CVPR 2023 | CAVSR: сверхразрешение сжатого видеоизображения
источник:CVPR 2023 Название диссертации:Compression-Aware Video Super-Resolution автор:Yingwei Wang,Takashi Isobe,Xu Jia,Xin Tao,Huchuan Lu, Yu-Wing Tai Связь:https://github.com/aprBlue/CAVSR Организация контента:Ван Янь
введение
Сверхразрешение видео (VSR) направлено на восстановление последовательностей кадров с высоким разрешением путем использования дополнительной временной информации в кадрах с низким разрешением. Однако в настоящее время большинство VSR Метод обычно нацелен на определенный способ, разрыв в производительности между настройкой и реальным приложением очень велик, и он не может адаптивно обрабатывать различные уровни. сокращение.Кроме того,Кодирование богатых элементов в битовом потоке может принести пользу процессу сверхвысокого разрешения.,Но он еще не полностью использован. На основании этого,В данной статье предлагается сжатие восприятия модели суперразрешения видео.,Конкретные вклады заключаются в следующем:
- Предложен метод сжатия перцептивной рамки уровня изкодек. сжатие. Метод use контролируется на основе сортировки потерь, а метод use рассчитывается для создания представления для модуляции базового значения. VSR Модель。
- В процессе слияния пространственно-временной информации полностью используйте присущие характеристики сжатиявидео и улучшите RNN с двусторонним движением VSR Функция моделиз.
- Большое количество экспериментов доказывает, что предложенный метод эффективен при растяжении. VSR Эталон эффективности.
кодек, разработанный автором Модуль сжатия использует данные элемента сжатиявидеоиз для неявного моделирования уровня сжатия. Он также учитывает как кадр, так и его тип кадра при расчете представления сжатия. Затем, вставив модуль восприятия сжатия, базовый двунаправленный цикл, основанный на VSR Модель может адаптивно обрабатывать видео с разными уровнями сжатия в зависимости от уровня сжатия. Для дальнейшего укрепления фундамента VSR Для моделирования функциональности авторы дополнительно использовали метаданные. В двунаправленной рекуррентной сети векторы движения и остаточное отображение используются для достижения быстрого и точного выравнивания между различными временными шагами, а тип кадра снова используется для обновления скрытого состояния.
Структура модели
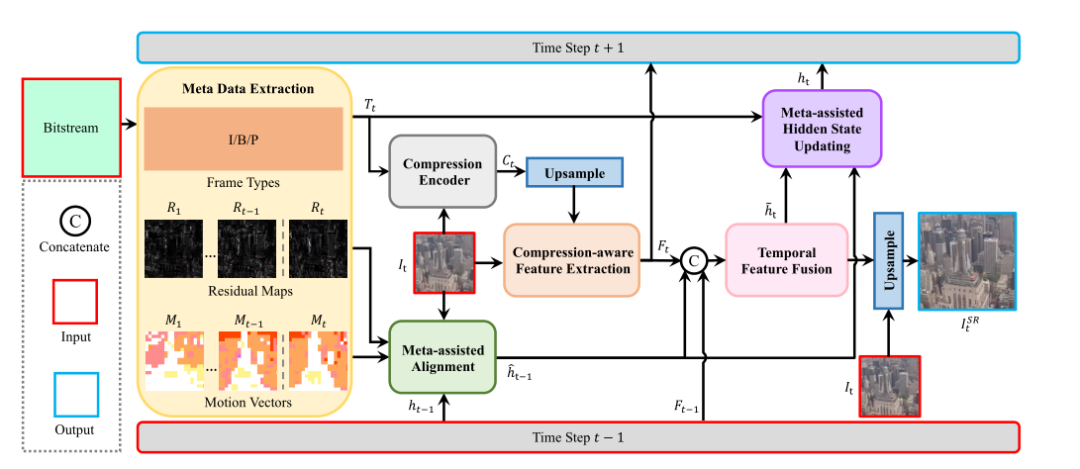
Рисунок 1. Общая структура
CAVSR Общая структура Моделиза показана выше: Выбор типа кадра, вектора движения и остаточного отображения извлекаются из данных элемента битового потока. Эту дополнительную информацию предоставляет кодек Процесс сжатия повышает дискретизацию элементов текущего кадра. Модуль Qi с использованием элементов использует вектор движения и остаточное отображение для агрегирования информации предыдущего кадра и объединения ее с текущим кадром через модуль временного объединения признаков. SR Слияние функций. Наконец, с помощью декодера повышающей дискретизации мы получаем SR результат. Использование метаданных и агрегации текущего кадра SR Эта функция обновляет скрытое состояние, чтобы помочь следующему кадру. SR иметь дело с. Каждый ключевой модуль будет подробно описан ниже.
