизменно превосходит существующие технологии. также,Покажите, что LFDM можно легко адаптировать к новым областям, просто настроив декодер изображений. Код находится по адресу https://github.com/nihaomiao/CVPR23_LFDM.
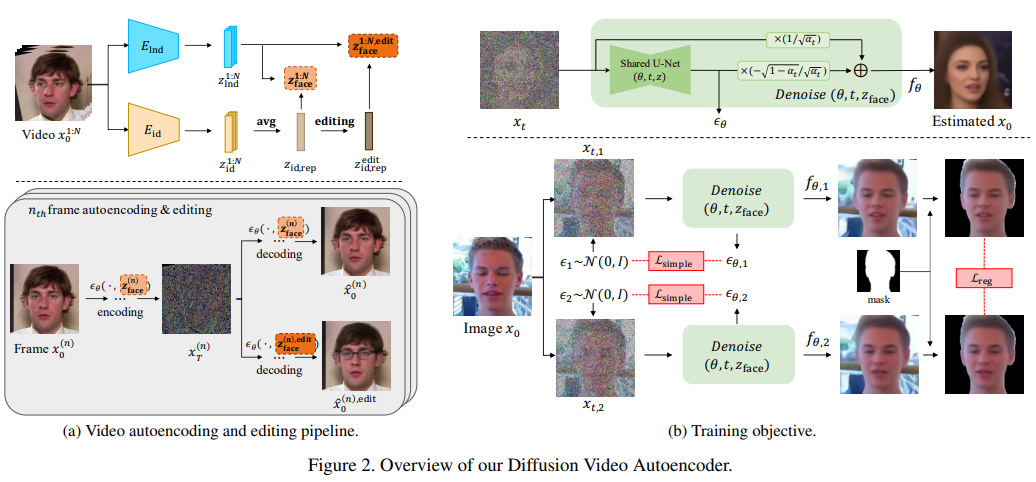
4、Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
- Вдохновлен превосходной производительностью новейших методов редактирования изображений лиц.,Некоторые исследования, естественно, предлагают распространить эти методы на задачи редактирования видео. Одной из основных проблем является временная согласованность между кадрами редактирования.,Это до сих пор не решено.
- с этой целью,Предлагается новая рамка редактирования лица на основе диффузионного автоэнкодера.,Возможность редактирования для достижения согласованности путем простого манипулирования временно стабильными функциями. Еще одним уникальным преимуществом Модели является то, что,Модель, основанная на диффузии, может удовлетворять возможностям как реконструкции, так и редактирования.,И в отличие от существующих методов на основе GAN,Выдерживает экстремальные ситуации,Видео с естественными лицами сцены (например, закрытыми лицами).
- https://diff-video-ae.github.io/
5、Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation
- Эффективно извлекайте информацию о межкадровом движении и внешнем виде для интерполяции видеокадров (видео frame интерполяция (VFI) очень важна. Раньше либо извлекалась смесь этих двух типов информации, либо для каждого типа информации требовался подробный отдельный модуль, что приводило к неоднозначности и неэффективности представления.
- В этой статье предлагается новый модуль для явного извлечения информации о движении и внешнем виде посредством унифицированных операций. В частности, пересматривается обработка информации при межкадровом внимании, и ее карта внимания повторно используется для улучшения характеристик внешнего вида и извлечения информации о движении. Кроме того, для достижения эффективного VFI модуль можно легко интегрировать в гибридные архитектуры CNN и Transformer. Этот гибридный конвейер может облегчить вычислительную сложность межкадрового внимания, сохраняя при этом подробную структурную информацию низкого уровня.
- Результаты экспериментов показывают,Как с точки зрения интерполяции с фиксированным интервалом, так и с произвольным интервалом.,Этот метод обеспечивает высочайшую производительность на различных наборах данных. в то же время,По сравнению с моделью с аналогичными характеристиками,Имеет меньшие вычислительные затраты. Исходный код и модель на https://github.com/MCG-NJU/EMA-VF.