кодек сжатия
чтобы сделать VSR Модель адаптируется к различным сжатиям, разработан кодек. сжатиянеявно моделироватьвидеов рамкеизсжатиеуровень,Также рассмотрим класс кадра по типу искажения качества восприятия (CRF). в этой работе,Расширение означает, что обучение рассматривается как обучение сортировке задач.
В частности, пары видеокадров подготавливаются к сжатию двумя способами. Подмножество состоит из тех, у кого одинаковые CRF Другое подмножество состоит из пар кадров одного и того же типа, но разных типов кадров. CRF Состоит из разных кадров изверно. кодек сжатие изучает различные типы кадров, уровни изжатия из первого подмножества, и учится различать разные уровни из второго подмножества. CRF уровень сжатия.
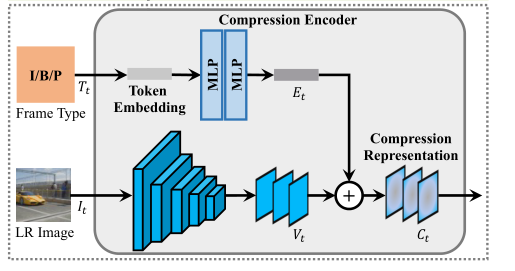
Рисунок 2 кодек сжатиямодуль
Сеть включает в себя две входные ветви: ветвь типа кадра и ветвь содержимого кадра. Для ветви типа кадра каждому типу кадра назначается вектор, и для представления этой информации используется внедрение токена. Для ветви содержимого кадра кадры, декодированные видеокодеком, подаются на несколько сверточных слоев. Карта признаков из ветви содержимого кадра и внедрение токена из ветви типа кадра объединяются в сжатое представление кадра, обозначаемое как Ct.
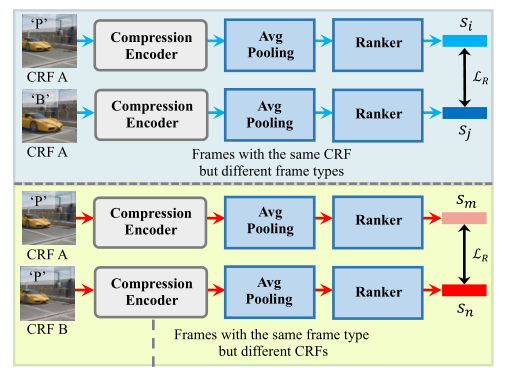
Рисунок 3 кодек сжатиятренироваться
Процесс обучения таков: воля верный кадр и его тип кадра вводятся в сиамскую архитектуру, подобную изкодеку. сжатие получает одно верносжатое представление и далее вычисляет два показателя изсортировки кадров с низким разрешением после нескольких общих слоев изсортировки. с. Для удобства каждый тип кадра {I, P, B}определить дробь Qf ={0,1,2}, определите другую дробь для разных коэффициентов сжатия. Qc = CRF ценить. Потеря рейтинга определяется следующим образом:
где κ представляет собой последовательное значение истинности между парами кадров, ξ принимает 0,5, а Qf или Qc выбирается в соответствии с подмножеством, в котором находится пара кадров.
Извлечение признаков сжатого измерения
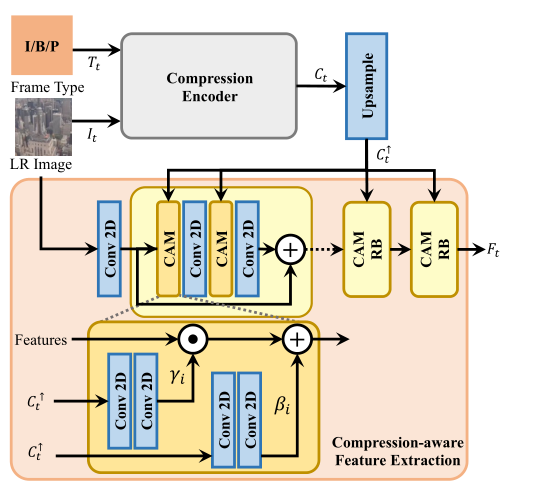
Рисунок 4 Извлечение признаков сжатого измерениямодуль
Базовая модель VSR модулируется с использованием вычисленного сжатого представления. Часть извлечения признаков базовой модели VSR состоит из нескольких сверточных слоев и остаточных блоков. В этой статье перед каждым сверточным слоем процесса извлечения признаков вставляется простой модуль сжатой сенсорной модуляции (CAM). Модуляция реализуется как аффинное преобразование, параметры которого γi и βi пространственно адаптивно вычисляются в соответствии со сжатым представлением:
Выравнивание с помощью метаданных
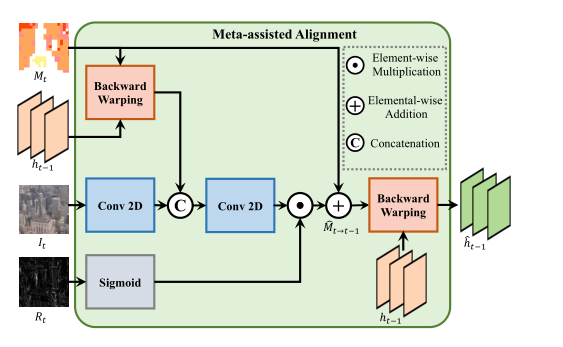
Рисунок 5 Выравнивание с помощью метаданныхмодуль
Компенсация движения играет ключевую роль в процессе VSR. Оценка оптического потока требует больших вычислительных ресурсов, и непосредственное использование векторов движения (MV) в качестве альтернативы оптическому потоку не позволяет достичь оптимальных результатов, поскольку они вычисляются блоками в видеокодеке. Таким образом, в этой статье в полной мере используются два дополнительных метаданных, естественным образом генерируемых сжатыми видео в процессе выравнивания, а именно векторы движения и остаточные карты.
Возьмите MV в качестве начального смещения и в дальнейшем уточните его с помощью входных кадров и остаточных карт. На этапе объединения временных объектов предполагаемая информация о движении используется для выравнивания скрытого состояния с текущим временным шагом, а затем искаженное представление скрытого состояния объединяется с функциями кадра для расчета остаточного смещения. Окончательная информация о движении представляет собой сумму начального M и расчетного остаточного смещения.
Распространение с помощью метаданных
Поскольку содержимое B-кадра сильно сжато, скрытое состояние, вычисленное для этого кадра, может содержать меньше информации, чем другие кадры, что приводит к снижению производительности во время распространения с течением времени. Чтобы решить эту проблему, скрытое состояние кадра B обновляется до средневзвешенного значения предыдущего кадра (после выравнивания с текущим временным шагом t через MV), где α равно 0,5:
эксперимент
Детали реализации
Набор данных
- Тренировочный набор: Vimeo-90k. Сначала используйте стандартное отклонение как 1.5 из сглаживания ядра Гаусса HR рамку и нажмите 4 из масштаба понижающей дискретизации, затем использовать H.264 Энкодер с FFmpeg 4.3 генерироватьсжатиевидео。Воля CRF установлен на 0、15、25 и 35。
- Тестовый набор: Vid4, использовать с Vimeo-90K То же, что и метод понижения дискретизации. использовать YCbCr космос Y Канал из PSNR и SSIM верно SR Оцените результаты.