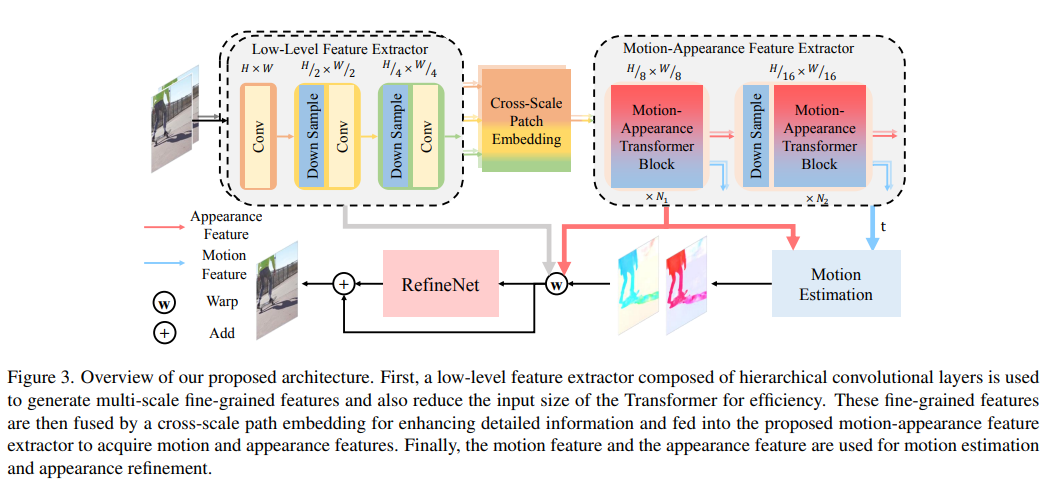
6、MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
- Предложена первая совместная аудио-кадр, сгенерированная видео,Обеспечивает захватывающий опыт просмотра и прослушивания одновременно,Создан для создания высококачественного и реалистичного видео. Для создания совместных звуковых пар видео,Предлагается новая модель мультимодальной диффузии (т.е. ММ-диффузия).,К ним относятся два связанных автоэнкодера шумоподавления. В отличие от существующей одномодальной модели диффузии,MM-Diffusion состоит из последовательной мультимодальной сети U-Net.,Разработан для совместного процесса шумоподавления. Две подсети для аудио и видео постепенно учатся генерировать выровненные пары аудио-видео из гауссовского шума.
- Результаты экспериментов показывают,В задачах генерации безусловных тональных видео и задач обработки нулевой выборки (например,,видео в аудио) с превосходными результатами. Код и модель предварительного обучения на https://github.com/researchmm/MM-Diffusion.
7、MOSO: Decomposing MOtion, Scene and Object for Video Prediction
- Движение, сцена и объект — три основных визуальных компонента видео. в частности,Объект представляет собой передний план,сцена представляет собой фон,Движение отслеживает их динамику. Исходя из этого понимания,В этой статье предлагается двухэтапная схема декомпозиции движения, сцены и объекта (декомпозиция движения, сцены и объекта).,MOSO),Используется для видеопрогнозирования.,Включает MOSO-VQVAE и MOSO-трансформатор.
- на первом этапе,MOSO-VQVAE разбивает предыдущие клипы на компоненты движения, сцены и объекта.,И представить их как разные дискретные группы токенов. Затем,на втором этапе,MOSO-Transformer прогнозирует токены объектов и сцен для последующих клипов на основе предыдущих токенов.,И в сгенерированных объектах и сценахtokenДобавить динамику на уровнеспорт。
- рамка Может быть легко расширено до безусловноговидео Генерировать ивидеозадача интерполяции кадров。Результаты экспериментов показывают,Этот метод обеспечивает новую современную производительность в пяти сложных тестах для прогнозирования видео и безусловной генерации видео: BAIR, RoboNet, KTH, KITTI и UCF101. также,MOSO может создавать реалистичное видео, комбинируя объекты и сцены из разных видео.
- https://github.com/iva-mzsun/MOSO

8、Text-Visual Prompting for Efficient 2D Temporal Video Grounding
- В данной статье рассматривается темпоральная локализация видео (временная video grounding,ТВГ) вопрос,Его цель — предсказать временные точки начала и окончания видео момента, описанного текстовым предложением. Благодаря преимуществам прекрасных 3D-визуальных функций,За последние годы TVG добилась значительного прогресса. Однако,Высокая сложность 3D-сверточных нейронных сетей (CNN) требует много времени.,Требует большого количества памяти и вычислительных ресурсов.
- Для достижения эффективного TVG,Предлагаю новую текстово-визуальную подсказку (ТВП) кадр,Оптимизированный шаблон возмущений (оптимизированный perturbation шаблоны (называемые «подсказками») включены в визуальный ввод и текстовые функции TVGModel. с 3D По сравнению с CNN, TVP эффективен в 2D. Визуальный и языковой кодировщик совместно обучаются в модели TVG, а разреженные 2D-визуальные функции низкой сложности используются для повышения производительности кросс-модального объединения функций. Кроме того, для эффективного обучения TVG предлагается потеря временного расстояния по U (TDIOU). На основе Charades-STA и ActivityNet. Эксперименты на наборе «Титры» доказывают, что TVP существенно улучшает 2D. Производительность TVG (улучшение на 9,79% по Charades-STA и ActivityNet) Улучшение подписей на 30,77%), а по сравнению с использованием визуальных функций 3D для TVG ускорение вывода достигает 5 раз.