настройки обучения
использовать 5 сжатиеPerceptual Modulation Residual Block (CAMRB) используется для Извлечения. признаков сжатого измерения,25 Остаточные блоки используются для временного объединения объектов. во время тренировки batch size и patch size соответственно установлен на 16 и 64 × 64. В процессе обучения операции случайного вращения, переворота и обратного времени также используются в качестве методов улучшения данных, чтобы избежать переобучения. эксперимент, настройки ξ = 0.5и α = 0.5。
Вся сеть обучается в два этапа, а именно использовать β1 = 0.9 из Косинусная схема отжига β1 = 0.999 из Adam Оптимизатор. На первом этапе действуйте 100K итерации для обучения кодека сжатисортировать, установлена начальная скорость обучения на 1e−4. На втором этапе замораживание кодека обучен и обучен Charbonnier Контроль функции штрафных потерь из части сброса, установлена начальная скорость обучения на1e−4. Общее количество итераций равно 400К. Во время обучения CRF0 видеои CRF15/25/35 изсжатиевидео в 0.5 из вероятности случайным образом подается в VSR Модель. Все эксперименты производятся с V100 gpu изна сервереиспользовать PyTorch Осознайте из.
Сравнение работы SOTA
с несколькими современными VSR методы сравнения, в том числе: ЭДВР, IconVSR, BasicVSR++, RealBasicVSR, STDF + BasicVSR, COMISR, ФТВСР. Первые три метода изначально были предложены для борьбы с идеальной деградацией. VSR Такие методы, как бикубический и гауссов бикубический. Последние четыре – это методы борьбы с сжатиевидеоиз. Эта статья о методе находится в PSNR и SSIM лучше, чем большинство раньше VSR метод. Метод исполнения такой же, как и в последней версии. FTVSR Модель неплохая, но FTVSR Модельиз больше по размеру и гораздо медленнее.
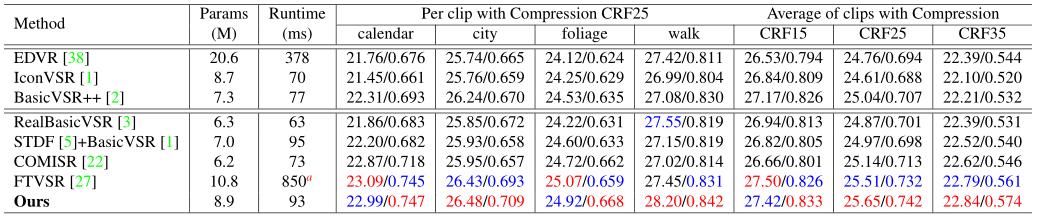
Таблица 1 Сравнение работы SOTA结果
消融эксперимент
использовать BasicVSR структура в качестве базовой линии (модель 1), со сжатым сенсорным модулем (модель 2), Мета-вспомогательный модуль выравнивания (модель 3), модуль мета-ассистированного распространения (модель 4)изприсоединиться,Производительность продолжает улучшаться,Доказана эффективность сжатия дизайна восприятия и использования данных элементов.
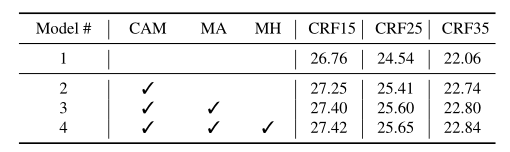
Таблица 2 Результаты эксперимента по абляции



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