- https://github.com/intel
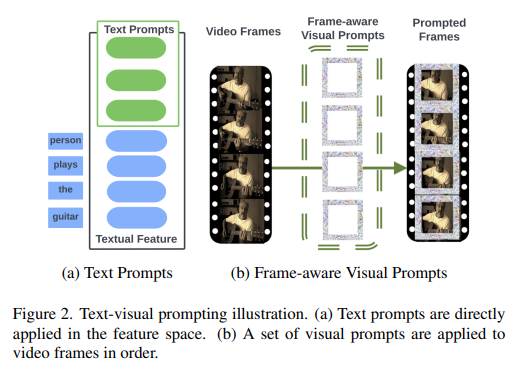
9、Towards End-to-End Generative Modeling of Long Videos with Memory-Efficient Bidirectional Transformers
- Авторегрессионный преобразователь превосходно справляется с созданием видео. Однако,Ограничено квадратичной сложностью самовнимания,Долгосрочные зависимости в видео невозможно изучить напрямую.,и страдает от медленного времени вывода и распространения ошибок из-за процесса авторегрессии.
- В этой статье предлагается двусторонний преобразователь с эффективным использованием памяти (эффективное использование памяти). Bidirectional Transformer,MeBT),Долгосрочные зависимости и быстрый вывод в сквозном обучении. На основе последних событий,Метод учится декодировать весь пространственно-временной объем параллельно из частично наблюдаемых участков. Имеет линейную временную сложность как при кодировании, так и при декодировании.,Проецируя наблюдаемый токен контекста на фиксированное количество скрытых токенов.,И заставьте их кодировать и декодировать токены маски посредством перекрестного внимания.
- Из-за линейной сложности и двунаправленного моделирования,Этот метод обеспечивает значительные улучшения качества и скорости по сравнению с авторегрессией при создании видео в течение умеренно длительных периодов времени. видео и код на https://sites.google.com/view/mebt-cvpr2023
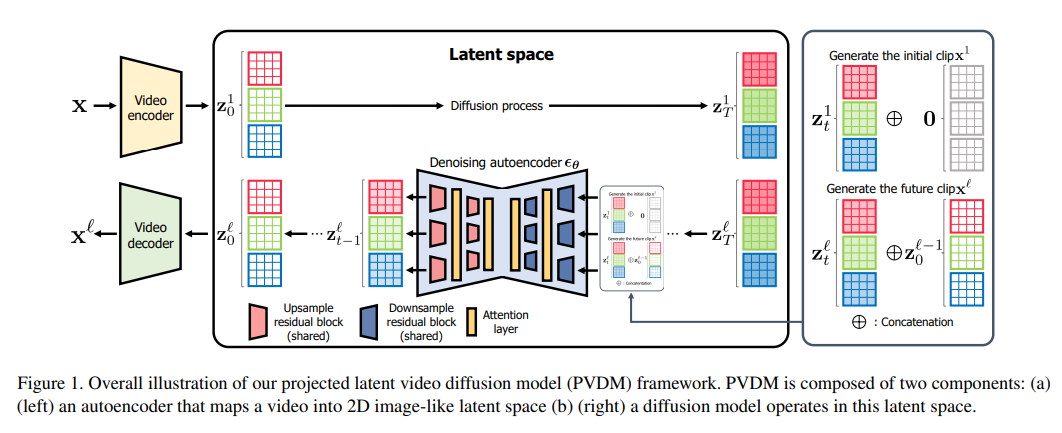
10、Video Probabilistic Diffusion Models in Projected Latent Space
- Несмотря на значительный прогресс в глубокой генерации Модель,Однако из-за больших размеров, сложной пространственно-временной динамики и больших пространственных изменений,Синтез изображений высокого разрешения и когерентных во времени остается сложной задачей. Недавнее исследование диффузионных моделей показывает их потенциал для решения этой проблемы.,Но они сталкиваются с проблемами эффективности вычислений и памяти.
- Чтобы решить эту проблему,В этой статье предлагается новая модель видеогенератора.,Известна как модель прогнозируемой потенциальной видеодиффузии (PVDM).,Это модель диффузии вероятностей.,Распределение видео можно изучить в низкомерном скрытом пространстве.,Поэтому видео высокого разрешения можно эффективно обучать при ограниченных ресурсах. Конкретно,PVDM состоит из двух компонентов: (а) автоэнкодера,Спроецируйте данное видео в скрытый вектор 2D-формы.,Эти векторы разлагают сложную кубическую структуру видеопикселей и (б) диффузную архитектуру Модели;,Специально разработан для новых скрытых пространств разложения и процессов обучения/отбора проб.,И используйте одну модель для синтеза видео любой длины. Эксперименты с популярными наборами данных, генерируемыми видео, демонстрируют превосходство PVDM над предыдущими методами синтеза видео;,PVDM получил оценку FVD 639,7 в тесте генерации длинных видео (128 кадров) UCF-101.,Это улучшение на 1773,4 по сравнению с предыдущим лучшим методом.
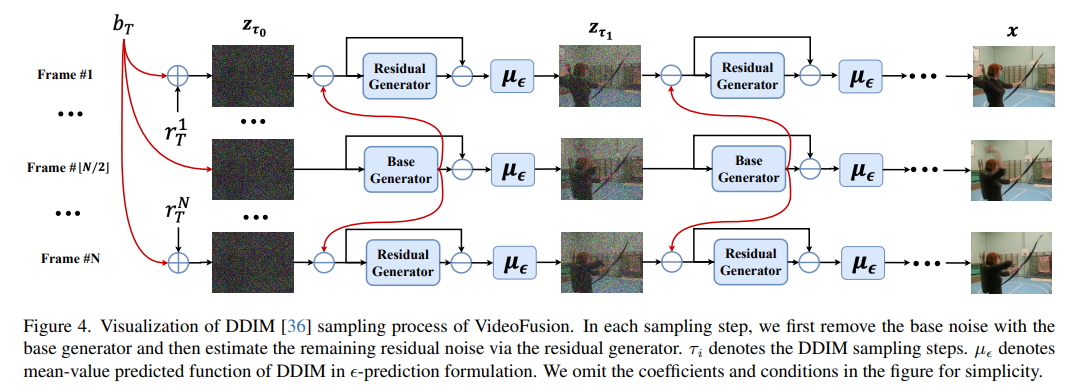
11、VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
- Модель вероятности диффузии (DPM) строит процесс прямого распространения, постепенно добавляя шум к данным.,и изучите процесс обратного шумоподавления для создания новых образцов,Доказано, что он справляется со сложным распределением данных. Несмотря на успехи в создании изображений,Но применить DPM для генерации видео по-прежнему сложно.,Потому что он обращен к многомерному пространству данных. Предыдущие методы обычно использовали стандартные процессы диффузии.,при котором кадры внутри одной сети искажаются независимым шумом,Избыточность контента и временные зависимости игнорируются.
- В этой статье шум каждого кадра решается путем разделения его на базовый шум, общий для всех кадров, и остаточный шум, который изменяется по оси времени.,Предложен процесс разложения-диффузии. В процессе шумоподавления используются две совместно обученные сети для соответствующего согласования с разложением шума. Эксперименты с различными наборами данных подтверждают, что метод (называемый VideoFusion) превосходит альтернативы на основе GAN и диффузии с точки зрения генерации высококачественного видео.
Следите за общедоступной учетной записью [Машинное обучение и создание с помощью искусственного интеллекта], вас ждут еще более интересные вещи.
Простое введение в ControlNet, управляемый алгоритм генерации изображений AIGC!
Классический GAN следует читать: StyleGAN.
Нажмите на меня, чтобы просмотреть серию альбомов GAN~!
Чашка чая с молоком и станьте законодателем мод в видении AIGC+CV!
Самый последний и самый полный сборник из 100 статей! Создание моделей диффузии Модели диффузии
ECCV2022 | Краткое изложение некоторых статей о генеративно-состязательной сети GAN
CVPR 2022 | 25+ направлений, последние 50 статей ГАН
ICCV 2021 | Краткое изложение 35 тематических документов GAN
Более 110 статей! ЦВПР Самый полный обзор документов GAN в 2021 году
Более 100 статей! Самый полный обзор документов GAN CVPR 2020
Распаковка нового GAN: развязка представления MixNMatch
StarGAN версия 2: создание изображений многодоменного разнообразия
Прикрепленная загрузка | «Объяснимое машинное обучение» на китайском языке
Прикрепленная загрузка |《TensorFlow 2.0 Алгоритм глубокого обучения на практике》
Прикрепленная загрузка обмен "Математические методы в компьютерном зрении" |
«Обзор методов обнаружения поверхностных дефектов на основе глубокого обучения»
«Обзор классификации изображений с нулевым выстрелом: Десять лет прогресса》
«Обзор маловыборочного обучения на основе глубоких нейронных сетей»



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
